- Презентация по математике "Основы концепции “глубинного анализа текстов" -

Содержание
- 2. © ElVisti Контент-анализ: определения Один из истоков концепции Text Mining – контент-анализ. Понятие контент-анализа, корни которого
- 3. © ElVisti Контент-анализ и добыча данных Контент-анализ в рамках исследования электронных информационных массивов - относительно новое
- 4. © ElVisti Основные задачи Text Mining Как и большинство когнитивных технологий – Text Mining – это
- 5. © ElVisti Основные элементы Text Mining В соответствии с уже сформированной методологии к основным элементам Text
- 6. © ElVisti Классификация При классификации текстов используются статистические корреляции для построения правил размещения документов в определенные
- 7. © ElVisti Кластеризация Кластеризация базируется на признаках документов, которые использует лингвистические и математические методы без использования
- 8. © ElVisti Другие элементы Построение семантических сетей Построение семантических сетей или анализ связей, которые определяют появление
- 9. © ElVisti Автоматическое реферирование Автоматическое реферирование (Automatic Text Summarization) - это составление коротких изложений материалов, аннотаций
- 10. © ElVisti 3 направления квазиреферирования В рамках квазиреферирования выделяют три основных направления, зачастую применяемых совместно: статистические
- 11. © ElVisti Определение веса фрагментов при квазиреферирования Определение веса фрагментов (предложений или абзацев) исходного текста выполняется
- 12. © ElVisti Поисковые образы документов На основе методов автоматического реферирования возможно формирование поисковых образов документов. По
- 13. © ElVisti Особенности реализации систем Рассматриваются системы: Intelligent Miner for Text (IBM) PolyAnalyst (Мегапьютер Інтеллидженс) Text
- 14. © ElVisti Intelligent Miner for Text (IBM) (http://www-3.ibm.com/software/data/iminer/fortext/) Система является одним из лучших инструментов глубинного анализа
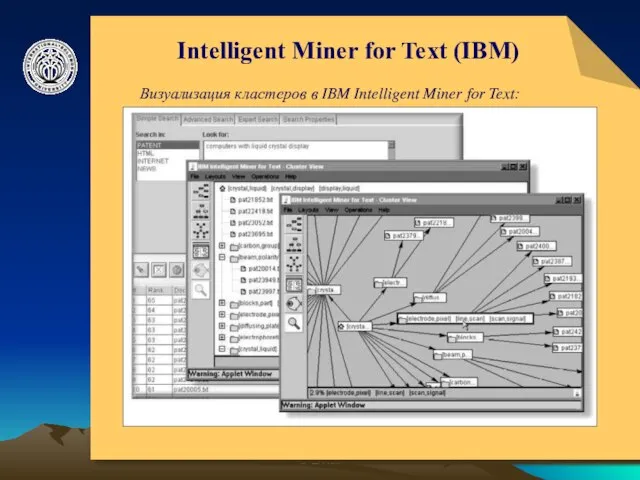
- 15. © ElVisti Intelligent Miner for Text (IBM) Визуализация кластеров в IBM Intelligent Miner for Text:
- 16. © ElVisti PolyAnalyst (Мегапьютер Інтеллидженс) ( http://www.megaputer.com/ ) PolyAnalyst может применяться для автоматизированного анализа числовых и
- 17. © ElVisti TextAnalyst В состав PolyAnalyst входит система TextAnalyst, которая решает такие задачи Text Mining: создание
- 18. © ElVisti Text Miner (SAS) http://www.sas.com/technologies/analytics/datamining/textminer/ Система SAS Text Miner может работать с текстовыми докумен-тами различных
- 19. © ElVisti SemioMap (Semio Corp.) http://www.entrieva.com/entrieva/products/semiomap.asp?Hdr=semiomap SemioMap - это продукт компании Entrieva, созданный в 1996 г.
- 20. © ElVisti SemioMap (Semio Corp.) Система SemioMap состоит из двух основных компонент - сервера SemioMap и
- 21. © ElVisti Oracle Text (Oracle) (www.oracle.com/technology/products/text/) Средства Text Mining, начиная с Text Server в составе СУБД
- 22. © ElVisti Oracle Text (Oracle) Основной задачей, на решение которой нацелены средства Oracle Text, является задача
- 23. © ElVisti Knowledge Server (Autonomy) http://www.autonomy.com/) Архитектура IDOL (Intelligent Data Operating Layer) сервера компании Autonomy, известной
- 24. © ElVisti Knowledge Server (Autonomy) Основное преимущество системы Autonomy - интеллектуальные алгоритмы, основанные на статистической обработке.
- 25. © ElVisti RetrievalWare (Convera) (www.convera.com) RetrievaWare - средство полнотекстового и атрибутивного поиска. К документам, с которыми
- 26. © ElVisti Galaktika-ZOOM ("Галактика") (http://zoom.galaktika.ru/) Основное назначение Galaktika-ZOOM - интеллектуальный поиск по ключевым словам с учетом
- 27. © ElVisti (ИЦ "ЭЛВИСТИ") (http://infostream.ua) Система InfoStream создана для охвата и обобщения динамических новостных информационных массивов,
- 28. © ElVisti (ИЦ "ЭЛВИСТИ") (http://infostream.ua) Система InfoStream обеспечивает: Доступ к оперативной информации (более 2700 источников) с
- 30. Скачать презентацию
Слайд 2© ElVisti
Контент-анализ: определения
Один из истоков концепции Text Mining – контент-анализ.
© ElVisti
Контент-анализ: определения
Один из истоков концепции Text Mining – контент-анализ.

Слайд 3© ElVisti
Контент-анализ и добыча данных
Контент-анализ в рамках исследования электронных информационных массивов
© ElVisti
Контент-анализ и добыча данных
Контент-анализ в рамках исследования электронных информационных массивов

Слайд 4© ElVisti
Основные задачи Text Mining
Как и большинство когнитивных технологий –
© ElVisti
Основные задачи Text Mining
Как и большинство когнитивных технологий –

Слайд 5© ElVisti
Основные элементы Text Mining
В соответствии с уже сформированной методологии
© ElVisti
Основные элементы Text Mining
В соответствии с уже сформированной методологии

Слайд 6© ElVisti
Классификация
При классификации текстов используются статистические корреляции для построения правил
© ElVisti
Классификация
При классификации текстов используются статистические корреляции для построения правил

Слайд 7© ElVisti
Кластеризация
Кластеризация базируется на признаках документов, которые использует лингвистические и математические
© ElVisti
Кластеризация
Кластеризация базируется на признаках документов, которые использует лингвистические и математические

Слайд 8© ElVisti
Другие элементы
Построение семантических сетей
Построение семантических сетей или анализ связей, которые
© ElVisti
Другие элементы
Построение семантических сетей
Построение семантических сетей или анализ связей, которые

Слайд 9© ElVisti
Автоматическое реферирование
Автоматическое реферирование (Automatic Text Summarization) - это составление
© ElVisti
Автоматическое реферирование
Автоматическое реферирование (Automatic Text Summarization) - это составление

Слайд 10© ElVisti
3 направления квазиреферирования
В рамках квазиреферирования выделяют три основных направления,
© ElVisti
3 направления квазиреферирования
В рамках квазиреферирования выделяют три основных направления,

Слайд 11© ElVisti
Определение веса фрагментов при квазиреферирования
Определение веса фрагментов (предложений или
© ElVisti
Определение веса фрагментов при квазиреферирования
Определение веса фрагментов (предложений или

Слайд 12© ElVisti
Поисковые образы документов
На основе методов автоматического реферирования возможно формирование
© ElVisti
Поисковые образы документов
На основе методов автоматического реферирования возможно формирование

Слайд 13© ElVisti
Особенности реализации систем
Рассматриваются системы:
Intelligent Miner for Text (IBM)
© ElVisti
Особенности реализации систем
Рассматриваются системы:
Intelligent Miner for Text (IBM)

Слайд 14© ElVisti
Intelligent Miner for Text (IBM)
(http://www-3.ibm.com/software/data/iminer/fortext/)
Система является одним из лучших
© ElVisti
Intelligent Miner for Text (IBM)
(http://www-3.ibm.com/software/data/iminer/fortext/)
Система является одним из лучших

Слайд 15© ElVisti
Intelligent Miner for Text (IBM)
Визуализация кластеров в IBM Intelligent
© ElVisti
Intelligent Miner for Text (IBM)
Визуализация кластеров в IBM Intelligent
Слайд 16© ElVisti
PolyAnalyst (Мегапьютер Інтеллидженс)
( http://www.megaputer.com/ )
PolyAnalyst может применяться для
© ElVisti
PolyAnalyst (Мегапьютер Інтеллидженс)
( http://www.megaputer.com/ )
PolyAnalyst может применяться для

Слайд 17© ElVisti
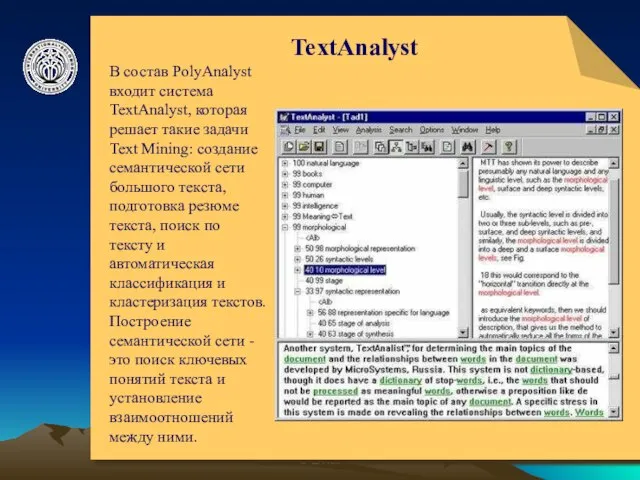
TextAnalyst
В состав PolyAnalyst входит система TextAnalyst, которая решает такие задачи
© ElVisti
TextAnalyst
В состав PolyAnalyst входит система TextAnalyst, которая решает такие задачи
Слайд 18© ElVisti
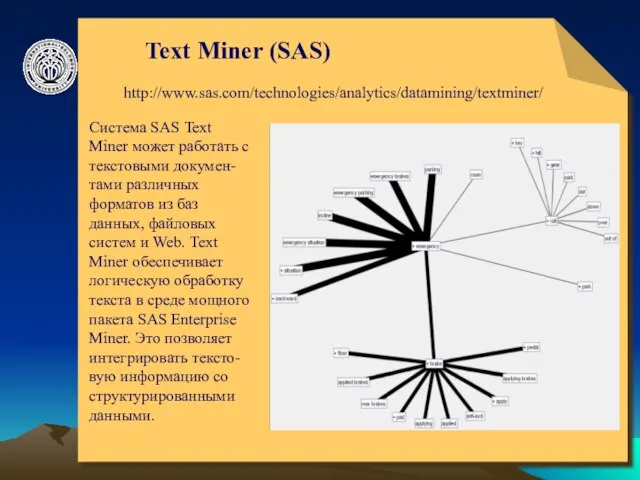
Text Miner (SAS)
http://www.sas.com/technologies/analytics/datamining/textminer/
Система SAS Text Miner может работать с
© ElVisti
Text Miner (SAS)
http://www.sas.com/technologies/analytics/datamining/textminer/
Система SAS Text Miner может работать с
Слайд 19© ElVisti
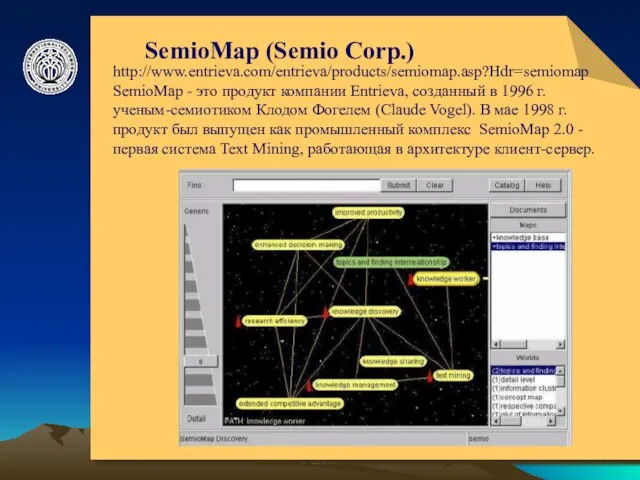
SemioMap (Semio Corp.)
http://www.entrieva.com/entrieva/products/semiomap.asp?Hdr=semiomap
SemioMap - это продукт компании Entrieva, созданный
© ElVisti
SemioMap (Semio Corp.)
http://www.entrieva.com/entrieva/products/semiomap.asp?Hdr=semiomap
SemioMap - это продукт компании Entrieva, созданный
Слайд 20© ElVisti
SemioMap (Semio Corp.)
Система SemioMap состоит из двух основных компонент -
© ElVisti
SemioMap (Semio Corp.)
Система SemioMap состоит из двух основных компонент -

Слайд 21© ElVisti
Oracle Text (Oracle)
(www.oracle.com/technology/products/text/)
Средства Text Mining, начиная с Text Server
© ElVisti
Oracle Text (Oracle)
(www.oracle.com/technology/products/text/)
Средства Text Mining, начиная с Text Server

Слайд 22© ElVisti
Oracle Text (Oracle)
Основной задачей, на решение которой нацелены средства Oracle
© ElVisti
Oracle Text (Oracle)
Основной задачей, на решение которой нацелены средства Oracle

Слайд 23© ElVisti
Knowledge Server (Autonomy)
http://www.autonomy.com/)
Архитектура IDOL (Intelligent Data Operating Layer)
© ElVisti
Knowledge Server (Autonomy)
http://www.autonomy.com/)
Архитектура IDOL (Intelligent Data Operating Layer)

Слайд 24© ElVisti
Knowledge Server (Autonomy)
Основное преимущество системы Autonomy - интеллектуальные алгоритмы, основанные
© ElVisti
Knowledge Server (Autonomy)
Основное преимущество системы Autonomy - интеллектуальные алгоритмы, основанные

Слайд 25© ElVisti
RetrievalWare (Convera)
(www.convera.com)
RetrievaWare - средство полнотекстового и атрибутивного поиска. К документам,
© ElVisti
RetrievalWare (Convera)
(www.convera.com)
RetrievaWare - средство полнотекстового и атрибутивного поиска. К документам,

Слайд 26© ElVisti
Galaktika-ZOOM ("Галактика")
(http://zoom.galaktika.ru/)
Основное назначение Galaktika-ZOOM - интеллектуальный поиск по ключевым словам
© ElVisti
Galaktika-ZOOM ("Галактика")
(http://zoom.galaktika.ru/)
Основное назначение Galaktika-ZOOM - интеллектуальный поиск по ключевым словам

Слайд 27© ElVisti
(ИЦ "ЭЛВИСТИ")
(http://infostream.ua)
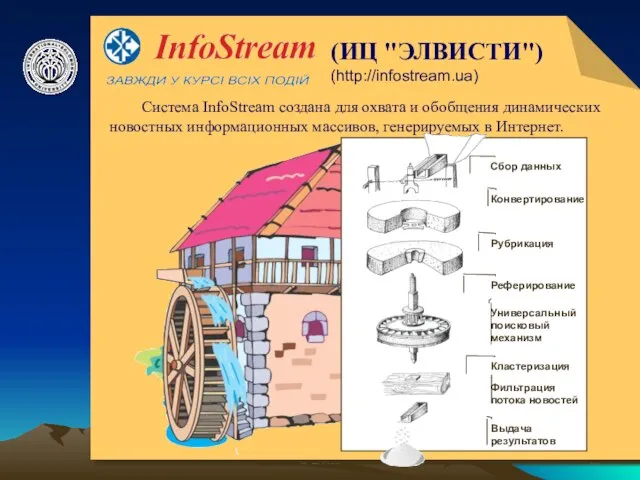
Система InfoStream создана для охвата и обобщения динамических
© ElVisti
(ИЦ "ЭЛВИСТИ")
(http://infostream.ua)
Система InfoStream создана для охвата и обобщения динамических
Слайд 28© ElVisti
(ИЦ "ЭЛВИСТИ")
(http://infostream.ua)
Система InfoStream обеспечивает:
Доступ к оперативной информации (более 2700
© ElVisti
(ИЦ "ЭЛВИСТИ")
(http://infostream.ua)
Система InfoStream обеспечивает:
Доступ к оперативной информации (более 2700

 Подобные треугольники. 8 класс
Подобные треугольники. 8 класс Решение прямоугольных треугольников
Решение прямоугольных треугольников Презентация на тему Треугольники (5 класс)
Презентация на тему Треугольники (5 класс)  Решение задач с помощью уравнений
Решение задач с помощью уравнений Составление словосочетаний, предложений с местоимениями. Морфологический разбор местоимения
Составление словосочетаний, предложений с местоимениями. Морфологический разбор местоимения Координатная плоскость
Координатная плоскость Типы задач на проценты
Типы задач на проценты В сказочной стране Дизайн
В сказочной стране Дизайн Угол. Виды углов
Угол. Виды углов Нахождение угла между прямой и плоскостью
Нахождение угла между прямой и плоскостью Геометрические преобразования в пространстве
Геометрические преобразования в пространстве Великие математики древности
Великие математики древности Площадь многоугольника
Площадь многоугольника Урок цифры в Республике Татарстан
Урок цифры в Республике Татарстан Центральная симметрия
Центральная симметрия Многоугольник
Многоугольник Путешествие на воздушных шарах
Путешествие на воздушных шарах Вписанная и описанная призмы. Задания
Вписанная и описанная призмы. Задания Угол. Измерение углов
Угол. Измерение углов Тела вращения
Тела вращения Сходимость несобственных интегралов первого рода от функций произвольного знака. Признак Больцано Коши. Лекция 2-13
Сходимость несобственных интегралов первого рода от функций произвольного знака. Признак Больцано Коши. Лекция 2-13 Школа олимпийского резерва. (задача)
Школа олимпийского резерва. (задача) Умножение 2 и на 2
Умножение 2 и на 2 Задача 14 на СС
Задача 14 на СС Окружность, круг и их элементы. Центральный угол
Окружность, круг и их элементы. Центральный угол Чётные и нечётные функции
Чётные и нечётные функции Умножение дробей. Анаграммы
Умножение дробей. Анаграммы Трапеция
Трапеция