- Neural Networks

Содержание
- 2. Pachshenko Galina Nikolaevna Associate Professor of Information System Department, Candidate of Technical Science
- 3. Week 4 Lecture 4
- 4. Topics Single-layer neural networks Multi-layer neural networks Single perceptron Multi-layer perceptron Hebbian Learning Rule Back propagation
- 5. Single-layer neural networks
- 6. Multi-layer neural networks
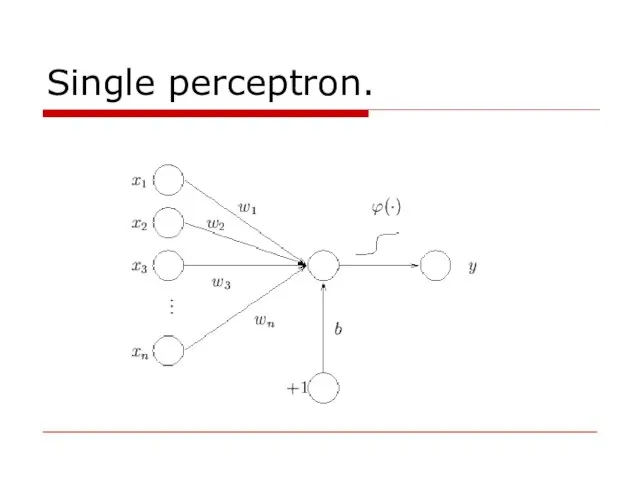
- 7. Single perceptron The perceptron computes a single output from multiple real-valued inputs by forming a linear
- 8. Single perceptron. Mathematically this can be written as
- 9. Single perceptron.
- 10. Task 1: Write a program that finds output of a single perceptron. Note: Use bias. The
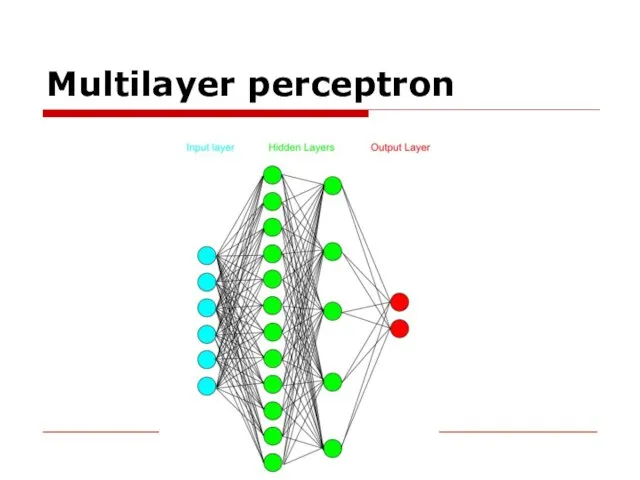
- 11. Multilayer perceptron A multilayer perceptron (MLP) is a class of feedforward artificial neural network.
- 12. Multilayer perceptron
- 13. Structure • nodes that are no target of any connection are called input neurons.
- 14. • nodes that are no source of any connection are called output neurons. A MLP can
- 15. • all nodes that are neither input neurons nor output neurons are called hidden neurons. •
- 16. The original Rosenblatt's perceptron used a Heaviside step function as the activation function.
- 17. Nowadays, in multilayer networks, the activation function is often chosen to be the sigmoid function
- 18. or the hyperbolic tangent
- 19. They are related by
- 20. These functions are used because they are mathematically convenient.
- 21. An MLP consists of at least three layers of nodes. Except for the input nodes, each
- 22. MLP utilizes a supervised learning technique called backpropagation for training.
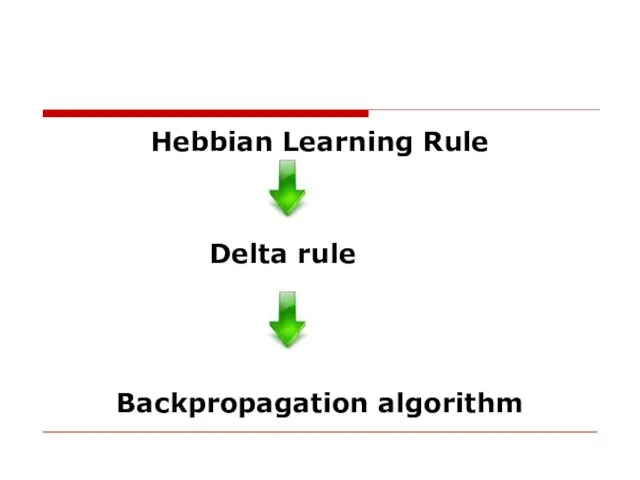
- 23. Hebbian Learning Rule Delta rule Backpropagation algorithm
- 24. Hebbian Learning Rule (Hebb's rule) The Hebbian Learning Rule (1949) is a learning rule that specifies
- 25. Hebbian Learning Rule (Hebb's rule)
- 27. Delta rule (proposed in 1960)
- 28. The backpropagation algorithm was originally introduced in the 1970s, but its importance wasn't fully appreciated until
- 29. That paper describes several neural networks where backpropagation works far faster than earlier approaches to learning,
- 30. Supervised Backpropagation – The mechanism of backward error transmission (delta learning rule) is used to modify
- 31. Back propagation The back propagation learning algorithm uses the delta-rule. What this does is that it
- 32. The delta rule is derived by attempting to minimize the error in the output of the
- 33. To compute the deltas of the output neurons though we first have to get the error
- 34. That’s pretty simple, since the multi-layer perceptron is a supervised training network so the error is
- 35. Now to compute the deltas: deltaj(L)(n) = ej(L)(n) * f'(uj(L)(n)) , for neuron j in the
- 36. The same formula:
- 37. Weight adjustment Having calculated the deltas for all the neurons we are now ready for the
- 38. Weight adjustment
- 39. For
- 40. Note: For sigmoid activation function Derivative of the function: S'(x) = S(x)*(1 - S(x))
- 42. Cost Function We need a function that will minimize the parameters over our dataset. One common
- 43. Squared Error: which we can minimize using gradient descent A cost function is something you want
- 44. Back-propagation is a gradient descent over the entire networks weight vectors. In practice, it often works
- 45. Task 2: Write a program that can update weights of neural network using backpropagation.
- 47. Скачать презентацию

Слайд 3Week 4
Lecture 4
Week 4
Lecture 4

Слайд 4Topics
Single-layer neural networks
Multi-layer neural networks
Single perceptron
Multi-layer perceptron
Hebbian Learning Rule
Back propagation
Delta-rule
Weight adjustment
Cost Function
Сlassification
Topics
Single-layer neural networks
Multi-layer neural networks
Single perceptron
Multi-layer perceptron
Hebbian Learning Rule
Back propagation
Delta-rule
Weight adjustment
Cost Function
Сlassification

Слайд 5 Single-layer neural networks
Single-layer neural networks
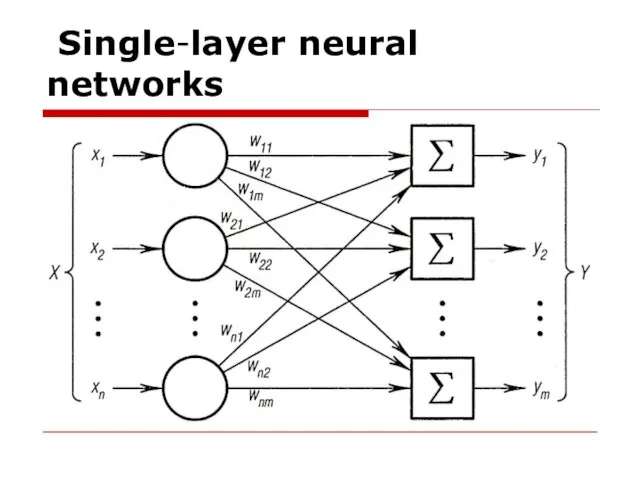
Слайд 6Multi-layer neural networks
Multi-layer neural networks

Слайд 7Single perceptron
The perceptron computes a single output from multiple real-valued inputs by forming a linear combination
Single perceptron
The perceptron computes a single output from multiple real-valued inputs by forming a linear combination

Слайд 8Single perceptron.
Mathematically this can be written as
Single perceptron.
Mathematically this can be written as

Слайд 9Single perceptron.
Single perceptron.
Слайд 10Task 1:
Write a program that finds output of a single perceptron.
Note:
Use bias.
Task 1:
Write a program that finds output of a single perceptron.
Note:
Use bias.

Слайд 11Multilayer perceptron
A multilayer perceptron (MLP) is a class of feedforward artificial neural network.
Multilayer perceptron
A multilayer perceptron (MLP) is a class of feedforward artificial neural network.

Слайд 12Multilayer perceptron
Multilayer perceptron
Слайд 13Structure
• nodes that are no target of any connection are called input
Structure
• nodes that are no target of any connection are called input

Слайд 14• nodes that are no source of any connection are called output
• nodes that are no source of any connection are called output

Слайд 15• all nodes that are neither input neurons nor output neurons are
• all nodes that are neither input neurons nor output neurons are

Слайд 16The original Rosenblatt's perceptron used a Heaviside step function as the activation
The original Rosenblatt's perceptron used a Heaviside step function as the activation

Слайд 17Nowadays, in multilayer networks, the activation function is often chosen to be
Nowadays, in multilayer networks, the activation function is often chosen to be

Слайд 18or the hyperbolic tangent
or the hyperbolic tangent

Слайд 19They are related by
They are related by

Слайд 20These functions are used because they are mathematically convenient.
These functions are used because they are mathematically convenient.

Слайд 21An MLP consists of at least three layers of nodes.
Except for the
An MLP consists of at least three layers of nodes.
Except for the

Слайд 22MLP utilizes a supervised learning technique called backpropagation for training.
MLP utilizes a supervised learning technique called backpropagation for training.

Слайд 23Hebbian Learning Rule
Delta rule
Backpropagation algorithm
Hebbian Learning Rule
Delta rule
Backpropagation algorithm
Слайд 24
Hebbian Learning Rule
(Hebb's rule)
The Hebbian Learning Rule (1949)
is a learning rule that
Hebbian Learning Rule
(Hebb's rule)
The Hebbian Learning Rule (1949)
is a learning rule that

Слайд 25Hebbian Learning Rule
(Hebb's rule)
Hebbian Learning Rule
(Hebb's rule)


Слайд 27Delta rule
(proposed in 1960)
Delta rule
(proposed in 1960)

Слайд 28The backpropagation algorithm was originally introduced in the 1970s, but its importance
The backpropagation algorithm was originally introduced in the 1970s, but its importance

Слайд 29That paper describes several neural networks where backpropagation works far faster than
That paper describes several neural networks where backpropagation works far faster than

Слайд 30Supervised Backpropagation – The mechanism of backward error transmission (delta learning rule)
Supervised Backpropagation – The mechanism of backward error transmission (delta learning rule)

Слайд 31Back propagation
The back propagation learning algorithm uses the delta-rule.
What this does
Back propagation
The back propagation learning algorithm uses the delta-rule.
What this does

Слайд 32The delta rule is derived by attempting to minimize the error in
The delta rule is derived by attempting to minimize the error in

Слайд 33To compute the deltas of the output neurons though we first have
To compute the deltas of the output neurons though we first have

Слайд 34That’s pretty simple, since the multi-layer perceptron is a supervised training network
That’s pretty simple, since the multi-layer perceptron is a supervised training network

Слайд 35Now to compute the deltas:
deltaj(L)(n) = ej(L)(n) * f'(uj(L)(n)) ,
for neuron j
Now to compute the deltas:
deltaj(L)(n) = ej(L)(n) * f'(uj(L)(n)) ,
for neuron j

Слайд 36The same formula:
The same formula:

Слайд 37Weight adjustment
Having calculated the deltas for all the neurons we are now
Weight adjustment
Having calculated the deltas for all the neurons we are now

Слайд 38Weight adjustment
Weight adjustment

Слайд 39For
For

Слайд 40Note: For sigmoid activation function
Derivative of the function:
S'(x) = S(x)*(1 -
Note: For sigmoid activation function
Derivative of the function:
S'(x) = S(x)*(1 -


Слайд 42
Cost Function
We need a function that will minimize the parameters over our
Cost Function We need a function that will minimize the parameters over our

Слайд 43Squared Error: which we can minimize using gradient descent
A cost function is
Squared Error: which we can minimize using gradient descent
A cost function is

Слайд 44Back-propagation is a gradient descent over the entire networks weight vectors.
In practice,
Back-propagation is a gradient descent over the entire networks weight vectors.
In practice,

Слайд 45Task 2:
Write a program that can update weights of neural network using
Task 2:
Write a program that can update weights of neural network using

 Microsoft Office. Краткая характеристика программ офисного пакета
Microsoft Office. Краткая характеристика программ офисного пакета Презентация на тему Мобильная связь (поколение мобильных телефонов)
Презентация на тему Мобильная связь (поколение мобильных телефонов)  История развития вычислительной техники
История развития вычислительной техники Устройства ввода графической информации. Практическая работа № 8. Работаем с графическими фрагментами
Устройства ввода графической информации. Практическая работа № 8. Работаем с графическими фрагментами Информационные технологии в инженерной практике
Информационные технологии в инженерной практике Разработка программы для тестирования знаний учеников по информатике на языке программирования C#
Разработка программы для тестирования знаний учеников по информатике на языке программирования C# Основы работы с информацией. Часть 2. Тема 1.2
Основы работы с информацией. Часть 2. Тема 1.2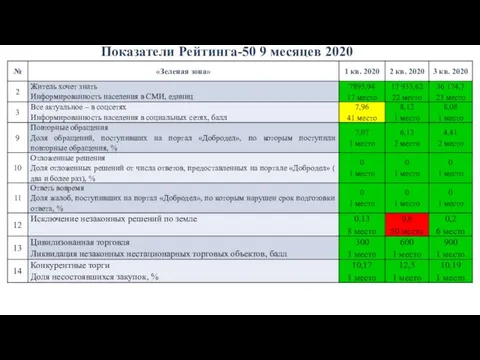 Показатели Рейтинга-50
Показатели Рейтинга-50 Багатошарова віртуальна мережа
Багатошарова віртуальна мережа Продающий или непродающий
Продающий или непродающий Информационная система исследование норм нагрузки
Информационная система исследование норм нагрузки Lecture04_Python_Expressions
Lecture04_Python_Expressions Проект по реализации турнира по геополитическому симулятору
Проект по реализации турнира по геополитическому симулятору Проект ITeam
Проект ITeam Інтерактивний веб-сайт з використанням технологій доповненої реальності
Інтерактивний веб-сайт з використанням технологій доповненої реальності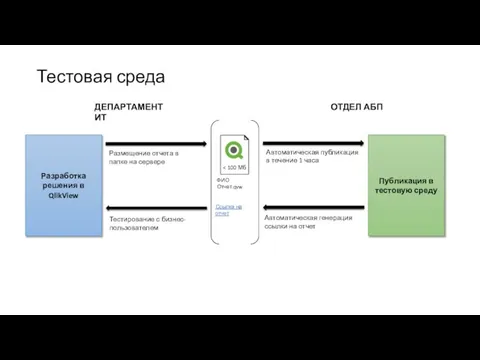 Процесс взаимодействия с IT
Процесс взаимодействия с IT Статистический анализ информационной безопасности и кибер-рисков
Статистический анализ информационной безопасности и кибер-рисков Тестовая отчетность (лекция - 8)
Тестовая отчетность (лекция - 8) Файлы и файловые структуры. Работа с учебником и опорным конспектом
Файлы и файловые структуры. Работа с учебником и опорным конспектом 3D принтер для строительства домов как шаг в будущее
3D принтер для строительства домов как шаг в будущее Методы проектирования организации сложных комплексов работ на основе матричных моделей с применением программы MS Project
Методы проектирования организации сложных комплексов работ на основе матричных моделей с применением программы MS Project л2_сетевые приложения
л2_сетевые приложения Чемпионат CyberHeroes
Чемпионат CyberHeroes Презентация на тему Функциональная схема компьютера
Презентация на тему Функциональная схема компьютера  Использование прикладных компьютерных программ в экологических исследованиях
Использование прикладных компьютерных программ в экологических исследованиях Защита информации
Защита информации Функции и модули 2
Функции и модули 2 Моё хобби
Моё хобби