- Понятие информации в теории Шеннона

Содержание
- 2. Случайное событие – означает отсутствие полной уверенности в его наступлении. Пусть опыт имеет n равновероятных исходов.
- 3. f(1) = 0, если n = 1 исход опыта не является случайным и неопределенность отсутствует; f(n)
- 4. Пусть α и β независимые опыты. nα, nβ - число равновероятных исходов. Рассмотрим сложный опыт, который
- 5. f(nα ∙ nβ) - мера неопределенности сложного опыта. α и β – независимы, т.е. в сложном
- 6. f(1) = 0 f(n) возрастает с ростом n f(nα ∙ nβ)= f(nα) + f(nβ) Этим свойствам
- 7. Выбор основания логарифма значения не имеет. переход к другому основанию состоит во введении одинакового для обеих
- 8. Удобно, основание 2. За единицу измерения принимается неопределенность, содержащаяся в опыте, имеющем лишь два равновероятных исхода,
- 9. Определение. Мера неопределенности опыта, имеющего n равновероятных исходов равна f(n)=log2(n). (4.1) Эта величина – энтропия, обозначается
- 10. Рассмотрим опыт с n равновероятными исходами. Неопределенность, вносимую одним исходом? где р =1/n - вероятность любого
- 11. Пусть исходы неравновероятны, р(А1) и р(А2) – вероятности исходов. Если опыт α имеет n неравновероятных исходов
- 12. Используя формулу для среднего значения дискретных случайных величин: А(α) - обозначает исходы, возможные в опыте α.
- 13. Определение. Энтропия является мерой неопределенности опыта, в котором проявляются случайные события, и равна средней неопределенности всех
- 14. ПРИМЕР Имеются два ящика, в каждом из которых по 12 шаров. В первом - 3 белых,
- 15. Нβ > Нα, т.е. неопределенность результата в опыте β выше и, следовательно, предсказать его можно с
- 16. Свойства энтропии 1) Н > 0. Н = 0 в двух случаях: (а) если p(Aj) =
- 17. 2) Для двух независимых опытов α и β Энтропия сложного опыта, состоящего из нескольких независимых, равна
- 18. 3) При прочих равных условиях наибольшую энтропию имеет опыт с равновероятными исходами.
- 19. Условная энтропия Найдем энтропию сложного опыта α ^ β (опыты не являются независимыми, на исход β
- 20. Подставим в (7)
- 21. В первом слагаемом индекс j имеется только у B; изменив порядок суммирования, получим члены вида:
- 22. Свойства условной энтропии 1. Условная энтропия является величиной неотрицательной. Hα(β) = 0, если любой исход α
- 23. Пример 2.2. В ящике имеются 2 белых шара и 4 черных. Из ящика извлекают последовательно два
- 24. Задача 2.3. Имеется три тела с одинаковыми внешними размерами, но с разными массами х1, х2 и
- 25. 2.2. Энтропия и информация Определение. I - информацией относительно опыта β, содержащейся в опыте α I(α,β)=H
- 26. Следствие 1. Единицы измерения количество информации – бит. Следствие 2. Пусть опыт α = β, тогда
- 27. Свойств информации: 1. /(α, β) ≥ 0, причем /(α, β) = 0 тогда и только тогда,
- 28. Пример 2.4. Какое количество информации требуется, чтобы узнать исход броска монеты? Пример 2.5. Виктор Сергеевич задумал
- 30. Количество информации численно равно числу вопросов с равновероятными бинарными вариантами ответов, которые необходимо задать, чтобы полностью
- 31. Формула Хартли (1928). 30.11.1888 - 1.05.1970 (81). США
- 32. Cвязывает количество равновероятных состояний (n) и (/), что любое из этих состояний реализовалось. Частным случаем применения
- 33. Пример 2.6 В.С. случайным образом вынимает карта из колоды в 32 карты. Какое количество информации требуется,
- 34. Выводы 1. Выражение является статистическим определением понятия «информация», поскольку в него входят вероятности возможных исходов опыта.
- 35. 2. Если начальная энтропия опыта Н1, а в результате сообщения информации / энтропия становится равной Н2
- 36. Если изначально равновероятных исходов было n1, а в результате передачи информации I неопределенность уменьшилась, и число
- 37. Определение. Информация - это содержание сообщения, понижающего неопределенность некоторого опыта с неоднозначным исходом; убыль связанной с
- 38. 3. Аддитивность информации. Пусть IА = log2nA - первого опыта, IB = log2nB - второго опыта,
- 39. 4. Рассмотрим опыт, реализующийся посредством двух случайных событий; если эти события равновероятны, р1 = р2 =
- 40. График этой функции Ответ на бинарный вопрос может содержать не более 1 бит информации; информация равна
- 41. Пример 2.8. При угадывании результата броска игральной кости задается вопрос «Выпало 6?». Какое количество информации содержит
- 42. На бытовом уровне, «информация» отождествляется с «информированностью», т.е. человеческим знанием. В «теории информации» информация является мерой
- 43. Глава 3. Кодирование символьной информации 3.1. Постановка задачи кодирования. Первая теорема Шеннона 3.2. Способы построения двоичных
- 44. 3.1. Постановка задачи кодирования. Первая теорема Шеннона Код (1) правило, описывающее соответствие знаков или их сочетаний
- 45. Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов. Кодер
- 46. Источник представляет информацию в форме дискретного сообщения, используя для этого алфавит - первичным. Далее сообщение попадает
- 47. Математическая постановка задачи кодировании. Пусть первичный алфавит А состоит из N знаков со средней информацией на
- 48. Операция обратимого кодирования может увеличить количество информации в сообщении, но не может его уменьшить.
- 49. т/n - характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного
- 50. Обычно N > М и I(А) > I(В), откуда К(А,В) > 1, т.е. один знак первичного
- 51. Минимально возможным значением средней длины кода устанавливающее нижний предел длины кода.
- 52. Первая теорема Шеннона (основная теорема о кодировании при отсутствии помех). 1. При отсутствии помех всегда возможен
- 53. Смысл теоремы: теорема открывает принципиальную возможность оптимального кодирования, т.е. построения кода со средней длиной Кmin(А,В).
- 54. Два пути сокращения Кmin(А,В): 1. уменьшение числителя - если при кодировании учесть различие частот появления разных
- 55. Для первого приближения Относительная избыточность кода:
- 56. Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения. Q(A,B) → 0 при К(А,В) →
- 57. Наиболее важной для практики оказывается ситуация, когда М = 2, т.е. для представления кодов в линии
- 59. 3.2. Способы построения двоичных кодов
- 60. Возможны следующие особенности вторичного алфавита: элементарные сигналы (0 и 1) могут иметь одинаковые длительности (to=t1) или
- 61. 3.2.1. Алфавитное неравномерное двоичное кодирование сигналами равной длительности. Префиксные коды
- 62. знаки первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1). длина кодов
- 63. Для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время T=K(A,2) ∙t Построить такую
- 64. Решение: коды знаков первичного алфавита, вероятность появления которых в сообщении выше, следует строить из возможно меньшего
- 65. А) Неравномерный код с разделителем Разделителем отдельных кодов букв будет последовательность 00. Разделителем слов-слов – 000.
- 66. Правила построения кодов: код признака конца знака может быть включен в код буквы (т.е. коды всех
- 68. Среднюю длину кода К(r,2) для данного способа кодирования: (по определению средней дискретной величины).
- 69. I1(r) = 4,356 бит. Избыточность данного кода: При данном способе кодирования будет передаваться приблизительно на 14%
- 70. Рассмотрев один из вариантов двоичного неравномерного кодирования, возникают вопросы: 1) Возможно ли такое кодирование без использования
- 71. Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом (префиксом) какого-либо
- 72. Пример 3.1. Пусть имеется следующая таблица префиксных кодов: Требуется декодировать сообщение: 00100010000111010101110000110
- 73. Декодирование производится циклически 1. отрезать от текущего сообщения крайний левый символ, присоединить справа к рабочему кодовому
- 75. Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким. Условие Фано не устанавливает способа формирования
- 76. В) Префиксный код Шеннона-Фано. Данный вариант кодирования был предложен в 1948-1949 гг. независимо Р. Фано и
- 77. Пусть имеется первичный алфавит А, состоящий из шести знаков а1 ...а6 с вероятностями появления в сообщении,
- 79. Средняя длина кода равна: I1(A) = 2,390 бит. избыточность кода Q(A,2) = 0,0249, т.е. около 2,5%.
- 80. Данный код нельзя считать оптимальным, поскольку вероятности появления 0 и 1 неодинаковы (6/17=0,35 и 11/17=0,65, соответственно).
- 81. С) Префиксный код Хаффмана
- 82. Способ оптимального префиксного двоичного кодирования был предложен Д. Хаффманом. Построение кодов Хаффмана рассмотрим на том же
- 83. Аналогично продолжим создавать новые алфавиты, пока в последнем не останется два знака. Количество таких шагов будет
- 84. В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей.
- 85. Теперь в обратном направлении проведем процедуру кодирования.
- 86. К(А,2) = 0,3 ∙ 2 + 0,2 ∙ 2 + 0,2 ∙ 2 +0,15 ∙ 3
- 87. Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является самым экономичным из всех
- 88. Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана) - нашли широчайшее применение
- 90. Скачать презентацию

Слайд 3f(1) = 0, если n = 1 исход опыта не является случайным
f(1) = 0, если n = 1 исход опыта не является случайным

Слайд 4Пусть α и β независимые опыты.
nα, nβ - число равновероятных исходов.
Рассмотрим сложный
Пусть α и β независимые опыты.
nα, nβ - число равновероятных исходов.
Рассмотрим сложный

Слайд 5f(nα ∙ nβ) - мера неопределенности сложного опыта.
α и β –
f(nα ∙ nβ) - мера неопределенности сложного опыта.
α и β –

Слайд 6f(1) = 0
f(n) возрастает с ростом n
f(nα ∙ nβ)= f(nα) + f(nβ)
Этим
f(1) = 0
f(n) возрастает с ростом n
f(nα ∙ nβ)= f(nα) + f(nβ)
Этим

Слайд 7Выбор основания логарифма значения не имеет.
переход к другому основанию состоит во введении
Выбор основания логарифма значения не имеет.
переход к другому основанию состоит во введении

Слайд 8Удобно, основание 2.
За единицу измерения принимается неопределенность, содержащаяся в опыте, имеющем
Удобно, основание 2.
За единицу измерения принимается неопределенность, содержащаяся в опыте, имеющем

Слайд 9Определение. Мера неопределенности опыта, имеющего n равновероятных исходов равна
f(n)=log2(n). (4.1)
Эта величина –
Определение. Мера неопределенности опыта, имеющего n равновероятных исходов равна
f(n)=log2(n). (4.1)
Эта величина –

Слайд 10Рассмотрим опыт с n равновероятными исходами.
Неопределенность, вносимую одним исходом?
где р =1/n -
Рассмотрим опыт с n равновероятными исходами.
Неопределенность, вносимую одним исходом?
где р =1/n -

Слайд 11Пусть исходы неравновероятны,
р(А1) и р(А2) – вероятности исходов.
Если опыт α имеет
Пусть исходы неравновероятны,
р(А1) и р(А2) – вероятности исходов.
Если опыт α имеет

Слайд 12Используя формулу для среднего значения дискретных случайных величин:
А(α) - обозначает исходы,
Используя формулу для среднего значения дискретных случайных величин:
А(α) - обозначает исходы,

Слайд 13Определение. Энтропия является мерой неопределенности опыта, в котором проявляются случайные события, и
Определение. Энтропия является мерой неопределенности опыта, в котором проявляются случайные события, и

Слайд 14ПРИМЕР
Имеются два ящика, в каждом из которых по 12 шаров. В первом
ПРИМЕР
Имеются два ящика, в каждом из которых по 12 шаров. В первом

Слайд 15Нβ > Нα, т.е. неопределенность результата в опыте β выше и, следовательно,
Нβ > Нα, т.е. неопределенность результата в опыте β выше и, следовательно,

Слайд 16Свойства энтропии
1) Н > 0.
Н = 0 в двух случаях:
Свойства энтропии
1) Н > 0.
Н = 0 в двух случаях:

Слайд 172) Для двух независимых опытов α и β
Энтропия сложного опыта, состоящего из
2) Для двух независимых опытов α и β
Энтропия сложного опыта, состоящего из

Слайд 183) При прочих равных условиях наибольшую энтропию имеет опыт с равновероятными исходами.
3) При прочих равных условиях наибольшую энтропию имеет опыт с равновероятными исходами.

Слайд 19Условная энтропия
Найдем энтропию сложного опыта α ^ β (опыты не являются независимыми,
Условная энтропия
Найдем энтропию сложного опыта α ^ β (опыты не являются независимыми,

Слайд 20Подставим в (7)
Подставим в (7)

Слайд 21В первом слагаемом индекс j имеется только у B; изменив порядок суммирования,
В первом слагаемом индекс j имеется только у B; изменив порядок суммирования,

Слайд 22Свойства условной энтропии
1. Условная энтропия является величиной неотрицательной.
Hα(β) = 0,
Свойства условной энтропии
1. Условная энтропия является величиной неотрицательной.
Hα(β) = 0,

Слайд 23Пример 2.2.
В ящике имеются 2 белых шара и 4 черных. Из ящика
Пример 2.2. В ящике имеются 2 белых шара и 4 черных. Из ящика

Слайд 24Задача 2.3.
Имеется три тела с одинаковыми внешними размерами, но с разными массами
Задача 2.3.
Имеется три тела с одинаковыми внешними размерами, но с разными массами

Слайд 252.2. Энтропия и информация
Определение. I - информацией относительно опыта β, содержащейся в
2.2. Энтропия и информация
Определение. I - информацией относительно опыта β, содержащейся в

Слайд 26Следствие 1. Единицы измерения количество информации – бит.
Следствие 2. Пусть опыт α
Следствие 1. Единицы измерения количество информации – бит.
Следствие 2. Пусть опыт α

Слайд 27Свойств информации:
1. /(α, β) ≥ 0, причем /(α, β) = 0 тогда
Свойств информации:
1. /(α, β) ≥ 0, причем /(α, β) = 0 тогда

Слайд 28Пример 2.4. Какое количество информации требуется, чтобы узнать исход броска монеты?
Пример 2.5.
Пример 2.4. Какое количество информации требуется, чтобы узнать исход броска монеты?
Пример 2.5.


Слайд 30Количество информации численно равно числу вопросов с равновероятными бинарными вариантами ответов, которые
Количество информации численно равно числу вопросов с равновероятными бинарными вариантами ответов, которые

Слайд 31Формула Хартли (1928).
30.11.1888 - 1.05.1970 (81). США
Формула Хартли (1928).
30.11.1888 - 1.05.1970 (81). США

Слайд 32Cвязывает количество равновероятных состояний (n) и (/), что любое из этих состояний
Cвязывает количество равновероятных состояний (n) и (/), что любое из этих состояний

Слайд 33Пример 2.6 В.С. случайным образом вынимает карта из колоды в 32 карты.
Пример 2.6 В.С. случайным образом вынимает карта из колоды в 32 карты.

Слайд 34Выводы
1. Выражение
является статистическим определением понятия «информация», поскольку в него входят вероятности
Выводы
1. Выражение
является статистическим определением понятия «информация», поскольку в него входят вероятности

Слайд 352. Если начальная энтропия опыта Н1, а в результате сообщения информации /
2. Если начальная энтропия опыта Н1, а в результате сообщения информации /

Слайд 36Если изначально равновероятных исходов было n1, а в результате передачи информации I
Если изначально равновероятных исходов было n1, а в результате передачи информации I

Слайд 37Определение. Информация - это содержание сообщения, понижающего неопределенность некоторого опыта с неоднозначным
Определение. Информация - это содержание сообщения, понижающего неопределенность некоторого опыта с неоднозначным

Слайд 383. Аддитивность информации.
Пусть IА = log2nA - первого опыта,
IB =
3. Аддитивность информации.
Пусть IА = log2nA - первого опыта,
IB =

Слайд 394. Рассмотрим опыт, реализующийся посредством двух случайных событий; если эти события равновероятны,
4. Рассмотрим опыт, реализующийся посредством двух случайных событий; если эти события равновероятны,

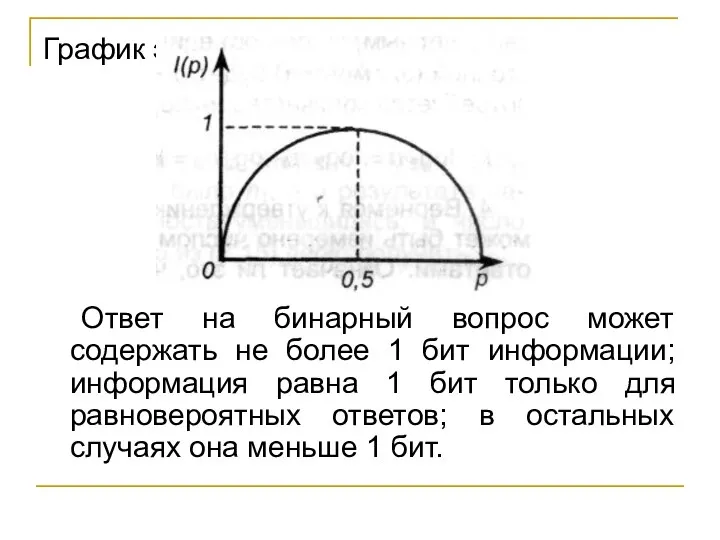
Слайд 40График этой функции
Ответ на бинарный вопрос может содержать не более 1 бит
График этой функции
Ответ на бинарный вопрос может содержать не более 1 бит
Слайд 41Пример 2.8. При угадывании результата броска игральной кости задается вопрос «Выпало 6?».
Пример 2.8. При угадывании результата броска игральной кости задается вопрос «Выпало 6?».

Слайд 42На бытовом уровне, «информация» отождествляется с «информированностью», т.е. человеческим знанием.
В «теории
На бытовом уровне, «информация» отождествляется с «информированностью», т.е. человеческим знанием.
В «теории

Слайд 43Глава 3. Кодирование символьной информации
3.1. Постановка задачи кодирования. Первая теорема Шеннона
3.2.
Глава 3. Кодирование символьной информации
3.1. Постановка задачи кодирования. Первая теорема Шеннона
3.2.

Слайд 443.1. Постановка задачи кодирования. Первая теорема Шеннона
Код
(1) правило, описывающее соответствие знаков
3.1. Постановка задачи кодирования. Первая теорема Шеннона
Код
(1) правило, описывающее соответствие знаков

Слайд 45Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по
Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по

Слайд 46Источник представляет информацию в форме дискретного сообщения, используя для этого алфавит -
Источник представляет информацию в форме дискретного сообщения, используя для этого алфавит -

Слайд 47Математическая постановка задачи кодировании. Пусть первичный алфавит
А состоит из N знаков
Математическая постановка задачи кодировании. Пусть первичный алфавит
А состоит из N знаков

Слайд 48Операция обратимого кодирования может увеличить количество информации в сообщении, но не может
Операция обратимого кодирования может увеличить количество информации в сообщении, но не может

Слайд 49т/n - характеризует среднее число знаков вторичного алфавита, которое приходится использовать для
т/n - характеризует среднее число знаков вторичного алфавита, которое приходится использовать для

Слайд 50Обычно N > М и I(А) > I(В), откуда К(А,В) > 1,
Обычно N > М и I(А) > I(В), откуда К(А,В) > 1,

Слайд 51Минимально возможным значением средней длины кода
устанавливающее нижний предел длины кода.
Минимально возможным значением средней длины кода
устанавливающее нижний предел длины кода.

Слайд 52Первая теорема Шеннона (основная теорема о кодировании при отсутствии помех).
1. При отсутствии
Первая теорема Шеннона (основная теорема о кодировании при отсутствии помех).
1. При отсутствии

Слайд 53Смысл теоремы: теорема открывает принципиальную возможность оптимального кодирования, т.е. построения кода со
Смысл теоремы: теорема открывает принципиальную возможность оптимального кодирования, т.е. построения кода со

Слайд 54Два пути сокращения Кmin(А,В):
1. уменьшение числителя - если при кодировании учесть
Два пути сокращения Кmin(А,В):
1. уменьшение числителя - если при кодировании учесть

Слайд 55Для первого приближения
Относительная избыточность кода:
Для первого приближения
Относительная избыточность кода:

Слайд 56Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения.
Q(A,B) →
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения.
Q(A,B) →

Слайд 57Наиболее важной для практики оказывается ситуация, когда М = 2, т.е. для
Наиболее важной для практики оказывается ситуация, когда М = 2, т.е. для


Слайд 593.2. Способы построения двоичных кодов
3.2. Способы построения двоичных кодов

Слайд 60Возможны следующие особенности вторичного алфавита:
элементарные сигналы (0 и 1) могут иметь одинаковые
Возможны следующие особенности вторичного алфавита:
элементарные сигналы (0 и 1) могут иметь одинаковые

Слайд 613.2.1. Алфавитное неравномерное двоичное кодирование сигналами равной длительности. Префиксные коды
3.2.1. Алфавитное неравномерное двоичное кодирование сигналами равной длительности. Префиксные коды

Слайд 62знаки первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0
знаки первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0

Слайд 63Для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время
Для передачи информации, в среднем приходящейся на знак первичного алфавита, необходимо время

Слайд 64Решение: коды знаков первичного алфавита, вероятность появления которых в сообщении выше, следует
Решение: коды знаков первичного алфавита, вероятность появления которых в сообщении выше, следует

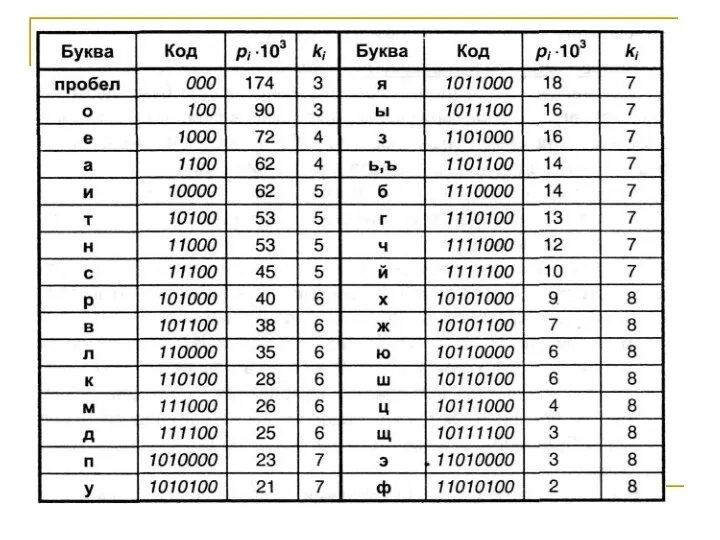
Слайд 65А) Неравномерный код с разделителем
Разделителем отдельных кодов букв будет последовательность 00.
Разделителем
А) Неравномерный код с разделителем
Разделителем отдельных кодов букв будет последовательность 00.
Разделителем

Слайд 66Правила построения кодов:
код признака конца знака может быть включен в код буквы
Правила построения кодов:
код признака конца знака может быть включен в код буквы

Слайд 68Среднюю длину кода К(r,2) для данного способа кодирования:
(по определению средней дискретной величины).
Среднюю длину кода К(r,2) для данного способа кодирования:
(по определению средней дискретной величины).

Слайд 69I1(r) = 4,356 бит.
Избыточность данного кода:
При данном способе кодирования будет передаваться
I1(r) = 4,356 бит.
Избыточность данного кода:
При данном способе кодирования будет передаваться

Слайд 70Рассмотрев один из вариантов двоичного неравномерного кодирования, возникают вопросы:
1) Возможно ли
Рассмотрев один из вариантов двоичного неравномерного кодирования, возникают вопросы:
1) Возможно ли

Слайд 71Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает

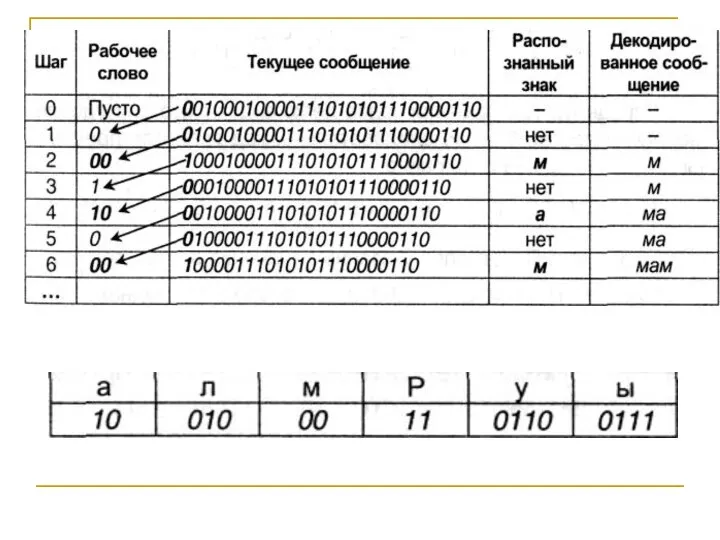
Слайд 72Пример 3.1.
Пусть имеется следующая таблица префиксных кодов:
Требуется декодировать сообщение:
00100010000111010101110000110
Пример 3.1.
Пусть имеется следующая таблица префиксных кодов:
Требуется декодировать сообщение:
00100010000111010101110000110

Слайд 73Декодирование производится циклически
1. отрезать от текущего сообщения крайний левый символ, присоединить
Декодирование производится циклически
1. отрезать от текущего сообщения крайний левый символ, присоединить

Слайд 75Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким.
Условие Фано
Условие Фано

Слайд 76В) Префиксный код Шеннона-Фано.
Данный вариант кодирования был предложен в 1948-1949 гг. независимо
В) Префиксный код Шеннона-Фано.
Данный вариант кодирования был предложен в 1948-1949 гг. независимо

Слайд 77Пусть имеется первичный алфавит А, состоящий из шести знаков а1 ...а6 с
Пусть имеется первичный алфавит А, состоящий из шести знаков а1 ...а6 с

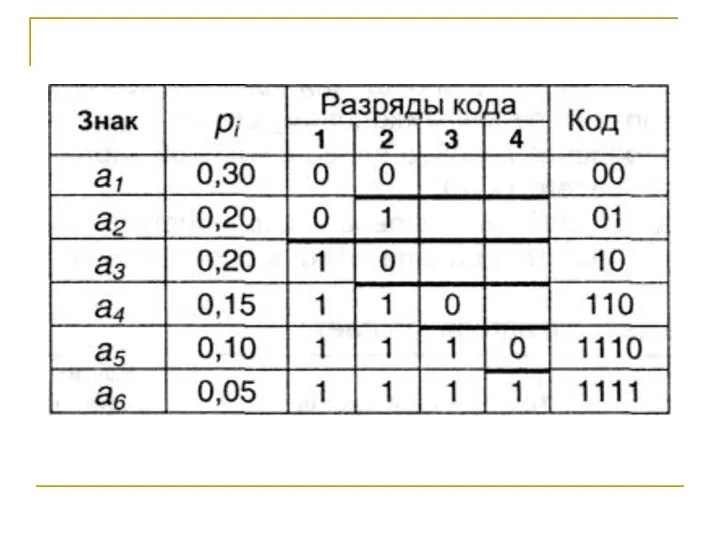
Слайд 79Средняя длина кода равна:
I1(A) = 2,390 бит.
избыточность кода Q(A,2) = 0,0249,
Средняя длина кода равна:
I1(A) = 2,390 бит.
избыточность кода Q(A,2) = 0,0249,

Слайд 80Данный код нельзя считать оптимальным, поскольку вероятности появления 0 и 1 неодинаковы
Данный код нельзя считать оптимальным, поскольку вероятности появления 0 и 1 неодинаковы

Слайд 81С) Префиксный код Хаффмана
С) Префиксный код Хаффмана

Слайд 82Способ оптимального префиксного двоичного кодирования был предложен Д. Хаффманом. Построение кодов Хаффмана
Способ оптимального префиксного двоичного кодирования был предложен Д. Хаффманом. Построение кодов Хаффмана

Слайд 83Аналогично продолжим создавать новые алфавиты, пока в последнем не останется два знака.
Аналогично продолжим создавать новые алфавиты, пока в последнем не останется два знака.

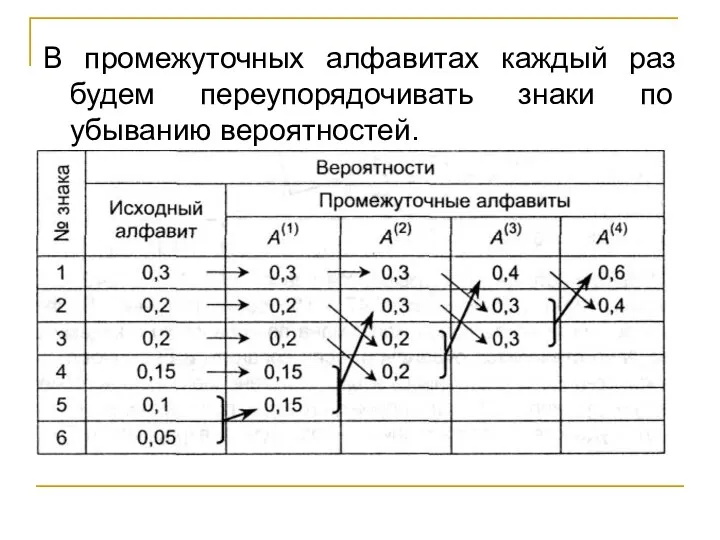
Слайд 84В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей.
В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей.
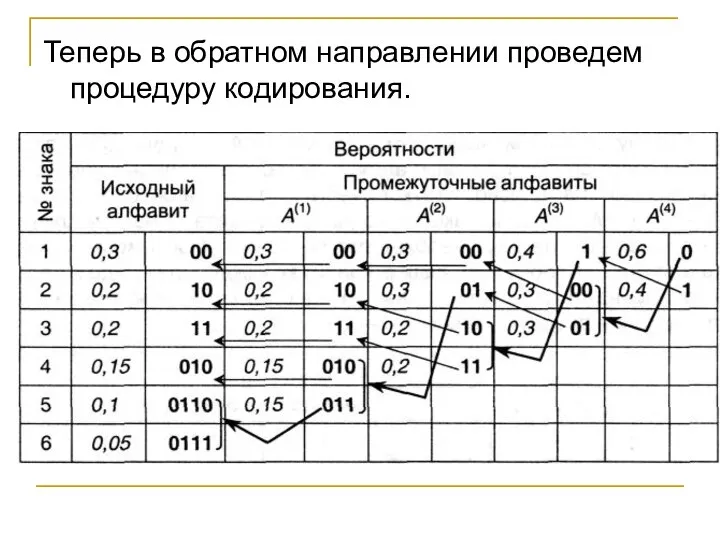
Слайд 85Теперь в обратном направлении проведем процедуру кодирования.
Теперь в обратном направлении проведем процедуру кодирования.
Слайд 86К(А,2) = 0,3 ∙ 2 + 0,2 ∙ 2 + 0,2 ∙
К(А,2) = 0,3 ∙ 2 + 0,2 ∙ 2 + 0,2 ∙

Слайд 87Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является
Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является

Слайд 88Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана)
Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана)

 Коммуникационное VS Информационное общество
Коммуникационное VS Информационное общество Цикловое управление манипулятором МП-9с c помощью TM-238
Цикловое управление манипулятором МП-9с c помощью TM-238 Программирование как процесс разработки ПО
Программирование как процесс разработки ПО Проект “Аналитик”
Проект “Аналитик” Методология объектно-ориентированного программирования
Методология объектно-ориентированного программирования Google Developer Groups
Google Developer Groups Основные понятия алгоритмизации
Основные понятия алгоритмизации Информационная деятельность человека
Информационная деятельность человека Месторождения драгоценных камней. Литература
Месторождения драгоценных камней. Литература Информ_лек2_информатика компьютинг (2)
Информ_лек2_информатика компьютинг (2) Как создать Wiki меню ВКонтакте
Как создать Wiki меню ВКонтакте Доверенная идентификация в избирательных информационных технологиях цифрового общества Сбербанк-МФТИ
Доверенная идентификация в избирательных информационных технологиях цифрового общества Сбербанк-МФТИ C de Dosya İşlemler
C de Dosya İşlemler Vp_Lektsia_1_Vvedenie
Vp_Lektsia_1_Vvedenie Основополагающие принципы устройства ЭВМ
Основополагающие принципы устройства ЭВМ Гиперссылки. Призентации
Гиперссылки. Призентации Front-end разработчик презентация
Front-end разработчик презентация Задание 2. Новогодняя елка
Задание 2. Новогодняя елка Разработка приложения Test Creator
Разработка приложения Test Creator Информационные технологии в музыкальном образовании
Информационные технологии в музыкальном образовании Средства и методы повышения надежности. Надежность программных продуктов. 4
Средства и методы повышения надежности. Надежность программных продуктов. 4 Информационный суверенитет - новая реальность
Информационный суверенитет - новая реальность Алгоритмы с результатом
Алгоритмы с результатом Периферийные устройства персонального компьютера. Программное обеспечение внешних устройств
Периферийные устройства персонального компьютера. Программное обеспечение внешних устройств Джедаисты. Цели
Джедаисты. Цели Безопасность ребёнка в интернете
Безопасность ребёнка в интернете Сайти інтернете
Сайти інтернете Интернет-маркетинг для чайников
Интернет-маркетинг для чайников