- Параллельное программирование в стандарте OpenMP

Содержание
- 2. Содержание Модель программирования в общей памяти Модель FORK-JOIN Стандарт OpenMP Основные понятия и функции OpenMP
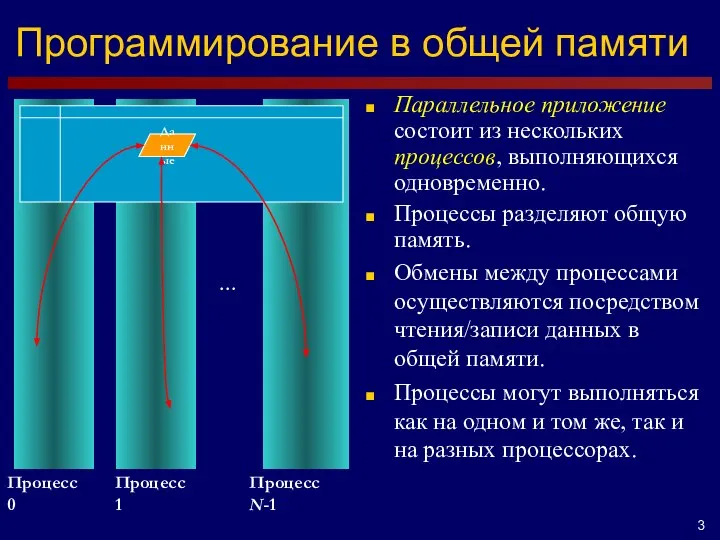
- 3. Программирование в общей памяти … Процесс 0 Процесс 1 Процесс N-1 Данные Параллельное приложение состоит из
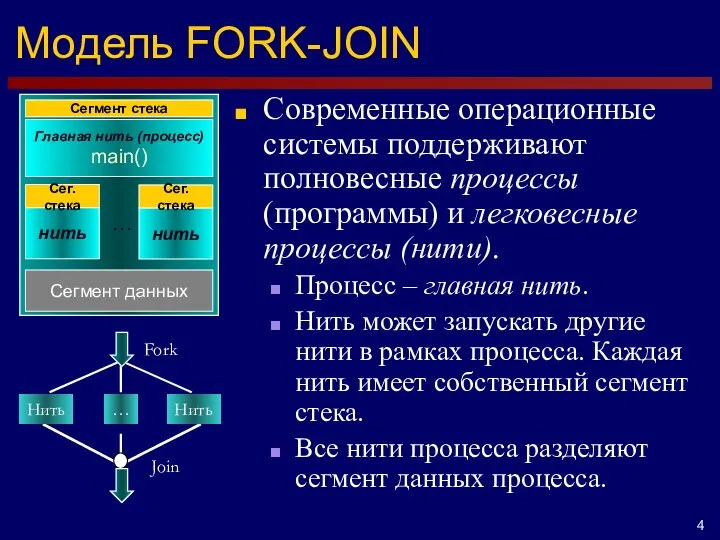
- 4. Модель FORK-JOIN Современные операционные системы поддерживают полновесные процессы (программы) и легковесные процессы (нити). Процесс – главная
- 5. Стандарт OpenMP OpenMP – стандарт, реализующий модели программирования в общей памяти и Fork-Join. Стандарт представляет собой
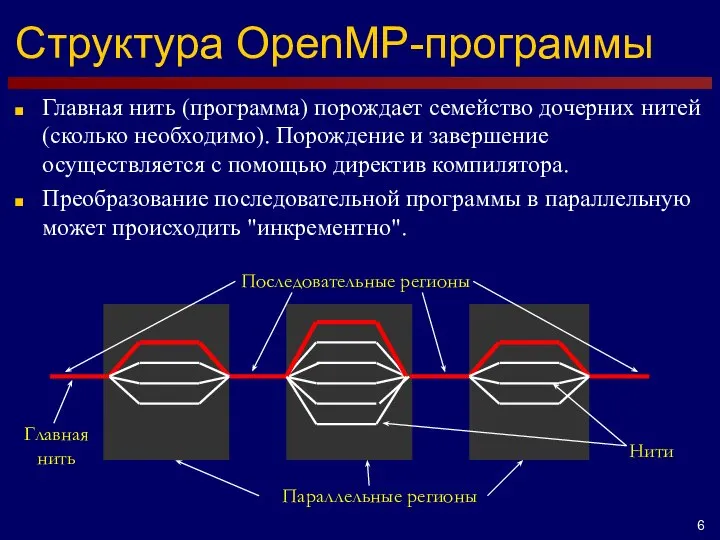
- 6. Структура OpenMP-программы Параллельные регионы Главная нить Главная нить (программа) порождает семейство дочерних нитей (сколько необходимо). Порождение
- 7. Директивы OpenMP Директивы OpenMP – директивы C/C++ компилятора #pragma. Для использования директив необходимо установить соответствующие параметры
- 8. Функции библиотеки OpenMP Назначение функций библиотеки: контроль и просмотр параметров OpenMP-программы omp_get_thread_num() возвращает номер текущей нити
- 9. Переменные окружения OpenMP Переменные окружения контролируют поведение приложения. OMP_NUM_THREADS – количество нитей в параллельном регионе OMP_DYNAMIC
- 10. Директивы определения параллельных фрагментов #pragma omp parallel Определяет блок кода, который будет выполнен всеми созданными на
- 11. Простая программа на OpenMP void main() { printf("Hello!\n"); } void main() { #pragma omp parallel {
- 12. Директива parallel for OpenMP поддерживает редукцию вычислительных операций, выполняемых в циклах. Редукция подразумевает определение для каждой
- 13. Параллельные секции Явное определение блоков кода, которые могут исполняться параллельно. Послед. Паралл. #pragma omp parallel sections
- 14. Область видимости переменных Общая переменная (shared) – доступна для модификации всем нитям. Частная переменная (private) –
- 15. Общие и частные переменные void main() { int a, b, c; … #pragma omp parallel {
- 16. Явное указание области видимости Для явного указания области видимости используются следующие параметры директив: shared() – общие
- 17. void main() { int a, b, c; … #pragma omp parallel shared(a) private(b) { int d,
- 18. void main() { int rank; #pragma omp parallel { rank = omp_get_thread_num(); } printf("%d\n", rank); }
- 19. void main() { int rank; #pragma omp parallel shared (rank) { rank = omp_get_thread_num(); printf("%d\n", rank);
- 20. Директивы синхронизации #pragma omp master Определяет блок кода, который будет выполнен только главной нитью. #pragma omp
- 21. #pragma omp master Определяет блок кода, который будет выполнен только главной нитью. Не подразумевает барьера для
- 23. Скачать презентацию
Слайд 2Содержание
Модель программирования в общей памяти
Модель FORK-JOIN
Стандарт OpenMP
Основные понятия и функции OpenMP
Содержание
Модель программирования в общей памяти
Модель FORK-JOIN
Стандарт OpenMP
Основные понятия и функции OpenMP

Слайд 3Программирование в общей памяти
…
Процесс 0
Процесс 1
Процесс N-1
Данные
Параллельное приложение состоит из нескольких процессов,
Программирование в общей памяти
…
Процесс 0
Процесс 1
Процесс N-1
Данные
Параллельное приложение состоит из нескольких процессов,
Слайд 4Модель FORK-JOIN
Современные операционные системы поддерживают полновесные процессы (программы) и легковесные процессы (нити).
Процесс
Модель FORK-JOIN
Современные операционные системы поддерживают полновесные процессы (программы) и легковесные процессы (нити).
Процесс
Слайд 5Стандарт OpenMP
OpenMP – стандарт, реализующий модели программирования в общей памяти и Fork-Join.
Стандарт
Стандарт OpenMP
OpenMP – стандарт, реализующий модели программирования в общей памяти и Fork-Join.
Стандарт

Слайд 6Структура OpenMP-программы
Параллельные регионы
Главная нить
Главная нить (программа) порождает семейство дочерних нитей (сколько необходимо).
Структура OpenMP-программы
Параллельные регионы
Главная нить
Главная нить (программа) порождает семейство дочерних нитей (сколько необходимо).
Слайд 7Директивы OpenMP
Директивы OpenMP – директивы C/C++ компилятора #pragma.
Для использования директив необходимо установить
Директивы OpenMP
Директивы OpenMP – директивы C/C++ компилятора #pragma.
Для использования директив необходимо установить

Слайд 8Функции библиотеки OpenMP
Назначение функций библиотеки:
контроль и просмотр параметров OpenMP-программы
omp_get_thread_num() возвращает номер текущей
Функции библиотеки OpenMP
Назначение функций библиотеки:
контроль и просмотр параметров OpenMP-программы
omp_get_thread_num() возвращает номер текущей

Слайд 9Переменные окружения OpenMP
Переменные окружения контролируют поведение приложения.
OMP_NUM_THREADS – количество нитей в параллельном
Переменные окружения OpenMP
Переменные окружения контролируют поведение приложения.
OMP_NUM_THREADS – количество нитей в параллельном

Слайд 10Директивы определения
параллельных фрагментов
#pragma omp parallel
Определяет блок кода, который будет выполнен
Директивы определения
параллельных фрагментов
#pragma omp parallel Определяет блок кода, который будет выполнен

Слайд 11Простая программа на OpenMP
void main()
{
printf("Hello!\n");
}
void main()
{
#pragma omp parallel
{
printf("Hello!\n");
}
}
Результат
Результат (для 2-х
Простая программа на OpenMP
void main()
{
printf("Hello!\n");
}
void main()
{
#pragma omp parallel
{
printf("Hello!\n");
}
}
Результат
Результат (для 2-х

Слайд 12Директива parallel for
OpenMP поддерживает редукцию вычислительных операций, выполняемых в циклах. Редукция
Директива parallel for
OpenMP поддерживает редукцию вычислительных операций, выполняемых в циклах. Редукция

Слайд 13Параллельные секции
Явное определение блоков кода, которые могут исполняться параллельно.
Послед.
Паралл.
#pragma omp parallel sections
{
Параллельные секции
Явное определение блоков кода, которые могут исполняться параллельно.
Послед.
Паралл.
#pragma omp parallel sections
{

Слайд 14Область видимости переменных
Общая переменная (shared) – доступна для модификации всем нитям.
Частная переменная
Область видимости переменных
Общая переменная (shared) – доступна для модификации всем нитям.
Частная переменная

Слайд 15Общие и частные переменные
void main()
{
int a, b, c;
…
#pragma omp
Общие и частные переменные
void main()
{
int a, b, c;
…
#pragma omp

Слайд 16Явное указание области видимости
Для явного указания области видимости используются следующие параметры директив:
shared()
Явное указание области видимости
Для явного указания области видимости используются следующие параметры директив:
shared()

Слайд 17void main()
{
int a, b, c;
…
#pragma omp parallel shared(a) private(b)
void main()
{
int a, b, c;
…
#pragma omp parallel shared(a) private(b)

Слайд 18void main()
{
int rank;
#pragma omp parallel
{
rank = omp_get_thread_num();
}
void main()
{
int rank;
#pragma omp parallel
{
rank = omp_get_thread_num();
}

Слайд 19void main()
{
int rank;
#pragma omp parallel shared (rank)
{
rank = omp_get_thread_num();
void main()
{
int rank;
#pragma omp parallel shared (rank)
{
rank = omp_get_thread_num();

Слайд 20Директивы синхронизации
#pragma omp master
Определяет блок кода, который будет выполнен только главной
Директивы синхронизации
#pragma omp master Определяет блок кода, который будет выполнен только главной

Слайд 21#pragma omp master
Определяет блок кода, который будет выполнен только главной нитью. Не
#pragma omp master
Определяет блок кода, который будет выполнен только главной нитью. Не

 Objektorientierte Programmierung. Modul 24
Objektorientierte Programmierung. Modul 24 Интернет вещей. Управление GPIO из WEB-браузера
Интернет вещей. Управление GPIO из WEB-браузера 202b64355ed2741af4039e665cb537b1
202b64355ed2741af4039e665cb537b1 7-1-3 Всемирная паутина
7-1-3 Всемирная паутина Язык структурированных запросов. Лекция №7
Язык структурированных запросов. Лекция №7 Методологические аспекты эволюции информационных технологий
Методологические аспекты эволюции информационных технологий Кибер-безопасность
Кибер-безопасность Создание однотабличной базы данных
Создание однотабличной базы данных Итеративная модель
Итеративная модель Системное программирование. Лекция №6
Системное программирование. Лекция №6 2) Процедуры и функции
2) Процедуры и функции Картинка для экрана
Картинка для экрана Информация и её свойства. Информация и информационные процессы
Информация и её свойства. Информация и информационные процессы Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Отчет интерна Теком
Отчет интерна Теком Operating System. Лабораторная работа 1
Operating System. Лабораторная работа 1 Развитие систем подвижной связи к 5G
Развитие систем подвижной связи к 5G Структура новостей
Структура новостей Издания книг. Новинки ИМЭ
Издания книг. Новинки ИМЭ Решение задач с одномерным массивом
Решение задач с одномерным массивом Curtis. Mood board
Curtis. Mood board Алгоритмы
Алгоритмы Залогинивание
Залогинивание Основные определения и термины криптологии. Тема 2
Основные определения и термины криптологии. Тема 2 Разработка информационной защиты переговорной комнаты
Разработка информационной защиты переговорной комнаты Tsoy (1)
Tsoy (1) Медиапрофиль. Фотомодель из города Обоянь
Медиапрофиль. Фотомодель из города Обоянь Безопасность в Internet
Безопасность в Internet