- Квантовые игры и теоретико-игровые основания прагматики

Содержание
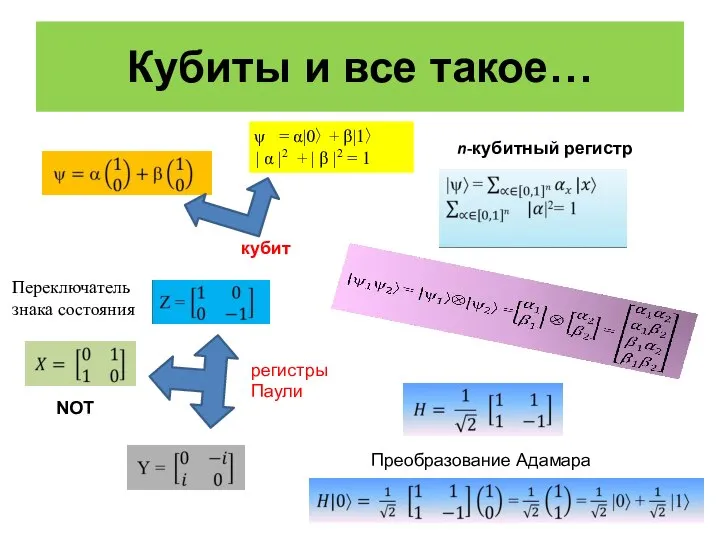
- 2. Кубиты и все такое… = α|0〉 + β|1〉 | α |2 + | β |2 =
- 3. Алгоритм квантового компьютера Приготовь начальное состояние (обычно берется |00…0〉 ) Примени последовательность унитарных преобразований Проделай измерение
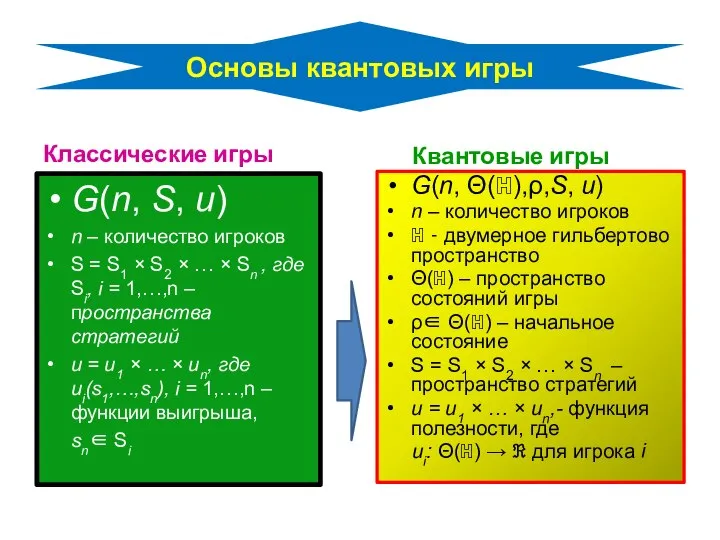
- 4. Основы квантовых игры Классические игры G(n, S, u) n – количество игроков S = S1 ×
- 5. Статические и динамические квантовые игры U U’ измерение U1 U2 U U’ измерение U1 U2
- 6. Переворачивание монеты Классический случай Квантовый случай P против Q Ходы: судья кладет монету орлом вверх Q
- 7. PQ – переворачивание монеты UQ1 = H U1 = X или I UQ1 = H измерение
- 8. Логика квантовых вычислений QCL Регистры Тоффоли T(1,1,1): ⊗3ℍ → ⊗3ℍ T(1,1,1)(|x〉⊗|y〉⊗|z〉) = |x〉⊗|y〉⊗|min(x,y)⊗z〉 Q(1,1,1): ⊗3ℍ →
- 9. Логика Дишканта LQ Г.Дишкант [1978] предложил включить аксиомы Макки в исчисление Лукасевича Łℵ0 и построил модальное
- 10. Логика Дишканта LQ I:W0 → S есть ŁQ - интерпретация, если она удовлетворяет следующим условиям: (I)
- 11. Логика Дишканта LQ A1. A → (B → A) A2. (A → B) → ((B →
- 12. Логика Дишканта LQ Ł-фрейм 〈O,K,R,*〉, где K есть непустое множество, O∈K, R - тернарное отношение достижимости
- 13. Логика Дишканта LQ (R1) Если 1й игрок принимает A → B в точке a, то всякий
- 15. Скачать презентацию
Слайд 3Алгоритм квантового компьютера
Приготовь начальное состояние (обычно берется |00…0〉 )
Примени последовательность унитарных преобразований
Проделай
Алгоритм квантового компьютера
Приготовь начальное состояние (обычно берется |00…0〉 )
Примени последовательность унитарных преобразований
Проделай

Слайд 4Основы квантовых игры
Классические игры
G(n, S, u)
n – количество игроков
S = S1 ×
Основы квантовых игры
Классические игры
G(n, S, u)
n – количество игроков
S = S1 ×
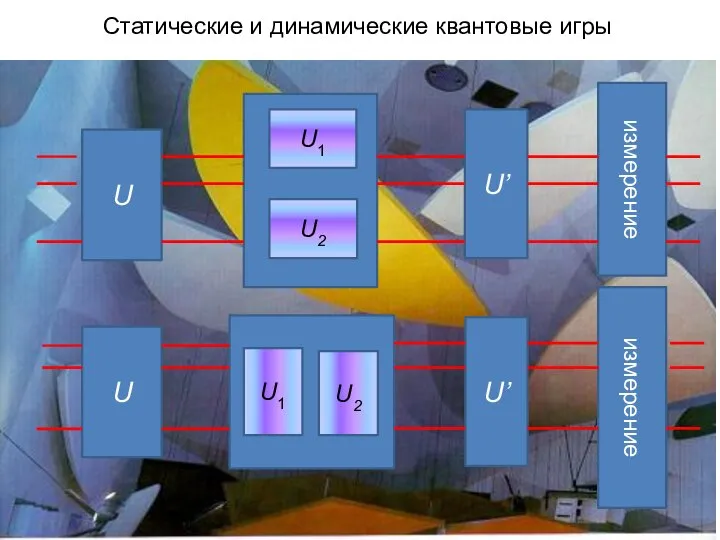
Слайд 5Статические и динамические квантовые игры
U
U’
измерение
U1
U2
U
U’
измерение
U1
U2
Статические и динамические квантовые игры
U
U’
измерение
U1
U2
U
U’
измерение
U1
U2
Слайд 6Переворачивание монеты
Классический случай
Квантовый случай
P против Q
Ходы:
судья кладет монету орлом вверх
Q либо переворачивает
Переворачивание монеты
Классический случай
Квантовый случай
P против Q
Ходы:
судья кладет монету орлом вверх
Q либо переворачивает

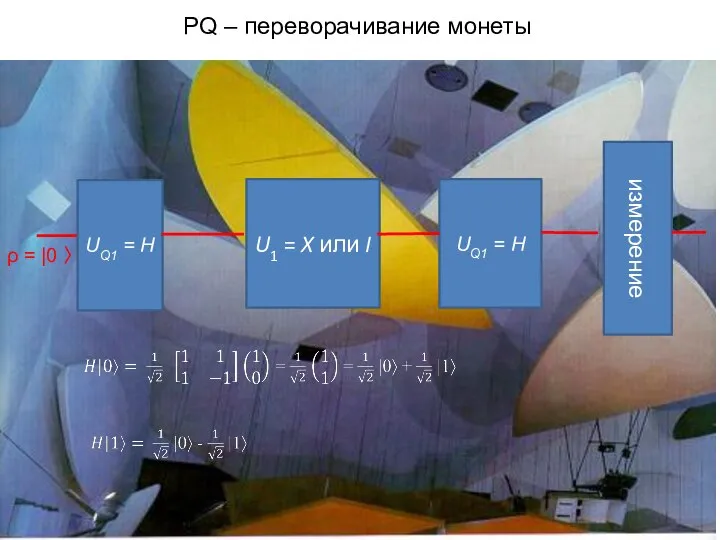
Слайд 7PQ – переворачивание монеты
UQ1 = H
U1 = X или I
UQ1 = H
измерение
ρ
PQ – переворачивание монеты
UQ1 = H
U1 = X или I
UQ1 = H
измерение
ρ
Слайд 8Логика квантовых вычислений QCL
Регистры Тоффоли
T(1,1,1): ⊗3ℍ → ⊗3ℍ
T(1,1,1)(|x〉⊗|y〉⊗|z〉) = |x〉⊗|y〉⊗|min(x,y)⊗z〉
Q(1,1,1):
Логика квантовых вычислений QCL
Регистры Тоффоли
T(1,1,1): ⊗3ℍ → ⊗3ℍ
T(1,1,1)(|x〉⊗|y〉⊗|z〉) = |x〉⊗|y〉⊗|min(x,y)⊗z〉
Q(1,1,1):

Слайд 9Логика Дишканта LQ
Г.Дишкант [1978] предложил включить аксиомы Макки в исчисление Лукасевича Łℵ0
Логика Дишканта LQ
Г.Дишкант [1978] предложил включить аксиомы Макки в исчисление Лукасевича Łℵ0
![Логика Дишканта LQ Г.Дишкант [1978] предложил включить аксиомы Макки в исчисление Лукасевича](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1051610/slide-8.jpg)
Слайд 10Логика Дишканта LQ
I:W0 → S есть ŁQ - интерпретация, если она удовлетворяет
Логика Дишканта LQ
I:W0 → S есть ŁQ - интерпретация, если она удовлетворяет

Слайд 11Логика Дишканта LQ
A1. A → (B → A)
A2. (A → B) →
Логика Дишканта LQ
A1. A → (B → A)
A2. (A → B) →

Слайд 12Логика Дишканта LQ
Ł-фрейм 〈O,K,R,*〉,
где K есть непустое
множество, O∈K,
R -
Логика Дишканта LQ
Ł-фрейм 〈O,K,R,*〉,
где K есть непустое
множество, O∈K,
R -

Слайд 13Логика Дишканта LQ
(R1) Если 1й игрок принимает A → B в точке
Логика Дишканта LQ
(R1) Если 1й игрок принимает A → B в точке

 Мастерская. Шаблоны
Мастерская. Шаблоны Устройства компьютера
Устройства компьютера Master-klass_po_napisaniyu_statyey
Master-klass_po_napisaniyu_statyey Программное обеспечение (ПО) персонального компьютера
Программное обеспечение (ПО) персонального компьютера О состоянии и распространении различных видов Интернет – угроз
О состоянии и распространении различных видов Интернет – угроз Практика в СМЦ
Практика в СМЦ Загальні принципи діі КС, структури високопродуктивних систем
Загальні принципи діі КС, структури високопродуктивних систем Характеристика систем цифрового кабельного телевизионного вещания
Характеристика систем цифрового кабельного телевизионного вещания Simcenter femap 2022.1
Simcenter femap 2022.1 Проектирование и разработка мобильных приложений под операционную систему android
Проектирование и разработка мобильных приложений под операционную систему android Портфолио обучающих программ EcoStruxure ™ Machine Expert HVAC. Модуль 4 - HMI на ESME HVAC и M172P
Портфолио обучающих программ EcoStruxure ™ Machine Expert HVAC. Модуль 4 - HMI на ESME HVAC и M172P Применение штрих-кода в торговле и производстве
Применение штрих-кода в торговле и производстве Движение за объектом
Движение за объектом NET Core и .NET Framework
NET Core и .NET Framework Устройства памяти
Устройства памяти Информационно-технологическая архитектура ИС
Информационно-технологическая архитектура ИС Основные конструкции языка Java
Основные конструкции языка Java Power Point Урок_2
Power Point Урок_2 Мастер-класс по созданию маски в instagram
Мастер-класс по созданию маски в instagram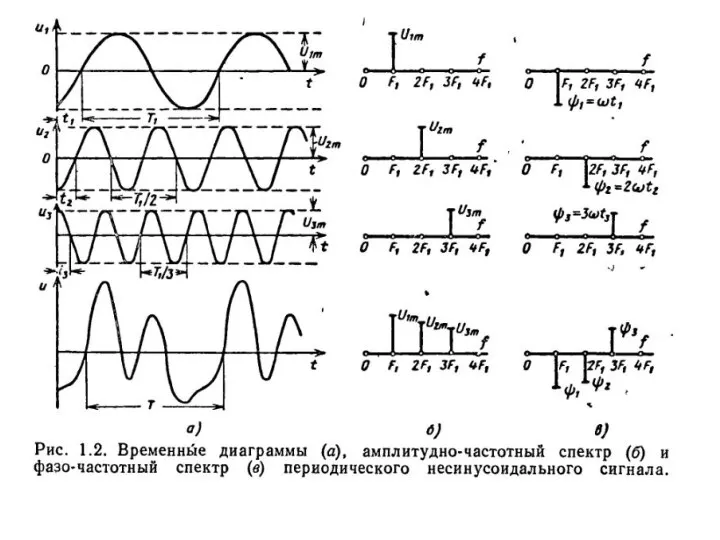 Теорема Котельникова
Теорема Котельникова Максимальное использование потенциала
Максимальное использование потенциала Знакомство с графическим оператором DRAW. Информатика 5 класс
Знакомство с графическим оператором DRAW. Информатика 5 класс Учебная практика по компьютерной графике
Учебная практика по компьютерной графике Разработка системы управления взаимоотношениями с клиентами-CRM на примере
Разработка системы управления взаимоотношениями с клиентами-CRM на примере Планета алгоритмика. Клад
Планета алгоритмика. Клад Программное обеспечение. Введение
Программное обеспечение. Введение Руководство по комплектованию персонального компьтера
Руководство по комплектованию персонального компьтера Презентация на тему Форматирование текста в MS Word
Презентация на тему Форматирование текста в MS Word