- Sklearn.impute. Transformers for missing value imputation

Содержание
- 2. Imputation transformer for completing missing values. Multivariate imputer that estimates each feature from all the others.
- 3. SimpleImputer IterativeImputer, KNNImputer Imputes values in the i-th feature dimension using only non-missing values in that
- 4. All imputers implement methods:
- 5. Simple Imputer class sklearn.impute.SimpleImputer SimpleImputer( missing_values=nan, strategy='mean’, fill_value=None, verbose=0, copy=True, add_indicator=False ) The placeholder for the
- 6. Example
- 7. Iterative Imputer class sklearn.impute.IterativeImputer A strategy for imputing missing values by modeling each feature with missing
- 8. Iterative Imputer class sklearn.impute.IterativeImputer IterativeImputer( estimator=None missing_values=nan, initial_strategy='mean’, n_nearest_features=None, verbose=0, imputation_order='ascending’, random_state=None …. many other settings
- 9. Example
- 10. k-Nearest Neighbors Imputer class sklearn.impute.KNNImputer KNNImputer( missing_values=nan, n_neighbors=5, weights='uniform’, metric='nan_euclidean’, copy=True, add_indicator=False ) The placeholder for
- 11. Example
- 12. Marking imputed values class sklearn.impute.MissingIndicator MissingIndicator( missing_values=nan, features='missing-only', sparse='auto', error_on_new=True’, ) The placeholder for the missing
- 14. Скачать презентацию
Слайд 2Imputation transformer for completing missing values.
Multivariate imputer that estimates each feature from
Imputation transformer for completing missing values.
Multivariate imputer that estimates each feature from
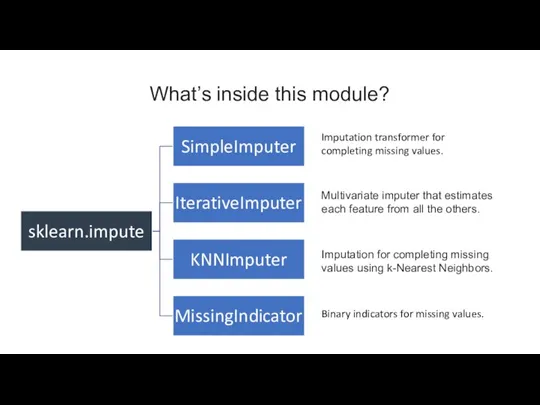
Слайд 3SimpleImputer
IterativeImputer,
KNNImputer
Imputes values in the i-th feature dimension using only non-missing values in
SimpleImputer
IterativeImputer,
KNNImputer
Imputes values in the i-th feature dimension using only non-missing values in
Слайд 4All imputers implement methods:
All imputers implement methods:

Слайд 5Simple Imputer
class sklearn.impute.SimpleImputer
SimpleImputer(
missing_values=nan,
strategy='mean’,
fill_value=None,
verbose=0,
copy=True,
add_indicator=False
)
The placeholder for the missing values
The imputation strategy:
‘constant’, ‘mean’,
Simple Imputer
class sklearn.impute.SimpleImputer
SimpleImputer(
missing_values=nan,
strategy='mean’,
fill_value=None,
verbose=0,
copy=True,
add_indicator=False
)
The placeholder for the missing values
The imputation strategy:
‘constant’, ‘mean’,

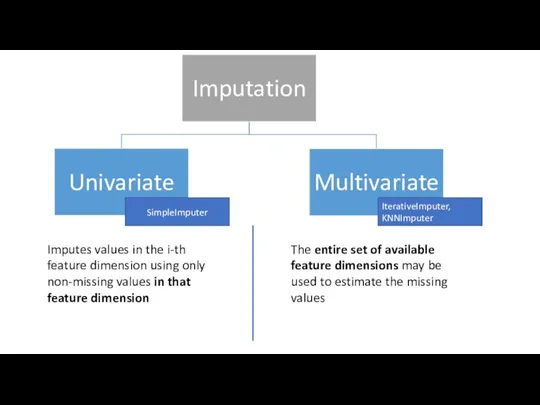
Слайд 6Example
Example
Слайд 7Iterative Imputer
class sklearn.impute.IterativeImputer
A strategy for imputing missing values by modeling each feature
Iterative Imputer
class sklearn.impute.IterativeImputer
A strategy for imputing missing values by modeling each feature

Слайд 8Iterative Imputer
class sklearn.impute.IterativeImputer
IterativeImputer(
estimator=None
missing_values=nan,
initial_strategy='mean’,
n_nearest_features=None,
verbose=0,
imputation_order='ascending’,
random_state=None
….
many other settings
)
The estimator to use
Iterative Imputer
class sklearn.impute.IterativeImputer
IterativeImputer(
estimator=None
missing_values=nan,
initial_strategy='mean’,
n_nearest_features=None,
verbose=0,
imputation_order='ascending’,
random_state=None
….
many other settings
)
The estimator to use

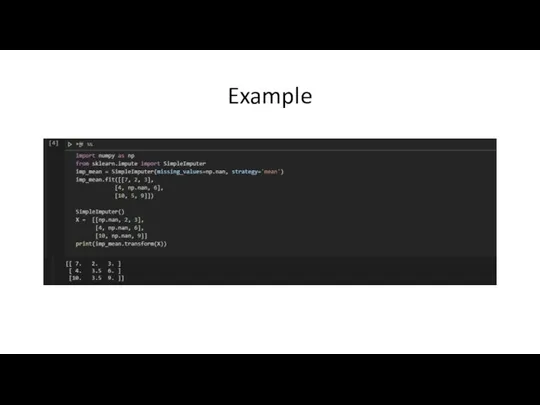
Слайд 9Example
Example
Слайд 10k-Nearest Neighbors Imputer
class sklearn.impute.KNNImputer
KNNImputer(
missing_values=nan,
n_neighbors=5,
weights='uniform’,
metric='nan_euclidean’,
copy=True,
add_indicator=False
)
The
k-Nearest Neighbors Imputer
class sklearn.impute.KNNImputer
KNNImputer(
missing_values=nan,
n_neighbors=5,
weights='uniform’,
metric='nan_euclidean’,
copy=True,
add_indicator=False
)
The

Слайд 11Example
Example
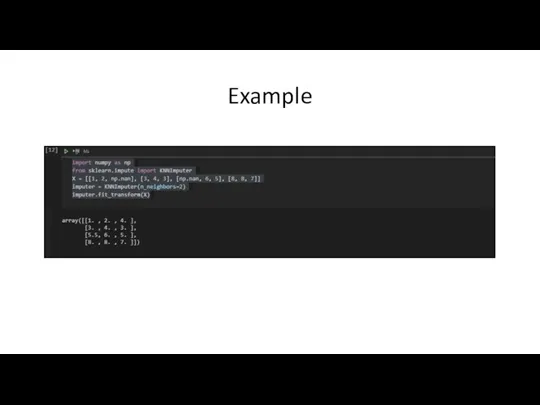
Слайд 12Marking imputed values
class sklearn.impute.MissingIndicator
MissingIndicator(
missing_values=nan,
features='missing-only',
sparse='auto',
error_on_new=True’,
)
The placeholder for the
Marking imputed values
class sklearn.impute.MissingIndicator
MissingIndicator(
missing_values=nan,
features='missing-only',
sparse='auto',
error_on_new=True’,
)
The placeholder for the

 Урок информатики в 7 классе
Урок информатики в 7 классе Программирование на языке С++
Программирование на языке С++ Распространение информации
Распространение информации Виды ссылок в ЭТ
Виды ссылок в ЭТ Интерактивные технологии. Облака слов. Форсайт-игра
Интерактивные технологии. Облака слов. Форсайт-игра Способы подключения к Интернету
Способы подключения к Интернету Компьютерная графика
Компьютерная графика Безопасный интернет. Интернет: вред и польза
Безопасный интернет. Интернет: вред и польза Компьютерная графика
Компьютерная графика RFID технология: Открытая библиотека
RFID технология: Открытая библиотека Списки. Срезы списков
Списки. Срезы списков Информационная безопасность
Информационная безопасность Применение технологии формирующего оценивания Цепочка заметок на уроке информатики
Применение технологии формирующего оценивания Цепочка заметок на уроке информатики Основы работы в QlikView
Основы работы в QlikView Редактор электронных таблиц MS Excel. Тема 3
Редактор электронных таблиц MS Excel. Тема 3 Презентация "Моделирование и формализация. Разработка и исследование математических моделей на компьютере" - скачать презен
Презентация "Моделирование и формализация. Разработка и исследование математических моделей на компьютере" - скачать презен Цвет в компьютерной графике
Цвет в компьютерной графике Как ИКТ помогают в ведении бизнеса
Как ИКТ помогают в ведении бизнеса Информатика. Представление чисел в ЭВМ. Лекция 4
Информатика. Представление чисел в ЭВМ. Лекция 4 2 ой раздел вводного экскурса в геоквантуме
2 ой раздел вводного экскурса в геоквантуме Программное обеспечение конроллеров. Алгоблоки
Программное обеспечение конроллеров. Алгоблоки Форсаж 2018
Форсаж 2018 Жанры тележурналистики
Жанры тележурналистики Умный город
Умный город Аналитика сайтов ЛПУ Хабаровского края
Аналитика сайтов ЛПУ Хабаровского края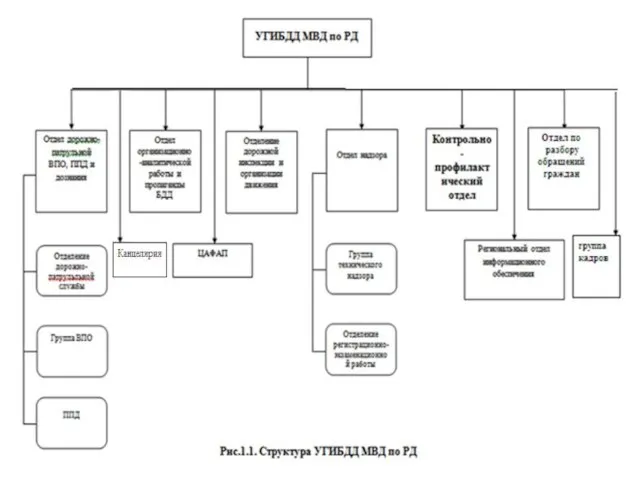 Организационная структура управления УГИБДД МВД по РД
Организационная структура управления УГИБДД МВД по РД Научная добросовестность и качество поиска и использования интеллектуальных ресурсов
Научная добросовестность и качество поиска и использования интеллектуальных ресурсов Language-Integrated Query (LINQ)
Language-Integrated Query (LINQ)