- Универсальные микропроцессоры

Содержание
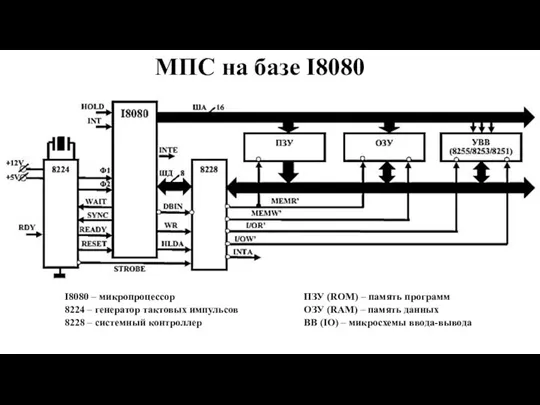
- 2. МПС на базе I8080 I8080 – микропроцессор 8224 – генератор тактовых импульсов 8228 – системный контроллер
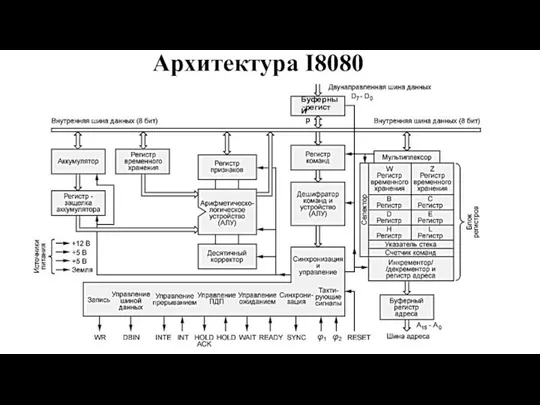
- 3. Архитектура I8080 Буферный регистр
- 4. A0 - A15: выводы шины адреса с тремя состояниями; D0 - D7: двунаправленная шина данных с
- 5. Регистры общего назначения (РОН) Формат регистра признаков (F) Универсальный регистр (А) участвует в большинстве операций, накапливает
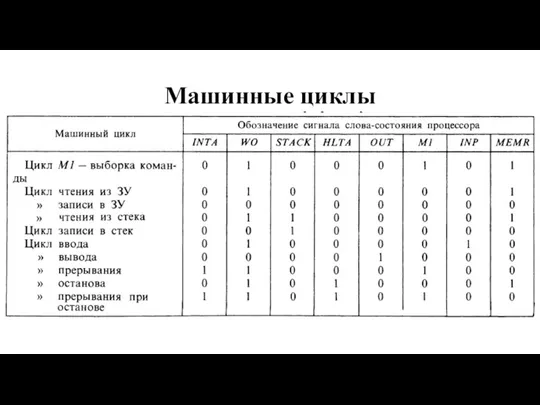
- 6. Машинные циклы
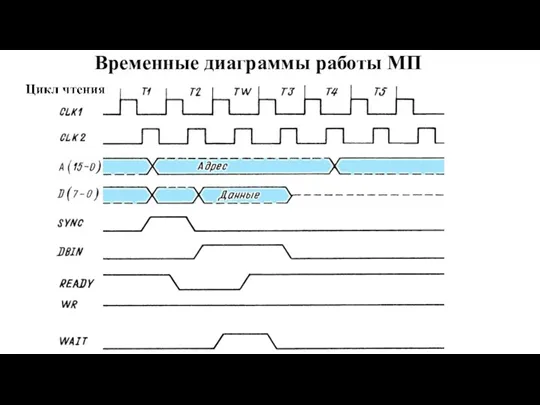
- 7. Временные диаграммы работы МП
- 9. Способы адресации
- 10. БИС параллельного интерфейса I8255
- 11. Подключение контактного датчика
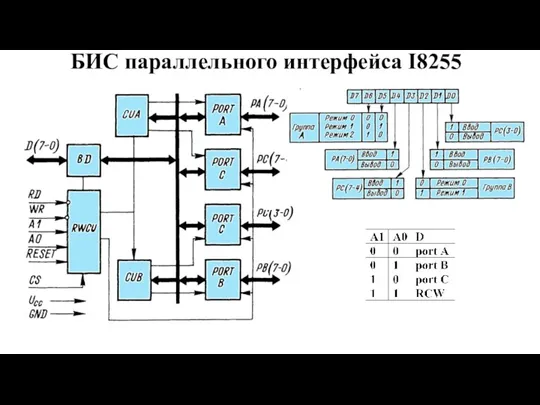
- 12. Подключение аналоговых датчиков к МП
- 13. БИС программируемого таймера I8253
- 14. БИС последовательного интерфейса I8251
- 16. БИС контроллера прерываний I8259
- 17. Intel 8086
- 18. Сегментные и индексные регистры
- 21. ВРЕМЕННЫЕ ДИАГРАММЫ РАБОТЫ В МИНИМАЛЬНОМ РЕЖИМЕ
- 23. 2014, 3–й квартал: 14 нм, Core M, i3, i5, i7 — Broadwell 2015, 3–й квартал: 14
- 24. ОКОД (SISD – single instruction stream / single data stream) одиночный поток команд, одиночный поток данных.
- 25. Структура современного микропроцессора предполагает наличие порядка десяти обрабатывающих устройств, каждое из которых представляет собой конвейер. Загрузка
- 26. Микропроцессор с разнесенной архитектурой Расщепление общей программы на программы для А- и Е- процессоров осуществляется на
- 27. два направления развития микропроцессоров RISC и CISC RISC (Reduced Instruction Set Computer) удалены сложные и редко
- 28. Обзор на примере семейства х86 1978 - Intel первый 16-разрядный процессор с маркировкой «8086», тактовая частота
- 29. 1985 - 80386, первый полностью 32-битным процессор. 275000 транзисторов, частота от 16 до 32 МГц. Максимальный
- 30. 1999 - ядро Katmai - введено расширение SSE (Streaming SIMD Extensions), инструкции одновременно над группой операндов
- 31. 2000 - Pentium 4 (Willamette), 0,18 мкм технология, 42 млн. транзисторов на кристалле, частоты от 1.4
- 33. БФА (блок формирования адреса) – формирует адреса выбираемых из памяти операндов, организуя связь с кэш-памятью данных
- 34. Система команд 80х86 подразделяется на группы: • команды передачи данных; • команды арифметических операций над целыми
- 35. Регистровая адресация – операнды могут находиться в любых регистрах общего назначения и сегментных. Непосредственная адресация –
- 36. Формат команд Поле префиксов может содержать префикс повторения команды или префикс запрета доступа к шине на
- 37. Архитектурные признаки IBM PC-совместимого компьютера ESCD (Extended System Configuration Data) —спецификация стандарта конфигурирования компьютеров х86 SMRAM
- 38. Ядро: один или несколько микропроцессоров, программно совместимых с х86; оперативная память; ПЗУ с BIOS; связующие их
- 39. Архитектурные построения системных плат Шинно-мостовая – наличие центральной магистральной шины и подключение к ней через мосты
- 40. Шинно-мостовая архитектура
- 41. Хабовая архитектура
- 42. Архитектура Hyper Transport
- 43. Компоненты и потоки данных на системной плате
- 44. Типы и характеристики интерфейсов Интерфейс – это аппаратное и программное обеспечение (элементы соединения и вспомогательные схемы
- 45. Архитектура системных интерфейсов Системный интерфейс выполняется в виде стандартизированных системных шин. Возможно внедрение сетевого взаимодействия в
- 46. Система с низкоскоростной шиной устройств ввода/вывода
- 47. Система на основе PCI
- 48. Сравнение топологий PCI и PCI Express
- 49. Порт параллельного интерфейса был введен в PC для подключения принтера –LPT-порт (Line PrinTer – построчный принтер);
- 50. Универсальный внешний последовательный интерфейс СОМ- порт (Communications Port) – коммуникационный порт; обеспечивает асинхронный обмен по стандарту
- 51. Стандарты последовательных интерфейсов
- 52. FireWire и USB последовательные соединения с возможностью коммутации при работающей системе большого количества периферийных устройств –
- 53. USB (Universal Serial Bus) – универсальная последовательная шина, промышленный стандарт расширения архитектуры PC кабель USB –
- 54. Транзакции с устройствами USB Поток (stream) однонаправленно доставляет данные от одного конца канала к другому, реализует
- 55. Интерфейсы локальных сетей организуются посредством сетевых адаптеров, или сетевых интерфейсных карт, Network Interface Card (NIC) Ethernet
- 56. Взаимодействие процессора с памятью Иерархическая организация памяти помогает компенсировать разницу в быстродействии процессоров и скорости доступа
- 57. Организация кэш-памяти (Cache memory) кэш для инструкций и данных может быть раздельный и общий в смешанной
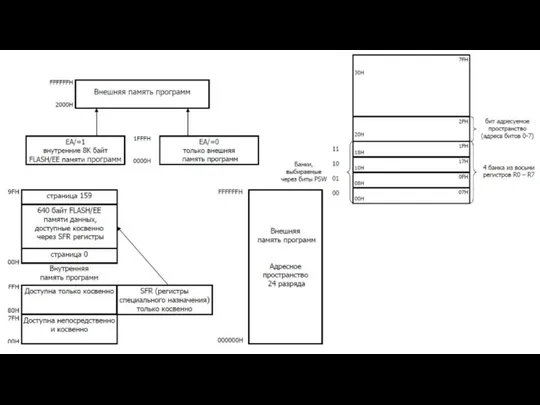
- 58. Логическое распределение пространства оперативной и постоянной физической памяти . • 00000h-9FFFFh (640 Кбайт) – стандартная, или
- 59. Режим прямого доступа к памяти (Direct Memory Access, DMA) пассивный доступ (Slave DMA) – устройство при
- 60. Внешняя память энергонезависимые устройства хранения данных, позволяющие сохранять информацию для последующего использования и реализующие различные физические
- 61. Виртуальная память использование иерархической организации системы памяти с непрерывным адресным пространством; системное программное обеспечение связывает каждое
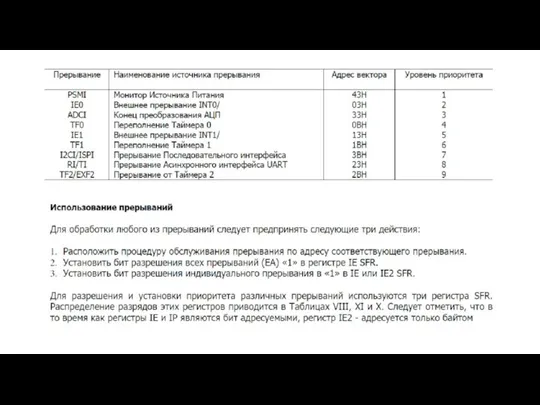
- 62. ТИПЫ ПРЕРЫВАНИЙ внутренние прерывания – реакция на возникшие внутренние проблемные события; аппаратные прерывания – запрос посылает
- 63. Аппаратные прерывания в порядке убывания приоритета
- 64. Коммутация запросов прерываний для реализаций системы прерываний процессоры Pentium и выше имеют встроенный контроллер прерываний APIC
- 65. Методы оценки производительности производительность – скорость появления некоторого числа событий в секунду. время выполнения заданной программы
- 66. Что влияет на производительность Применение конвейерной обработки, когда несколько последовательных команд находятся на разных стадиях выполнения,
- 67. Для оценки и сравнения систем используются следующие критерии: • Пиковая производительность – теоретический максимум быстродействия компьютера
- 68. Тестовая оценка производительности Тесты производителей – предназначены для оценки выпускаемых процессоров, ориентированы на сравнение ограниченного множества
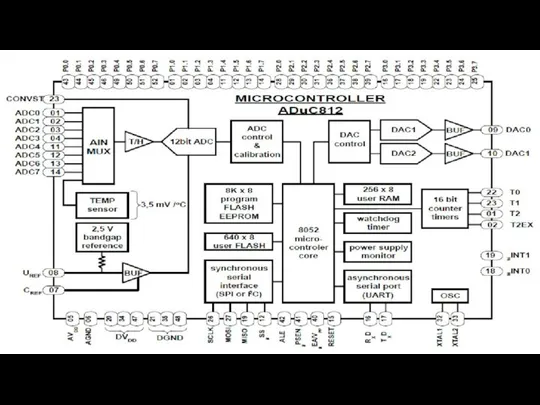
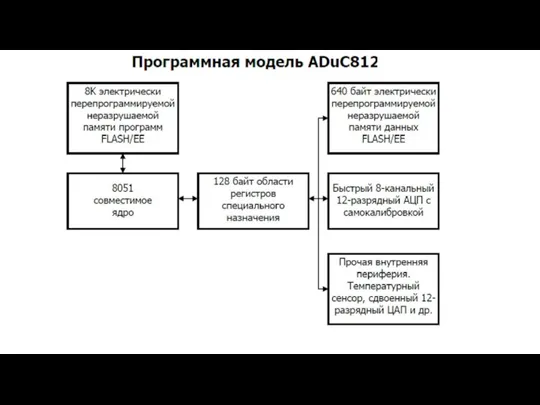
- 69. ОДНОКРИСТАЛЬНЫЕ МИКРОКОНТРОЛЛЕРЫ
- 70. Представители семейства мк ПЗУ (кБ) ОЗУ (Б) stanby реж. линий вв кол-во выводов примечания 8020 1
- 71. Универсальный периферийный интерфейс (UPI) Обозначение Встроенное ПЗУ (кВ) Встроенное ОЗУ (B) Примечания 8041 1 64 8041AH
- 73. Схемы синхронизации Начальная установка
- 74. Архитектура I8748
- 75. Слово состояния Типы команд
- 76. Карта памяти
- 77. Подключение внешней памяти программ
- 78. Подключение внешней памяти данных
- 79. Ввод информации от аналогового датчика
- 80. 3 Vcc Подключение контактных датчиков
- 81. Подавление дребезга контакта аппаратный и программные способы
- 82. 5 Подключение импульсного датчика 1
- 83. Подключение клавиатуры
- 84. Формирование и измерение временных интервалов вложенным циклом где Т – реализуемый временной интервал в микросекундах =
- 85. Формирование и измерение временных интервалов с использованием таймера
- 86. Передача в последовательном коде
- 87. Приём последовательного кода
- 88. Контроль паритета после выполнения программы аккумулятор сохранит своё значение, флаг пользователя (в состава PSW) будет установлен,
- 89. MCS 51
- 90. Микроконтроллеры семейства MCS 51 и его аналоги
- 91. • U — потенциал общего провода ("земли"); • U— основное напряжение литания +5 В; • X1,X2
- 92. Архитектура Intel 8751
- 93. Устройство управления и синхронизации Кварцевый резонатор, подключаемый к внешним выводам микроконтроллера, управляет работой внутреннего генератора, который
- 94. Организация ОЗУ, ПЗУ и регистров Объем резидентной ПП – 4 Кбайт. При обращении к внешней памяти
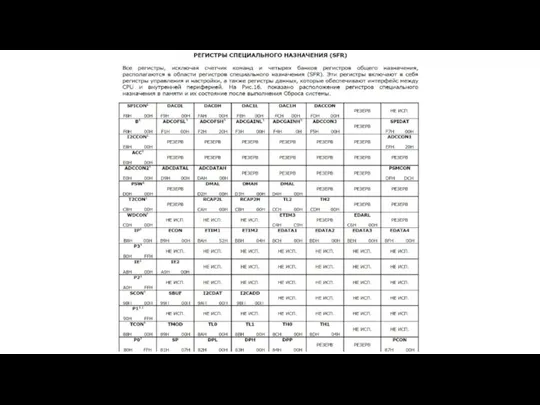
- 95. Регистры специальных функций (Special Function Register)
- 96. Карта адресуемых бит в блоке регистров специальных функций Карта адресуемых бит в РПД
- 97. Регистр флагов (PSW)
- 98. Схемотехника портов ввода-вывода мс51, а- порт 0, б- порт 3
- 99. Альтернативные функции порта Р3 активируются предварительной записью «1» в соответствующие биты порта
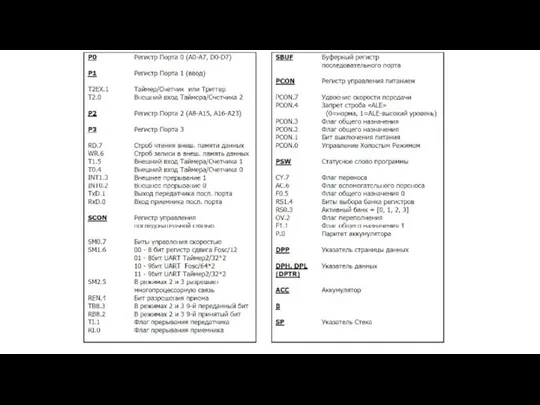
- 100. Таймеры / счетчики мс51 два программируемых 16-битных таймера/счетчика (T/C0 и T/C1), могут быть использованы как в
- 101. Регистр режима работы таймера/счетчика (TMOD)
- 102. Регистр управления/статуса таймера (TCON)
- 103. Режимы работы таймеров-счетчиков для Т/С0 и Т/С1 режимы работы 0, 1 и 2 одинаковы, режимы 3
- 104. Режим 2: работа организована таким образом, что переполнение TL приводит не только к установке флага TF,
- 105. Режим 3: Т/С1 сохраняет неизменным свое текущее содержимое, так же как и при сбросе управляющего бита
- 106. Универсальный асинхронный приемопередатчик UART (Universal Asynchronous ReceiverTransmitter) прием и передача информации в последовательном коде младшими битами
- 107. Режимы работы УАПП Режим 0. Информация и передается, и принимается через вывод входа приемника (RхD). Принимаются
- 108. УАПП в режиме 0
- 109. УАПП в режимах 1, 2, 3
- 110. Регистр управления/статуса приемопередатчика (SCON)
- 111. Скорость приема/передачи информации через последовательный порт. частота работы приемопередатчика в режиме 0: зависит только от резонансной
- 112. Настройка таймера 1 для управления частотой работы приемопередатчика
- 113. Регистр управления мощностью (PCON)
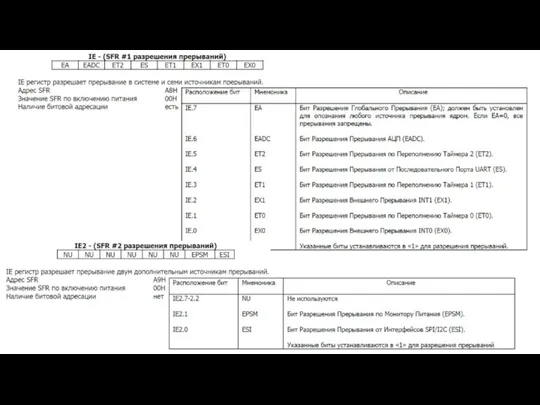
- 114. Система прерываний mc51
- 115. Регистр масок прерывания (IE)
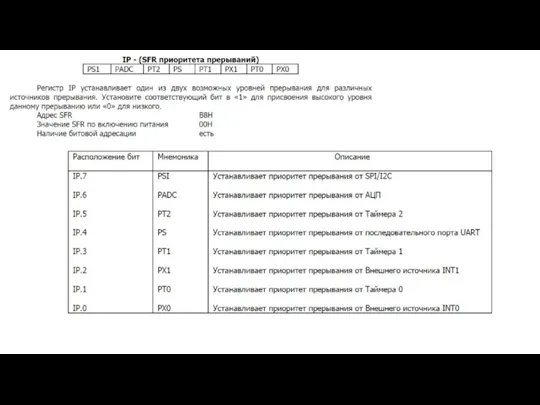
- 116. Регистр приоритетов прерываний (IP)
- 117. Система команд mс51 111 базовых команд, по функциональному признаку подразделяются на группы команд: пересылки данных; арифметических
- 118. Режимы адресации Прямая адресация (Direct Addressing) операнд определяется 8-битным адресом в инструкции, используется только для внутренней
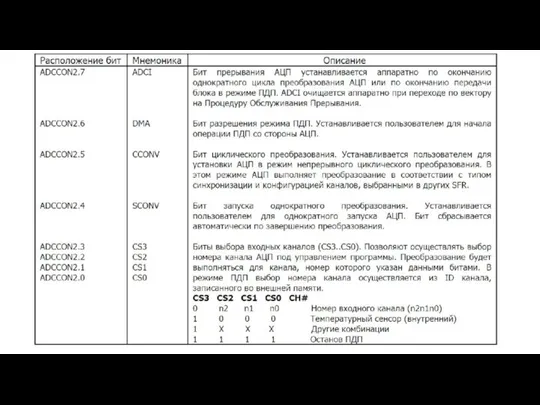
- 120. PCA (Programmable Counter Array) имеется у моделей 80C51FA, 80C51FB, 80С51 РС и 80C51GB обеспечивает большие "временные"
- 122. Структурная схема РСА таймера-счетчика
- 123. Регистр режимов PCA таймера-счетчика (CMOD)
- 124. Регистр управления РСА таймером-счетчиком (CCON)
- 125. Регистр режимов модуля сравнения захвата (ССАРМn)
- 126. Режимы работы РСА комбинации битов регистра ССАРМn, соответствующие различным режимам работы модуля сравнения-захвата
- 127. Режим захвата рекомендуется использовать при измерении периодов, длительности, скважности импульсов, разности фаз между различными входами; Установка
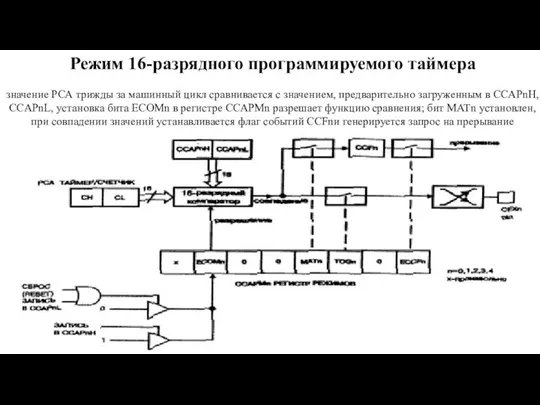
- 128. Режим 16-разрядного программируемого таймера значение РСА трижды за машинный цикл сравнивается с значением, предварительно загруженным в
- 129. Режим скоростного вывода формируется сигнал на внешнем выводе СЕХn, когда происходит совпадение РСА таймера со значением,
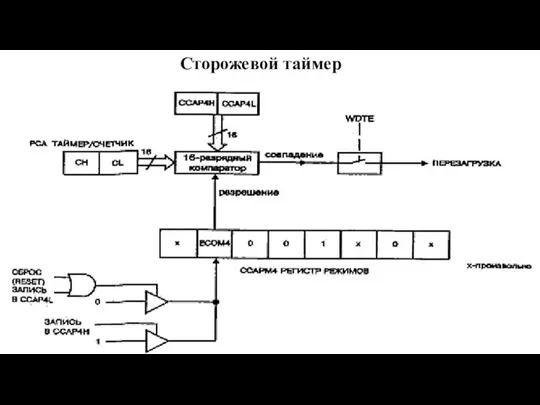
- 130. Режим сторожевого таймера (watchdog timer) Сторожевой таймер - это схема, которая автоматически сбрасывает микроконтроллер, если не
- 131. Сторожевой таймер
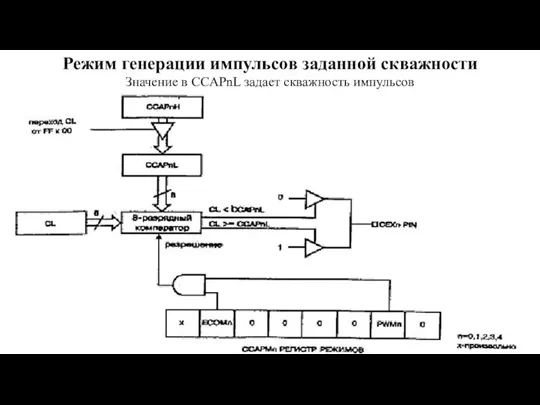
- 132. Режим генерации импульсов заданной скважности Значение в CCAPnL задает скважность импульсов
- 133. Аналого-цифровой преобразователь АЦП микроконтроллера в семействе MCS-51/52 (например, типа SAB 80515 фирмы Siemens или 80C51GB) обеспечивает
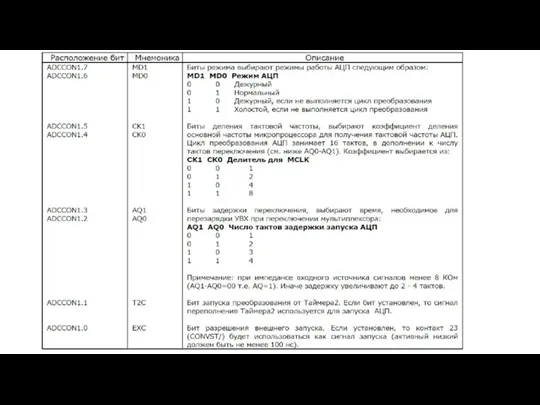
- 134. ADCON (регистр управления преобразователем) адрес - 0D8H, возможна побитовая адресация используется, чтобы • выбрать один из
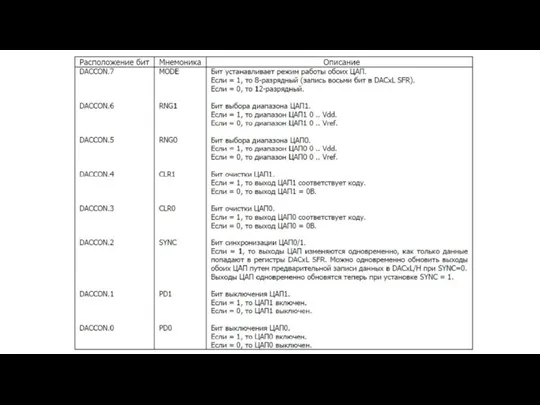
- 136. DAPR (регистр программирования опорных напряжений АЦП). Регистр DAPR позволяет менять внутренние опорные напряжения IVAREF и IVAGND.
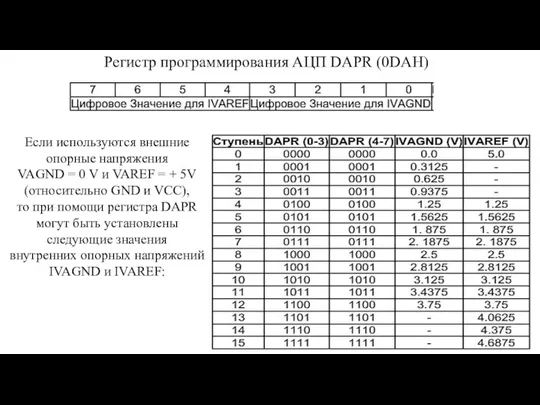
- 137. Регистр программирования АЦП DAPR (0DAH) Если используются внешние опорные напряжения VAGND = 0 V и VAREF
- 182. Скачать презентацию
Слайд 3Архитектура I8080
Буферный
регистр
Архитектура I8080
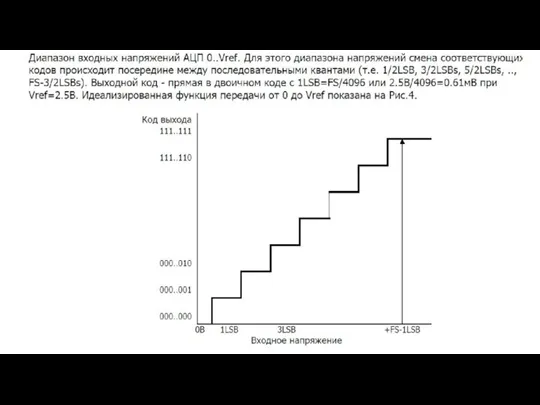
Буферный
регистр
Слайд 4A0 - A15: выводы шины адреса с тремя состояниями;
D0 - D7: двунаправленная
A0 - A15: выводы шины адреса с тремя состояниями;
D0 - D7: двунаправленная

Слайд 5Регистры общего назначения (РОН)
Формат регистра признаков (F)
Универсальный регистр (А)
участвует в
Регистры общего назначения (РОН)
Формат регистра признаков (F)
Универсальный регистр (А)
участвует в

Слайд 6Машинные циклы
Машинные циклы
Слайд 7Временные диаграммы работы МП
Временные диаграммы работы МП
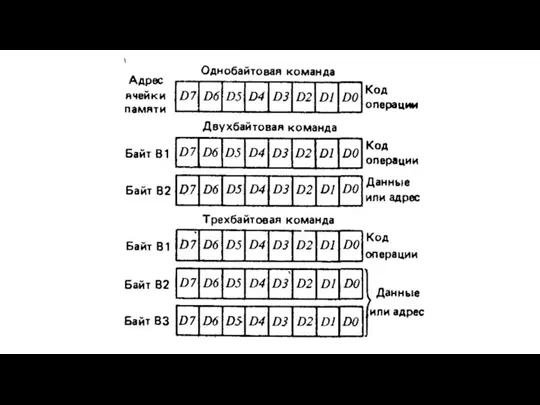
Слайд 9Способы адресации
Способы адресации
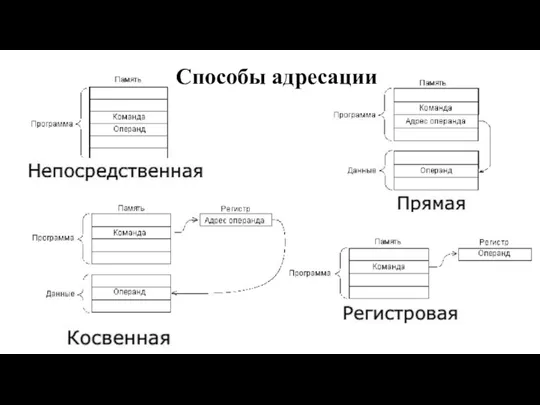
Слайд 10БИС параллельного интерфейса I8255
БИС параллельного интерфейса I8255
Слайд 11Подключение контактного датчика
Подключение контактного датчика

Слайд 12Подключение аналоговых датчиков к МП
Подключение аналоговых датчиков к МП
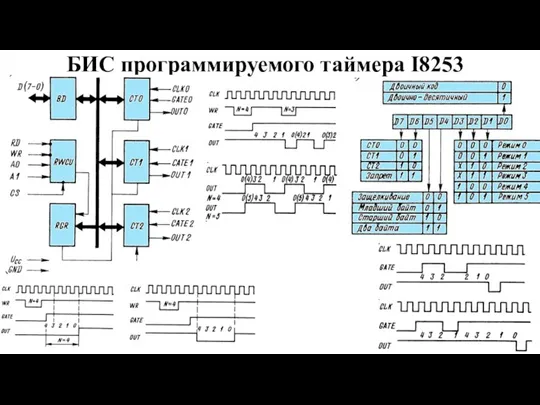
Слайд 13БИС программируемого таймера I8253
БИС программируемого таймера I8253
Слайд 14БИС последовательного интерфейса I8251
БИС последовательного интерфейса I8251
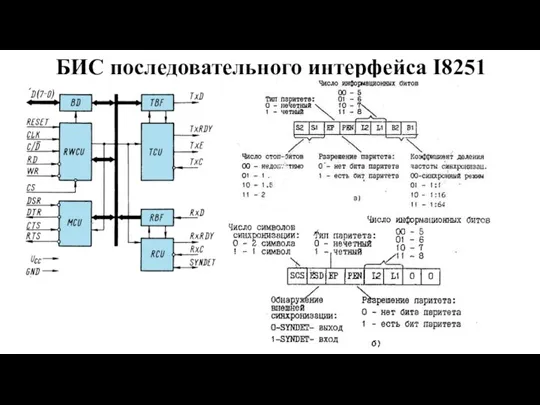
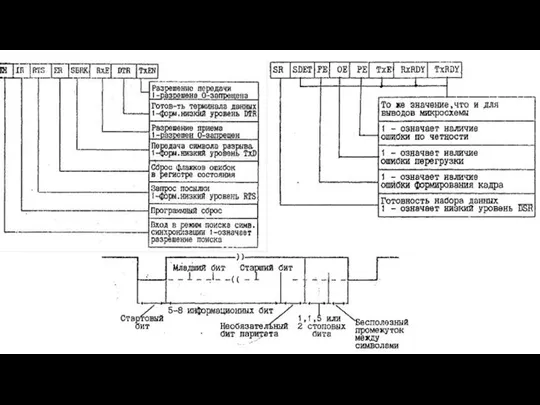
Слайд 16БИС контроллера прерываний I8259
БИС контроллера прерываний I8259

Слайд 17Intel 8086
Intel 8086
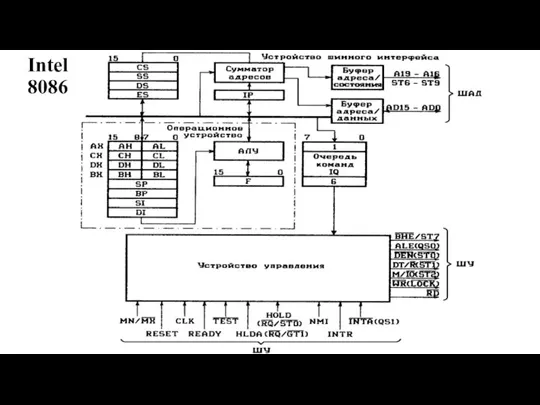
Слайд 18Сегментные и индексные регистры
Сегментные и индексные регистры



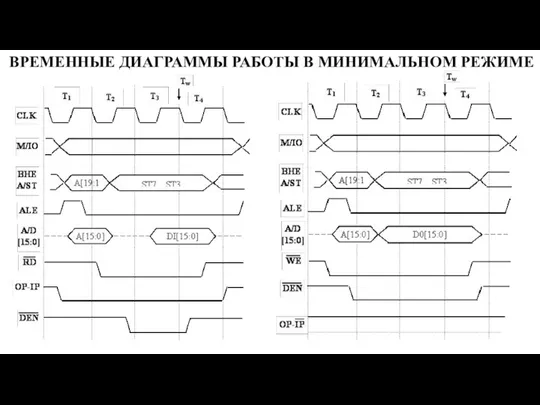
Слайд 21ВРЕМЕННЫЕ ДИАГРАММЫ РАБОТЫ В МИНИМАЛЬНОМ РЕЖИМЕ
ВРЕМЕННЫЕ ДИАГРАММЫ РАБОТЫ В МИНИМАЛЬНОМ РЕЖИМЕ

Слайд 232014, 3–й квартал: 14 нм, Core M, i3, i5, i7 — Broadwell
2015,
2014, 3–й квартал: 14 нм, Core M, i3, i5, i7 — Broadwell
2015,

Слайд 24ОКОД (SISD – single instruction stream / single data stream) одиночный поток
ОКОД (SISD – single instruction stream / single data stream) одиночный поток

Слайд 25Структура современного микропроцессора предполагает наличие порядка десяти обрабатывающих устройств, каждое из которых
Структура современного микропроцессора предполагает наличие порядка десяти обрабатывающих устройств, каждое из которых

Слайд 26Микропроцессор с разнесенной архитектурой
Расщепление общей программы на программы для А- и Е-
Микропроцессор с разнесенной архитектурой
Расщепление общей программы на программы для А- и Е-

Слайд 27два направления развития микропроцессоров
RISC и CISC
RISC (Reduced Instruction Set Computer)
удалены сложные и
два направления развития микропроцессоров
RISC и CISC
RISC (Reduced Instruction Set Computer)
удалены сложные и

Слайд 28Обзор на примере семейства х86
1978 - Intel первый 16-разрядный процессор с маркировкой
Обзор на примере семейства х86
1978 - Intel первый 16-разрядный процессор с маркировкой

Слайд 291985 - 80386, первый полностью 32-битным процессор. 275000 транзисторов, частота от 16
1985 - 80386, первый полностью 32-битным процессор. 275000 транзисторов, частота от 16

Слайд 301999 - ядро Katmai - введено расширение SSE (Streaming SIMD Extensions), инструкции
1999 - ядро Katmai - введено расширение SSE (Streaming SIMD Extensions), инструкции

Слайд 312000 - Pentium 4 (Willamette), 0,18 мкм технология, 42 млн. транзисторов на
2000 - Pentium 4 (Willamette), 0,18 мкм технология, 42 млн. транзисторов на

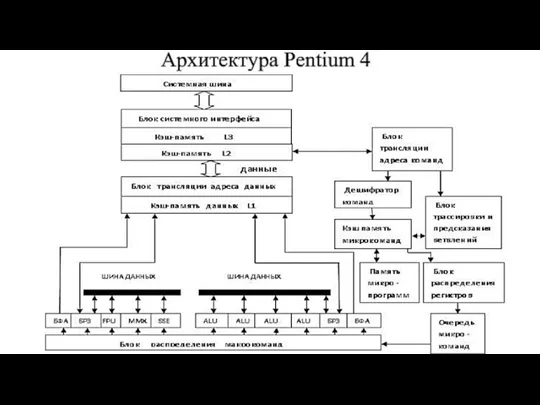
Слайд 33БФА (блок формирования адреса) –
формирует адреса выбираемых из памяти операндов,
организуя
БФА (блок формирования адреса) –
формирует адреса выбираемых из памяти операндов,
организуя

Слайд 34Система команд 80х86
подразделяется на группы:
• команды передачи данных;
• команды арифметических операций
Система команд 80х86
подразделяется на группы:
• команды передачи данных;
• команды арифметических операций

Слайд 35Регистровая адресация –
операнды могут находиться в любых регистрах общего назначения и
Регистровая адресация –
операнды могут находиться в любых регистрах общего назначения и

Слайд 36Формат команд
Поле префиксов может содержать префикс повторения команды или префикс запрета доступа
Формат команд
Поле префиксов может содержать префикс повторения команды или префикс запрета доступа

Слайд 37Архитектурные признаки IBM PC-совместимого компьютера
ESCD (Extended System Configuration Data) —спецификация стандарта конфигурирования
Архитектурные признаки IBM PC-совместимого компьютера
ESCD (Extended System Configuration Data) —спецификация стандарта конфигурирования
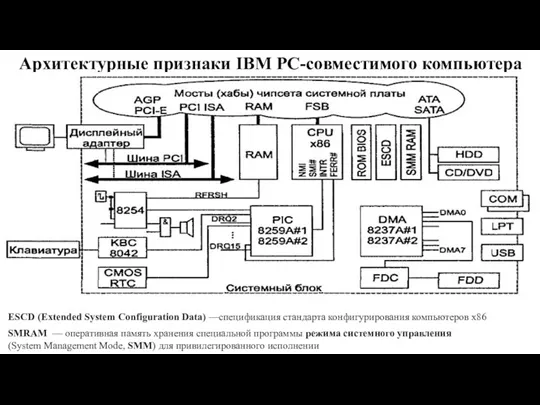
Слайд 38Ядро:
один или несколько микропроцессоров, программно совместимых с х86; оперативная память; ПЗУ
Ядро:
один или несколько микропроцессоров, программно совместимых с х86; оперативная память; ПЗУ

Слайд 39Архитектурные построения системных плат
Шинно-мостовая –
наличие центральной магистральной шины и подключение к ней
Архитектурные построения системных плат
Шинно-мостовая –
наличие центральной магистральной шины и подключение к ней

Слайд 40Шинно-мостовая архитектура
Шинно-мостовая архитектура
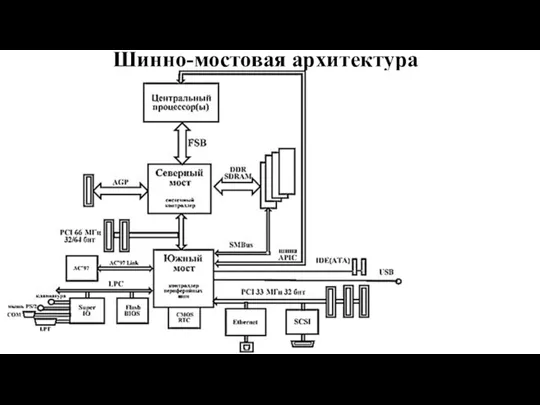
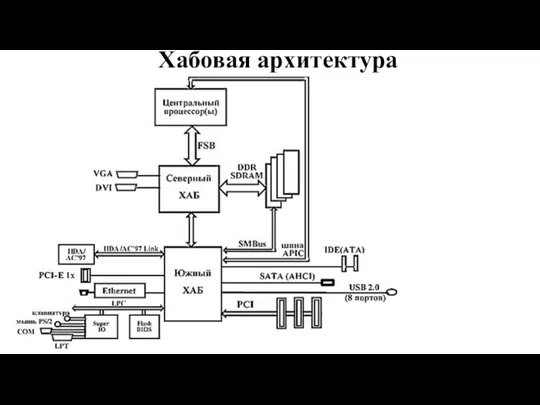
Слайд 41Хабовая архитектура
Хабовая архитектура
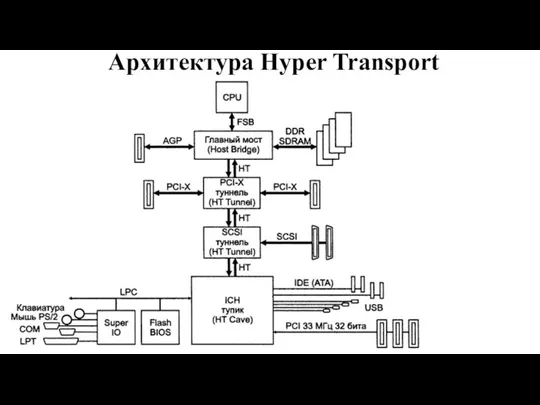
Слайд 42Архитектура Hyper Transport
Архитектура Hyper Transport
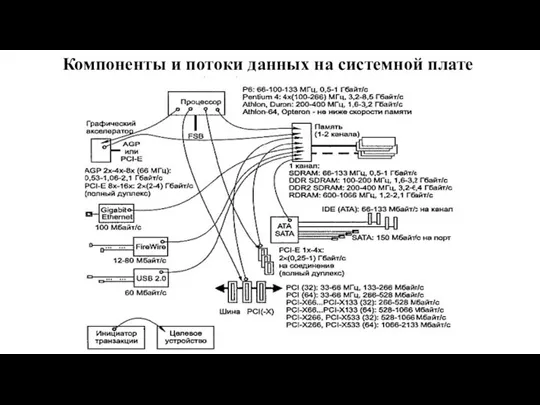
Слайд 43Компоненты и потоки данных на системной плате
Компоненты и потоки данных на системной плате
Слайд 44Типы и характеристики интерфейсов
Интерфейс –
это аппаратное и программное обеспечение
(элементы соединения
Типы и характеристики интерфейсов
Интерфейс –
это аппаратное и программное обеспечение
(элементы соединения

Слайд 45Архитектура системных интерфейсов
Системный интерфейс выполняется в виде стандартизированных системных шин.
Возможно внедрение
Архитектура системных интерфейсов
Системный интерфейс выполняется в виде стандартизированных системных шин.
Возможно внедрение

Слайд 46Система с низкоскоростной шиной устройств ввода/вывода
Система с низкоскоростной шиной устройств ввода/вывода
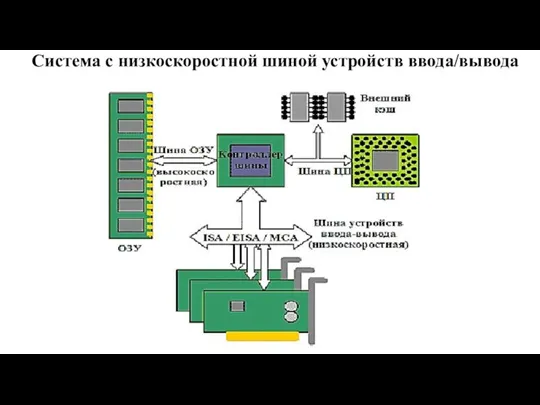
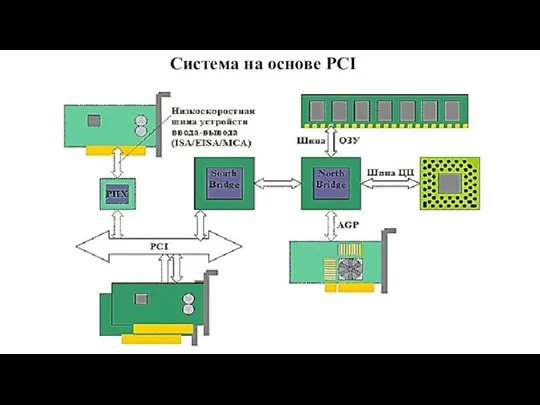
Слайд 47Система на основе PCI
Система на основе PCI
Слайд 48Сравнение топологий PCI и PCI Express
Сравнение топологий PCI и PCI Express

Слайд 49Порт параллельного интерфейса
был введен в PC для подключения принтера –LPT-порт (Line
Порт параллельного интерфейса
был введен в PC для подключения принтера –LPT-порт (Line

Слайд 50Универсальный внешний последовательный интерфейс
СОМ- порт (Communications Port) – коммуникационный порт;
обеспечивает
Универсальный внешний последовательный интерфейс
СОМ- порт (Communications Port) – коммуникационный порт;
обеспечивает

Слайд 51Стандарты последовательных интерфейсов
Стандарты последовательных интерфейсов

Слайд 52FireWire и USB
последовательные соединения с возможностью коммутации при работающей системе большого количества
FireWire и USB
последовательные соединения с возможностью коммутации при работающей системе большого количества

Слайд 53USB
(Universal Serial Bus) – универсальная последовательная шина,
промышленный стандарт расширения архитектуры
USB
(Universal Serial Bus) – универсальная последовательная шина,
промышленный стандарт расширения архитектуры

Слайд 54Транзакции с устройствами USB
Поток (stream)
однонаправленно доставляет данные от одного конца канала
Транзакции с устройствами USB
Поток (stream)
однонаправленно доставляет данные от одного конца канала

Слайд 55Интерфейсы локальных сетей
организуются посредством сетевых адаптеров,
или сетевых интерфейсных карт, Network Interface
Интерфейсы локальных сетей
организуются посредством сетевых адаптеров,
или сетевых интерфейсных карт, Network Interface

Слайд 56Взаимодействие процессора с памятью
Иерархическая организация памяти
помогает компенсировать разницу в быстродействии процессоров
Взаимодействие процессора с памятью
Иерархическая организация памяти
помогает компенсировать разницу в быстродействии процессоров

Слайд 57Организация кэш-памяти (Cache memory)
кэш для инструкций и данных может быть раздельный и
Организация кэш-памяти (Cache memory)
кэш для инструкций и данных может быть раздельный и

Слайд 58Логическое распределение пространства
оперативной и постоянной физической памяти
.
• 00000h-9FFFFh (640 Кбайт)
Логическое распределение пространства
оперативной и постоянной физической памяти
.
• 00000h-9FFFFh (640 Кбайт)

Слайд 59Режим прямого доступа к памяти
(Direct Memory Access, DMA)
пассивный доступ (Slave DMA) –
устройство
Режим прямого доступа к памяти
(Direct Memory Access, DMA)
пассивный доступ (Slave DMA) –
устройство

Слайд 60Внешняя память
энергонезависимые устройства хранения данных,
позволяющие сохранять информацию для последующего использования
и
Внешняя память
энергонезависимые устройства хранения данных,
позволяющие сохранять информацию для последующего использования
и

Слайд 61Виртуальная память
использование иерархической организации системы памяти
с непрерывным адресным пространством;
системное программное обеспечение
Виртуальная память
использование иерархической организации системы памяти
с непрерывным адресным пространством;
системное программное обеспечение

Слайд 62ТИПЫ ПРЕРЫВАНИЙ
внутренние прерывания –
реакция на возникшие внутренние проблемные события;
аппаратные прерывания
ТИПЫ ПРЕРЫВАНИЙ
внутренние прерывания –
реакция на возникшие внутренние проблемные события;
аппаратные прерывания

Слайд 63Аппаратные прерывания в порядке убывания приоритета
Аппаратные прерывания в порядке убывания приоритета

Слайд 64Коммутация запросов прерываний
для реализаций системы прерываний процессоры Pentium и выше имеют
встроенный
Коммутация запросов прерываний
для реализаций системы прерываний процессоры Pentium и выше имеют
встроенный

Слайд 65Методы оценки производительности
производительность – скорость появления некоторого числа событий в секунду.
время
Методы оценки производительности
производительность – скорость появления некоторого числа событий в секунду.
время

Слайд 66Что влияет на производительность
Применение конвейерной обработки,
когда несколько последовательных команд находятся на
Что влияет на производительность
Применение конвейерной обработки,
когда несколько последовательных команд находятся на

Слайд 67Для оценки и сравнения систем
используются следующие критерии:
• Пиковая производительность –
теоретический
Для оценки и сравнения систем
используются следующие критерии:
• Пиковая производительность –
теоретический

Слайд 68Тестовая оценка производительности
Тесты производителей –
предназначены для оценки выпускаемых процессоров,
ориентированы на
Тестовая оценка производительности
Тесты производителей –
предназначены для оценки выпускаемых процессоров,
ориентированы на

Слайд 69ОДНОКРИСТАЛЬНЫЕ
МИКРОКОНТРОЛЛЕРЫ
ОДНОКРИСТАЛЬНЫЕ
МИКРОКОНТРОЛЛЕРЫ

Слайд 70Представители семейства
мк ПЗУ (кБ) ОЗУ (Б) stanby реж. линий вв кол-во
Представители семейства
мк ПЗУ (кБ) ОЗУ (Б) stanby реж. линий вв кол-во

Слайд 71Универсальный периферийный интерфейс (UPI)
Обозначение Встроенное ПЗУ (кВ) Встроенное ОЗУ (B) Примечания
8041 1
Универсальный периферийный интерфейс (UPI)
Обозначение Встроенное ПЗУ (кВ) Встроенное ОЗУ (B) Примечания
8041 1

Слайд 73Схемы синхронизации
Начальная установка
Схемы синхронизации
Начальная установка

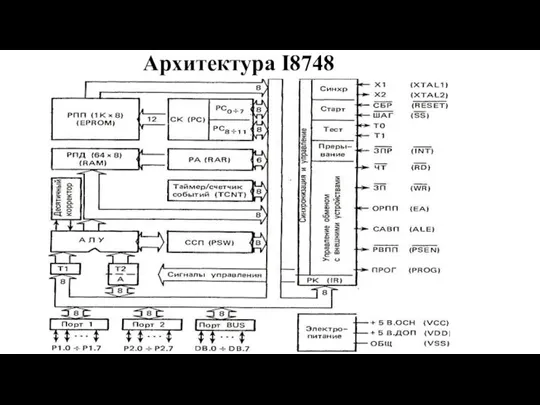
Слайд 74Архитектура I8748
Архитектура I8748
Слайд 75Слово состояния
Типы команд
Слово состояния
Типы команд

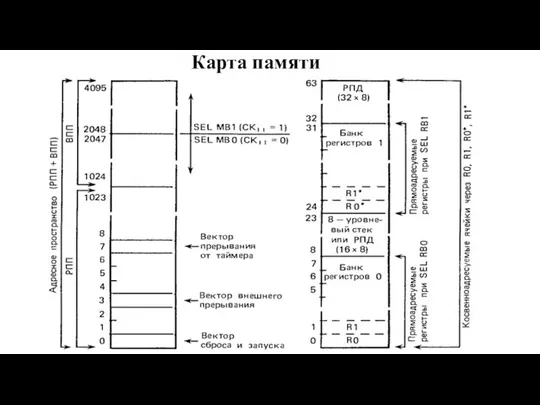
Слайд 76Карта памяти
Карта памяти
Слайд 77Подключение
внешней памяти программ
Подключение
внешней памяти программ
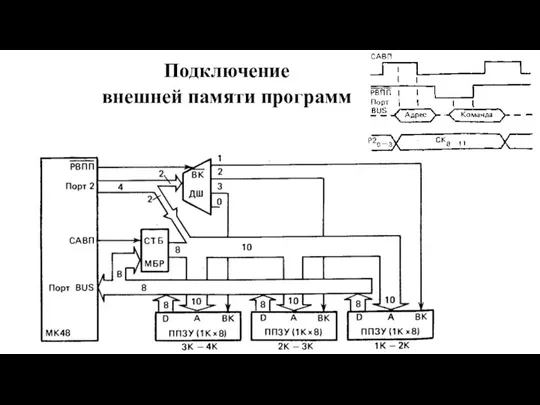
Слайд 78Подключение внешней памяти данных
Подключение внешней памяти данных
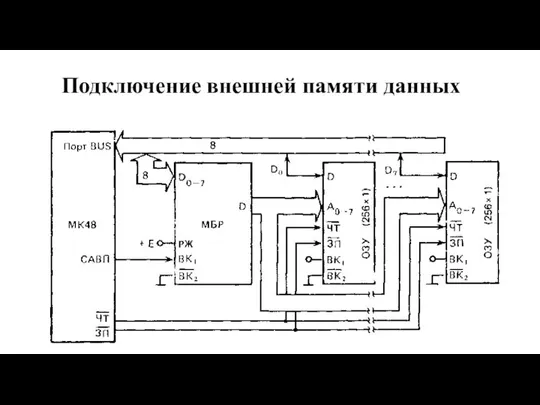
Слайд 79Ввод информации
от аналогового датчика
Ввод информации
от аналогового датчика

Слайд 803
Vcc
Подключение контактных датчиков
3
Vcc
Подключение контактных датчиков

Слайд 81Подавление дребезга контакта
аппаратный и программные способы
Подавление дребезга контакта
аппаратный и программные способы
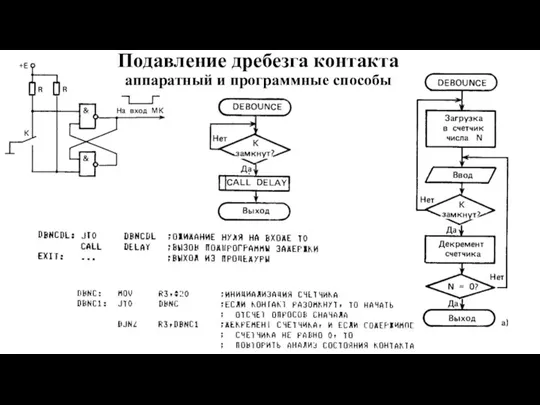
Слайд 825
Подключение импульсного датчика
1
5
Подключение импульсного датчика
1

Слайд 83Подключение клавиатуры
Подключение клавиатуры

Слайд 84Формирование и измерение временных интервалов
вложенным циклом
где Т – реализуемый временной интервал
в
Формирование и измерение временных интервалов
вложенным циклом
где Т – реализуемый временной интервал
в

Слайд 85Формирование и измерение временных интервалов
с использованием таймера
Формирование и измерение временных интервалов
с использованием таймера

Слайд 86Передача в последовательном коде
Передача в последовательном коде

Слайд 87Приём последовательного кода
Приём последовательного кода

Слайд 88Контроль паритета
после выполнения программы
аккумулятор сохранит своё значение,
флаг пользователя (в состава
Контроль паритета после выполнения программы аккумулятор сохранит своё значение, флаг пользователя (в состава

Слайд 89MCS 51
MCS 51

Слайд 90Микроконтроллеры семейства MCS 51 и его аналоги
Микроконтроллеры семейства MCS 51 и его аналоги
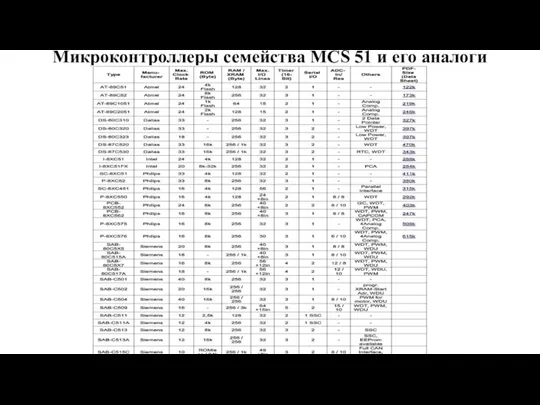
Слайд 91• U — потенциал общего провода ("земли");
• U— основное напряжение литания +5
• U — потенциал общего провода ("земли"); • U— основное напряжение литания +5

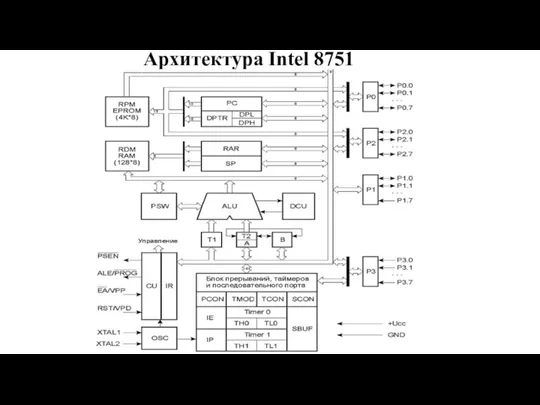
Слайд 92Архитектура Intel 8751
Архитектура Intel 8751
Слайд 93Устройство управления и синхронизации
Кварцевый резонатор,
подключаемый к внешним выводам микроконтроллера,
управляет работой
Устройство управления и синхронизации
Кварцевый резонатор,
подключаемый к внешним выводам микроконтроллера,
управляет работой

Слайд 94Организация ОЗУ, ПЗУ и регистров
Объем резидентной ПП – 4 Кбайт.
При обращении
Организация ОЗУ, ПЗУ и регистров
Объем резидентной ПП – 4 Кбайт.
При обращении

Слайд 95Регистры специальных функций (Special Function Register)
Регистры специальных функций (Special Function Register)

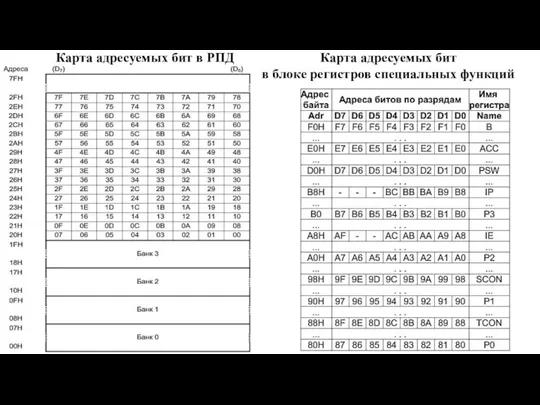
Слайд 96Карта адресуемых бит
в блоке регистров специальных функций
Карта адресуемых бит в РПД
Карта адресуемых бит
в блоке регистров специальных функций
Карта адресуемых бит в РПД
Слайд 97Регистр флагов (PSW)
Регистр флагов (PSW)

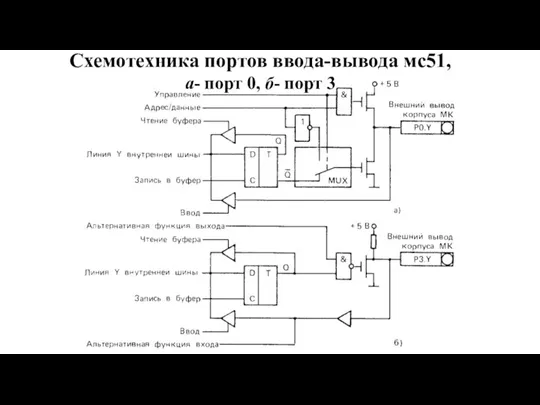
Слайд 98Схемотехника портов ввода-вывода мс51,
а- порт 0, б- порт 3
Схемотехника портов ввода-вывода мс51,
а- порт 0, б- порт 3
Слайд 99Альтернативные функции порта Р3
активируются предварительной записью «1»
в соответствующие биты порта
Альтернативные функции порта Р3
активируются предварительной записью «1»
в соответствующие биты порта

Слайд 100Таймеры / счетчики мс51
два программируемых 16-битных таймера/счетчика (T/C0 и T/C1),
могут быть
Таймеры / счетчики мс51
два программируемых 16-битных таймера/счетчика (T/C0 и T/C1),
могут быть

Слайд 101Регистр режима работы таймера/счетчика (TMOD)
Регистр режима работы таймера/счетчика (TMOD)

Слайд 102Регистр управления/статуса таймера (TCON)
Регистр управления/статуса таймера (TCON)

Слайд 103Режимы работы таймеров-счетчиков
для Т/С0 и Т/С1 режимы работы 0, 1 и 2
Режимы работы таймеров-счетчиков
для Т/С0 и Т/С1 режимы работы 0, 1 и 2

Слайд 104Режим 2:
работа организована таким образом, что переполнение TL
приводит не только к
Режим 2:
работа организована таким образом, что переполнение TL
приводит не только к

Слайд 105Режим 3:
Т/С1 сохраняет неизменным свое текущее содержимое, так же как и при
Режим 3:
Т/С1 сохраняет неизменным свое текущее содержимое, так же как и при

Слайд 106Универсальный асинхронный приемопередатчик UART
(Universal Asynchronous ReceiverTransmitter)
прием и передача информации в
Универсальный асинхронный приемопередатчик UART
(Universal Asynchronous ReceiverTransmitter)
прием и передача информации в

Слайд 107Режимы работы УАПП
Режим 0. Информация и передается, и принимается через вывод входа
Режимы работы УАПП
Режим 0. Информация и передается, и принимается через вывод входа

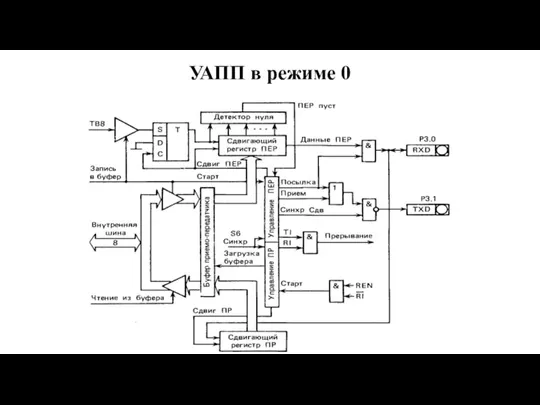
Слайд 108УАПП в режиме 0
УАПП в режиме 0
Слайд 109УАПП в режимах 1, 2, 3
УАПП в режимах 1, 2, 3

Слайд 110Регистр управления/статуса приемопередатчика (SCON)
Регистр управления/статуса приемопередатчика (SCON)

Слайд 111Скорость приема/передачи информации
через последовательный порт.
частота работы приемопередатчика в режиме 0:
зависит только
Скорость приема/передачи информации
через последовательный порт.
частота работы приемопередатчика в режиме 0:
зависит только

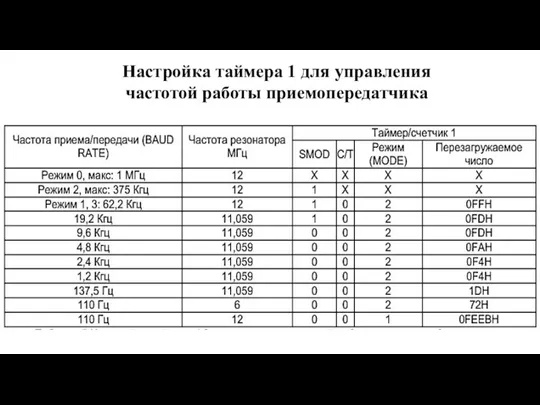
Слайд 112Настройка таймера 1 для управления
частотой работы приемопередатчика
Настройка таймера 1 для управления
частотой работы приемопередатчика
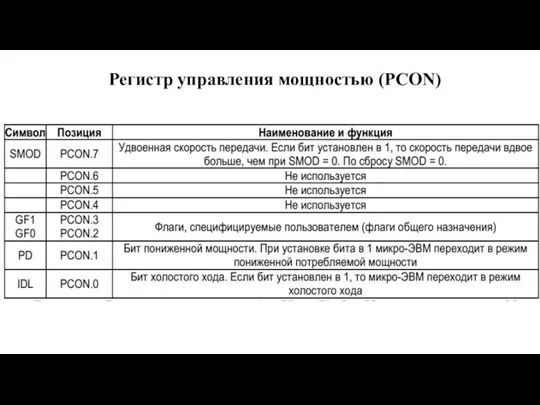
Слайд 113Регистр управления мощностью (PCON)
Регистр управления мощностью (PCON)
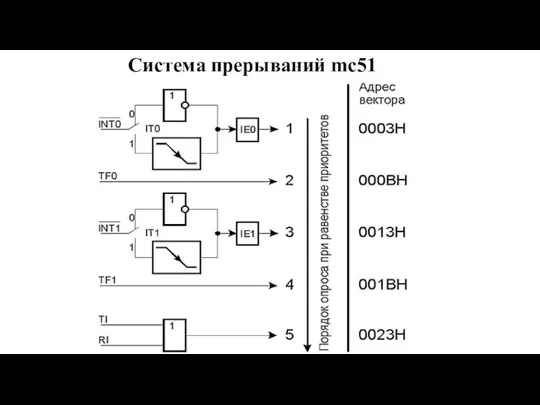
Слайд 114Система прерываний mc51
Система прерываний mc51
Слайд 115Регистр масок прерывания (IE)
Регистр масок прерывания (IE)

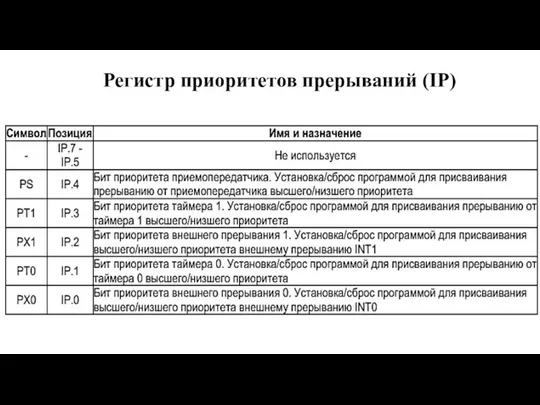
Слайд 116Регистр приоритетов прерываний (IP)
Регистр приоритетов прерываний (IP)
Слайд 117Система команд mс51
111 базовых команд,
по функциональному признаку подразделяются на группы команд:
Система команд mс51
111 базовых команд,
по функциональному признаку подразделяются на группы команд:

Слайд 118Режимы адресации
Прямая адресация (Direct Addressing)
операнд определяется 8-битным адресом в инструкции,
используется только
Режимы адресации
Прямая адресация (Direct Addressing)
операнд определяется 8-битным адресом в инструкции,
используется только


Слайд 120PCA (Programmable Counter Array)
имеется у моделей 80C51FA, 80C51FB, 80С51 РС и 80C51GB
обеспечивает
PCA (Programmable Counter Array)
имеется у моделей 80C51FA, 80C51FB, 80С51 РС и 80C51GB
обеспечивает


Слайд 122Структурная схема РСА таймера-счетчика
Структурная схема РСА таймера-счетчика
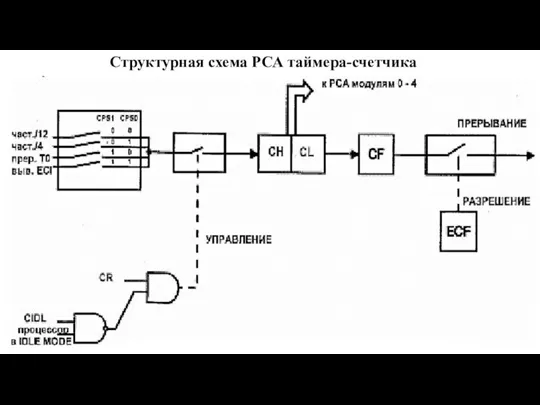
Слайд 123Регистр режимов PCA таймера-счетчика (CMOD)
Регистр режимов PCA таймера-счетчика (CMOD)

Слайд 124Регистр управления РСА таймером-счетчиком (CCON)
Регистр управления РСА таймером-счетчиком (CCON)
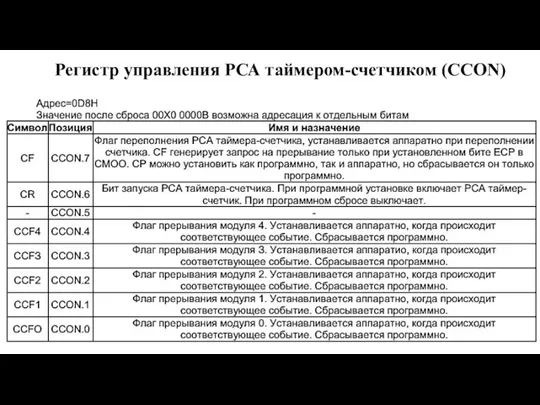
Слайд 125Регистр режимов модуля сравнения захвата (ССАРМn)
Регистр режимов модуля сравнения захвата (ССАРМn)

Слайд 126Режимы работы РСА
комбинации битов регистра ССАРМn,
соответствующие различным режимам работы модуля сравнения-захвата
Режимы работы РСА
комбинации битов регистра ССАРМn,
соответствующие различным режимам работы модуля сравнения-захвата
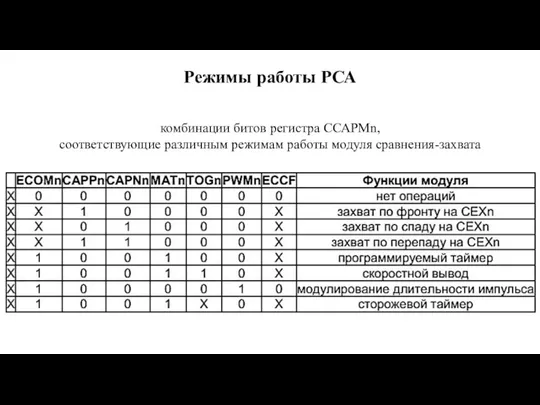
Слайд 127Режим захвата
рекомендуется использовать
при измерении периодов,
длительности,
скважности импульсов,
разности фаз между
Режим захвата
рекомендуется использовать
при измерении периодов,
длительности,
скважности импульсов,
разности фаз между
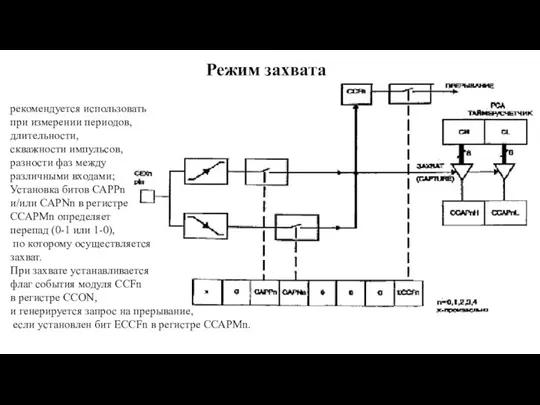
Слайд 128Режим 16-разрядного программируемого таймера
значение РСА трижды за машинный цикл сравнивается с значением,
Режим 16-разрядного программируемого таймера
значение РСА трижды за машинный цикл сравнивается с значением,
Слайд 129Режим скоростного вывода
формируется сигнал на внешнем выводе СЕХn,
когда происходит совпадение РСА
Режим скоростного вывода
формируется сигнал на внешнем выводе СЕХn,
когда происходит совпадение РСА

Слайд 130Режим сторожевого таймера (watchdog timer)
Сторожевой таймер - это схема, которая автоматически сбрасывает
Режим сторожевого таймера (watchdog timer)
Сторожевой таймер - это схема, которая автоматически сбрасывает

Слайд 131Сторожевой таймер
Сторожевой таймер
Слайд 132Режим генерации импульсов заданной скважности
Значение в CCAPnL задает скважность импульсов
Режим генерации импульсов заданной скважности
Значение в CCAPnL задает скважность импульсов
Слайд 133Аналого-цифровой преобразователь
АЦП микроконтроллера в семействе MCS-51/52
(например, типа SAB 80515 фирмы Siemens
Аналого-цифровой преобразователь
АЦП микроконтроллера в семействе MCS-51/52
(например, типа SAB 80515 фирмы Siemens

Слайд 134ADCON
(регистр управления преобразователем)
адрес - 0D8H, возможна побитовая адресация
используется, чтобы
• выбрать один
ADCON
(регистр управления преобразователем)
адрес - 0D8H, возможна побитовая адресация
используется, чтобы
• выбрать один


Слайд 136DAPR
(регистр программирования опорных напряжений АЦП).
Регистр DAPR позволяет менять внутренние опорные напряжения
DAPR
(регистр программирования опорных напряжений АЦП).
Регистр DAPR позволяет менять внутренние опорные напряжения

Слайд 137Регистр программирования АЦП DAPR (0DAH)
Если используются внешние опорные напряжения
VAGND = 0
Регистр программирования АЦП DAPR (0DAH)
Если используются внешние опорные напряжения
VAGND = 0































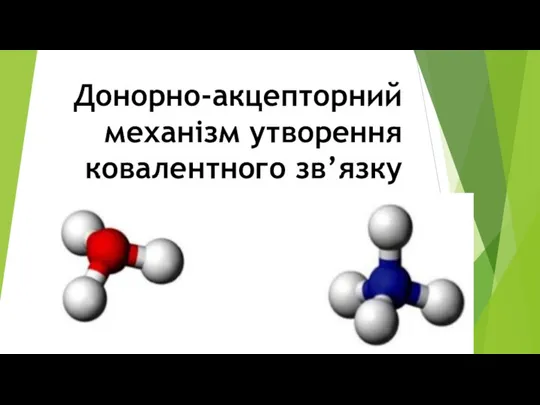 Донорно - акц. механізм
Донорно - акц. механізм ВОДА
ВОДА Моделирование
Моделирование Функциональная анатомия ствола головного мозга. Понятие о ретикулярной формации
Функциональная анатомия ствола головного мозга. Понятие о ретикулярной формации Изо – викторина (5 класс)
Изо – викторина (5 класс) Магнитное поле
Магнитное поле Компьютерная презентация команды id091тема: «Модели. Классификация моделей.»
Компьютерная презентация команды id091тема: «Модели. Классификация моделей.» Модернизм и новые направления культуры первой половины ХХ века
Модернизм и новые направления культуры первой половины ХХ века Появление и эволюция вредоносных программ. Основные направления развития. Методы противодействия.
Появление и эволюция вредоносных программ. Основные направления развития. Методы противодействия. Анализ показателей финансово-экономической деятельности ГБУЗ Городская больница
Анализ показателей финансово-экономической деятельности ГБУЗ Городская больница АНО СО Достойный Возраст
АНО СО Достойный Возраст Функции науки об управлении персоналом
Функции науки об управлении персоналом Food and healthy eating
Food and healthy eating  Презентация на тему Фольклор в музыке русских композиторов (5 класс)
Презентация на тему Фольклор в музыке русских композиторов (5 класс) Каплиев А.С., инициатор создания общественного движения «За право на достоинство и свободное развитие»
Каплиев А.С., инициатор создания общественного движения «За право на достоинство и свободное развитие» Маркетинг услуг по кадровому консалтингу
Маркетинг услуг по кадровому консалтингу Репрезентативная система и темперамент человекаПрактико-ориентированное занятие для педагогов Детской школы искусств
Репрезентативная система и темперамент человекаПрактико-ориентированное занятие для педагогов Детской школы искусств Тесты 7 – 8 класс
Тесты 7 – 8 класс Инертные газы
Инертные газы Дыхание
Дыхание Виды Москвы с Останкинской башни
Виды Москвы с Останкинской башни Что вчера было хорошо, может считаться таковым и завтра. Однако не должно. Остается понять, что должно измениться.
Что вчера было хорошо, может считаться таковым и завтра. Однако не должно. Остается понять, что должно измениться. Питер Брейгель Старший
Питер Брейгель Старший Отчет команды об участии в онлайн-конкурсе кулинарного искусства Мастер Шеф
Отчет команды об участии в онлайн-конкурсе кулинарного искусства Мастер Шеф ОСНОВИ НА ПРОЦЕСОТ НА ПЛАНИРАЊЕ НА КОМУНИЦИРАЊЕТО
ОСНОВИ НА ПРОЦЕСОТ НА ПЛАНИРАЊЕ НА КОМУНИЦИРАЊЕТО Технология изготовления изделия (руководство для школьников)
Технология изготовления изделия (руководство для школьников)  МЕТОДИЧЕСКОЕ ОБЪЕДИНЕНИЕ УЧИТЕЛЕЙ НАЧАЛЬНЫХ КЛАССОВМОУ СОШ №1
МЕТОДИЧЕСКОЕ ОБЪЕДИНЕНИЕ УЧИТЕЛЕЙ НАЧАЛЬНЫХ КЛАССОВМОУ СОШ №1 Система управления персоналом: приемы, методы, технологии, процедуры работы с кадрами
Система управления персоналом: приемы, методы, технологии, процедуры работы с кадрами