Экспертная система поддержки принятия решений в оценке риска генетического бесплодия и спонтанного прерывания беременности
- Экспертная система поддержки принятия решений в оценке риска генетического бесплодия и спонтанного прерывания беременности

Содержание
- 2. Задача классифика́ции формализованная задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы. Задано
- 3. Исходные данные
- 5. Оценка риска является задачей классификации, признаковое пространство генетического бесплодия и самопроизвольного прерывания беременности представляет собой множество
- 6. Алгоритм расчета оценки риска генетического бесплодия и самопроизвольного прерывания беременности
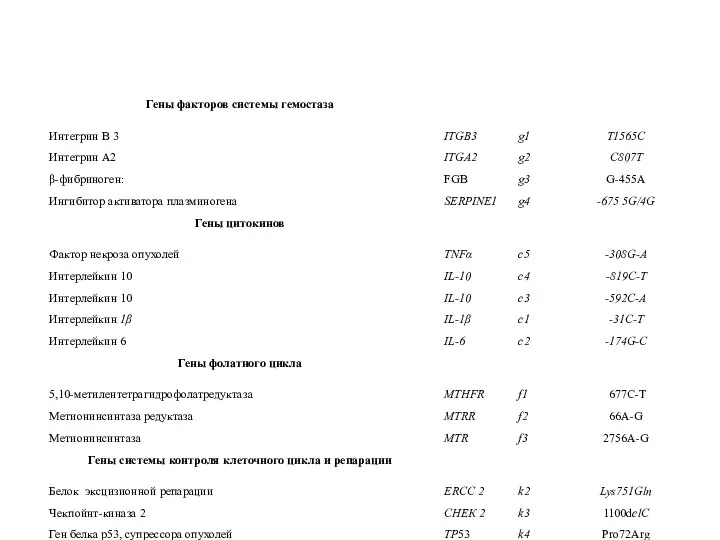
- 7. 1этап: f1(х),…, f3(х), k1(у),…, k4(у); 2 этап: g1(х),…, g4(х),c1(у),…, c5(у); 3 этап: c1(х),…, c5(х), g1(у),…, g4(у);
- 8. Ирисы Фишера Ирисы Фишера — это набор данных для задачи классификации, на примере которого Рональд Фишер
- 9. Ирисы Фишера
- 10. Диаграмма рассеяния ирисов Фишера «Anderson's Iris data set» участника Indon - собственная работа. Под лицензией CC
- 11. Диаграмма рассеяния генетического бесплодия и спонтанного прерывания беременности
- 12. Визуализация многомерных данных с помощью диаграмм Эндрюса Дэвид Эндрюс (Andrews, David F.) в 1972-м году описал
- 13. Диаграмма Эндрюса для ирисов Фишер
- 14. Анализ признаков xi в осуществляется в порядке убывания их информативности IDi (x1)> IDi(x2) > IDi(x3) >….
- 15. Данныедля построения диаграммы Парето
- 16. Вклад признаков при репродуктивных потерях
- 17. Наличие полиморфизмов в генах MTR; IL-6, iTGB3, ITGA2, MTRR, IL-10 выборка 86 выборка 241
- 18. Многослойная искусственная нейронная сеть Для решения проблемы с линейной неразделимостью образов была предложена двуслойная искусственная нейронная
- 19. Перекрестная проверка Исходное обучающее множество было перемешано и разбито на k=10 частей равного размера. Затем последовательно
- 20. Взаимодействие субъектов и компонентов экспертной системы при расчете оценки риска генетического бесплодия и спонтанного прерывания беременности
- 21. Форма ввода данных о полиморфизме генов
- 23. Скачать презентацию
Слайд 2Задача классифика́ции
формализованная задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы.
Задача классифика́ции
формализованная задача, в которой имеется множество объектов (ситуаций), разделённых некоторым образом на классы.

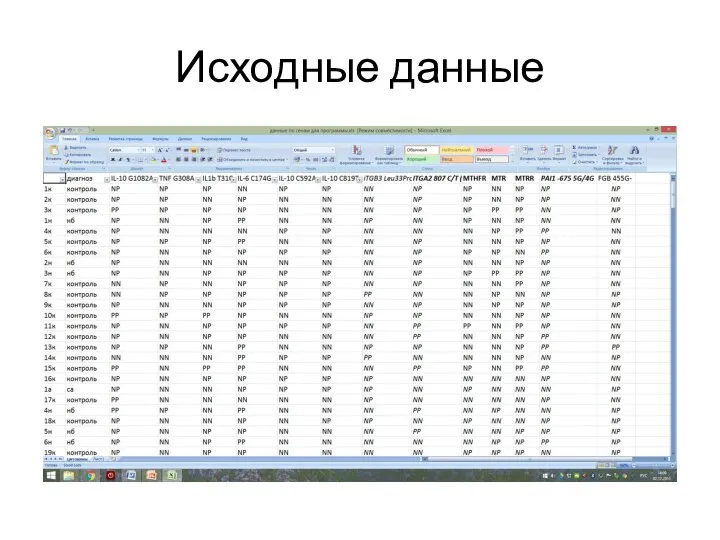
Слайд 3Исходные данные
Исходные данные
Слайд 5 Оценка риска является задачей классификации, признаковое пространство генетического бесплодия и самопроизвольного прерывания
Оценка риска является задачей классификации, признаковое пространство генетического бесплодия и самопроизвольного прерывания

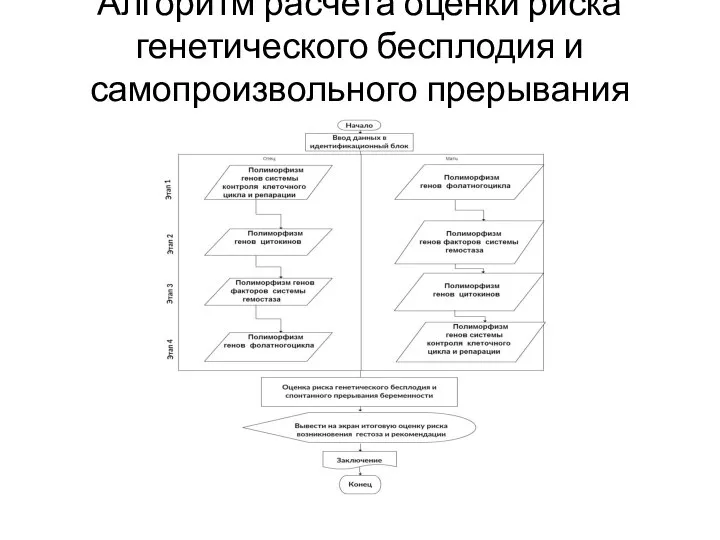
Слайд 6Алгоритм расчета оценки риска генетического бесплодия и самопроизвольного прерывания беременности
Алгоритм расчета оценки риска генетического бесплодия и самопроизвольного прерывания беременности
Слайд 71этап: f1(х),…, f3(х), k1(у),…, k4(у);
2 этап: g1(х),…, g4(х),c1(у),…, c5(у);
3 этап: c1(х),…, c5(х), g1(у),…,
1этап: f1(х),…, f3(х), k1(у),…, k4(у);
2 этап: g1(х),…, g4(х),c1(у),…, c5(у);
3 этап: c1(х),…, c5(х), g1(у),…,

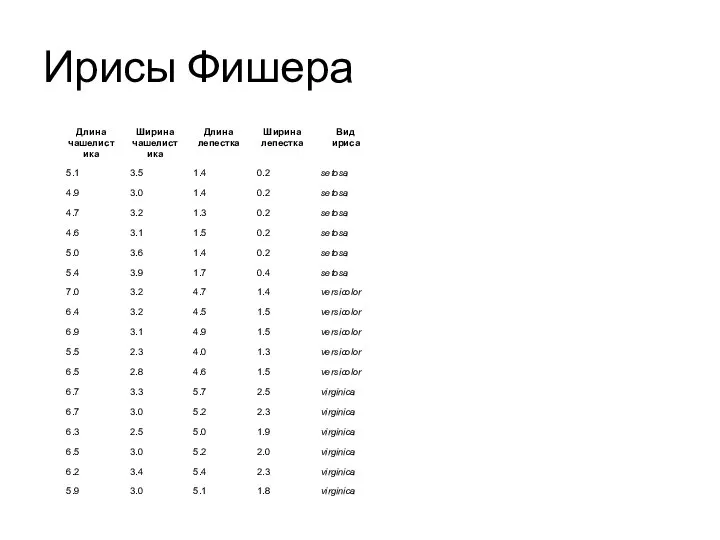
Слайд 8Ирисы Фишера
Ирисы Фишера — это набор данных для задачи классификации, на примере которого Рональд Фишер в 1936 году
Ирисы Фишера
Ирисы Фишера — это набор данных для задачи классификации, на примере которого Рональд Фишер в 1936 году

Слайд 9Ирисы Фишера
Ирисы Фишера
Слайд 10Диаграмма рассеяния
ирисов Фишера
«Anderson's Iris data set» участника Indon - собственная работа. Под
Диаграмма рассеяния
ирисов Фишера
«Anderson's Iris data set» участника Indon - собственная работа. Под

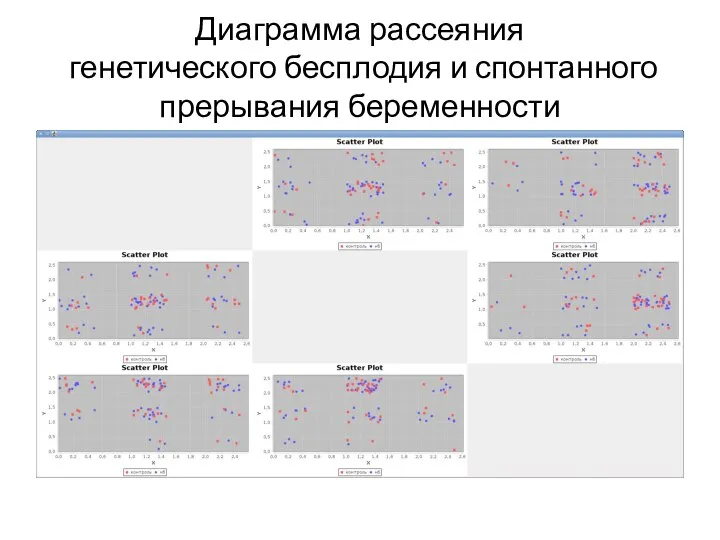
Слайд 11Диаграмма рассеяния
генетического бесплодия и спонтанного прерывания беременности
Диаграмма рассеяния
генетического бесплодия и спонтанного прерывания беременности
Слайд 12Визуализация многомерных данных с помощью диаграмм Эндрюса
Дэвид Эндрюс (Andrews, David F.) в
Визуализация многомерных данных с помощью диаграмм Эндрюса
Дэвид Эндрюс (Andrews, David F.) в

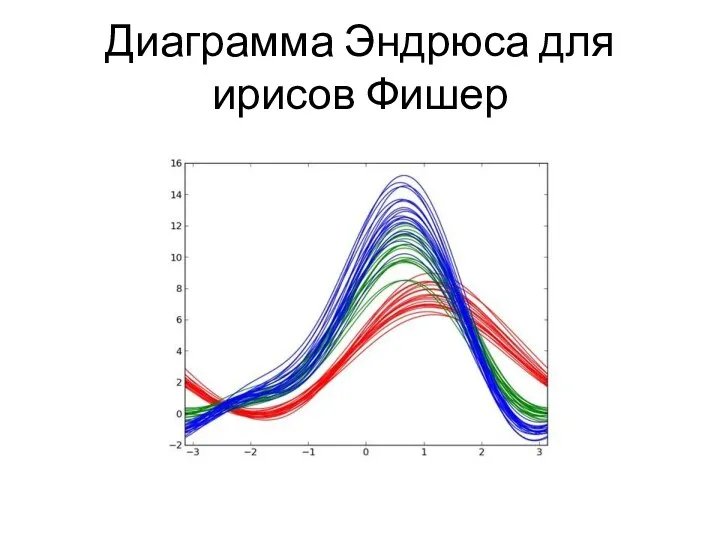
Слайд 13Диаграмма Эндрюса для ирисов Фишер
Диаграмма Эндрюса для ирисов Фишер
Слайд 14 Анализ признаков xi в осуществляется в порядке убывания их информативности
IDi (x1)>
Анализ признаков xi в осуществляется в порядке убывания их информативности
IDi (x1)>

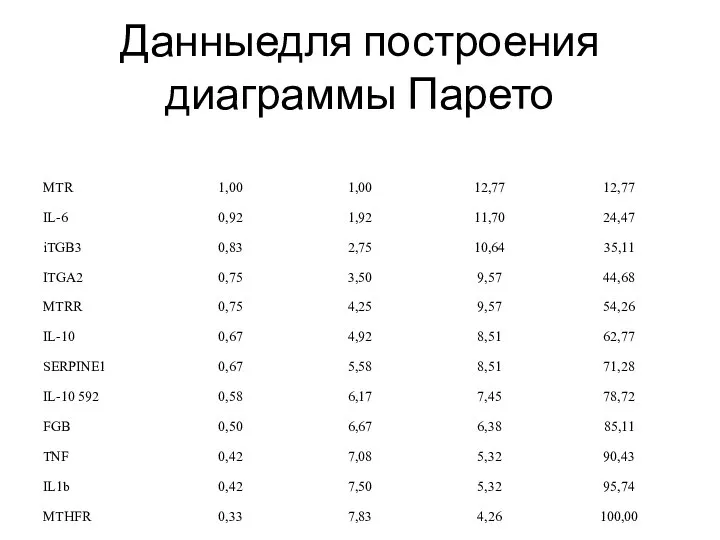
Слайд 15Данныедля построения диаграммы Парето
Данныедля построения диаграммы Парето
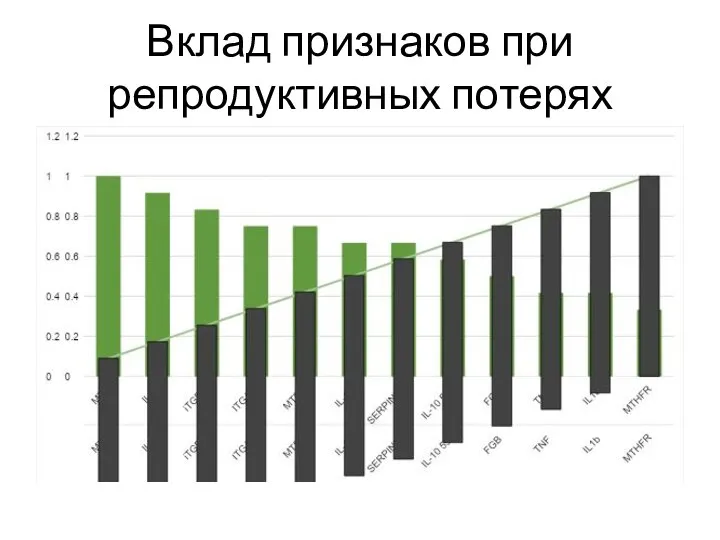
Слайд 16Вклад признаков при репродуктивных потерях
Вклад признаков при репродуктивных потерях
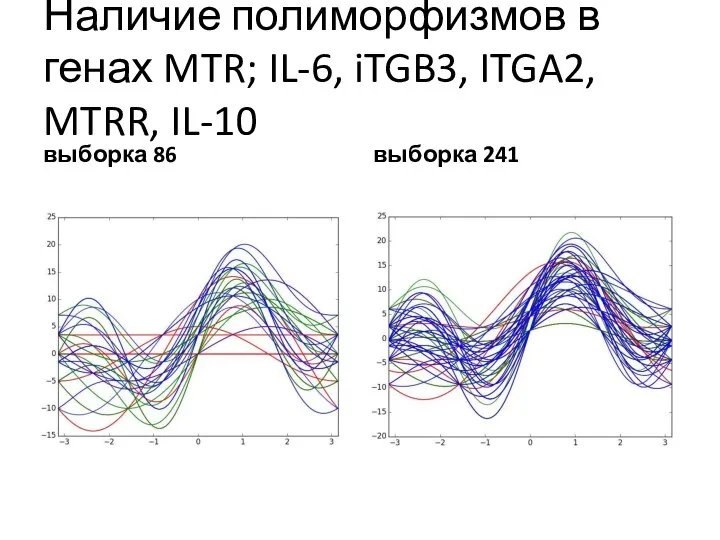
Слайд 17Наличие полиморфизмов в генах MTR; IL-6, iTGB3, ITGA2, MTRR, IL-10
выборка 86
выборка
Наличие полиморфизмов в генах MTR; IL-6, iTGB3, ITGA2, MTRR, IL-10
выборка 86
выборка
Слайд 18Многослойная искусственная нейронная сеть
Для решения проблемы с линейной неразделимостью образов была предложена
Многослойная искусственная нейронная сеть
Для решения проблемы с линейной неразделимостью образов была предложена

Слайд 19Перекрестная проверка
Исходное обучающее множество было перемешано и разбито на k=10 частей равного
Перекрестная проверка
Исходное обучающее множество было перемешано и разбито на k=10 частей равного

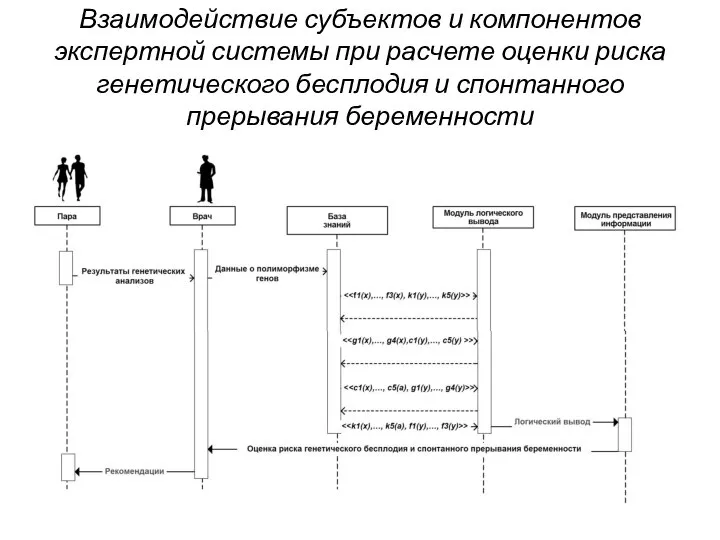
Слайд 20Взаимодействие субъектов и компонентов экспертной системы при расчете оценки риска генетического бесплодия
Взаимодействие субъектов и компонентов экспертной системы при расчете оценки риска генетического бесплодия
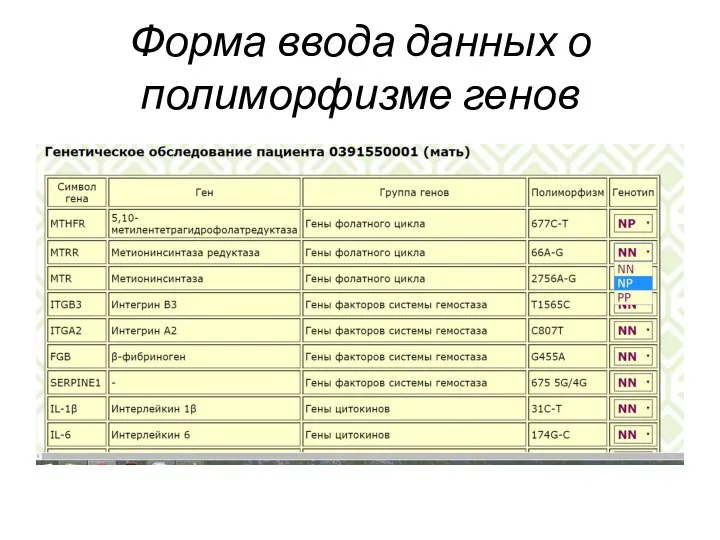
Слайд 21Форма ввода данных о полиморфизме генов
Форма ввода данных о полиморфизме генов
 Иммунитет. Активная иммунизация
Иммунитет. Активная иммунизация Розвиток професійних хвороб зумовлений впливом на організм працівників шкідливих виробничих чинників
Розвиток професійних хвороб зумовлений впливом на організм працівників шкідливих виробничих чинників Воспаление седалищного нерва
Воспаление седалищного нерва Практическое занятие. Вынос и транспортировка пострадавших из очагов поражения
Практическое занятие. Вынос и транспортировка пострадавших из очагов поражения Синдром Эдвардса
Синдром Эдвардса Внедрение в психиатрию
Внедрение в психиатрию Реабилитация пациентов, перенесших энцефалиты. Диагностика, лечение, профилактика, реабилитация
Реабилитация пациентов, перенесших энцефалиты. Диагностика, лечение, профилактика, реабилитация Анатомия стопы
Анатомия стопы Пути оттока внутриглазной жидкости из глазного яблока
Пути оттока внутриглазной жидкости из глазного яблока Реабилитация при Болезни Паркинсона
Реабилитация при Болезни Паркинсона Основные, дополнительные и вспомогательные методы диагностики АГ. Этапы диагностического поиска
Основные, дополнительные и вспомогательные методы диагностики АГ. Этапы диагностического поиска Реакция преципитации. Реакции с участием комплемента
Реакция преципитации. Реакции с участием комплемента Препятствия на пути вакцинации детей в рамках национального календаря профилактических прививок и пути их преодоления
Препятствия на пути вакцинации детей в рамках национального календаря профилактических прививок и пути их преодоления Реабилитация пациентов при заболеваниях обмена веществ, в хирургии
Реабилитация пациентов при заболеваниях обмена веществ, в хирургии Причины расхождения патологоанатомического и клинического диагноза деструктивных форм аппендицита
Причины расхождения патологоанатомического и клинического диагноза деструктивных форм аппендицита Индивидуальная и клубная работа с получателями услуг
Индивидуальная и клубная работа с получателями услуг Инфекция вируса герпеса 1-2 типа
Инфекция вируса герпеса 1-2 типа Анатомо-физиологические особенности поджелудочной железы
Анатомо-физиологические особенности поджелудочной железы Преэклампсия и эклампсия: междисциплинарные аспекты ведения беременных
Преэклампсия и эклампсия: междисциплинарные аспекты ведения беременных Бородавки. Причини появи бородавок. Види бородавок
Бородавки. Причини появи бородавок. Види бородавок Питание при беременности
Питание при беременности Сатурация кислорода в смешанной венозной крови
Сатурация кислорода в смешанной венозной крови Несахарный диабет
Несахарный диабет Фетоплацентарная недостаточность. Диагностика. Лечение
Фетоплацентарная недостаточность. Диагностика. Лечение Сестринский процесс при инсульте в остром периоде и в периоде реабилитации
Сестринский процесс при инсульте в остром периоде и в периоде реабилитации Бешенство
Бешенство Какие используются варианты патогенеза РДА
Какие используются варианты патогенеза РДА Биометрия 002
Биометрия 002