- Распознавание образов в программировании

Содержание
- 2. 4.1. Машина (метод) опорных векторов (SVM, Support Vector Machine – Вапник В. и др. – 60-80
- 3. Все гиперплоскости вида (w,x) + b′ = 0, где b′ ∈ (b –1, b +1) также
- 4. Рис. 4.1 Для надёжного разделения классов необходимо чтобы расстояние между разделяющими гиперплоскостями было как можно большим.
- 5. Свойства Метода опорных векторов: 1) это наиболее быстрый способ нахождения решающих функций; 2) метод сводится к
- 6. 4.2. Классификация с помощью функции расстояния Этот способ предполагает определение функции, оценивающей меру принадлежности предъявленного для
- 7. В качестве такой меры близости чаще всего используют метрику, т.е. такую неотрицательную функцию d : Rn
- 8. 2. Метод ближайшего соседа. В этом способе расстояние определяется в соответствии со следующим алгоритмом: а) Определяется
- 9. Предположим, что имеется множество прецедентов, т.е. обучающая выборка Ξ = {x1 ,..., xN} в пространстве признаков
- 10. Метод потенциальных функций связан с определением так называемой потенциальной функции u(x,y) , т.е. некоторой положительной функциии,
- 11. Решающая функция может и не содержать всех слагаемых и будет иметь вид (1) где xj∈ Ξ
- 12. Рис. 4.1. Образы жокеев и баскетболистов в пространстве признаков. Детерминированный подход 4.4. Статистический подход к задаче
- 13. Рис. 4.2 Образы жокеев и баскетболистов в пространстве признаков.
- 14. Рис. 4.3 Образы жокеев и баскетболистов в пространстве признаков. Статистический подход
- 15. При большом количестве объектов относительную частоту появления образа в классе можно оценить, построив гистограмму по объектам,
- 16. Рис. 4.4 Гистограмма Рис. 4.5 Функция плотности распределения вероятностей
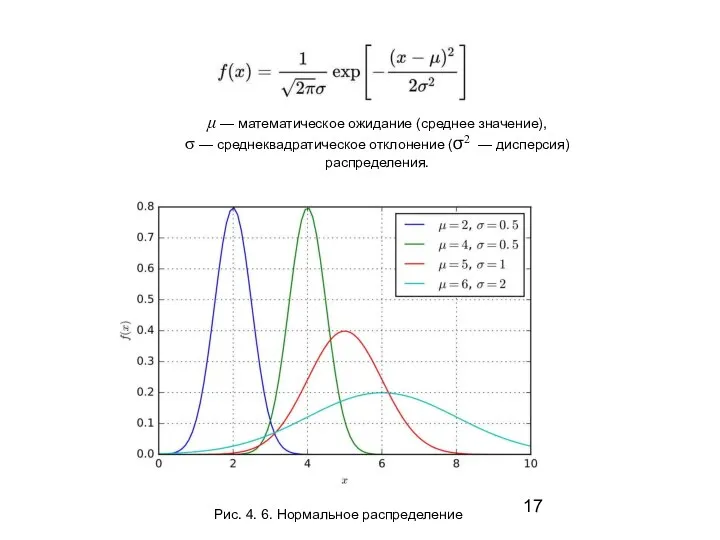
- 17. Рис. 4. 6. Нормальное распределение μ — математическое ожидание (среднее значение), σ — среднеквадратическое отклонение (σ2
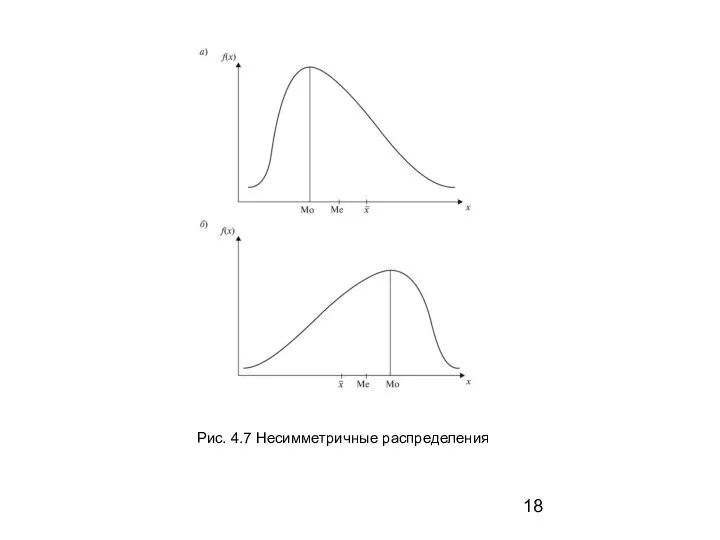
- 18. Рис. 4.7 Несимметричные распределения
- 19. В основе статистических методов классификации лежит предположение, что функция плотности вероятности f(x) для любого из выделяемых
- 20. Критерий Байеса обеспечивает минимальную в среднем вероятность ошибки распознавания при многократном принятии решения. С этой целью
- 21. Второе выражение (4.2) соответствует уже знакомому нам виду разделяющей функции для пары классов: dij(x)=0 . То
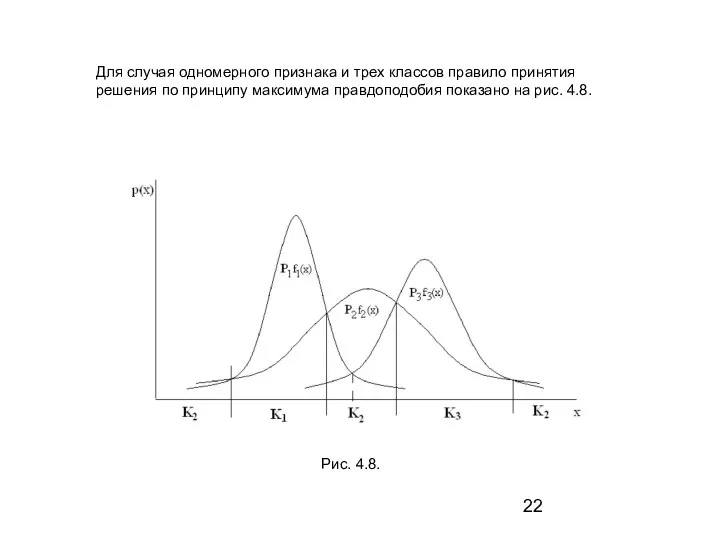
- 22. Для случая одномерного признака и трех классов правило принятия решения по принципу максимума правдоподобия показано на
- 24. Наиболее распространенные методы классификации без обучения: ISODATA; K-Средних. Метод классификации без обучения ISODATA (Итерационная самоорганизующаяся методика
- 26. Скачать презентацию

Слайд 3Все гиперплоскости вида (w,x) + b′ = 0, где b′ ∈ (b
Все гиперплоскости вида (w,x) + b′ = 0, где b′ ∈ (b

Слайд 4Рис. 4.1
Для надёжного разделения классов необходимо чтобы расстояние между разделяющими гиперплоскостями было
Рис. 4.1
Для надёжного разделения классов необходимо чтобы расстояние между разделяющими гиперплоскостями было

Слайд 5Свойства Метода опорных векторов:
1) это наиболее быстрый способ нахождения решающих функций;
2)
Свойства Метода опорных векторов:
1) это наиболее быстрый способ нахождения решающих функций;
2)

Слайд 6 4.2. Классификация с помощью функции расстояния
Этот способ предполагает определение функции,
4.2. Классификация с помощью функции расстояния
Этот способ предполагает определение функции,

Слайд 7В качестве такой меры близости чаще всего используют метрику, т.е. такую
неотрицательную
неотрицательную

Слайд 82. Метод ближайшего соседа.
В этом способе расстояние определяется в соответствии со
2. Метод ближайшего соседа.
В этом способе расстояние определяется в соответствии со

Слайд 9 Предположим, что имеется множество прецедентов, т.е. обучающая выборка Ξ = {x1
Предположим, что имеется множество прецедентов, т.е. обучающая выборка Ξ = {x1

Слайд 10 Метод потенциальных функций связан с определением так называемой потенциальной функции u(x,y)
Метод потенциальных функций связан с определением так называемой потенциальной функции u(x,y)

Слайд 11Решающая функция может и не содержать всех слагаемых и будет иметь вид
Решающая функция может и не содержать всех слагаемых и будет иметь вид

Слайд 12Рис. 4.1. Образы жокеев и баскетболистов в пространстве
признаков. Детерминированный подход
4.4. Статистический подход
Рис. 4.1. Образы жокеев и баскетболистов в пространстве
признаков. Детерминированный подход
4.4. Статистический подход
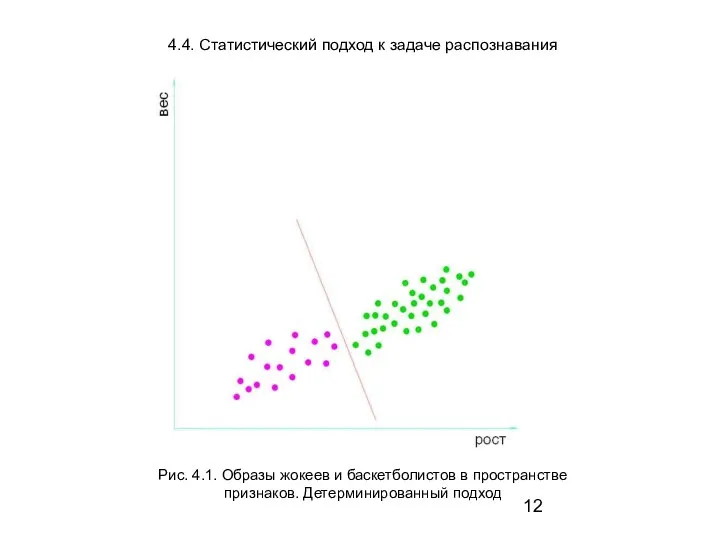
Слайд 13Рис. 4.2 Образы жокеев и баскетболистов в пространстве
признаков.
Рис. 4.2 Образы жокеев и баскетболистов в пространстве
признаков.
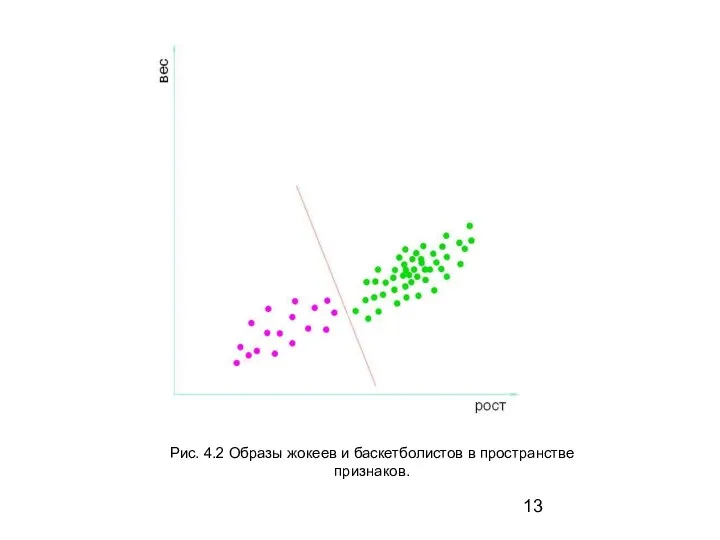
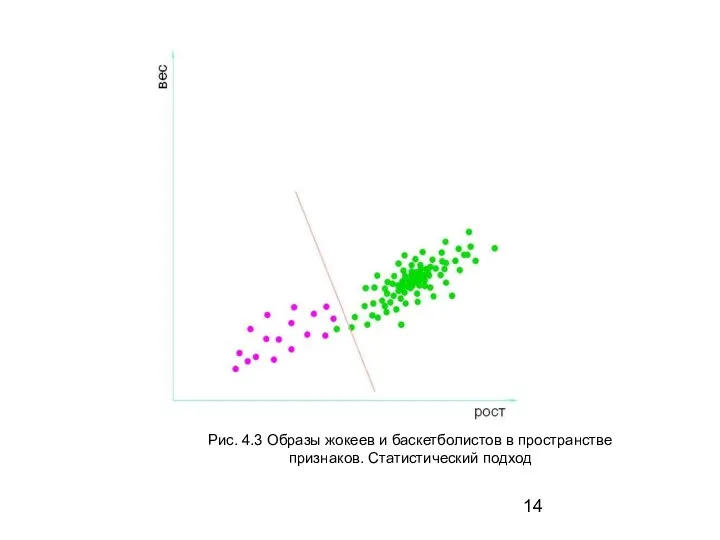
Слайд 14Рис. 4.3 Образы жокеев и баскетболистов в пространстве
признаков. Статистический подход
Рис. 4.3 Образы жокеев и баскетболистов в пространстве
признаков. Статистический подход
Слайд 15 При большом количестве объектов относительную частоту появления
образа в классе можно оценить,
При большом количестве объектов относительную частоту появления
образа в классе можно оценить,

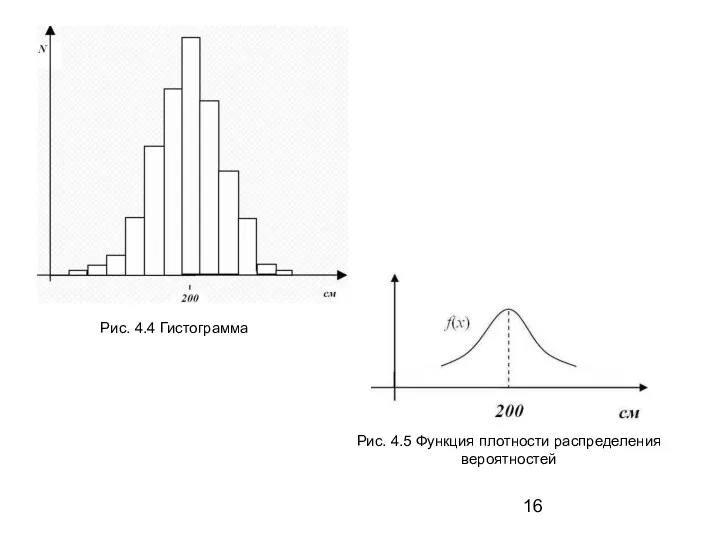
Слайд 16Рис. 4.4 Гистограмма
Рис. 4.5 Функция плотности распределения
вероятностей
Рис. 4.4 Гистограмма
Рис. 4.5 Функция плотности распределения
вероятностей
Слайд 17Рис. 4. 6. Нормальное распределение
μ — математическое ожидание (среднее значение),
σ — среднеквадратическое отклонение
Рис. 4. 6. Нормальное распределение
μ — математическое ожидание (среднее значение),
σ — среднеквадратическое отклонение
Слайд 18Рис. 4.7 Несимметричные распределения
Рис. 4.7 Несимметричные распределения
Слайд 19 В основе статистических методов классификации лежит предположение,
что функция плотности вероятности
В основе статистических методов классификации лежит предположение,
что функция плотности вероятности

Слайд 20 Критерий Байеса обеспечивает минимальную в среднем вероятность ошибки
распознавания при многократном
Критерий Байеса обеспечивает минимальную в среднем вероятность ошибки
распознавания при многократном

Слайд 21Второе выражение (4.2) соответствует уже знакомому нам
виду разделяющей функции для пары классов:
Второе выражение (4.2) соответствует уже знакомому нам
виду разделяющей функции для пары классов:

Слайд 22Для случая одномерного признака и трех классов правило принятия решения по принципу
Для случая одномерного признака и трех классов правило принятия решения по принципу

Слайд 24 Наиболее распространенные методы классификации без обучения:
ISODATA;
K-Средних.
Метод классификации без обучения
Наиболее распространенные методы классификации без обучения:
ISODATA;
K-Средних.
Метод классификации без обучения

 Организация профессиональной диспетчерской службы в 2 клика
Организация профессиональной диспетчерской службы в 2 клика СРМ Калькулятор
СРМ Калькулятор Динамические структуры данных. Списки
Динамические структуры данных. Списки Чек-лист полезных ссылок для поиска работы
Чек-лист полезных ссылок для поиска работы Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование Знакомство учащихся с мультимедийными ресурсами школьной библиотеки
Знакомство учащихся с мультимедийными ресурсами школьной библиотеки Безопасность в сети интернет. Дистанционное воспитательное мероприятие
Безопасность в сети интернет. Дистанционное воспитательное мероприятие LectOS3
LectOS3 Разработка проектной документации для системы управления процессом создания программного обеспечения АО Тандер
Разработка проектной документации для системы управления процессом создания программного обеспечения АО Тандер Object Oriented Programming
Object Oriented Programming Использование электронных документов как доказательств по уголовным делам
Использование электронных документов как доказательств по уголовным делам Знакомство с языками программирования. Начальные сведения о Паскале
Знакомство с языками программирования. Начальные сведения о Паскале Создать БД Видеосалон
Создать БД Видеосалон История развития RPG, как жанра игр
История развития RPG, как жанра игр Продуктовое направление. Отчет 2021. Стратегия 2022. Работа с Битриксом , работа над реплатформингом
Продуктовое направление. Отчет 2021. Стратегия 2022. Работа с Битриксом , работа над реплатформингом Сложность вычислений
Сложность вычислений Как написать грамотный PR-текст для социальных сетей: практические советы с примерами
Как написать грамотный PR-текст для социальных сетей: практические советы с примерами Базы данных. Запрос параметров
Базы данных. Запрос параметров Информация. Введение
Информация. Введение Уверенность в каждом дне
Уверенность в каждом дне Курс по продвижению сайтов
Курс по продвижению сайтов Информационная безопасность автоматизированных систем
Информационная безопасность автоматизированных систем Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Кодирование информации
Кодирование информации Основные вектора атак на приложения. Способы их достижения и возможные последствия
Основные вектора атак на приложения. Способы их достижения и возможные последствия Презентация на тему Текстовые документы и технологии их создания (7 класс)
Презентация на тему Текстовые документы и технологии их создания (7 класс)  Тема 11. Занятие 2. Мероприятия по контролю эффективности инженернотехнической защиты информации
Тема 11. Занятие 2. Мероприятия по контролю эффективности инженернотехнической защиты информации Работа в Excel
Работа в Excel