- Полногеномный анализ ассоциаций

Содержание
- 2. GWAS Полногено́мный анализ ассоциа́ций (англ. GWAS, Genome-Wide Association Studies) — направление биологических (как правило, биомедицинских) исследований,
- 3. GWAS Обычно сравнивают геномы группы больных людей с геномами контрольной группы, включающей в себя аналогичных по
- 4. GWAS (Википедия) Вторая по важности область применения GWAS — фармакогенетика, то есть поиск аллелей, связанных с
- 5. GWAS (Википедия) В основе поиска полногеномных ассоциаций как правило лежит сравнение геномов двух групп людей: носителей
- 6. GWAS (Википедия)
- 7. GWAS Верхняя прямая − критерий Бонферрони, нижняя − FDR
- 8. Если нам нужно сравнить средние двух заданных групп, обычно используется t-критерий Стьюдента или Уэлша. Если число
- 9. На самом деле нормальность распределения требуется не для самих выборок, а только для их средних, а
- 10. Слева: экспоненциальное распределение (λ=1). Справа: распределение выборочных средних из него объема n=10. Красная кривая: аппроксимация нормальным
- 11. Нулевая гипотеза заключается в том, что различия между выборками являются случайными и все выборки на самом
- 12. Распределение t-критерия Распределение F-критерия 2.5% 2.5% 5%
- 13. Но это верно для одного эксперимента. Если эксперимент повторяется N раз, то вероятность, что хотя бы
- 14. Этот критерий слишком жесткий. Если, например, α= 0.05 и N= 106, то p= α/N= 5∙10-8 и
- 15. Критерий FDR заключается в следущем. Произвольно выбираем уровень значимости p. Ожидаемое число случайных выборочных критериев, которые
- 16. FDR (false discovery rate) (N=106)
- 17. Multi-Trait meta-GWAS
- 18. Спасибо за внимание! Thank you for your attention! 感谢您的关注!
- 19. GWAS
- 21. Скачать презентацию
Слайд 2GWAS
Полногено́мный анализ ассоциа́ций (англ. GWAS, Genome-Wide Association Studies) — направление биологических (как правило, биомедицинских) исследований,
GWAS
Полногено́мный анализ ассоциа́ций (англ. GWAS, Genome-Wide Association Studies) — направление биологических (как правило, биомедицинских) исследований,

Слайд 3GWAS
Обычно сравнивают геномы группы больных людей с геномами контрольной группы, включающей в
GWAS
Обычно сравнивают геномы группы больных людей с геномами контрольной группы, включающей в

Слайд 4GWAS
(Википедия)
Вторая по важности область применения GWAS — фармакогенетика, то есть поиск аллелей,
GWAS
(Википедия)
Вторая по важности область применения GWAS — фармакогенетика, то есть поиск аллелей,

Слайд 5GWAS
(Википедия)
В основе поиска полногеномных ассоциаций как правило лежит сравнение геномов двух групп
GWAS
(Википедия)
В основе поиска полногеномных ассоциаций как правило лежит сравнение геномов двух групп

Слайд 6GWAS
(Википедия)
GWAS
(Википедия)
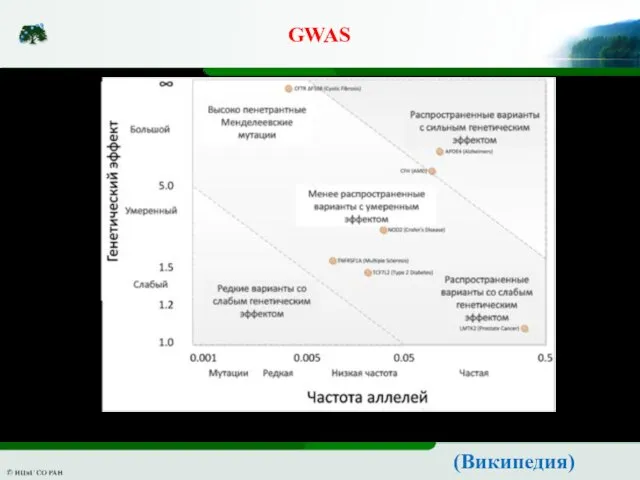
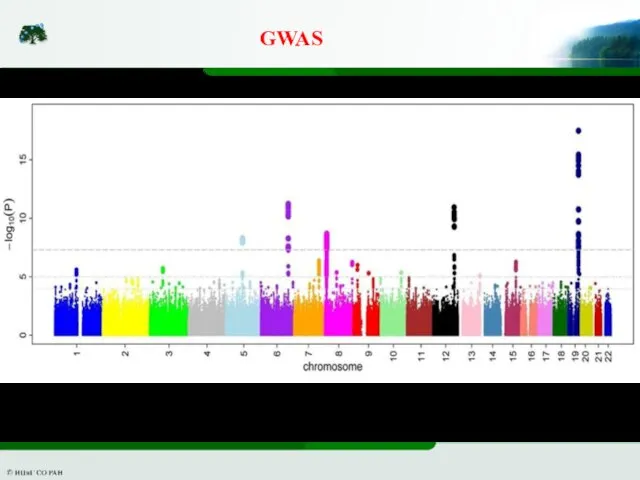
Слайд 7GWAS
Верхняя прямая − критерий Бонферрони, нижняя − FDR
GWAS
Верхняя прямая − критерий Бонферрони, нижняя − FDR
Слайд 8Если нам нужно сравнить средние двух заданных групп, обычно используется t-критерий Стьюдента
Если нам нужно сравнить средние двух заданных групп, обычно используется t-критерий Стьюдента

Слайд 9На самом деле нормальность распределения требуется не для самих выборок, а только
На самом деле нормальность распределения требуется не для самих выборок, а только

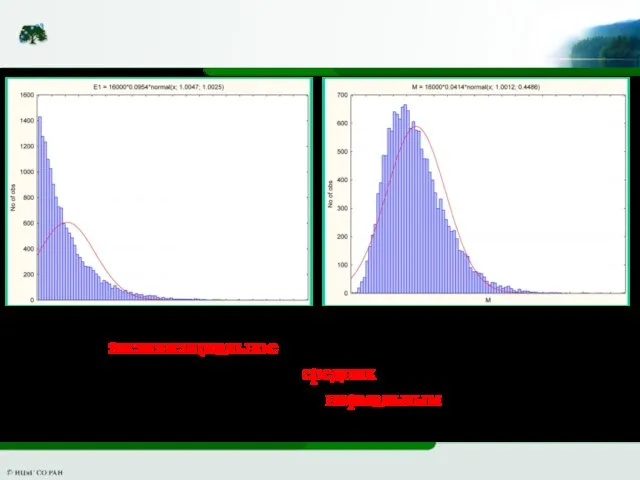
Слайд 10Слева: экспоненциальное распределение (λ=1). Справа: распределение выборочных средних из него объема n=10.
Слева: экспоненциальное распределение (λ=1). Справа: распределение выборочных средних из него объема n=10.
Слайд 11Нулевая гипотеза заключается в том, что различия между выборками являются случайными и
Нулевая гипотеза заключается в том, что различия между выборками являются случайными и

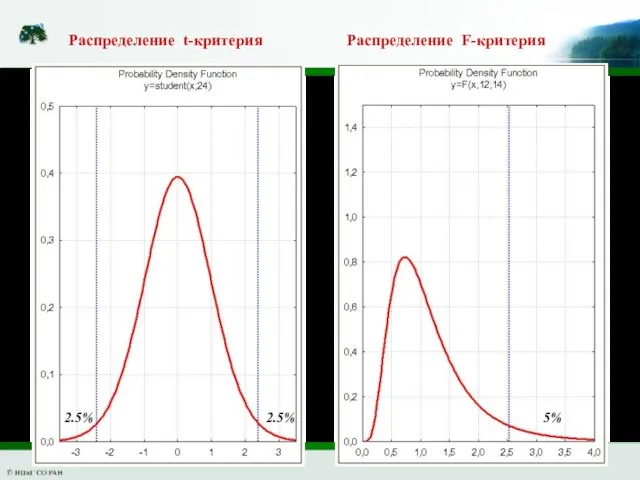
Слайд 12Распределение t-критерия Распределение F-критерия
2.5%
2.5%
5%
Распределение t-критерия Распределение F-критерия
2.5%
2.5%
5%
Слайд 13Но это верно для одного эксперимента. Если эксперимент повторяется N раз, то
Но это верно для одного эксперимента. Если эксперимент повторяется N раз, то

Слайд 14Этот критерий слишком жесткий. Если, например, α= 0.05 и N= 106, то
Этот критерий слишком жесткий. Если, например, α= 0.05 и N= 106, то

Слайд 15Критерий FDR заключается в следущем. Произвольно выбираем уровень значимости p. Ожидаемое число
Критерий FDR заключается в следущем. Произвольно выбираем уровень значимости p. Ожидаемое число

Слайд 16FDR (false discovery rate)
(N=106)
FDR (false discovery rate)
(N=106)

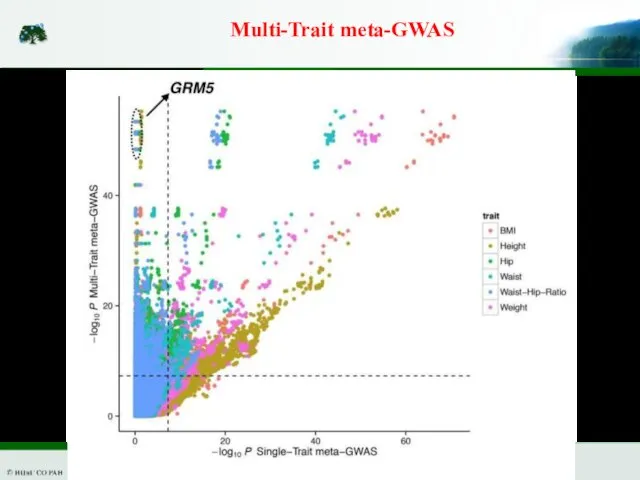
Слайд 17Multi-Trait meta-GWAS
Multi-Trait meta-GWAS
Слайд 18Спасибо за внимание!
Thank you for your attention!
感谢您的关注!
Спасибо за внимание!
Thank you for your attention!
感谢您的关注!

Слайд 19GWAS
GWAS

 Здоровое питание
Здоровое питание Тепловодолечение. Теплолечение
Тепловодолечение. Теплолечение ВВЕДЕНИЕ ПРИКОРМА Ведущая: Наталья Разахацкая, консультант по грудному вскармливанию, IBCLC
ВВЕДЕНИЕ ПРИКОРМА Ведущая: Наталья Разахацкая, консультант по грудному вскармливанию, IBCLC Клиническая задача от Чугунова Р.П
Клиническая задача от Чугунова Р.П Проект #стопСПИД/ВИЧ
Проект #стопСПИД/ВИЧ Хирургические и функциональные особенности анатомии кисти
Хирургические и функциональные особенности анатомии кисти Отчет о работе управления Роспотребнадзора по Архангельской области в 2020году
Отчет о работе управления Роспотребнадзора по Архангельской области в 2020году Хронический холецистит
Хронический холецистит Оказание первой помощи
Оказание первой помощи Геморрой. Стадии геморроя
Геморрой. Стадии геморроя Технология, делающая реабилитацию доступной
Технология, делающая реабилитацию доступной Zanyatie_3_Ostry_kholitsistit
Zanyatie_3_Ostry_kholitsistit Специфическая профилактика COVID-19. Вакцинация беременных
Специфическая профилактика COVID-19. Вакцинация беременных Туберкулез. Классические симптомы туберкулёза
Туберкулез. Классические симптомы туберкулёза Закупки в сфере здравоохранения в 2019 году
Закупки в сфере здравоохранения в 2019 году Нарушения менструального цикла
Нарушения менструального цикла Аутизм, РАС – биокоррекция с помощью диеты и продуктов Тенториум
Аутизм, РАС – биокоррекция с помощью диеты и продуктов Тенториум Диагностика доброкачественных опухолей ГМ
Диагностика доброкачественных опухолей ГМ Экстремальные состояния
Экстремальные состояния Течение беременности при заболеваниях внутренних органов
Течение беременности при заболеваниях внутренних органов Повреждение. Некроз. Апоптоз
Повреждение. Некроз. Апоптоз Лептоспироз. Збудник
Лептоспироз. Збудник Гинекологиядағы эндоскопияның даму тарихы. Эндоскопиялық зерттеу әдістерінің жіктелісі
Гинекологиядағы эндоскопияның даму тарихы. Эндоскопиялық зерттеу әдістерінің жіктелісі Желудочная диспепсия – синдром ленивого желудка
Желудочная диспепсия – синдром ленивого желудка Санитарно-эпидемиологические требования к условиям и организации обучения в общеобразовательных учреждениях
Санитарно-эпидемиологические требования к условиям и организации обучения в общеобразовательных учреждениях Особенности поддерживающей терапии пациентов с трижды-негативным раком молочной железы на фоне химиотерапии
Особенности поддерживающей терапии пациентов с трижды-негативным раком молочной железы на фоне химиотерапии Лептоспироз 2020 (1)
Лептоспироз 2020 (1) Вторичный сифилис
Вторичный сифилис