- Лекция 2: OpenMP - модель параллелизма по управлению

Содержание
- 2. Москва, 2010 г. Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению © Бахтин В.А.
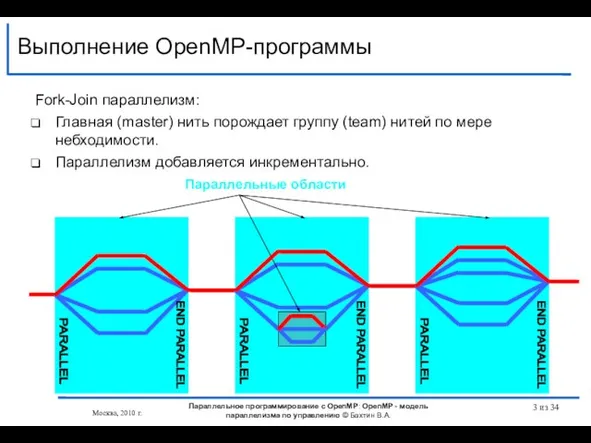
- 3. END PARALLEL PARALLEL END PARALLEL PARALLEL Выполнение OpenMP-программы Fork-Join параллелизм: Главная (master) нить порождает группу (team)
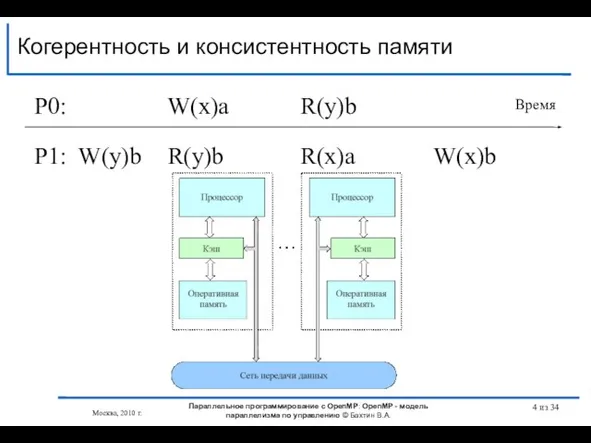
- 4. Когерентность и консистентность памяти Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению © Бахтин
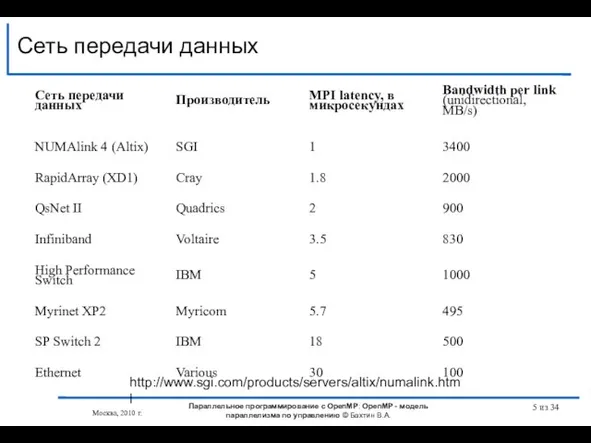
- 5. Сеть передачи данных http://www.sgi.com/products/servers/altix/numalink.html Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению © Бахтин
- 6. Модели консистентности памяти из 34 Модель консистентности представляет собой некоторый договор между программами и памятью, в
- 7. Строгая консистентность из 34 Операция чтения ячейки памяти с адресом X должна возвращать значение, записанное самой
- 8. Последовательная консистентность из 34 Впервые определил Lamport в 1979 г. в контексте совместно используемой памяти для
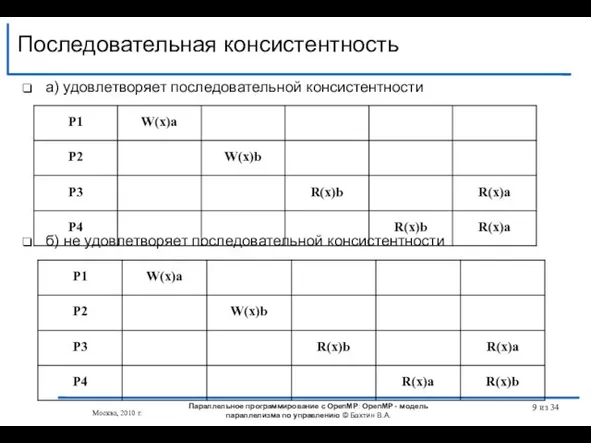
- 9. а) удовлетворяет последовательной консистентности б) не удовлетворяет последовательной консистентности Последовательная консистентность из 34 Параллельное программирование с
- 10. Результат повторного выполнения параллельной программы в системе с последовательной консистентностью может не совпадать с результатом предыдущего
- 11. Причинная консистентность из 34 Предположим, что процесс P1 модифицировал переменную x, затем процесс P2 прочитал x
- 12. Причинная консистентность из 34 Нарушение модели причинной консистентности Корректная последовательность для модели причинной консистентности Определение потенциальной
- 13. PRAM (Pipelined RAM) и процессорная консистентность из 34 PRAM: Операции записи, выполняемые одним процессором, видны всем
- 14. Слабая консистентность (weak consistency) из 34 Пусть процесс в критической секции циклически читает и записывает значение
- 15. Слабая консистентность (weak consistency) из 34 Первое правило определяет, что все процессы видят обращения к синхронизационным
- 16. Слабая консистентность (weak consistency) из 34 Допустимая последователь- ность событий Недопустимая последовательность событий Параллельное программирование с
- 17. Консистентность по выходу из 34 В системе со слабой консистентностью возникает проблема при обращении к синхронизационной
- 18. Консистентность по выходу из 34 Следующие правила определяют требования к модели консистентности по выходу: До выполнения
- 19. 001 Модель памяти в OpenMP из 34 Нить Кэш общих переменных Общая память Private-переменные Threadprivate-переменные 001
- 20. 001 Модель памяти в OpenMP из 34 Нить 0 Общая память 001 Нить 1 static int
- 21. Консистентность памяти в OpenMP из 34 Корректная последовательность работы нитей с переменной: Нить0 записывает значение переменной
- 22. Консистентность памяти в OpenMP из 34 Если пересечение множеств переменных, указанных в операциях flush, выполняемых различными
- 23. Консистентность памяти в OpenMP из 34 #pragma omp flush [(список переменных)] По умолчанию все переменные приводятся
- 24. Классы переменных В модели программирования с разделяемой памятью: Большинство переменных по умолчанию считаются SHARED Глобальные переменные
- 25. Классы переменных double Array1[100]; int main() { int Array2[100]; #pragma omp parallel { int iam =
- 26. Можно изменить класс переменной при помощи конструкций: SHARED (список переменных) PRIVATE (список переменных) FIRSTPRIVATE (список переменных)
- 27. Конструкция PRIVATE Конструкция «private(var)» создает локальную копию переменной «var» в каждой из нитей. Значение переменной не
- 28. Конструкция FIRSTPRIVATE «firstprivate» является специальным случаем «private». Инициализирует каждую приватную копию соответствующим значением из главной (master)
- 29. Конструкция LASTPRIVATE lastprivate передает значение приватной переменной, посчитанной на последней итерации в глобальную переменную. из 34
- 30. Конструкция THREADPRIVATE Отличается от применения конструкции PRIVATE: с PRIVATE глобальные переменные маскируются THREADPRIVATE сохраняют глобальную область
- 31. Конструкция DEFAULT Меняет класс переменной по умолчанию: DEFAULT (SHARED) – действует по умолчанию DEFAULT (PRIVATE) –
- 32. из 34 Литература… http://www.openmp.org Распределенные системы. Принципы и парадигмы. / Э. Таненбаум, М. ван Стеен. –
- 33. из 34 Вопросы? Вопросы? Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению © Бахтин
- 35. Скачать презентацию
Слайд 2Москва, 2010 г.
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению
Москва, 2010 г.
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению

Слайд 3END PARALLEL
PARALLEL
END PARALLEL
PARALLEL
Выполнение OpenMP-программы
Fork-Join параллелизм:
Главная (master) нить порождает группу (team) нитей
END PARALLEL
PARALLEL
END PARALLEL
PARALLEL
Выполнение OpenMP-программы
Fork-Join параллелизм:
Главная (master) нить порождает группу (team) нитей
Слайд 4Когерентность и консистентность памяти
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по
Когерентность и консистентность памяти
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по
Слайд 5Сеть передачи данных
http://www.sgi.com/products/servers/altix/numalink.html
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению
Сеть передачи данных
http://www.sgi.com/products/servers/altix/numalink.html
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению
Слайд 6Модели консистентности памяти
из 34
Модель консистентности представляет собой некоторый договор между программами
Модели консистентности памяти
из 34
Модель консистентности представляет собой некоторый договор между программами

Слайд 7Строгая консистентность
из 34
Операция чтения ячейки памяти с адресом X должна возвращать
Строгая консистентность
из 34
Операция чтения ячейки памяти с адресом X должна возвращать

Слайд 8Последовательная консистентность
из 34
Впервые определил Lamport в 1979 г. в контексте совместно
Последовательная консистентность
из 34
Впервые определил Lamport в 1979 г. в контексте совместно

Слайд 9а) удовлетворяет последовательной консистентности
б) не удовлетворяет последовательной консистентности
Последовательная консистентность
из 34
Параллельное программирование
а) удовлетворяет последовательной консистентности
б) не удовлетворяет последовательной консистентности
Последовательная консистентность
из 34
Параллельное программирование
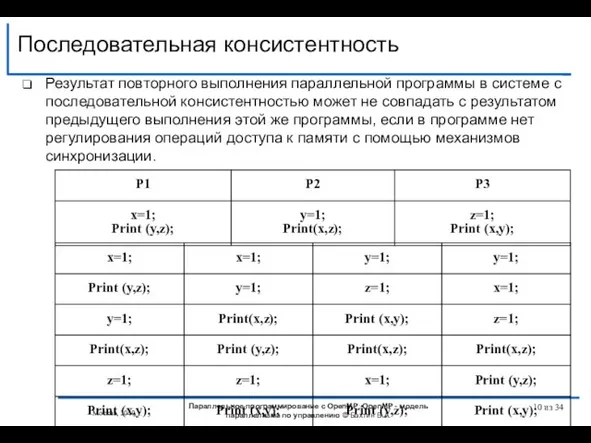
Слайд 10Результат повторного выполнения параллельной программы в системе с последовательной консистентностью может не
Результат повторного выполнения параллельной программы в системе с последовательной консистентностью может не
Слайд 11Причинная консистентность
из 34
Предположим, что процесс P1 модифицировал переменную x, затем процесс
Причинная консистентность
из 34
Предположим, что процесс P1 модифицировал переменную x, затем процесс

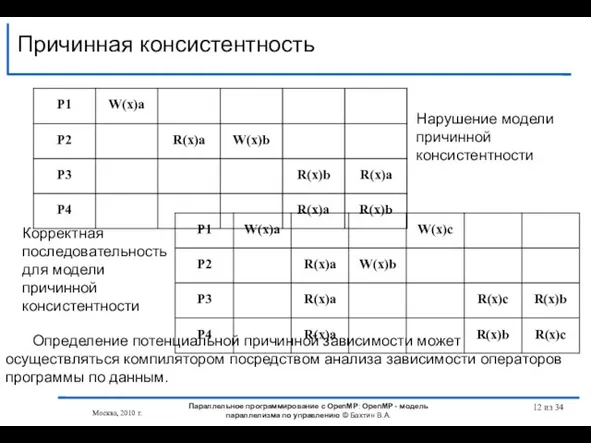
Слайд 12Причинная консистентность
из 34
Нарушение модели причинной консистентности
Корректная последовательность для модели причинной
Причинная консистентность
из 34
Нарушение модели причинной консистентности
Корректная последовательность для модели причинной
Слайд 13PRAM (Pipelined RAM) и процессорная консистентность
из 34
PRAM: Операции записи, выполняемые одним
PRAM (Pipelined RAM) и процессорная консистентность
из 34
PRAM: Операции записи, выполняемые одним

Слайд 14Слабая консистентность (weak consistency)
из 34
Пусть процесс в критической секции циклически читает
Слабая консистентность (weak consistency)
из 34
Пусть процесс в критической секции циклически читает

Слайд 15Слабая консистентность (weak consistency)
из 34
Первое правило определяет, что все процессы видят
Слабая консистентность (weak consistency)
из 34
Первое правило определяет, что все процессы видят

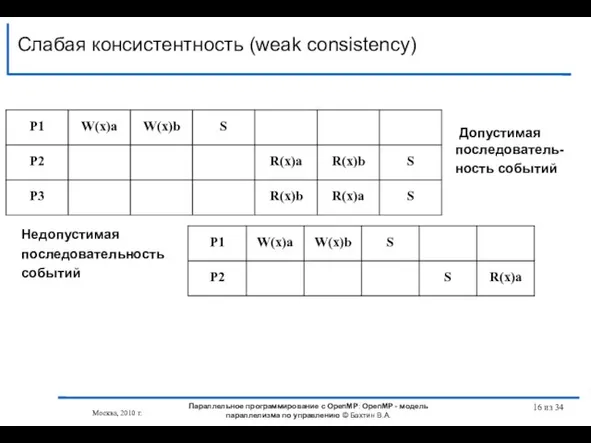
Слайд 16Слабая консистентность (weak consistency)
из 34
Допустимая последователь-
ность событий
Недопустимая
последовательность
событий
Параллельное программирование с
Слабая консистентность (weak consistency)
из 34
Допустимая последователь-
ность событий
Недопустимая
последовательность
событий
Параллельное программирование с
Слайд 17Консистентность по выходу
из 34
В системе со слабой консистентностью возникает проблема при
Консистентность по выходу
из 34
В системе со слабой консистентностью возникает проблема при

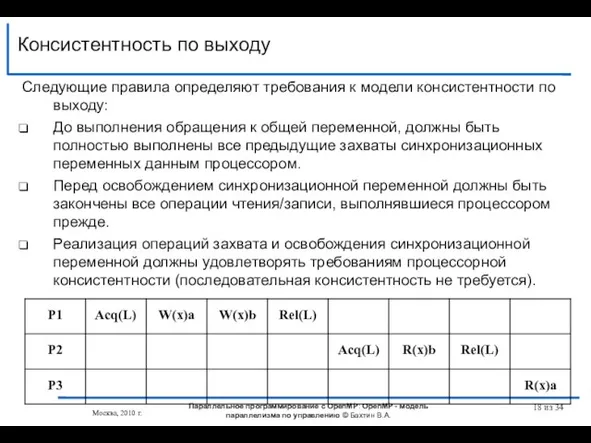
Слайд 18Консистентность по выходу
из 34
Следующие правила определяют требования к модели консистентности по
Консистентность по выходу
из 34
Следующие правила определяют требования к модели консистентности по
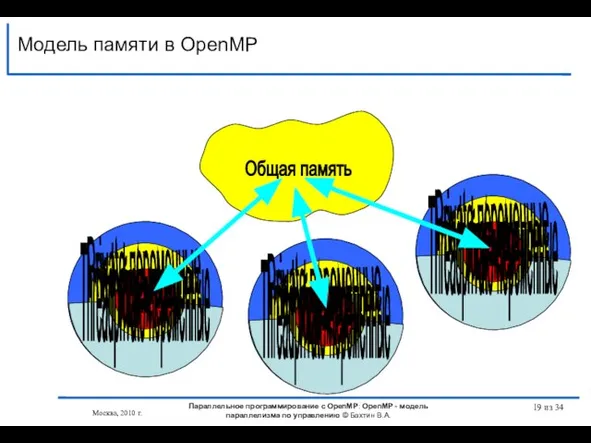
Слайд 19001
Модель памяти в OpenMP
из 34
Нить
Кэш общих переменных
Общая память
Private-переменные
Threadprivate-переменные
001
Нить
Кэш общих переменных
Private-переменные
Threadprivate-переменные
001
Нить
Кэш общих
001
Модель памяти в OpenMP
из 34
Нить
Кэш общих переменных
Общая память
Private-переменные
Threadprivate-переменные
001
Нить
Кэш общих переменных
Private-переменные
Threadprivate-переменные
001
Нить
Кэш общих
Слайд 20001
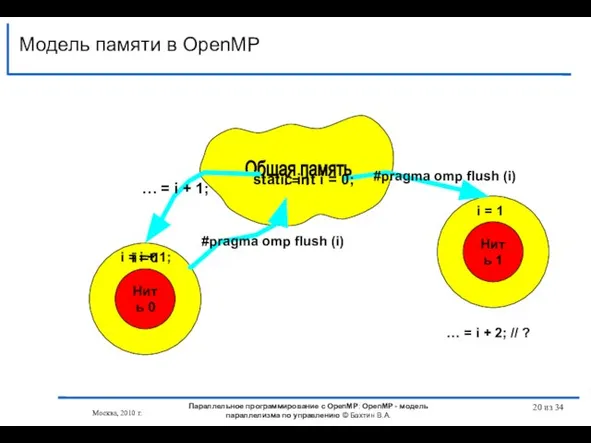
Модель памяти в OpenMP
из 34
Нить 0
Общая память
001
Нить 1
static int i =
001
Модель памяти в OpenMP
из 34
Нить 0
Общая память
001
Нить 1
static int i =
Слайд 21Консистентность памяти в OpenMP
из 34
Корректная последовательность работы нитей с переменной:
Нить0 записывает
Консистентность памяти в OpenMP
из 34
Корректная последовательность работы нитей с переменной:
Нить0 записывает

Слайд 22Консистентность памяти в OpenMP
из 34
Если пересечение множеств переменных, указанных в операциях
Консистентность памяти в OpenMP
из 34
Если пересечение множеств переменных, указанных в операциях

Слайд 23Консистентность памяти в OpenMP
из 34
#pragma omp flush [(список переменных)]
По умолчанию все
Консистентность памяти в OpenMP
из 34
#pragma omp flush [(список переменных)]
По умолчанию все
![Консистентность памяти в OpenMP из 34 #pragma omp flush [(список переменных)] По](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/414869/slide-22.jpg)
Слайд 24Классы переменных
В модели программирования с разделяемой памятью:
Большинство переменных по умолчанию считаются
Классы переменных
В модели программирования с разделяемой памятью:
Большинство переменных по умолчанию считаются

Слайд 25Классы переменных
double Array1[100];
int main() {
int Array2[100];
#pragma omp parallel
{ int iam
Классы переменных
double Array1[100];
int main() {
int Array2[100];
#pragma omp parallel
{ int iam
![Классы переменных double Array1[100]; int main() { int Array2[100]; #pragma omp parallel](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/414869/slide-24.jpg)
Слайд 26Можно изменить класс переменной при помощи конструкций:
SHARED (список переменных)
PRIVATE (список переменных)
FIRSTPRIVATE (список
Можно изменить класс переменной при помощи конструкций:
SHARED (список переменных)
PRIVATE (список переменных)
FIRSTPRIVATE (список

Слайд 27Конструкция PRIVATE
Конструкция «private(var)» создает локальную копию переменной «var» в каждой из нитей.
Значение
Конструкция PRIVATE
Конструкция «private(var)» создает локальную копию переменной «var» в каждой из нитей.
Значение

Слайд 28Конструкция FIRSTPRIVATE
«firstprivate» является специальным случаем «private».
Инициализирует каждую приватную копию соответствующим значением из
Конструкция FIRSTPRIVATE
«firstprivate» является специальным случаем «private».
Инициализирует каждую приватную копию соответствующим значением из

Слайд 29Конструкция LASTPRIVATE
lastprivate передает значение приватной переменной, посчитанной на последней итерации в глобальную
Конструкция LASTPRIVATE
lastprivate передает значение приватной переменной, посчитанной на последней итерации в глобальную

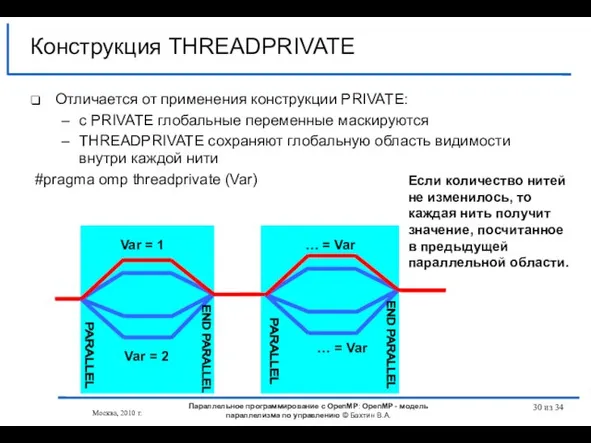
Слайд 30Конструкция THREADPRIVATE
Отличается от применения конструкции PRIVATE:
с PRIVATE глобальные переменные маскируются
THREADPRIVATE сохраняют
Конструкция THREADPRIVATE
Отличается от применения конструкции PRIVATE:
с PRIVATE глобальные переменные маскируются
THREADPRIVATE сохраняют
Слайд 31Конструкция DEFAULT
Меняет класс переменной по умолчанию:
DEFAULT (SHARED) – действует по умолчанию
DEFAULT (PRIVATE)
Конструкция DEFAULT
Меняет класс переменной по умолчанию:
DEFAULT (SHARED) – действует по умолчанию
DEFAULT (PRIVATE)

Слайд 32 из 34
Литература…
http://www.openmp.org
Распределенные системы. Принципы и парадигмы. / Э. Таненбаум, М.
из 34
Литература…
http://www.openmp.org
Распределенные системы. Принципы и парадигмы. / Э. Таненбаум, М.

Слайд 33 из 34
Вопросы?
Вопросы?
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению
из 34
Вопросы?
Вопросы?
Параллельное программирование с OpenMP: OpenMP - модель параллелизма по управлению

 Основные вопросы и задачи формирования электронного правительства в субъектах Российской Федерации
Основные вопросы и задачи формирования электронного правительства в субъектах Российской Федерации Ціннісні орієнтації підлітка
Ціннісні орієнтації підлітка Подведение итогов реализации мероприятий базовыми школами в соответствии с РЦП
Подведение итогов реализации мероприятий базовыми школами в соответствии с РЦП Университетский лицей представляет
Университетский лицей представляет ОЛЕГ САМОЙЛОВ
ОЛЕГ САМОЙЛОВ Пейзажная лирика Ф.И.Тютчева
Пейзажная лирика Ф.И.Тютчева Экология в искусстве
Экология в искусстве Нашествие Персидских войск на Элладу (5 класс)
Нашествие Персидских войск на Элладу (5 класс) Физика и здоровье
Физика и здоровье Основы промышленной автоматизации
Основы промышленной автоматизации  MTV Upgrade. Статистика
MTV Upgrade. Статистика Взаимодействие детского сада и семьи в процессе социально-нравственного воспитания детей дошкольного возраста.
Взаимодействие детского сада и семьи в процессе социально-нравственного воспитания детей дошкольного возраста. Раскрой цельнокроеного платья
Раскрой цельнокроеного платья Урок – экспедиция в страну «Лексики и Фразеологии»
Урок – экспедиция в страну «Лексики и Фразеологии» Задания для 6 класса
Задания для 6 класса Бетон и железобетон
Бетон и железобетон 7 период развития соц.работы
7 период развития соц.работы Презентация на тему Атмосфера
Презентация на тему Атмосфера  Презентация на тему Живопись Голландии
Презентация на тему Живопись Голландии НОВЫЕ ПОСТУПЛЕНИЯ ЛИТЕРАТУРЫ
НОВЫЕ ПОСТУПЛЕНИЯ ЛИТЕРАТУРЫ ЛОГОПЕДИЧЕСКИЙ МАССАЖ ПРИ РАЗЛИЧНЫХ РЕЧЕВЫХ НАРУШЕНИЯХ
ЛОГОПЕДИЧЕСКИЙ МАССАЖ ПРИ РАЗЛИЧНЫХ РЕЧЕВЫХ НАРУШЕНИЯХ Как накормить акул пера
Как накормить акул пера Бамблби
Бамблби Профессиональная деятельность учителя русского языка и литературы МОУ «Средняя общеобразовательная школа №3 п.Советский» Мухино
Профессиональная деятельность учителя русского языка и литературы МОУ «Средняя общеобразовательная школа №3 п.Советский» Мухино Система профориентации и основные её направления
Система профориентации и основные её направления Презентация продукта
Презентация продукта Презентация на тему Ребенок и право
Презентация на тему Ребенок и право Закон радиоактивного распада
Закон радиоактивного распада