- Basic Local Alignment

Содержание
- 2. BLAST – алгоритм для нахождения участков локального сходства между последовательностями. Алгоритм сравнивает входную последовательность с последовательностями
- 3. Почему локальное выравнивание? Глобальное выравнивание следует применять только в случае заранее известной гомологии последовательностей по всей
- 4. Protein BLAST: поиск гомологов данного белка в банке аминокислотных последовательностей Алгоритмы blastp psi-blast phi-blast Можно использовать:
- 5. Что подаётся на вход программе BLAST? Последовательность запроса Банк последовательностей Параметры: параметры выравнивания: матрица аминокислотных замен,
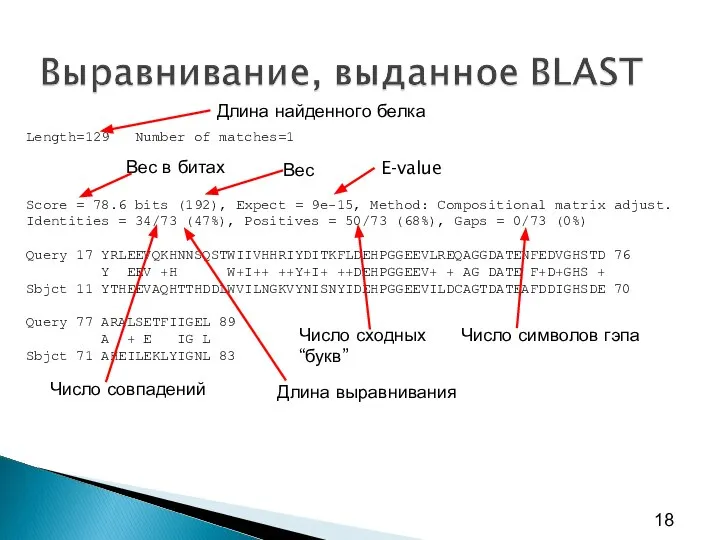
- 6. Что выдает BLAST? Выдача самой программы состоит из четырёх частей: – заголовок с описанием программы, банка,
- 8. E-value – ожидаемое количество случайных находок с таким же и лучшим весом (в той же базе
- 9. Как посчитать E-value Прямой способ — вычислительный эксперимент: перемешать банк (или запрос) очень много раз, каждый
- 10. Как посчитать E-value Имеется замечательная теорема (С.Карлина): E-value=Kmn·e-λS S – Score (вес) m – длина исходной
- 11. Вес в битах Вес в битах B зависит от обычного веса S и параметров вычисления веса.
- 12. Здесь описан интерфейс, установленный на «родине» BLAST: National Center for Biotechnology Information (NCBI) в США, http://blast.ncbi.nlm.nih.gov/
- 13. http://blast.ncbi.nlm.nih.gov/ → protein blast
- 15. Участок малой сложности Ищем: белок P02929 если отключить “Compositional adjustment” и фильтр, то одной из находок
- 16. Определяется как участок с смещенным составом (biased composition) • Гомополимерные участки • Короткие повторы • Перепредставленность
- 17. выбираем formatting options подтверждаем выбор Переход к текстовому виду Чтобы увидеть выдачу самой программы (а не
- 19. Как работает BLAST? Поиск коротких сходных слов (якорей) Якорь (в примере —длины 3) Сходные слова Порог
- 20. BLAST — эвристический алгоритм Алгоритмы биоинформатики можно разделить на точные и эвристические. Точные алгоритмы решают какую-либо
- 23. Скачать презентацию
Слайд 2BLAST – алгоритм для нахождения участков локального сходства между последовательностями.
Алгоритм сравнивает входную
BLAST – алгоритм для нахождения участков локального сходства между последовательностями.
Алгоритм сравнивает входную

Слайд 3Почему локальное выравнивание?
Глобальное выравнивание следует применять только в случае заранее известной гомологии
Почему локальное выравнивание?
Глобальное выравнивание следует применять только в случае заранее известной гомологии

Слайд 4Protein BLAST: поиск гомологов данного белка в банке аминокислотных последовательностей
Алгоритмы
blastp
psi-blast
phi-blast
Можно использовать:
–
Protein BLAST: поиск гомологов данного белка в банке аминокислотных последовательностей
Алгоритмы
blastp
psi-blast
phi-blast
Можно использовать:
–

Слайд 5Что подаётся на вход программе BLAST?
Последовательность запроса
Банк последовательностей
Параметры:
параметры выравнивания:
Что подаётся на вход программе BLAST?
Последовательность запроса
Банк последовательностей
Параметры:
параметры выравнивания:

Слайд 6Что выдает BLAST?
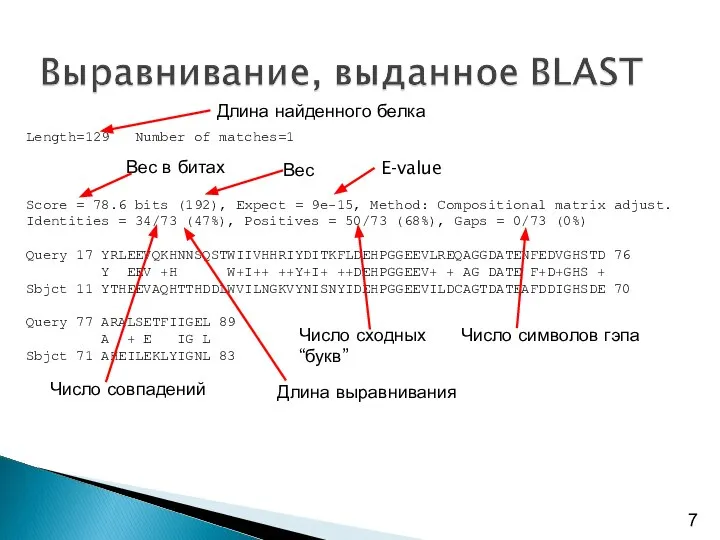
Выдача самой программы состоит из четырёх частей:
– заголовок с
Что выдает BLAST?
Выдача самой программы состоит из четырёх частей:
– заголовок с

Слайд 8E-value – ожидаемое количество случайных находок с таким же и лучшим весом
E-value – ожидаемое количество случайных находок с таким же и лучшим весом

Слайд 9Как посчитать E-value
Прямой способ — вычислительный эксперимент:
перемешать банк (или запрос) очень
Как посчитать E-value
Прямой способ — вычислительный эксперимент: перемешать банк (или запрос) очень

Слайд 10Как посчитать E-value
Имеется замечательная теорема (С.Карлина):
E-value=Kmn·e-λS
S – Score (вес)
m – длина
Как посчитать E-value
Имеется замечательная теорема (С.Карлина):
E-value=Kmn·e-λS
S – Score (вес)
m – длина

Слайд 11Вес в битах
Вес в битах B зависит от обычного веса S и
Вес в битах
Вес в битах B зависит от обычного веса S и

Слайд 12Здесь описан интерфейс, установленный на «родине» BLAST: National Center for Biotechnology Information
Здесь описан интерфейс, установленный на «родине» BLAST: National Center for Biotechnology Information

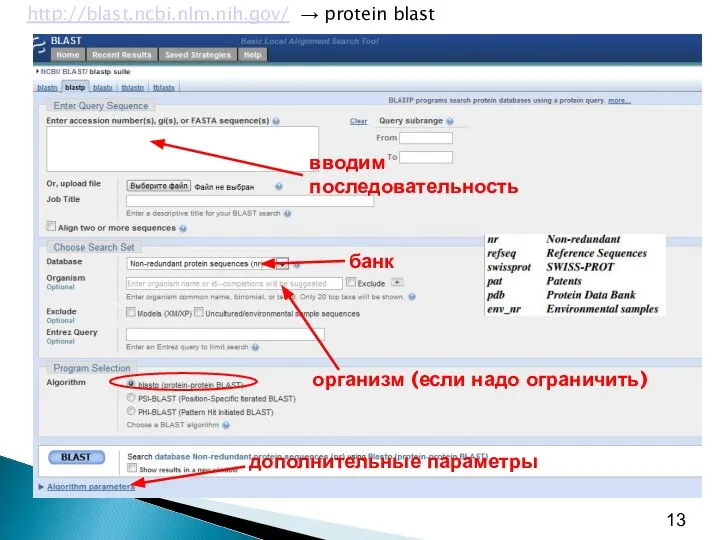
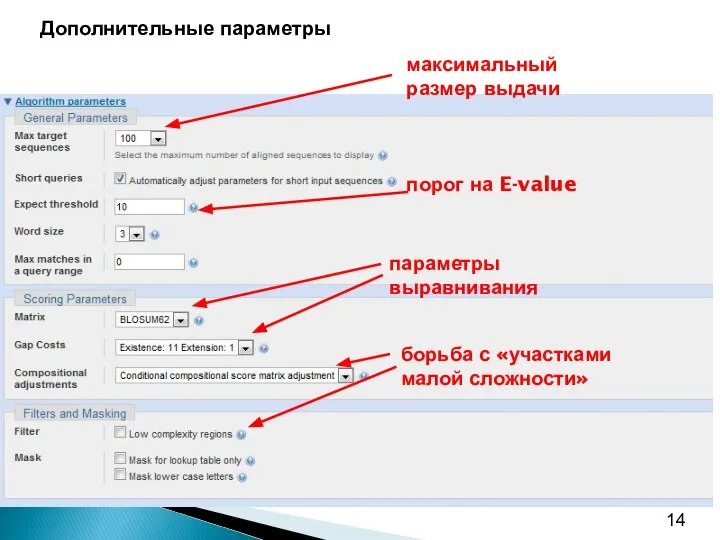
Слайд 13http://blast.ncbi.nlm.nih.gov/ → protein blast
http://blast.ncbi.nlm.nih.gov/ → protein blast
Слайд 15Участок малой сложности
Ищем: белок P02929
если отключить “Compositional adjustment” и фильтр, то одной
Участок малой сложности
Ищем: белок P02929
если отключить “Compositional adjustment” и фильтр, то одной

Слайд 16Определяется как участок с смещенным составом (biased composition)
• Гомополимерные участки
• Короткие повторы
•
Определяется как участок с смещенным составом (biased composition)
• Гомополимерные участки
• Короткие повторы
•

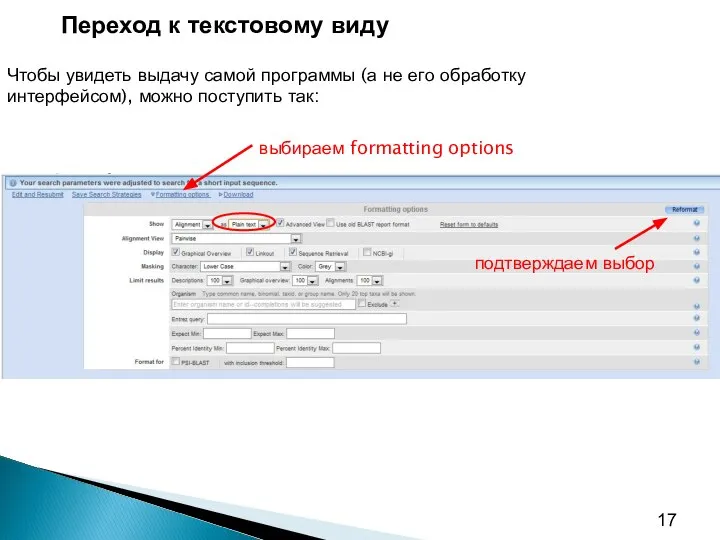
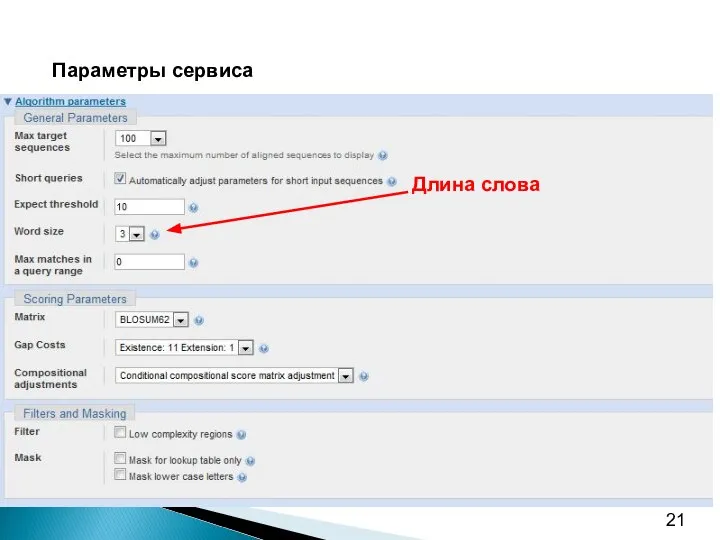
Слайд 17выбираем formatting options
подтверждаем выбор
Переход к текстовому виду
Чтобы увидеть выдачу самой программы
выбираем formatting options
подтверждаем выбор
Переход к текстовому виду
Чтобы увидеть выдачу самой программы
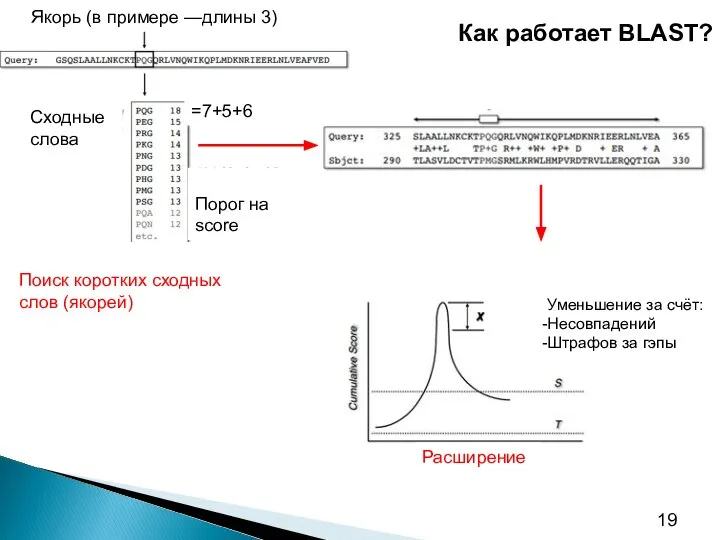
Слайд 19Как работает BLAST?
Поиск коротких сходных слов (якорей)
Якорь (в примере —длины 3)
Сходные слова
Порог
Как работает BLAST?
Поиск коротких сходных слов (якорей)
Якорь (в примере —длины 3)
Сходные слова
Порог
Слайд 20BLAST — эвристический алгоритм
Алгоритмы биоинформатики можно разделить на точные и эвристические.
Точные алгоритмы
BLAST — эвристический алгоритм
Алгоритмы биоинформатики можно разделить на точные и эвристические.
Точные алгоритмы

 Понятие информации
Понятие информации Сообщение Блюпринтов. Лекция 8
Сообщение Блюпринтов. Лекция 8 Компьютерная графика: Растровая и Векторная графика
Компьютерная графика: Растровая и Векторная графика Регистрация магазина на Etsy
Регистрация магазина на Etsy Способы унификации текстов документов
Способы унификации текстов документов 30 сентября - профессиональный праздник всех пользователей и работников Интернет-индустрии. Международный День Интернета
30 сентября - профессиональный праздник всех пользователей и работников Интернет-индустрии. Международный День Интернета Поисковые системы Internet
Поисковые системы Internet Конструкция while
Конструкция while Создание стиля
Создание стиля Челлендж #мамыдочки #мамысыночки
Челлендж #мамыдочки #мамысыночки Знакомство с программой LEGO Digital Designer
Знакомство с программой LEGO Digital Designer Первоначальная работа с VHMS
Первоначальная работа с VHMS Основы командной работы
Основы командной работы Сервис Dalee ID
Сервис Dalee ID Символ собака
Символ собака Разработка информационной системы для автоматизации действий кладовщика в фирме по установке и демонтажу оконных систем
Разработка информационной системы для автоматизации действий кладовщика в фирме по установке и демонтажу оконных систем Автоматизированная система учета инструмента в цехах
Автоматизированная система учета инструмента в цехах DH Standard AVN Update
DH Standard AVN Update Microsoft Visio - это отличное программное решение для создания графиков, диаграмм, чертежей, блок-схем
Microsoft Visio - это отличное программное решение для создания графиков, диаграмм, чертежей, блок-схем Величины в среде программирования КУМИР
Величины в среде программирования КУМИР Коммерческое предложение по составлению SEO-стратегии
Коммерческое предложение по составлению SEO-стратегии Логические элементы компьютеров
Логические элементы компьютеров История развития программного обеспечения
История развития программного обеспечения Тест об игре Need For Speed (NFS)
Тест об игре Need For Speed (NFS) Spike prime & first lego league
Spike prime & first lego league Gale Reference Complete
Gale Reference Complete Разработка сайта
Разработка сайта Обучающая презентация
Обучающая презентация