- T-SQL. Производительность запросов. Вынесение подзапроса в оператор WITH

Содержание
- 2. Объединение результатов нескольких запросов Вынесение подзапроса в оператор WITH Аналитические функции Оконные функции Иерархические запросы Практика
- 3. Что такое производительность запросов и что на нее влияет? Оптимизатор запроса Анализ плана запроса Индексы и
- 4. Ресурсы необходимые для выполнения запроса Память – данные нужно где-то сохранить Оперативная – быстрая Долговременная(Диски) –
- 5. Что такое производительность запросов Кол-во запросов в единицу времени? Объем выводимых данных\ кол-во строк в ед.
- 6. Что влияет на производительность запросов Железо Объем данных Сложность запроса SQL – декларативный язык, СУБД сама
- 7. Выполнение SQL запроса Оптимизатор запросов парсит текст SQL запроса Поиск и обработка команд, проверка существования объектов,
- 8. Порядок обработки операторов при парсинге запроса FROM – найти таблицу(ы) ON – узнать как соединять JOIN
- 9. Порядок выполнения запроса Чтение данных из таблиц Все остальное Соединение данных Расчет констант Группировка Вывод Чтение
- 10. План выполнения запроса План выполнения определяет, как именно будет происходить: Чтение данных из таблиц Сканирование \
- 11. Анализ плана выполнения запроса План выполнения запроса состоит из операторов обработки данных, соединенных стрелками - «потоками
- 12. Выполнение SQL запроса Оптимизатор запросов парсит текст SQL запроса Поиск и обработка команд, проверка существования объектов,
- 13. План выполнения запроса План выполнения определяет, как именно будет происходить: Чтение данных из таблиц Сканирование \
- 14. Чтение данных из таблиц Есть 2 способа чтения данных из таблицы Сканирование – чтение всех строк,
- 15. Что такое индекс Индекс – бинарное дерево поиска. У индекса есть узлы. Поиск по индексу быстрее
- 16. Индексы в MS SQL Server Кластерный индекс – структура, в которой хранится вся таблица, отсортированная по
- 17. Чтение данных из таблиц Оптимизатор запросов выберет сканирование таблицы в случаях: Когда у таблицы нет индексов
- 18. Статистики Статистики – это примерная информация о данных в таблице, которую СУБД собирает самостоятельно в фоновом
- 19. Типы данных и их влияние на производительность Типы данных столбцов таблицы влияют на производительность: Из-за выделяемой
- 21. Скачать презентацию
Слайд 2Объединение результатов нескольких запросов
Вынесение подзапроса в оператор WITH
Аналитические функции
Оконные функции
Иерархические
Объединение результатов нескольких запросов
Вынесение подзапроса в оператор WITH
Аналитические функции
Оконные функции
Иерархические

Слайд 3Что такое производительность запросов и что на нее влияет?
Оптимизатор запроса
Анализ плана
Что такое производительность запросов и что на нее влияет?
Оптимизатор запроса
Анализ плана

Слайд 4Ресурсы необходимые
для выполнения запроса
Память – данные нужно где-то сохранить
Оперативная – быстрая
Долговременная(Диски)
Ресурсы необходимые
для выполнения запроса
Память – данные нужно где-то сохранить
Оперативная – быстрая
Долговременная(Диски)

Слайд 5Что такое производительность запросов
Кол-во запросов в единицу времени?
Объем выводимых данных\ кол-во
Что такое производительность запросов
Кол-во запросов в единицу времени?
Объем выводимых данных\ кол-во

Слайд 6Что влияет на производительность запросов
Железо
Объем данных
Сложность запроса
SQL – декларативный язык, СУБД
Что влияет на производительность запросов
Железо
Объем данных
Сложность запроса
SQL – декларативный язык, СУБД

Слайд 7Выполнение SQL запроса
Оптимизатор запросов парсит текст SQL запроса
Поиск и обработка команд, проверка
Выполнение SQL запроса
Оптимизатор запросов парсит текст SQL запроса
Поиск и обработка команд, проверка

Слайд 8Порядок обработки операторов при парсинге запроса
FROM – найти таблицу(ы)
ON – узнать как
Порядок обработки операторов при парсинге запроса
FROM – найти таблицу(ы)
ON – узнать как

Слайд 9Порядок выполнения запроса
Чтение данных из таблиц
Все остальное
Соединение данных
Расчет констант
Группировка
Вывод
Чтение данных из таблиц,
Порядок выполнения запроса
Чтение данных из таблиц
Все остальное
Соединение данных
Расчет констант
Группировка
Вывод
Чтение данных из таблиц,

Слайд 10План выполнения запроса
План выполнения определяет, как именно будет происходить:
Чтение данных из таблиц
Сканирование
План выполнения запроса
План выполнения определяет, как именно будет происходить:
Чтение данных из таблиц
Сканирование

Слайд 11Анализ плана выполнения запроса
План выполнения запроса состоит из операторов обработки данных, соединенных
Анализ плана выполнения запроса
План выполнения запроса состоит из операторов обработки данных, соединенных

Слайд 12Выполнение SQL запроса
Оптимизатор запросов парсит текст SQL запроса
Поиск и обработка команд, проверка
Выполнение SQL запроса
Оптимизатор запросов парсит текст SQL запроса
Поиск и обработка команд, проверка

Слайд 13План выполнения запроса
План выполнения определяет, как именно будет происходить:
Чтение данных из таблиц
Сканирование
План выполнения запроса
План выполнения определяет, как именно будет происходить:
Чтение данных из таблиц
Сканирование

Слайд 14Чтение данных из таблиц
Есть 2 способа чтения данных из таблицы
Сканирование – чтение
Чтение данных из таблиц
Есть 2 способа чтения данных из таблицы
Сканирование – чтение

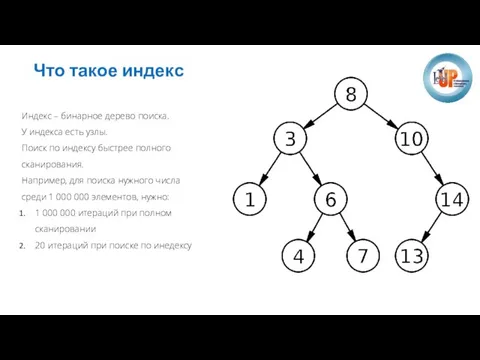
Слайд 15Что такое индекс
Индекс – бинарное дерево поиска.
У индекса есть узлы.
Поиск по индексу
Что такое индекс
Индекс – бинарное дерево поиска.
У индекса есть узлы.
Поиск по индексу
Слайд 16Индексы в MS SQL Server
Кластерный индекс – структура, в которой хранится вся
Индексы в MS SQL Server
Кластерный индекс – структура, в которой хранится вся

Слайд 17Чтение данных из таблиц
Оптимизатор запросов выберет сканирование таблицы в случаях:
Когда у таблицы
Чтение данных из таблиц
Оптимизатор запросов выберет сканирование таблицы в случаях:
Когда у таблицы

Слайд 18Статистики
Статистики – это примерная информация о данных в таблице, которую СУБД собирает
Статистики
Статистики – это примерная информация о данных в таблице, которую СУБД собирает

Слайд 19Типы данных и их влияние на производительность
Типы данных столбцов таблицы влияют на
Типы данных и их влияние на производительность
Типы данных столбцов таблицы влияют на

 Технология программирования задач с циклами
Технология программирования задач с циклами История развития интернета
История развития интернета Знакомство с системой компьютерной математики
Знакомство с системой компьютерной математики Традиционный подход к вебпрограммированию на основе перезагрузки страницы. Тема 9
Традиционный подход к вебпрограммированию на основе перезагрузки страницы. Тема 9 Циклы в С++
Циклы в С++ Базовые теги. Урок 2
Базовые теги. Урок 2 Стандартная библиотека шаблонов STL. Обобщенные алгоритмы. (Лекция 15)
Стандартная библиотека шаблонов STL. Обобщенные алгоритмы. (Лекция 15) Фактическая информация. Занятие 4
Фактическая информация. Занятие 4 РПГ-Рогалик Бесконечная Шутка
РПГ-Рогалик Бесконечная Шутка Разработка проектов приграничного сотрудничества
Разработка проектов приграничного сотрудничества Источники информации
Источники информации Все, все про Майнкрафт
Все, все про Майнкрафт МЕТОДОЛОГИЯ ПРОЕКТИРОВАНИЯ
МЕТОДОЛОГИЯ ПРОЕКТИРОВАНИЯ Разновидности журналистики. Информационная журналистика
Разновидности журналистики. Информационная журналистика Оператор Ввода
Оператор Ввода Презентация на тему История развития отечественной вычислительной техники
Презентация на тему История развития отечественной вычислительной техники  Правила поведения в интернете
Правила поведения в интернете Развитие программирования. Лекция 1
Развитие программирования. Лекция 1 Наука информатика
Наука информатика Медиация в нашей жизни
Медиация в нашей жизни Пусть будет добрым интернет
Пусть будет добрым интернет Понятие информационной безопасности
Понятие информационной безопасности Аппаратная часть компьютера
Аппаратная часть компьютера Язык программирования Pascal Массивы А. Жидков
Язык программирования Pascal Массивы А. Жидков Онлайн кассы 2018
Онлайн кассы 2018 Представление звуковой информации
Представление звуковой информации Касса
Касса Ввод и вывод. Паскаль. 8 класс
Ввод и вывод. Паскаль. 8 класс