- Язык программирования СИ

Содержание
- 2. Язык программирования СИ Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в
- 3. Обзор Язык программирования Си отличается минимализмом. Авторы языка хотели, чтобы программы на нём легко компилировались с
- 4. Ранние разработки Язык программирования Си был разработан в лабораториях Bell Labs в период с 1969 по
- 5. K&R C В 1978 году Ритчи и Керниган опубликовали первую редакцию книги «Язык программирования Си». Эта
- 6. ISO C ANSI C В конце 1970-х годов Си начал вытеснять Бейсик с позиции ведущего языка
- 7. C99 После стандартизации в ANSI спецификация языка Си оставалась относительно неизменной в течение долгого времени, в
- 8. C11 8 декабря 2011 опубликован новый стандарт для языка Си (ISO/IEC 9899:2011). Основные изменения: поддержка многопоточности;
- 9. Связь с C++ Язык программирования С++ произошёл от Си. Однако в дальнейшем Си и C++ развивались
- 10. C++ C++ (произносится «си плас плас», допустимо также русскоязычное произношение «си плюс плюс») — компилируемый статически
- 11. Ключевые слова В С89 есть 32 ключевых слова:
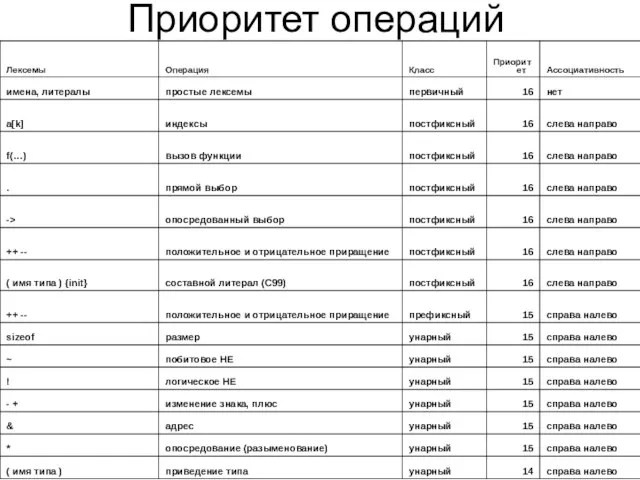
- 12. Приоритет операций
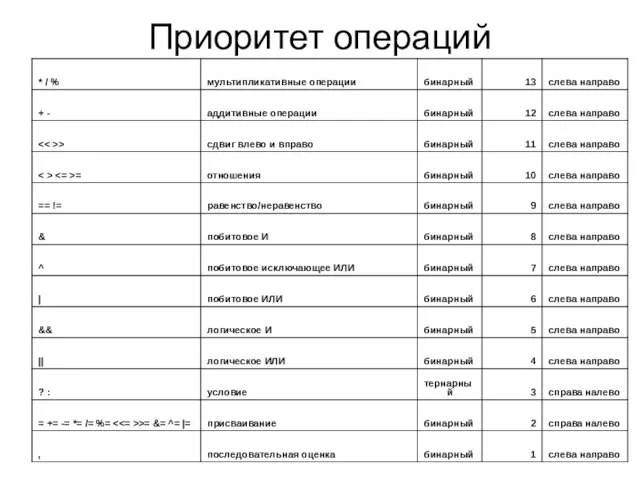
- 13. Приоритет операций
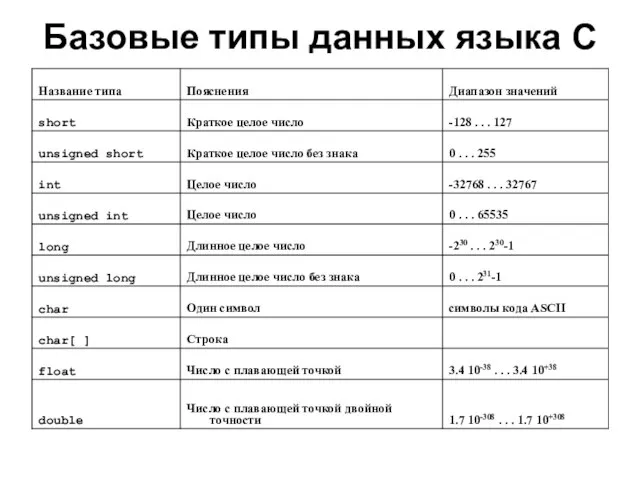
- 14. Базовые типы данных языка С
- 16. Hello в стиле СИ //*********prog1.cpp********* #include void main(void) { printf("Hello\n"); }
- 17. Hello в стиле С++ //*********prog2.cpp********* #include void main(void) { cout }
- 18. Hello в стиле С++ на современных компиляторах //*********prog2.cpp********* #include using namespace std; int main(void) { cout
- 19. Использование переменных Любая переменная, используемая в программе, должна быть описана перед первым её использованием. Описать переменную
- 20. Некоторые функции стандартного ввода-вывода Функции стандартного ввода - вывода описаны в файле stdio.h. printf() - форматный
- 21. %[flags][width][.prec]type
- 22. scanf() - форматный ввод с клавиатуры: int scanf(char *format, ); Первый параметр является символьной строкой, которая
- 23. //*********prog4.cpp********* #include void main(void) { float a,b,c; printf(“input a:”); scanf(“%f”,&a); printf(“input b:”); scanf(“%f”,&b); c=a/b; printf("c=%f\n",c); }
- 24. Вывод значений нескольких переменных //*********prog4.cpp********* #include void main(void) { float a=1.5; int b=7; char c=‘A’; char
- 25. Ввод вывод в С++ //*********prog5.cpp********* #include void main(void) { float a,b,c; cout cin>>a; cout cin>>b; c=a/b;
- 26. Целочисленное деление (оба операнда — целые числа) Деление не целочисленное (операнд 5. - вещественное число)
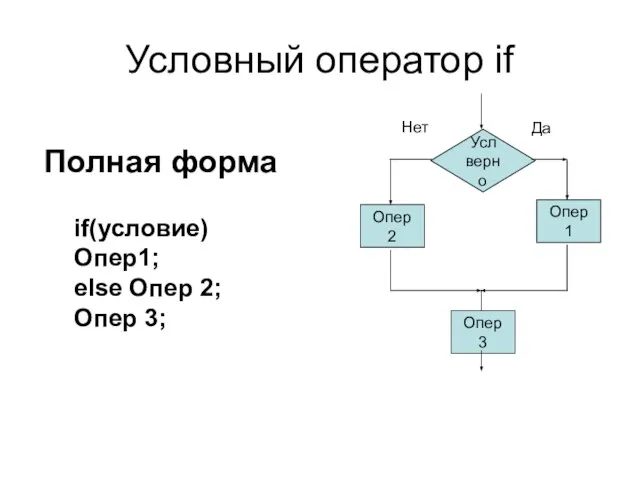
- 27. Условный оператор if Усл верно Опер 2 Опер 1 Опер 3 Да Нет if(условие) Опер1; else
- 28. Условный оператор if Усл верно Опер 1 Опер 2 Да Нет if(условие)Опер1; Опер 2; Краткая форма
- 29. Логические операции Язык С имеет ровно три логические операции: это && или (AND); || или (OR);
- 30. Таблицы истинности логических операций Операция "&&" называется логическим умножением потому, что выполняется таблица истинности этой операции,
- 31. Операция "||" (ИЛИ) называется логическим сложением потому, что выполняется таблица истинности этой операции, очень напоминающая таблицу
- 32. Пример с полной формой if /* Объявления переменных x и y и ввод исходных данных */
- 33. Пример с краткой формой if /* Объявления переменных “x” и “y” и ввод исходных данных */
- 34. Операции инкремента и декремента Операции инкрементации и декрементации являются унарными операциями, то есть операциями, имеющими один
- 35. Операндом может быть именующее выражение, например, имя переменной. Следующие три строки увеличивают переменную x на 1:
- 36. Префиксная (++x, --x ) и постфиксная (x++ , x--) форма Операции инкрементации и декрементации имеют префиксную
- 37. Сложное присваивание Сложное Аналог присваивание y+=5; y=y+5; y-=5; y=y-5; y*=5; y=y*5; y/=5; y=y/5;
- 40. Заполнение лидирующими нулями
- 41. Операторы циклов for while do …..while
- 42. Оператор for выр2 верно Опер 1 Опер 2 Да Нет for(выр1; выр2;выр3) Опер1; Опер 2; выр3
- 43. Пример int i; for( i=1;i cout На экране увидим: 12345 Переменную i обычно называют счетчиком цикла;
- 45. Оператор while усл верно Опер Да Нет while(условие) Опер; Цикл с предусловием
- 46. Пример int i; i=1; while( i { cout i++; } На экране увидим: 12345
- 47. Оператор do while усл верно Опер Да Нет do { Опер; } while(условие); Цикл с постусловием
- 48. Пример int i; i=1; do { cout i++; } while( i На экране увидим: 12345
- 49. Сравнение операторов циклов
- 50. Задача табулирования
- 51. Задача табулирования //********* for ( format output) **************** #include #include void main(viod) { float x,y,xn,xk,dx; int
- 52. Операторы break continue
- 53. Операторы break и continue Часто при возникновении некоторого события удобно иметь возможность досрочно завершить цикл. Используемый
- 54. #include int main(void) { int i; for(i=1;i { if(i==5) break; printf(“%d” ,i); } return 0; }
- 55. Оператор continue Оператор continue тоже предназначен для прерывания циклического процесса, организуемого операторами for, while, do-while. Но
- 56. #include int main(void) { int i; for(i=1;i { if(i==5) continue; printf(“%d” ,i); } return 0; }
- 57. Переключатель switch Оператор switch (переключатель) предназначен для принятия одного из многих решений. Он выглядит следующим образом:
- 58. При выполнении этого оператора вычисляется выражение, стоящее в скобках после ключевого слова switch, которое должно быть
- 60. Калькулятор (правильный) Пример - калькулятор #include main() { int a,b,c; char op; printf( “ Input a
- 61. Массивы Массив - это упорядоченная совокупность данных одного типа. Можно говорить о массивах целых чисел, массивов
- 62. В случае многомерных массивов показывают столько пар скобок , какова размерность массива, а число внутри скобок
- 63. Элементам массива могут быть присвоены начальные значения: int a[6]={5,0,4,-17,49,1}; приведенная запись обеспечивает присвоения a[0]=5; a[1]=0; a[2]=4
- 65. Расположение массивов в памяти double arr[]={0.1,1.1,2.1,3.1,4.1,5.1,6.1,7.1,8.1,9.1}; for(i=0;i { cout } arr[0]=0.1 addr=0x1ebd0fa8 arr[1]=1.1 addr=0x1ebd0fb0 arr[2]=2.1 addr=0x1ebd0fb8
- 66. Многомерные массивы Многомерные массивы - это массивы с более чем одним индексом. Чаще всего используются двумерные
- 67. В памяти многомерные массивы представляются как одномерный массив, каждый из элементов которого, в свою очередь, представляет
- 68. Программа инициализирует массив и выводит его элементы на экран. #include int main () { int a[3]
- 69. //Ввод массива int a[3] [2]; int i,j; for (i=0; i for(j=0;j { cout cin>> a[i][j]; }
- 70. //обработка массива ( сумма элем.) int s=0; for (i=0; i for(j=0;j s+=a[i][j];
- 71. //вывод на экран for (i=0; i { for(j=0;j cout cout }
- 73. Указатели Указатели — это переменные, которые хранят адрес объекта (переменной) в памяти. Для объявления указателя нужно
- 74. Теперь сделаем так, чтобы указатели на что-нибудь указывали: int some_number=5, some_other_number=10; pNumberOne = &some_number; pNumberTwo =
- 76. #include void main() { // объявляем переменные: int nNumber; int *pPointer; // инициализируем объявленные переменные: nNumber
- 77. Динамическая память Динамическая память позволяет выделять/освобождать память во время работы программы. Код ниже демонстрирует, как выделить
- 78. Освобождение памяти С памятью всегда существуют сложности и в данном случае довольно серьезные, но эти сложности
- 80. Операции с указателями Унарные операции: инкремент и декремент. При выполнении операций ++ и -- значение указателя
- 82. Операции с указателями В бинарных операциях сложения и вычитания могут участвовать указатель и величина типа int.
- 84. Операции с указателями В операции вычитания могут участвовать два указателя на один и тот же тип.
- 86. Операции с указателями Значения двух указателей на одинаковые типы можно сравнивать в операциях ==, !=, ,
- 87. Методы доступа к элементам массивов Для доступа к элементам массива существует два различных способа. Первый способ
- 88. Методы доступа к элементам массивов Второй способ доступа к элементам массива связан с использованием адресных выражений
- 89. Функции Мощность языка программирования С во многом определяется легкостью и гибкостью в определении и использовании функций
- 90. функции При вызове функции ей при помощи аргументов (формальных параметров) могут быть переданы некоторые значения (фактические
- 91. Функции С использованием функций в языке СИ связаны три понятия: определение функции (описание действий, выполняемых функцией)
- 92. Определение функции задает тип возвращаемого значения, имя функции, типы и число формальных параметров, а также объявления
- 93. В языке СИ нет требования, чтобы определение функции обязательно предшествовало ее вызову. Определения используемых функций могут
- 94. Функции В программах на языке СИ широко используются, так называемые, библиотечные функции, т.е. функции предварительно разработанные
- 95. В соответствии с синтаксисом языка СИ определение функции имеет следующую форму: [спецификатор-класса-памяти] [спецификатор-типа] имя-функции ([список-формальных-параметров]) {
- 96. Функции ( возвращаемое значение) Функция возвращает значение если ее выполнение заканчивается оператором return, содержащим некоторое выражение.
- 97. Список-формальных-параметров Список-формальных-параметров - это последовательность объявлений формальных параметров, разделенная запятыми. Формальные параметры - это переменные, используемые
- 98. Формальные параметры Порядок и типы формальных параметров должны быть одинаковыми в определении функции и ее объявлении.
- 99. Передача параметров по значению Параметры функции передаются по значению и могут рассматриваться как локальные переменные, для
- 100. Пример: /* Неправильное использование параметров */ void change (int x, int y) { int k=x; x=y;
- 101. Передача параметров по указателю Однако, если в качестве параметра передать указатель на некоторую переменную, то используя
- 102. /* Правильное использование параметров */ void change (int *x, int *y) { int k=*x; *x=*y; *y=k;
- 103. Передача параметров по ссылке /* Правильное использование параметров */ void change (int &x, int &y) {
- 104. Ввод массива #include void vvod(float mas[],int n) { int i; for(i=0; i { printf("mas[%d]=", i); scanf("%f",
- 105. Вывод массива void vivod(float mas[], int n) { int i; for(i=0; i printf("mas[%d]=%7.3f\n",i,mas[i]); }
- 106. Обработка массива ( функция возвращает сумму отрицательных элементов) float otr(float mas[],int n) { int i; float
- 107. Вызов функций int main() { float s; int n; char c; float a[10]; printf("vvesti razmer\n"); scanf("%d",&n);
- 108. Лаб. Раб. 7 вар 9
- 109. Функция main int main() { int n; char c; float a[100], b[100], c[100], as[100], bs[100], cs[100],
- 110. Функция, возвращающая сумму элементов массива float sum(float mas[],int n) { int i; float s=0; for(i=0; i
- 111. Функция strih void strih(float m[],float ms[],int n) { int i; float s; s=sum(m,n); for(i=0; i ms[i]=m[i]/s;
- 112. Функция calc void calc(float m1[],float m2[],float mrez[],int n) { int i; for(i=0; i mrez[i]=m1[i]+m2[i]; }
- 113. Прототипы функций void vvod(float mas[],int n); void vivod(float mas[], int n); float sum(float mas[],int n); void
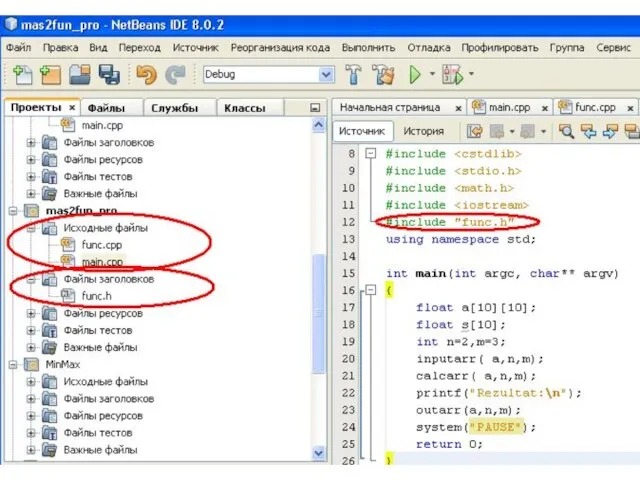
- 118. Проекты
- 123. Препроцессор Компилятор Компоновщик func.cpp func.o main.cpp main.o mas2fun_pro.exe библиотеки
- 124. Область действия ( видимость ) переменных #include void main(void) { int a=10; { int a=5; cout
- 125. Автоматические и статические преременные #include int calc() { int a=0; a++; return(a); } void main(void) {
- 126. #include int calc() { static int a=0; a++; return(a); } void main(void) { int x; x=calc();
- 127. Динамические массивы #include void inputarr(int *inarr, int n, char arrname[]) { int i; cout for (i=0;
- 128. void outputarr(int *outarr, int n, char arrname[]) { int i; for (i=0; i cout }
- 129. void createoutarr(int arr1[], int arr2[], int outarr[], int n) { int i; for (i=0; i }
- 130. void main() { int *x,*y,*z,*xy,*xz,*yz; int Size; cout cin>>Size; x =new int[Size]; y =new int[Size]; z
- 131. inputarr(x, Size, "x"); inputarr(y, Size, "y"); inputarr(z, Size, "z"); createoutarr(x, y, xy, Size); createoutarr(x, z, xz,
- 132. Освобождение динамической памяти delete [] x; delete [] y; delete [] z; delete [] xy; delete
- 133. Передача имен функций в качестве параметров Функцию можно вызвать через указатель на нее. Для этого объявляется
- 134. #include #include #include int f(int a ){ return a; } int (*pf)(int); int main(void) { pf
- 135. #include #include #include int f(int a ){ return a; } int (*pf)(int); void fun(int (*pf)(int) ,
- 136. Перегрузка функций Перегрузка функций — это механизм, который позволяет двум родственным функциям иметь одинаковые имена. В
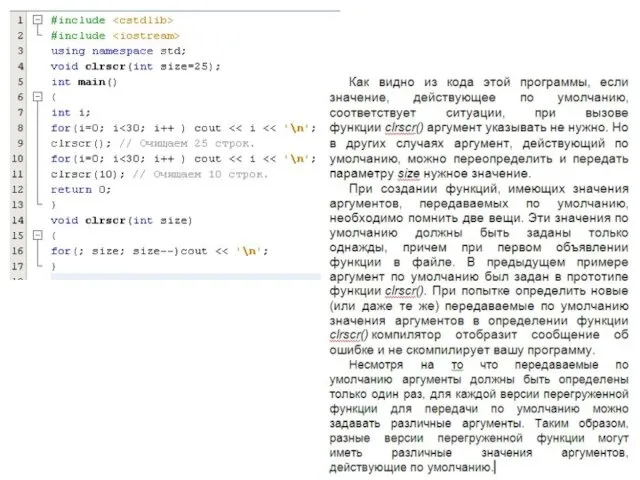
- 138. Аргументы, передаваемые функции по умолчанию В C++ мы можем придать параметру некоторое значение, которое будет автоматически
- 139. Включение в C++ возможности передачи аргументов по умолчанию позволяет программистам упрощать код программ. Чтобы предусмотреть максимально
- 141. Важно понимать, что все параметры, которые принимают значения по умолчанию, должны быть расположены справа от остальных.
- 142. Об использовании аргументов, передаваемых по умолчанию Несмотря на то что аргументы, передаваемые функции по умолчанию, —
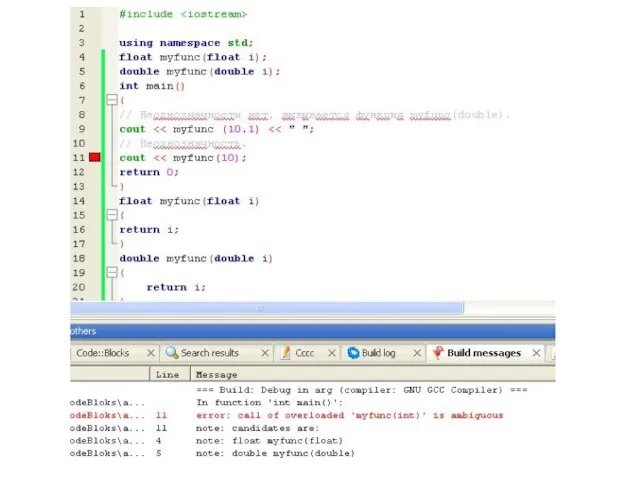
- 144. Перегрузка функций и неоднозначность Неоднозначность возникает тогда, когда компилятор не может определить различие между двумя перегруженными
- 145. // Неоднозначность вследствие перегрузки функций. #include using namespace std; float myfunc(float i); double myfunc(double i); int
- 146. Здесь благодаря перегрузке функция myfunc() может принимать аргументы либо типа float, либо типа double. При выполнении
- 149. Возврат ссылок Функция может возвращать ссылку. В программировании на C++ предусмотрено несколько применений для ссылочных значений,
- 151. Рассмотрим эту программу подробнее. Судя по прототипу функции f(), она должна возвращать ссылку на double-значение. За
- 152. программа изменяет значения второго и четвертого элементов массива
- 153. Функция change_it() объявлена как возвращающая ссылку на значение типа double. Говоря более конкретно, она возвращает ссылку
- 154. Создание ограниченного массива Ссылочный тип в качестве типа значения, возвращаемого функцией, можно с успехом применить для
- 156. Независимые ссылки Понятие ссылки включено в C++ главным образом для поддержки способа передачи параметров "по ссылке"
- 158. Функция Си/ C++ - qsort //void qsort(void *base, size_t nelem, //size_t width, int (*fcmp)(const void *,
- 159. #include #include #include int sort_function( const void *a, const void *b); char list[5][4] = { "cat",
- 161. Двумерные динамические массивы Санкт-Петербургский государственный университет телекоммуникаций им. проф. М.А. Бонч-Бруевича
- 162. Вспомним одномерные динамич. массивы
- 163. Работаем с дин. масс. как с обычным массивом
- 164. Освобождаем память
- 165. Двумерный динамический массив
- 166. Недостаток!
- 167. Вывод! Нужно сделать массив указателей динамическим!
- 172. Массив указателей на функции Массив указателей на функции определяется точно также, как и обычный массив –
- 176. Часто указатели на функцию становятся громоздкими. Работу с ними можно упростить, если ввести новый тип. Предыдущий
- 179. Препроцессор C++ Препроцессор C++ подвергает программу различным текстовым преобразованиям до реальной трансляции исходного кода в объектный.
- 180. Директива #define Директива #define используется для определения идентификатора и символьной последовательности, которая будет подставлена вместо идентификатора
- 181. После определения имени макроса его можно использовать как часть определения других макроимен. Например, следующий код определяет
- 182. Если текстовая последовательность не помещается на строке, ее можно продолжить на следующей, поставив обратную косую черту
- 183. Макроопределения, действующие как функции Директива #define имеет еще одно назначение: макроимя может использоваться с аргументами. При
- 184. Макроопределения, действующие как функции, — это макроопределения, которые принимают аргументы. Кажущиеся избыточными круглые скобки, в которые
- 185. // Эта программа работает корректно. #include using namespace std; #define EVEN(a) (a)%2==0 ? 1 : 0
- 186. Директива #еrror Директива #error отображает сообщение об ошибке. Директива #error дает указание компилятору остановить компиляцию. Она
- 187. Директива #include Директива #include включает заголовочный или другой исходный файл. Директива препроцессора #include обязывает компилятор включить
- 188. Директивы условной компиляции Существуют директивы, которые позволяют избирательно компилировать части исходного кода. Этот процесс, именуемый условной
- 189. // Простой пример использования директивы #if. #include using namespace std; #define MAX 100 int main() {
- 190. Поведение директивы #else во многом подобно поведению инструкции else, которая является частью языка C++: она определяет
- 191. Директива #elif эквивалентна связке инструкций else-if и используется для формирования многозвенной схемы if-else-if,представляющей несколько вариантов компиляции.
- 192. Например, в этом фрагменте кода используется идентификатор COMPILED_BY, который позволяет определить, кем компилируется программа. #define JOHN
- 193. Директивы #if и #elif могут быть вложенными. В этом случае директива #endif, #else или #elif связывается
- 194. Директивы #ifdef и #ifndef Директивы #ifdef и #ifndef предлагают еще два варианта условной компиляции, которые можно
- 195. Директива #undef Директива #undef используется для удаления предыдущего определения некоторого макроимени. Ее общий формат таков. #undef
- 196. Использование оператора defined Помимо директивы #ifdef существует еще один способ выяснить, определено ли в программе некоторое
- 197. Директива #line Директива #line изменяет содержимое псевдопеременных _ _LINE_ _ и _ _FILE_ _. Директива #line
- 198. Директива #pragma Работа директивы #pragma зависит от конкретной реализации компилятора. Она позволяет выдавать компилятору различные инструкции,
- 199. Операторы препроцессора "#" и "##" В C++ предусмотрена поддержка двух операторов препроцессора: "#" и"##". Эти операторы
- 200. ## Оператор используется для конкатенации двух лексем. Рассмотрим пример. #include using namespace std; #define concat(a, b)
- 202. Скачать презентацию
Слайд 2Язык программирования СИ
Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом
Язык программирования СИ
Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом

Слайд 3Обзор
Язык программирования Си отличается минимализмом. Авторы языка хотели, чтобы программы на
Обзор
Язык программирования Си отличается минимализмом. Авторы языка хотели, чтобы программы на

Слайд 4Ранние разработки
Язык программирования Си был разработан в лабораториях Bell Labs в период
Ранние разработки
Язык программирования Си был разработан в лабораториях Bell Labs в период

Слайд 5K&R C
В 1978 году Ритчи и Керниган опубликовали первую редакцию книги «Язык
K&R C
В 1978 году Ритчи и Керниган опубликовали первую редакцию книги «Язык

Слайд 6ISO C ANSI C
В конце 1970-х годов Си начал вытеснять Бейсик с
ISO C ANSI C
В конце 1970-х годов Си начал вытеснять Бейсик с

Слайд 7C99
После стандартизации в ANSI спецификация языка Си оставалась относительно неизменной в течение
C99
После стандартизации в ANSI спецификация языка Си оставалась относительно неизменной в течение

Слайд 8C11
8 декабря 2011 опубликован новый стандарт для языка Си (ISO/IEC 9899:2011). Основные
C11
8 декабря 2011 опубликован новый стандарт для языка Си (ISO/IEC 9899:2011). Основные

Слайд 9Связь с C++
Язык программирования С++ произошёл от Си. Однако в дальнейшем Си
Связь с C++
Язык программирования С++ произошёл от Си. Однако в дальнейшем Си

Слайд 10C++
C++ (произносится «си плас плас», допустимо также русскоязычное произношение «си плюс плюс»)
C++
C++ (произносится «си плас плас», допустимо также русскоязычное произношение «си плюс плюс»)

Слайд 11Ключевые слова
В С89 есть 32 ключевых слова:
Ключевые слова
В С89 есть 32 ключевых слова:

Слайд 12Приоритет операций
Приоритет операций
Слайд 13Приоритет операций
Приоритет операций
Слайд 14Базовые типы данных языка С
Базовые типы данных языка С

Слайд 16Hello в стиле СИ
//*********prog1.cpp*********
#include
void main(void)
{
printf("Hello\n");
}
Hello в стиле СИ
//*********prog1.cpp*********
#include
void main(void)
{
printf("Hello\n");
}

Слайд 17Hello в стиле С++
//*********prog2.cpp*********
#include
void main(void)
{
cout<<"Hello"<}
Hello в стиле С++
//*********prog2.cpp*********
#include
void main(void)
{
cout<<"Hello"<

Слайд 18Hello в стиле С++ на современных компиляторах
//*********prog2.cpp*********
#include
using namespace std;
int main(void)
{
cout<<"Hello"<return 0;
}
Hello в стиле С++ на современных компиляторах
//*********prog2.cpp*********
#include
using namespace std;
int main(void)
{
cout<<"Hello"<
}

Слайд 19Использование переменных
Любая переменная, используемая в программе, должна быть описана перед первым её
Использование переменных
Любая переменная, используемая в программе, должна быть описана перед первым её

Слайд 20Некоторые функции стандартного ввода-вывода
Функции стандартного ввода - вывода описаны в файле stdio.h.
printf()
Некоторые функции стандартного ввода-вывода
Функции стандартного ввода - вывода описаны в файле stdio.h.
printf()

Слайд 21%[flags][width][.prec]type
%[flags][width][.prec]type
![%[flags][width][.prec]type](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-20.jpg)
Слайд 22scanf() - форматный ввод с клавиатуры:
int scanf(char *format, <список ввода>); Первый
scanf() - форматный ввод с клавиатуры:
int scanf(char *format, <список ввода>); Первый

Слайд 23//*********prog4.cpp*********
#include
void main(void)
{
float a,b,c;
printf(“input a:”);
scanf(“%f”,&a);
printf(“input b:”);
scanf(“%f”,&b);
c=a/b;
printf("c=%f\n",c);
}
//*********prog4.cpp*********
#include
void main(void)
{
float a,b,c;
printf(“input a:”);
scanf(“%f”,&a);
printf(“input b:”);
scanf(“%f”,&b);
c=a/b;
printf("c=%f\n",c);
}

Слайд 24Вывод значений нескольких переменных
//*********prog4.cpp*********
#include
void main(void)
{
float a=1.5;
int b=7;
char c=‘A’;
char str[]=“Stroka”;
printf(“a=%f b=%d c=%c str=%s\n",a,b,c,str);
}
Вывод значений нескольких переменных
//*********prog4.cpp*********
#include
void main(void)
{
float a=1.5;
int b=7;
char c=‘A’;
char str[]=“Stroka”;
printf(“a=%f b=%d c=%c str=%s\n",a,b,c,str);
}

Слайд 25Ввод вывод в С++
//*********prog5.cpp*********
#include
void main(void)
{
float a,b,c;
cout<<“input a”;
cin>>a;
cout<<“input b”;
cin>>b;
c=a/b;
cout<<”c=”<}
Ввод вывод в С++
//*********prog5.cpp*********
#include
void main(void)
{
float a,b,c;
cout<<“input a”;
cin>>a;
cout<<“input b”;
cin>>b;
c=a/b;
cout<<”c=”<

Слайд 26Целочисленное деление (оба операнда — целые числа)
Деление не целочисленное (операнд 5. -
Целочисленное деление (оба операнда — целые числа)
Деление не целочисленное (операнд 5. -

Слайд 27Условный оператор if
Усл верно
Опер 2
Опер 1
Опер 3
Да
Нет
if(условие) Опер1;
else Опер 2;
Опер 3;
Полная форма
Условный оператор if
Усл верно
Опер 2
Опер 1
Опер 3
Да
Нет
if(условие) Опер1;
else Опер 2;
Опер 3;
Полная форма
Слайд 28Условный оператор if
Усл верно
Опер 1
Опер 2
Да
Нет
if(условие)Опер1;
Опер 2;
Краткая форма
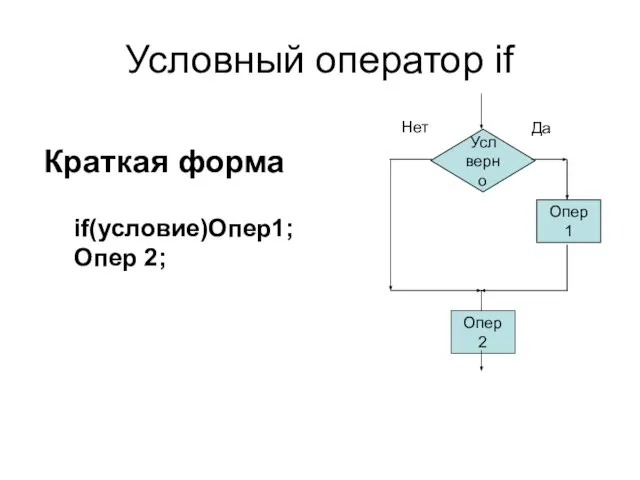
Условный оператор if
Усл верно
Опер 1
Опер 2
Да
Нет
if(условие)Опер1;
Опер 2;
Краткая форма
Слайд 29Логические операции
Язык С имеет ровно три логические операции: это
&& или (AND);
||
Логические операции
Язык С имеет ровно три логические операции: это
&& или (AND);
||

Слайд 30Таблицы истинности логических операций
Операция "&&" называется логическим умножением потому, что выполняется таблица
Таблицы истинности логических операций
Операция "&&" называется логическим умножением потому, что выполняется таблица

Слайд 31Операция "||" (ИЛИ) называется логическим сложением потому, что выполняется таблица истинности этой
Операция "||" (ИЛИ) называется логическим сложением потому, что выполняется таблица истинности этой

Слайд 32Пример с полной формой if
/* Объявления переменных x и y и ввод
Пример с полной формой if
/* Объявления переменных x и y и ввод

Слайд 33Пример с краткой формой if
/* Объявления переменных “x” и “y” и ввод
Пример с краткой формой if
/* Объявления переменных “x” и “y” и ввод

Слайд 34Операции инкремента и декремента
Операции инкрементации и декрементации являются унарными операциями, то есть
Операции инкремента и декремента
Операции инкрементации и декрементации являются унарными операциями, то есть

Слайд 35Операндом может быть именующее выражение, например, имя переменной.
Следующие три строки увеличивают переменную
Операндом может быть именующее выражение, например, имя переменной.
Следующие три строки увеличивают переменную

Слайд 36Префиксная (++x, --x ) и постфиксная (x++ , x--) форма
Операции инкрементации и
Префиксная (++x, --x ) и постфиксная (x++ , x--) форма
Операции инкрементации и

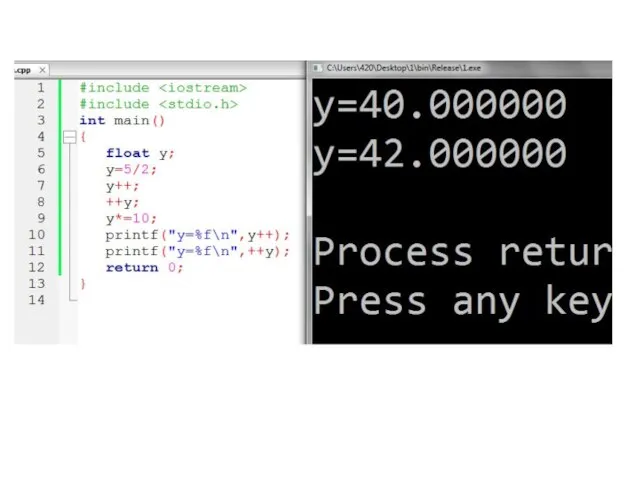
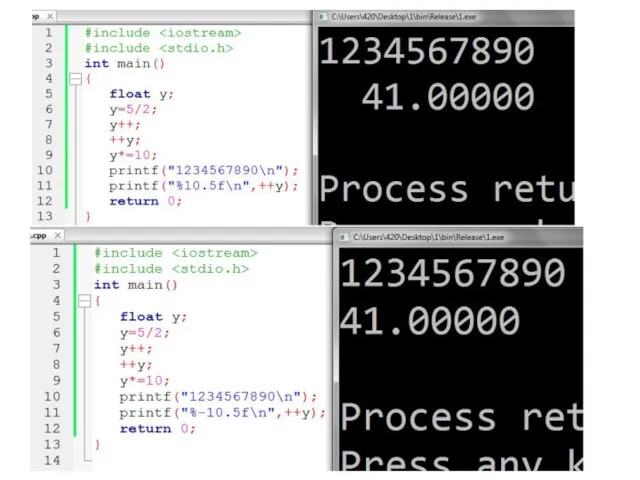
Слайд 37Сложное присваивание
Сложное Аналог
присваивание
y+=5; y=y+5;
y-=5; y=y-5;
y*=5; y=y*5;
y/=5; y=y/5;
Сложное присваивание
Сложное Аналог
присваивание
y+=5; y=y+5;
y-=5; y=y-5;
y*=5; y=y*5;
y/=5; y=y/5;

Слайд 40Заполнение лидирующими нулями
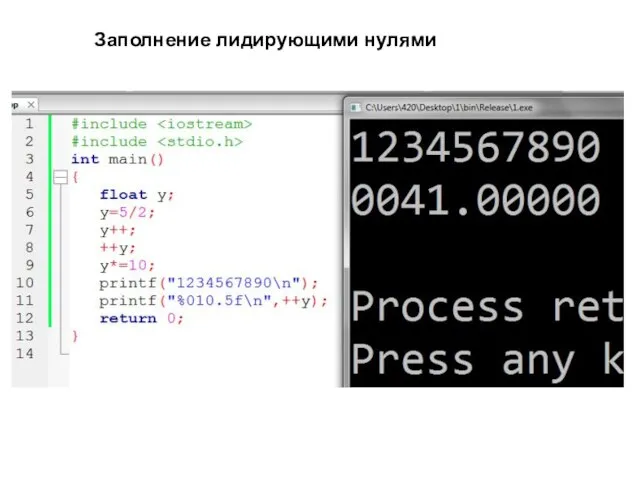
Заполнение лидирующими нулями
Слайд 41Операторы циклов
for
while
do …..while
Операторы циклов
for
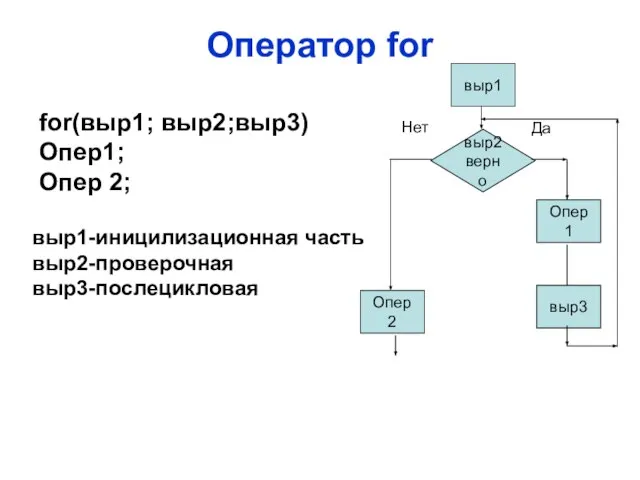
while
do …..while

Слайд 42Оператор for
выр2 верно
Опер 1
Опер 2
Да
Нет
for(выр1; выр2;выр3)
Опер1;
Опер 2;
выр3
выр1
выр1-иницилизационная часть
выр2-проверочная
выр3-послецикловая
Оператор for
выр2 верно
Опер 1
Опер 2
Да
Нет
for(выр1; выр2;выр3)
Опер1;
Опер 2;
выр3
выр1
выр1-иницилизационная часть
выр2-проверочная
выр3-послецикловая
Слайд 43Пример
int i;
for( i=1;i<=5; i++)
cout< На экране увидим: 12345
Переменную i обычно
Пример
int i;
for( i=1;i<=5; i++)
cout<
Переменную i обычно


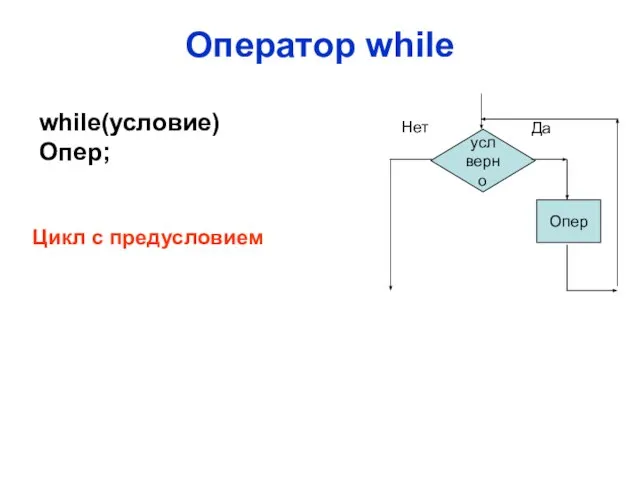
Слайд 45Оператор while
усл верно
Опер
Да
Нет
while(условие)
Опер;
Цикл с предусловием
Оператор while
усл верно
Опер
Да
Нет
while(условие)
Опер;
Цикл с предусловием
Слайд 46Пример
int i;
i=1;
while( i<=5)
{
cout< i++;
}
На экране увидим: 12345
Пример
int i;
i=1;
while( i<=5)
{
cout<
}
На экране увидим: 12345

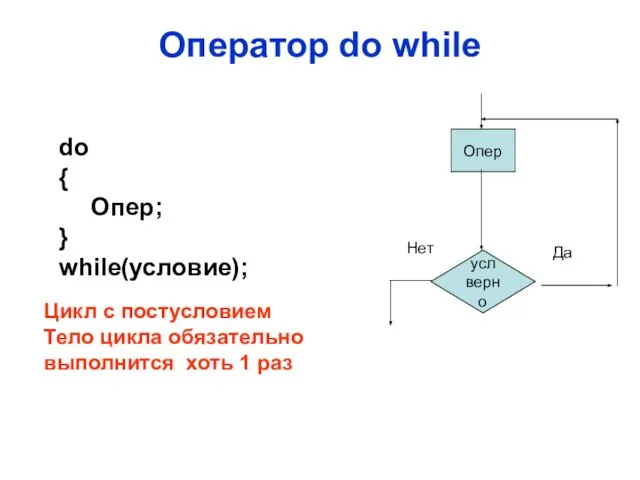
Слайд 47Оператор do while
усл верно
Опер
Да
Нет
do
{
Опер;
}
while(условие);
Цикл с постусловием
Тело цикла обязательно
выполнится хоть 1 раз
Оператор do while
усл верно
Опер
Да
Нет
do
{
Опер;
}
while(условие);
Цикл с постусловием
Тело цикла обязательно
выполнится хоть 1 раз
Слайд 48Пример
int i;
i=1;
do
{
cout< i++;
} while( i<=5);
На экране увидим: 12345
Пример
int i;
i=1;
do
{
cout<
} while( i<=5);
На экране увидим: 12345

Слайд 49Сравнение операторов циклов
Сравнение операторов циклов

Слайд 50Задача табулирования
Задача табулирования
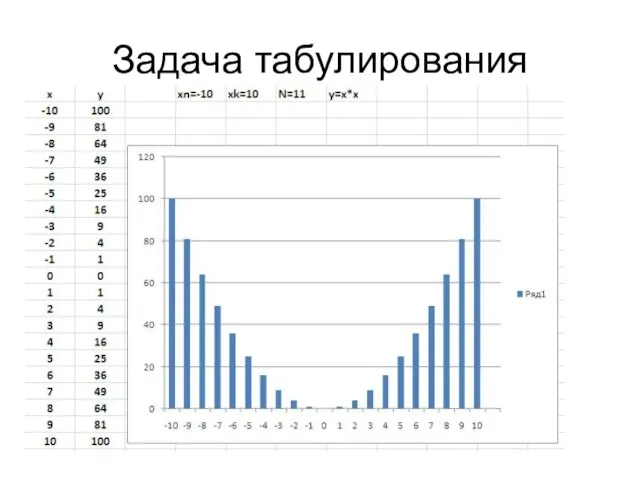
Слайд 51Задача табулирования
//********* for ( format output) ****************
#include
#include
void main(viod)
{
float x,y,xn,xk,dx; int n;
Задача табулирования
//********* for ( format output) ****************
#include
#include
void main(viod)
{
float x,y,xn,xk,dx; int n;

Слайд 52Операторы
break
continue
Операторы
break
continue

Слайд 53Операторы break и continue
Часто при возникновении некоторого события удобно иметь возможность досрочно
Операторы break и continue
Часто при возникновении некоторого события удобно иметь возможность досрочно

Слайд 54#include
int main(void)
{
int i;
for(i=1;i<10;i++)
{
if(i==5)
break;
printf(“%d” ,i);
}
return 0;
}
На
#include
int main(void)
{
int i;
for(i=1;i<10;i++)
{
if(i==5)
break;
printf(“%d” ,i);
}
return 0;
}
На

Слайд 55Оператор continue
Оператор continue тоже предназначен для прерывания циклического процесса, организуемого операторами
Оператор continue
Оператор continue тоже предназначен для прерывания циклического процесса, организуемого операторами

Слайд 56#include
int main(void)
{
int i;
for(i=1;i<10;i++)
{
if(i==5)
continue;
printf(“%d” ,i);
}
return 0;
}
На
#include
int main(void)
{
int i;
for(i=1;i<10;i++)
{
if(i==5)
continue;
printf(“%d” ,i);
}
return 0;
}
На

Слайд 57Переключатель switch
Оператор switch (переключатель) предназначен для принятия одного из многих решений. Он
Переключатель switch
Оператор switch (переключатель) предназначен для принятия одного из многих решений. Он

Слайд 58 При выполнении этого оператора вычисляется выражение, стоящее в скобках после ключевого слова
При выполнении этого оператора вычисляется выражение, стоящее в скобках после ключевого слова


Слайд 60Калькулятор (правильный)
Пример - калькулятор
#include
main()
{
int a,b,c; char op;
printf(
Калькулятор (правильный)
Пример - калькулятор
#include
main()
{
int a,b,c; char op;
printf(

Слайд 61Массивы
Массив - это упорядоченная совокупность данных одного типа. Можно говорить о массивах
Массивы
Массив - это упорядоченная совокупность данных одного типа. Можно говорить о массивах

Слайд 62 В случае многомерных массивов показывают столько пар скобок , какова размерность массива,
В случае многомерных массивов показывают столько пар скобок , какова размерность массива,

Слайд 63 Элементам массива могут быть присвоены начальные значения:
int a[6]={5,0,4,-17,49,1};
приведенная запись
Элементам массива могут быть присвоены начальные значения:
int a[6]={5,0,4,-17,49,1};
приведенная запись
![Элементам массива могут быть присвоены начальные значения: int a[6]={5,0,4,-17,49,1}; приведенная запись обеспечивает](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-62.jpg)

Слайд 66Многомерные массивы
Многомерные массивы - это массивы с более чем одним индексом.
Чаще всего
Многомерные массивы
Многомерные массивы - это массивы с более чем одним индексом.
Чаще всего

Слайд 67В памяти многомерные массивы представляются как одномерный массив, каждый из элементов которого,
В памяти многомерные массивы представляются как одномерный массив, каждый из элементов которого,

Слайд 68Программа инициализирует массив и выводит его элементы на экран.
#include
int main
Программа инициализирует массив и выводит его элементы на экран.
#include
int main

Слайд 69//Ввод массива
int a[3] [2];
int i,j;
for (i=0; i<3; i++)
for(j=0;j<2;j++)
{
cout <<"a["<< i
//Ввод массива
int a[3] [2];
int i,j;
for (i=0; i<3; i++)
for(j=0;j<2;j++)
{
cout <<"a["<< i
![//Ввод массива int a[3] [2]; int i,j; for (i=0; i for(j=0;j { cout cin>> a[i][j]; }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-68.jpg)
Слайд 70//обработка массива ( сумма элем.)
int s=0;
for (i=0; i<3; i++)
for(j=0;j<2;j++)
s+=a[i][j];
//обработка массива ( сумма элем.)
int s=0;
for (i=0; i<3; i++)
for(j=0;j<2;j++)
s+=a[i][j];
![//обработка массива ( сумма элем.) int s=0; for (i=0; i for(j=0;j s+=a[i][j];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-69.jpg)
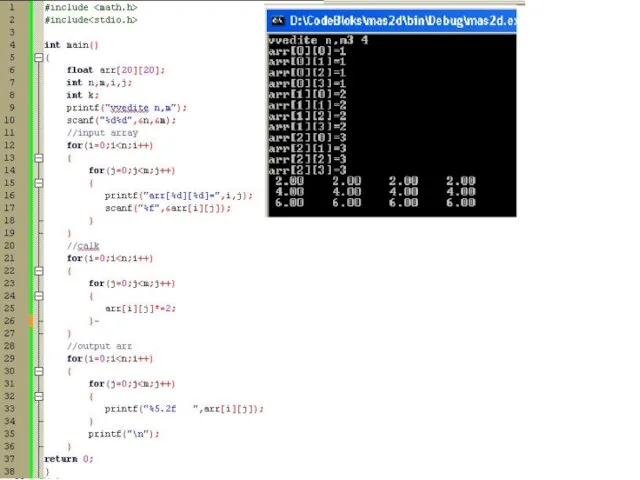
Слайд 71//вывод на экран
for (i=0; i<3; i++)
{
for(j=0;j<2;j++)
cout < cout< }
//вывод на экран
for (i=0; i<3; i++)
{
for(j=0;j<2;j++)
cout <

Слайд 73Указатели
Указатели — это переменные, которые хранят адрес объекта (переменной) в памяти.
Для
Указатели
Указатели — это переменные, которые хранят адрес объекта (переменной) в памяти.
Для

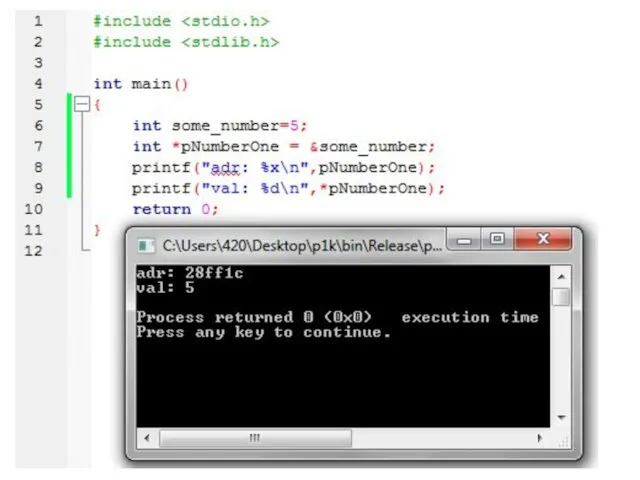
Слайд 74Теперь сделаем так, чтобы указатели на что-нибудь указывали:
int some_number=5, some_other_number=10;
pNumberOne = &some_number;
pNumberTwo
Теперь сделаем так, чтобы указатели на что-нибудь указывали:
int some_number=5, some_other_number=10;
pNumberOne = &some_number;
pNumberTwo

Слайд 76#include
void main()
{
// объявляем переменные:
int nNumber;
int *pPointer;
// инициализируем объявленные переменные:
nNumber = 15;
pPointer
#include
void main()
{
// объявляем переменные:
int nNumber;
int *pPointer;
// инициализируем объявленные переменные:
nNumber = 15;
pPointer

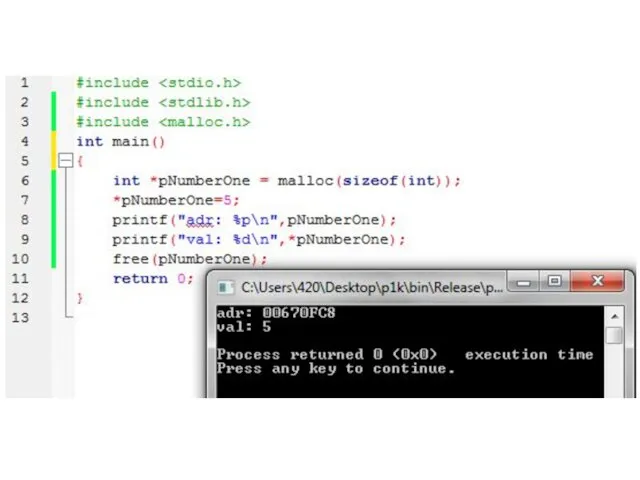
Слайд 77Динамическая память
Динамическая память позволяет выделять/освобождать память во время работы программы. Код ниже
Динамическая память
Динамическая память позволяет выделять/освобождать память во время работы программы. Код ниже

Слайд 78Освобождение памяти
С памятью всегда существуют сложности и в данном случае довольно серьезные,
Освобождение памяти
С памятью всегда существуют сложности и в данном случае довольно серьезные,

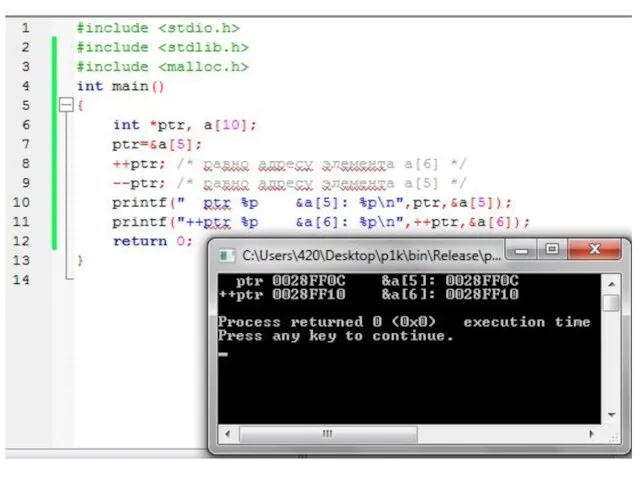
Слайд 80Операции с указателями
Унарные операции: инкремент и декремент. При выполнении операций ++ и
Операции с указателями
Унарные операции: инкремент и декремент. При выполнении операций ++ и

Слайд 82Операции с указателями
В бинарных операциях сложения и вычитания могут участвовать указатель и
Операции с указателями
В бинарных операциях сложения и вычитания могут участвовать указатель и

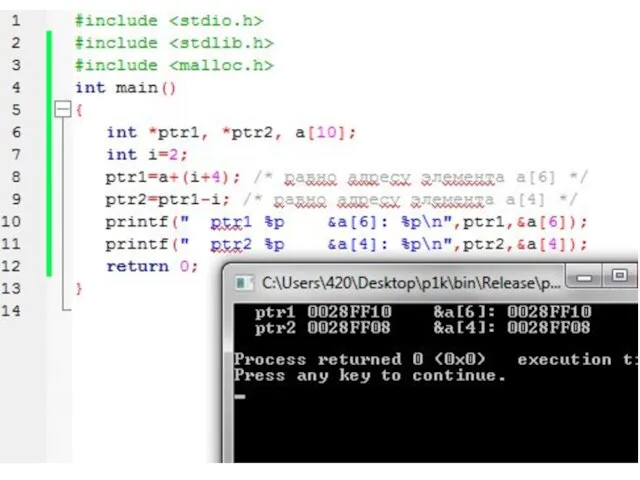
Слайд 84Операции с указателями
В операции вычитания могут участвовать два указателя на один и
Операции с указателями
В операции вычитания могут участвовать два указателя на один и

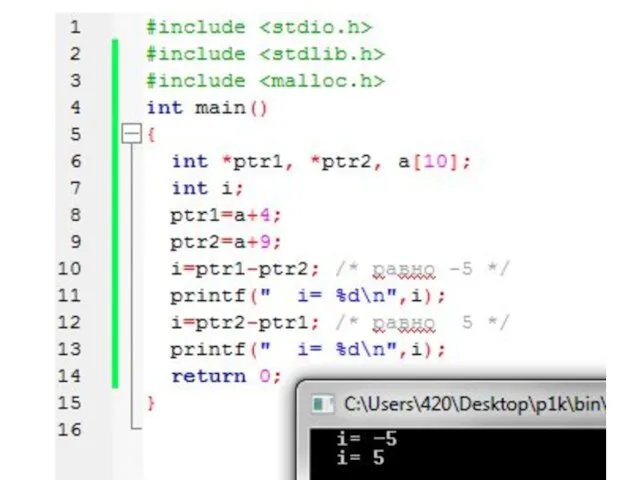
Слайд 86Операции с указателями
Значения двух указателей на одинаковые типы можно сравнивать в операциях
Операции с указателями
Значения двух указателей на одинаковые типы можно сравнивать в операциях

Слайд 87Методы доступа к элементам массивов
Для доступа к элементам массива существует два различных
Методы доступа к элементам массивов
Для доступа к элементам массива существует два различных

Слайд 88Методы доступа к элементам массивов
Второй способ доступа к элементам массива связан с
Методы доступа к элементам массивов
Второй способ доступа к элементам массива связан с

Слайд 89Функции
Мощность языка программирования С во многом определяется легкостью и гибкостью в определении
Функции
Мощность языка программирования С во многом определяется легкостью и гибкостью в определении

Слайд 90функции
При вызове функции ей при помощи аргументов (формальных параметров) могут быть переданы
функции
При вызове функции ей при помощи аргументов (формальных параметров) могут быть переданы

Слайд 91Функции
С использованием функций в языке СИ связаны три понятия:
определение функции (описание действий,
Функции
С использованием функций в языке СИ связаны три понятия:
определение функции (описание действий,

Слайд 92Определение функции задает тип возвращаемого значения, имя функции, типы и число формальных
Определение функции задает тип возвращаемого значения, имя функции, типы и число формальных

Слайд 93В языке СИ нет требования, чтобы определение функции обязательно предшествовало ее вызову.
В языке СИ нет требования, чтобы определение функции обязательно предшествовало ее вызову.

Слайд 94Функции
В программах на языке СИ широко используются, так называемые, библиотечные функции, т.е.
Функции
В программах на языке СИ широко используются, так называемые, библиотечные функции, т.е.

Слайд 95В соответствии с синтаксисом языка СИ определение функции имеет следующую форму:
В соответствии с синтаксисом языка СИ определение функции имеет следующую форму:
![В соответствии с синтаксисом языка СИ определение функции имеет следующую форму: [спецификатор-класса-памяти]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-94.jpg)
Слайд 96Функции ( возвращаемое значение)
Функция возвращает значение если ее выполнение заканчивается оператором return,
Функции ( возвращаемое значение)
Функция возвращает значение если ее выполнение заканчивается оператором return,

Слайд 97Список-формальных-параметров
Список-формальных-параметров - это последовательность объявлений формальных параметров, разделенная запятыми. Формальные параметры -
Список-формальных-параметров
Список-формальных-параметров - это последовательность объявлений формальных параметров, разделенная запятыми. Формальные параметры -

Слайд 98Формальные параметры
Порядок и типы формальных параметров должны быть одинаковыми в определении функции
Формальные параметры
Порядок и типы формальных параметров должны быть одинаковыми в определении функции

Слайд 99Передача параметров по значению
Параметры функции передаются по значению и могут рассматриваться как
Передача параметров по значению
Параметры функции передаются по значению и могут рассматриваться как

Слайд 100Пример:
/* Неправильное использование параметров */
void change (int x, int
Пример:
/* Неправильное использование параметров */
void change (int x, int

Слайд 101Передача параметров по указателю
Однако, если в качестве параметра передать указатель на некоторую
Передача параметров по указателю
Однако, если в качестве параметра передать указатель на некоторую

Слайд 102 /* Правильное использование параметров */
void change (int *x, int *y)
/* Правильное использование параметров */
void change (int *x, int *y)

Слайд 103Передача параметров по ссылке
/* Правильное использование параметров */
void change (int &x,
Передача параметров по ссылке
/* Правильное использование параметров */
void change (int &x,

Слайд 104Ввод массива
#include
void vvod(float mas[],int n)
{
int i;
for(i=0; i {
printf("mas[%d]=",
Ввод массива
#include
void vvod(float mas[],int n)
{
int i;
for(i=0; i
printf("mas[%d]=",
![Ввод массива #include void vvod(float mas[],int n) { int i; for(i=0; i](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-103.jpg)
Слайд 105Вывод массива
void vivod(float mas[], int n)
{
int i;
for(i=0; i printf("mas[%d]=%7.3f\n",i,mas[i]);
}
Вывод массива
void vivod(float mas[], int n)
{
int i;
for(i=0; i
}
![Вывод массива void vivod(float mas[], int n) { int i; for(i=0; i printf("mas[%d]=%7.3f\n",i,mas[i]); }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-104.jpg)
Слайд 106Обработка массива
( функция возвращает сумму отрицательных элементов)
float otr(float mas[],int n)
{
int i;
Обработка массива
( функция возвращает сумму отрицательных элементов)
float otr(float mas[],int n)
{
int i;
![Обработка массива ( функция возвращает сумму отрицательных элементов) float otr(float mas[],int n)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-105.jpg)
Слайд 107Вызов функций
int main()
{
float s;
int n;
char c;
float a[10];
printf("vvesti razmer\n");
Вызов функций
int main()
{
float s;
int n;
char c;
float a[10];
printf("vvesti razmer\n");

Слайд 108Лаб. Раб. 7 вар 9
Лаб. Раб. 7 вар 9

Слайд 109Функция main
int main()
{
int n; char c;
float a[100], b[100], c[100], as[100],
Функция main
int main()
{
int n; char c;
float a[100], b[100], c[100], as[100],
![Функция main int main() { int n; char c; float a[100], b[100],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-108.jpg)
Слайд 110Функция, возвращающая сумму элементов массива
float sum(float mas[],int n)
{
int i;
float s=0;
Функция, возвращающая сумму элементов массива
float sum(float mas[],int n)
{
int i;
float s=0;
![Функция, возвращающая сумму элементов массива float sum(float mas[],int n) { int i;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-109.jpg)
Слайд 111Функция strih
void strih(float m[],float ms[],int n)
{
int i;
float s; s=sum(m,n);
for(i=0;
Функция strih
void strih(float m[],float ms[],int n)
{
int i;
float s; s=sum(m,n);
for(i=0;
![Функция strih void strih(float m[],float ms[],int n) { int i; float s;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-110.jpg)
Слайд 112Функция calc
void calc(float m1[],float m2[],float mrez[],int n)
{
int i;
for(i=0; i
Функция calc
void calc(float m1[],float m2[],float mrez[],int n)
{
int i;
for(i=0; i
![Функция calc void calc(float m1[],float m2[],float mrez[],int n) { int i; for(i=0; i mrez[i]=m1[i]+m2[i]; }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-111.jpg)
Слайд 113Прототипы функций
void vvod(float mas[],int n);
void vivod(float mas[], int n);
float sum(float mas[],int n);
void
Прототипы функций
void vvod(float mas[],int n);
void vivod(float mas[], int n);
float sum(float mas[],int n);
void
![Прототипы функций void vvod(float mas[],int n); void vivod(float mas[], int n); float](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-112.jpg)




Слайд 118Проекты
Проекты


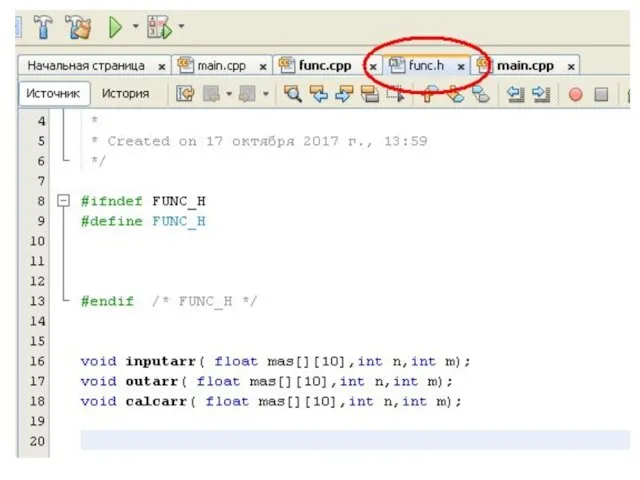
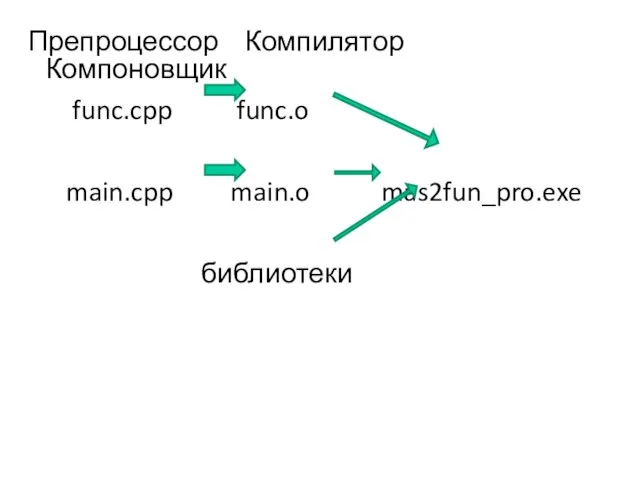
Слайд 123 Препроцессор Компилятор Компоновщик
func.cpp func.o
main.cpp main.o mas2fun_pro.exe
библиотеки
Препроцессор Компилятор Компоновщик
func.cpp func.o
main.cpp main.o mas2fun_pro.exe
библиотеки
Слайд 124Область действия ( видимость ) переменных
#include
void main(void)
{ int a=10;
{
int a=5;
cout< }
cout<}
Переменная видна в
Область действия ( видимость ) переменных
#include Переменная видна в
void main(void)
{ int a=10;
{
int a=5;
cout<
cout<

Слайд 125Автоматические и статические преременные
#include
int calc()
{
int a=0;
a++;
return(a);
}
void main(void)
{
int x;
x=calc();
Автоматические и статические преременные
#include
int calc()
{
int a=0;
a++;
return(a);
}
void main(void)
{
int x;
x=calc();

Слайд 126#include
int calc()
{
static int a=0;
a++;
return(a);
}
void main(void)
{
int x;
x=calc();
cout<<"x="<
#include
int calc()
{
static int a=0;
a++;
return(a);
}
void main(void)
{
int x;
x=calc();
cout<<"x="<

Слайд 127Динамические массивы
#include
void inputarr(int *inarr, int n, char arrname[])
{
int i;
cout << "Input
Динамические массивы
#include
void inputarr(int *inarr, int n, char arrname[])
{
int i;
cout << "Input
![Динамические массивы #include void inputarr(int *inarr, int n, char arrname[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-126.jpg)
Слайд 128void outputarr(int *outarr, int n, char arrname[])
{
int i;
for (i=0; i cout
void outputarr(int *outarr, int n, char arrname[])
{
int i;
for (i=0; i
![void outputarr(int *outarr, int n, char arrname[]) { int i; for (i=0; i cout }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-127.jpg)
Слайд 129void createoutarr(int arr1[], int arr2[], int outarr[], int n)
{
int i;
for (i=0; i![void createoutarr(int arr1[], int arr2[], int outarr[], int n) { int i; for (i=0; i }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-128.jpg)
void createoutarr(int arr1[], int arr2[], int outarr[], int n)
{
int i;
for (i=0; i
Слайд 130void main()
{
int *x,*y,*z,*xy,*xz,*yz;
int Size;
cout<<"Enter size of array ";
cin>>Size;
x =new int[Size];
y
void main()
{
int *x,*y,*z,*xy,*xz,*yz;
int Size;
cout<<"Enter size of array ";
cin>>Size;
x =new int[Size];
y
![void main() { int *x,*y,*z,*xy,*xz,*yz; int Size; cout cin>>Size; x =new int[Size];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-129.jpg)
Слайд 131 inputarr(x, Size, "x");
inputarr(y, Size, "y");
inputarr(z, Size, "z");
createoutarr(x, y, xy, Size);
createoutarr(x, z, xz,
inputarr(x, Size, "x");
inputarr(y, Size, "y");
inputarr(z, Size, "z");
createoutarr(x, y, xy, Size);
createoutarr(x, z, xz,

Слайд 132Освобождение динамической памяти
delete [] x;
delete [] y;
delete [] z;
delete [] xy;
delete
Освобождение динамической памяти
delete [] x;
delete [] y;
delete [] z;
delete [] xy;
delete
![Освобождение динамической памяти delete [] x; delete [] y; delete [] z;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/902511/slide-131.jpg)
Слайд 133Передача имен функций в качестве параметров
Функцию можно вызвать через указатель на нее.
Передача имен функций в качестве параметров
Функцию можно вызвать через указатель на нее.

Слайд 134#include
#include
#include
int f(int a ){ return a; }
int (*pf)(int);
int main(void)
{
pf
#include
#include
#include
int f(int a ){ return a; }
int (*pf)(int);
int main(void)
{
pf

Слайд 135#include
#include
#include
int f(int a ){ return a; }
int (*pf)(int);
void fun(int
#include
#include
#include
int f(int a ){ return a; }
int (*pf)(int);
void fun(int

Слайд 136Перегрузка функций
Перегрузка функций — это механизм, который позволяет двум родственным функциям иметь одинаковые имена.
В
Перегрузка функций
Перегрузка функций — это механизм, который позволяет двум родственным функциям иметь одинаковые имена.
В


Слайд 138Аргументы, передаваемые функции по умолчанию
В C++ мы можем придать параметру некоторое значение,
Аргументы, передаваемые функции по умолчанию
В C++ мы можем придать параметру некоторое значение,

Слайд 139Включение в C++ возможности передачи аргументов по умолчанию позволяет программистам упрощать код
Включение в C++ возможности передачи аргументов по умолчанию позволяет программистам упрощать код

Слайд 141Важно понимать, что все параметры, которые принимают значения по умолчанию, должны быть
Важно понимать, что все параметры, которые принимают значения по умолчанию, должны быть

Слайд 142Об использовании аргументов, передаваемых по умолчанию
Несмотря на то что аргументы, передаваемые функции
Об использовании аргументов, передаваемых по умолчанию
Несмотря на то что аргументы, передаваемые функции


Слайд 144Перегрузка функций и неоднозначность
Неоднозначность возникает тогда, когда компилятор не может определить различие
Перегрузка функций и неоднозначность
Неоднозначность возникает тогда, когда компилятор не может определить различие

Слайд 145// Неоднозначность вследствие перегрузки функций.
#include
using namespace std;
float myfunc(float i);
double myfunc(double i);
int
// Неоднозначность вследствие перегрузки функций.
#include
using namespace std;
float myfunc(float i);
double myfunc(double i);
int

Слайд 146Здесь благодаря перегрузке функция myfunc() может принимать аргументы либо типа float, либо типа double.
Здесь благодаря перегрузке функция myfunc() может принимать аргументы либо типа float, либо типа double.

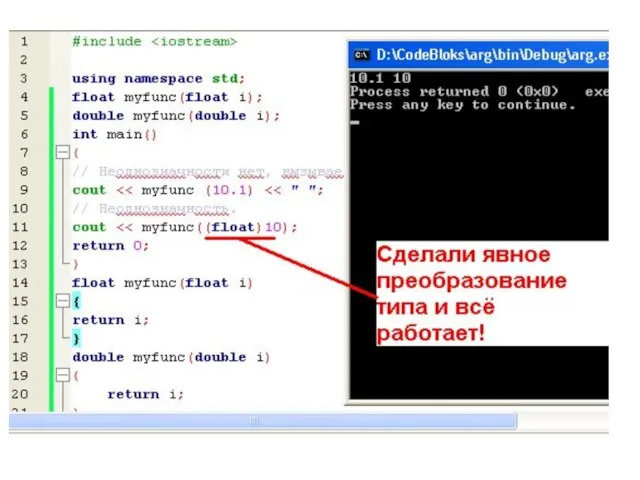
Слайд 149Возврат ссылок
Функция может возвращать ссылку. В программировании на C++ предусмотрено несколько применений
Возврат ссылок
Функция может возвращать ссылку. В программировании на C++ предусмотрено несколько применений

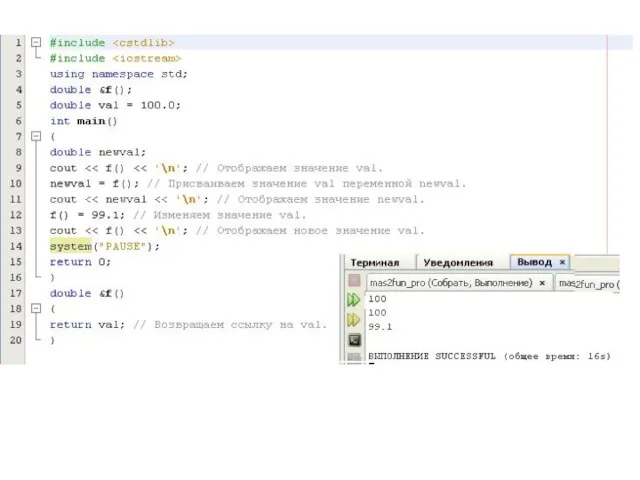
Слайд 151Рассмотрим эту программу подробнее. Судя по прототипу функции f(), она должна возвращать ссылку
Рассмотрим эту программу подробнее. Судя по прототипу функции f(), она должна возвращать ссылку

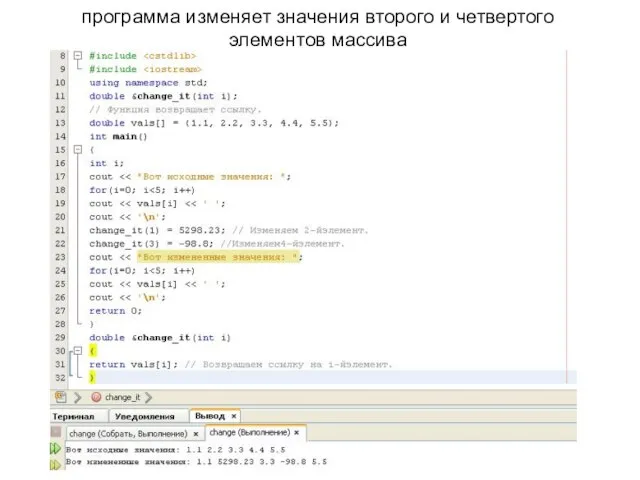
Слайд 152программа изменяет значения второго и четвертого элементов массива
программа изменяет значения второго и четвертого элементов массива
Слайд 153Функция change_it() объявлена как возвращающая ссылку на значение типа double. Говоря более конкретно, она
Функция change_it() объявлена как возвращающая ссылку на значение типа double. Говоря более конкретно, она

Слайд 154Создание ограниченного массива
Ссылочный тип в качестве типа значения, возвращаемого функцией, можно с
Создание ограниченного массива
Ссылочный тип в качестве типа значения, возвращаемого функцией, можно с

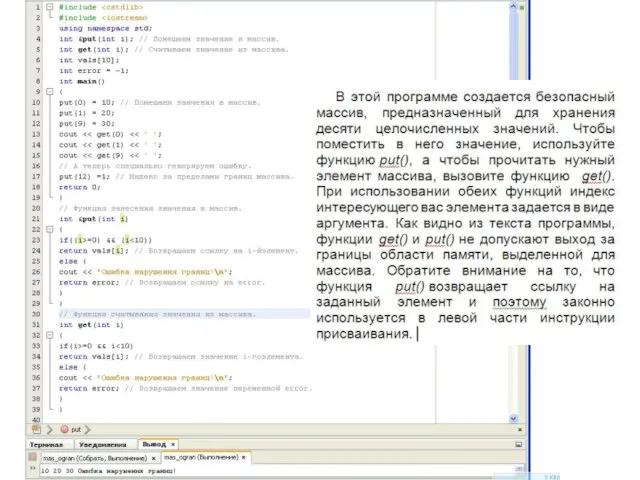
Слайд 156Независимые ссылки
Понятие ссылки включено в C++ главным образом для поддержки способа передачи
Независимые ссылки
Понятие ссылки включено в C++ главным образом для поддержки способа передачи

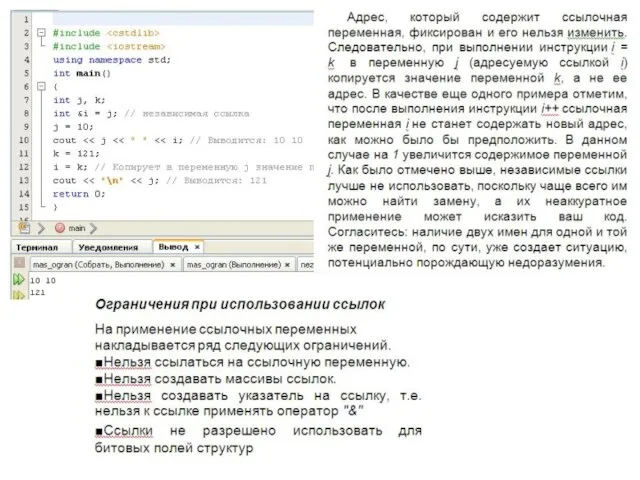
Слайд 158Функция Си/ C++ - qsort
//void qsort(void *base, size_t nelem,
//size_t width, int (*fcmp)(const
Функция Си/ C++ - qsort
//void qsort(void *base, size_t nelem,
//size_t width, int (*fcmp)(const

Слайд 159#include
#include
#include
int sort_function( const void *a, const void *b);
char list[5][4]
#include
#include
#include
int sort_function( const void *a, const void *b);
char list[5][4]


Слайд 161Двумерные динамические массивы
Санкт-Петербургский государственный университет телекоммуникаций им. проф. М.А. Бонч-Бруевича
Двумерные динамические массивы
Санкт-Петербургский государственный университет телекоммуникаций им. проф. М.А. Бонч-Бруевича

Слайд 162Вспомним одномерные динамич. массивы
Вспомним одномерные динамич. массивы

Слайд 163Работаем с дин. масс. как с обычным массивом
Работаем с дин. масс. как с обычным массивом

Слайд 164Освобождаем память
Освобождаем память

Слайд 165Двумерный динамический массив
Двумерный динамический массив

Слайд 166Недостаток!
Недостаток!

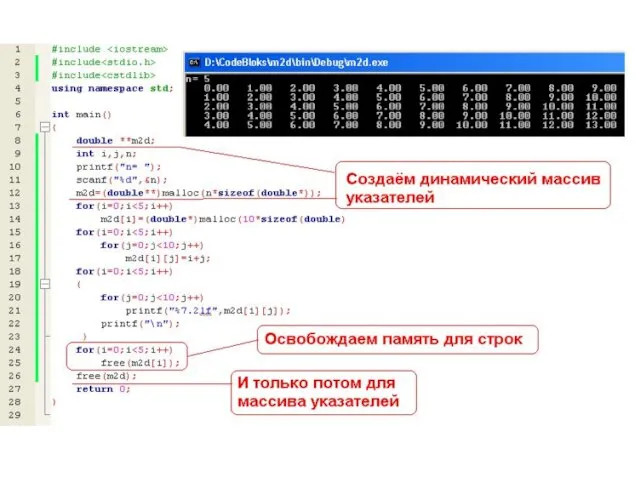
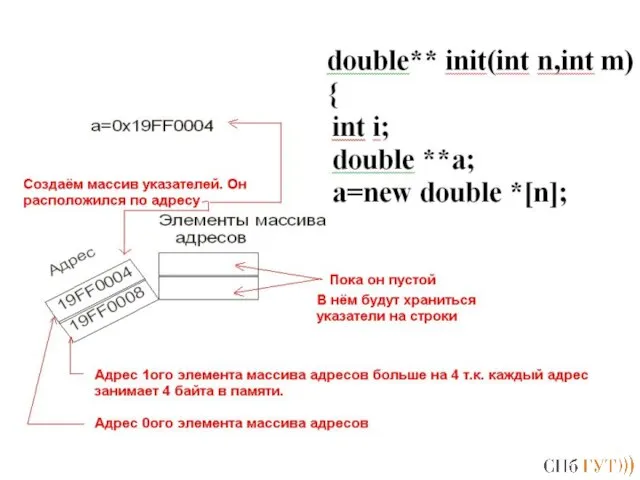
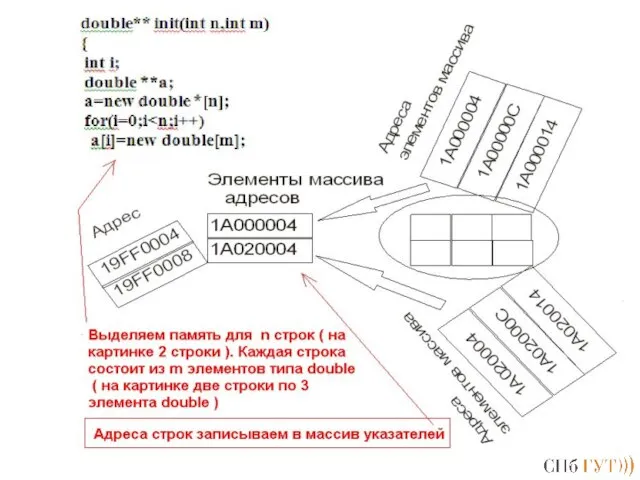
Слайд 167Вывод! Нужно сделать массив указателей динамическим!
Вывод! Нужно сделать массив указателей динамическим!

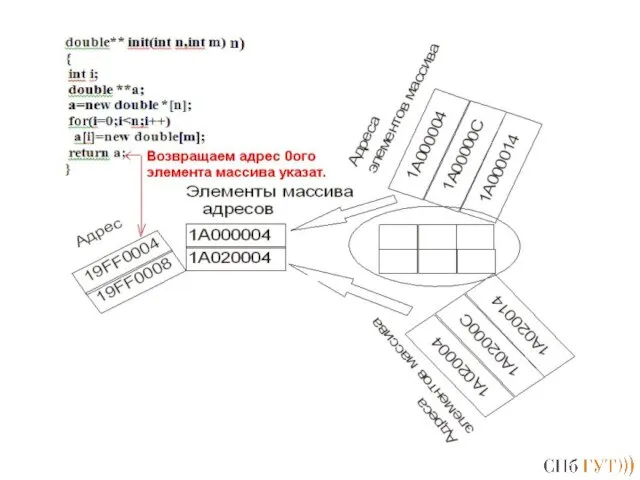
Слайд 172Массив указателей на функции
Массив указателей на функции определяется точно также, как и
Массив указателей на функции Массив указателей на функции определяется точно также, как и




Слайд 176Часто указатели на функцию становятся громоздкими. Работу с ними можно упростить, если
Часто указатели на функцию становятся громоздкими. Работу с ними можно упростить, если



Слайд 179Препроцессор C++
Препроцессор C++ подвергает программу различным текстовым преобразованиям до реальной трансляции исходного
Препроцессор C++
Препроцессор C++ подвергает программу различным текстовым преобразованиям до реальной трансляции исходного

Слайд 180Директива #define
Директива #define используется для определения идентификатора и символьной последовательности, которая будет подставлена вместо
Директива #define
Директива #define используется для определения идентификатора и символьной последовательности, которая будет подставлена вместо

Слайд 181После определения имени макроса его можно использовать как часть определения других макроимен.
После определения имени макроса его можно использовать как часть определения других макроимен.

Слайд 182Если текстовая последовательность не помещается на строке, ее можно продолжить на следующей,
Если текстовая последовательность не помещается на строке, ее можно продолжить на следующей,

Слайд 183Макроопределения, действующие как функции
Директива #define имеет еще одно назначение: макроимя может использоваться с аргументами.
Макроопределения, действующие как функции
Директива #define имеет еще одно назначение: макроимя может использоваться с аргументами.

Слайд 184Макроопределения, действующие как функции, — это макроопределения, которые принимают аргументы.
Кажущиеся избыточными круглые скобки, в
Макроопределения, действующие как функции, — это макроопределения, которые принимают аргументы.
Кажущиеся избыточными круглые скобки, в

Слайд 185// Эта программа работает корректно.
#include
using namespace std;
#define EVEN(a) (a)%2==0 ? 1
// Эта программа работает корректно.
#include
using namespace std;
#define EVEN(a) (a)%2==0 ? 1

Слайд 186Директива #еrror
Директива #error отображает сообщение об ошибке.
Директива #error дает указание компилятору остановить компиляцию. Она
Директива #еrror
Директива #error отображает сообщение об ошибке.
Директива #error дает указание компилятору остановить компиляцию. Она

Слайд 187Директива #include
Директива #include включает заголовочный или другой исходный файл.
Директива препроцессора #include обязывает компилятор включить либо стандартный
Директива #include
Директива #include включает заголовочный или другой исходный файл.
Директива препроцессора #include обязывает компилятор включить либо стандартный

Слайд 188Директивы условной компиляции
Существуют директивы, которые позволяют избирательно компилировать части исходного кода. Этот
Директивы условной компиляции
Существуют директивы, которые позволяют избирательно компилировать части исходного кода. Этот

Слайд 189// Простой пример использования директивы #if.
#include
using namespace std;
#define MAX 100
int main()
{
#if
// Простой пример использования директивы #if.
#include
using namespace std;
#define MAX 100
int main()
{
#if

Слайд 190Поведение директивы #else во многом подобно поведению инструкции else, которая является частью языка C++:
Поведение директивы #else во многом подобно поведению инструкции else, которая является частью языка C++:

Слайд 191Директива #elif эквивалентна связке инструкций else-if и используется для формирования многозвенной схемы if-else-if,представляющей несколько вариантов
Директива #elif эквивалентна связке инструкций else-if и используется для формирования многозвенной схемы if-else-if,представляющей несколько вариантов

Слайд 192Например, в этом фрагменте кода используется идентификатор COMPILED_BY, который позволяет определить, кем компилируется
Например, в этом фрагменте кода используется идентификатор COMPILED_BY, который позволяет определить, кем компилируется

Слайд 193Директивы #if и #elif могут быть вложенными. В этом случае директива #endif, #else или #elif связывается
Директивы #if и #elif могут быть вложенными. В этом случае директива #endif, #else или #elif связывается

Слайд 194Директивы #ifdef и #ifndef
Директивы #ifdef и #ifndef предлагают еще два варианта условной компиляции, которые можно
Директивы #ifdef и #ifndef
Директивы #ifdef и #ifndef предлагают еще два варианта условной компиляции, которые можно

Слайд 195Директива #undef
Директива #undef используется для удаления предыдущего определения некоторого макроимени. Ее общий формат таков.
#undef
Директива #undef
Директива #undef используется для удаления предыдущего определения некоторого макроимени. Ее общий формат таков.
#undef

Слайд 196Использование оператора defined
Помимо директивы #ifdef существует еще один способ выяснить, определено ли в программе
Использование оператора defined
Помимо директивы #ifdef существует еще один способ выяснить, определено ли в программе

Слайд 197Директива #line
Директива #line изменяет содержимое псевдопеременных _ _LINE_ _ и _ _FILE_
Директива #line
Директива #line изменяет содержимое псевдопеременных _ _LINE_ _ и _ _FILE_

Слайд 198Директива #pragma
Работа директивы #pragma зависит от конкретной реализации компилятора. Она позволяет выдавать компилятору различные
Директива #pragma
Работа директивы #pragma зависит от конкретной реализации компилятора. Она позволяет выдавать компилятору различные

Слайд 199Операторы препроцессора "#" и "##"
В C++ предусмотрена поддержка двух операторов препроцессора: "#" и"##". Эти
Операторы препроцессора "#" и "##"
В C++ предусмотрена поддержка двух операторов препроцессора: "#" и"##". Эти

Слайд 200##
Оператор используется для конкатенации двух лексем. Рассмотрим пример.
#include
using namespace std;
#define concat(a,
##
Оператор используется для конкатенации двух лексем. Рассмотрим пример.
#include
using namespace std;
#define concat(a,

 Helping Companies Leverage Investments in SAP Solutions
Helping Companies Leverage Investments in SAP Solutions Основы Python. Составные типы данных. Функции. Область видимости переменных
Основы Python. Составные типы данных. Функции. Область видимости переменных Сфера деятельности Adobe Systems
Сфера деятельности Adobe Systems Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера programmirovanie_l5-2016
programmirovanie_l5-2016 Сотовая связь
Сотовая связь Выбор провайдера и виртуальная организация взаимодействия с ним
Выбор провайдера и виртуальная организация взаимодействия с ним Компьютерные телекоммуникации. Организация работы Интернет
Компьютерные телекоммуникации. Организация работы Интернет Лекция 2
Лекция 2 Летняя школа по биоинформатике 2019
Летняя школа по биоинформатике 2019 Аналитическая бизнес-справка на ЮЛ
Аналитическая бизнес-справка на ЮЛ Killer in the game
Killer in the game Самостоятельная работа ИКТ
Самостоятельная работа ИКТ Предпроектная стадия создания информационной системы
Предпроектная стадия создания информационной системы Решение задач на компьютере алгоритмизация и программирование
Решение задач на компьютере алгоритмизация и программирование Работа с готовой электронной таблицей. Практическая работа №11. 8 класс
Работа с готовой электронной таблицей. Практическая работа №11. 8 класс Оптические сети переноса
Оптические сети переноса Немаркетинговые способы организации избирательного процесса
Немаркетинговые способы организации избирательного процесса Разработка ПО для управления движения денежных средств клиентов инвестиционного фонда
Разработка ПО для управления движения денежных средств клиентов инвестиционного фонда Презентация к уроку информатики в 2 классе по программе А.В.Горячева (IV четверть 7 урок)
Презентация к уроку информатики в 2 классе по программе А.В.Горячева (IV четверть 7 урок) Деснол Софт. Управляемый интерфейс 1С
Деснол Софт. Управляемый интерфейс 1С Инструкция для обучающихся КазНМУ по тестированию с прокторингом
Инструкция для обучающихся КазНМУ по тестированию с прокторингом Творческая работа на уроке информатики
Творческая работа на уроке информатики ليلى عثمان باحلى الموضاعت التعليمية
ليلى عثمان باحلى الموضاعت التعليمية Назначение компьютерных сетей
Назначение компьютерных сетей 20141113_klimatoobrazuyushchie_faktory
20141113_klimatoobrazuyushchie_faktory Объектная модель Excel
Объектная модель Excel КирТим.ру. Интернет
КирТим.ру. Интернет