- Параллельное и распределенное программирование. Современное состояние и вызовы.

Содержание
- 2. Вызовы: ● Сложность создаваемых систем (авиационная и космическая промышленность, атомная энергетика, кораблестроение, автомобильная промышленность и др.)
- 3. Традиционный научно-технический подход: 1) Разработка теории или проектирование на бумаге 2) Поставить эксперименты или построить систему
- 4. Пример: Глобальное предсказание погоды Территория России 17,075,200 км2. Пусть атмосфера над территорией России разделена на ячейки
- 5. Современные высокопроизводительные вычислительные системы ∙ За последние 20 лет рост производительности компьютеров, входящих в список «Top500»,
- 6. Высокопроизводительный кластер (I)
- 7. Кластер* строится из стандартных (commodity) аппаратных компонент, на которых установлено стандартное системное программное обеспечение Аппаратура узла:
- 8. Высокопроизводительный кластер (III) За счет чего достигается рост производительности: ● рост производительности узлов ● развитие сети
- 9. Рост производительности процессора - повышение тактовой частоты и увеличение пропускной способности памяти - параллелизм на уровне
- 10. Сравнение одного из первых компьютеров Eniac и современного ПК
- 11. Архитектура фон Неймана Один поток вычислений, следующий изначальному порядку команд программы Каждая команда выполняется полностью перед
- 12. Параллелизм на уровне команд (I) Часто последовательное выполнение является искусственным ограничением x = y + z;
- 13. Параллелизм на уровне команд (II) Подходы к использованию ILP: Конвейеризация вычислений: параллельно работают разные стадии выполнения
- 14. Параллелизм на уровне команд (III) Архитектура с длинным командным словом: Компилятор упаковывает команды, которые должны выполняться
- 15. Параллелизм на уровне команд (IV) Параллелизм по данным (векторизация): Однотипные операции над элементами вектора можно выполнять
- 16. Параллелизм на уровне команд (V) Возможности использования параллелизма на уровне команд достигли предела! Улучшение компилятора/архитектуры не
- 17. Текущий тренд (I) Производители (Intel, IBM, Sun) сделали ставку на параллелизм через multicore/manycore, т.к. развитие однопроцессорных
- 18. Текущий тренд (II) Фундаментальные проблемы: ● Было: энергия дешева, транзисторы дороги Стало: транзисторы дешевы, энергия дорога
- 19. Текущий тренд (III) ● Расширение спектра задач решаемых с использованием графических акселераторов (Nebulae, Китай - 2-е
- 20. Архитектура Tesla
- 21. Архитектура Cell
- 22. Проблема: обеспечение высокопродуктивных вычислений (компромисс между стоимостью разработки и сопровождения и эффективностью выполнения) Мечта! Создание языка
- 23. // MPI вариант while ((iterN--) != 0) { for(i = 2; i for(j = ((myidy ==
- 24. Средства разработки ПО (III) Почему HPF не оправдал надежд: отсутствие компиляторных технологий, позволяющих генерировать эффективный параллельный
- 25. В настоящее время фактическим языковым стандартом разработки промышленных прикладных программ является использование одного из языков программирования
- 26. Пример доводки MPI-программы (1) //sending Send Recv //calculating for (i = beg_i; i for (j =
- 27. Пример доводки MPI-программы (2)
- 28. Пример доводки MPI-программы (3) Моделирование торнадо
- 29. Эффективные программы для GPU Необходимо учитывать ряд особенностей Количество нитей Загруженность мультипроцессора, зависящая от: Количества регистров
- 30. Разреженные матрицы Специализированные форматы хранения Типичная задача – умножение на плотный вектор (SpMV) 2 FLOPS на
- 31. Предлагаемый формат (“sliced” ELLPACK) Матрица делится на полоски из строк Каждая полоска хранится в формате ELL
- 32. Улучшения алгоритма (I) Переупорядочивание строк Хочется расположить рядом строки с одинаковым количеством ненулевых элементов Дорогая оптимизация,
- 33. Улучшения алгоритма (II) Параметры реализации: Зависящие от устройства Количество строк на полоску Количество нитей на блок
- 34. Результаты тестирования Варианты алгоритма сравниваются с реализацией от NVIDIA как базовой Тесты – набор матриц, использующийся
- 35. ● Создание технологий для классов приложений ● Разработка библиотек и пакетов прикладных программ ● Организация междисциплинарных
- 36. Программная модель Map/Reduce Вычисления производятся над множествами пар (k, v), где k – ключ, v –
- 37. // Функция, используемая рабочими узлами на Map-шаге // для обработки пар ключ-значение из входного потока map(String
- 38. Существуют эффективные масштабируемые реализации MapReduce (компания Google, система Hadoop) в рамках распределенной среды: ● десятки тысяч
- 39. ● Системы автоматизации инженерного анализа (CAE системы) ANSYS, CFX, LS_DYNA, ICEM CFD, STAR-CD, FLUENT, Diffpack, COMET/Acoustics,
- 40. Цели Grid* Обеспечение возможности решения крупномасштабных научно-технических задач Организация работы распределенных (административно и географически) коллективов Оптимизация
- 41. Проект CERN
- 42. Globus Toolkit Реализует стандарт OGSI Реализует аутентификацию на основе стандарта X.509 Содержит контейнер Grid служб Содержит
- 43. Пример стенда – TeraGrid
- 44. Концепция «Облачных вычислений» ∙ Все есть сервис (XaaS) − AaaS: приложения как сервис − PaaS: платформа
- 45. Компании предлагающие «Облачные» решения (небольшая выборка) Ожидаемый рост рынка облачных вычислений к 2015 г. до 200
- 46. Примеры внедрения «Облачных» решений ? Nebula – «облачная» платформа NASA ? RACE – частное облако для
- 47. Правительственные инициативы по «Облачным» решениям ? G-Cloud – Правительственное облако Великобритании, которое опирается на инициативу: «Deliver
- 48. NEBULA Cloud Computing Platform Nebula (туманность) – это проект который разрабатывается в Исследовательском центре Эймс а
- 49. Свободное ПО и «Облачные вычисления» Одно из основных направлений развития ? Стандартный стек системного ПО ?
- 50. Почему сейчас? Создание чрезвычайно крупномасштабных центров обработки данных - в ~10 раз снижение стоимости (использование систем
- 51. Примеры применения ◊ Конвертирование большого количества файлов из одного формата в другой (пакетная обработка) Washington post:
- 52. Неиспользуемые ресурсы Преимущества «облачного» ЦОДа ◊ Гибкость предоставления ресурсов может обеспечить беспрецедентную экономию – минимум неиспользуемых
- 53. «Облачные вычисления» в науке и образовании (1) Возможность создания web-ориентированных лабораторий (хабов) в конкретных предметных областях
- 54. «Облачные вычисления» в науке и образовании (2) ◊ Принципиально новые возможности для исследователей по организации доступа,
- 55. Общая схема организации «хаба»
- 56. Globus, Condor-G, gLite,…C Linux, Apache, LDAP, PHP, Joomla, MySQL, Sendna (ИСП РАН), Xen, Handoop, VNC, Rappture
- 57. «Университетский кластер» (1) Программа учреждена 4 сентября 2008 года Российской академией наук (ИСП РАН и МСЦ
- 58. «Университетский кластер» (2) Для достижения целей Программы решаются следующие задачи: - построение, развитие и поддержка вычислительной
- 59. «Университетский кластер» (3) Инфраструктура включает в себя современные аппаратные, программные, сетевые технологии, а также компетенцию передовых
- 60. «Университетский кластер» (4)
- 61. «Университетский кластер». Проект OpenCirrus OpenCirrus был основан компаниями НР, Intel и Yahoo Цель – создание открытого
- 62. OpenCirrus – география проекта
- 63. «Университетский кластер». Текущее состояние (1) Реализованы базовые сетевые службы VPN «Университетский кластер» (служба доменных имен DNS,
- 64. «Университетский кластер». Текущее состояние (2) ИСП РАН совместно с РНЦ «Курчатовский институт» и компанией HP, на
- 65. Пакетизация идет с конца 80-х гг. Универсальные пакеты – PHOENICS, ANSYS, Nastran, FIDAP, StarCD, FIRE, FLUENT,
- 66. Свободное Программное Обеспечение
- 67. Основные этапы и модули при решении задач МСС
- 68. Salome (EDF, CEA, OpenCASCADE) Salome - является бесплатным программным обеспечением, которое предоставляет платформу для Пре и
- 69. ОpenFOAM — свободно распространяемое программное обеспечение для проведения численных расчетов. OpenFOAM — объектно-ориентированная платформа, реализованная на
- 70. Paraview (ARL,ASC, Los Alamos NL, Kitware, Sandia NL,Kitware) Multi-view support Quantitative analysis Undo/redo Python scripting Time
- 72. Скачать презентацию
Слайд 2Вызовы:
● Сложность создаваемых систем (авиационная и космическая промышленность, атомная энергетика, кораблестроение, автомобильная
Вызовы:
● Сложность создаваемых систем (авиационная и космическая промышленность, атомная энергетика, кораблестроение, автомобильная

Слайд 3Традиционный научно-технический подход:
1) Разработка теории или проектирование на бумаге
2) Поставить эксперименты или
Традиционный научно-технический подход:
1) Разработка теории или проектирование на бумаге
2) Поставить эксперименты или

Слайд 4Пример: Глобальное предсказание погоды
Территория России 17,075,200 км2. Пусть атмосфера над территорией России
Пример: Глобальное предсказание погоды
Территория России 17,075,200 км2. Пусть атмосфера над территорией России

Слайд 5Современные высокопроизводительные вычислительные системы
∙ За последние 20 лет рост производительности компьютеров, входящих
Современные высокопроизводительные вычислительные системы
∙ За последние 20 лет рост производительности компьютеров, входящих

Слайд 6
Высокопроизводительный кластер (I)
Высокопроизводительный кластер (I)
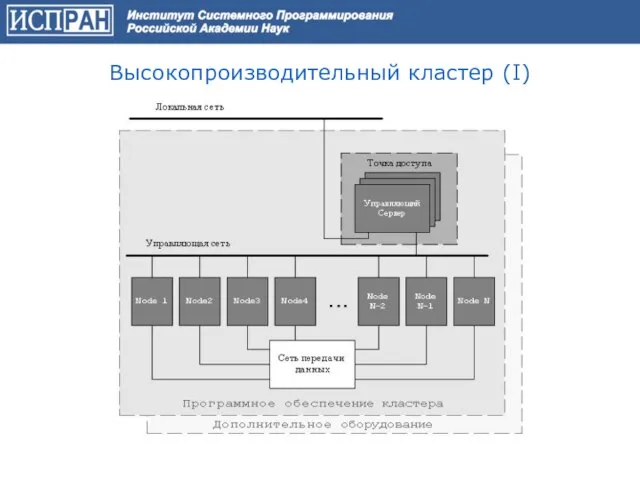
Слайд 7Кластер* строится из стандартных (commodity) аппаратных компонент, на которых установлено стандартное системное
Кластер* строится из стандартных (commodity) аппаратных компонент, на которых установлено стандартное системное

Слайд 8Высокопроизводительный кластер (III)
За счет чего достигается рост производительности:
● рост производительности узлов
● развитие
Высокопроизводительный кластер (III)
За счет чего достигается рост производительности:
● рост производительности узлов
● развитие

Слайд 9Рост производительности процессора
- повышение тактовой частоты и увеличение пропускной способности памяти
- параллелизм
Рост производительности процессора
- повышение тактовой частоты и увеличение пропускной способности памяти
- параллелизм

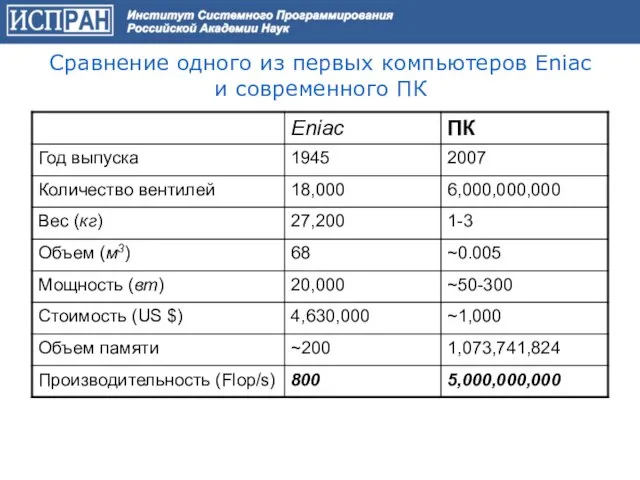
Слайд 10Сравнение одного из первых компьютеров Eniac и современного ПК
Сравнение одного из первых компьютеров Eniac и современного ПК
Слайд 11Архитектура фон Неймана
Один поток вычислений, следующий изначальному порядку команд программы
Каждая команда выполняется
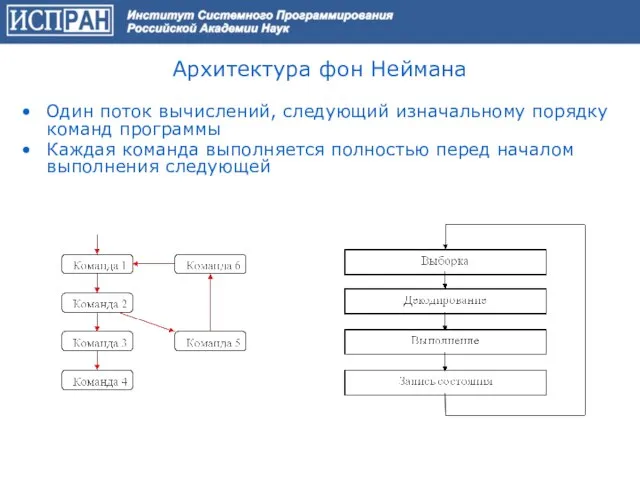
Архитектура фон Неймана
Один поток вычислений, следующий изначальному порядку команд программы
Каждая команда выполняется
Слайд 12Параллелизм на уровне команд (I)
Часто последовательное выполнение является искусственным ограничением
x = y
Параллелизм на уровне команд (I)
Часто последовательное выполнение является искусственным ограничением
x = y

Слайд 13Параллелизм на уровне команд (II)
Подходы к использованию ILP:
Конвейеризация вычислений: параллельно работают
Параллелизм на уровне команд (II)
Подходы к использованию ILP:
Конвейеризация вычислений: параллельно работают

Слайд 14Параллелизм на уровне команд (III)
Архитектура с длинным командным словом:
Компилятор упаковывает команды,
Параллелизм на уровне команд (III)
Архитектура с длинным командным словом:
Компилятор упаковывает команды,

Слайд 15Параллелизм на уровне команд (IV)
Параллелизм по данным (векторизация):
Однотипные операции над элементами вектора
Параллелизм на уровне команд (IV)
Параллелизм по данным (векторизация):
Однотипные операции над элементами вектора

Слайд 16Параллелизм на уровне команд (V)
Возможности использования параллелизма на уровне команд достигли предела!
Улучшение
Параллелизм на уровне команд (V)
Возможности использования параллелизма на уровне команд достигли предела!
Улучшение

Слайд 17Текущий тренд (I)
Производители (Intel, IBM, Sun) сделали ставку на параллелизм через multicore/manycore,
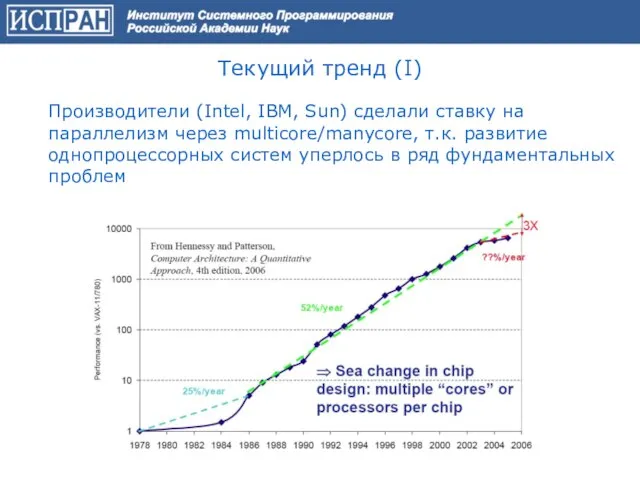
Текущий тренд (I)
Производители (Intel, IBM, Sun) сделали ставку на параллелизм через multicore/manycore,
Слайд 18Текущий тренд (II)
Фундаментальные проблемы:
● Было: энергия дешева, транзисторы дороги
Стало: транзисторы
Текущий тренд (II)
Фундаментальные проблемы:
● Было: энергия дешева, транзисторы дороги
Стало: транзисторы

Слайд 19Текущий тренд (III)
● Расширение спектра задач решаемых с использованием графических акселераторов (Nebulae,
Текущий тренд (III)
● Расширение спектра задач решаемых с использованием графических акселераторов (Nebulae,

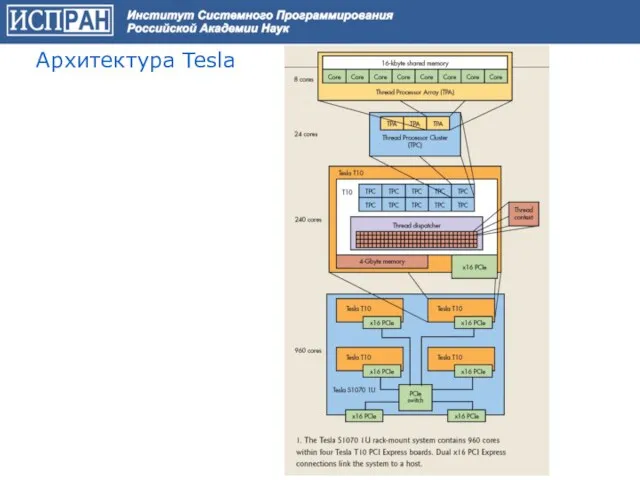
Слайд 20Архитектура Tesla
Архитектура Tesla
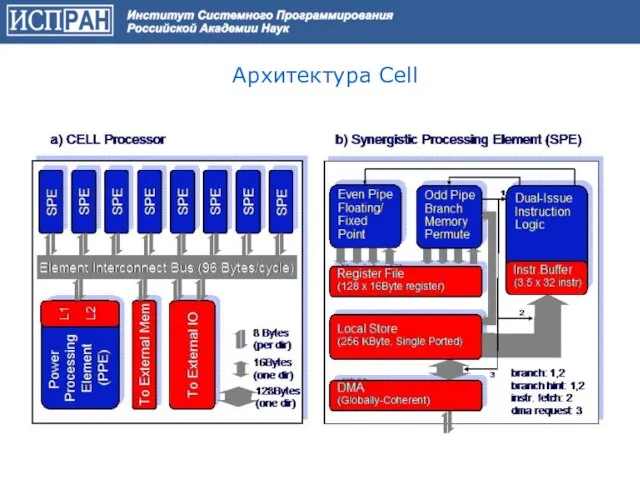
Слайд 21Архитектура Cell
Архитектура Cell
Слайд 22 Проблема: обеспечение высокопродуктивных вычислений (компромисс между стоимостью разработки и сопровождения и эффективностью
Проблема: обеспечение высокопродуктивных вычислений (компромисс между стоимостью разработки и сопровождения и эффективностью

Слайд 23// MPI вариант
while ((iterN--) != 0)
{
for(i = 2; i
// MPI вариант
while ((iterN--) != 0)
{
for(i = 2; i

Слайд 24Средства разработки ПО (III)
Почему HPF не оправдал надежд:
отсутствие компиляторных технологий, позволяющих генерировать
Средства разработки ПО (III)
Почему HPF не оправдал надежд:
отсутствие компиляторных технологий, позволяющих генерировать

Слайд 25 В настоящее время фактическим языковым стандартом разработки промышленных прикладных программ является использование
В настоящее время фактическим языковым стандартом разработки промышленных прикладных программ является использование

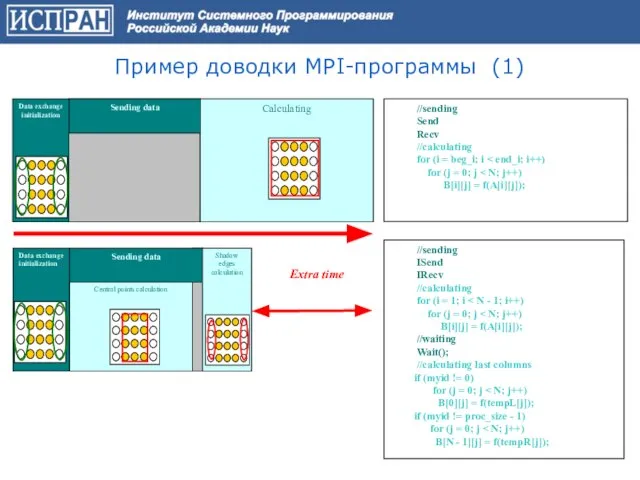
Слайд 26Пример доводки MPI-программы (1)
//sending
Send
Recv
//calculating
for (i = beg_i;
Пример доводки MPI-программы (1)
//sending
Send
Recv
//calculating
for (i = beg_i;
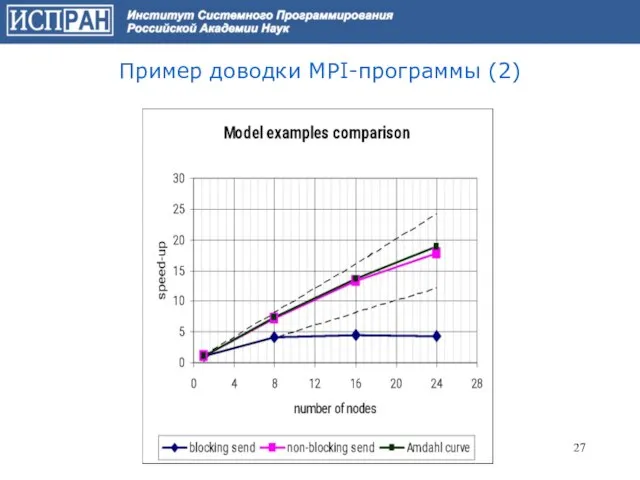
Слайд 27Пример доводки MPI-программы (2)
Пример доводки MPI-программы (2)
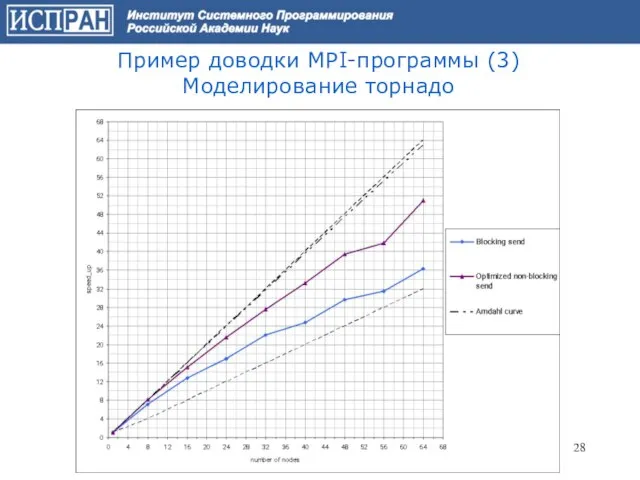
Слайд 28Пример доводки MPI-программы (3)
Моделирование торнадо
Пример доводки MPI-программы (3)
Моделирование торнадо
Слайд 29Эффективные программы для GPU
Необходимо учитывать ряд особенностей
Количество нитей
Загруженность мультипроцессора, зависящая от:
Количества регистров
Эффективные программы для GPU
Необходимо учитывать ряд особенностей
Количество нитей
Загруженность мультипроцессора, зависящая от:
Количества регистров

Слайд 30Разреженные матрицы
Специализированные форматы хранения
Типичная задача – умножение на плотный вектор (SpMV)
2 FLOPS
Разреженные матрицы
Специализированные форматы хранения
Типичная задача – умножение на плотный вектор (SpMV)
2 FLOPS

Слайд 31Предлагаемый формат (“sliced” ELLPACK)
Матрица делится на полоски из строк
Каждая полоска хранится в
Предлагаемый формат (“sliced” ELLPACK)
Матрица делится на полоски из строк
Каждая полоска хранится в

Слайд 32Улучшения алгоритма (I)
Переупорядочивание строк
Хочется расположить рядом строки с одинаковым количеством ненулевых элементов
Дорогая
Улучшения алгоритма (I)
Переупорядочивание строк
Хочется расположить рядом строки с одинаковым количеством ненулевых элементов
Дорогая

Слайд 33Улучшения алгоритма (II)
Параметры реализации:
Зависящие от устройства
Количество строк на полоску
Количество нитей на блок
Зависящие
Улучшения алгоритма (II)
Параметры реализации:
Зависящие от устройства
Количество строк на полоску
Количество нитей на блок
Зависящие

Слайд 34Результаты тестирования
Варианты алгоритма сравниваются с реализацией от NVIDIA как базовой
Тесты – набор
Результаты тестирования
Варианты алгоритма сравниваются с реализацией от NVIDIA как базовой
Тесты – набор

Слайд 35● Создание технологий для классов приложений
● Разработка библиотек и пакетов прикладных программ
●
● Создание технологий для классов приложений
● Разработка библиотек и пакетов прикладных программ
●
Слайд 36Программная модель Map/Reduce
Вычисления производятся над множествами пар (k, v), где k –
Программная модель Map/Reduce
Вычисления производятся над множествами пар (k, v), где k –

Слайд 37// Функция, используемая рабочими узлами на Map-шаге
// для обработки пар ключ-значение из
// Функция, используемая рабочими узлами на Map-шаге
// для обработки пар ключ-значение из

Слайд 38Существуют эффективные масштабируемые реализации MapReduce (компания Google, система Hadoop) в рамках распределенной
Существуют эффективные масштабируемые реализации MapReduce (компания Google, система Hadoop) в рамках распределенной

Слайд 39● Системы автоматизации инженерного анализа (CAE системы)
ANSYS, CFX, LS_DYNA, ICEM CFD, STAR-CD,
● Системы автоматизации инженерного анализа (CAE системы)
ANSYS, CFX, LS_DYNA, ICEM CFD, STAR-CD,

Слайд 40Цели Grid*
Обеспечение возможности решения крупномасштабных научно-технических задач
Организация работы распределенных (административно и географически)
Цели Grid*
Обеспечение возможности решения крупномасштабных научно-технических задач
Организация работы распределенных (административно и географически)

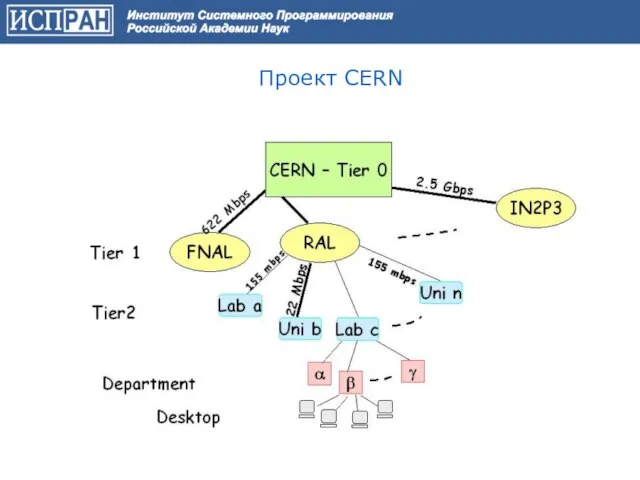
Слайд 41Проект CERN
Проект CERN
Слайд 42Globus Toolkit
Реализует стандарт OGSI
Реализует аутентификацию на основе стандарта X.509
Содержит контейнер Grid служб
Содержит
Globus Toolkit
Реализует стандарт OGSI
Реализует аутентификацию на основе стандарта X.509
Содержит контейнер Grid служб
Содержит

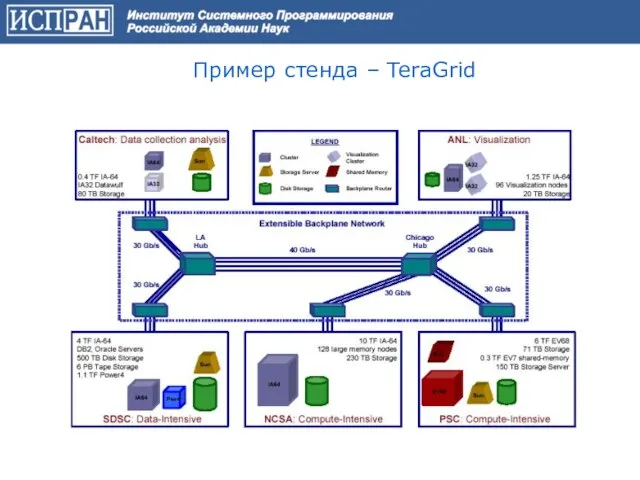
Слайд 43Пример стенда – TeraGrid
Пример стенда – TeraGrid
Слайд 44Концепция «Облачных вычислений»
∙ Все есть сервис (XaaS)
− AaaS: приложения как сервис
−
Концепция «Облачных вычислений»
∙ Все есть сервис (XaaS)
− AaaS: приложения как сервис
−

Слайд 45Компании предлагающие «Облачные» решения
(небольшая выборка)
Ожидаемый рост рынка облачных вычислений к 2015 г.
Компании предлагающие «Облачные» решения
(небольшая выборка)
Ожидаемый рост рынка облачных вычислений к 2015 г.

Слайд 46Примеры внедрения «Облачных» решений
? Nebula – «облачная» платформа NASA
? RACE – частное
Примеры внедрения «Облачных» решений
? Nebula – «облачная» платформа NASA
? RACE – частное

Слайд 47Правительственные инициативы по «Облачным» решениям
? G-Cloud – Правительственное облако Великобритании, которое опирается
Правительственные инициативы по «Облачным» решениям
? G-Cloud – Правительственное облако Великобритании, которое опирается

Слайд 48NEBULA Cloud Computing Platform
Nebula (туманность) – это проект который разрабатывается в Исследовательском
NEBULA Cloud Computing Platform
Nebula (туманность) – это проект который разрабатывается в Исследовательском

Слайд 49Свободное ПО и «Облачные вычисления»
Одно из основных направлений развития
? Стандартный стек
Свободное ПО и «Облачные вычисления»
Одно из основных направлений развития
? Стандартный стек

Слайд 50Почему сейчас?
Создание чрезвычайно крупномасштабных центров обработки данных
- в ~10 раз снижение
Почему сейчас?
Создание чрезвычайно крупномасштабных центров обработки данных - в ~10 раз снижение

Слайд 51Примеры применения
◊ Конвертирование большого количества файлов из одного формата в другой (пакетная
Примеры применения
◊ Конвертирование большого количества файлов из одного формата в другой (пакетная

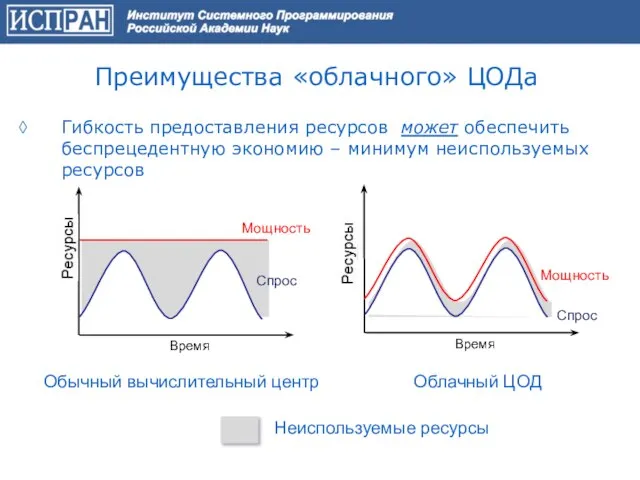
Слайд 52Неиспользуемые ресурсы
Преимущества «облачного» ЦОДа
◊ Гибкость предоставления ресурсов может обеспечить беспрецедентную экономию – минимум
Неиспользуемые ресурсы
Преимущества «облачного» ЦОДа
◊ Гибкость предоставления ресурсов может обеспечить беспрецедентную экономию – минимум
Слайд 53«Облачные вычисления»
в науке и образовании (1)
Возможность создания web-ориентированных лабораторий (хабов) в
«Облачные вычисления»
в науке и образовании (1)
Возможность создания web-ориентированных лабораторий (хабов) в

Слайд 54«Облачные вычисления»
в науке и образовании (2)
◊ Принципиально новые возможности для исследователей
«Облачные вычисления»
в науке и образовании (2)
◊ Принципиально новые возможности для исследователей

Слайд 55Общая схема организации «хаба»
Общая схема организации «хаба»
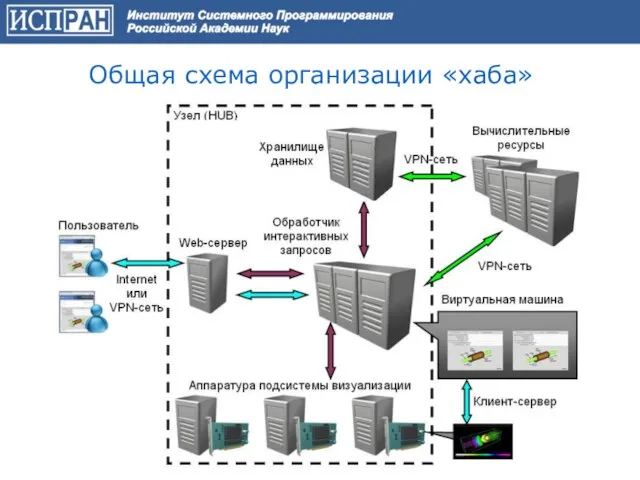
Слайд 56Globus, Condor-G, gLite,…C
Linux, Apache, LDAP, PHP, Joomla, MySQL, Sendna (ИСП РАН), Xen,
Linux, Apache, LDAP, PHP, Joomla, MySQL, Sendna (ИСП РАН), Xen,

Слайд 57«Университетский кластер» (1)
Программа учреждена 4 сентября 2008 года Российской академией наук (ИСП
«Университетский кластер» (1)
Программа учреждена 4 сентября 2008 года Российской академией наук (ИСП

Слайд 58«Университетский кластер» (2)
Для достижения целей Программы решаются
следующие задачи:
- построение, развитие и
«Университетский кластер» (2)
Для достижения целей Программы решаются
следующие задачи:
- построение, развитие и

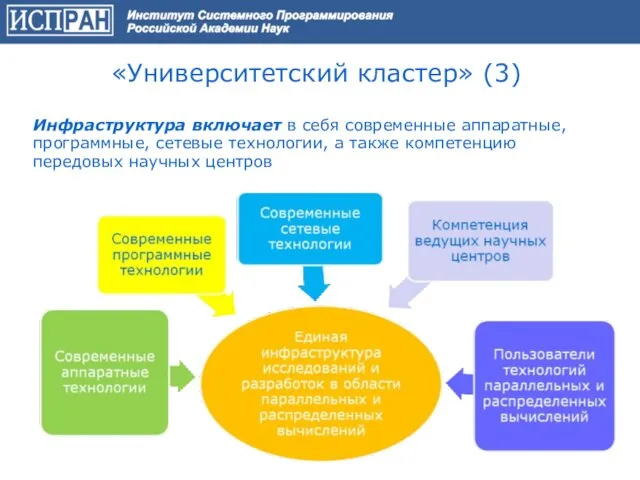
Слайд 59«Университетский кластер» (3)
Инфраструктура включает в себя современные аппаратные, программные, сетевые технологии, а
«Университетский кластер» (3)
Инфраструктура включает в себя современные аппаратные, программные, сетевые технологии, а
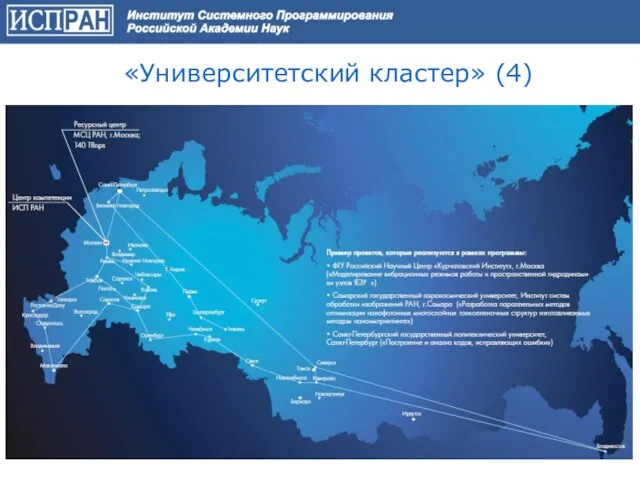
Слайд 60«Университетский кластер» (4)
«Университетский кластер» (4)
Слайд 61«Университетский кластер». Проект OpenCirrus
OpenCirrus был основан компаниями НР, Intel и Yahoo
Цель –
«Университетский кластер». Проект OpenCirrus
OpenCirrus был основан компаниями НР, Intel и Yahoo
Цель –

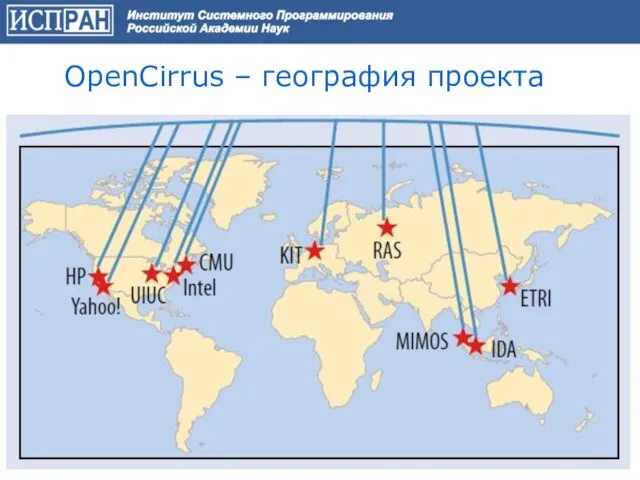
Слайд 62OpenCirrus – география проекта
OpenCirrus – география проекта
Слайд 63«Университетский кластер».
Текущее состояние (1)
Реализованы базовые сетевые службы VPN «Университетский кластер» (служба
«Университетский кластер».
Текущее состояние (1)
Реализованы базовые сетевые службы VPN «Университетский кластер» (служба

Слайд 64«Университетский кластер».
Текущее состояние (2)
ИСП РАН совместно с РНЦ «Курчатовский институт»
«Университетский кластер».
Текущее состояние (2)
ИСП РАН совместно с РНЦ «Курчатовский институт»

Слайд 65 Пакетизация идет с конца 80-х гг.
Универсальные пакеты – PHOENICS, ANSYS, Nastran,
Пакетизация идет с конца 80-х гг.
Универсальные пакеты – PHOENICS, ANSYS, Nastran,

Слайд 66Свободное Программное Обеспечение
Свободное Программное Обеспечение

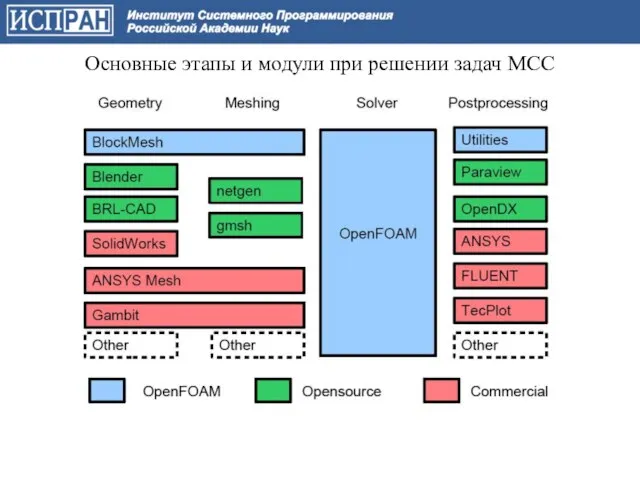
Слайд 67Основные этапы и модули при решении задач МСС
Основные этапы и модули при решении задач МСС
Слайд 68Salome (EDF, CEA, OpenCASCADE)
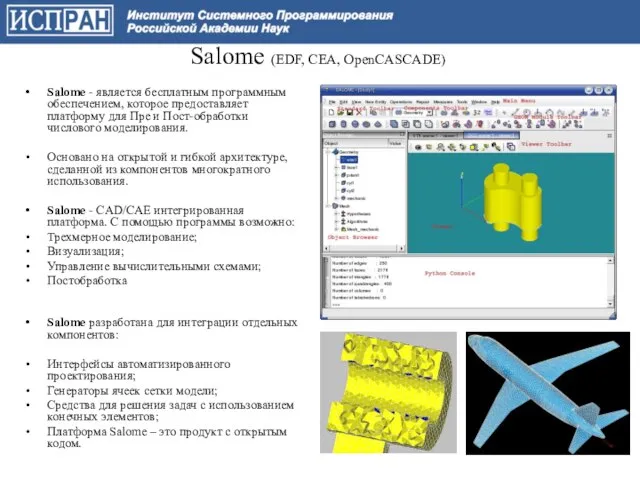
Salome - является бесплатным программным обеспечением, которое предоставляет платформу
Salome (EDF, CEA, OpenCASCADE)
Salome - является бесплатным программным обеспечением, которое предоставляет платформу
Слайд 69ОpenFOAM — свободно распространяемое программное обеспечение для проведения численных расчетов.
OpenFOAM — объектно-ориентированная
OpenFOAM — объектно-ориентированная

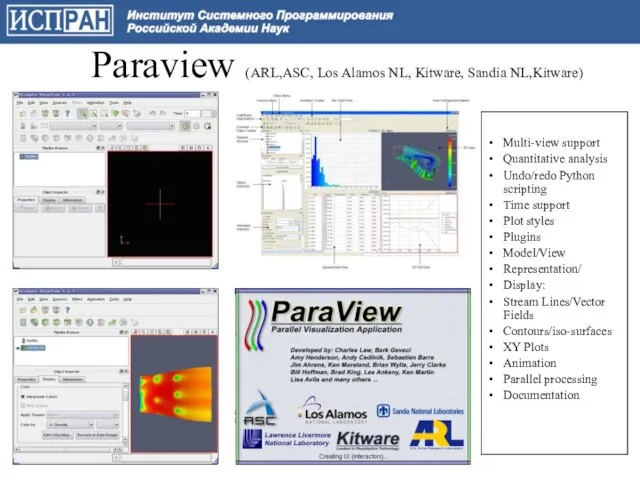
Слайд 70 Paraview (ARL,ASC, Los Alamos NL, Kitware, Sandia NL,Kitware)
Multi-view support
Quantitative analysis
Paraview (ARL,ASC, Los Alamos NL, Kitware, Sandia NL,Kitware)
Multi-view support
Quantitative analysis
 Древний Восток и античный мир (10 класс)
Древний Восток и античный мир (10 класс) KU-3 (Ку три) Система управления мультимедиа тренингами, моделирующими играми и динамическими тестами.
KU-3 (Ку три) Система управления мультимедиа тренингами, моделирующими играми и динамическими тестами. Средства автоматизации при раскрое, облицовывании пластей и кромок
Средства автоматизации при раскрое, облицовывании пластей и кромок Презентация на тему Губки Тупиковая ветвь эволюции
Презентация на тему Губки Тупиковая ветвь эволюции Презентация на тему Рынок труда
Презентация на тему Рынок труда Жүктерді маркировкалау
Жүктерді маркировкалау Основы проектной деятельности
Основы проектной деятельности Шаблон для фотопрезентации
Шаблон для фотопрезентации Шаги процесса изменения
Шаги процесса изменения Модель Суда по интеллектуальным правам
Модель Суда по интеллектуальным правам Белорусская деревообработка
Белорусская деревообработка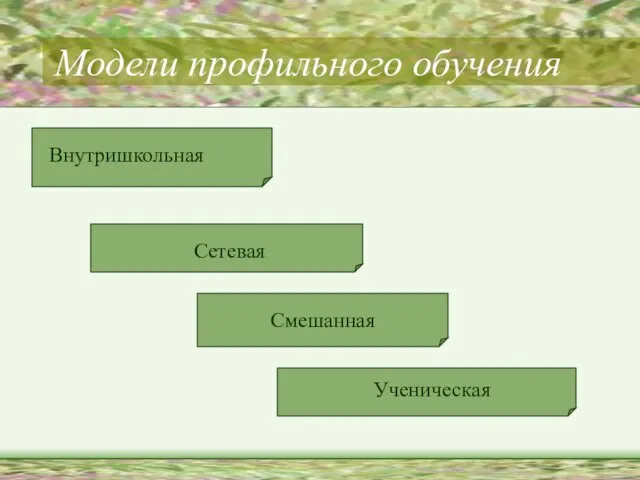 Модели профильного обучения
Модели профильного обучения Синтетический лёд - Agility Ice
Синтетический лёд - Agility Ice ЦЕНТР ОРГАНИЗАЦИОННО-МЕТОДИЧЕСКОГО ОБЕСПЕЧЕНИЯ ФИЗИЧЕСКОГО ВОСПИТАНИЯ «Система столичного мониторинга физической подготовленн
ЦЕНТР ОРГАНИЗАЦИОННО-МЕТОДИЧЕСКОГО ОБЕСПЕЧЕНИЯ ФИЗИЧЕСКОГО ВОСПИТАНИЯ «Система столичного мониторинга физической подготовленн Составление расписаний. Правила назначения приоритетов
Составление расписаний. Правила назначения приоритетов Турбаза Береза
Турбаза Береза Качество и уровень жизни. Бюджет прожиточного минимума. Потребительская корзина
Качество и уровень жизни. Бюджет прожиточного минимума. Потребительская корзина Табличный процессор MS EXCEL
Табличный процессор MS EXCEL Зимнее первенство городского округа Тольятти по футболу среди юношей
Зимнее первенство городского округа Тольятти по футболу среди юношей Проектно-конструкторская служба химического производства
Проектно-конструкторская служба химического производства Презентация на тему Наш дом и Родина - Россия
Презентация на тему Наш дом и Родина - Россия English test
English test Опыт реализации системы контентной фильтрации Интернет-ресурсов на базе технологий АРИОН
Опыт реализации системы контентной фильтрации Интернет-ресурсов на базе технологий АРИОН Каким будет для Вас год
Каким будет для Вас год Сувенирная реклама. Занятие 7
Сувенирная реклама. Занятие 7 Цветотипы
Цветотипы ВОДА
ВОДА Филиал московского университета имени С.Ю. Витте в г. Сергиев Посад, для выпускников 9 классов
Филиал московского университета имени С.Ю. Витте в г. Сергиев Посад, для выпускников 9 классов