- Кодирование текста

Содержание
- 2. §6 (начало и п1) (стр.43–45) – выучить. Вопрос 1 (стр. 51) – устно. Домашнее задание
- 3. Представление данных и программ в компьютере Итак, чтобы компьютер мог воспринять и обработать числовые значения, текст,
- 4. в памяти – ? Кодирование текста на экране – символы двоичные коды
- 5. Вспомним n – информационный вес символа – количество бит в двоичном коде. N – мощность алфавита
- 6. Кодовые таблицы Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы – наборы кодов
- 7. Кодовая таблица ASCII ASCII (англ. American standard code for information interchange, [’æs.ki]) — самая популярная кодовая
- 8. Первая половина таблицы ASCII
- 9. Вторая половина таблицы ASCII
- 10. Проблема ASCII Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы (0—127) занимают всегда
- 11. Кириллица в ASCII К сожалению, в настоящее время существуют много различных кодовых таблиц для кириллицы в
- 12. Разные кодировки кириллицы Одним из первых стандартов кодирования русских букв был КОИ8 ("Код обмена информацией, 8-битный").
- 13. Unicode С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется
- 14. UTF-8 UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») — одна из общепринятых
- 16. Скачать презентацию

Слайд 3Представление данных и программ в компьютере
Итак, чтобы компьютер мог воспринять и обработать
Представление данных и программ в компьютере
Итак, чтобы компьютер мог воспринять и обработать
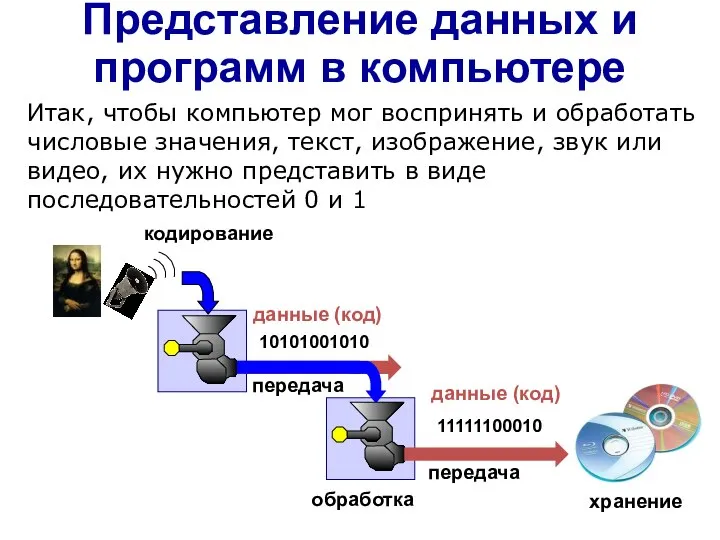
Слайд 4в памяти – ?
Кодирование текста
на экране – символы
двоичные коды
в памяти – ?
Кодирование текста
на экране – символы
двоичные коды

Слайд 5Вспомним
n – информационный вес символа – количество бит в двоичном коде.
N –
Вспомним
n – информационный вес символа – количество бит в двоичном коде.
N –

Слайд 6Кодовые таблицы
Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы
Кодовые таблицы
Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы

Слайд 7Кодовая таблица ASCII
ASCII (англ. American standard code for information interchange, [’æs.ki]) —
Кодовая таблица ASCII
ASCII (англ. American standard code for information interchange, [’æs.ki]) —
![Кодовая таблица ASCII ASCII (англ. American standard code for information interchange, [’æs.ki])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/958793/slide-6.jpg)
Слайд 8Первая половина таблицы ASCII
Первая половина таблицы ASCII
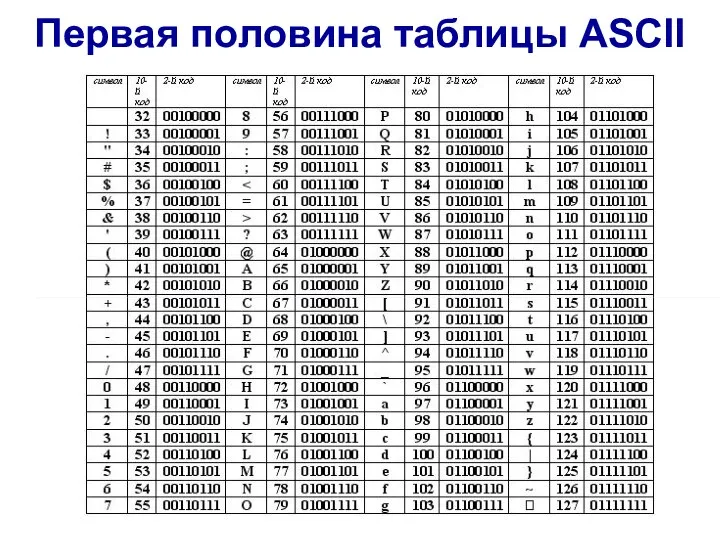
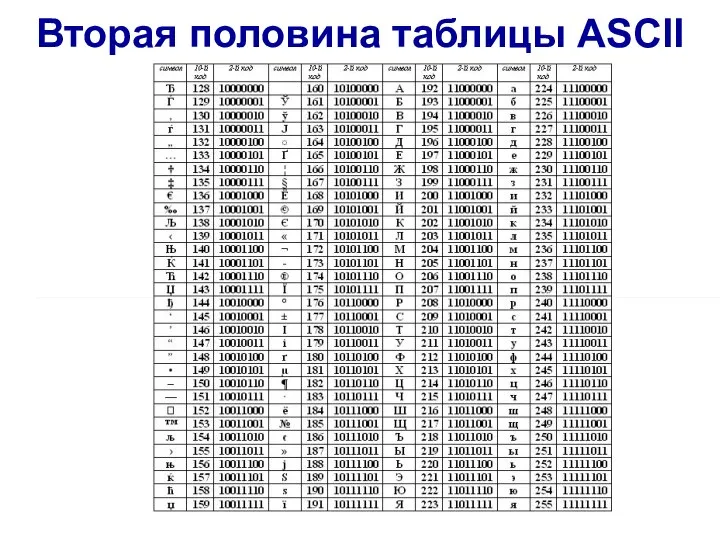
Слайд 9Вторая половина таблицы ASCII
Вторая половина таблицы ASCII
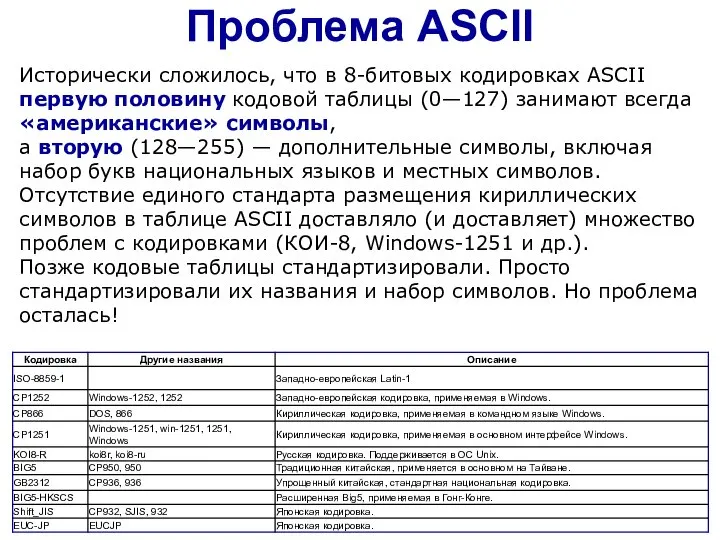
Слайд 10Проблема ASCII
Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы
Проблема ASCII
Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы
Слайд 11Кириллица в ASCII
К сожалению, в настоящее время существуют много различных кодовых таблиц
Кириллица в ASCII
К сожалению, в настоящее время существуют много различных кодовых таблиц

Слайд 12Разные кодировки кириллицы
Одним из первых стандартов кодирования русских букв был КОИ8 ("Код
Разные кодировки кириллицы
Одним из первых стандартов кодирования русских букв был КОИ8 ("Код

Слайд 13Unicode
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного
Unicode
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного

Слайд 14UTF-8
UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») —
UTF-8
UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») —

 Пять секретов убедительной речи. Курс Голос успеха. Вебинар
Пять секретов убедительной речи. Курс Голос успеха. Вебинар Роль визуальных социальных сетей в формировании политического имиджа
Роль визуальных социальных сетей в формировании политического имиджа Двумерные массивы
Двумерные массивы Визуализация рекламной деятельности на персональном компьютере на примере создания поздравительных материалов к юбилею техникума
Визуализация рекламной деятельности на персональном компьютере на примере создания поздравительных материалов к юбилею техникума Вселенная коллекционера
Вселенная коллекционера Проектирование информационных систем (ИС). Нормативная база. Модели качества ПО ИС
Проектирование информационных систем (ИС). Нормативная база. Модели качества ПО ИС Трон — многопользовательская аркадная игра, основанная на одноименном фильме 1982 года
Трон — многопользовательская аркадная игра, основанная на одноименном фильме 1982 года net intro
net intro Устройство компьютера. Ребусы
Устройство компьютера. Ребусы Интернет-ресурсы. Подготовка к ЕГЭ по математике
Интернет-ресурсы. Подготовка к ЕГЭ по математике Soul.village. Аккаунты в Instagram
Soul.village. Аккаунты в Instagram Презентация на тему Файловый ввод и вывод на Паскале
Презентация на тему Файловый ввод и вывод на Паскале  Виды СУБД
Виды СУБД Направления развития информатики
Направления развития информатики Разметка и параметризация изображений. Лекция 11
Разметка и параметризация изображений. Лекция 11 Создание запросов. 11 класс
Создание запросов. 11 класс Рекурсивный перебор с возвратом. Семинар для учителей информатики
Рекурсивный перебор с возвратом. Семинар для учителей информатики Примеры САПР
Примеры САПР Формирование: первая, вторая и третья нормальные формы. Нормальная форма Бойс-кода
Формирование: первая, вторая и третья нормальные формы. Нормальная форма Бойс-кода Мир социальных сетей
Мир социальных сетей Логические команды, сдвиги, битовые команды. Логические команды. (Лекция 11)
Логические команды, сдвиги, битовые команды. Логические команды. (Лекция 11) Распределение функциональных требований безопасности
Распределение функциональных требований безопасности Особенности материалов для соцсетей: пост, лонгрид подкаст
Особенности материалов для соцсетей: пост, лонгрид подкаст Рабочие окна приложений операционной системы Windows
Рабочие окна приложений операционной системы Windows Сделай свой сайт. Новый поток бесплатной онлайн-школы Я блогер
Сделай свой сайт. Новый поток бесплатной онлайн-школы Я блогер Побитовые операции
Побитовые операции Vytváření a úpravy tabulek
Vytváření a úpravy tabulek Адресация в IP-сетях (2)
Адресация в IP-сетях (2)