- Коллекции HashSet, HashMap

Содержание
- 2. Задание на практическую работу 2 1. Изучить теоретический материал (слайды 5-17). Внимательно ознакомиться с ожидаемыми результатами
- 3. Результат выполнения практической работы (задание 3)
- 4. Результат выполнения практической работы (задание 4)
- 5. Хеш-таблицы (hash table) Хеш-таблица (hash table) – это структура данных, обеспечивающая быструю вставку, поиск и удаление
- 6. Хеш-таблицы . Методы hashCode() и equals() Вычисление хэш-кода объекта и точное сравнение объектов – способы, которые
- 7. Хеш-таблицы (hash table) Работа с элементами хеш-таблицы выполняются по следующему алгоритму. 1. Вызов хеш-функции. Добавление нового
- 8. Хеш-таблицы. Понятие коллизии Коллизия – ситуация, при которой два разных объекта получают одинаковый хеш-код (см. рисунок).
- 9. Хеш-таблицы. Разрешение коллизий. Метод цепочек Метод цепочек (chaining) – каждой ячейке массива соответствует свой связный список.
- 10. Хеш-таблицы. Разрешение коллизий. Открытая адресация Открытая адресация (open addressing) – в каждой ячейке хеш-таблицы хранится не
- 11. Хеш-таблицы. Выводы 1. Хеш-таблица создается на основе массива. Главное преимущество хеш-таблиц – скорость добавления, поиска и
- 12. Интерфейсы Set, SortedSet, NavigableSet Интерфейс Set расширяет интерфейс Collection (см. практическую работу 1, слайды 7-8) и
- 13. Интерфейс Map Интерфейс Map – является самостоятельным интерфейсом (не расширяет интерфейс Collection, см. практическую работу 1,
- 14. Основные методы интерфейса Map
- 15. Классы коллекций
- 16. Реализация интерфейса Set. Класс HashSet Класс HashSet – реализует интерфейс Set, необходим для создания неупорядоченного множества
- 17. Реализация интерфейса Map. Класс HashMap Класс HashMap – реализует интерфейс Map, необходим для создания множества (отображения,
- 18. Применение класса HashSet 1.Создадим множество HashSet, например, cats, содержащее объекты ссылочного типа String, используя конструктор, определенный
- 19. Применение класса HashSet (начало)
- 20. Применение класса HashSet (окончание)
- 21. Применение класса HashMap 1. Создадим отображение HashMap, например, catMap, содержащее объекты ссылочного типа String, используя конструктор,
- 22. Применение класса HashMap (начало)
- 24. Скачать презентацию
Слайд 2Задание на практическую работу 2
1. Изучить теоретический материал (слайды 5-17). Внимательно ознакомиться
Задание на практическую работу 2
1. Изучить теоретический материал (слайды 5-17). Внимательно ознакомиться

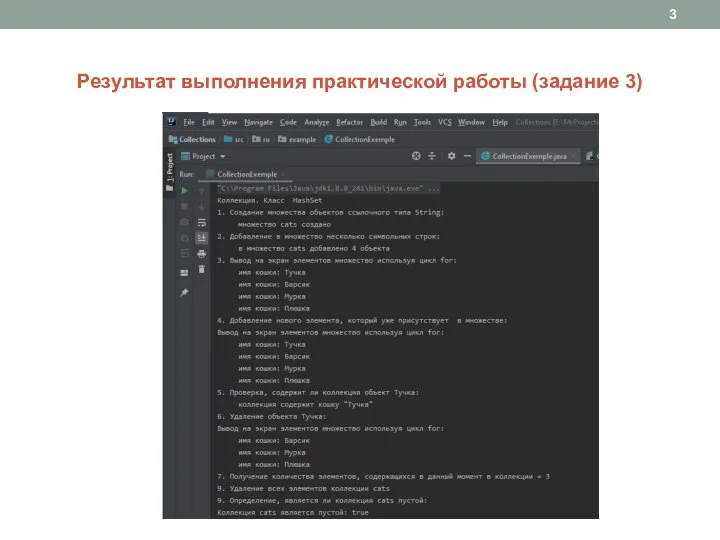
Слайд 3Результат выполнения практической работы (задание 3)
Результат выполнения практической работы (задание 3)
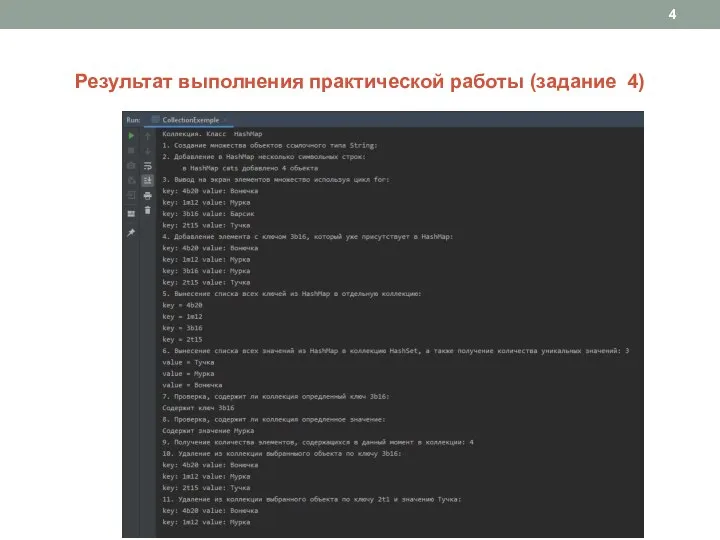
Слайд 4Результат выполнения практической работы (задание 4)
Результат выполнения практической работы (задание 4)
Слайд 5Хеш-таблицы (hash table)
Хеш-таблица (hash table) – это структура данных, обеспечивающая быструю вставку, поиск
Хеш-таблицы (hash table)
Хеш-таблица (hash table) – это структура данных, обеспечивающая быструю вставку, поиск

Слайд 6Хеш-таблицы . Методы hashCode() и equals()
Вычисление хэш-кода объекта и точное сравнение объектов
Хеш-таблицы . Методы hashCode() и equals()
Вычисление хэш-кода объекта и точное сравнение объектов

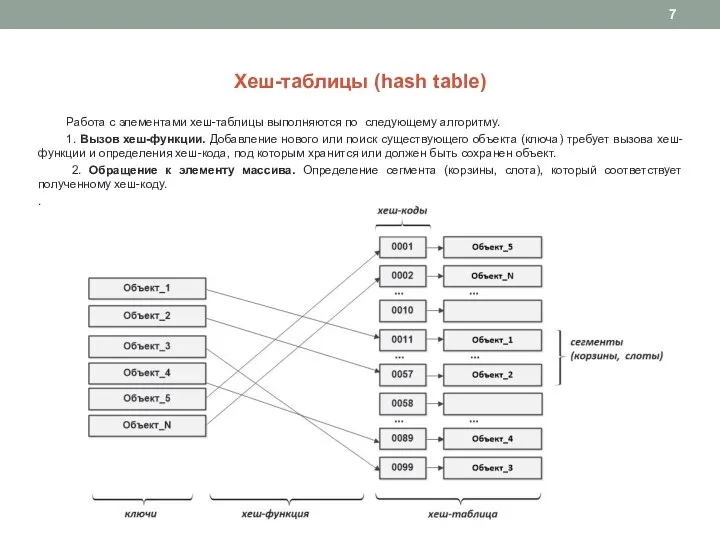
Слайд 7Хеш-таблицы (hash table)
Работа с элементами хеш-таблицы выполняются по следующему алгоритму.
1. Вызов
Хеш-таблицы (hash table)
Работа с элементами хеш-таблицы выполняются по следующему алгоритму.
1. Вызов
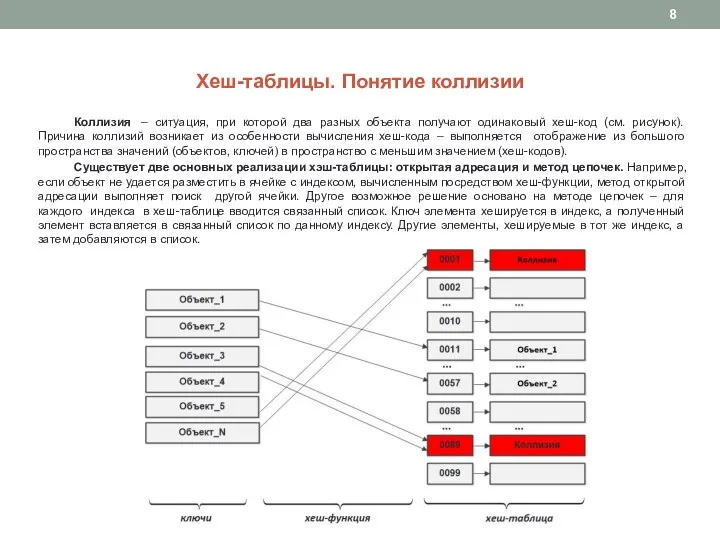
Слайд 8Хеш-таблицы. Понятие коллизии
Коллизия – ситуация, при которой два разных объекта получают одинаковый
Хеш-таблицы. Понятие коллизии
Коллизия – ситуация, при которой два разных объекта получают одинаковый
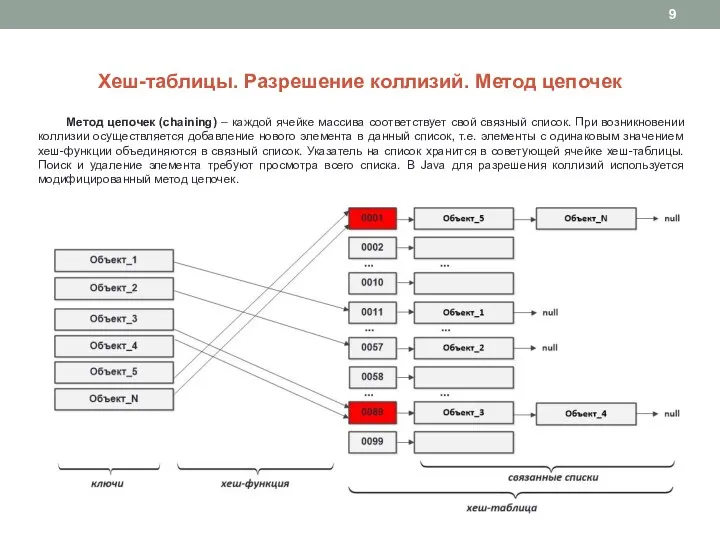
Слайд 9Хеш-таблицы. Разрешение коллизий. Метод цепочек
Метод цепочек (chaining) – каждой ячейке массива
Хеш-таблицы. Разрешение коллизий. Метод цепочек
Метод цепочек (chaining) – каждой ячейке массива
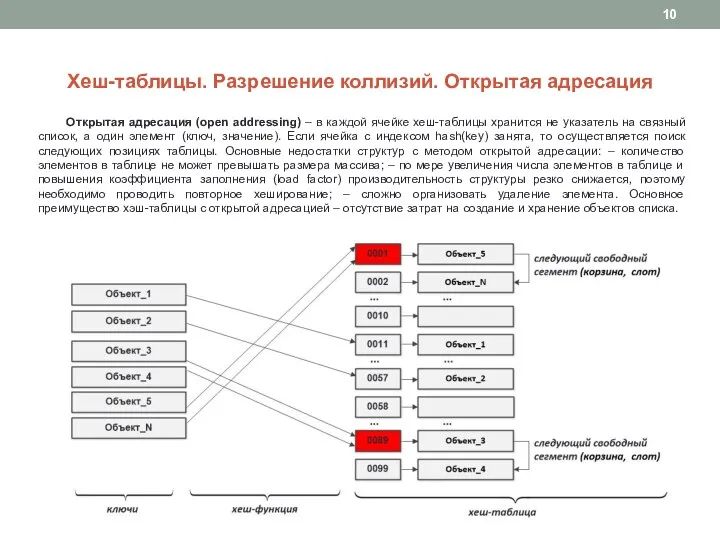
Слайд 10Хеш-таблицы. Разрешение коллизий. Открытая адресация
Открытая адресация (open addressing) – в каждой
Хеш-таблицы. Разрешение коллизий. Открытая адресация
Открытая адресация (open addressing) – в каждой
Слайд 11Хеш-таблицы. Выводы
1. Хеш-таблица создается на основе массива. Главное преимущество хеш-таблиц –
Хеш-таблицы. Выводы
1. Хеш-таблица создается на основе массива. Главное преимущество хеш-таблиц –

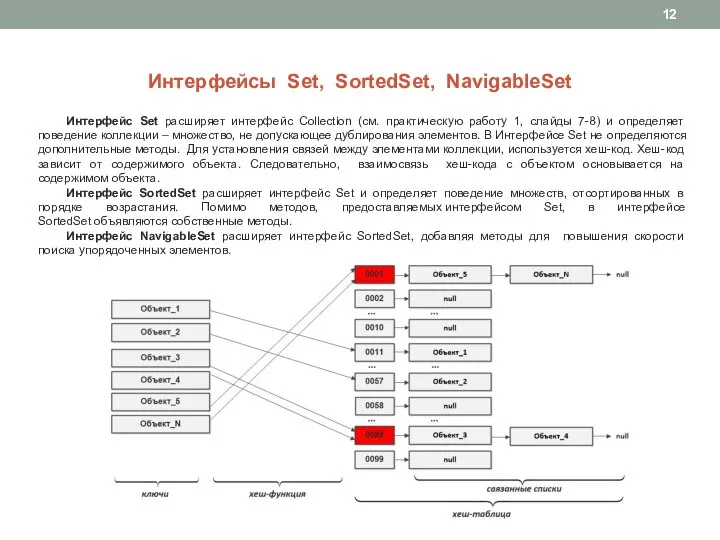
Слайд 12Интерфейсы Set, SortedSet, NavigableSet
Интерфейс Set расширяет интерфейс Collection (см. практическую работу 1,
Интерфейсы Set, SortedSet, NavigableSet
Интерфейс Set расширяет интерфейс Collection (см. практическую работу 1,
Слайд 13Интерфейс Map
Интерфейс Map – является самостоятельным интерфейсом (не расширяет интерфейс Collection, см.
Интерфейс Map
Интерфейс Map – является самостоятельным интерфейсом (не расширяет интерфейс Collection, см.

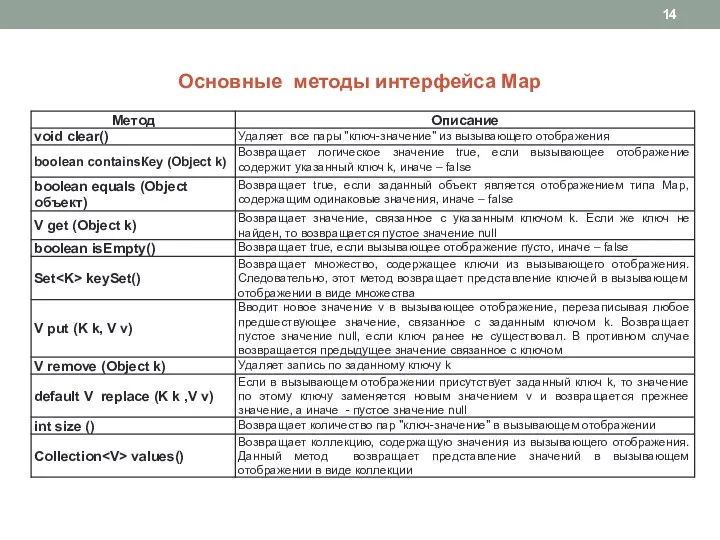
Слайд 14Основные методы интерфейса Map
Основные методы интерфейса Map
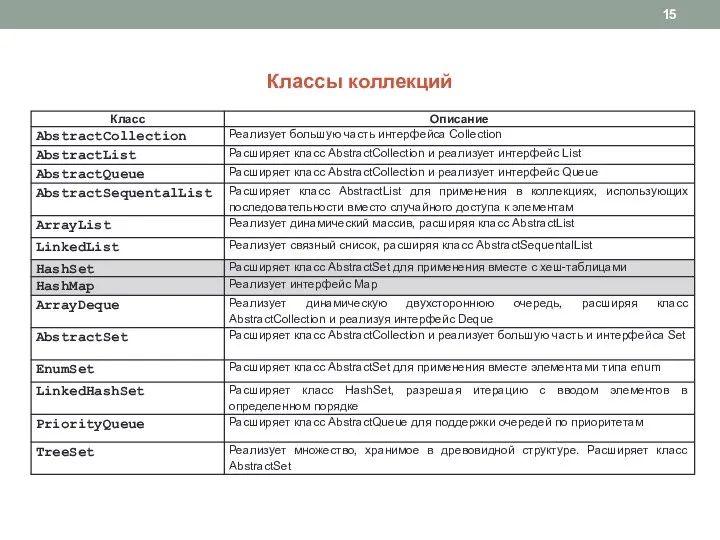
Слайд 15Классы коллекций
Классы коллекций
Слайд 16Реализация интерфейса Set. Класс HashSet
Класс HashSet – реализует интерфейс Set, необходим
Реализация интерфейса Set. Класс HashSet
Класс HashSet – реализует интерфейс Set, необходим

Слайд 17Реализация интерфейса Map. Класс HashMap
Класс HashMap – реализует интерфейс Map, необходим для
Реализация интерфейса Map. Класс HashMap
Класс HashMap – реализует интерфейс Map, необходим для

Слайд 18Применение класса HashSet
1.Создадим множество HashSet, например, cats, содержащее объекты ссылочного типа
Применение класса HashSet
1.Создадим множество HashSet, например, cats, содержащее объекты ссылочного типа

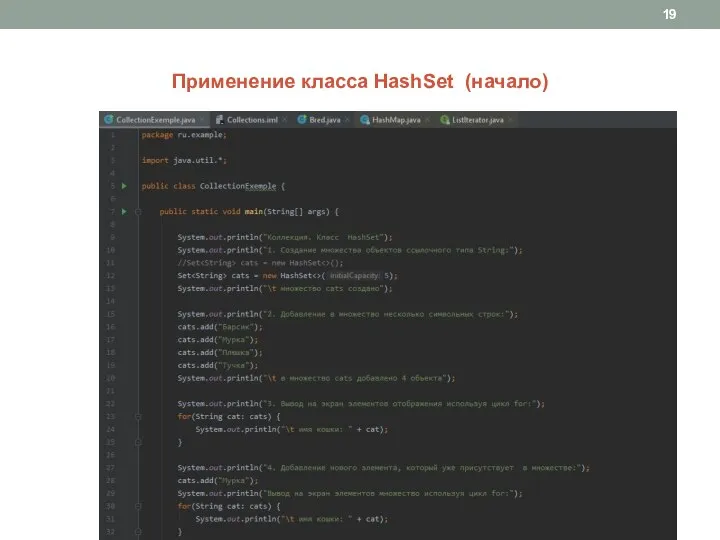
Слайд 19Применение класса HashSet (начало)
Применение класса HashSet (начало)
Слайд 20Применение класса HashSet (окончание)
Применение класса HashSet (окончание)

Слайд 21Применение класса HashMap
1. Создадим отображение HashMap, например, catMap, содержащее объекты ссылочного
Применение класса HashMap
1. Создадим отображение HashMap, например, catMap, содержащее объекты ссылочного

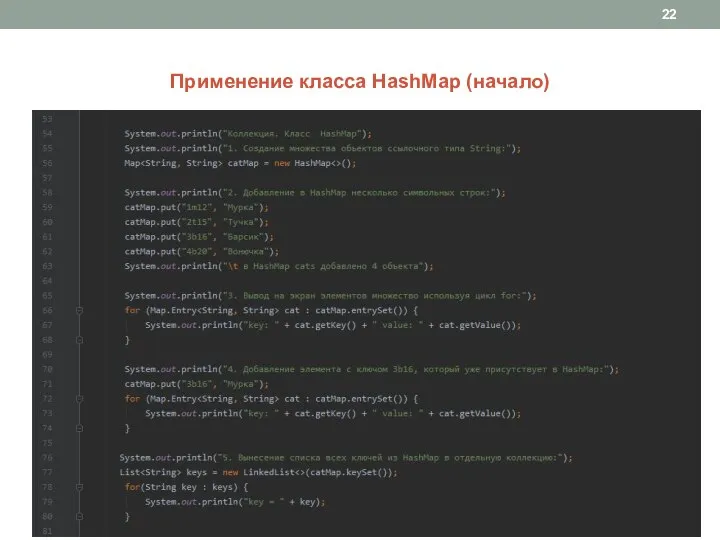
Слайд 22Применение класса HashMap (начало)
Применение класса HashMap (начало)
 Виды СУБД
Виды СУБД Безопасность в интернете для дошкольников
Безопасность в интернете для дошкольников Определи вид данного суждения
Определи вид данного суждения Алгоритм. Разгадайте ребус
Алгоритм. Разгадайте ребус Вред и польза социальных сетей
Вред и польза социальных сетей Инструментальное программное обеспечение
Инструментальное программное обеспечение Разработка мобильных сервисов для велотуристов и сети мини/микро бизнесов
Разработка мобильных сервисов для велотуристов и сети мини/микро бизнесов OCL (объектный язык ограничений)
OCL (объектный язык ограничений) Экспериментальное проектирование и процедура
Экспериментальное проектирование и процедура В программе ART RADE
В программе ART RADE Группа ВК Плечом к плечу. Конкурс
Группа ВК Плечом к плечу. Конкурс 7-0-0 Введение
7-0-0 Введение Презентация на тему Файлы и файловая система (8 класс)
Презентация на тему Файлы и файловая система (8 класс)  Программирование на языке Паскаль (продолжение). Вычисления (случайные числа)
Программирование на языке Паскаль (продолжение). Вычисления (случайные числа) Всемирная паутина. Информация и информационные процессы
Всемирная паутина. Информация и информационные процессы Курс обучения Smart Notebook для начинающих пользователей. Создание упражнения: скрыть-показать
Курс обучения Smart Notebook для начинающих пользователей. Создание упражнения: скрыть-показать Создание таблиц
Создание таблиц Нескучный текст
Нескучный текст Памятка по программам
Памятка по программам Осуществление поиска в готовой базе данных. Задачи с пояснениями решений
Осуществление поиска в готовой базе данных. Задачи с пояснениями решений Элементы математической логики. Тема 2
Элементы математической логики. Тема 2 Стандартные функции ввода-вывода
Стандартные функции ввода-вывода Внедрение и развитие автоматизированного тестирования Siebel CRM
Внедрение и развитие автоматизированного тестирования Siebel CRM Модель Захмана
Модель Захмана Глава 6. Сетевой уровень
Глава 6. Сетевой уровень Брендбук. Независимый периодический интернет-журнал ИС
Брендбук. Независимый периодический интернет-журнал ИС Эволюция языков программирования
Эволюция языков программирования Компьютер как унивесальное устройство для работы с информацией. 7 класс
Компьютер как унивесальное устройство для работы с информацией. 7 класс