- Математические методы в психологии

Содержание
- 2. Рекомендуемая литература Ермолаев-Томин, О.Ю Математические методы в психологии. – М., 2013. – 511 с. Кутейников, А.Н.
- 3. Тема 1. Измерение в психологии История возникновения Предмет и назначение дисциплины Измерение в психологии. Взаимоотношение параметров,
- 4. В первой четверти XIX в. философ И.Ф. Гербарт (1776-1841) провозгласил психологию наукой, которая должна основываться на
- 7. (William Sealy Gosset, 13 июня 1876, Кентербери — 16 октября 1937, Беконсфильд) — известный учёный-статистик, более
- 8. Определение статистики и связь с психологией и математикой Термин «статистика» имеет несколько значений: ∙ это совокупность
- 9. Слово «статистика» часто ассоциируется со словом «математика», и связывающее это понятие со сложными формулами, требующими высокого
- 10. Соотношение обыденного и научного познания
- 11. Основные задачи решаемые математическими методами в психологии Подтверждение экспериментальных данных Проверка валидности и надежности создаваемых методик
- 12. Анализ данных на компьютере. Использование MS Excel Статистические пакеты: SPSS, STATISTICA. Особенности подготовки данных для анализа
- 13. Алгоритм применения анализа данных на компьютере
- 14. Использование MS Excel Плюсы и минусы MC Excel В Microsoft Excel входит набор средств анализа данных
- 15. Статистические пакеты: SPSS, STATISTICA STATISTICA for Windows представляет собой интегрированную систему статистического анализа и обработки данных.
- 16. SPSS Альтернативное программное обеспечение SPSS включает также все процедуры ввода, отбора и корректировки данных, а также
- 17. Связь «Математических методов в психологии» с другими дисциплинами
- 18. Понятие переменных в психологии, их виды Признаки и переменные - это измеряемые психологические явления
- 19. Измерение — это приписывание объекту числа по определенному правилу. Это правило устанавливает соответствие между измеряемым свойством
- 20. Шкалы по С. Стивенсу
- 21. Сводка характеристик и примеры измерительных шкал
- 22. Типы данных
- 23. Наглядное представление данных
- 24. Графическое представление данных В самом общем виде диаграммы делятся на: 1. Столбиковые: Вертикальные; Горизонтальные; 2. Линейные
- 25. Правила графического оформления Вся структура графика предполагает его чтение слева направо, вертикальные шкалы — снизу вверх.
- 26. Правила табличного представления первичных данных Вся структура таблицы предполагает ее чтение слева направо. В первом столбце
- 27. Табулирование данных - это методы и способы построения таблиц Таблица 1 – Результаты исследования младших школьников
- 28. Тема 2. Генеральная совокупность и выборка. Понятие генеральной совокупности и выборки Виды вероятностной выборки Зависимые и
- 29. Понятие генеральной совокупности и выборки Генеральной совокупностью – называется всякая большая (конечная или бесконечная) коллекция или
- 30. Виды вероятностной выборки Случайная выборка – сформированная на основе случайного отбора. Минус случайной выборки: отобранная часть
- 31. Зависимые и независимые выборки Независимые выборки – это разные группы (людей, характеристик или параметров). Характеризуются тем,
- 32. Объем выборки вычисляют, ориентируясь на несколько параметров: 1. Задачи и методы исследования. Это критерий, которым иногда
- 33. Объем выборки – определяется численностью входящих в нее элементов. Объем выборки зависит от целей и методов
- 34. По схеме испытаний – выборки могут быть независимые и зависимые. По объему выборки делят на малые
- 35. Тема 3. Способы представления данных в психологии Представление данных. Понятие о квантилях. Понятие о рангах. Процедура
- 36. Представление данных в психологии бывает в виде: Массив данных – первичные результаты измерения искомых параметров сводятся
- 37. Варианты представления данных
- 38. Меры положения – квантили Квантиль — это точка на числовой оси измеренного признака, которая делит всю
- 39. Нахождение процентиля Процентили указывают на относительное положение индивида в выборке стандартизации. Р-й процентиль представляет собой точку,
- 40. Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов. В качестве оценки теста выбиралось
- 41. Ранговый порядок Ранжирование – это приписывание объектам чисел в зависимости от степени выраженности измеряемого свойства Установите
- 42. Ранжирование данных Ранжирование связанных рангов
- 43. Распределение частот Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько раз встречается каждое значение
- 44. Таблица распределения частот Абсолютная и относительная частоты связаны соотношением: где fa — абсолютная частота некоторого значения
- 45. Этапы построения распределения сгруппированных частот Уточнение лимитов (крайних значений интервала) – производится округление лимитов - min
- 46. Графическое представление Гистограмма – это последовательность столбцов, каждый из которых опирается на один раздельный интервал, а
- 48. Тема 4. Меры центральной тенденции Определение меры центральной тенденции; Мода; Медиана; Среднее; Выбор и особенности мер
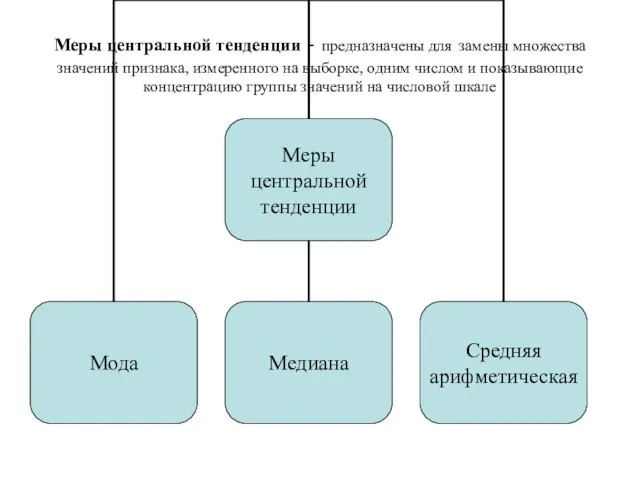
- 49. Меры центральной тенденции - предназначены для замены множества значений признака, измеренного на выборке, одним числом и
- 50. Мода (Mode) — это такое значение из множества измерений, которое встречается наиболее часто. Если все значения
- 51. Медиана (Median) — это такое значение признака, которое делит упорядоченное множество данных пополам так, что одна
- 52. Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как сумма всех значений измеренного признака,
- 53. Выбор и особенности мер центральной тенденции Для номинативных данных единственной подходящей мерой центральной тенденции является мода.
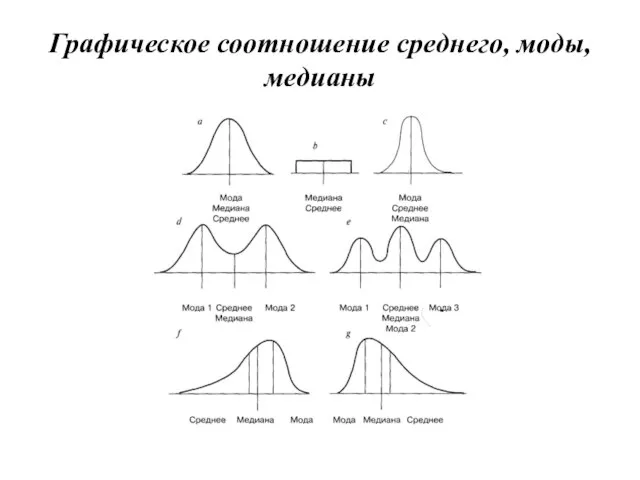
- 54. Графическое соотношение среднего, моды, медианы
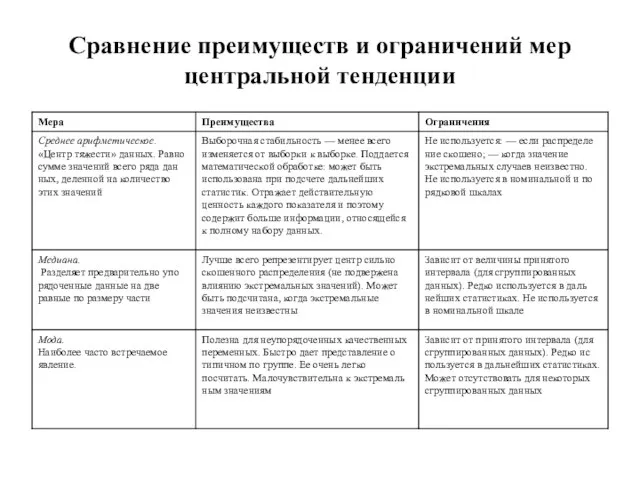
- 55. Сравнение преимуществ и ограничений мер центральной тенденции
- 56. Тема 5. Меры изменчивости Понятие меры изменчивости Лимиты. Размах вариации и его разновидности. Дисперсия и ее
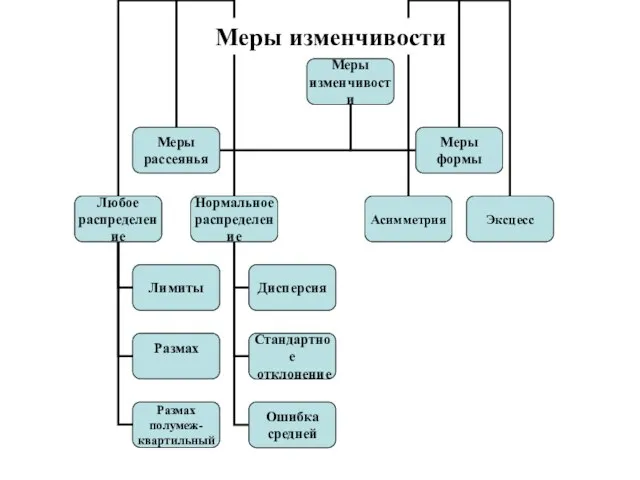
- 57. Меры изменчивости
- 58. Меры рассеяния независящие от распределения Лимиты – это характеристики, определяющие верхнюю (max) и нижнюю (min) границы
- 59. Меры рассеяния характеризующие нормальное распределение Дисперсия (Variance) — мера изменчивости для метрических данных, пропорциональная сумме квадратов
- 60. Расчет дисперсии
- 61. Меры рассеяния характеризующие нормальное распределение Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) — положительное значение квадратного
- 62. Меры формы Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида относительно среднего значения:
- 63. Тема 6. Стандартизация данных Понятие стандартизации данных. Основные формы стандартизации. z-преобразование данных.
- 64. Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры и оценок теста. Различают две
- 65. Преобразование первичных оценок в новую шкалу Центрирование – это линейная трансформация величин признака, при котором средняя
- 66. Пример преобразования в z-значения, Т-баллы
- 67. Тема 7. Теоретические распределения, используемые при статистических выводах Нормальное распределение Единичное нормальное распределение и его свойства
- 68. Виды распределения данных
- 69. Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего встречаются средние значения соответствующих показателей,
- 70. Единичное нормальное распределение и его свойства Если применить z-преобразование ко всем возможным измерениям свойств, все многообразие
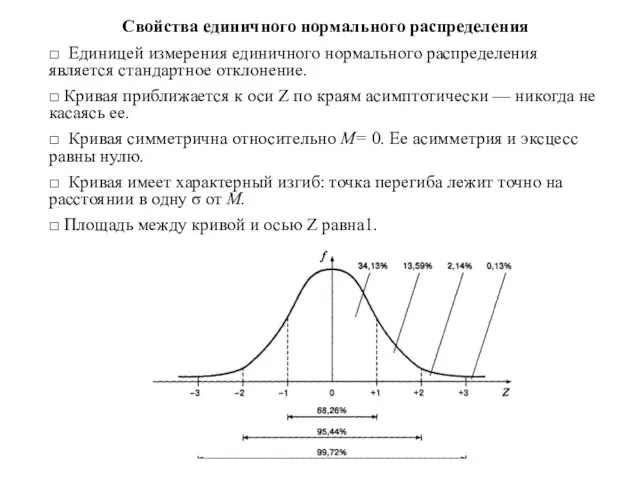
- 71. Свойства единичного нормального распределения □ Единицей измерения единичного нормального распределения является стандартное отклонение. □ Кривая приближается
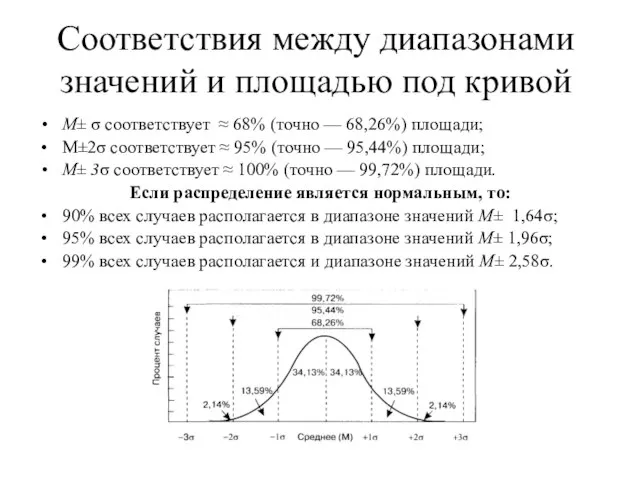
- 72. Соответствия между диапазонами значений и площадью под кривой М± σ соответствует ≈ 68% (точно — 68,26%)
- 73. Проверка нормальности распределения 1. Нормальность распределения результативного признака можно проверить путем расчета показателей асимметрии и эксцесса
- 74. 2. Еще одним из критериев проверки на нормальность - является критерий Колмагорова-Смирнова. Он позволяет оценить вероятность
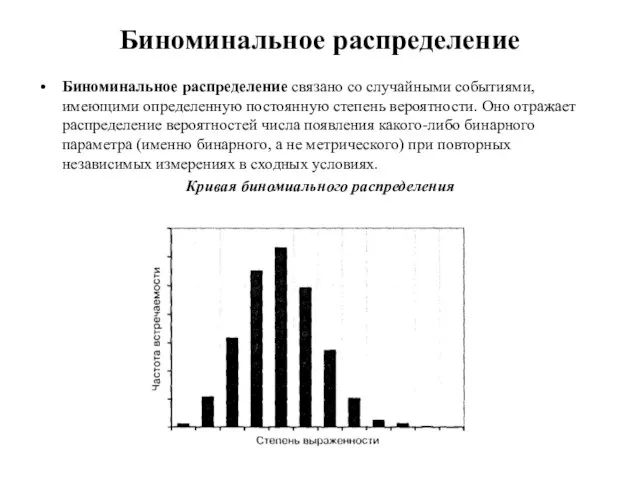
- 75. Биноминальное распределение Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень вероятности. Оно отражает распределение
- 76. Распределение Пуассона Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в отдельных случаях мала, но
- 77. Тема 8. Статистическое оценивание и проверка гипотез Статистические гипотезы. Статистический вывод. Ошибки 1 и 2 рода.
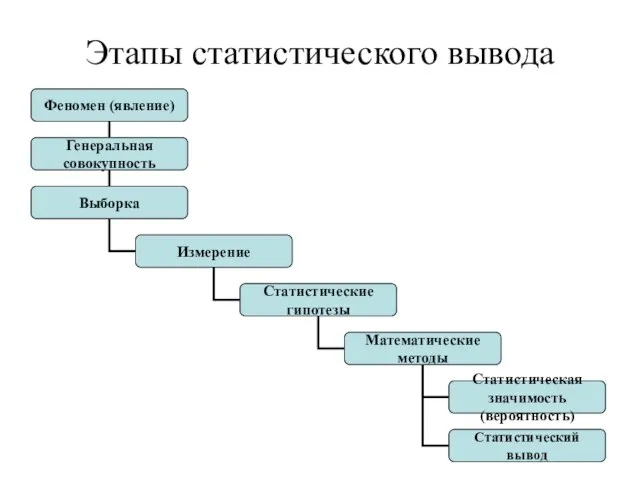
- 78. Этапы статистического вывода
- 79. Различают научные и статистические гипотезы. Научные гипотезы (предположение) формулируются как предполагаемое решение проблемы. Статистическая гипотеза –
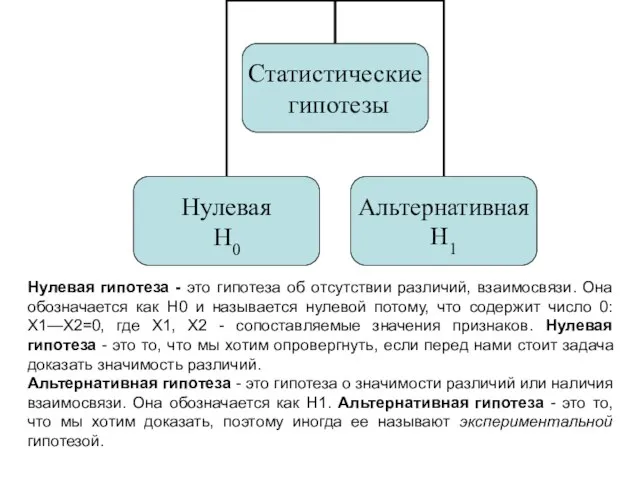
- 80. Нулевая гипотеза - это гипотеза об отсутствии различий, взаимосвязи. Она обозначается как H0 и называется нулевой
- 81. Алгоритм проверки статистических гипотез Обоснование применения критерия. Выполнение ограничений (если есть). Формулирование статистических гипотез (Н0 и
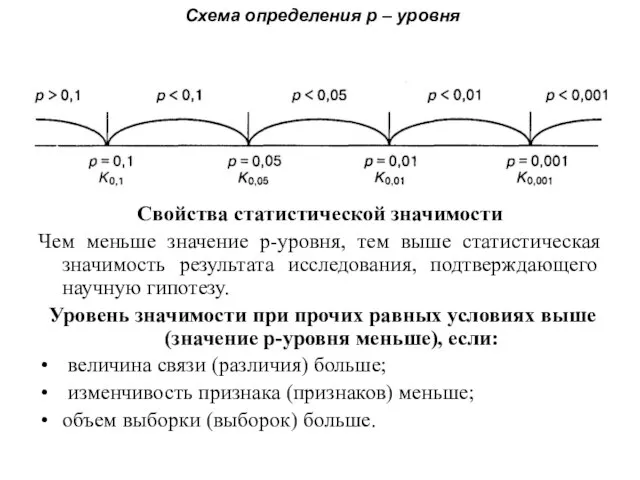
- 82. Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level). Величину называют статисти́чески зна́чимой, если мала
- 83. Схема определения р – уровня Свойства статистической значимости Чем меньше значение р-уровня, тем выше статистическая значимость
- 84. Ошибки 1 и 2 рода Ошибка I рода - ошибка, состоящая в том, что мы отклонили
- 85. Степень свободы Число степеней свободы – это количество возможных направлений изменчивости признака. Это характеристика распределения, используемая
- 86. Показатели степеней свободы для зависимых и независимых выборок Если имеются две независимые выборки, то число степеней
- 87. Статистический критерий Статистический критерий – это решающее правило, обеспечивающее надежное поведение, т.е. принятие истинной и отклонение
- 88. Параметрические и непараметрические критерии Параметрические критерии – это группа статистических критериев, которые включают в расчет параметры
- 89. Основание выбора критерия а) простота; б) более широкий диапазон использования (например, по отношению к данным, определенным
- 90. Алгоритм работы с критериями 1. Обоснование применения критерия. 2. Выполнение ограничений критерия (если они есть). 3.
- 91. Статистический вывод — это формулирование вывода на основе статистической значимости. Результатом статистического вывода является статистическое суждение,
- 92. Тема 9. Меры связи Понятие корреляции. Диаграмма рассеяния. Классификация коэффициентов корреляции. Корреляционные матрицы. Интерпретация коэффициентов корреляции.
- 93. Понятие корреляции и ее основные параметры Корреляционная связь – это согласованное изменение двух или более признаков.
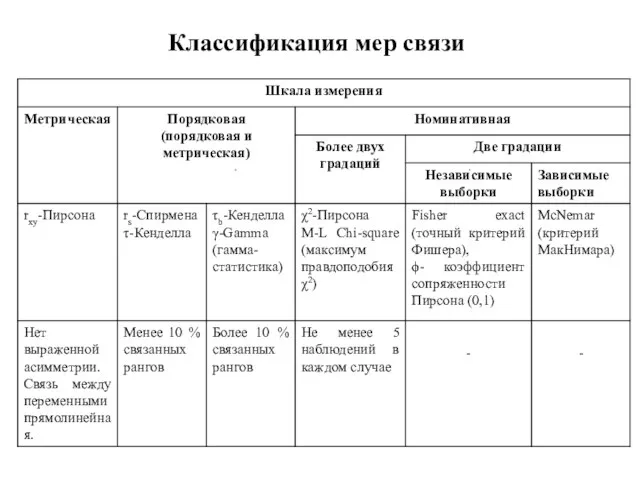
- 94. Классификация мер связи
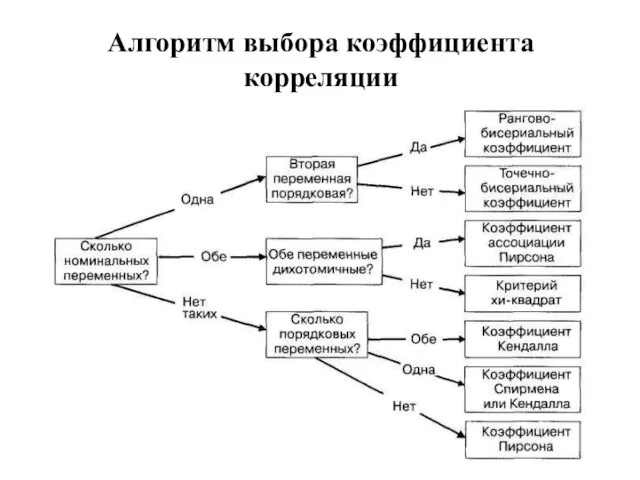
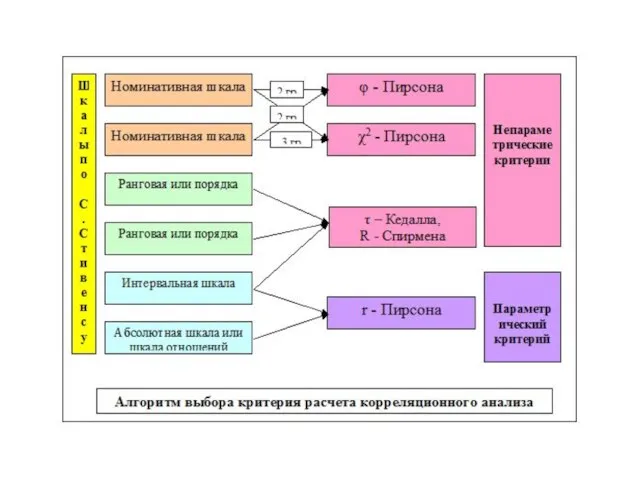
- 95. Алгоритм выбора коэффициента корреляции
- 97. Формулировка статистических гипотез Н0: Корреляция между переменными не отличается от нуля. Н1: Корреляция между переменными отличается
- 98. Виды связей Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически изображаются в виде
- 99. Примеры графиков часто встречающихся функций
- 100. Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а каждый испытуемый представляет собой точку
- 102. Классификация мер связи
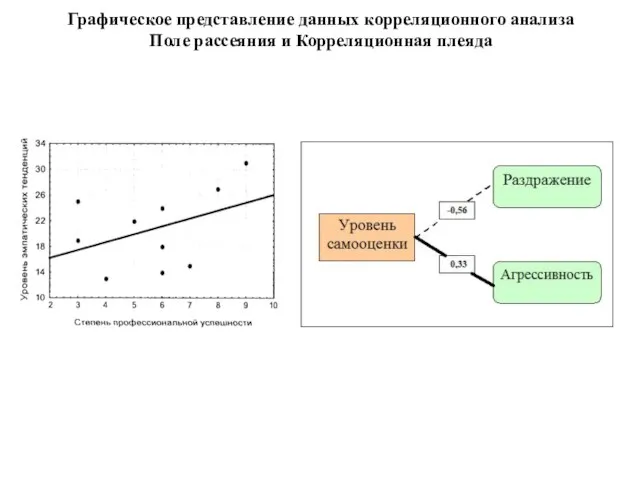
- 103. Графическое представление данных корреляционного анализа Поле рассеяния и Корреляционная плеяда
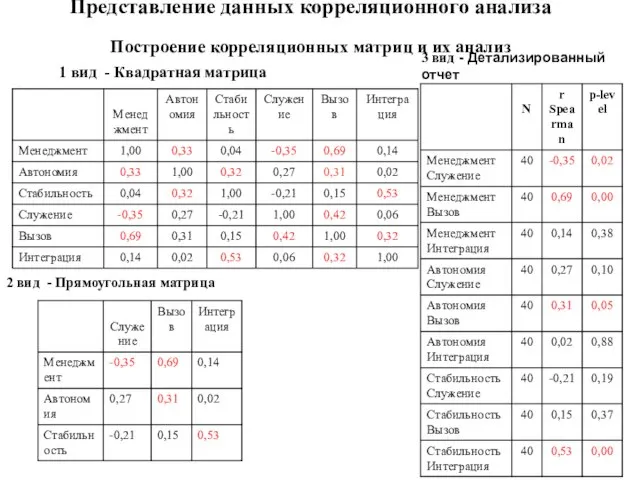
- 104. Представление данных корреляционного анализа Построение корреляционных матриц и их анализ 1 вид - Квадратная матрица 2
- 105. Коэффициент корреляции rxy- Пирсона r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических переменных, измеренных на
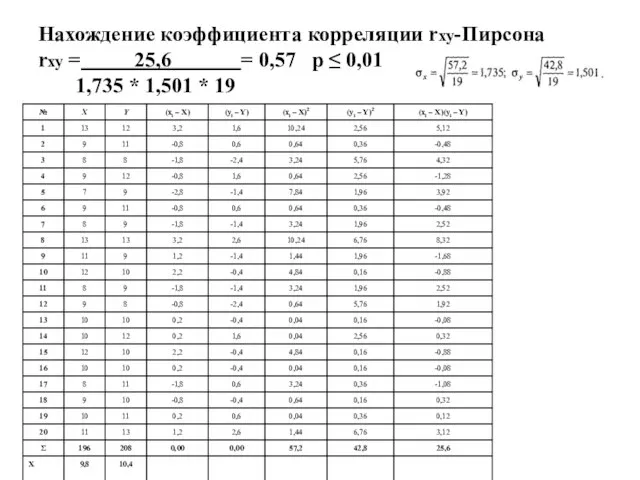
- 106. Нахождение коэффициента корреляции rxy-Пирсона rxy = 25,6 = 0,57 р ≤ 0,01 1,735 * 1,501 *
- 107. Поле рассеяния
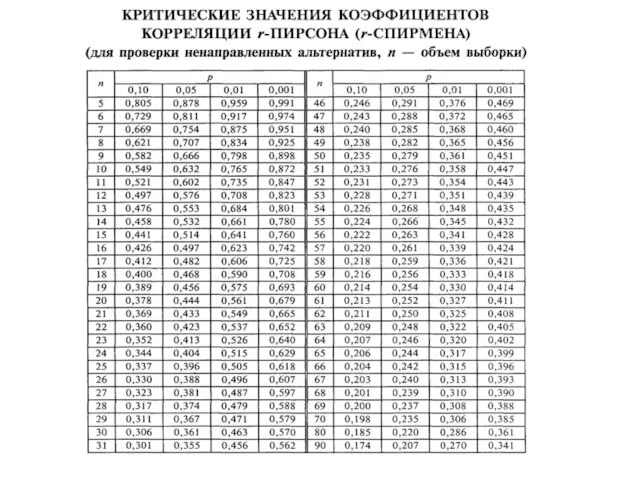
- 109. Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла Коэффициенты ранговой корреляции: r-Спирмена или ι-Кенделла применяются если обе переменные
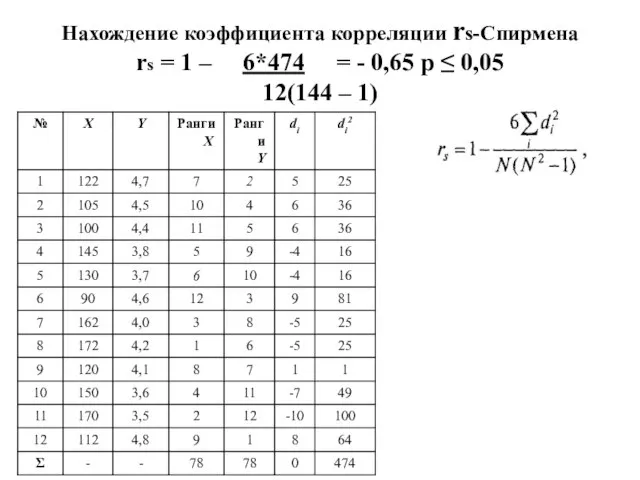
- 110. Нахождение коэффициента корреляции rs-Спирмена rs = 1 – 6*474 = - 0,65 р ≤ 0,05 12(144
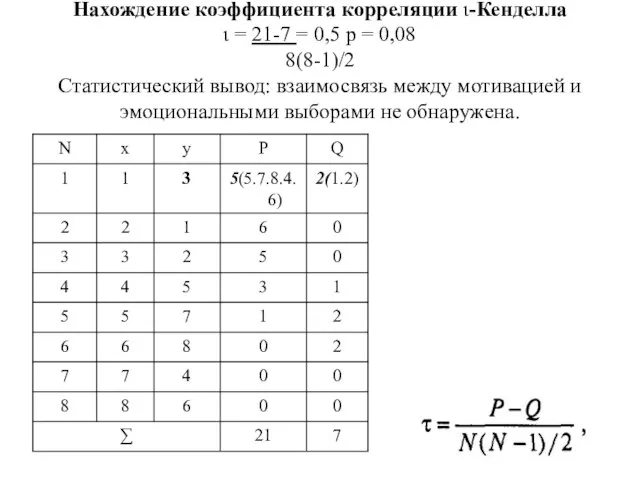
- 111. Формула ι-Кенделла : Пояснения к формуле Р — общее число совпадений. Q — общее число инверсий
- 112. Нахождение коэффициента корреляции ι-Кенделла ι = 21-7 = 0,5 р = 0,08 8(8-1)/2 Статистический вывод: взаимосвязь
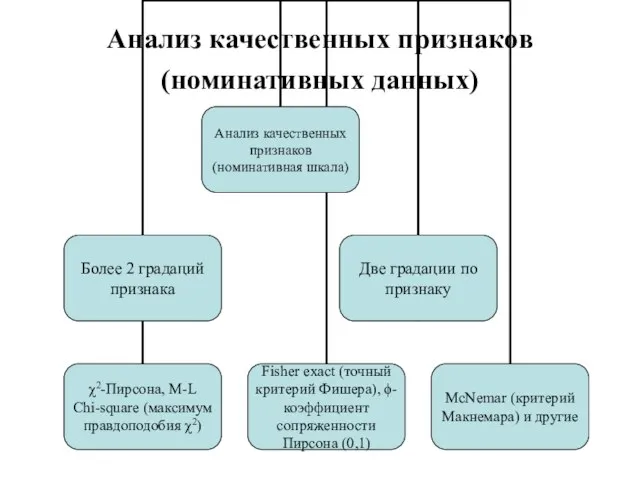
- 113. Тема 10. Анализ качественных признаков (номинативных данных) Корреляция номинативных данных критерий χ2-Пирсона Корреляция бинарных данных фи-коэффициент
- 114. Анализ качественных признаков (номинативных данных)
- 115. Корреляция номинативных данных критерий χ2-Пирсона Критерий χ2-Пирсона применяется если обе переменные представлены в номинативной шкале, одна
- 116. Нахождение критерия χ2-Пирсона Теоретические частоты fe женский и синий = 4 x 8 = 2,1 15
- 117. Нахождение критерия χ2-Пирсона Расчет χ2= 11,8 k = 3; j = 2; df = (k –
- 118. Корреляция бинарных данных фи-коэффициент сопряженности Пирсона Коэффициент сопряженности φ-Пирсона применяется если обе переменные представлены в номинативной
- 119. Нахождение коэффициента сопряженности φ-Пирсона
- 120. Тема 11. Анализ различий между 2 группами независимых выборок Классификация методов сравнения Представление данных сравнительного анализа
- 121. Классификация методов сравнения
- 123. Методы сравнения В зависимости от решаемых задач методы внутри этой группы классифицируются по трем основаниям: Количество
- 124. Представление данных сравнительного анализа Графическое представление данных
- 125. Построение таблиц
- 126. Параметрический критерий t-Стьюдента для двух независимых выборок Метод позволяет проверить гипотезу о том, что средние значения
- 127. Параметрический критерий сравнения 2 групп (зависимых и независимых) t-Стьюдента Данный критерий был разработан Уильямом Госсетом для
- 128. Нахождение критерия t-Стьюдента для двух независимых выборок tэ = 44,1-34,9 =2,5 √9,12/10+7,19/10 df = 10 +
- 129. Непараметрический критерий U-Манна-Уитни для двух независимых выборок Критерий предназначен для оценки различий между двумя выборками по
- 130. Нахождение критерия U-Манна-Уитни Ш а г 1. Значения двух выборок объединяются в один ряд и упорядочиваются.
- 131. Тема 12. Анализ различий между 2 группами зависимых выборок Параметрический критерий t-Стьюдента для двух зависимых выборок
- 132. Параметрический критерий t-Стьюдента для двух зависимых выборок Метод позволяет проверить гипотезу о том, что средние значения
- 133. Нахождение критерия t-Стьюдента для двух зависимых выборок Ша г 1. Эмпирическое значение критерия по формуле: средняя
- 134. Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп Критерий предназначен для оценки различий между двумя зависимыми
- 135. Нахождение непараметрического критерия Т-Уилкоксона Ш а г 1. Подсчитать разности значений для каждого объекта выборки (строка
- 136. Тема 13. Анализ различий между 3 и более группами независимых выборок Непараметрический критерий Н-Краскала-Уоллеса для сравнения
- 137. Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп Критерий Н-Краскала-Уоллеса позволяет проверять гипотезы о различии
- 138. Нахождение Н-Краскала-Уоллеса Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность каждого значения к выборке
- 139. Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок Критерий χ2-Фридмана позволяет проверять гипотезы о различии
- 140. Нахождение критерия χ2-Фридмана Шаг 1. Для каждого объекта условия ранжируются (по строке). Ш а г 2.
- 141. Тема 14. Дисперсионный анализ (ANOVA) Однофакторный дисперсионный анализ ANOVA Методы множественного сравнения
- 142. Дисперсионный анализ ANOVA (от англоязычного ANalysis Of VАriance) Анализ предназначен для изучения различий у трех и
- 143. Виды дисперсионного анализа (ANOVA\MANOVA) Однофакторный дисперсионный анализ Многофакторный дисперсионный анализ Дисперсионный анализ с повторными измерениями Многомерный
- 144. Метод однофакторного дисперсионного анализа применяется в тех случаях, когда исследуются изменения результативного признака под влиянием изменяющихся
- 145. Последовательность вычислений для ANOVA В общей изменчивости зависимой переменной выделяются основные ее составляющие. (В однофакторном ANOVA
- 146. Формулы расчетов однофакторного дисперсионного анализа
- 147. Нахождение однофакторного ANOVA Общее среднее: М= 7. Среднее для разных условий: М1 = 5; М2 =
- 148. Многофакторный дисперсионный анализ Многофакторный дисперсионный анализ предназначен для изучения влияния двух и более независимых переменных, с
- 149. Дисперсионный анализ с повторными измерениями Анализ позволяет проверить гипотезы о различии более двух зависимых выборок (повторных
- 150. Методы множественного сравнения
- 151. Тема 15. Многомерные методы Определение и классификация многомерных методов Регрессионный анализ (частный случай множественного регрессионного анализа)
- 152. Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания изучаемых явлений. ММ воспроизводят мыслительные
- 153. Классификация многомерных методов
- 154. Регрессионный анализ (частный случай множественного регрессионного анализа) Регрессионный анализ — основан на коэффициенте детерминации. Регрессионный анализ
- 155. Уравнение линейной регрессии Если переменные пропорциональны друг другу, то графически связь между ними можно представить в
- 156. Расчеты уравнения регрессии Пример: Школьникам была дана тестовая задача, которую им необходимо было решить, при этом
- 157. Множественный регрессионный анализ Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей -
- 158. Основными целями МРА являются Определение того, в какой мере «зависимая» переменная связана с совокупностью «независимых» переменных,
- 159. Дискриминантный анализ Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у) и нескольких других переменных
- 160. Основные результаты дискриминантного анализа Определение статистической значимости различения классов при помощи данного набора дискриминантных переменных. Показатели
- 161. Факторный анализ Главная цель факторного анализа — уменьшение размерности исходных данных. Результатом факторного анализа является переход
- 162. Основные этапы факторного анализа Выбор исходных данных. Предварительное решение проблемы числа факторов: используются критерий отсеивания Р.
- 163. Кластерный анализ Кластерный анализ — это процедура упорядочивания объектов в сравнительно однородные классы на основе попарного
- 164. Этапы кластерного анализа 1. Отбор объектов для кластеризации. Объектами могут быть, в зависимости от цели исследования:
- 165. Многомерное шкалирование Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества объектов Главная задача МШ
- 166. Основные этапы многомерного шкалирования Определение величины стресса (φ-Stress), который является показателем точности - наиболее приемлемый для
- 167. Тема 16. Математическое моделирование в психологии Системные подходы. Теория функциональных систем. Становление кибернетики. Системный анализ. Теория
- 168. Моделирование Моделирование — это претендующее на адекватность построение и описание образа или символа действительности, некоторого аспекта
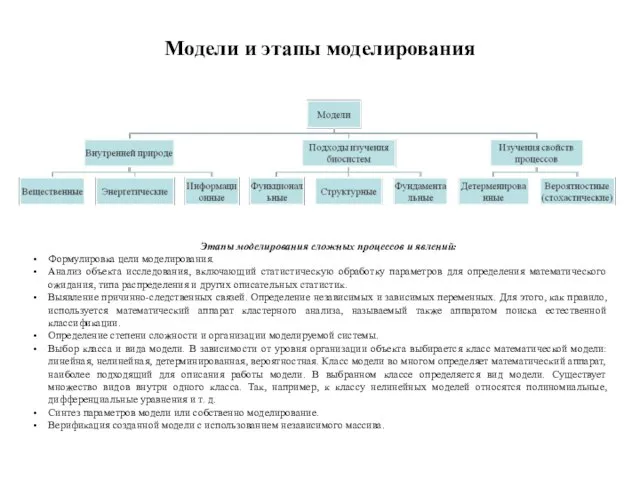
- 169. Модели и этапы моделирования Этапы моделирования сложных процессов и явлений: Формулировка цели моделирования. Анализ объекта исследования,
- 170. Психологические модели Модель И.П. Павлова И.П. Павлов выделяет целостный механизм анализатора включающий: периферическое, промежуточное и центральное
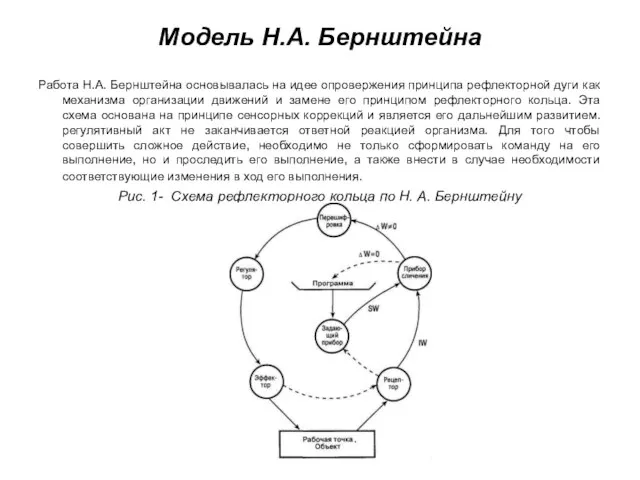
- 171. Модель Н.А. Бернштейна Работа Н.А. Бернштейна основывалась на идее опровержения принципа рефлекторной дуги как механизма организации
- 172. Модель К. Халла Американский ученый К. Халл рассматривал живой организм как саморегулируемую систему со специфическими механизмами
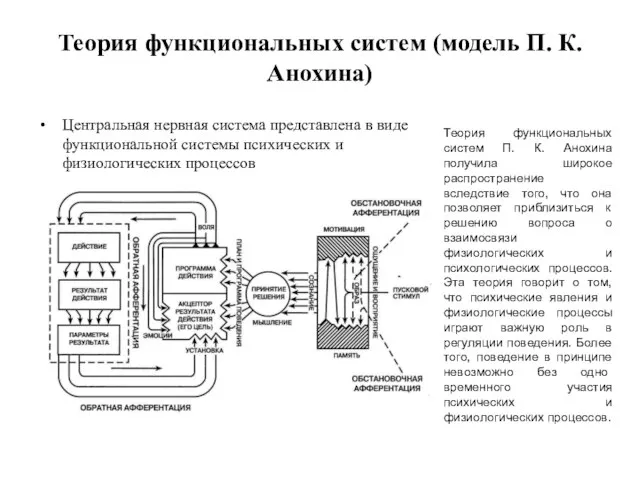
- 173. Теория функциональных систем (модель П. К. Анохина) Центральная нервная система представлена в виде функциональной системы психических
- 174. Модель А.Р. Лурии Так, А. Р. Лурия предложил выделить анатомически относительно автономные блоки головного мозга, обеспечивающие
- 175. Системный подход Система - множество элементов, находящихся в отношениях и связях друг с другом, которое образует
- 176. Кибернетика Н. Винера Появление кибернетики как самостоятельного научного направления относится к 1948 г., когда американский ученый,
- 177. Теория сигналов является центральной в кибернетике. Ее основными понятиями являются управляющий контур и информация. Управляющий контур
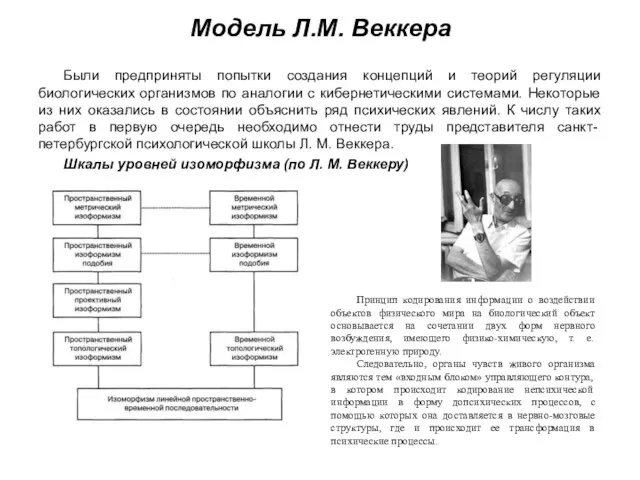
- 178. Модель Л.М. Веккера Были предприняты попытки создания концепций и теорий регуляции биологических организмов по аналогии с
- 179. Синергетика (Г. Хакена) Хакен Герман (Hermann Haken, род. 12 июля 1927 г.) — немецкий физик-теоретик, основатель
- 180. Общая теория систем Л. Фон Берталанфи Карл Людвиг фон Берталанфи (англ. Ludwig von Bertalanffy; 19 сентября
- 181. Теория развития И.Р. Пригожина Илья́ Рома́нович Приго́жин (фр. Ilya Prigogine; (12) 25 января 1917, Москва —
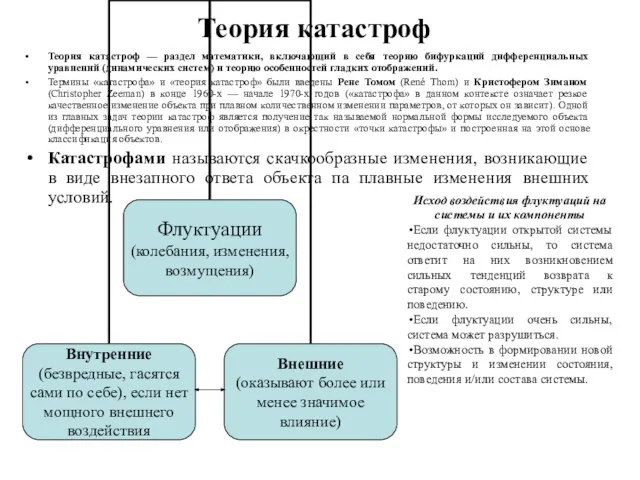
- 182. Теория катастроф Теория катастроф — раздел математики, включающий в себя теорию бифуркаций дифференциальных уравнений (динамических систем)
- 183. Системный анализ Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных объектов с учетом их
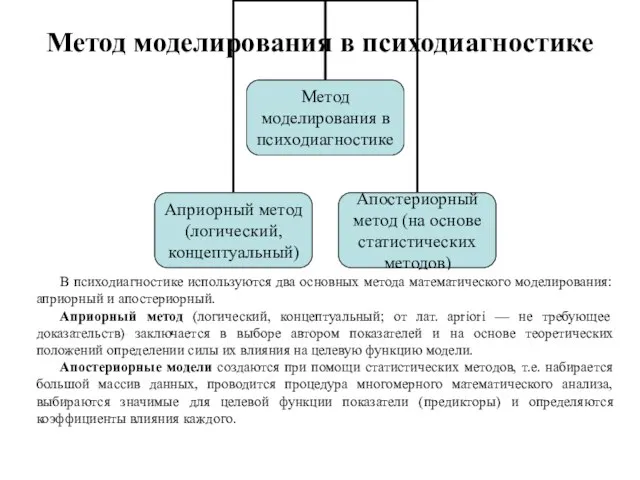
- 184. Метод моделирования в психодиагностике В психодиагностике используются два основных метода математического моделирования: априорный и апостериорный. Априорный
- 186. Скачать презентацию
Слайд 2Рекомендуемая литература
Ермолаев-Томин, О.Ю Математические методы в психологии. – М., 2013. – 511
Рекомендуемая литература
Ермолаев-Томин, О.Ю Математические методы в психологии. – М., 2013. – 511

Слайд 3Тема 1. Измерение в психологии
История возникновения
Предмет и назначение дисциплины
Измерение в психологии. Взаимоотношение
Тема 1. Измерение в психологии
История возникновения
Предмет и назначение дисциплины
Измерение в психологии. Взаимоотношение

Слайд 4 В первой четверти XIX в. философ И.Ф. Гербарт (1776-1841) провозгласил психологию
В первой четверти XIX в. философ И.Ф. Гербарт (1776-1841) провозгласил психологию



Слайд 7(William Sealy Gosset, 13 июня 1876, Кентербери — 16 октября 1937, Беконсфильд)
(William Sealy Gosset, 13 июня 1876, Кентербери — 16 октября 1937, Беконсфильд)

Слайд 8Определение статистики и связь с психологией и математикой
Термин «статистика» имеет несколько значений:
∙
Определение статистики и связь с психологией и математикой
Термин «статистика» имеет несколько значений:
∙

Слайд 9Слово «статистика» часто ассоциируется со словом «математика», и связывающее это понятие со
Слово «статистика» часто ассоциируется со словом «математика», и связывающее это понятие со

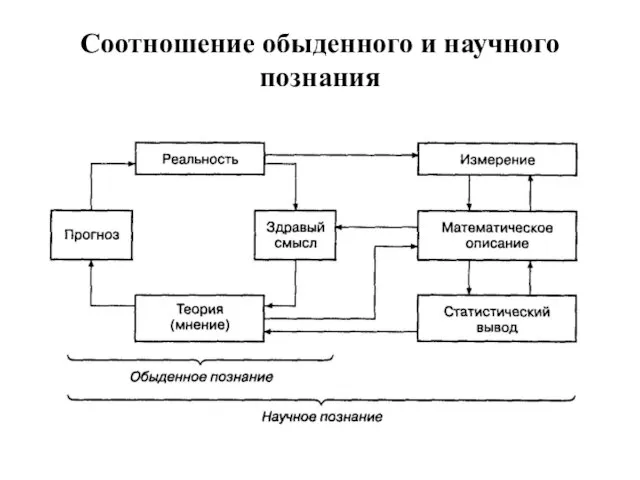
Слайд 10Соотношение обыденного и научного познания
Соотношение обыденного и научного познания
Слайд 11Основные задачи решаемые математическими методами в психологии
Подтверждение экспериментальных данных
Проверка валидности и
Основные задачи решаемые математическими методами в психологии
Подтверждение экспериментальных данных
Проверка валидности и

Слайд 12 Анализ данных на компьютере.
Использование MS Excel
Статистические пакеты: SPSS, STATISTICA.
Анализ данных на компьютере.
Использование MS Excel
Статистические пакеты: SPSS, STATISTICA.

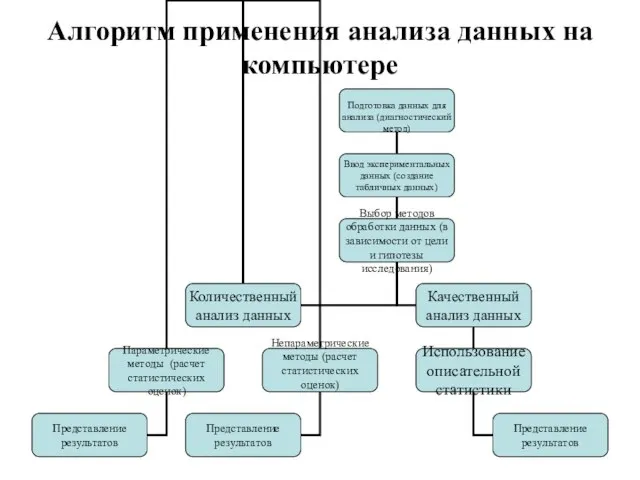
Слайд 13Алгоритм применения анализа данных на компьютере
Алгоритм применения анализа данных на компьютере
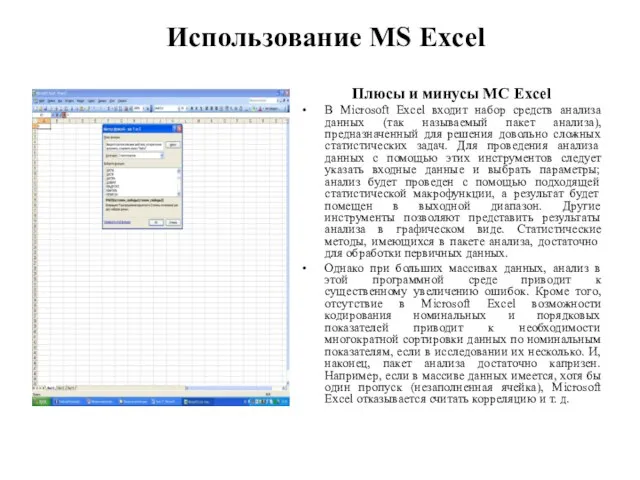
Слайд 14Использование MS Excel
Плюсы и минусы MC Excel
В Microsoft Excel входит набор
Использование MS Excel
Плюсы и минусы MC Excel
В Microsoft Excel входит набор
Слайд 15Статистические пакеты: SPSS, STATISTICA
STATISTICA for Windows представляет собой интегрированную систему статистического
Статистические пакеты: SPSS, STATISTICA
STATISTICA for Windows представляет собой интегрированную систему статистического

Слайд 16SPSS
Альтернативное программное обеспечение SPSS включает также все процедуры ввода, отбора и корректировки
SPSS
Альтернативное программное обеспечение SPSS включает также все процедуры ввода, отбора и корректировки

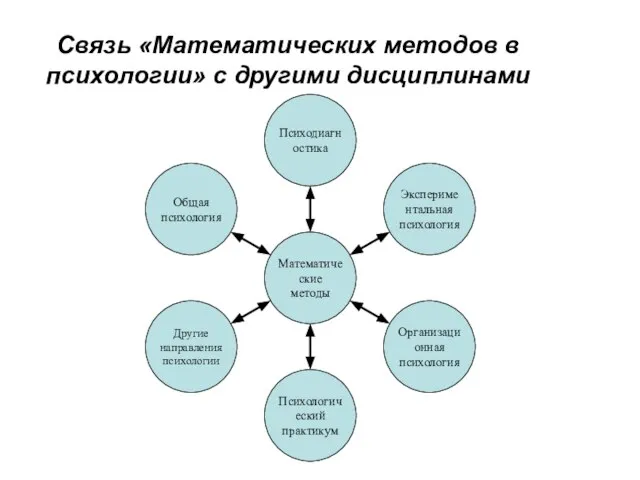
Слайд 17Связь «Математических методов в психологии» с другими дисциплинами
Связь «Математических методов в психологии» с другими дисциплинами
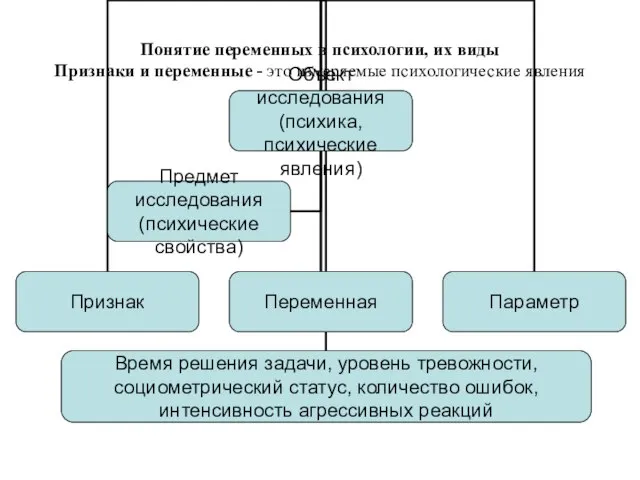
Слайд 18Понятие переменных в психологии, их виды
Признаки и переменные - это измеряемые
Понятие переменных в психологии, их виды Признаки и переменные - это измеряемые
Слайд 19Измерение — это приписывание объекту числа по определенному правилу. Это правило устанавливает
Измерение — это приписывание объекту числа по определенному правилу. Это правило устанавливает

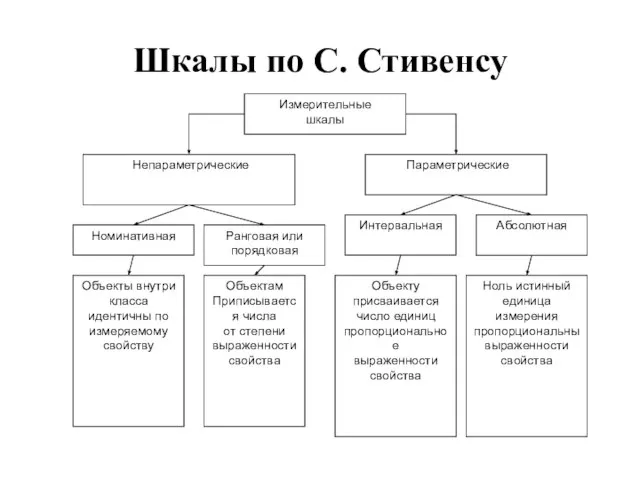
Слайд 20Шкалы по С. Стивенсу
Шкалы по С. Стивенсу
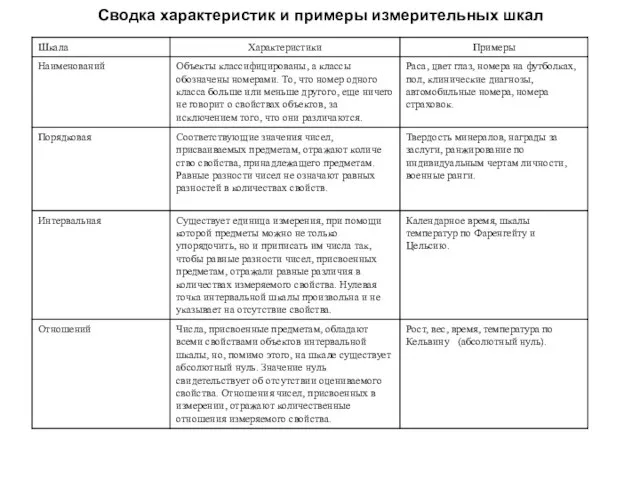
Слайд 21Сводка характеристик и примеры измерительных шкал
Сводка характеристик и примеры измерительных шкал
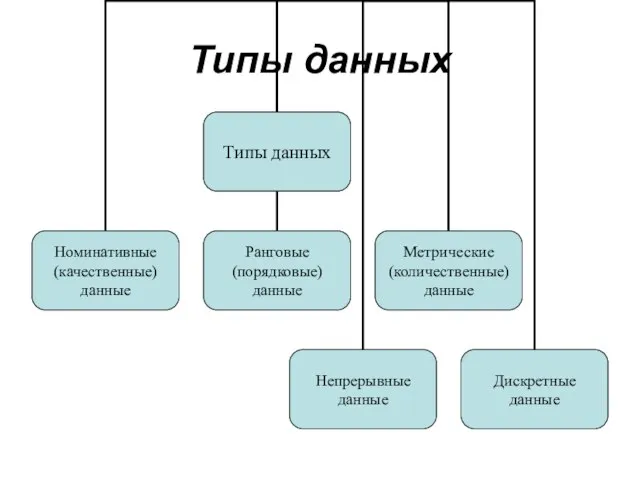
Слайд 22Типы данных
Типы данных
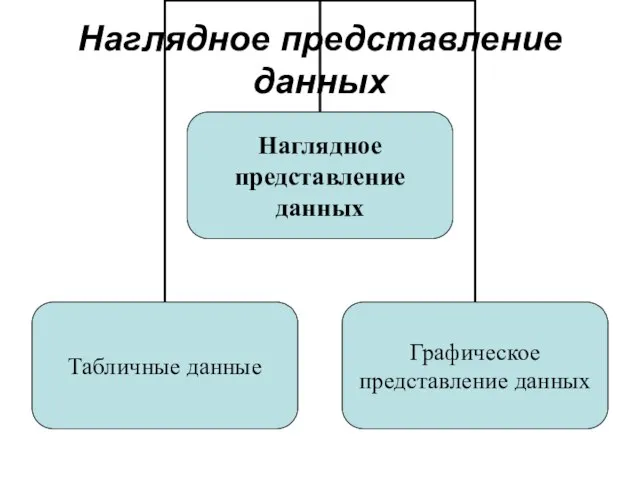
Слайд 23Наглядное представление данных
Наглядное представление данных
Слайд 24Графическое представление данных
В самом общем виде диаграммы делятся на:
1. Столбиковые:
Вертикальные;
Горизонтальные;
2. Линейные
Собственно линейные,
Ступенчатые,
Линейные
Графическое представление данных
В самом общем виде диаграммы делятся на:
1. Столбиковые:
Вертикальные;
Горизонтальные;
2. Линейные
Собственно линейные,
Ступенчатые,
Линейные

Слайд 25Правила графического оформления
Вся структура графика предполагает его чтение слева направо, вертикальные шкалы
Правила графического оформления
Вся структура графика предполагает его чтение слева направо, вертикальные шкалы

Слайд 26Правила табличного представления первичных данных
Вся структура таблицы предполагает ее чтение слева направо.
В
Правила табличного представления первичных данных
Вся структура таблицы предполагает ее чтение слева направо.
В

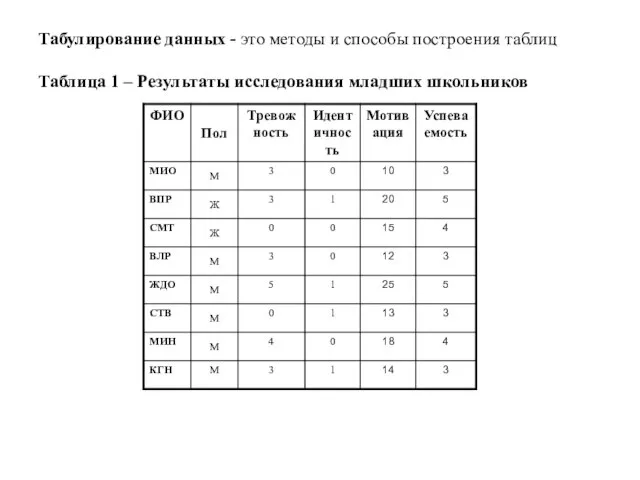
Слайд 27Табулирование данных - это методы и способы построения таблиц
Таблица 1 – Результаты
Табулирование данных - это методы и способы построения таблиц Таблица 1 – Результаты
Слайд 28Тема 2. Генеральная совокупность и выборка.
Понятие генеральной совокупности и выборки
Виды вероятностной
Тема 2. Генеральная совокупность и выборка.
Понятие генеральной совокупности и выборки
Виды вероятностной

Слайд 29Понятие генеральной совокупности и выборки
Генеральной совокупностью – называется всякая большая (конечная или
Понятие генеральной совокупности и выборки
Генеральной совокупностью – называется всякая большая (конечная или

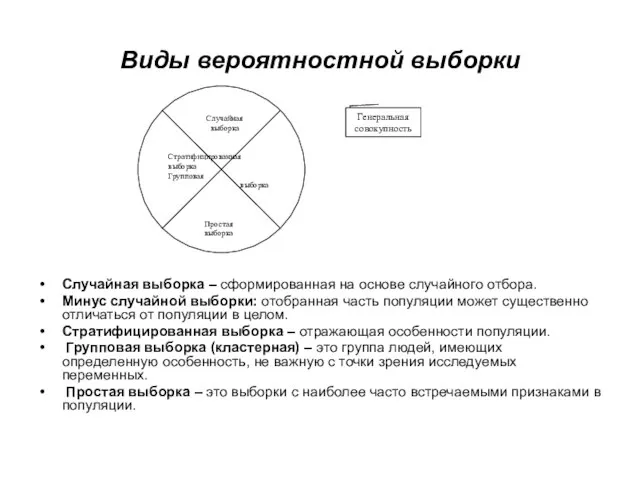
Слайд 30Виды вероятностной выборки
Случайная выборка – сформированная на основе случайного отбора.
Минус случайной выборки:
Виды вероятностной выборки
Случайная выборка – сформированная на основе случайного отбора.
Минус случайной выборки:
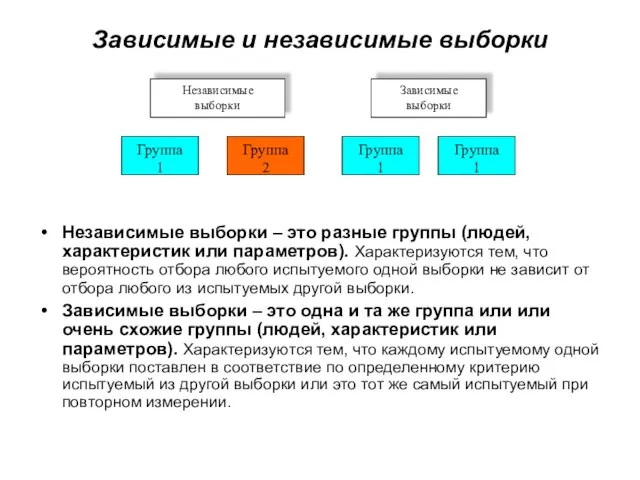
Слайд 31Зависимые и независимые выборки
Независимые выборки – это разные группы (людей, характеристик или
Зависимые и независимые выборки
Независимые выборки – это разные группы (людей, характеристик или
Слайд 32Объем выборки вычисляют, ориентируясь на несколько параметров:
1. Задачи и методы исследования.
Объем выборки вычисляют, ориентируясь на несколько параметров:
1. Задачи и методы исследования.

Слайд 33Объем выборки – определяется численностью входящих в нее элементов. Объем выборки зависит
Объем выборки – определяется численностью входящих в нее элементов. Объем выборки зависит

Слайд 34По схеме испытаний – выборки могут быть независимые и зависимые.
По объему
По схеме испытаний – выборки могут быть независимые и зависимые.
По объему

Слайд 35Тема 3.
Способы представления данных в психологии
Представление данных.
Понятие о квантилях.
Понятие о рангах.
Тема 3.
Способы представления данных в психологии
Представление данных.
Понятие о квантилях.
Понятие о рангах.

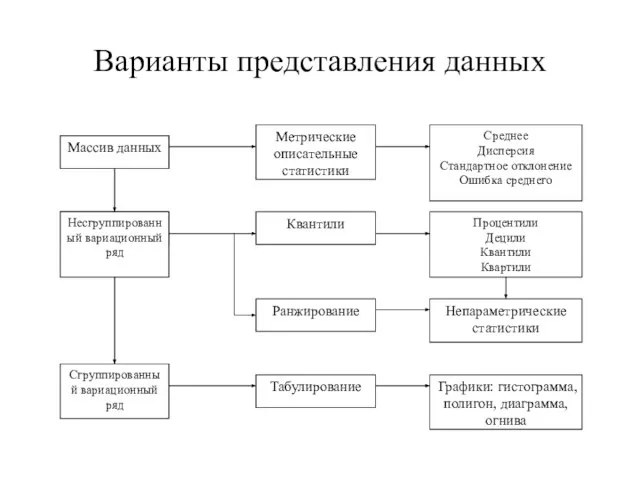
Слайд 36Представление данных в психологии бывает в виде:
Массив данных – первичные результаты измерения
Представление данных в психологии бывает в виде:
Массив данных – первичные результаты измерения

Слайд 37Варианты представления данных
Варианты представления данных
Слайд 38Меры положения – квантили
Квантиль — это точка на числовой оси измеренного признака,
Меры положения – квантили Квантиль — это точка на числовой оси измеренного признака,

Слайд 39Нахождение процентиля
Процентили указывают на относительное положение индивида в выборке стандартизации.
Р-й процентиль представляет
Нахождение процентиля
Процентили указывают на относительное положение индивида в выборке стандартизации.
Р-й процентиль представляет

Слайд 40Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов. В
Задача: Преподаватель предложил 125 учащимся контрольное задание, состоящее из 40 вопросов. В

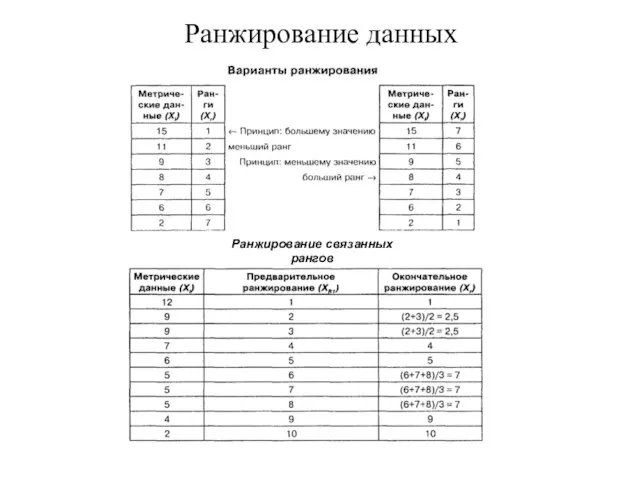
Слайд 41Ранговый порядок
Ранжирование – это приписывание объектам чисел в зависимости от степени
Ранговый порядок Ранжирование – это приписывание объектам чисел в зависимости от степени

Слайд 42Ранжирование данных
Ранжирование связанных рангов
Ранжирование данных
Ранжирование связанных рангов
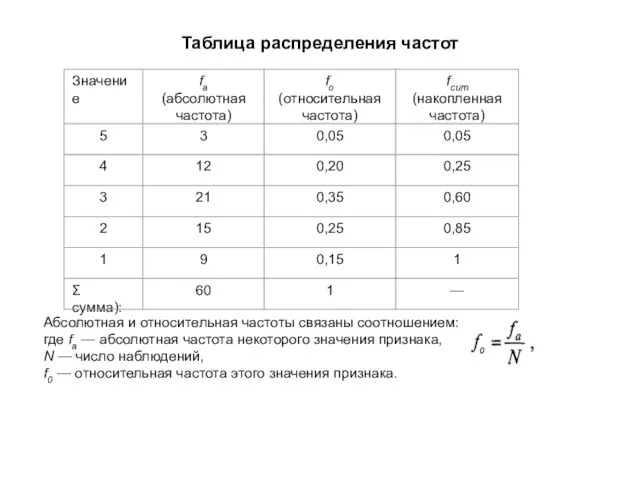
Слайд 43Распределение частот
Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько раз
Распределение частот
Абсолютная частота распределения (fa ) - называется частота. указывающая, сколько раз

Слайд 44Таблица распределения частот
Абсолютная и относительная частоты связаны соотношением:
где fa — абсолютная частота
Таблица распределения частот
Абсолютная и относительная частоты связаны соотношением:
где fa — абсолютная частота
Слайд 45Этапы построения распределения сгруппированных частот
Уточнение лимитов (крайних значений интервала) – производится округление
Этапы построения распределения сгруппированных частот
Уточнение лимитов (крайних значений интервала) – производится округление

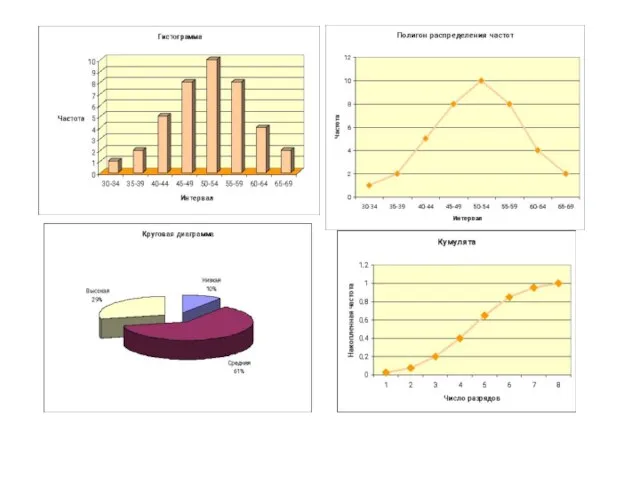
Слайд 46Графическое представление
Гистограмма – это последовательность столбцов, каждый из которых опирается на
Графическое представление
Гистограмма – это последовательность столбцов, каждый из которых опирается на

Слайд 48Тема 4. Меры центральной тенденции
Определение меры центральной тенденции;
Мода;
Медиана;
Среднее;
Выбор и особенности мер центральной
Тема 4. Меры центральной тенденции
Определение меры центральной тенденции;
Мода;
Медиана;
Среднее;
Выбор и особенности мер центральной

Слайд 49Меры центральной тенденции - предназначены для замены множества значений признака, измеренного на
Меры центральной тенденции - предназначены для замены множества значений признака, измеренного на
Слайд 50Мода (Mode) — это такое значение из множества измерений, которое встречается наиболее
Мода (Mode) — это такое значение из множества измерений, которое встречается наиболее

Слайд 51Медиана (Median) — это такое значение признака, которое делит упорядоченное множество данных
Медиана (Median) — это такое значение признака, которое делит упорядоченное множество данных

Слайд 52Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как сумма
Среднее (Mean) (М — выборочное среднее, среднее арифметическое) — определяется как сумма

Слайд 53Выбор и особенности мер центральной тенденции
Для номинативных данных единственной подходящей мерой центральной
Выбор и особенности мер центральной тенденции
Для номинативных данных единственной подходящей мерой центральной

Слайд 54Графическое соотношение среднего, моды, медианы
Графическое соотношение среднего, моды, медианы
Слайд 55Сравнение преимуществ и ограничений мер центральной тенденции
Сравнение преимуществ и ограничений мер центральной тенденции
Слайд 56Тема 5. Меры изменчивости
Понятие меры изменчивости
Лимиты. Размах вариации и его разновидности.
Дисперсия и
Тема 5. Меры изменчивости
Понятие меры изменчивости
Лимиты. Размах вариации и его разновидности.
Дисперсия и

Слайд 57Меры изменчивости
Меры изменчивости
Слайд 58Меры рассеяния
независящие от распределения
Лимиты – это характеристики, определяющие верхнюю (max) и нижнюю
Меры рассеяния
независящие от распределения
Лимиты – это характеристики, определяющие верхнюю (max) и нижнюю

Слайд 59Меры рассеяния
характеризующие нормальное распределение
Дисперсия (Variance) — мера изменчивости для метрических данных, пропорциональная
Меры рассеяния
характеризующие нормальное распределение
Дисперсия (Variance) — мера изменчивости для метрических данных, пропорциональная

Слайд 60Расчет дисперсии
Расчет дисперсии

Слайд 61Меры рассеяния
характеризующие нормальное распределение
Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) — положительное
Меры рассеяния
характеризующие нормальное распределение
Стандартное отклонение (Std. deviation) (сигма, среднеквадратическое отклонение) — положительное

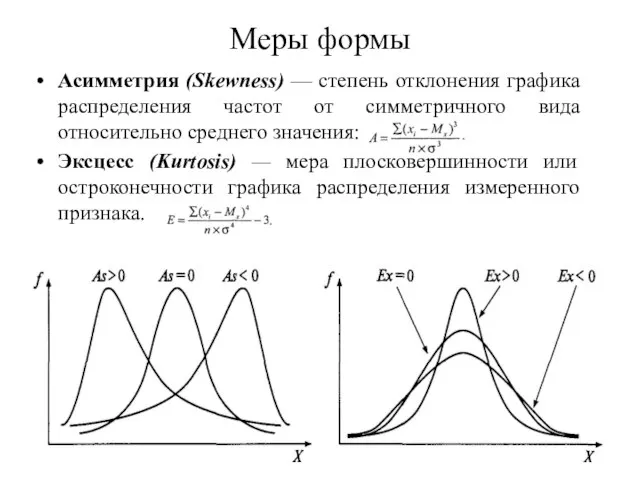
Слайд 62Меры формы
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида
Меры формы
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида
Слайд 63Тема 6. Стандартизация данных
Понятие стандартизации данных.
Основные формы стандартизации.
z-преобразование данных.
Тема 6. Стандартизация данных
Понятие стандартизации данных.
Основные формы стандартизации.
z-преобразование данных.

Слайд 64Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры и
Стандартизация (англ. standard нормальный) — унификация, приведение к единым нормативам процедуры и

Слайд 65Преобразование первичных оценок в новую шкалу
Центрирование – это линейная трансформация величин признака,
Преобразование первичных оценок в новую шкалу
Центрирование – это линейная трансформация величин признака,

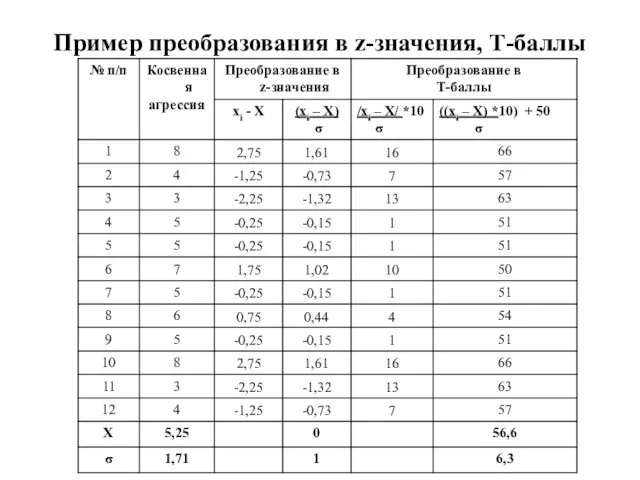
Слайд 66Пример преобразования в z-значения, Т-баллы
Пример преобразования в z-значения, Т-баллы
Слайд 67Тема 7. Теоретические распределения, используемые при статистических выводах
Нормальное распределение
Единичное нормальное распределение
Тема 7. Теоретические распределения, используемые при статистических выводах
Нормальное распределение
Единичное нормальное распределение

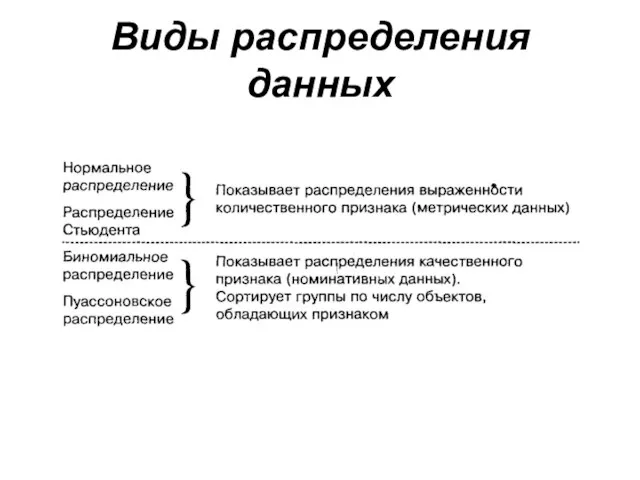
Слайд 68Виды распределения данных
Виды распределения данных
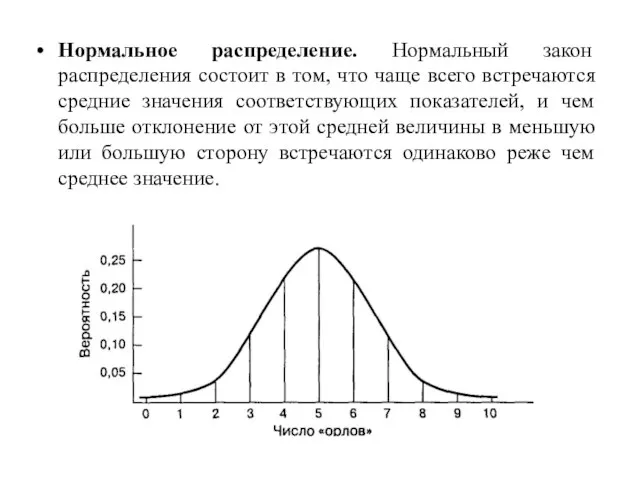
Слайд 69Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего встречаются
Нормальное распределение. Нормальный закон распределения состоит в том, что чаще всего встречаются
Слайд 70Единичное нормальное распределение и его свойства
Если применить z-преобразование ко всем возможным
Единичное нормальное распределение и его свойства
Если применить z-преобразование ко всем возможным

Слайд 71Свойства единичного нормального распределения
□ Единицей измерения единичного нормального распределения является стандартное отклонение.
□
Свойства единичного нормального распределения
□ Единицей измерения единичного нормального распределения является стандартное отклонение.
□
Слайд 72Соответствия между диапазонами значений и площадью под кривой
М± σ соответствует ≈ 68%
Соответствия между диапазонами значений и площадью под кривой
М± σ соответствует ≈ 68%
Слайд 73Проверка нормальности распределения
1. Нормальность распределения результативного признака можно проверить путем расчета показателей
Проверка нормальности распределения
1. Нормальность распределения результативного признака можно проверить путем расчета показателей

Слайд 742. Еще одним из критериев проверки на нормальность - является критерий Колмагорова-Смирнова.
2. Еще одним из критериев проверки на нормальность - является критерий Колмагорова-Смирнова.

Слайд 75Биноминальное распределение
Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень вероятности.
Биноминальное распределение
Биноминальное распределение связано со случайными событиями, имеющими определенную постоянную степень вероятности.
Слайд 76Распределение Пуассона
Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в отдельных
Распределение Пуассона
Распределение Пуассона описывает случайные (редкие) события, вероятность появления которых в отдельных

Слайд 77Тема 8. Статистическое оценивание и проверка гипотез
Статистические гипотезы.
Статистический вывод.
Ошибки 1 и
Тема 8. Статистическое оценивание и проверка гипотез
Статистические гипотезы.
Статистический вывод.
Ошибки 1 и

Слайд 78Этапы статистического вывода
Этапы статистического вывода
Слайд 79Различают научные и статистические гипотезы.
Научные гипотезы (предположение) формулируются как предполагаемое решение
Различают научные и статистические гипотезы.
Научные гипотезы (предположение) формулируются как предполагаемое решение

Слайд 80Нулевая гипотеза - это гипотеза об отсутствии различий, взаимосвязи. Она обозначается как
Нулевая гипотеза - это гипотеза об отсутствии различий, взаимосвязи. Она обозначается как
Слайд 81Алгоритм проверки статистических гипотез
Обоснование применения критерия.
Выполнение ограничений (если есть).
Формулирование статистических гипотез
Алгоритм проверки статистических гипотез
Обоснование применения критерия.
Выполнение ограничений (если есть).
Формулирование статистических гипотез

Слайд 82Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level).
Величину называют
Статистическая значимость (Significant level, сокращенно Sig.), или р-уровень значимости (p-level).
Величину называют

Слайд 83Схема определения р – уровня
Свойства статистической значимости
Чем меньше значение р-уровня, тем выше
Схема определения р – уровня
Свойства статистической значимости
Чем меньше значение р-уровня, тем выше
Слайд 84Ошибки 1 и 2 рода
Ошибка I рода - ошибка, состоящая в
Ошибки 1 и 2 рода
Ошибка I рода - ошибка, состоящая в

Слайд 85Степень свободы
Число степеней свободы – это количество возможных направлений изменчивости признака.
Степень свободы
Число степеней свободы – это количество возможных направлений изменчивости признака.

Слайд 86Показатели степеней свободы для зависимых и независимых выборок
Если имеются две независимые выборки,
Показатели степеней свободы для зависимых и независимых выборок
Если имеются две независимые выборки,

Слайд 87Статистический критерий
Статистический критерий – это решающее правило, обеспечивающее надежное поведение, т.е.
Статистический критерий
Статистический критерий – это решающее правило, обеспечивающее надежное поведение, т.е.

Слайд 88Параметрические и непараметрические критерии
Параметрические критерии – это группа статистических критериев, которые включают
Параметрические и непараметрические критерии
Параметрические критерии – это группа статистических критериев, которые включают

Слайд 89Основание выбора критерия
а) простота;
б) более широкий диапазон использования (например, по отношению к
Основание выбора критерия
а) простота;
б) более широкий диапазон использования (например, по отношению к

Слайд 90Алгоритм работы с критериями
1. Обоснование применения критерия.
2. Выполнение ограничений критерия (если они есть).
3. Выдвижение статистических
Алгоритм работы с критериями
1. Обоснование применения критерия.
2. Выполнение ограничений критерия (если они есть).
3. Выдвижение статистических

Слайд 91Статистический вывод — это формулирование вывода на основе статистической значимости.
Результатом статистического
Статистический вывод — это формулирование вывода на основе статистической значимости.
Результатом статистического

Слайд 92Тема 9. Меры связи
Понятие корреляции.
Диаграмма рассеяния.
Классификация коэффициентов корреляции.
Корреляционные матрицы.
Интерпретация коэффициентов
Тема 9. Меры связи
Понятие корреляции.
Диаграмма рассеяния.
Классификация коэффициентов корреляции.
Корреляционные матрицы.
Интерпретация коэффициентов

Слайд 93Понятие корреляции и ее основные параметры
Корреляционная связь – это согласованное изменение двух
Понятие корреляции и ее основные параметры
Корреляционная связь – это согласованное изменение двух

Слайд 94Классификация мер связи
Классификация мер связи

Слайд 95Алгоритм выбора коэффициента корреляции
Алгоритм выбора коэффициента корреляции
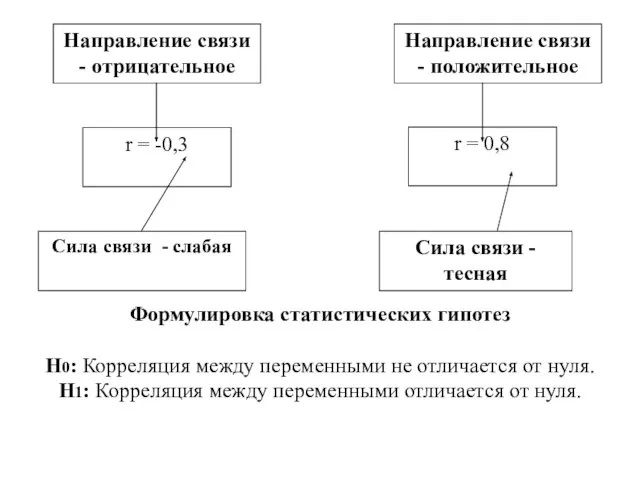
Слайд 97Формулировка статистических гипотез
Н0: Корреляция между переменными не отличается от нуля.
Н1: Корреляция
Формулировка статистических гипотез
Н0: Корреляция между переменными не отличается от нуля.
Н1: Корреляция
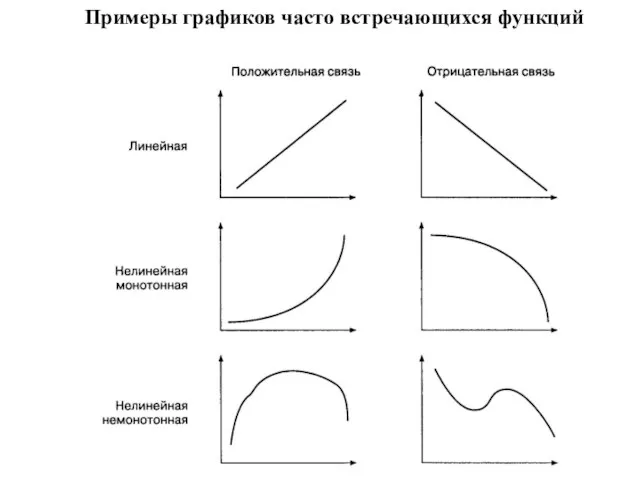
Слайд 98Виды связей
Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически
Виды связей
Взаимосвязи на языке математики обычно описываются при помощи функций, которые графически

Слайд 99Примеры графиков часто встречающихся функций
Примеры графиков часто встречающихся функций
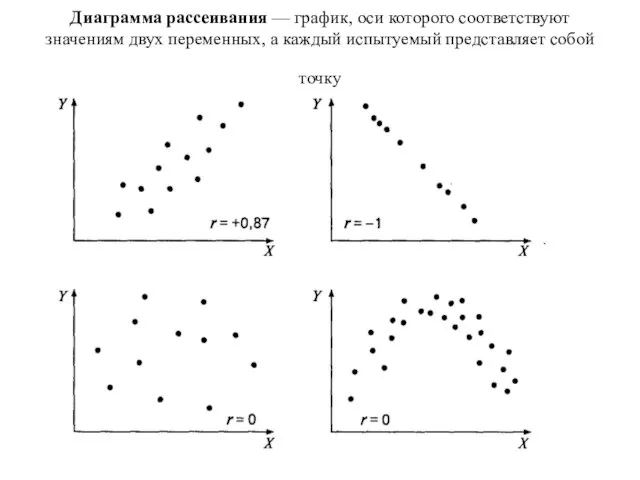
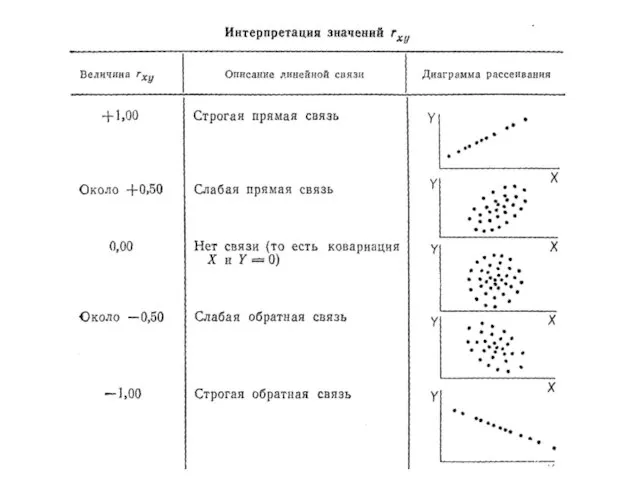
Слайд 100Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а каждый
Диаграмма рассеивания — график, оси которого соответствуют значениям двух переменных, а каждый
Слайд 102Классификация мер связи
Классификация мер связи
Слайд 103Графическое представление данных корреляционного анализа
Поле рассеяния и Корреляционная плеяда
Графическое представление данных корреляционного анализа
Поле рассеяния и Корреляционная плеяда
Слайд 104Представление данных корреляционного анализа
Построение корреляционных матриц и их анализ
1 вид
Представление данных корреляционного анализа
Построение корреляционных матриц и их анализ
1 вид
Слайд 105Коэффициент корреляции rxy- Пирсона
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух
Коэффициент корреляции rxy- Пирсона
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух

Слайд 106Нахождение коэффициента корреляции rxy-Пирсона
rxy = 25,6 = 0,57 р ≤ 0,01
1,735
Нахождение коэффициента корреляции rxy-Пирсона rxy = 25,6 = 0,57 р ≤ 0,01 1,735
Слайд 107Поле рассеяния
Поле рассеяния

Слайд 109
Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла
Коэффициенты ранговой корреляции: r-Спирмена или ι-Кенделла
Коэффициенты ранговой корреляции rs-Спирмена и ι-Кендалла
Коэффициенты ранговой корреляции: r-Спирмена или ι-Кенделла

Слайд 110Нахождение коэффициента корреляции rs-Спирмена
rs = 1 – 6*474 = - 0,65
Нахождение коэффициента корреляции rs-Спирмена rs = 1 – 6*474 = - 0,65
Слайд 111Формула ι-Кенделла :
Пояснения к формуле
Р — общее число совпадений.
Q — общее
Формула ι-Кенделла :
Пояснения к формуле
Р — общее число совпадений.
Q — общее

Слайд 112Нахождение коэффициента корреляции ι-Кенделла
ι = 21-7 = 0,5 р = 0,08
Нахождение коэффициента корреляции ι-Кенделла ι = 21-7 = 0,5 р = 0,08
Слайд 113Тема 10. Анализ качественных признаков (номинативных данных)
Корреляция номинативных данных
критерий χ2-Пирсона
Корреляция бинарных данных
фи-коэффициент
Тема 10. Анализ качественных признаков (номинативных данных)
Корреляция номинативных данных
критерий χ2-Пирсона
Корреляция бинарных данных
фи-коэффициент

Слайд 114Анализ качественных признаков (номинативных данных)
Анализ качественных признаков (номинативных данных)
Слайд 115Корреляция номинативных данных
критерий χ2-Пирсона
Критерий χ2-Пирсона применяется если обе переменные представлены в номинативной
Корреляция номинативных данных
критерий χ2-Пирсона
Критерий χ2-Пирсона применяется если обе переменные представлены в номинативной

Слайд 116Нахождение критерия χ2-Пирсона
Теоретические частоты fe женский и синий = 4 x 8
Нахождение критерия χ2-Пирсона
Теоретические частоты fe женский и синий = 4 x 8
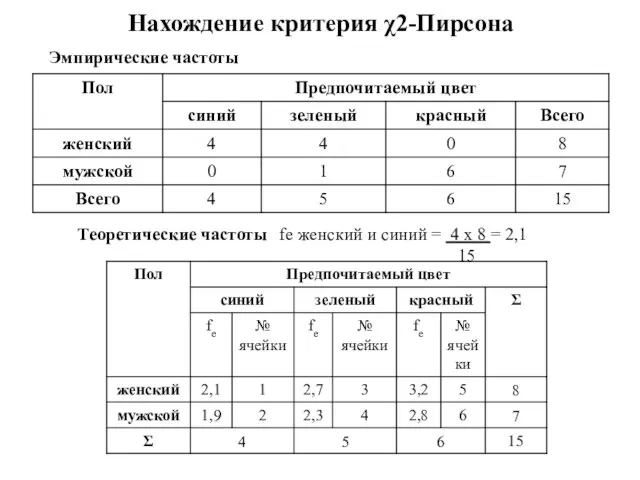
Слайд 117Нахождение критерия χ2-Пирсона
Расчет
χ2= 11,8
k = 3; j = 2; df =
Нахождение критерия χ2-Пирсона
Расчет
χ2= 11,8
k = 3; j = 2; df =

Слайд 118Корреляция бинарных данных
фи-коэффициент сопряженности Пирсона
Коэффициент сопряженности φ-Пирсона применяется если обе переменные представлены
Корреляция бинарных данных
фи-коэффициент сопряженности Пирсона
Коэффициент сопряженности φ-Пирсона применяется если обе переменные представлены

Слайд 119Нахождение коэффициента сопряженности φ-Пирсона
Нахождение коэффициента сопряженности φ-Пирсона
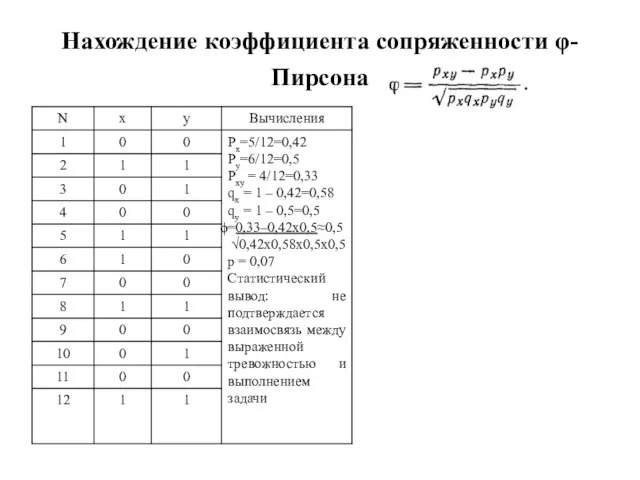
Слайд 120Тема 11. Анализ различий между 2 группами независимых выборок
Классификация методов сравнения
Представление данных
Тема 11. Анализ различий между 2 группами независимых выборок
Классификация методов сравнения
Представление данных

Слайд 121Классификация методов сравнения
Классификация методов сравнения
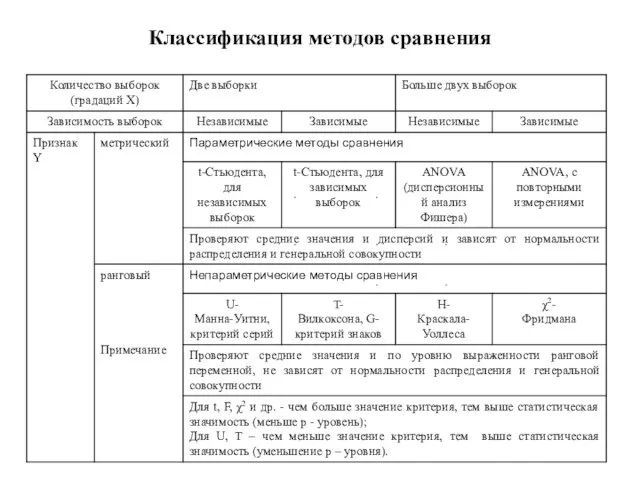
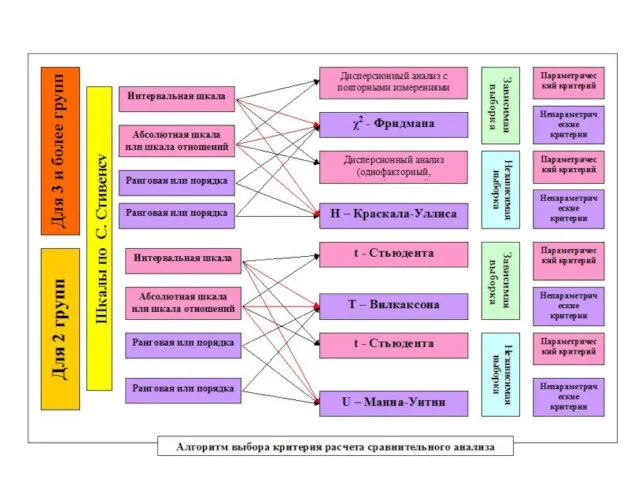
Слайд 123Методы сравнения
В зависимости от решаемых задач методы внутри этой группы классифицируются по
Методы сравнения
В зависимости от решаемых задач методы внутри этой группы классифицируются по

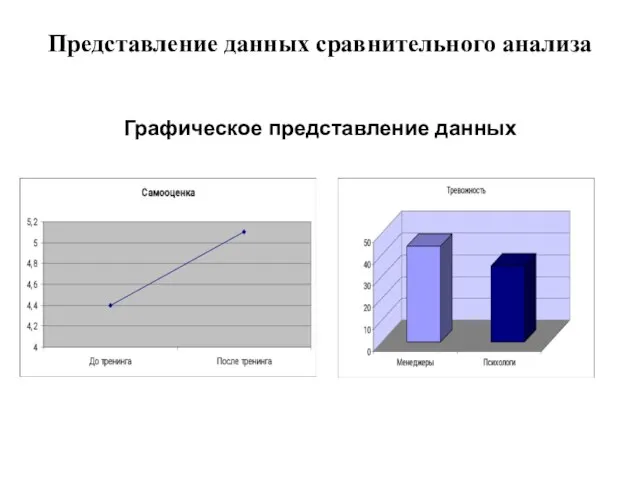
Слайд 124Представление данных сравнительного анализа
Графическое представление данных
Представление данных сравнительного анализа
Графическое представление данных
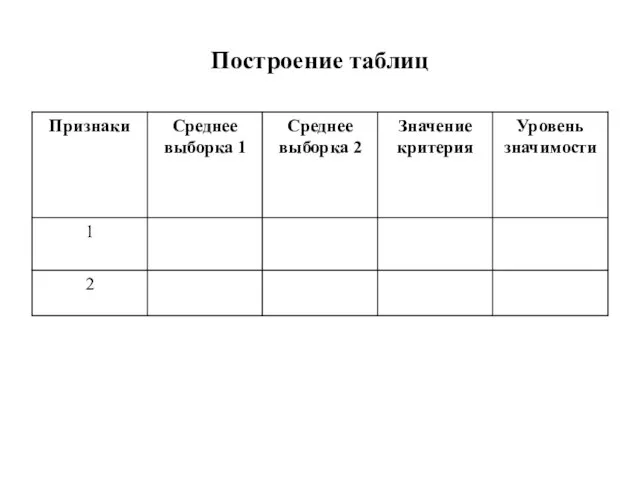
Слайд 125Построение таблиц
Построение таблиц
Слайд 126Параметрический критерий t-Стьюдента для двух независимых выборок
Метод позволяет проверить гипотезу о
Параметрический критерий t-Стьюдента для двух независимых выборок
Метод позволяет проверить гипотезу о

Слайд 127Параметрический критерий сравнения 2 групп (зависимых и независимых) t-Стьюдента
Данный критерий был разработан
Параметрический критерий сравнения 2 групп (зависимых и независимых) t-Стьюдента
Данный критерий был разработан

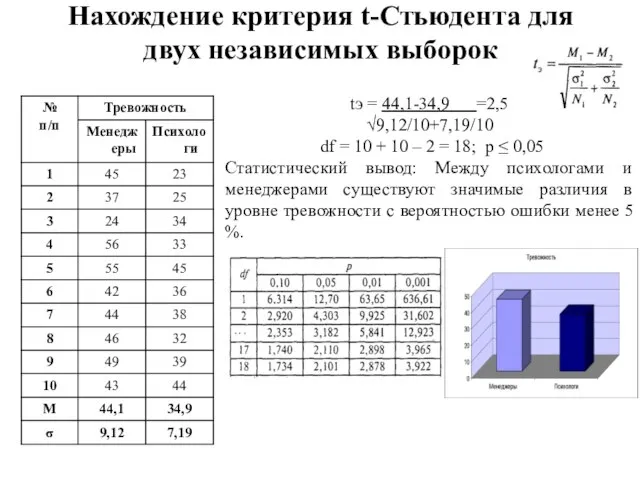
Слайд 128Нахождение критерия t-Стьюдента для двух независимых выборок
tэ = 44,1-34,9 =2,5
√9,12/10+7,19/10
df
Нахождение критерия t-Стьюдента для двух независимых выборок
tэ = 44,1-34,9 =2,5
√9,12/10+7,19/10
df
Слайд 129Непараметрический критерий U-Манна-Уитни для двух независимых выборок
Критерий предназначен для оценки различий между
Непараметрический критерий U-Манна-Уитни для двух независимых выборок
Критерий предназначен для оценки различий между

Слайд 130Нахождение критерия U-Манна-Уитни
Ш а г 1. Значения двух выборок объединяются в один
Нахождение критерия U-Манна-Уитни
Ш а г 1. Значения двух выборок объединяются в один

Слайд 131Тема 12. Анализ различий между 2 группами зависимых выборок
Параметрический критерий t-Стьюдента для
Тема 12. Анализ различий между 2 группами зависимых выборок
Параметрический критерий t-Стьюдента для

Слайд 132Параметрический критерий t-Стьюдента для двух зависимых выборок
Метод позволяет проверить гипотезу о том,
Параметрический критерий t-Стьюдента для двух зависимых выборок
Метод позволяет проверить гипотезу о том,

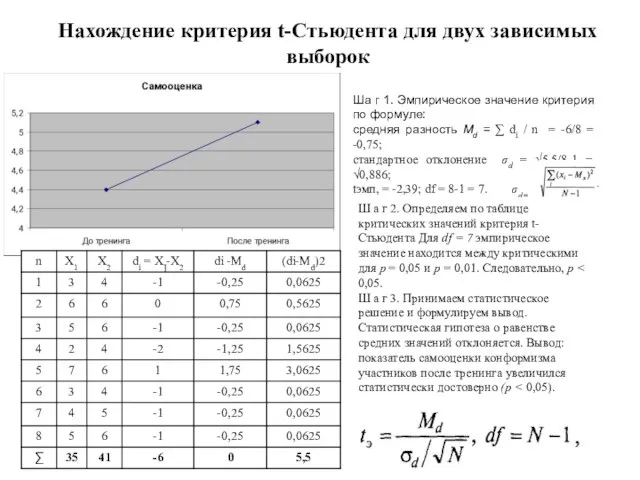
Слайд 133Нахождение критерия t-Стьюдента для двух зависимых выборок
Ша г 1. Эмпирическое значение критерия
Нахождение критерия t-Стьюдента для двух зависимых выборок
Ша г 1. Эмпирическое значение критерия
Слайд 134Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп
Критерий предназначен для оценки различий
Непараметрический критерий Т-Уилкоксона для сравнения двух зависимых групп
Критерий предназначен для оценки различий

Слайд 135Нахождение непараметрического критерия Т-Уилкоксона
Ш а г 1. Подсчитать разности значений для каждого
Нахождение непараметрического критерия Т-Уилкоксона
Ш а г 1. Подсчитать разности значений для каждого
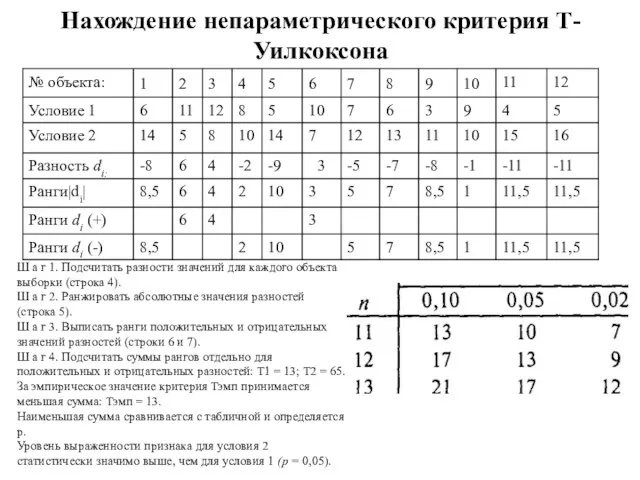
Слайд 136Тема 13. Анализ различий между 3 и более группами независимых выборок
Непараметрический критерий
Тема 13. Анализ различий между 3 и более группами независимых выборок
Непараметрический критерий

Слайд 137Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп
Критерий Н-Краскала-Уоллеса позволяет проверять
Непараметрический критерий Н-Краскала-Уоллеса для сравнения 3 и более групп
Критерий Н-Краскала-Уоллеса позволяет проверять

Слайд 138Нахождение Н-Краскала-Уоллеса
Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность каждого
Нахождение Н-Краскала-Уоллеса
Шаг 1. Значения объединяются в один упорядоченный ряд. Обозначается принадлежность каждого

Слайд 139Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок
Критерий χ2-Фридмана позволяет
Критерий χ2-Фридмана для сравнение 3-х и более зависимых выборок
Критерий χ2-Фридмана позволяет

Слайд 140Нахождение критерия χ2-Фридмана
Шаг 1. Для каждого объекта условия ранжируются (по строке).
Ш
Нахождение критерия χ2-Фридмана
Шаг 1. Для каждого объекта условия ранжируются (по строке).
Ш

Слайд 141Тема 14. Дисперсионный анализ (ANOVA)
Однофакторный дисперсионный анализ ANOVA
Методы множественного сравнения
Тема 14. Дисперсионный анализ (ANOVA)
Однофакторный дисперсионный анализ ANOVA
Методы множественного сравнения

Слайд 142Дисперсионный анализ ANOVA
(от англоязычного ANalysis Of VАriance)
Анализ предназначен для изучения
Дисперсионный анализ ANOVA
(от англоязычного ANalysis Of VАriance)
Анализ предназначен для изучения

Слайд 143Виды дисперсионного анализа (ANOVA\MANOVA)
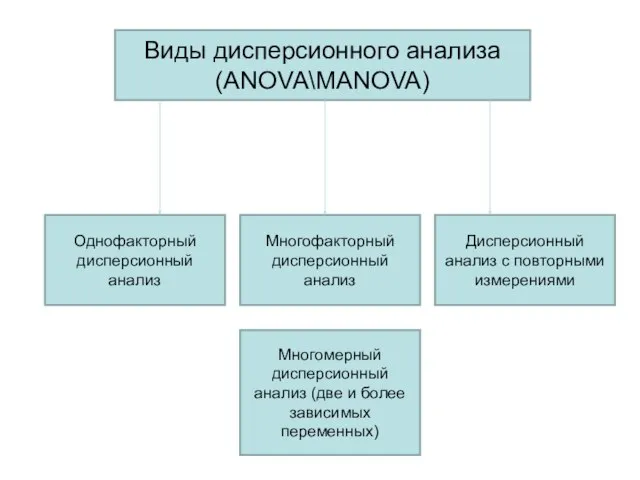
Однофакторный дисперсионный анализ
Многофакторный дисперсионный анализ
Дисперсионный анализ с повторными измерениями
Многомерный
Виды дисперсионного анализа (ANOVA\MANOVA)
Однофакторный дисперсионный анализ
Многофакторный дисперсионный анализ
Дисперсионный анализ с повторными измерениями
Многомерный
Слайд 144Метод однофакторного дисперсионного анализа применяется в тех случаях, когда исследуются изменения результативного
Метод однофакторного дисперсионного анализа применяется в тех случаях, когда исследуются изменения результативного

Слайд 145Последовательность вычислений для ANOVA
В общей изменчивости зависимой переменной выделяются основные ее
Последовательность вычислений для ANOVA
В общей изменчивости зависимой переменной выделяются основные ее

Слайд 146Формулы расчетов однофакторного дисперсионного анализа
Формулы расчетов однофакторного дисперсионного анализа

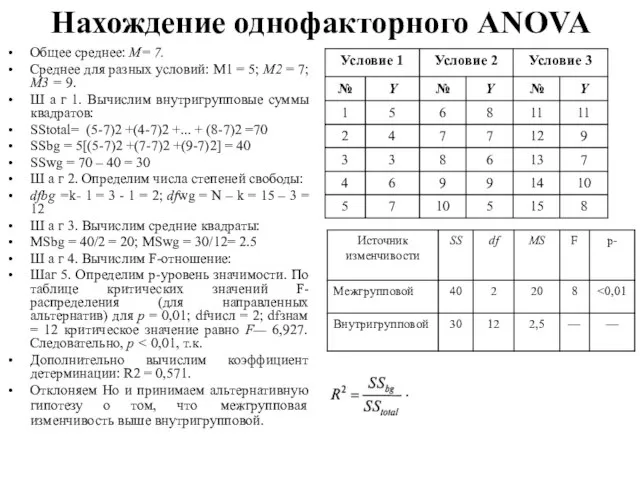
Слайд 147Нахождение однофакторного ANOVA
Общее среднее: М= 7.
Среднее для разных условий: М1 = 5;
Нахождение однофакторного ANOVA
Общее среднее: М= 7.
Среднее для разных условий: М1 = 5;
Слайд 148Многофакторный дисперсионный анализ
Многофакторный дисперсионный анализ предназначен для изучения влияния двух и более
Многофакторный дисперсионный анализ
Многофакторный дисперсионный анализ предназначен для изучения влияния двух и более

Слайд 149
Дисперсионный анализ с повторными измерениями
Анализ позволяет проверить гипотезы о различии более
Дисперсионный анализ с повторными измерениями
Анализ позволяет проверить гипотезы о различии более

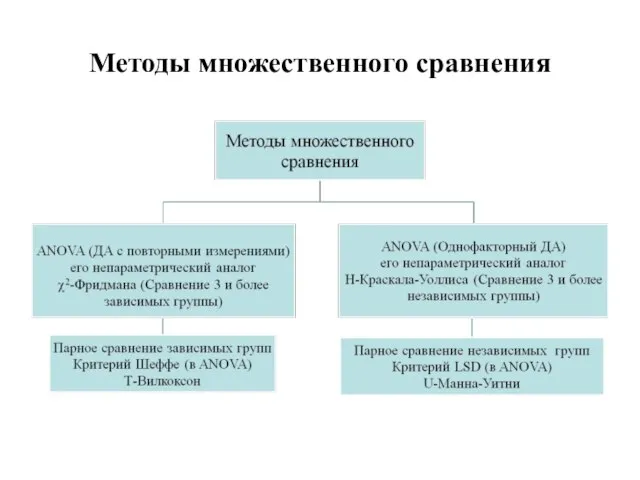
Слайд 150Методы множественного сравнения
Методы множественного сравнения
Слайд 151Тема 15. Многомерные методы
Определение и классификация многомерных методов
Регрессионный анализ (частный случай множественного
Тема 15. Многомерные методы
Определение и классификация многомерных методов
Регрессионный анализ (частный случай множественного

Слайд 152
Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания изучаемых
Многомерные методы - это математические модели в отношении многостороннего (многомерного) описания изучаемых

Слайд 153Классификация многомерных методов
Классификация многомерных методов
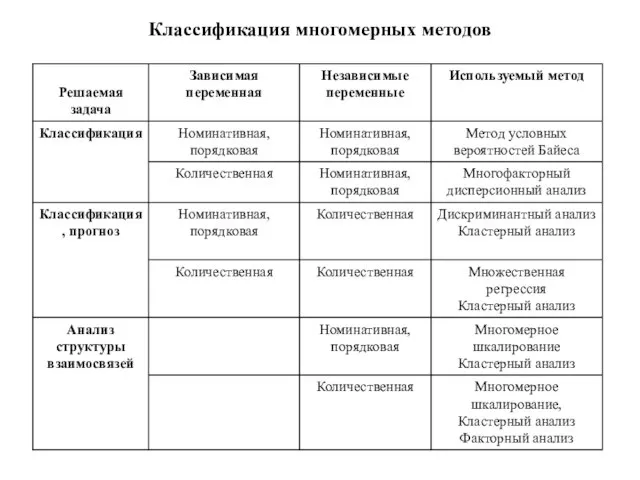
Слайд 154Регрессионный анализ (частный случай множественного регрессионного анализа)
Регрессионный анализ — основан на коэффициенте
Регрессионный анализ (частный случай множественного регрессионного анализа)
Регрессионный анализ — основан на коэффициенте

Слайд 155Уравнение линейной регрессии
Если переменные пропорциональны друг другу, то графически связь между
Уравнение линейной регрессии
Если переменные пропорциональны друг другу, то графически связь между

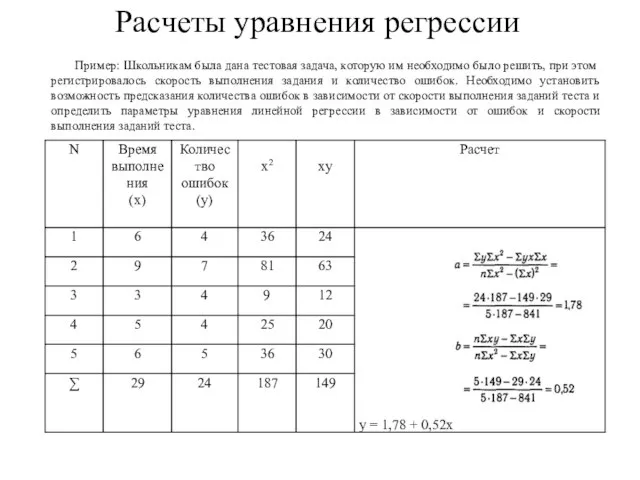
Слайд 156Расчеты уравнения регрессии
Пример: Школьникам была дана тестовая задача, которую им необходимо было
Расчеты уравнения регрессии
Пример: Школьникам была дана тестовая задача, которую им необходимо было
Слайд 157Множественный регрессионный анализ
Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной переменной
Множественный регрессионный анализ
Множественный регрессионный анализ (МРА) предназначен для изучения взаимосвязи одной переменной

Слайд 158Основными целями МРА являются
Определение того, в какой мере «зависимая» переменная связана с
Основными целями МРА являются
Определение того, в какой мере «зависимая» переменная связана с

Слайд 159Дискриминантный анализ
Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у) и
Дискриминантный анализ
Предназначен для изучения взаимосвязи одной переменной (зависимой, результирующей - у) и

Слайд 160Основные результаты дискриминантного анализа
Определение статистической значимости различения классов при помощи данного
Основные результаты дискриминантного анализа
Определение статистической значимости различения классов при помощи данного

Слайд 161Факторный анализ
Главная цель факторного анализа — уменьшение размерности исходных данных.
Результатом
Факторный анализ
Главная цель факторного анализа — уменьшение размерности исходных данных.
Результатом

Слайд 162Основные этапы факторного анализа
Выбор исходных данных.
Предварительное решение проблемы числа факторов: используются
Основные этапы факторного анализа
Выбор исходных данных.
Предварительное решение проблемы числа факторов: используются

Слайд 163Кластерный анализ
Кластерный анализ — это процедура упорядочивания объектов в сравнительно однородные
Кластерный анализ
Кластерный анализ — это процедура упорядочивания объектов в сравнительно однородные

Слайд 164Этапы кластерного анализа
1. Отбор объектов для кластеризации. Объектами могут быть, в зависимости
Этапы кластерного анализа
1. Отбор объектов для кластеризации. Объектами могут быть, в зависимости

Слайд 165Многомерное шкалирование
Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества объектов
Многомерное шкалирование
Основная цель многомерного шкалирования (МШ) — выявление структуры исследуемого множества объектов

Слайд 166Основные этапы многомерного шкалирования
Определение величины стресса (φ-Stress), который является показателем точности -
Основные этапы многомерного шкалирования
Определение величины стресса (φ-Stress), который является показателем точности -

Слайд 167Тема 16. Математическое моделирование в психологии
Системные подходы.
Теория функциональных систем.
Становление кибернетики.
Тема 16. Математическое моделирование в психологии
Системные подходы.
Теория функциональных систем.
Становление кибернетики.

Слайд 168Моделирование
Моделирование — это претендующее на адекватность построение и описание образа или символа
Моделирование
Моделирование — это претендующее на адекватность построение и описание образа или символа

Слайд 169Модели и этапы моделирования
Этапы моделирования сложных процессов и явлений:
Формулировка цели моделирования.
Анализ объекта
Модели и этапы моделирования
Этапы моделирования сложных процессов и явлений:
Формулировка цели моделирования.
Анализ объекта
Слайд 170Психологические модели
Модель И.П. Павлова
И.П. Павлов выделяет целостный механизм анализатора включающий: периферическое,
Психологические модели
Модель И.П. Павлова
И.П. Павлов выделяет целостный механизм анализатора включающий: периферическое,

Слайд 171Модель Н.А. Бернштейна
Работа Н.А. Бернштейна основывалась на идее опровержения принципа рефлекторной дуги
Модель Н.А. Бернштейна
Работа Н.А. Бернштейна основывалась на идее опровержения принципа рефлекторной дуги
Слайд 172Модель К. Халла
Американский ученый К. Халл рассматривал живой организм как саморегулируемую систему
Модель К. Халла
Американский ученый К. Халл рассматривал живой организм как саморегулируемую систему

Слайд 173Теория функциональных систем (модель П. К. Анохина)
Центральная нервная система представлена в виде
Теория функциональных систем (модель П. К. Анохина)
Центральная нервная система представлена в виде
Слайд 174Модель А.Р. Лурии
Так, А. Р. Лурия предложил выделить анатомически относительно автономные блоки
Модель А.Р. Лурии
Так, А. Р. Лурия предложил выделить анатомически относительно автономные блоки

Слайд 175Системный подход
Система - множество элементов, находящихся в отношениях и связях друг с
Системный подход
Система - множество элементов, находящихся в отношениях и связях друг с

Слайд 176Кибернетика Н. Винера
Появление кибернетики как самостоятельного научного направления относится к 1948 г.,
Кибернетика Н. Винера
Появление кибернетики как самостоятельного научного направления относится к 1948 г.,

Слайд 177Теория сигналов является центральной в кибернетике. Ее основными понятиями являются управляющий контур
Теория сигналов является центральной в кибернетике. Ее основными понятиями являются управляющий контур

Слайд 178Модель Л.М. Веккера
Были предприняты попытки создания концепций и теорий регуляции биологических организмов
Модель Л.М. Веккера
Были предприняты попытки создания концепций и теорий регуляции биологических организмов
Слайд 179Синергетика (Г. Хакена)
Хакен Герман (Hermann Haken, род. 12 июля 1927 г.) —
Синергетика (Г. Хакена)
Хакен Герман (Hermann Haken, род. 12 июля 1927 г.) —

Слайд 180Общая теория систем Л. Фон Берталанфи
Карл Людвиг фон Берталанфи (англ. Ludwig von
Общая теория систем Л. Фон Берталанфи
Карл Людвиг фон Берталанфи (англ. Ludwig von

Слайд 181Теория развития И.Р. Пригожина
Илья́ Рома́нович Приго́жин (фр. Ilya Prigogine; (12) 25 января
Теория развития И.Р. Пригожина
Илья́ Рома́нович Приго́жин (фр. Ilya Prigogine; (12) 25 января

Слайд 182Теория катастроф
Теория катастроф — раздел математики, включающий в себя теорию бифуркаций дифференциальных
Теория катастроф
Теория катастроф — раздел математики, включающий в себя теорию бифуркаций дифференциальных
Слайд 183Системный анализ
Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных объектов
Системный анализ
Системный анализ - научная дисциплина, разрабатывающая общие принципы исследования сложных объектов

Слайд 184Метод моделирования в психодиагностике
В психодиагностике используются два основных метода математического моделирования: априорный
Метод моделирования в психодиагностике
В психодиагностике используются два основных метода математического моделирования: априорный
 Этапы консультирования
Этапы консультирования Presentation_of_Uzbekistan_RU-03-2022
Presentation_of_Uzbekistan_RU-03-2022 Война России в союзе с Австрией против Наполеона
Война России в союзе с Австрией против Наполеона Процесс запуска изменений. InterimConsult
Процесс запуска изменений. InterimConsult ТОПОГРАФИЧЕСКАЯ АНАТОМИЯ И ОПЕРАТИВНАЯ ХИРУРГИЯ ЛИЦА
ТОПОГРАФИЧЕСКАЯ АНАТОМИЯ И ОПЕРАТИВНАЯ ХИРУРГИЯ ЛИЦА  Тема 7-8 (7.1., 7.2) Понятие об инновационном проекте
Тема 7-8 (7.1., 7.2) Понятие об инновационном проекте Презентация на тему Презентация учителя-дефектолога
Презентация на тему Презентация учителя-дефектолога Рисуем мимозу
Рисуем мимозу СОВРЕМЕННЫЕ МЕТОДЫ СТОИМОСТНО-ОРИЕНТИРОВАННОГО УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ
СОВРЕМЕННЫЕ МЕТОДЫ СТОИМОСТНО-ОРИЕНТИРОВАННОГО УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ Что же есть человек?
Что же есть человек? Жизнь на Земле
Жизнь на Земле 2022-04-04_GIA-9_normat_dok
2022-04-04_GIA-9_normat_dok КОНДИЦИОНЕРЫ АВТОНОМНЫЕ ДЛЯ АТОМНЫХ ЭЛЕКТРОСТАНЦИЙ КСА – 6,5/25 1КСА – 6,5/25
КОНДИЦИОНЕРЫ АВТОНОМНЫЕ ДЛЯ АТОМНЫХ ЭЛЕКТРОСТАНЦИЙ КСА – 6,5/25 1КСА – 6,5/25 Презентация на тему Трансгенные продукты
Презентация на тему Трансгенные продукты ПРОГРАММА ИНФОРМАТИЗАЦИИ ОБРАЗОВАТЕЛЬНОГО УЧЕРЕЖДЕНИЯ
ПРОГРАММА ИНФОРМАТИЗАЦИИ ОБРАЗОВАТЕЛЬНОГО УЧЕРЕЖДЕНИЯ День защитника Отечества
День защитника Отечества Создать плакат реклам кампании
Создать плакат реклам кампании  Общие требования и правила оформления текстов. Лексические средства научного произведения
Общие требования и правила оформления текстов. Лексические средства научного произведения Мир психологии
Мир психологии Торговый Дом Дианна-Юг
Торговый Дом Дианна-Юг Взаимодействие органов исполнительной власти региона и органов местного самоуправления в сфере образовательной политики
Взаимодействие органов исполнительной власти региона и органов местного самоуправления в сфере образовательной политики Новогодний натюрморт
Новогодний натюрморт бойцовский клуб воин
бойцовский клуб воин Растения, которые мы едим
Растения, которые мы едим Что такое телеканал Успех? Это тематический канал платного ТВ с круглосуточным вещанием по всей России, странам СНГ и Балтии Наши з
Что такое телеканал Успех? Это тематический канал платного ТВ с круглосуточным вещанием по всей России, странам СНГ и Балтии Наши з Внеклассная массовая работа как средство эстетического воспитания учащихся
Внеклассная массовая работа как средство эстетического воспитания учащихся Презентация на тему История создания книги и библиотеки
Презентация на тему История создания книги и библиотеки Культура России XVII века
Культура России XVII века