- Динамическая память, динамические переменные в С++

Содержание
- 2. Определение, создание и работа с динамическими переменными int x = 15; - Описана статическая переменная x,
- 3. Определение, создание и работа с динамическими переменными Оператор cout Создать динамическую переменную можно двумя способами: описать
- 4. Определение, создание и работа с динамическими переменными x = NULL – говорит о том, что указатель
- 5. работа с динамическими переменными int *x = new int; *x = 15; ………….. delete x; Если
- 6. работа с динамическими переменными Графически это можно представить так. x x x y y y 10
- 7. работа с динамическими переменными 2. Меняем местами значения динамических переменных с помощью статической переменной r. int
- 8. работа с динамическими переменными Меняем местами указатели на динамические области памяти. void main () { int
- 9. Работа с динамическими переменными. ….Зачем нужны динамические переменные?.... Можно создать статический массив записей (структур), но работать
- 10. Абстрактные структуры данных. ….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные отношения между элементами данных….
- 11. Абстрактные структуры данных. С линейными списками могут быть выполнены следующие операции: Получить доступ к к-й компоненте
- 12. Линейный связный список (ЛССп) – это конечное множество компонент, каждая из которых состоит из двух частей:
- 13. Двунаправленный список Линейные последовательности данных, связанные с точки зрения программной обработки, можно представить с помощью массива
- 14. Работа со списками Сохранив упорядоченность, нужно две фамилии удалить и одну вставить. Связный список требует дополнительной
- 15. Линейные связные списоки Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп. Список может быть реализован
- 16. Стек Реализация стека. Стек – это настолько популярная структура данных, что во многих ЭВМ она реализуется
- 17. Стек На С++ эти операции реализуются так: 1. stack[sp] = x; // положить x на вершину
- 18. пример использования стека Получение обратной польской записи выражения. Существуют три формы записи выражений: 1) инфиксная, 2)
- 19. пример использования стека Идея алгоритма : операнды из входной строки сразу попадают в выходную строку, а
- 20. Если очередным символом во входной строке является правая скобка, то из стека выталкиваются в выходную строку
- 21. Очередь. Очередь. Очередь – это абстрактная структура данных, которая работает по принципу FIFO (First In First
- 22. Очередь. Инициализация очереди заключается в присваивании начальных значений переменным head и tail. Если очередь пуста, положим
- 23. Очередь. Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной с помощью закольцованного массива, приходится
- 24. Очередь. Здесь head указывает на первый элемент в очереди, а tail на ячейку, следующую за последним
- 25. Очередь. добавить элемент в очередь: tail = ((tail+1)% n); if (tail = =head) cout else Queue[tail]
- 26. Деревья. Создание теории деревьев связывают с именами инженера – электрика Г. Кирхгофа и математика А. Кэли,
- 27. Представление деревьев 1) a 2) b c d e f g h i k l 3)
- 28. Опр.2. Дерево – это неориентированный связный граф без циклов. Опр. 3. Дерево – это неориентированный, связный
- 29. Исходя из этого определения, можно сказать, что рисунки 1, 2 и 3 учитывают связи между узлами
- 30. Операции над деревьями, представление массивом Важнейшими операциями над деревьями являются: Построение дерева …. Добавление элемента в
- 31. Представление массивом (a + b / c ) * ( d – e * f )
- 32. Представление дерева массивом Представление дерева массивом позволяет легко находить путь от корня к заданному узлу, если
- 33. АСД. Представление и работа с помощью дин. переменных. Стек. Графически стек: NULL sp struct tstack {int
- 34. Стек с помощью дин. переменных просмотр элемента, расположенного на вершине стека int peek(tstack *sp) {return sp->inf;};
- 35. #include #include "stackint.h" #include using namespace std; void main() { FILE *h = fopen("input_stack.txt”,"r"); // файл
- 36. Очередь Очередь с помощью динамических переменных графически представляется так: tail head Элемент очереди описывается также, как
- 37. Очередь 1. Инициализация очереди: head = NULL; tail = NULL; head tail 2. Добавить элемент в
- 38. 3. Взять элемент из очереди: if (head != NULL) {r = head; x = head->inf; head
- 39. Общие операции со списками. Описание элемента списка в общем виде: struct tnode {int inf; tnode *next}
- 40. 4. Удалить элемент с указателем p. r = first; if (p == first) {first = first->next;
- 41. Бинарные деревья, программирование их с помощью динамических переменных. Дерево – это структура данных, которая может быть
- 42. Построение дерева с n узлами и минимальной высотой Идеально сбалансированное дерево… Пусть информационной частью будут номера
- 43. Идеально сбалансированное дерево. Функция, возвращающая значение: tnode *Tree (int n) { tnode *r; int nr, nl,
- 44. Бинарные деревья Если n = 21 и с клавиатуры введены номера вершин в следующем порядке: 8,9,11,15,
- 45. Обходы бинарного дерева: void Preorder (tnode *&t) //прямой { if (t != NULL) { cout inf
- 46. #include “iostream” // построение и обход дерева мин. высоты using namespace std; struct tnode {int inf;
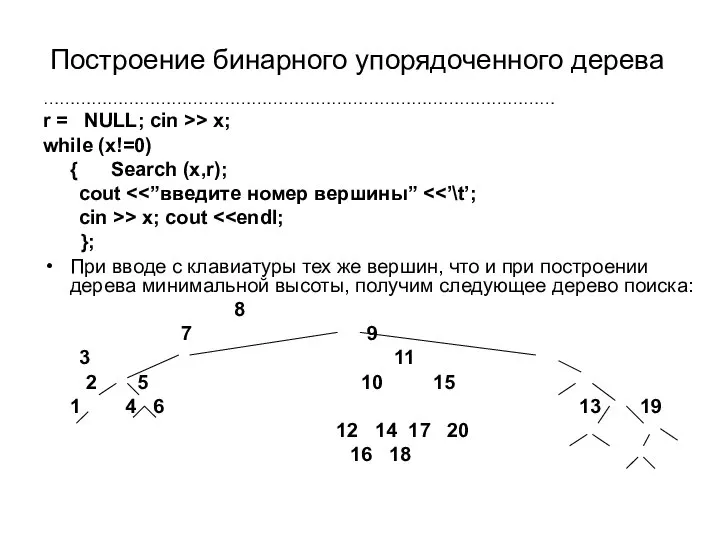
- 47. Построение бинарного упорядоченного дерева Пусть ключевое поле – это поле inf и мы рассматриваем упорядоченное бинарное
- 48. Построениe бинарного упорядоченного дерева …………………………………………………………………………………… r = NULL; cin >> x; while (x!=0) { Search (x,r);
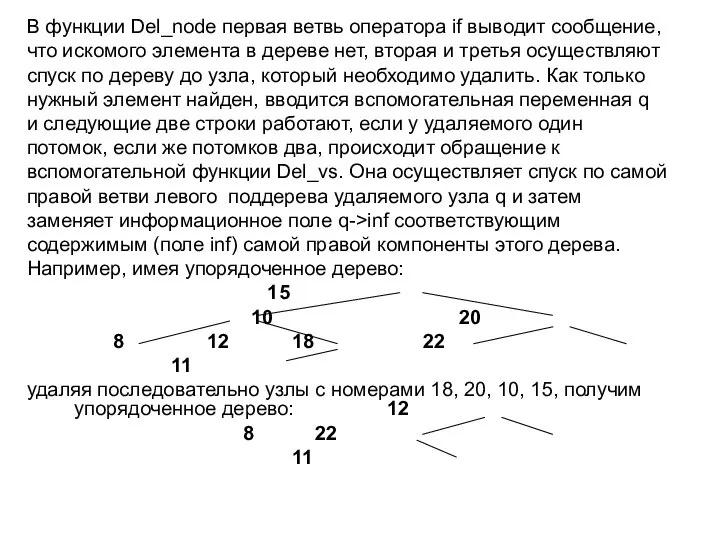
- 49. Удаление из упорядоченного дерева tnode *q; void Del_node(int x, tnode *&t) { if (t == NULL)
- 50. В функции Del_node первая ветвь оператора if выводит сообщение, что искомого элемента в дереве нет, вторая
- 51. Создание, обход и удаление из дерева поиска #include "iostream" using namespace std; struct tnode {int inf;
- 52. tnode *q; void Del_vs (tnode *&r); // прототип функции void Del_node(int x, tnode *&t) //удаление из
- 53. int main () { tnode *r; int x, n ; r = NULL; cout >x; while
- 54. Сильно ветвящиеся деревья Сильно ветвящиеся деревья - это деревья у узлов которых может быть больше двух
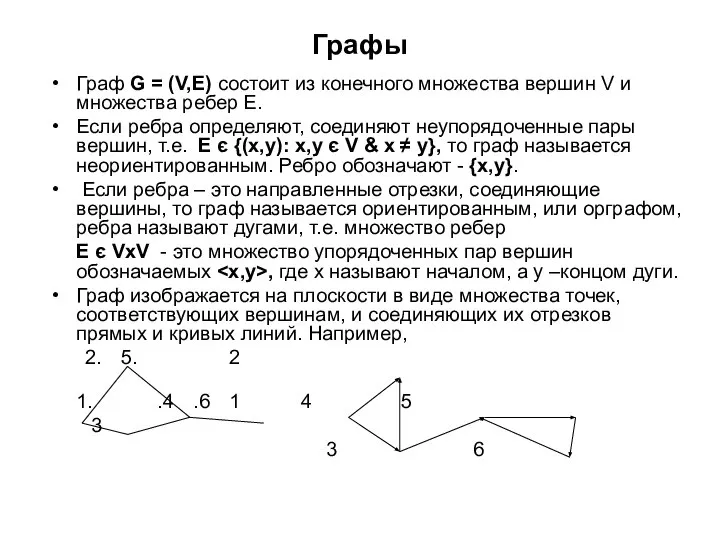
- 55. Графы Граф G = (V,E) состоит из конечного множества вершин V и множества ребер E. Если
- 56. Графы Если в графе G(V,E) ребро {u,v} или дуга є E, то вершины u и v
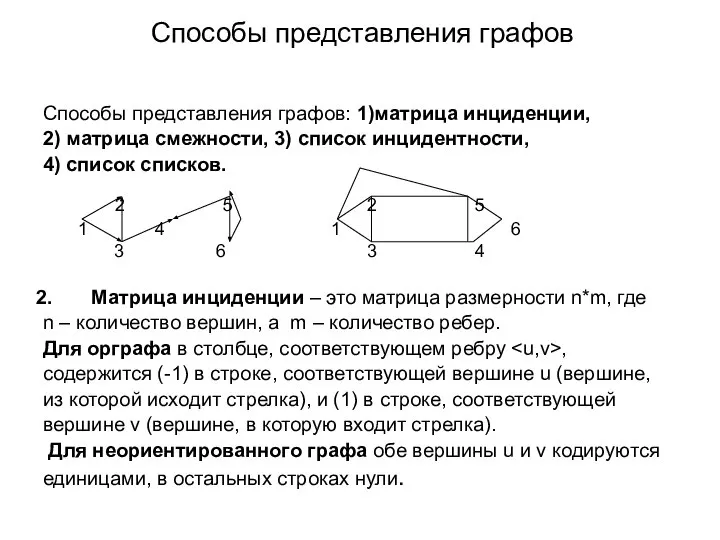
- 57. Cпособы представления графов Cпособы представления графов: 1)матрица инциденции, 2) матрица смежности, 3) список инцидентности, 4) список
- 58. Cпособы представления графов Для представленного орграфа матрица инциденции: 1 -1 -1 0 0 0 0 0
- 59. Cпособы представления графов На практике ребер в графе бывает обычно больше, чем вершин... Второй способ представления
- 60. Cпособы представления графов Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я и 4-я вершины не
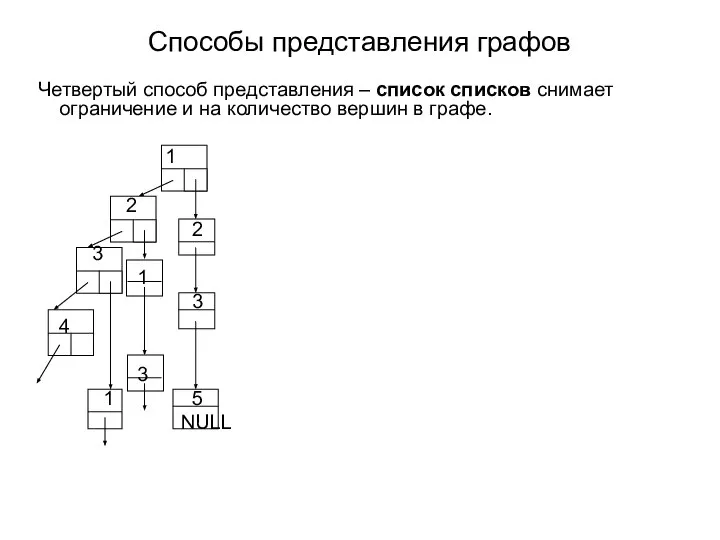
- 61. Cпособы представления графов Четвертый способ представления – список списков снимает ограничение и на количество вершин в
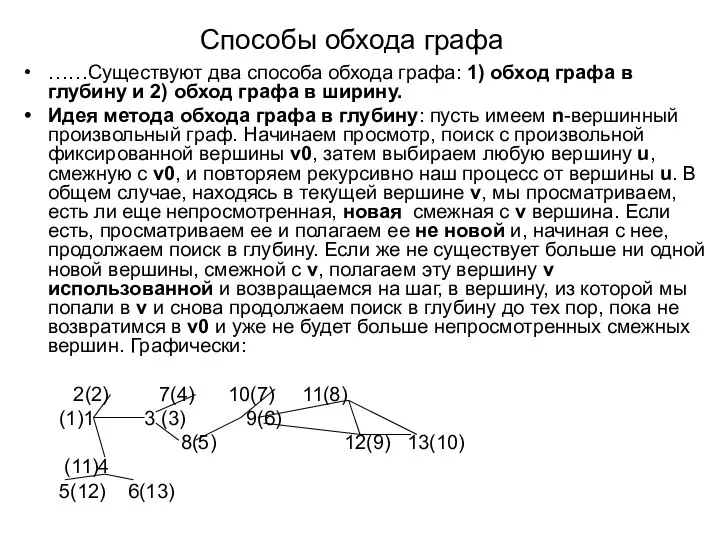
- 62. Способы обхода графа ……Существуют два способа обхода графа: 1) обход графа в глубину и 2) обход
- 63. Обход графа в глубину Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот метод. Чтобы отличить просмотренную
- 64. Обход графа в глубину Здесь V – множество всех вершин данного графа Spisok[v] – содержит номера
- 65. Обход графа в глубину - не рекурсивный function DFS1 (v); begin stack = 0; v ->
- 66. Нерекурсивный обход графа в глубину function DFS1 (v); begin stack = 0; v -> stack; просмотреть
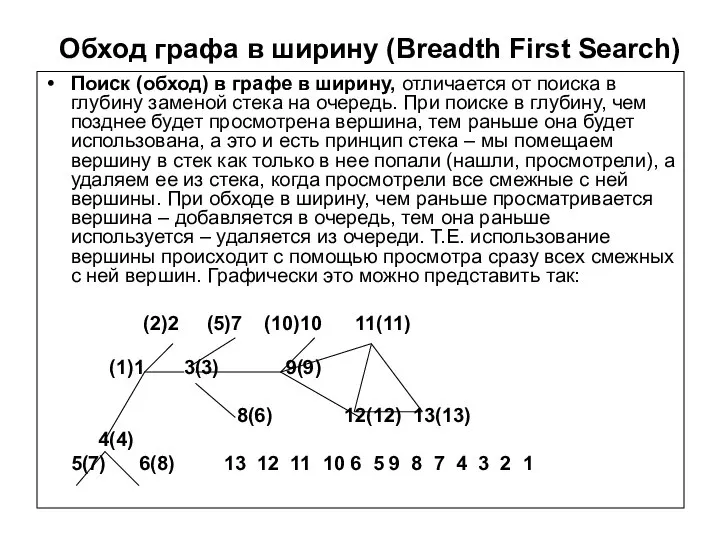
- 67. Обход графа в ширину (Breadth First Search) Поиск (обход) в графе в ширину, отличается от поиска
- 68. Обход графа в ширину Алгоритм обхода в ширину на псевдокоде можно записать так: function BFS (v)
- 69. Обход графа в ширину Оба алгоритма могут использоваться для нахождения пути между данными вершинами u и
- 70. Представление графов в С/С++ Матрицу инциденции и матрицу смежности можно представить двумерным массивом целых элементов: const
- 72. Скачать презентацию

Слайд 3Определение, создание и работа с динамическими переменными
Оператор cout << x << ”\t”
Определение, создание и работа с динамическими переменными
Оператор cout << x << ”\t”

Слайд 4Определение, создание и работа с динамическими переменными
x = NULL – говорит о
Определение, создание и работа с динамическими переменными
x = NULL – говорит о

Слайд 5работа с динамическими переменными
int *x = new int;
*x = 15;
…………..
delete x;
Если вместо
работа с динамическими переменными
int *x = new int;
*x = 15;
…………..
delete x;
Если вместо

Слайд 6работа с динамическими переменными
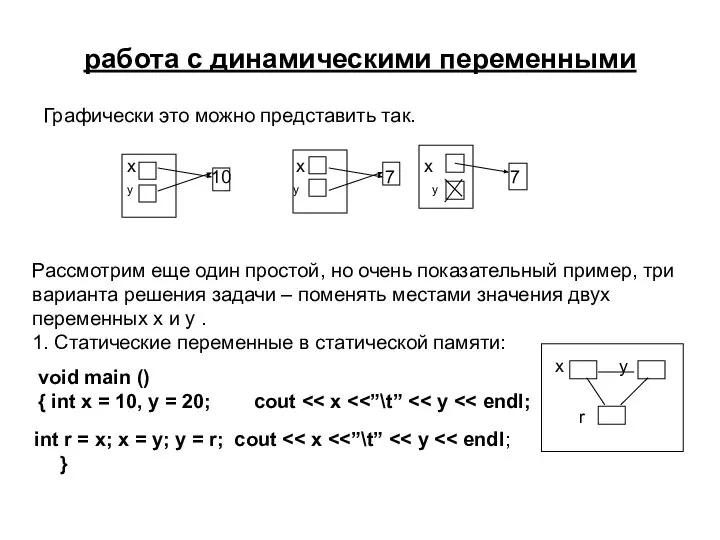
Графически это можно представить так.
x x x
y
работа с динамическими переменными
Графически это можно представить так.
x x x
y
Слайд 7работа с динамическими переменными
2. Меняем местами значения динамических переменных с помощью статической
работа с динамическими переменными
2. Меняем местами значения динамических переменных с помощью статической

Слайд 8работа с динамическими переменными
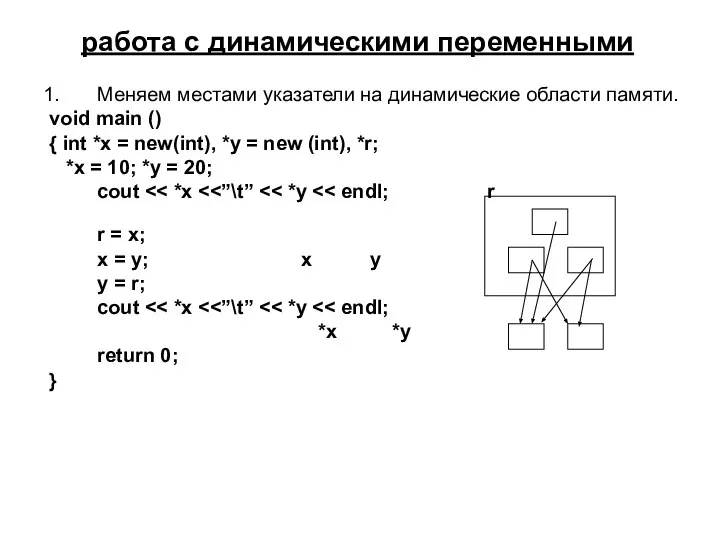
Меняем местами указатели на динамические области памяти.
void main
работа с динамическими переменными
Меняем местами указатели на динамические области памяти.
void main
Слайд 9Работа с динамическими переменными.
….Зачем нужны динамические переменные?....
Можно создать статический массив записей
Работа с динамическими переменными.
….Зачем нужны динамические переменные?....
Можно создать статический массив записей

Слайд 10Абстрактные структуры данных.
….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные отношения
Абстрактные структуры данных.
….в наборах данных, подлежащих компьютерной обработке, присутствуют важные структурные отношения

Слайд 11Абстрактные структуры данных.
С линейными списками могут быть выполнены следующие операции:
Получить доступ к
Абстрактные структуры данных.
С линейными списками могут быть выполнены следующие операции:
Получить доступ к

Слайд 12 Линейный связный список (ЛССп) – это конечное множество компонент, каждая из которых
Линейный связный список (ЛССп) – это конечное множество компонент, каждая из которых

Слайд 13Двунаправленный список
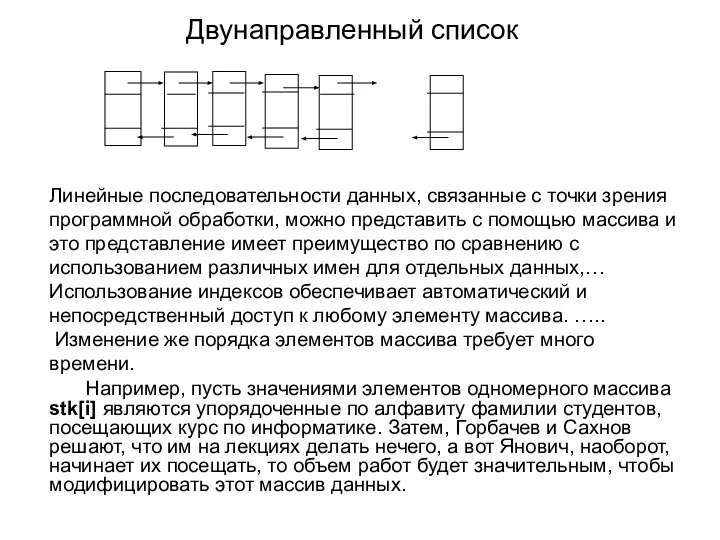
Линейные последовательности данных, связанные с точки зрения программной обработки, можно представить
Двунаправленный список
Линейные последовательности данных, связанные с точки зрения программной обработки, можно представить
Слайд 14Работа со списками
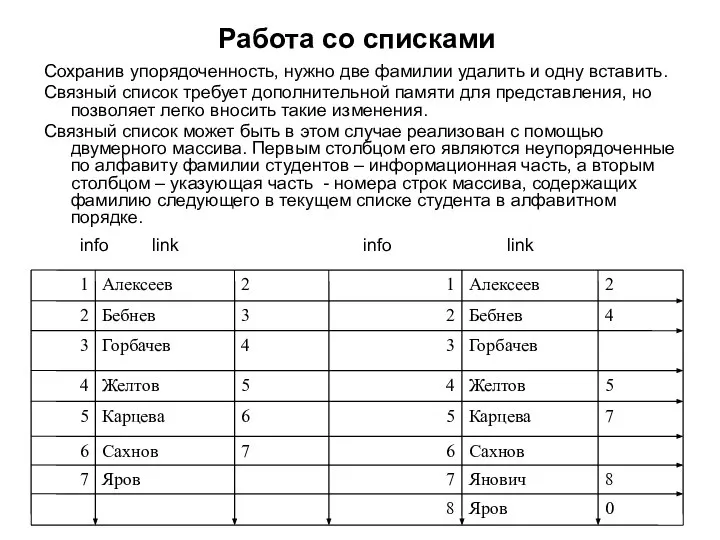
Сохранив упорядоченность, нужно две фамилии удалить и одну вставить.
Связный
Работа со списками
Сохранив упорядоченность, нужно две фамилии удалить и одну вставить.
Связный
Слайд 15Линейные связные списоки
Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп. Список
Линейные связные списоки
Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп. Список
![Линейные связные списоки Двумерный массив stk{i,j] размером 2*n может работать как Л.С.Сп.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1071732/slide-14.jpg)
Слайд 16Стек
Реализация стека. Стек – это настолько популярная структура данных, что во многих
Стек
Реализация стека. Стек – это настолько популярная структура данных, что во многих

Слайд 17Стек
На С++ эти операции реализуются так:
1. stack[sp] = x; // положить x
Стек
На С++ эти операции реализуются так:
1. stack[sp] = x; // положить x
![Стек На С++ эти операции реализуются так: 1. stack[sp] = x; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1071732/slide-16.jpg)
Слайд 18пример использования стека
Получение обратной польской записи выражения.
Существуют три формы записи выражений:
пример использования стека
Получение обратной польской записи выражения.
Существуют три формы записи выражений:

Слайд 19пример использования стека
Идея алгоритма : операнды из входной строки сразу попадают в
пример использования стека
Идея алгоритма : операнды из входной строки сразу попадают в

Слайд 20Если очередным символом во входной строке является правая скобка, то из стека
Если очередным символом во входной строке является правая скобка, то из стека

Слайд 21Очередь.
Очередь. Очередь – это абстрактная структура данных, которая работает по принципу FIFO
Очередь.
Очередь. Очередь – это абстрактная структура данных, которая работает по принципу FIFO

Слайд 22Очередь.
Инициализация очереди заключается в присваивании начальных значений переменным head и tail. Если
Очередь.
Инициализация очереди заключается в присваивании начальных значений переменным head и tail. Если

Слайд 23Очередь.
Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной с
Очередь.
Чтобы отличить пустую очередь от полностью заполненной в очереди, смоделированной с

Слайд 24Очередь.
Здесь head указывает на первый элемент в очереди, а tail на ячейку,
Очередь.
Здесь head указывает на первый элемент в очереди, а tail на ячейку,

Слайд 25Очередь.
добавить элемент в очередь:
tail = ((tail+1)% n);
if (tail = =head) cout <<”очередь
Очередь.
добавить элемент в очередь:
tail = ((tail+1)% n);
if (tail = =head) cout <<”очередь

Слайд 26Деревья.
Создание теории деревьев связывают с именами инженера – электрика Г. Кирхгофа
Деревья.
Создание теории деревьев связывают с именами инженера – электрика Г. Кирхгофа

Слайд 27Представление деревьев
1) a 2)
b c
d e f g h
i k
Представление деревьев
1) a 2)
b c
d e f g h
i k
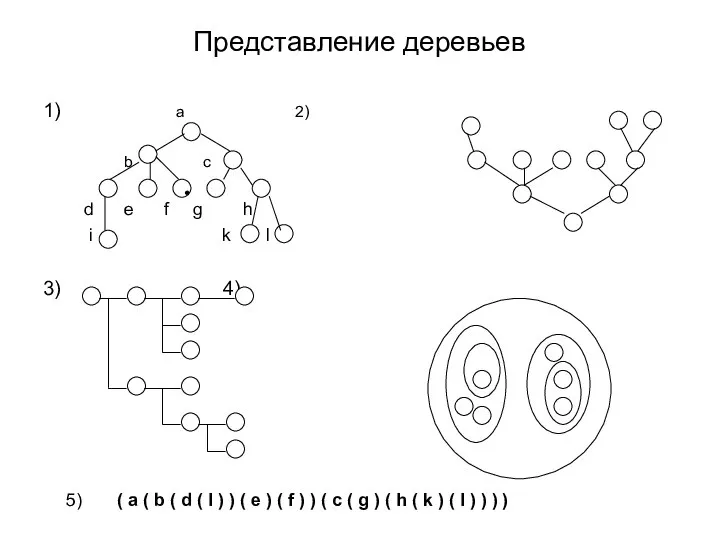
Слайд 28Опр.2. Дерево – это неориентированный связный граф без циклов.
Опр. 3. Дерево –
Опр.2. Дерево – это неориентированный связный граф без циклов.
Опр. 3. Дерево –

Слайд 29Исходя из этого определения, можно сказать, что рисунки 1, 2 и 3
Исходя из этого определения, можно сказать, что рисунки 1, 2 и 3

Слайд 30Операции над деревьями, представление массивом
Важнейшими операциями над деревьями являются:
Построение дерева ….
Добавление
Операции над деревьями, представление массивом
Важнейшими операциями над деревьями являются:
Построение дерева ….
Добавление

Слайд 31Представление массивом
(a + b / c ) * ( d –
Представление массивом (a + b / c ) * ( d –
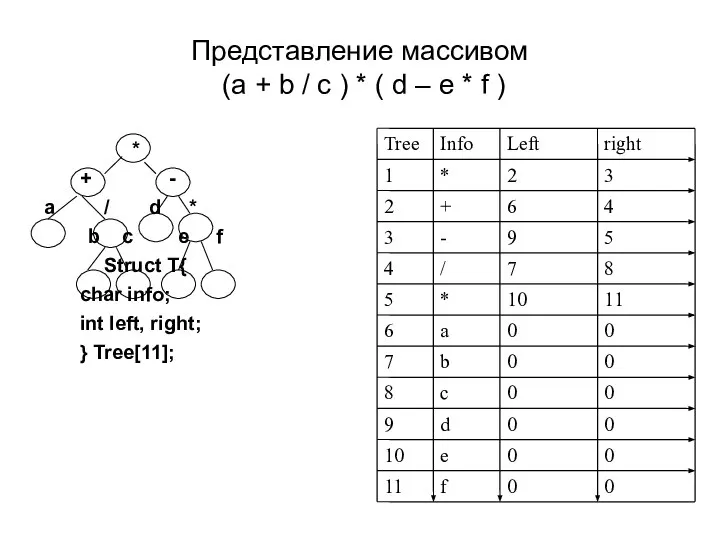
Слайд 32Представление дерева массивом
Представление дерева массивом позволяет легко находить путь от корня к
Представление дерева массивом
Представление дерева массивом позволяет легко находить путь от корня к

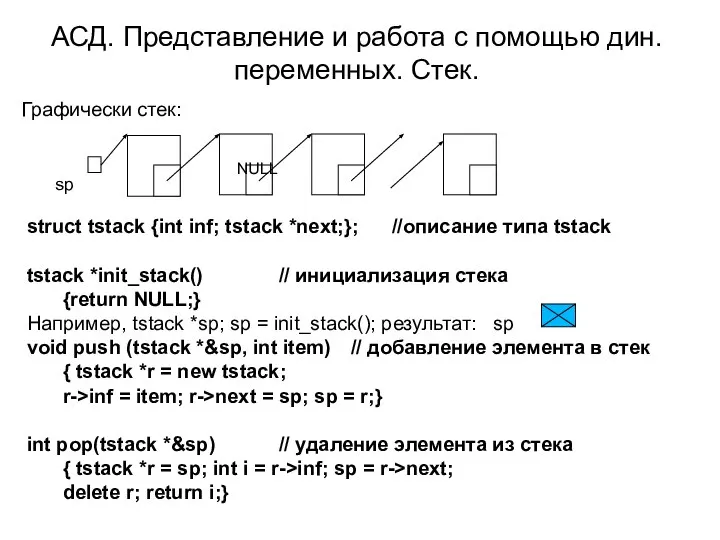
Слайд 33АСД. Представление и работа с помощью дин. переменных. Стек.
Графически стек:
NULL
sp
struct tstack {int
АСД. Представление и работа с помощью дин. переменных. Стек.
Графически стек:
NULL
sp
struct tstack {int
Слайд 34Стек с помощью дин. переменных
просмотр элемента, расположенного на вершине стека
int peek(tstack *sp)
Стек с помощью дин. переменных
просмотр элемента, расположенного на вершине стека
int peek(tstack *sp)

Слайд 35#include
#include "stackint.h"
#include
using namespace std;
void main() {
FILE *h = fopen("input_stack.txt”,"r"); //
#include
#include "stackint.h"
#include
using namespace std;
void main() {
FILE *h = fopen("input_stack.txt”,"r"); //

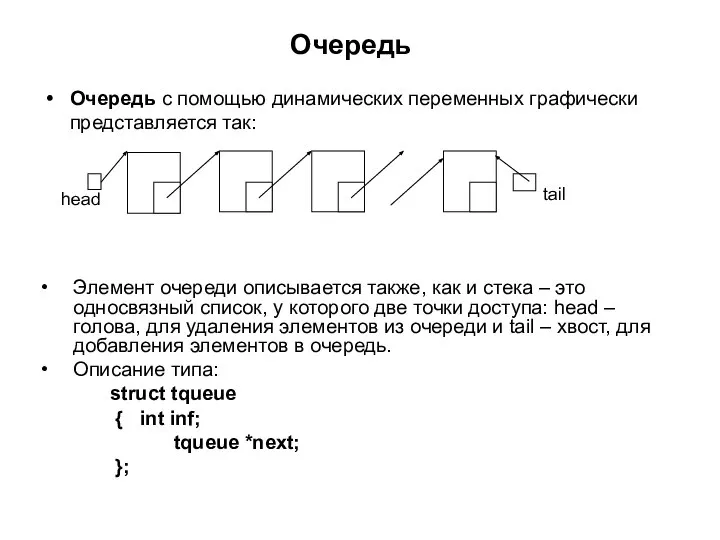
Слайд 36Очередь
Очередь с помощью динамических переменных графически представляется так:
tail
head
Элемент очереди описывается также, как
Очередь
Очередь с помощью динамических переменных графически представляется так:
tail
head
Элемент очереди описывается также, как
Слайд 37Очередь
1. Инициализация очереди:
head = NULL; tail = NULL; head tail
2. Добавить
Очередь
1. Инициализация очереди:
head = NULL; tail = NULL; head tail
2. Добавить
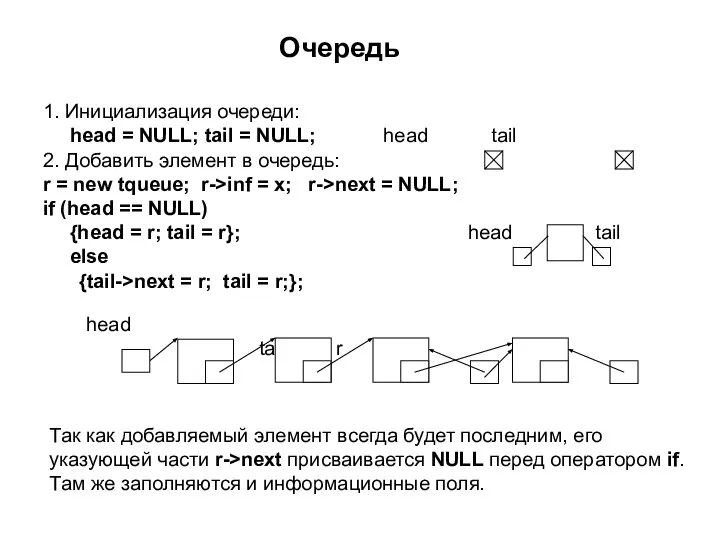
Слайд 383. Взять элемент из очереди:
if (head != NULL)
{r = head;
3. Взять элемент из очереди:
if (head != NULL)
{r = head;

Слайд 39Общие операции со списками.
Описание элемента списка в общем виде:
struct tnode {int
Общие операции со списками.
Описание элемента списка в общем виде:
struct tnode {int
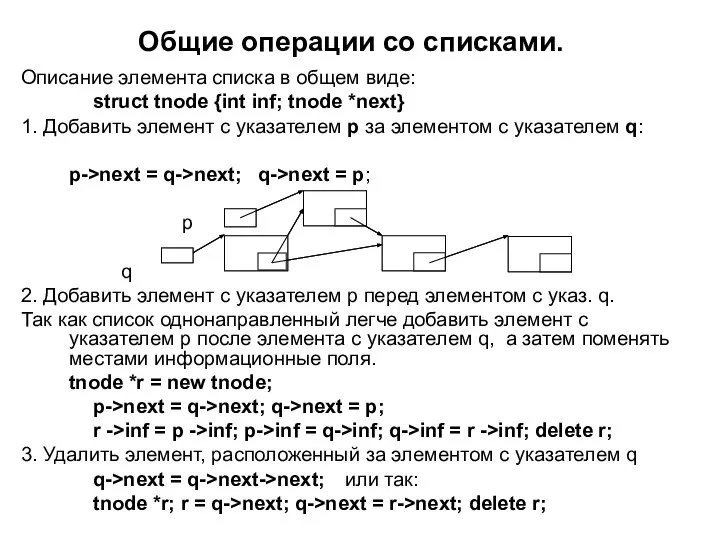
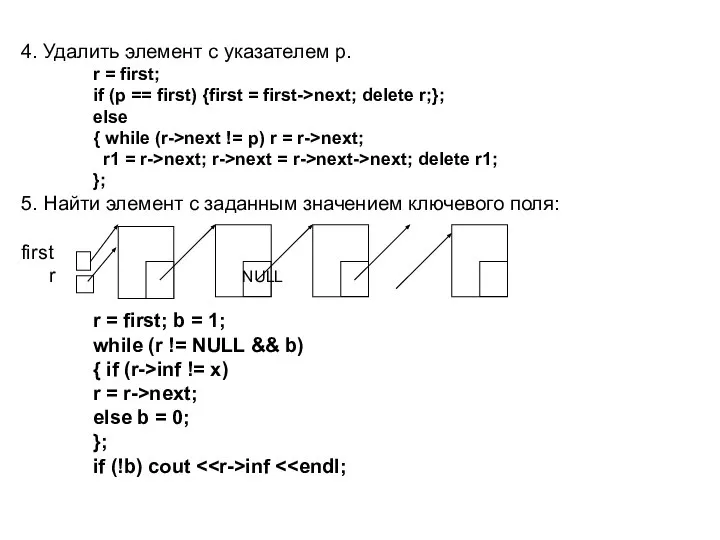
Слайд 404. Удалить элемент с указателем p.
r = first;
if (p == first)
4. Удалить элемент с указателем p.
r = first;
if (p == first)
Слайд 41Бинарные деревья, программирование их с помощью динамических переменных.
Дерево – это структура данных,
Бинарные деревья, программирование их с помощью динамических переменных.
Дерево – это структура данных,

Слайд 42Построение дерева с n узлами и минимальной высотой
Идеально сбалансированное дерево…
Пусть
Построение дерева с n узлами и минимальной высотой
Идеально сбалансированное дерево…
Пусть

Слайд 43Идеально сбалансированное дерево.
Функция, возвращающая значение:
tnode *Tree (int n)
{ tnode *r; int
Идеально сбалансированное дерево.
Функция, возвращающая значение:
tnode *Tree (int n)
{ tnode *r; int

Слайд 44Бинарные деревья
Если n = 21 и с клавиатуры введены номера вершин в
Бинарные деревья
Если n = 21 и с клавиатуры введены номера вершин в
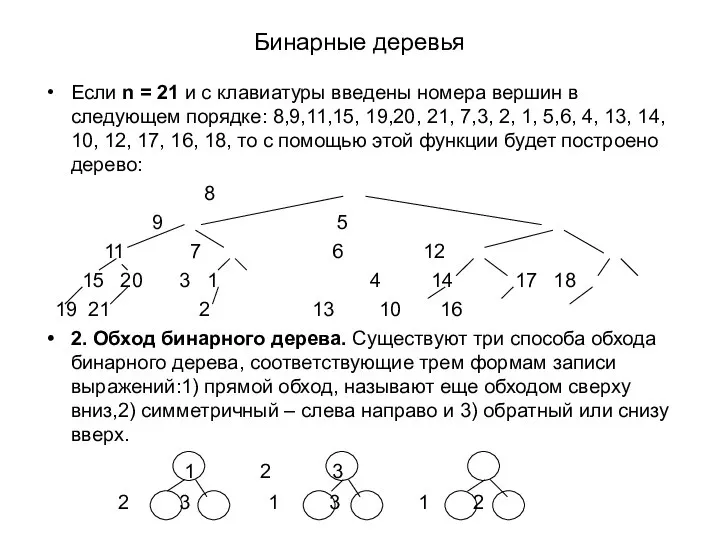
Слайд 45Обходы бинарного дерева:
void Preorder (tnode *&t) //прямой
{ if (t != NULL)
Обходы бинарного дерева:
void Preorder (tnode *&t) //прямой
{ if (t != NULL)

Слайд 46#include “iostream” // построение и обход дерева мин. высоты
using namespace std;
struct tnode
#include “iostream” // построение и обход дерева мин. высоты
using namespace std;
struct tnode

Слайд 47Построение бинарного упорядоченного дерева
Пусть ключевое поле – это поле inf и
Построение бинарного упорядоченного дерева
Пусть ключевое поле – это поле inf и

Слайд 48Построениe бинарного упорядоченного дерева
……………………………………………………………………………………
r = NULL; cin >> x;
while (x!=0)
{
Построениe бинарного упорядоченного дерева
……………………………………………………………………………………
r = NULL; cin >> x;
while (x!=0)
{
Слайд 49Удаление из упорядоченного дерева
tnode *q;
void Del_node(int x, tnode *&t)
{ if (t
Удаление из упорядоченного дерева
tnode *q;
void Del_node(int x, tnode *&t)
{ if (t

Слайд 50В функции Del_node первая ветвь оператора if выводит сообщение,
что искомого элемента в
В функции Del_node первая ветвь оператора if выводит сообщение,
что искомого элемента в
Слайд 51Создание, обход и удаление из дерева поиска
#include "iostream"
using namespace std;
struct tnode {int
Создание, обход и удаление из дерева поиска
#include "iostream"
using namespace std;
struct tnode {int

Слайд 52tnode *q;
void Del_vs (tnode *&r); // прототип функции
void Del_node(int x, tnode
tnode *q;
void Del_vs (tnode *&r); // прототип функции
void Del_node(int x, tnode

Слайд 53int main ()
{ tnode *r; int x, n ;
r = NULL;
cout
int main ()
{ tnode *r; int x, n ;
r = NULL;
cout

Слайд 54Сильно ветвящиеся деревья
Сильно ветвящиеся деревья - это деревья у узлов которых
Сильно ветвящиеся деревья
Сильно ветвящиеся деревья - это деревья у узлов которых

Слайд 55Графы
Граф G = (V,E) состоит из конечного множества вершин V и множества
Графы
Граф G = (V,E) состоит из конечного множества вершин V и множества
Слайд 56Графы
Если в графе G(V,E) ребро {u,v} или дуга є E, то
Графы
Если в графе G(V,E) ребро {u,v} или дуга

Слайд 57Cпособы представления графов
Cпособы представления графов: 1)матрица инциденции,
2) матрица смежности, 3) список
Cпособы представления графов
Cпособы представления графов: 1)матрица инциденции,
2) матрица смежности, 3) список
Слайд 58Cпособы представления графов
Для представленного орграфа матрица инциденции:
<1,2> <1,3> <3,2> <3,4> <5,4>
Cпособы представления графов
Для представленного орграфа матрица инциденции:
<1,2> <1,3> <3,2> <3,4> <5,4>

Слайд 59Cпособы представления графов
На практике ребер в графе бывает обычно больше, чем вершин...
Второй
Cпособы представления графов
На практике ребер в графе бывает обычно больше, чем вершин...
Второй

Слайд 60Cпособы представления графов
Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я и
Cпособы представления графов
Для орграфа 2-я и 4-я строки нулевые, т.к. 2-я и

Слайд 61Cпособы представления графов
Четвертый способ представления – список списков снимает ограничение и
Cпособы представления графов
Четвертый способ представления – список списков снимает ограничение и
Слайд 62Способы обхода графа
……Существуют два способа обхода графа: 1) обход графа в
Способы обхода графа
……Существуют два способа обхода графа: 1) обход графа в
Слайд 63Обход графа в глубину
Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот метод.
Обход графа в глубину
Существуют рекурсивный и не рекурсивный алгоритмы, реализующие этот метод.

Слайд 64Обход графа в глубину
Здесь V – множество всех вершин данного графа
Spisok[v] –
Обход графа в глубину
Здесь V – множество всех вершин данного графа
Spisok[v] –

Слайд 65Обход графа в глубину - не рекурсивный
function DFS1 (v);
begin
Обход графа в глубину - не рекурсивный
function DFS1 (v);
begin

Слайд 66Нерекурсивный обход графа в глубину
function DFS1 (v);
begin
stack = 0;
Нерекурсивный обход графа в глубину
function DFS1 (v);
begin
stack = 0;

Слайд 67Обход графа в ширину (Breadth First Search)
Поиск (обход) в графе в
Обход графа в ширину (Breadth First Search)
Поиск (обход) в графе в
Слайд 68Обход графа в ширину
Алгоритм обхода в ширину на псевдокоде можно записать так:
function
Обход графа в ширину
Алгоритм обхода в ширину на псевдокоде можно записать так:
function

Слайд 69Обход графа в ширину
Оба алгоритма могут использоваться для нахождения пути между данными
Обход графа в ширину
Оба алгоритма могут использоваться для нахождения пути между данными

Слайд 70Представление графов в С/С++
Матрицу инциденции и матрицу смежности можно представить двумерным массивом
Представление графов в С/С++
Матрицу инциденции и матрицу смежности можно представить двумерным массивом

 Креатив и оптимизация: друзья или враги?
Креатив и оптимизация: друзья или враги? Экономика и финансы. Творческая школа Хорошие презентации
Экономика и финансы. Творческая школа Хорошие презентации Методы обработки информации
Методы обработки информации Устройство ПК
Устройство ПК 5 Типы данных
5 Типы данных Носители информации. Кодирование информации. Способы кодирования информации
Носители информации. Кодирование информации. Способы кодирования информации Operators and Expression / 1 of 25
Operators and Expression / 1 of 25 Компьютерное зрение
Компьютерное зрение Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий
Комплексный интернет-маркетинг. Аналитика. Академия Digital-профессий Редактирование текста
Редактирование текста Вход в личный кабинет
Вход в личный кабинет Дополнительные устройства компьютера
Дополнительные устройства компьютера Планерка. Семейство IG
Планерка. Семейство IG Шаблон паспорта проектной идеи
Шаблон паспорта проектной идеи Измерение текстовой информации
Измерение текстовой информации Комплектующие компьютера
Комплектующие компьютера Разработка архитектурного прототипа системы для репетиторства
Разработка архитектурного прототипа системы для репетиторства Делаем первый проект
Делаем первый проект Свинограм
Свинограм Базы данных
Базы данных Використання інформаційних технологій у вирішенні галузевих завдань
Використання інформаційних технологій у вирішенні галузевих завдань Эллиптическое шифрование
Эллиптическое шифрование Диаграммы и графики
Диаграммы и графики Базы данных
Базы данных Информационные технологии на уроках
Информационные технологии на уроках Медиация в моей жизни
Медиация в моей жизни Растровая и векторная графика
Растровая и векторная графика Признаки предметов
Признаки предметов