- Курс SEO-практик. Управление индексацией сайта. Дубли и служебные страницы

Содержание
- 2. bit.ly/2JKmiS0 Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 3. Задание для самостоятельного выполнения Самостоятельно разобраться с программой Xenu или другой на выбор. http://stalnik.by/ проверить на
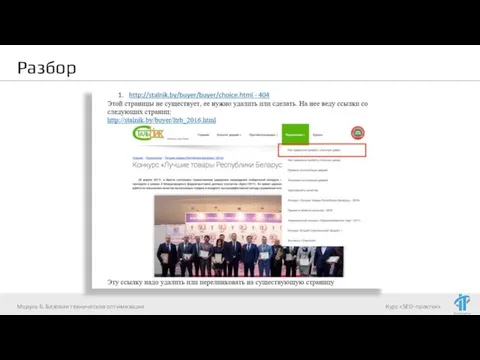
- 4. Разбор Модуль 6. Базовая техническая оптимизация
- 5. Разбор Модуль 6. Базовая техническая оптимизация
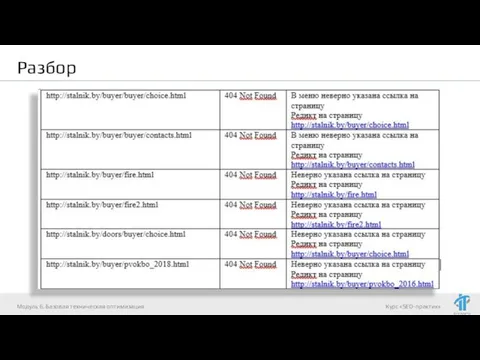
- 6. Разбор Модуль 6. Базовая техническая оптимизация
- 7. Разбор Модуль 6. Базовая техническая оптимизация
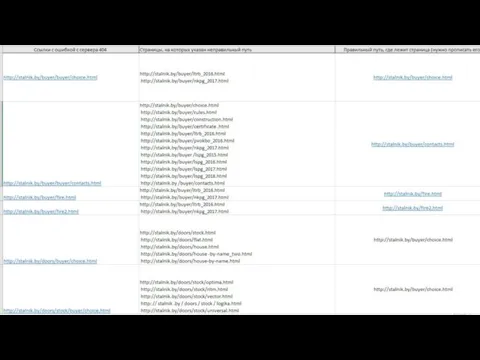
- 8. Разбор На мой взгляд, указанные на листе "404 ошибки" очень похожи на ошибки разработчиков, т.к. они
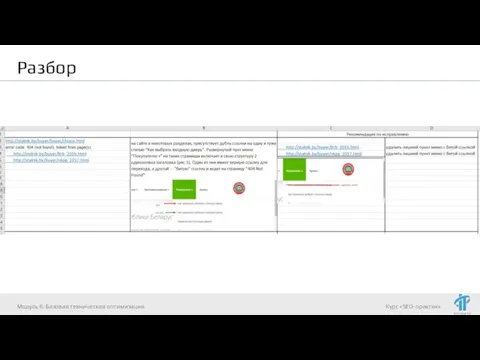
- 9. Разбор Модуль 6. Базовая техническая оптимизация
- 10. Разбор Модуль 6. Базовая техническая оптимизация
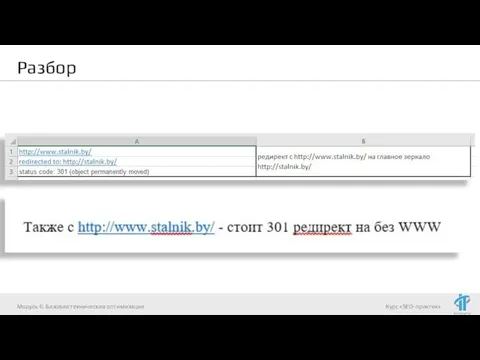
- 11. Разбор Ошибка 301 редиректа решается путем подключения к сайту по протоколу FTP, затем в корневой категории
- 12. Разбор Модуль 6. Базовая техническая оптимизация
- 13. Управление индексацией сайта. Дубли и служебные страницы Курс SEO-практик Модуль 7
- 14. Sitemap.xml для чего необходим и как создать Sitemap.xml Модуль 7. Управление индексацией сайта. Дубли и служебные
- 15. Sitemap.xml для чего необходим и как создать Sitemap.xml – карта сайта в формате XML, которая содержит
- 16. Sitemap.xml для чего необходим и как создать Нужен ли файл Sitemap.xml? Если страницы файла корректно связаны
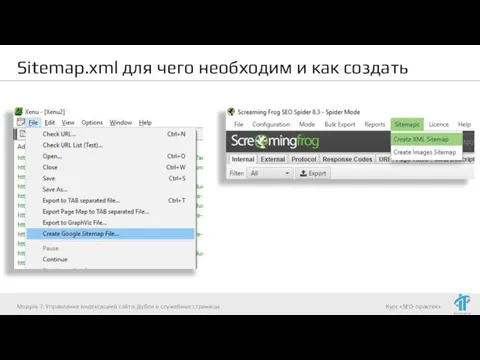
- 17. Sitemap.xml для чего необходим и как создать Как создать Sitemap.xml Генерация средствами CMS Генерация сторонними сервисами\программами
- 18. Sitemap.xml для чего необходим и как создать Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 19. Sitemap.xml для чего необходим и как создать Синтаксис для Sitemap.xml Яндекс и Google поддерживают стандартный протокол
- 20. Sitemap.xml для чего необходим и как создать Обязательные атрибуты: - определяет стандарт протокола и инкапсулирует этот
- 21. Sitemap.xml для чего необходим и как создать Необязательные атрибуты: - Дата последнего изменения файла. - Вероятная
- 22. Sitemap.xml для чего необходим и как создать Пример sitemap.xml https://www.termebel.by/sitemap.xml (1) Модуль 7. Управление индексацией сайта.
- 23. Sitemap.xml наиболее частые ошибки Основные требования Google и Яндекса: Используйте кодировку UTF-8. Максимальное количество ссылок —
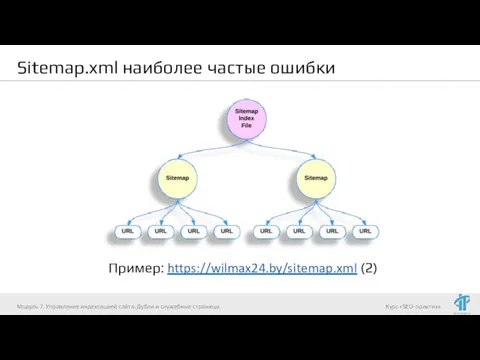
- 24. Sitemap.xml наиболее частые ошибки Пример: https://wilmax24.by/sitemap.xml (2) Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 25. Sitemap.xml наиболее частые ошибки Отличия: Рекомендации Яндекса к файлу: Поддерживает кириллические URL. Рекомендации Google: Поддерживает только
- 26. Sitemap.xml наиболее частые ошибки Как сообщить поисковым системам о Sitemap.xml: Укажите ссылку на файл в robots.txt
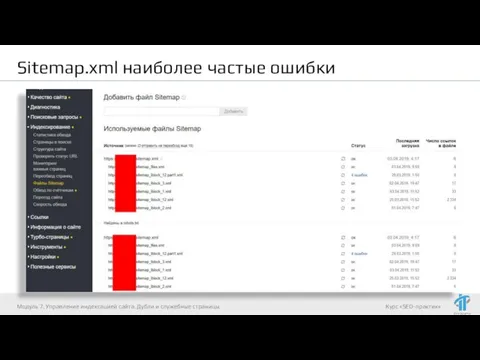
- 27. Sitemap.xml наиболее частые ошибки Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
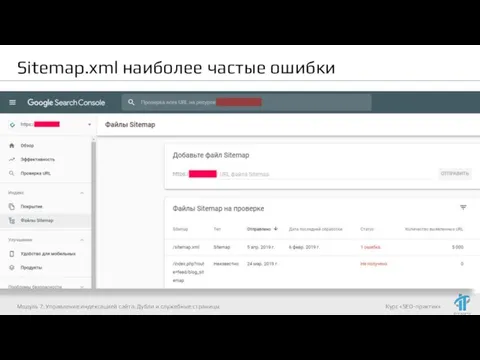
- 28. Sitemap.xml наиболее частые ошибки Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 29. Sitemap.xml наиболее частые ошибки Наиболее частые ошибки: Нет регулярной актуализации Sitemap.xml; Содержит ссылки на 404 и
- 30. Sitemap.xml наиболее частые ошибки Частые заблуждения: Включение URL-адреса в файл Sitemap.xml гарантирует, что он будет проиндексирован;
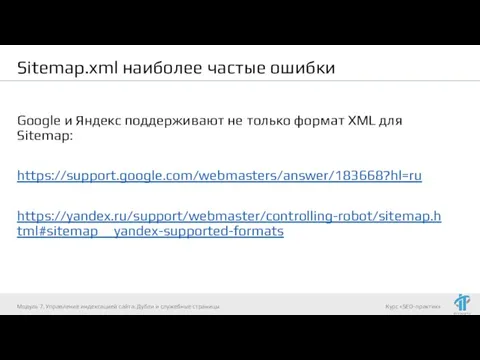
- 31. Sitemap.xml наиболее частые ошибки Google и Яндекс поддерживают не только формат XML для Sitemap: https://support.google.com/webmasters/answer/183668?hl=ru https://yandex.ru/support/webmaster/controlling-robot/sitemap.html#sitemap__yandex-supported-formats
- 32. Sitemap.xml наиболее частые ошибки Проверить корректность Sitemap.xml (синтаксис): Если нет доступа к панелям вебмастеров (например, сайт
- 33. Robots.txt директивы и их использование robots.txt Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 34. Robots.txt директивы и их использование Robots.txt - текстовый файл, который содержит параметры индексирования сайта для роботов
- 35. Robots.txt директивы и их использование Зачем нужен файл robots.txt Например, мы не хотим, чтобы роботы поисковых
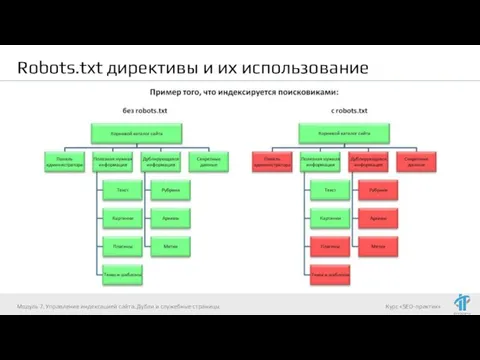
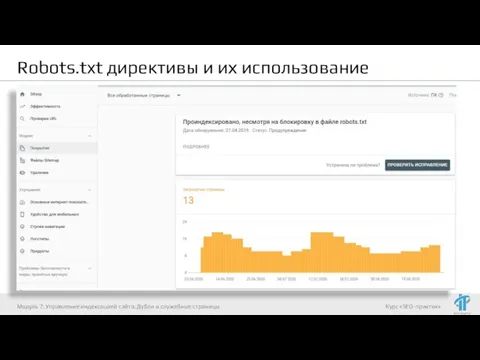
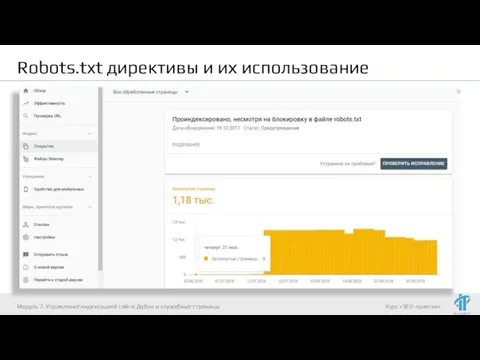
- 36. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 37. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 38. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 39. Robots.txt директивы и их использование Директива robots.txt – это инструкция, которая обрабатывается роботами поисковых систем. Какие
- 40. Robots.txt директивы и их использование User-agent - правило о том, каким роботам необходимо просмотреть инструкции, описанные
- 41. Robots.txt директивы и их использование Disallow: - чтобы запретить доступ робота к сайту, некоторым его разделам
- 42. Robots.txt директивы и их использование Allow: - чтобы разрешить доступ робота к сайту, некоторым его разделам
- 43. Robots.txt директивы и их использование Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине
- 44. Robots.txt директивы и их использование # Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog
- 45. Robots.txt директивы и их использование Директивы Allow и Disallow без параметров User-agent: * Disallow: # то
- 46. Robots.txt директивы и их использование При указании путей директив Allow и Disallow можно использовать спецсимволы *
- 47. Robots.txt директивы и их использование User-agent: * Disallow: /catalog/*.html site.by/catalog/tv/ site.by/catalog/tv/Samsung.html Disallow: /*tv site.by/catalog/Tv/ site.by/catalog/tv/ site.by/catalog/smart-tv/Samsung.html
- 48. Robots.txt директивы и их использование По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается
- 49. Robots.txt директивы и их использование Чтобы отменить * на конце правила, можно использовать спецсимвол $, например:
- 50. Robots.txt директивы и их использование Использование кириллицы запрещено Для указания имен доменов используйте Punycode https://ru.wikipedia.org/wiki/Punycode #Неверно:
- 51. Robots.txt директивы и их использование Директива Sitemap User-agent: * Sitemap: http://www.example.com/sitemap.xml Важно указывать полный путь с
- 52. Robots.txt директивы и их использование Директива Host: ранее использовалась для указания главного зеркала сайта, учитывалась только
- 53. Robots.txt директивы и их использование Директива Crawl-delay - Если сервер сильно нагружен и не успевает отрабатывать
- 54. Robots.txt директивы и их использование Директива Clean-param - Если адреса страниц сайта содержат динамические параметры, которые
- 55. Robots.txt директивы и их использование https://webmaster.yandex.ru/tools/robotstxt/ (4)- проверка robots.txt Модуль 7. Управление индексацией сайта. Дубли и
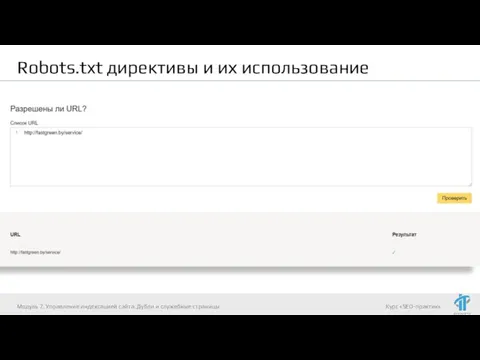
- 56. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 57. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 58. Robots.txt директивы и их использование Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 59. Robots.txt директивы и их использование Практическое задание Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 60. Robots.txt директивы и их использование Для сайта https://linenmill.by (5) доработать текущий robots.txt с учетом необходимости закрытия
- 61. Robots.txt директивы и их использование Добавили в блок «User-agent: Yandex» следующие директивы: Disallow: /kontraktnyj-zakaz/$ Disallow: /author/vova/$
- 62. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 63. Базовые условия индексации документа, проверка индексации Страница должна отдавать код ответа сервера 200 ОК; Страница не
- 64. Базовые условия индексации документа, проверка индексации Проверка индексации: Информация в панелях вебсмастеров Яндекса и Google Запросы
- 65. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 66. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 67. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 68. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 69. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 70. Базовые условия индексации документа, проверка индексации Ускоряем индексацию: Индексирование -> Переобход страниц (в Яндекс.Вебмастер) Сканирование ->
- 71. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 72. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 73. Базовые условия индексации документа, проверка индексации Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
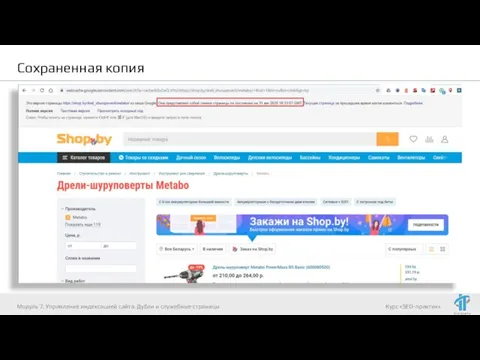
- 74. Сохраненная копия Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 75. Сохраненная копия Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 76. Полные и частичные дубли: методы борьбы Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 77. Полные и частичные дубли: методы борьбы Дубли -это отдельные страницы сайта, контент которых полностью или частично
- 78. Полные и частичные дубли: методы борьбы Откуда могут появляться дубли: Автоматическая генерация дублирующих страниц движком системой
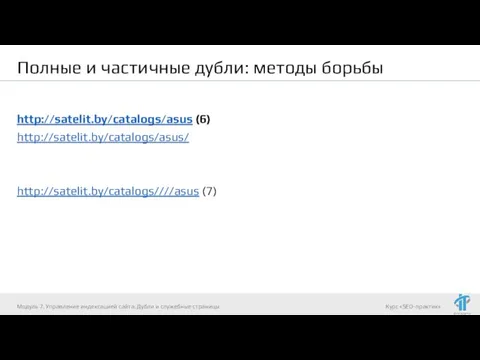
- 79. Полные и частичные дубли: методы борьбы Полные дубли - это страницы с идентичным содержимым, доступны по
- 80. Полные и частичные дубли: методы борьбы http://satelit.by/catalogs/asus (6) http://satelit.by/catalogs/asus/ http://satelit.by/catalogs////asus (7) Модуль 7. Управление индексацией сайта.
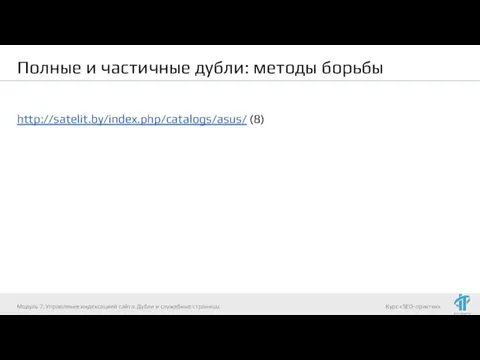
- 81. Полные и частичные дубли: методы борьбы URL-адреса страниц с index.php, index.html, default.asp, default.aspx, home, home.php, main.php
- 82. Полные и частичные дубли: методы борьбы http://satelit.by/index.php/catalogs/asus/ (8) Модуль 7. Управление индексацией сайта. Дубли и служебные
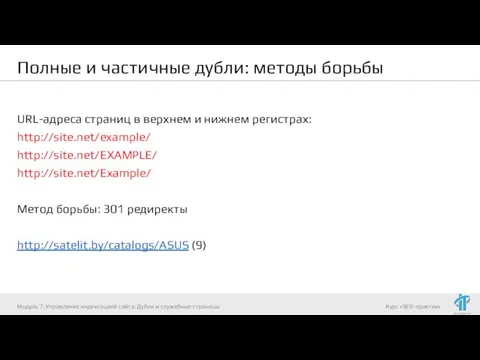
- 83. Полные и частичные дубли: методы борьбы URL-адреса страниц в верхнем и нижнем регистрах: http://site.net/example/ http://site.net/EXAMPLE/ http://site.net/Example/
- 84. Полные и частичные дубли: методы борьбы Изменения в иерархической структуре URL. Например, если товар доступен по
- 85. Полные и частичные дубли: методы борьбы https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/series-premium/1085-premium-inverter-msz-ln60vgw/ (10) https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/1085-premium-inverter-msz-ln60vgw/ Модуль 7. Управление индексацией сайта. Дубли и
- 86. Полные и частичные дубли: методы борьбы Дополнительные параметры и метки в URL. Наличие меток utm, gclid,
- 87. Полные и частичные дубли: методы борьбы Первая страница пагинации каталога товаров интернет-магазина или доски объявлений, блога.
- 88. Полные и частичные дубли: методы борьбы Неправильные настройки 404 ошибки http://site.net/catalog http://site.net/catalog/asdasdadkjnwefhblsdkfmkldf Метод борьбы: ТЗ программистам
- 89. Полные и частичные дубли: методы борьбы Частичные дубли - в частично дублирующихся страницах контент одинаковый, но
- 90. Полные и частичные дубли: методы борьбы Дубли на страницах для печати или для скачивания, основные данные
- 91. Полные и частичные дубли: методы борьбы Страницы пагинации (кроме первой) ТЗ программистам: Уникализация title, description по
- 92. Полные и частичные дубли: методы борьбы Часто решение проблемы кроется в настройке самого движка, а потому
- 93. Служебные (мусорные) страницы Служебные (мусорные) страницы: Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 94. Служебные\мусорные страницы Служебные страницы: Корзина Регистрация Личный кабинет Вход в администраторскую часть Результаты поиска по сайту
- 95. Служебные (мусорные) страницы Что с ними делаем? Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
- 96. Задание для самостоятельного выполнения Проанализируйте сайт http://it-m.by найдите дубли, определите их тип – полные или частичные;
- 98. Скачать презентацию

Слайд 3Задание для самостоятельного выполнения
Самостоятельно разобраться с программой Xenu или другой на выбор.
http://stalnik.by/
проверить
Задание для самостоятельного выполнения
Самостоятельно разобраться с программой Xenu или другой на выбор.
http://stalnik.by/
проверить

Слайд 4Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация

Слайд 5Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация
Слайд 6Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация
Слайд 7Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация
Слайд 8Разбор
На мой взгляд, указанные на листе "404 ошибки" очень похожи на ошибки
Разбор
На мой взгляд, указанные на листе "404 ошибки" очень похожи на ошибки

Слайд 9Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация
Слайд 10Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация

Слайд 11Разбор
Ошибка 301 редиректа решается путем подключения к сайту по протоколу FTP, затем
Разбор
Ошибка 301 редиректа решается путем подключения к сайту по протоколу FTP, затем

Слайд 12Разбор
Модуль 6. Базовая техническая оптимизация
Разбор
Модуль 6. Базовая техническая оптимизация
Слайд 13Управление индексацией сайта.
Дубли и служебные страницы
Курс SEO-практик
Модуль 7
Управление индексацией сайта.
Дубли и служебные страницы
Курс SEO-практик
Модуль 7

Слайд 14Sitemap.xml для чего необходим и как создать
Sitemap.xml
Модуль 7. Управление индексацией сайта. Дубли
Sitemap.xml для чего необходим и как создать
Sitemap.xml
Модуль 7. Управление индексацией сайта. Дубли
Слайд 15Sitemap.xml для чего необходим и как создать
Sitemap.xml
– карта сайта в формате
Sitemap.xml для чего необходим и как создать
Sitemap.xml
– карта сайта в формате

Слайд 16Sitemap.xml для чего необходим и как создать
Нужен ли файл Sitemap.xml?
Если страницы файла
Sitemap.xml для чего необходим и как создать
Нужен ли файл Sitemap.xml?
Если страницы файла

Слайд 17Sitemap.xml для чего необходим и как создать
Как создать Sitemap.xml
Генерация средствами CMS
Генерация сторонними
Sitemap.xml для чего необходим и как создать
Как создать Sitemap.xml
Генерация средствами CMS
Генерация сторонними

Слайд 18Sitemap.xml для чего необходим и как создать
Модуль 7. Управление индексацией сайта. Дубли
Sitemap.xml для чего необходим и как создать
Модуль 7. Управление индексацией сайта. Дубли
Слайд 19Sitemap.xml для чего необходим и как создать
Синтаксис для Sitemap.xml
Яндекс и Google поддерживают
Sitemap.xml для чего необходим и как создать
Синтаксис для Sitemap.xml
Яндекс и Google поддерживают

Слайд 20Sitemap.xml для чего необходим и как создать
Обязательные атрибуты:
- определяет стандарт протокола
Sitemap.xml для чего необходим и как создать
Обязательные атрибуты:

Слайд 21Sitemap.xml для чего необходим и как создать
Необязательные атрибуты:
- Дата последнего изменения
Sitemap.xml для чего необходим и как создать
Необязательные атрибуты:

Слайд 22Sitemap.xml для чего необходим и как создать
Пример sitemap.xml
https://www.termebel.by/sitemap.xml (1)
Модуль 7. Управление индексацией
Sitemap.xml для чего необходим и как создать
Пример sitemap.xml
https://www.termebel.by/sitemap.xml (1)
Модуль 7. Управление индексацией

Слайд 23Sitemap.xml наиболее частые ошибки
Основные требования Google и Яндекса:
Используйте кодировку UTF-8.
Максимальное количество ссылок —
Sitemap.xml наиболее частые ошибки
Основные требования Google и Яндекса:
Используйте кодировку UTF-8.
Максимальное количество ссылок —
Слайд 24Sitemap.xml наиболее частые ошибки
Пример: https://wilmax24.by/sitemap.xml (2)
Модуль 7. Управление индексацией сайта. Дубли
Sitemap.xml наиболее частые ошибки
Пример: https://wilmax24.by/sitemap.xml (2)
Модуль 7. Управление индексацией сайта. Дубли
Слайд 25Sitemap.xml наиболее частые ошибки
Отличия:
Рекомендации Яндекса к файлу:
Поддерживает кириллические URL.
Рекомендации Google:
Поддерживает только цифры
Sitemap.xml наиболее частые ошибки
Отличия:
Рекомендации Яндекса к файлу:
Поддерживает кириллические URL.
Рекомендации Google:
Поддерживает только цифры

Слайд 26Sitemap.xml наиболее частые ошибки
Как сообщить поисковым системам о Sitemap.xml:
Укажите ссылку на файл
Sitemap.xml наиболее частые ошибки
Как сообщить поисковым системам о Sitemap.xml:
Укажите ссылку на файл

Слайд 27Sitemap.xml наиболее частые ошибки
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Sitemap.xml наиболее частые ошибки
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Слайд 28Sitemap.xml наиболее частые ошибки
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Sitemap.xml наиболее частые ошибки
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Слайд 29Sitemap.xml наиболее частые ошибки
Наиболее частые ошибки:
Нет регулярной актуализации Sitemap.xml;
Содержит ссылки на 404
Sitemap.xml наиболее частые ошибки
Наиболее частые ошибки:
Нет регулярной актуализации Sitemap.xml;
Содержит ссылки на 404

Слайд 30Sitemap.xml наиболее частые ошибки
Частые заблуждения:
Включение URL-адреса в файл Sitemap.xml гарантирует, что он
Sitemap.xml наиболее частые ошибки
Частые заблуждения:
Включение URL-адреса в файл Sitemap.xml гарантирует, что он

Слайд 31Sitemap.xml наиболее частые ошибки
Google и Яндекс поддерживают не только формат XML для
Sitemap.xml наиболее частые ошибки
Google и Яндекс поддерживают не только формат XML для
Слайд 32Sitemap.xml наиболее частые ошибки
Проверить корректность Sitemap.xml (синтаксис):
Если нет доступа к панелям вебмастеров
Sitemap.xml наиболее частые ошибки
Проверить корректность Sitemap.xml (синтаксис):
Если нет доступа к панелям вебмастеров

Слайд 33Robots.txt директивы и их использование
robots.txt
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
robots.txt
Модуль 7. Управление индексацией сайта. Дубли и служебные

Слайд 34Robots.txt директивы и их использование
Robots.txt
- текстовый файл, который содержит параметры индексирования сайта
Robots.txt директивы и их использование
Robots.txt
- текстовый файл, который содержит параметры индексирования сайта

Слайд 35Robots.txt директивы и их использование
Зачем нужен файл robots.txt
Например, мы не хотим, чтобы
Robots.txt директивы и их использование
Зачем нужен файл robots.txt
Например, мы не хотим, чтобы

Слайд 36Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Слайд 37Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Слайд 38Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Слайд 39Robots.txt директивы и их использование
Директива robots.txt
– это инструкция, которая обрабатывается роботами
Robots.txt директивы и их использование
Директива robots.txt
– это инструкция, которая обрабатывается роботами

Слайд 40Robots.txt директивы и их использование
User-agent
- правило о том, каким роботам необходимо просмотреть
Robots.txt директивы и их использование
User-agent
- правило о том, каким роботам необходимо просмотреть

Слайд 41Robots.txt директивы и их использование
Disallow: - чтобы запретить доступ робота к сайту,
Robots.txt директивы и их использование
Disallow: - чтобы запретить доступ робота к сайту,

Слайд 42Robots.txt директивы и их использование
Allow: - чтобы разрешить доступ робота к сайту,
Robots.txt директивы и их использование
Allow: - чтобы разрешить доступ робота к сайту,

Слайд 43Robots.txt директивы и их использование
Директивы Allow и Disallow из соответствующего User-agent блока
Robots.txt директивы и их использование
Директивы Allow и Disallow из соответствующего User-agent блока

Слайд 44Robots.txt директивы и их использование
# Исходный robots.txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный
Robots.txt директивы и их использование
# Исходный robots.txt:
User-agent: Yandex
Allow: /
Allow: /catalog/auto
Disallow: /catalog
# Сортированный

Слайд 45Robots.txt директивы и их использование
Директивы Allow и Disallow без параметров
User-agent: *
Disallow: #
Robots.txt директивы и их использование
Директивы Allow и Disallow без параметров
User-agent: *
Disallow: #

Слайд 46Robots.txt директивы и их использование
При указании путей директив Allow и Disallow можно
Robots.txt директивы и их использование
При указании путей директив Allow и Disallow можно

Слайд 47Robots.txt директивы и их использование
User-agent: *
Disallow: /catalog/*.html
site.by/catalog/tv/
site.by/catalog/tv/Samsung.html
Disallow: /*tv
site.by/catalog/Tv/
site.by/catalog/tv/
site.by/catalog/smart-tv/Samsung.html
Модуль 7. Управление индексацией сайта.
Robots.txt директивы и их использование
User-agent: *
Disallow: /catalog/*.html
site.by/catalog/tv/
site.by/catalog/tv/Samsung.html
Disallow: /*tv
site.by/catalog/Tv/
site.by/catalog/tv/
site.by/catalog/smart-tv/Samsung.html
Модуль 7. Управление индексацией сайта.

Слайд 48Robots.txt директивы и их использование
По умолчанию к концу каждого правила, описанного в
Robots.txt директивы и их использование
По умолчанию к концу каждого правила, описанного в

Слайд 49Robots.txt директивы и их использование
Чтобы отменить * на конце правила, можно использовать
Robots.txt директивы и их использование
Чтобы отменить * на конце правила, можно использовать

Слайд 50Robots.txt директивы и их использование
Использование кириллицы запрещено
Для указания имен доменов используйте Punycode https://ru.wikipedia.org/wiki/Punycode
#Неверно:
User-agent:
Robots.txt директивы и их использование
Использование кириллицы запрещено
Для указания имен доменов используйте Punycode https://ru.wikipedia.org/wiki/Punycode
#Неверно:
User-agent:

Слайд 51Robots.txt директивы и их использование
Директива Sitemap
User-agent: *
Sitemap: http://www.example.com/sitemap.xml
Важно указывать полный путь с
Robots.txt директивы и их использование
Директива Sitemap
User-agent: *
Sitemap: http://www.example.com/sitemap.xml
Важно указывать полный путь с

Слайд 52Robots.txt директивы и их использование
Директива Host: ранее использовалась для указания главного зеркала
Robots.txt директивы и их использование
Директива Host: ранее использовалась для указания главного зеркала

Слайд 53Robots.txt директивы и их использование
Директива Crawl-delay - Если сервер сильно нагружен и
Robots.txt директивы и их использование
Директива Crawl-delay - Если сервер сильно нагружен и

Слайд 54Robots.txt директивы и их использование
Директива Clean-param
- Если адреса страниц сайта содержат
Robots.txt директивы и их использование
Директива Clean-param
- Если адреса страниц сайта содержат

Слайд 55Robots.txt директивы и их использование
https://webmaster.yandex.ru/tools/robotstxt/ (4)- проверка robots.txt
Модуль 7. Управление индексацией сайта.
Robots.txt директивы и их использование
https://webmaster.yandex.ru/tools/robotstxt/ (4)- проверка robots.txt
Модуль 7. Управление индексацией сайта.

Слайд 56Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные

Слайд 57Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные

Слайд 58Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Robots.txt директивы и их использование
Модуль 7. Управление индексацией сайта. Дубли и служебные
Слайд 59Robots.txt директивы и их использование
Практическое задание
Модуль 7. Управление индексацией сайта. Дубли и
Robots.txt директивы и их использование
Практическое задание
Модуль 7. Управление индексацией сайта. Дубли и

Слайд 60Robots.txt директивы и их использование
Для сайта https://linenmill.by (5) доработать текущий robots.txt с
Robots.txt директивы и их использование
Для сайта https://linenmill.by (5) доработать текущий robots.txt с

Слайд 61Robots.txt директивы и их использование
Добавили в блок «User-agent: Yandex» следующие директивы:
Disallow: /kontraktnyj-zakaz/$
Disallow:
Robots.txt директивы и их использование
Добавили в блок «User-agent: Yandex» следующие директивы:
Disallow: /kontraktnyj-zakaz/$
Disallow:

Слайд 62Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и

Слайд 63Базовые условия индексации документа, проверка индексации
Страница должна отдавать код ответа сервера 200
Базовые условия индексации документа, проверка индексации
Страница должна отдавать код ответа сервера 200

Слайд 64Базовые условия индексации документа, проверка индексации
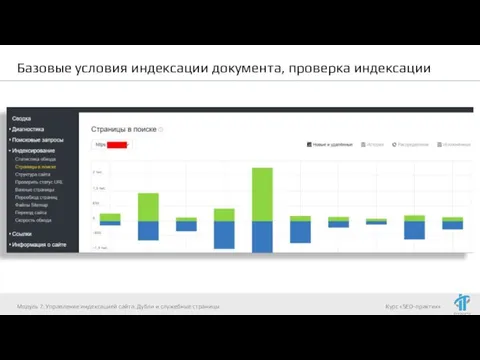
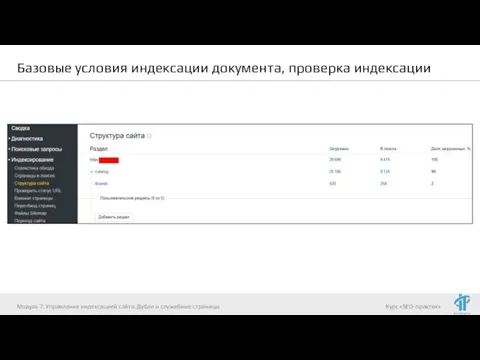
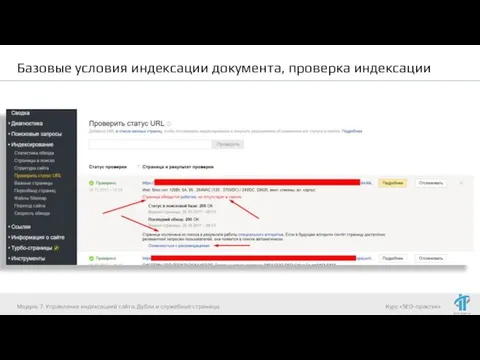
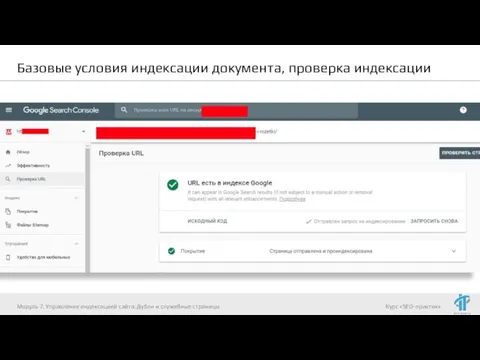
Проверка индексации:
Информация в панелях вебсмастеров Яндекса и
Базовые условия индексации документа, проверка индексации
Проверка индексации:
Информация в панелях вебсмастеров Яндекса и

Слайд 65Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 66Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 67Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 68Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 69Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и

Слайд 70Базовые условия индексации документа, проверка индексации
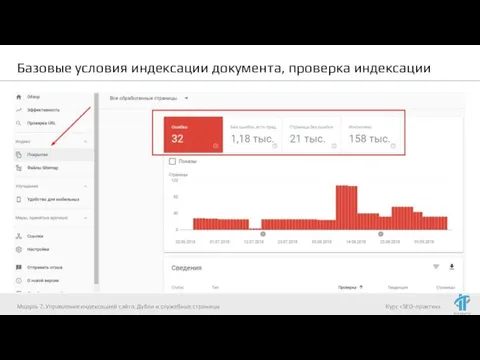
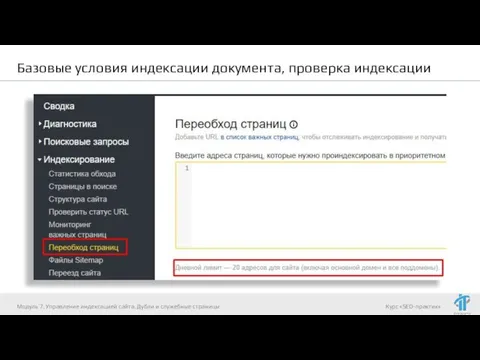
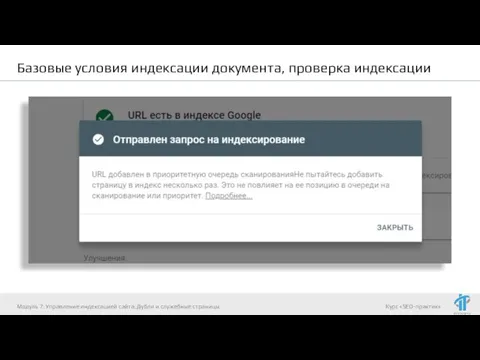
Ускоряем индексацию:
Индексирование -> Переобход страниц (в Яндекс.Вебмастер)
Сканирование
Базовые условия индексации документа, проверка индексации
Ускоряем индексацию:
Индексирование -> Переобход страниц (в Яндекс.Вебмастер)
Сканирование

Слайд 71Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 72Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Слайд 73Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
Базовые условия индексации документа, проверка индексации
Модуль 7. Управление индексацией сайта. Дубли и
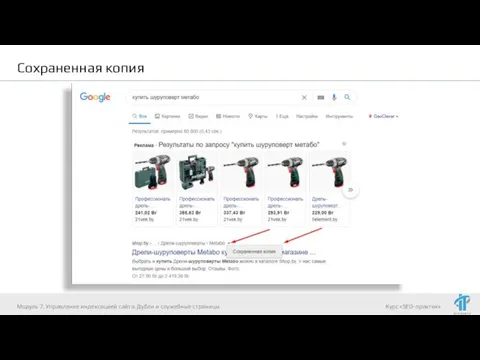
Слайд 74Сохраненная копия
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Сохраненная копия
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Слайд 75Сохраненная копия
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Сохраненная копия
Модуль 7. Управление индексацией сайта. Дубли и служебные страницы
Слайд 76Полные и частичные дубли: методы борьбы
Модуль 7. Управление индексацией сайта. Дубли и
Полные и частичные дубли: методы борьбы
Модуль 7. Управление индексацией сайта. Дубли и

Слайд 77Полные и частичные дубли: методы борьбы
Дубли
-это отдельные страницы сайта, контент которых полностью
Полные и частичные дубли: методы борьбы
Дубли
-это отдельные страницы сайта, контент которых полностью

Слайд 78Полные и частичные дубли: методы борьбы
Откуда могут появляться дубли:
Автоматическая генерация дублирующих страниц
Полные и частичные дубли: методы борьбы
Откуда могут появляться дубли:
Автоматическая генерация дублирующих страниц

Слайд 79Полные и частичные дубли: методы борьбы
Полные дубли - это страницы с идентичным
Полные и частичные дубли: методы борьбы
Полные дубли - это страницы с идентичным

Слайд 80Полные и частичные дубли: методы борьбы
http://satelit.by/catalogs/asus (6)
http://satelit.by/catalogs/asus/
http://satelit.by/catalogs////asus (7)
Модуль 7. Управление индексацией
Полные и частичные дубли: методы борьбы
http://satelit.by/catalogs/asus (6)
http://satelit.by/catalogs/asus/
http://satelit.by/catalogs////asus (7)
Модуль 7. Управление индексацией
Слайд 81Полные и частичные дубли: методы борьбы
URL-адреса страниц с index.php, index.html, default.asp, default.aspx,
Полные и частичные дубли: методы борьбы
URL-адреса страниц с index.php, index.html, default.asp, default.aspx,

Слайд 82Полные и частичные дубли: методы борьбы
http://satelit.by/index.php/catalogs/asus/ (8)
Модуль 7. Управление индексацией сайта. Дубли
Полные и частичные дубли: методы борьбы
http://satelit.by/index.php/catalogs/asus/ (8)
Модуль 7. Управление индексацией сайта. Дубли
Слайд 83Полные и частичные дубли: методы борьбы
URL-адреса страниц в верхнем и нижнем регистрах:
http://site.net/example/
http://site.net/EXAMPLE/
http://site.net/Example/
Метод
Полные и частичные дубли: методы борьбы
URL-адреса страниц в верхнем и нижнем регистрах:
http://site.net/example/
http://site.net/EXAMPLE/
http://site.net/Example/
Метод
Слайд 84Полные и частичные дубли: методы борьбы
Изменения в иерархической структуре URL. Например, если
Полные и частичные дубли: методы борьбы
Изменения в иерархической структуре URL. Например, если

Слайд 85Полные и частичные дубли: методы борьбы
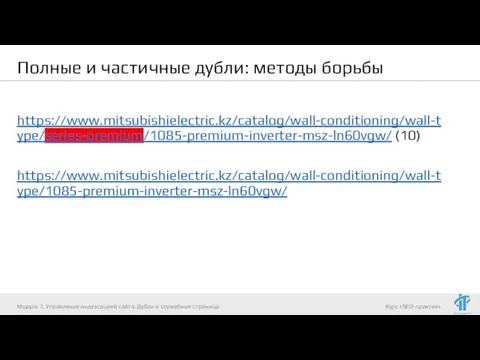
https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/series-premium/1085-premium-inverter-msz-ln60vgw/ (10)
https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/1085-premium-inverter-msz-ln60vgw/
Модуль 7. Управление индексацией сайта.
Полные и частичные дубли: методы борьбы
https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/series-premium/1085-premium-inverter-msz-ln60vgw/ (10)
https://www.mitsubishielectric.kz/catalog/wall-conditioning/wall-type/1085-premium-inverter-msz-ln60vgw/
Модуль 7. Управление индексацией сайта.
Слайд 86Полные и частичные дубли: методы борьбы
Дополнительные параметры и метки в URL.
Наличие меток
Полные и частичные дубли: методы борьбы
Дополнительные параметры и метки в URL.
Наличие меток

Слайд 87Полные и частичные дубли: методы борьбы
Первая страница пагинации каталога товаров интернет-магазина или
Полные и частичные дубли: методы борьбы
Первая страница пагинации каталога товаров интернет-магазина или

Слайд 88Полные и частичные дубли: методы борьбы
Неправильные настройки 404 ошибки
http://site.net/catalog
http://site.net/catalog/asdasdadkjnwefhblsdkfmkldf
Метод борьбы: ТЗ программистам
Полные и частичные дубли: методы борьбы
Неправильные настройки 404 ошибки
http://site.net/catalog
http://site.net/catalog/asdasdadkjnwefhblsdkfmkldf
Метод борьбы: ТЗ программистам

Слайд 89Полные и частичные дубли: методы борьбы
Частичные дубли - в частично дублирующихся страницах
Полные и частичные дубли: методы борьбы
Частичные дубли - в частично дублирующихся страницах

Слайд 90Полные и частичные дубли: методы борьбы
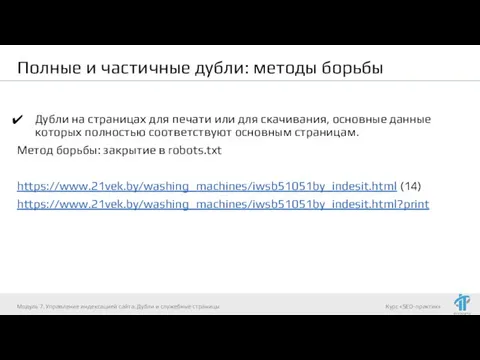
Дубли на страницах для печати или для
Полные и частичные дубли: методы борьбы
Дубли на страницах для печати или для
Слайд 91Полные и частичные дубли: методы борьбы
Страницы пагинации (кроме первой)
ТЗ программистам: Уникализация title,
Полные и частичные дубли: методы борьбы
Страницы пагинации (кроме первой)
ТЗ программистам: Уникализация title,

Слайд 92Полные и частичные дубли: методы борьбы
Часто решение проблемы кроется в настройке самого
Полные и частичные дубли: методы борьбы
Часто решение проблемы кроется в настройке самого

Слайд 93Служебные (мусорные) страницы
Служебные (мусорные) страницы:
Модуль 7. Управление индексацией сайта. Дубли и служебные
Служебные (мусорные) страницы
Служебные (мусорные) страницы:
Модуль 7. Управление индексацией сайта. Дубли и служебные

Слайд 94Служебные\мусорные страницы
Служебные страницы:
Корзина
Регистрация
Личный кабинет
Вход в администраторскую часть
Результаты поиска по сайту
Технические страницы
Тестовые страницы
Служебные\мусорные страницы
Служебные страницы:
Корзина
Регистрация
Личный кабинет
Вход в администраторскую часть
Результаты поиска по сайту
Технические страницы
Тестовые страницы

Слайд 95Служебные (мусорные) страницы
Что с ними делаем?
Модуль 7. Управление индексацией сайта. Дубли и
Служебные (мусорные) страницы
Что с ними делаем?
Модуль 7. Управление индексацией сайта. Дубли и

Слайд 96Задание для самостоятельного выполнения
Проанализируйте сайт http://it-m.by
найдите дубли, определите их тип – полные
Задание для самостоятельного выполнения
Проанализируйте сайт http://it-m.by
найдите дубли, определите их тип – полные

 Марафон “5 дней - 5 навыков”. Востребованные навыки в удаленной профессии
Марафон “5 дней - 5 навыков”. Востребованные навыки в удаленной профессии Опыт взаимодействия с Партнерами в области BIM. Лекция 2
Опыт взаимодействия с Партнерами в области BIM. Лекция 2 Отчет по прочитанной книге Эриха Шпикмана О шрифте
Отчет по прочитанной книге Эриха Шпикмана О шрифте Презентация на тему Перевод чисел из одной системы счисления в другую
Презентация на тему Перевод чисел из одной системы счисления в другую  Официальная группа администрации ЛГО
Официальная группа администрации ЛГО Анализ социальных групп. Занятие 2. Изучение структуры сообщества, авторов сообщений в социальной сети ВКонтакте
Анализ социальных групп. Занятие 2. Изучение структуры сообщества, авторов сообщений в социальной сети ВКонтакте Збереження персональних даних
Збереження персональних даних Я лисенок Вилли
Я лисенок Вилли Алгоритмическая конструкция ветвление
Алгоритмическая конструкция ветвление Multisample Anti-Aliasing (MSAA)
Multisample Anti-Aliasing (MSAA) Модульное проектирование программных средств
Модульное проектирование программных средств История термина алгоритм
История термина алгоритм Системные прерывания
Системные прерывания Сравнение сетевых ОС
Сравнение сетевых ОС Как заполнить Google форму?
Как заполнить Google форму? Возможности внедрения 3D проектирования
Возможности внедрения 3D проектирования 70 лет Победы. Основные цели информационного сопровождения
70 лет Победы. Основные цели информационного сопровождения Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Плюсы и минусы Интернета
Плюсы и минусы Интернета Поколение ЭВМ
Поколение ЭВМ Основные элементы системы управления базами данных Access
Основные элементы системы управления базами данных Access Всероссийская Ассоциация Блогеров
Всероссийская Ассоциация Блогеров Зависимости. Перспективы
Зависимости. Перспективы Программы-архиваторы
Программы-архиваторы Организация сетевого администрирования
Организация сетевого администрирования Функции информационного менеджмента. Формирование технологической среды сферы информатизации предприятия
Функции информационного менеджмента. Формирование технологической среды сферы информатизации предприятия Расчет корреляционных зависимостей в MS Excel
Расчет корреляционных зависимостей в MS Excel Основы программирования на языке Python
Основы программирования на языке Python