- Лекции 19. Алгоритмы Маркова

Содержание
- 2. Ассоциативные исчисления. Пусть имеется алфавит (конечный набор различных символов). Составляющие его символы будем называть буквами. Любая
- 3. Чтобы задать ассоциативное исчисление, достаточно задать алфавит и систему подстановок. Слова P1 и Р2 в некотором
- 4. Лемма. Пусть P~Q; тогда, если в каком-либо слове R имеется вхождение Р, то в результате подстановки
- 5. В 1946 и 1947 годах русский математик А.А.Марков и американский математик Э.Пост независимо один от другого
- 6. Пример 1.2 (Г.С.Цейтин). Дано ассоциативное исчисление, включающее алфавит A={ a, b, c, d, e} и систему
- 7. Формальные основы экспертных систем Большинство экспертных систем базируется на понятии "формальная продукционная система". Продукционные системы берут
- 8. Пусть некоторое слово Y начинается словом xi . Применить к Y продукцию xiW →Wyi - это
- 10. Алгоритмы Маркова Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом в алфавите А называется понятное точное
- 11. Алгоритмы Маркова Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом в алфавите А называется понятное точное
- 12. Система подстановок В: cb → cc сса→ аb ab → bса Применяя систему подстановок В из
- 13. Проанализируем сложение натуральных чисел. На входе алгоритма поступают два натуральных числа x и y. Пусть числа
- 14. Нормальные алгоритмы Маркова Теория нормальных алгоритмов (или алгорифмов, как называл их создатель теории) была разработана советским
- 15. Алфавит и схема нормального алгоритма. Нормальный алгоритм М задается двумя компонентами: алфавитом алгоритма, схемой алгоритма. 1)
- 16. Работа нормального алгоритма. Пусть на вход нормального алгоритма A со схемой Z поступило слово P. Начинаем
- 17. Таким образом, в результате получаем ровно один из двух случаев I или II. I. Процесс переработки
- 18. Такой набор предписаний вместе с алфавитом А и набором подстановок В определяют нормальный алгоритм. Процесс останавливается
- 19. 2. Вычисление остатка при делении на 4. Построим нормальный алгоритм, который находит остаток от деления натурального
- 20. 3. Вычитание единицы (считаем, что 0 − 1 = 0): А = {| , ?}. |
- 21. 5. Аннулирующий алгоритм. Зададим нормальный алгоритм М схемой a1 →ε a2 →ε . . . ak
- 22. Отметим, что не все вербальные алгоритмы являются нормальными алгоритмами. Вербальные алгоритмы реализуют произвольные преобразования слов, а
- 23. Определение 1. Пусть заданы алфавиты A и A1. Если A ⊆ A1, то алфавит A1 называется
- 24. Примеры. 1. Алгоритм М левого присоединения слова v. В нем для любого входного слова u выходным
- 25. 2. Алгоритм правого присоединения. В этом случае нет простейшего алгоритма. Для реализации правого присоединения расширим алфавит
- 26. 3. Алгоритм удаления первой буквы непустого слова. Алфавит Σ = {?, ?,c}. Вставим в начало слова
- 27. При записи системы подстановок (т.е. схемы алгоритма) иногда удобно сокращать запись, вводя новые буквы, не принадлежащие
- 28. Если применить эту схему к пустому слову, то мы получим зацикливание (первые две подстановки останутся после
- 29. Таким же образом, добавляя буквы к алфавиту A , можно получить схему для операции перевертывания слов
- 30. 4. Увеличение на единицу натурального числа в двоичной форме. Действие алгоритма будет состоять из двух этапов:
- 31. Второй этап: подстановки (е) или (ё) заменяют ? на ? и либо срабатывают заключительные подстановки (a)
- 32. А.А.Марков предложил следующий тезис. Принцип нормализации. Пусть задан произвольный вербальный алгоритм В в алфавите A .
- 33. Данный принцип не может быть строго доказан, поскольку понятие произвольного алгоритма не является строго определенным и
- 35. Скачать презентацию
Слайд 2 Ассоциативные исчисления.
Пусть имеется алфавит (конечный набор различных символов). Составляющие его
Ассоциативные исчисления.
Пусть имеется алфавит (конечный набор различных символов). Составляющие его

Слайд 3 Чтобы задать ассоциативное исчисление, достаточно задать алфавит и систему подстановок.
Чтобы задать ассоциативное исчисление, достаточно задать алфавит и систему подстановок.

Слайд 4Лемма. Пусть P~Q; тогда, если в каком-либо слове R имеется вхождение Р,
Лемма. Пусть P~Q; тогда, если в каком-либо слове R имеется вхождение Р,

Слайд 5В 1946 и 1947 годах русский математик А.А.Марков и американский математик Э.Пост
В 1946 и 1947 годах русский математик А.А.Марков и американский математик Э.Пост

Слайд 6Пример 1.2 (Г.С.Цейтин). Дано ассоциативное исчисление, включающее алфавит A={ a, b, c,
Пример 1.2 (Г.С.Цейтин). Дано ассоциативное исчисление, включающее алфавит A={ a, b, c,

Слайд 7 Формальные основы экспертных систем
Большинство экспертных систем базируется на понятии "формальная
Формальные основы экспертных систем
Большинство экспертных систем базируется на понятии "формальная

Слайд 8
Пусть некоторое слово Y начинается словом xi . Применить к
Пусть некоторое слово Y начинается словом xi . Применить к

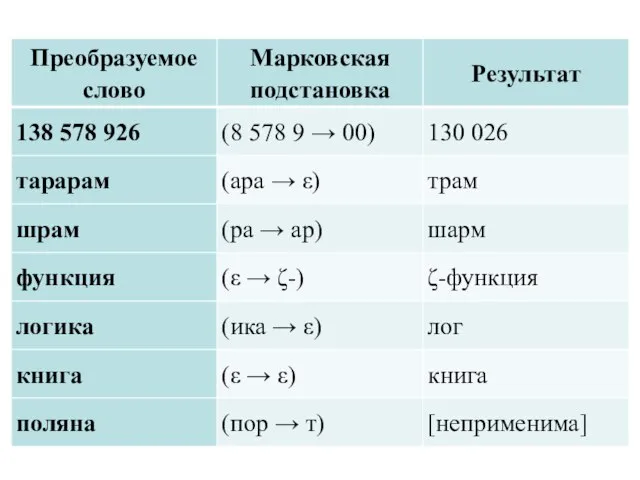
Слайд 10 Алгоритмы Маркова
Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом
Алгоритмы Маркова
Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом

Слайд 11 Алгоритмы Маркова
Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом
Алгоритмы Маркова
Введем понятие алгоритма на основе ассоциативного исчисления: алгоритмом

Слайд 12Система подстановок В:
cb → cc
сса→ аb
ab → bса
Применяя систему подстановок В из
cb → cc
сса→ аb
ab → bса
Применяя систему подстановок В из

Слайд 13 Проанализируем сложение натуральных чисел. На входе алгоритма поступают два натуральных числа
Проанализируем сложение натуральных чисел. На входе алгоритма поступают два натуральных числа

Слайд 14Нормальные алгоритмы Маркова
Теория нормальных алгоритмов (или алгорифмов, как называл их создатель
Нормальные алгоритмы Маркова
Теория нормальных алгоритмов (или алгорифмов, как называл их создатель

Слайд 15 Алфавит и схема нормального алгоритма.
Нормальный алгоритм М задается двумя
Алфавит и схема нормального алгоритма.
Нормальный алгоритм М задается двумя

Слайд 16 Работа нормального алгоритма.
Пусть на вход нормального алгоритма A со
Работа нормального алгоритма.
Пусть на вход нормального алгоритма A со

Слайд 17
Таким образом, в результате получаем ровно один из двух случаев
Таким образом, в результате получаем ровно один из двух случаев

Слайд 18Такой набор предписаний вместе с алфавитом А и набором подстановок В определяют нормальный алгоритм. Процесс останавливается
Такой набор предписаний вместе с алфавитом А и набором подстановок В определяют нормальный алгоритм. Процесс останавливается

Слайд 192. Вычисление остатка при делении на 4. Построим нормальный алгоритм, который находит
2. Вычисление остатка при делении на 4. Построим нормальный алгоритм, который находит

Слайд 203. Вычитание единицы (считаем, что 0 − 1 = 0):
А = {|
3. Вычитание единицы (считаем, что 0 − 1 = 0):
А = {|

Слайд 215. Аннулирующий алгоритм. Зададим нормальный алгоритм М схемой
a1 →ε
5. Аннулирующий алгоритм. Зададим нормальный алгоритм М схемой
a1 →ε

Слайд 22 Отметим, что не все вербальные алгоритмы являются нормальными алгоритмами. Вербальные алгоритмы
Отметим, что не все вербальные алгоритмы являются нормальными алгоритмами. Вербальные алгоритмы

Слайд 23Определение 1. Пусть заданы алфавиты A и A1. Если
A ⊆ A1, то
Определение 1. Пусть заданы алфавиты A и A1. Если
A ⊆ A1, то

Слайд 24Примеры.
1. Алгоритм М левого присоединения слова v. В нем для любого входного
1. Алгоритм М левого присоединения слова v. В нем для любого входного

Слайд 252. Алгоритм правого присоединения. В этом случае нет простейшего алгоритма. Для реализации
2. Алгоритм правого присоединения. В этом случае нет простейшего алгоритма. Для реализации

Слайд 263. Алгоритм удаления первой буквы непустого слова.
Алфавит Σ = {?, ?,c}.
3. Алгоритм удаления первой буквы непустого слова.
Алфавит Σ = {?, ?,c}.

Слайд 27При записи системы подстановок (т.е. схемы алгоритма) иногда удобно сокращать запись, вводя

Слайд 28
Если применить эту схему к пустому слову, то мы получим
Если применить эту схему к пустому слову, то мы получим

Слайд 29 Таким же образом, добавляя буквы к алфавиту A , можно получить
Таким же образом, добавляя буквы к алфавиту A , можно получить

Слайд 304. Увеличение на единицу натурального числа в двоичной форме.
Действие алгоритма
4. Увеличение на единицу натурального числа в двоичной форме.
Действие алгоритма

Слайд 31 Второй этап: подстановки (е) или (ё) заменяют ? на ? и
Второй этап: подстановки (е) или (ё) заменяют ? на ? и

Слайд 32 А.А.Марков предложил следующий тезис.
Принцип нормализации. Пусть задан произвольный вербальный алгоритм В
А.А.Марков предложил следующий тезис.
Принцип нормализации. Пусть задан произвольный вербальный алгоритм В

Слайд 33 Данный принцип не может быть строго доказан, поскольку понятие произвольного алгоритма
Данный принцип не может быть строго доказан, поскольку понятие произвольного алгоритма

 Исследование функций
Исследование функций Параллельные прямые 7 класс
Параллельные прямые 7 класс Презентация на тему Прибавление числа 4 (1 класс)
Презентация на тему Прибавление числа 4 (1 класс)  Чтение девятизначных чисел
Чтение девятизначных чисел Взаимное расположение прямой и окружности. Касательная
Взаимное расположение прямой и окружности. Касательная Решение задач с помощью уравнений
Решение задач с помощью уравнений Алгебра логики
Алгебра логики Математика – наука о наиболее общих и фундаментальных структурах реального мира
Математика – наука о наиболее общих и фундаментальных структурах реального мира Прямоугольник. Признак прямоугольника
Прямоугольник. Признак прямоугольника Письменное умножение на трёхзначное число
Письменное умножение на трёхзначное число Сборник по подготовке к государственной итоговой аттестации по геометрии
Сборник по подготовке к государственной итоговой аттестации по геометрии Презентация на тему Правильные многоугольники
Презентация на тему Правильные многоугольники  Доминино
Доминино Что должен знать ученик о способах задания функции? Какие достоинства и недостатки имеет каждый способ?
Что должен знать ученик о способах задания функции? Какие достоинства и недостатки имеет каждый способ? Ликвидация пробелов в знаниях по теме Соотношения между сторонами и углами треугольника
Ликвидация пробелов в знаниях по теме Соотношения между сторонами и углами треугольника КВН по математике Привет друзья! Сегодня в школе Большой и интересный день Мы приготовили веселый Наш школьный праздник КВН.
КВН по математике Привет друзья! Сегодня в школе Большой и интересный день Мы приготовили веселый Наш школьный праздник КВН. Простейшие линейные цепи при гармоническом воздействии
Простейшие линейные цепи при гармоническом воздействии Теория алгоритмов
Теория алгоритмов Полиномы над полями конечной характеристики
Полиномы над полями конечной характеристики Действия с числами, записанными в стандартном виде
Действия с числами, записанными в стандартном виде Серединный перпендикуляр
Серединный перпендикуляр Иллюзии и математические парадоксы
Иллюзии и математические парадоксы Учимся складывать столбиком
Учимся складывать столбиком Функциональная грамотность на уроках математики
Функциональная грамотность на уроках математики Презентация по математике "Праздник чисел «5 плюс »" -
Презентация по математике "Праздник чисел «5 плюс »" -  ДУ и численные методы. Системы дифференциальных уравнений. 2 семестр. Лекция 8
ДУ и численные методы. Системы дифференциальных уравнений. 2 семестр. Лекция 8 Интерполирование с кратными узлами
Интерполирование с кратными узлами Кривые второго порядка
Кривые второго порядка