- НАНОТЕХНОЛОГИЯ НА ПУТИ К РЕЛЯТИВИСТСКИМКОМПЬЮТЕРАМ

Содержание
- 2. ПРОБЛЕМА БЫСТРОДЕЙСТВИЯ Фундаментальная задача современной науки и техники - достижение быстродействия компьютеров 1012 ÷1016 Flops и
- 3. ИСТОРИЯ СУПЕРКОМПЬЮТЕРОВ В РОССИИ 1958 – клеточные автоматы фон Неймана (теория) 1962 – однородная машина Холланда
- 4. ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ 1. БУФЕРИЗАЦИЯ, обеспечивающая сглаживание потоков команд и данных. Буферизация применяется, в первую очередь,
- 5. ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ 2. КОНВЕЙЕРИЗАЦИЯ, позволяющая ускорить исполнение повторяющихся последовательностей действий при приемлемом увеличении оборудования. Наиболее
- 6. ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ 3. СТРУКТУРНАЯ РЕАЛИЗАЦИЯ, позволяющая настроить аппаратуру специально для решения данной задачи. Структурная (аппаратурная)
- 7. ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ 4. РАСПАРАЛЛЕЛИВАНИЕ, позволяющее максимально использовать естественный параллелизм вычислений и привлечь к вычислениям большое
- 8. ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ 5. БАЛАНСИРОВКА НАГРУЗКИ, то есть такое планирование работ, при котором вся аппаратура загружается
- 9. ИСТОЧНОКИ ПАРАЛЛЕЛИЗМА Существует два источника параллелизма 1. Независимые операторы алгоритма. 2. Независимые вычисления над разными данными.
- 10. СИЛА ПАРАЛЛЕЛИЗМА Пусть происходит умножение матриц C=A∙B размера (N×N). Тогда в каждом витке ijk-цикла выполняется cij
- 11. СИЛА ПАРАЛЛЕЛИЗМА 1. Работу всех N ² вычислителей над общей памятью. 2. Хранение в памяти каждого
- 12. ДВА КЛАССА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
- 13. КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ Э.Таннен-баум. Архи-тектура компью-тера. – Питер, 2006.
- 14. КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ Пусть (О/М)К МД означает ОКМД либо МКМД. Например, ОКМД (О/Л)П – класс ОКМД
- 15. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 1. ВЫСОКАЯ СТОИМОСТЬ. В соответствии с законом Гроша (Grosch), производительность компьютера
- 16. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 2. ПОТЕРИ ПРОИЗВОДИТЕЛЬНОСТИ ПРИ ОРГАНИЗАЦИИ ПАРАЛЛЕЛИЗМА. Согласно гипотезе Минского (Minsky), ускорение,
- 17. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 3. ОПЕРЕЖАЮЩЕЕ СОВЕРШЕНСТВОВАНИЕ ПОСЛЕДОВАТЕЛЬНЫХ КОМПЬЮТЕРОВ. По закону Мура (Moore) быстродействие последовательных
- 18. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 4. НЕИЗБЕЖНОСТЬ ПОСЛЕДОВАТЕЛЬНЫХ ВЫЧИСЛЕНИЙ. В соответствии с законом Амдаля (Amdahl) ускорение
- 19. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ Закон Амдаля а - доля последовательных вычислений
- 20. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 5. ЗАВИСИМОСТЬ ЭФФЕКТИВНОСТИ ОТ СТРУКТУРЫ СИСТЕМЫ Параллельные системы отличаются существенным разнообразием
- 21. ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ 6. ОТСУТСТВИЕ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ. Существующее программное обеспечение ориентировано, в основном,
- 22. ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА Степенью параллелизма алгоритма называется число p операций, которые можно выполнять одновременно. Пусть: Vp(N) –
- 23. ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА Пусть: Т1 – время исполнения алгоритма на одном процессоре. Tпар – время исполнения параллельного
- 24. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА Редукция вектора – пример вырождения параллелизма Редукция вектора X = – получение суммы его
- 25. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА Для алгоритма сдваивания число операций равно Vp(N) = N – 1, число этапов сдваивания
- 26. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА Для рекурсивного сдваивания Vp(n) = N log2N – (N + 1) число этапов сдваивания
- 27. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА Пусть t – время сложения, β – коэффициент затрат на передачу данных βt –
- 28. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие его недостаточности При больших p и при β = p ускорение параллельного
- 29. ФУНДАМЕНТАЛЬНЫЕ ПРЕДЕЛЫ ПРОИЗВОДИТЕЛЬНОСТИ Наблюдение за развитием современной вычислительной техники говорит о достижении ФУНДАМЕНТАЛЬНЫХ ПРЕДЕЛОВ роста производительности
- 30. СВЕТОВОЙ БАРЬЕР Световой барьер ограничивает размер синхронного компьютера соотношением: f⋅d ≤ c с – скорость света
- 31. СВЕТОВОЙ И ТЕПЛОВОЙ БАРЬЕРЫ ТРИ НАПРАВЛЕНИЯ развития параллельных вычислительных систем: 1. Классическое 2. Технологическое 3. Релятивистское
- 32. ЕСТЬ ДВЕ ТЕОРИИ ВЫЧИСЛЕНИЙ: КЛАССИЧЕСКАЯ И РЕЛЯТИВИСТСКАЯ Классическая теория вычислений пренебрегает временем доставки данных к процессору.
- 33. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие светового барьера В общем случае для p процессоров имеем ускорение: Sp= T1
- 34. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие светового барьера Закон Амдаля получается как в классической механике, если положить, td
- 35. ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие светового барьера Реалистично полагать для одномерных систем: td = l1p f(T1, p)
- 36. ПРИНЦИП ЛОКАЛЬНОСТИ Для параллельных вычислений нужны такие функции td = f(T1, p), которые 1. отражают технические
- 37. ПРИНЦИП ЛОКАЛЬНОСТИ Параллельные вычисления не вырождаются при td1 = l1p f(T1, p) = l1pkT1⋅ p-1 =
- 38. ПРИНЦИП ЛОКАЛЬНОСТИ 1. В системе с общей памятью все запросы от p процессоров идут к различным
- 39. КЛАССИЧЕСКИЕ КОММУТАТОРЫ Коммутатор – схема обеспечивающая соединение p входов и q выходов. Рис. 1 – разделённый
- 40. СЛОЖНОСТЬ и ЗАДЕРЖКА КЛАССИЧЕСКИХ КОММУТАТОРОВ ТЕОРЕМА ШЕННОНА. Сложность (число узлов коммутации) неблокирующего коммутатора на p входов
- 41. ЛОКАЛЬНЫЕ КОММУТАТОРЫ ЛОКАЛЬНЫЕ КОММУТАТОРЫ СОЕДИНЯЮТ ТОЛЬКО СОСЕДЕЙ И ТОЛЬКО НА ОГРАНИЧЕННОМ РАССТОЯНИИ СЛОЖНОСТЬ ЛОКАЛЬНОГО КОММУТАТОРА ПРОПОРЦИОНАЛЬНА
- 42. ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ Структура вычислительной системы – граф связей между её элементами. Структура однородна, если она
- 43. ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ Примеры локальных однородных структур и тороидальный конструктив системы Qa 4 b Qa 9
- 44. ПРОБЛЕМА РЕЛЯТИВИСТСКОГО КОМПЬЮТЕРА Релятивистский компьютер технически возможен поскольку: 1. Существуют локальные однородные структуры связей с линейной
- 45. РЕЛЯТИВИСТСКАЯ Однородная Вычислительная Система Архитектура ОВС на Неразрезных Процессорных Матрицах СБИС ПК - Мониторная подсистема на
- 46. РЕШАЮЩЕЕ ПОЛЕ – НЕРАЗРЕЗНАЯ ПРОЦЕССОРНАЯ МАТРИЦА СБИС Современная НАНОТЕХНОЛОГИЯ позволяет вплотную подойти к изготовлению неразрезных процессорных
- 47. КЛАССИЧЕСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ 1. Контролируемое и диагностируемое устройство присутствует в системе в единственном экземпляре. 2. Это
- 48. 1. Невозможность замены отказавших элементов; 2. Отказы не только процессорных элементов, но и связей между ними;
- 49. Указанные особенности СБИС создают принципиальные сложности и фундаментальные ограничения при производстве и обеспечения отказоустойчивости НПМ СБИС.
- 50. 1. Отказавшие ПЭ следует обходить, используя резервные элементы 2. Отказавшие связи следует заменять резервными связями. 3.
- 51. ПРОСАЧИВАНИЕ – ФУНДАМЕНТАЛЬНЫЙ ПРЕДЕЛ ОТКАЗОУСТОЙЧИВОСТИ НПМ Задача Хаммерсли (1963г.) Будем удалять узлы и связи случайным образом,
- 52. КРИТЕРИЙ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ) Пусть на множестве локальных однородных структур одного типа, вложенных в R2 с абсолютно
- 53. МОДЕЛЬ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ) Шаблон соседства для решетки К
- 54. МОДЕЛЬ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ)
- 55. МОДЕЛЬ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ) Шаблоны соседства и области просачивания для некоторых решеток
- 56. ПОРОГИ ПРОСАЧИВАНИЯ
- 57. ДИНАМИЧЕСКАЯ МОДЕЛЬ ОТКАЗОУСТОЙЧИВОСТИ НПМ Пусть время безотказного функционирования ЭМ распределено по экспоненциальному закону с параметром α
- 58. ОТКАЗОУСТОЙЧИВОСТЬ НПМ БЕЗ ВОССТАНОВЛЕНИЯ Утверждение 2. Время существования бесконечного исправного кластера в локальной однородной структуре без
- 59. РЕКОНФИГУРАЦИЯ НПМ по САМИ и СТЕФАНЕЛЛИ Сами и Стефанелли предложили несколько алгоритмов реконфигурации НПМ для обхода
- 60. НПМ с ОГРАНИЧЕННЫМ ВОССТАНОВЛЕНИЕМ Пусть N − число ЭМ; m − число восстанавливающих органов, работающих параллельно;
- 61. КОММУТАЦИОННОЕ ОКРУЖЕНИЕ ПЭ по САМИ И СТЕФАНЕЛЛИ
- 62. РЕЗЕРВНЫЕ СВЯЗИ ПЭ по Сами и Стефанелли
- 63. РЕКОНФИГУРАЦИЯ НПМ по В.А.Воробьёву – Н.В.Лаходыновой В.А. Воробьёв и Н.В. Лаходынова модифицировали те же алгоритмы реконфигурации
- 64. КОММУТАЦИОННОЕ ОКРУЖЕНИЕ по В.А.Воробьёву– Н.В.Лаходыновой
- 65. РЕКОНФИГУРАЦИЯ НПМ по В.А. Воробьёву – Н.В. Лаходыновой
- 66. ВИЗАНТИЙСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ 1. Элементом замены является элементарная машина (ЭМ) − устройство, которое обычно само
- 67. КОНСЕНСУС-ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ 1. ПЭ много и они связаны однородной, локальной сетью связи. 2. Число связей
- 68. ВОЛНОВОЙ АЛГОРИТМ ПОИСКА КОНСЕНСУСА Каждый ПЭ тестируется и результаты тестирования сравниваются с результатами тестирования соседей. По
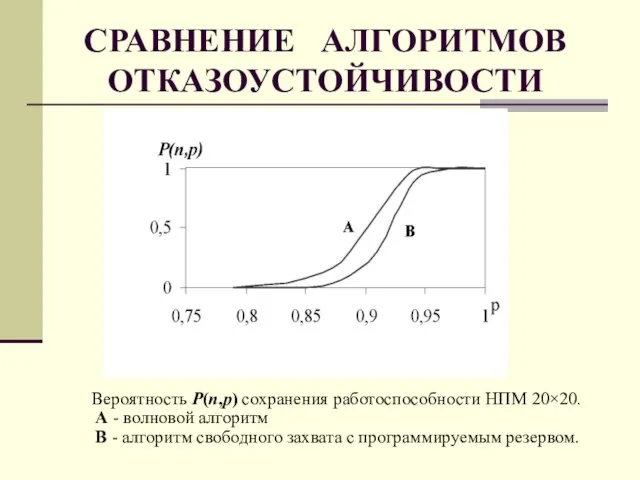
- 69. СРАВНЕНИЕ АЛГОРИТМОВ ОТКАЗОУСТОЙЧИВОСТИ Вероятность P(n,p) сохранения работоспособности НПМ 20×20. А - волновой алгоритм В - алгоритм
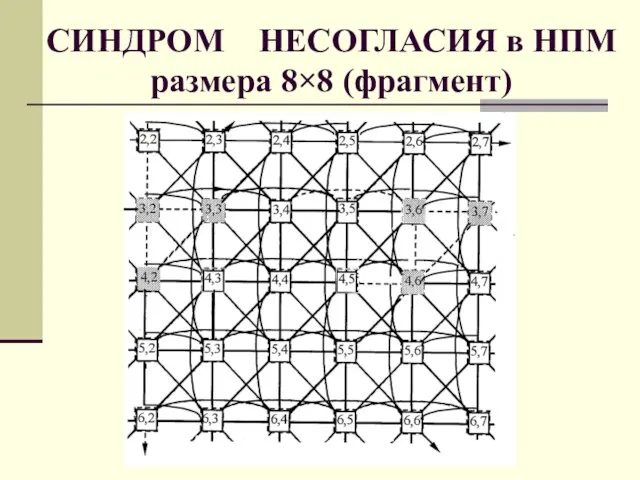
- 70. СИНДРОМ НЕСОГЛАСИЯ в НПМ размера 8×8 (фрагмент)
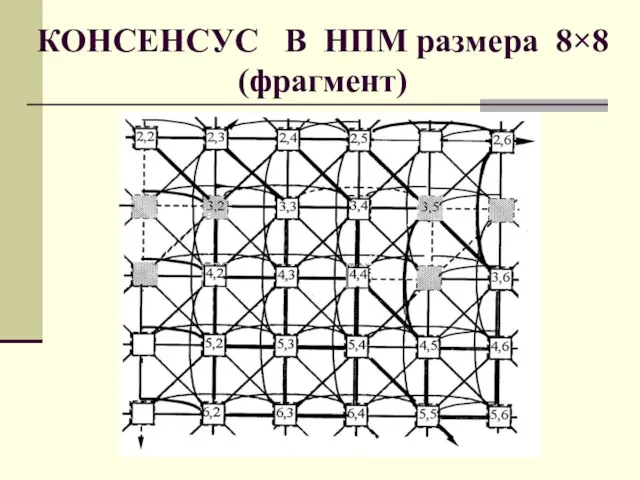
- 71. КОНСЕНСУС В НПМ размера 8×8 (фрагмент)
- 72. 1. Выполняется на локальных однородных структурах 2. Параллелизм максимален 3. Объём данных и вычислений в ЭМ
- 73. суммирует параллельно N строк за время Nt с ускорением (N−1) и эффективностью (N −1)/N →1 при
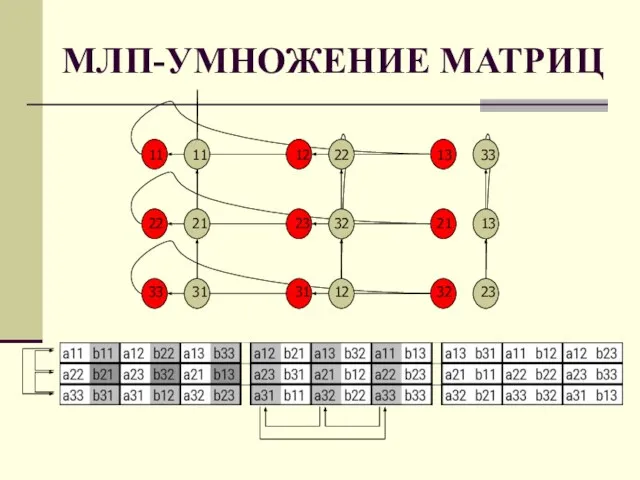
- 74. МЛП-УМНОЖЕНИЕ МАТРИЦ Одним из примеров мелкозернистого распараллеливания может служить умножение матриц размера n2 при использовании n2
- 75. МЛП-УМНОЖЕНИЕ МАТРИЦ
- 76. ОЦЕНКА МЛП-умножения матриц Сложность параллельного алгоритма O(n). Процесс вычислений состоит из 3-х команд: 1. пересылка исходных
- 78. Скачать презентацию
Слайд 2ПРОБЛЕМА БЫСТРОДЕЙСТВИЯ
Фундаментальная задача современной науки и техники - достижение быстродействия компьютеров
ПРОБЛЕМА БЫСТРОДЕЙСТВИЯ
Фундаментальная задача современной науки и техники - достижение быстродействия компьютеров

Слайд 3ИСТОРИЯ СУПЕРКОМПЬЮТЕРОВ
В РОССИИ
1958 – клеточные автоматы фон Неймана (теория)
1962 – однородная машина
ИСТОРИЯ СУПЕРКОМПЬЮТЕРОВ
В РОССИИ
1958 – клеточные автоматы фон Неймана (теория)
1962 – однородная машина

Слайд 4ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
1. БУФЕРИЗАЦИЯ,
обеспечивающая сглаживание потоков команд и данных. Буферизация применяется, в
ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
1. БУФЕРИЗАЦИЯ,
обеспечивающая сглаживание потоков команд и данных. Буферизация применяется, в

Слайд 5ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
2. КОНВЕЙЕРИЗАЦИЯ,
позволяющая ускорить исполнение повторяющихся последовательностей действий при приемлемом увеличении
ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
2. КОНВЕЙЕРИЗАЦИЯ,
позволяющая ускорить исполнение повторяющихся последовательностей действий при приемлемом увеличении

Слайд 6ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
3. СТРУКТУРНАЯ РЕАЛИЗАЦИЯ,
позволяющая настроить аппаратуру специально для решения данной задачи.
ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
3. СТРУКТУРНАЯ РЕАЛИЗАЦИЯ,
позволяющая настроить аппаратуру специально для решения данной задачи.

Слайд 7ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
4. РАСПАРАЛЛЕЛИВАНИЕ,
позволяющее максимально использовать естественный параллелизм вычислений и привлечь
ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
4. РАСПАРАЛЛЕЛИВАНИЕ,
позволяющее максимально использовать естественный параллелизм вычислений и привлечь

Слайд 8ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
5. БАЛАНСИРОВКА НАГРУЗКИ,
то есть такое планирование работ, при котором вся
ПУТИ ПОВЫШЕНИЯ БЫСТРОДЕЙСТВИЯ
5. БАЛАНСИРОВКА НАГРУЗКИ,
то есть такое планирование работ, при котором вся

Слайд 9ИСТОЧНОКИ ПАРАЛЛЕЛИЗМА
Существует два источника параллелизма
1. Независимые операторы алгоритма.
2. Независимые вычисления над разными
ИСТОЧНОКИ ПАРАЛЛЕЛИЗМА
Существует два источника параллелизма
1. Независимые операторы алгоритма.
2. Независимые вычисления над разными

Слайд 10СИЛА ПАРАЛЛЕЛИЗМА
Пусть происходит умножение матриц C=A∙B размера (N×N). Тогда в каждом витке
СИЛА ПАРАЛЛЕЛИЗМА
Пусть происходит умножение матриц C=A∙B размера (N×N). Тогда в каждом витке

Слайд 11СИЛА ПАРАЛЛЕЛИЗМА
1. Работу всех N ² вычислителей над общей памятью.
2. Хранение в
СИЛА ПАРАЛЛЕЛИЗМА
1. Работу всех N ² вычислителей над общей памятью.
2. Хранение в

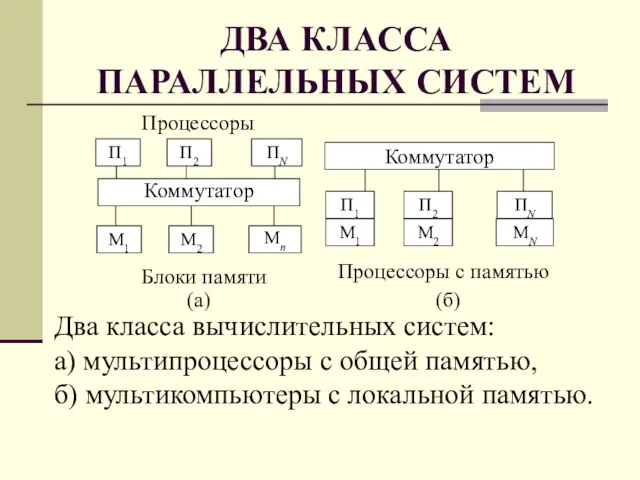
Слайд 12ДВА КЛАССА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
ДВА КЛАССА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Слайд 13КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Э.Таннен-баум.
Архи-тектура компью-тера. –
Питер, 2006.
КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Э.Таннен-баум.
Архи-тектура компью-тера. –
Питер, 2006.
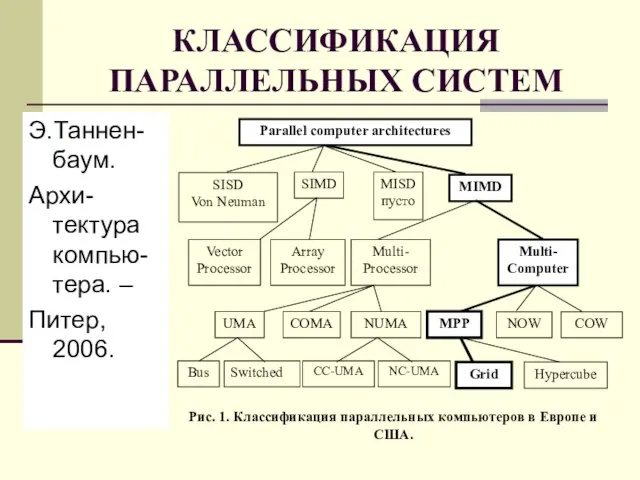
Слайд 14КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Пусть (О/М)К МД означает ОКМД либо МКМД. Например, ОКМД (О/Л)П
КЛАССИФИКАЦИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Пусть (О/М)К МД означает ОКМД либо МКМД. Например, ОКМД (О/Л)П

Слайд 15ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
1. ВЫСОКАЯ СТОИМОСТЬ.
В соответствии с законом Гроша (Grosch),
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
1. ВЫСОКАЯ СТОИМОСТЬ.
В соответствии с законом Гроша (Grosch),

Слайд 16ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
2. ПОТЕРИ ПРОИЗВОДИТЕЛЬНОСТИ ПРИ ОРГАНИЗАЦИИ ПАРАЛЛЕЛИЗМА.
Согласно гипотезе Минского
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
2. ПОТЕРИ ПРОИЗВОДИТЕЛЬНОСТИ ПРИ ОРГАНИЗАЦИИ ПАРАЛЛЕЛИЗМА.
Согласно гипотезе Минского

Слайд 17ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
3. ОПЕРЕЖАЮЩЕЕ СОВЕРШЕНСТВОВАНИЕ ПОСЛЕДОВАТЕЛЬНЫХ КОМПЬЮТЕРОВ.
По закону Мура (Moore)
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
3. ОПЕРЕЖАЮЩЕЕ СОВЕРШЕНСТВОВАНИЕ ПОСЛЕДОВАТЕЛЬНЫХ КОМПЬЮТЕРОВ.
По закону Мура (Moore)

Слайд 18ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
4. НЕИЗБЕЖНОСТЬ ПОСЛЕДОВАТЕЛЬНЫХ ВЫЧИСЛЕНИЙ.
В соответствии с законом Амдаля
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
4. НЕИЗБЕЖНОСТЬ ПОСЛЕДОВАТЕЛЬНЫХ ВЫЧИСЛЕНИЙ.
В соответствии с законом Амдаля

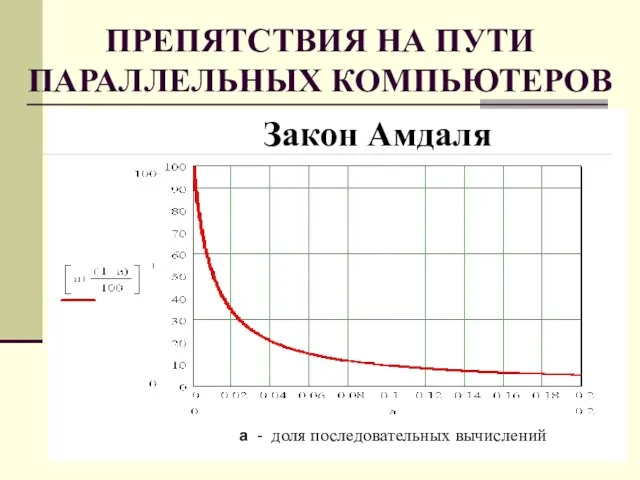
Слайд 19ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
Закон Амдаля
а - доля последовательных вычислений
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
Закон Амдаля
а - доля последовательных вычислений
Слайд 20ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
5. ЗАВИСИМОСТЬ ЭФФЕКТИВНОСТИ ОТ СТРУКТУРЫ СИСТЕМЫ
Параллельные системы
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
5. ЗАВИСИМОСТЬ ЭФФЕКТИВНОСТИ ОТ СТРУКТУРЫ СИСТЕМЫ
Параллельные системы

Слайд 21ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
6. ОТСУТСТВИЕ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ.
Существующее программное обеспечение ориентировано,
ПРЕПЯТСТВИЯ НА ПУТИ ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРОВ
6. ОТСУТСТВИЕ ЭФФЕКТИВНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ.
Существующее программное обеспечение ориентировано,

Слайд 22ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА
Степенью параллелизма алгоритма называется число p операций, которые можно выполнять одновременно.
Пусть:
Vp(N)
ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА
Степенью параллелизма алгоритма называется число p операций, которые можно выполнять одновременно.
Пусть:
Vp(N)

Слайд 23ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА
Пусть:
Т1 – время исполнения алгоритма на одном процессоре.
Tпар – время исполнения
ПАРАМЕТРЫ ПАРАЛЛЕЛИЗМА
Пусть:
Т1 – время исполнения алгоритма на одном процессоре.
Tпар – время исполнения

Слайд 24ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Редукция вектора – пример вырождения параллелизма
Редукция вектора X = 
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Редукция вектора – пример вырождения параллелизма
Редукция вектора X =
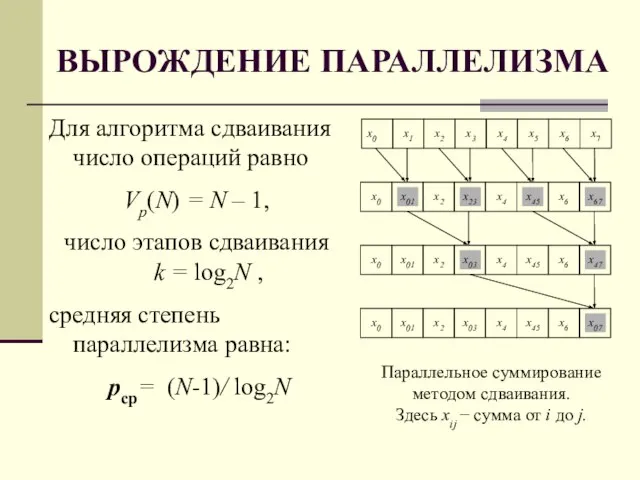
Слайд 25ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Для алгоритма сдваивания число операций равно
Vp(N) = N – 1,
число этапов сдваивания k = log2N ,
средняя степень
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Для алгоритма сдваивания число операций равно
Vp(N) = N – 1,
число этапов сдваивания k = log2N ,
средняя степень
Слайд 26ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Для рекурсивного сдваивания
Vp(n) = N log2N – (N + 1)
число этапов сдваивания равно k = log2N
pср =
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Для рекурсивного сдваивания
Vp(n) = N log2N – (N + 1)
число этапов сдваивания равно k = log2N
pср =

Слайд 27ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Пусть
t – время сложения,
β – коэффициент затрат на передачу данных
βt –
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
Пусть
t – время сложения,
β – коэффициент затрат на передачу данных
βt –

Слайд 28ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие его недостаточности
При больших p и при β = p
ускорение параллельного сдваивания:
Sпар
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие его недостаточности
При больших p и при β = p
ускорение параллельного сдваивания:
Sпар

Слайд 29ФУНДАМЕНТАЛЬНЫЕ ПРЕДЕЛЫ ПРОИЗВОДИТЕЛЬНОСТИ
Наблюдение за развитием современной вычислительной техники говорит о достижении ФУНДАМЕНТАЛЬНЫХ
ФУНДАМЕНТАЛЬНЫЕ ПРЕДЕЛЫ ПРОИЗВОДИТЕЛЬНОСТИ
Наблюдение за развитием современной вычислительной техники говорит о достижении ФУНДАМЕНТАЛЬНЫХ

Слайд 30СВЕТОВОЙ БАРЬЕР
Световой барьер ограничивает размер синхронного компьютера соотношением:
f⋅d ≤ c
с –
СВЕТОВОЙ БАРЬЕР
Световой барьер ограничивает размер синхронного компьютера соотношением:
f⋅d ≤ c
с –

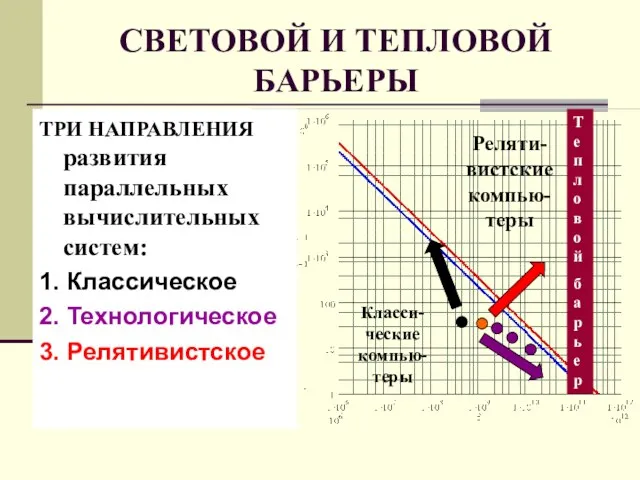
Слайд 31СВЕТОВОЙ И ТЕПЛОВОЙ БАРЬЕРЫ
ТРИ НАПРАВЛЕНИЯ развития параллельных вычислительных систем:
1. Классическое
2. Технологическое
3. Релятивистское
СВЕТОВОЙ И ТЕПЛОВОЙ БАРЬЕРЫ
ТРИ НАПРАВЛЕНИЯ развития параллельных вычислительных систем:
1. Классическое
2. Технологическое
3. Релятивистское
Слайд 32ЕСТЬ ДВЕ ТЕОРИИ ВЫЧИСЛЕНИЙ:
КЛАССИЧЕСКАЯ И РЕЛЯТИВИСТСКАЯ
Классическая теория вычислений пренебрегает временем доставки
ЕСТЬ ДВЕ ТЕОРИИ ВЫЧИСЛЕНИЙ:
КЛАССИЧЕСКАЯ И РЕЛЯТИВИСТСКАЯ
Классическая теория вычислений пренебрегает временем доставки

Слайд 33ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие светового барьера
В общем случае для p процессоров имеем
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие светового барьера
В общем случае для p процессоров имеем

Слайд 34ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие светового барьера
Закон Амдаля получается как в классической механике,
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА как следствие светового барьера
Закон Амдаля получается как в классической механике,

Слайд 35ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие светового барьера
Реалистично полагать для одномерных систем:
td = l1p
ВЫРОЖДЕНИЕ ПАРАЛЛЕЛИЗМА
как следствие светового барьера
Реалистично полагать для одномерных систем:
td = l1p

Слайд 36ПРИНЦИП ЛОКАЛЬНОСТИ
Для параллельных вычислений нужны такие функции td = f(T1, p), которые
1.
ПРИНЦИП ЛОКАЛЬНОСТИ
Для параллельных вычислений нужны такие функции td = f(T1, p), которые
1.

Слайд 37ПРИНЦИП ЛОКАЛЬНОСТИ
Параллельные вычисления
не вырождаются при
td1 = l1p f(T1, p) = l1pkT1⋅ p-1 =
ПРИНЦИП ЛОКАЛЬНОСТИ
Параллельные вычисления
не вырождаются при
td1 = l1p f(T1, p) = l1pkT1⋅ p-1 =

Слайд 38ПРИНЦИП ЛОКАЛЬНОСТИ
1. В системе с общей памятью все запросы от p процессоров
ПРИНЦИП ЛОКАЛЬНОСТИ
1. В системе с общей памятью все запросы от p процессоров

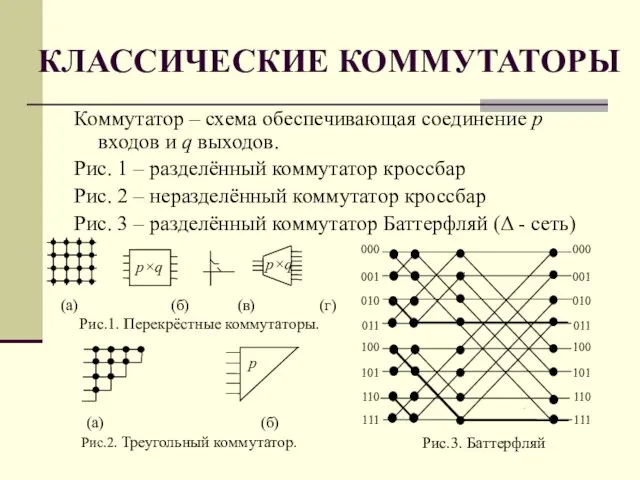
Слайд 39КЛАССИЧЕСКИЕ КОММУТАТОРЫ
Коммутатор – схема обеспечивающая соединение p входов и q выходов.
Рис. 1
КЛАССИЧЕСКИЕ КОММУТАТОРЫ
Коммутатор – схема обеспечивающая соединение p входов и q выходов.
Рис. 1
Слайд 40СЛОЖНОСТЬ и ЗАДЕРЖКА КЛАССИЧЕСКИХ КОММУТАТОРОВ
ТЕОРЕМА ШЕННОНА.
Сложность (число узлов коммутации) неблокирующего коммутатора на
СЛОЖНОСТЬ и ЗАДЕРЖКА КЛАССИЧЕСКИХ КОММУТАТОРОВ
ТЕОРЕМА ШЕННОНА.
Сложность (число узлов коммутации) неблокирующего коммутатора на

Слайд 41ЛОКАЛЬНЫЕ КОММУТАТОРЫ
ЛОКАЛЬНЫЕ КОММУТАТОРЫ СОЕДИНЯЮТ ТОЛЬКО СОСЕДЕЙ И ТОЛЬКО НА ОГРАНИЧЕННОМ РАССТОЯНИИ
СЛОЖНОСТЬ ЛОКАЛЬНОГО
ЛОКАЛЬНЫЕ КОММУТАТОРЫ
ЛОКАЛЬНЫЕ КОММУТАТОРЫ СОЕДИНЯЮТ ТОЛЬКО СОСЕДЕЙ И ТОЛЬКО НА ОГРАНИЧЕННОМ РАССТОЯНИИ
СЛОЖНОСТЬ ЛОКАЛЬНОГО

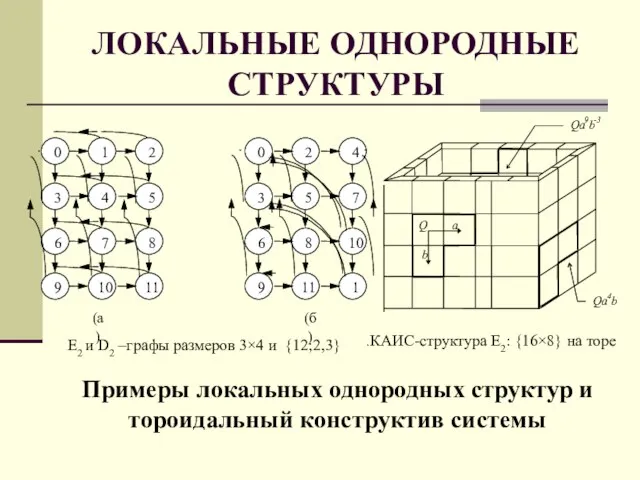
Слайд 42ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ
Структура вычислительной системы – граф связей между её элементами. Структура
ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ
Структура вычислительной системы – граф связей между её элементами. Структура

Слайд 43ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ
Примеры локальных однородных структур и тороидальный конструктив системы
Qa
4
b
Qa
9
b
-3
Q a
ЛОКАЛЬНЫЕ ОДНОРОДНЫЕ СТРУКТУРЫ
Примеры локальных однородных структур и тороидальный конструктив системы
Qa
4
b
Qa
9
b
-3
Q a
Слайд 44ПРОБЛЕМА РЕЛЯТИВИСТСКОГО КОМПЬЮТЕРА
Релятивистский компьютер технически возможен поскольку:
1. Существуют локальные однородные структуры связей
ПРОБЛЕМА РЕЛЯТИВИСТСКОГО КОМПЬЮТЕРА
Релятивистский компьютер технически возможен поскольку:
1. Существуют локальные однородные структуры связей

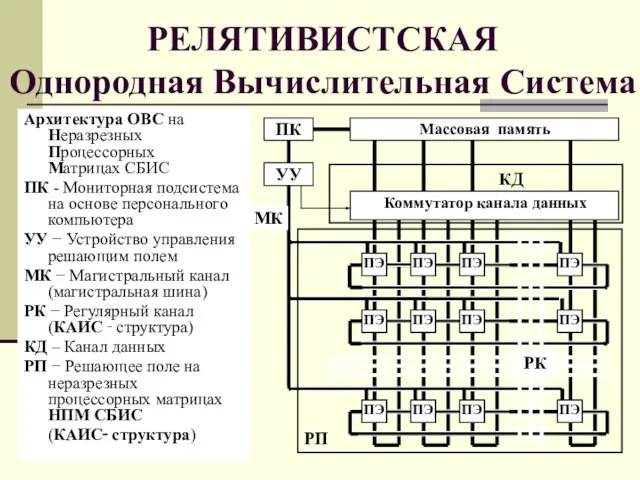
Слайд 45РЕЛЯТИВИСТСКАЯ
Однородная Вычислительная Система
Архитектура ОВС на Неразрезных Процессорных
Матрицах СБИС
ПК - Мониторная
РЕЛЯТИВИСТСКАЯ
Однородная Вычислительная Система
Архитектура ОВС на Неразрезных Процессорных
Матрицах СБИС
ПК - Мониторная
Слайд 46РЕШАЮЩЕЕ ПОЛЕ – НЕРАЗРЕЗНАЯ ПРОЦЕССОРНАЯ МАТРИЦА СБИС
Современная НАНОТЕХНОЛОГИЯ позволяет вплотную подойти к
РЕШАЮЩЕЕ ПОЛЕ – НЕРАЗРЕЗНАЯ ПРОЦЕССОРНАЯ МАТРИЦА СБИС
Современная НАНОТЕХНОЛОГИЯ позволяет вплотную подойти к

Слайд 47КЛАССИЧЕСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ
1. Контролируемое и диагностируемое устройство присутствует в системе в единственном
КЛАССИЧЕСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ
1. Контролируемое и диагностируемое устройство присутствует в системе в единственном

Слайд 481. Невозможность замены отказавших элементов;
2. Отказы не только процессорных элементов, но и
1. Невозможность замены отказавших элементов;
2. Отказы не только процессорных элементов, но и

Слайд 49Указанные особенности СБИС создают принципиальные сложности и фундаментальные ограничения при производстве и
Указанные особенности СБИС создают принципиальные сложности и фундаментальные ограничения при производстве и

Слайд 501. Отказавшие ПЭ следует обходить, используя резервные элементы
2. Отказавшие связи следует заменять
1. Отказавшие ПЭ следует обходить, используя резервные элементы
2. Отказавшие связи следует заменять

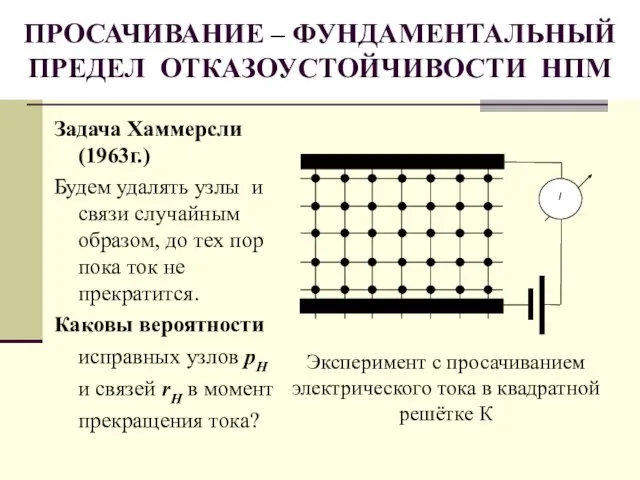
Слайд 51ПРОСАЧИВАНИЕ – ФУНДАМЕНТАЛЬНЫЙ ПРЕДЕЛ ОТКАЗОУСТОЙЧИВОСТИ НПМ
Задача Хаммерсли (1963г.)
Будем удалять узлы и связи
ПРОСАЧИВАНИЕ – ФУНДАМЕНТАЛЬНЫЙ ПРЕДЕЛ ОТКАЗОУСТОЙЧИВОСТИ НПМ
Задача Хаммерсли (1963г.)
Будем удалять узлы и связи
Слайд 52КРИТЕРИЙ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ)
Пусть на множестве локальных однородных структур одного типа, вложенных в
КРИТЕРИЙ ПРОСАЧИВАНИЯ (ПЕРКОЛЯЦИИ)
Пусть на множестве локальных однородных структур одного типа, вложенных в

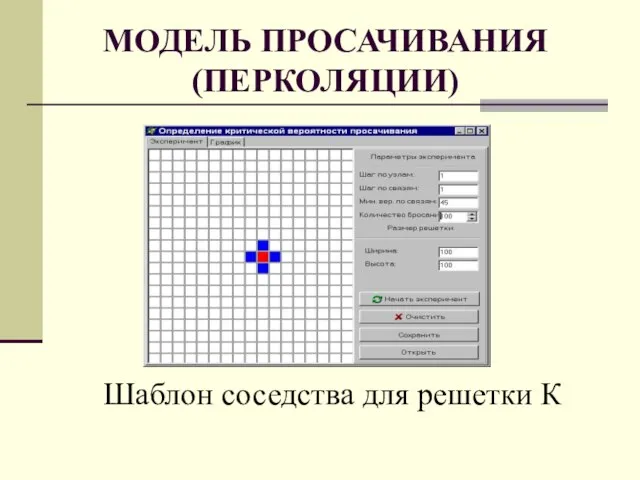
Слайд 53МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
Шаблон соседства для решетки К
МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
Шаблон соседства для решетки К
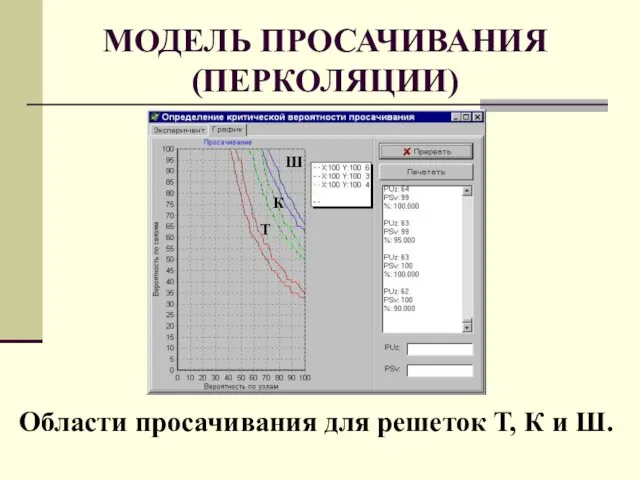
Слайд 54МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
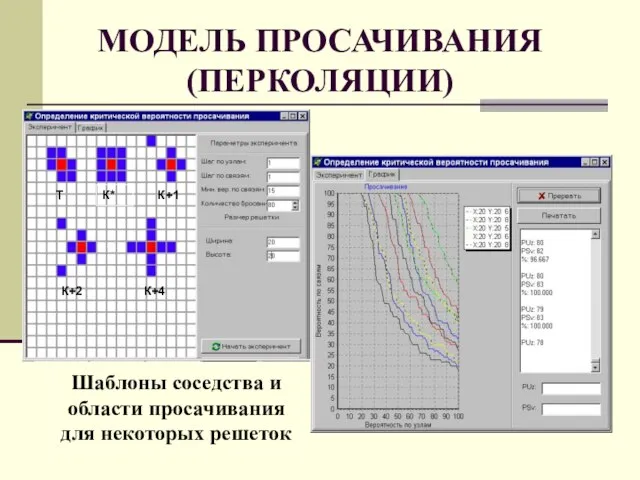
Слайд 55МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
Шаблоны соседства и области просачивания для некоторых решеток
МОДЕЛЬ ПРОСАЧИВАНИЯ
(ПЕРКОЛЯЦИИ)
Шаблоны соседства и области просачивания для некоторых решеток
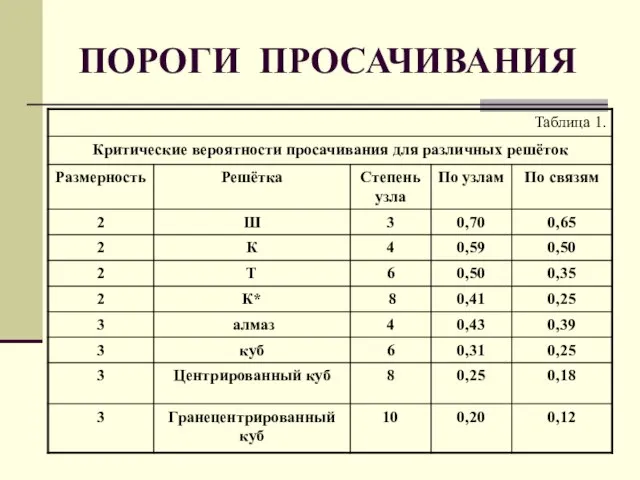
Слайд 56ПОРОГИ ПРОСАЧИВАНИЯ
ПОРОГИ ПРОСАЧИВАНИЯ
Слайд 57ДИНАМИЧЕСКАЯ МОДЕЛЬ
ОТКАЗОУСТОЙЧИВОСТИ НПМ
Пусть время безотказного функционирования ЭМ распределено по экспоненциальному закону с
ДИНАМИЧЕСКАЯ МОДЕЛЬ
ОТКАЗОУСТОЙЧИВОСТИ НПМ
Пусть время безотказного функционирования ЭМ распределено по экспоненциальному закону с

Слайд 58ОТКАЗОУСТОЙЧИВОСТЬ НПМ
БЕЗ ВОССТАНОВЛЕНИЯ
Утверждение 2. Время существования бесконечного исправного кластера в локальной однородной
ОТКАЗОУСТОЙЧИВОСТЬ НПМ
БЕЗ ВОССТАНОВЛЕНИЯ
Утверждение 2. Время существования бесконечного исправного кластера в локальной однородной

Слайд 59РЕКОНФИГУРАЦИЯ НПМ по
САМИ и СТЕФАНЕЛЛИ
Сами и Стефанелли предложили несколько алгоритмов реконфигурации
РЕКОНФИГУРАЦИЯ НПМ по
САМИ и СТЕФАНЕЛЛИ
Сами и Стефанелли предложили несколько алгоритмов реконфигурации

Слайд 60НПМ с ОГРАНИЧЕННЫМ ВОССТАНОВЛЕНИЕМ
Пусть N − число ЭМ; m − число восстанавливающих органов, работающих
НПМ с ОГРАНИЧЕННЫМ ВОССТАНОВЛЕНИЕМ
Пусть N − число ЭМ; m − число восстанавливающих органов, работающих

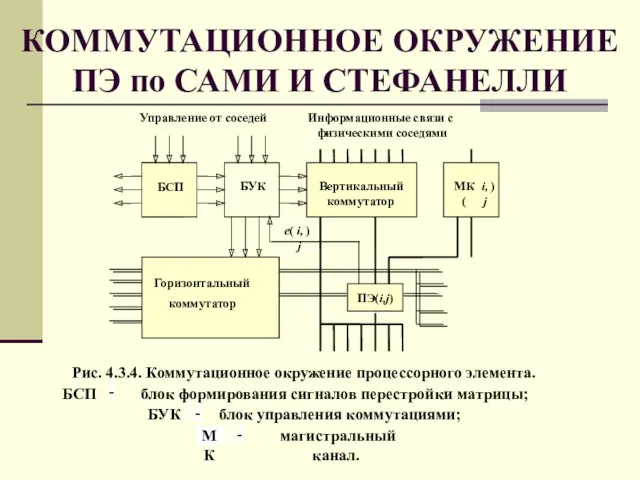
Слайд 61КОММУТАЦИОННОЕ ОКРУЖЕНИЕ ПЭ по САМИ И СТЕФАНЕЛЛИ
КОММУТАЦИОННОЕ ОКРУЖЕНИЕ ПЭ по САМИ И СТЕФАНЕЛЛИ
Слайд 62РЕЗЕРВНЫЕ СВЯЗИ ПЭ
по Сами и Стефанелли
РЕЗЕРВНЫЕ СВЯЗИ ПЭ
по Сами и Стефанелли

Слайд 63РЕКОНФИГУРАЦИЯ НПМ по
В.А.Воробьёву – Н.В.Лаходыновой
В.А. Воробьёв и Н.В. Лаходынова модифицировали те
РЕКОНФИГУРАЦИЯ НПМ по
В.А.Воробьёву – Н.В.Лаходыновой
В.А. Воробьёв и Н.В. Лаходынова модифицировали те

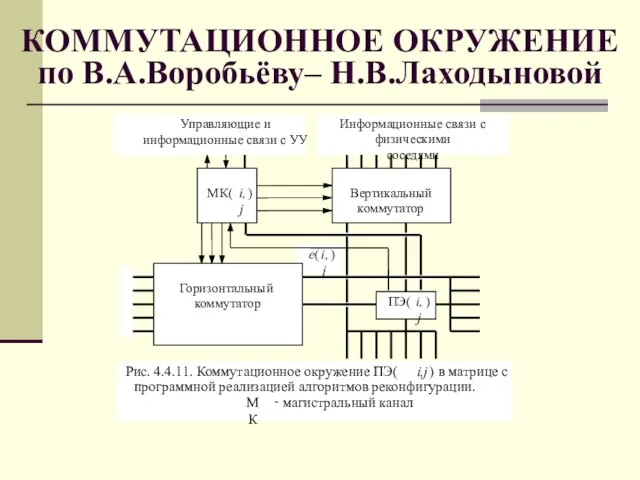
Слайд 64КОММУТАЦИОННОЕ ОКРУЖЕНИЕ по В.А.Воробьёву– Н.В.Лаходыновой
КОММУТАЦИОННОЕ ОКРУЖЕНИЕ по В.А.Воробьёву– Н.В.Лаходыновой
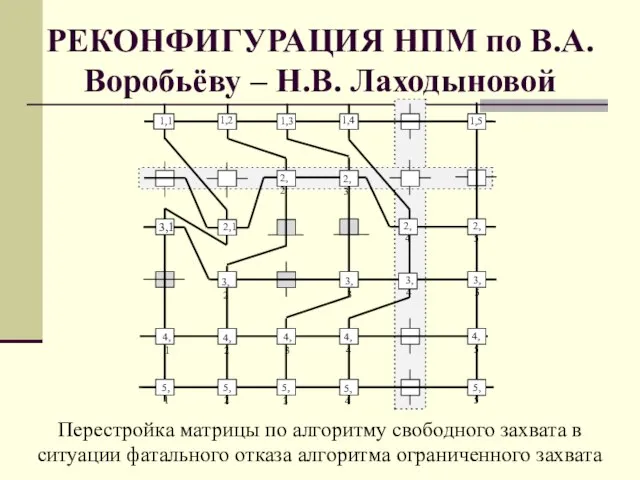
Слайд 65РЕКОНФИГУРАЦИЯ НПМ по В.А. Воробьёву – Н.В. Лаходыновой
РЕКОНФИГУРАЦИЯ НПМ по В.А. Воробьёву – Н.В. Лаходыновой
Слайд 66ВИЗАНТИЙСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ
1. Элементом замены является элементарная машина (ЭМ) − устройство,
ВИЗАНТИЙСКАЯ ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ
1. Элементом замены является элементарная машина (ЭМ) − устройство,

Слайд 67КОНСЕНСУС-ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ
1. ПЭ много и они связаны однородной, локальной сетью связи.
2.
КОНСЕНСУС-ПАРАДИГМА ОТКАЗОУСТОЙЧИВОСТИ НПМ
1. ПЭ много и они связаны однородной, локальной сетью связи.
2.

Слайд 68ВОЛНОВОЙ АЛГОРИТМ ПОИСКА КОНСЕНСУСА
Каждый ПЭ тестируется и результаты тестирования сравниваются с результатами
ВОЛНОВОЙ АЛГОРИТМ ПОИСКА КОНСЕНСУСА
Каждый ПЭ тестируется и результаты тестирования сравниваются с результатами

Слайд 69СРАВНЕНИЕ АЛГОРИТМОВ
ОТКАЗОУСТОЙЧИВОСТИ
Вероятность P(n,p) сохранения работоспособности НПМ 20×20.
А - волновой алгоритм
В - алгоритм
СРАВНЕНИЕ АЛГОРИТМОВ
ОТКАЗОУСТОЙЧИВОСТИ
Вероятность P(n,p) сохранения работоспособности НПМ 20×20.
А - волновой алгоритм
В - алгоритм
Слайд 70СИНДРОМ НЕСОГЛАСИЯ в НПМ размера 8×8 (фрагмент)
СИНДРОМ НЕСОГЛАСИЯ в НПМ размера 8×8 (фрагмент)
Слайд 71КОНСЕНСУС В НПМ размера 8×8 (фрагмент)
КОНСЕНСУС В НПМ размера 8×8 (фрагмент)
Слайд 721. Выполняется на локальных однородных структурах
2. Параллелизм максимален
3. Объём данных и вычислений
1. Выполняется на локальных однородных структурах
2. Параллелизм максимален
3. Объём данных и вычислений

Слайд 73суммирует параллельно N строк за время Nt с ускорением (N−1) и эффективностью
(N
суммирует параллельно N строк за время Nt с ускорением (N−1) и эффективностью
(N
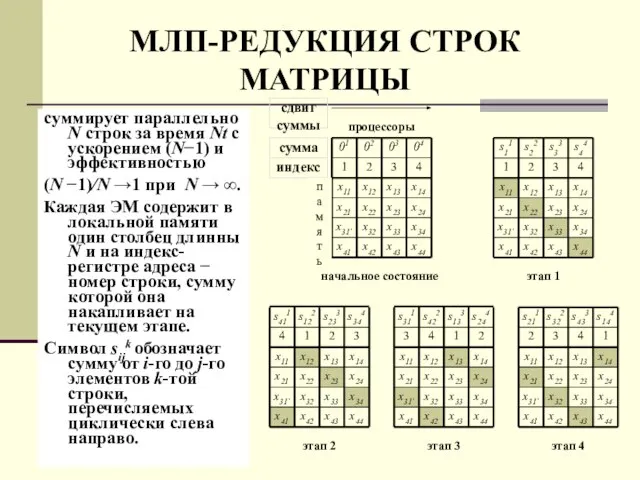
Слайд 74МЛП-УМНОЖЕНИЕ МАТРИЦ
Одним из примеров мелкозернистого распараллеливания может служить умножение матриц размера n2
МЛП-УМНОЖЕНИЕ МАТРИЦ
Одним из примеров мелкозернистого распараллеливания может служить умножение матриц размера n2

Слайд 75МЛП-УМНОЖЕНИЕ МАТРИЦ
МЛП-УМНОЖЕНИЕ МАТРИЦ
Слайд 76ОЦЕНКА
МЛП-умножения матриц
Сложность параллельного алгоритма O(n).
Процесс вычислений состоит из 3-х команд:
1. пересылка исходных
ОЦЕНКА
МЛП-умножения матриц
Сложность параллельного алгоритма O(n).
Процесс вычислений состоит из 3-х команд:
1. пересылка исходных

 Стан електронів у атомі
Стан електронів у атомі Электронный микроскоп
Электронный микроскоп Презентация на тему Иконография образа Пресвятой Богородицы
Презентация на тему Иконография образа Пресвятой Богородицы HOW OFTEN DO YOU EAT CAKES
HOW OFTEN DO YOU EAT CAKES Профильная комиссия экспертного совета Минздравсоцразвития «Урология»
Профильная комиссия экспертного совета Минздравсоцразвития «Урология» Кот в пальто
Кот в пальто Влияние изменения солнечной активностина напряженное состояние и геодинамику земной коры Урала Зубк
Влияние изменения солнечной активностина напряженное состояние и геодинамику земной коры Урала Зубк Проект по математике «Удивительное рядом»
Проект по математике «Удивительное рядом» AmadeusService Fee Manager
AmadeusService Fee Manager Улучшение технологического процесса изготовления шлангов ПЭ-32 SDR 18
Улучшение технологического процесса изготовления шлангов ПЭ-32 SDR 18 Тест Местоимения
Тест Местоимения Многонациональные и однонациональные государства
Многонациональные и однонациональные государства Крещение (Богоявление)
Крещение (Богоявление) Административное право
Административное право Жестокое обращение с детьми
Жестокое обращение с детьми Элементы песочной терапии на логопедических занятиях. Логопедическая служба ГОУ ЦО «Школа здоровья
Элементы песочной терапии на логопедических занятиях. Логопедическая служба ГОУ ЦО «Школа здоровья Экологическое право
Экологическое право Реальность и фантазия в творчестве художника. 6 класс
Реальность и фантазия в творчестве художника. 6 класс Админская паранойя в быту или страшная криптографическая сказка для самых маленьких параноиков
Админская паранойя в быту или страшная криптографическая сказка для самых маленьких параноиков Образы "Слова о полку Игореве"
Образы "Слова о полку Игореве" Оборудование для измельчения и переработки шин
Оборудование для измельчения и переработки шин Структура и содержание образовательной деятельности
Структура и содержание образовательной деятельности Анималистический жанр. 7 клас
Анималистический жанр. 7 клас Актив. Экономика и финансы проекта
Актив. Экономика и финансы проекта Витамин Е
Витамин Е Информационная безопасность
Информационная безопасность Sustainable agriculture, forestry and fishery
Sustainable agriculture, forestry and fishery Практическая № 37-38
Практическая № 37-38