- Концептуальный анализ текстов

Содержание
- 2. 1.Разработать новые методы, алгоритмы и технологии решения задачи создания декларативных средств для автоматической кластеризации текстовых документов
- 3. Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла устойчивых фразеологических и терминологических
- 4. Основные технологии автоматической обработки неструктурированной текстовой информации 1.Технологии создание декларативных средств по тематическому корпусу текстов. 3.Технологии
- 5. Формально-логический контроль текста Морфологический анализ Семантико-синтаксический анализ Концептуальный анализ Дистрибутивно-статистический анализ Автоматическое смысловое структурирование документов на
- 6. Концепция установления смысловой близости фрагментов документов В качестве базовой теоретической концепции использовалась концепция фразеологического концептуального анализа
- 7. В связном тексте предложения выступают в тесной смысловой связи. В основе этой связи лежат мыслительные образы
- 8. Преобразование текстового представления в его формализованное смысловое представление дает возможность сопоставления текстов по их смысловому содержанию.
- 9. Выделение наименований понятий выполняется на этапе концептуального анализа текстов Концептуальный анализ текстов - это лингвистическая процедура,
- 10. Фрагмент частотного словаря синтаксических структур словосочетаний в словаре ЭКС
- 11. 1.Идея алгоритма: если некоторому отрезку текста соответствует в эталонном словаре хотя бы одно наименование понятия, имеющее
- 12. Шаг 1. Членение входного текста на предложения; Шаг 2. Морфологический анализ текста; Шаг 3. Пословная нормализация
- 13. 1.Идея алгоритма: если известна информация о длине словосочетания и о всех словах, входящих в состав этих
- 14. Шаг 1. Членение входного текста на предложения; Шаг 2. Морфологический анализ текста; Шаг 3. Пословная нормализация
- 15. 1.Идея алгоритма: если некоторому отрезку текста соответствует в эталонном словаре хотя бы одно наименование понятия, имеющее
- 16. Шаг 1. Членение входного текста на предложения; Шаг 2. Морфологический анализ текста; Шаг 3. Пословная нормализация
- 17. 1.Идея алгоритма: если сформированной последовательности обобщенных символов грамматических классов слов некоторого отрезка текста соответствует какой-либо элемент
- 18. Шаг 7. Поиск синтаксических структур, построенных по фрагментам текста, в эталонном словаре обобщенных синтагм; Шаг 8.
- 19. 1.Идея алгоритма: если фрагменту сформированной последовательности обобщенных синтагм предложения соответствует какой-либо элемент словаря обобщенных синтагм, представляющий
- 20. Шаг 1. Членение входного текста на предложения; Шаг 2. Морфологический анализ текста; Шаг 3. Построение синтаксического
- 21. Результаты работы алгоритм №4 (выделения словосочетаний основе обобщенных синтагм)
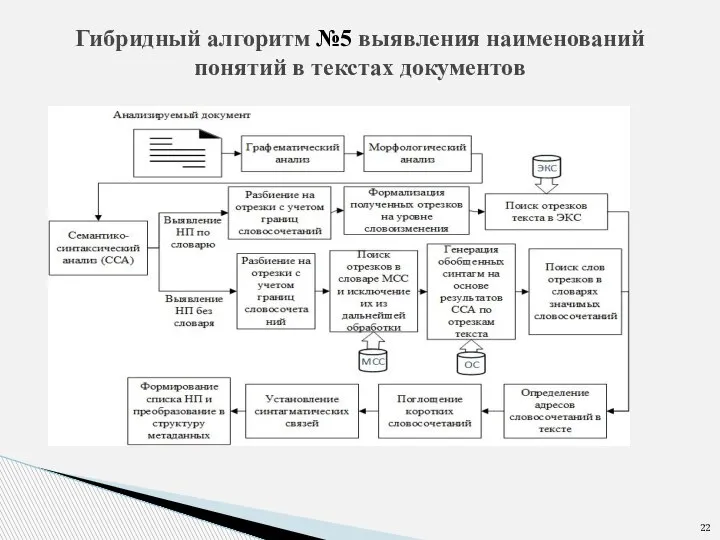
- 22. Гибридный алгоритм №5 выявления наименований понятий в текстах документов
- 23. Кол. Документов в массиве = 3 004 документов Всего слов в массиве документов= 523 810 слов
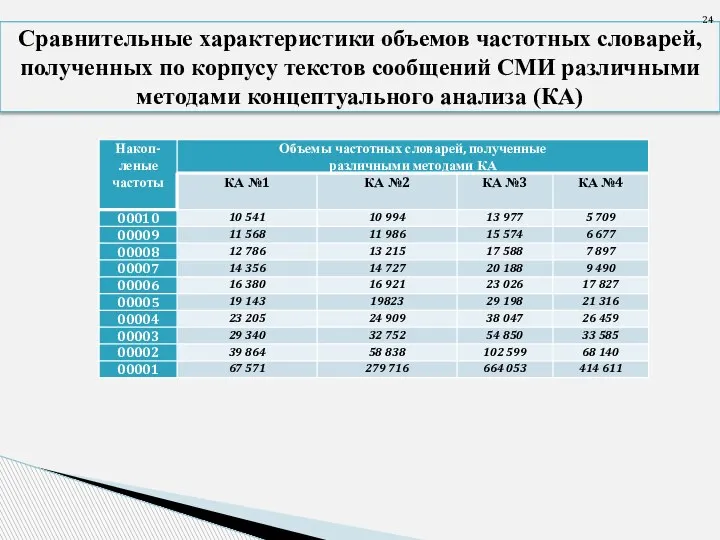
- 24. Сравнительные характеристики объемов частотных словарей, полученных по корпусу текстов сообщений СМИ различными методами концептуального анализа (КА)
- 25. Для реализации статистической меры TF-IDF ( TF — term frequency, IDF — inverse document frequency) и
- 26. 00000084 глава государство * Глава государства 00000084 чемпионат мир * Чемпионат Мира 00000065 русский язык *
- 27. Doc-934.t = 0003 Олимпийские игры в Лондоне / 0002 двукратный олимпийский чемпион / 0003 Ильин /
- 28. Кол.док.=00036 Понятие - «неправительственная организация» *1342.t*1347.t*1353.t*1358.t *1367.t *1369.t *1374.t *1398.t *1442.t *1456.t *1499.t *1543.t *1547.t *1554.t
- 29. Объем сокращенного частотного словаря (полученного по словарю ЭКС)=23 205 Объем частного словаря разных главных слов словосочетаний
- 30. Родовое понятие =«спорт*4208.00» Видовые понятия = спорт велосипедный - велосипедный спорт *4208.01 спорт высших достижений -
- 31. 00002 спортивная машина *1994.00 *1994.09 00002 спортивная команда *1624.00 *1624.07 00002 спортивная карьера *1519.00 *1519.08 00002
- 32. 00001 являлся *9878.00 00001 являлся аграрным донором *9878.00 *9878.01 00001 являлся акционером этой компании *9878.00 *9878.02
- 33. 1.Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для автоматической кластеризации текстовых документов
- 35. Скачать презентацию
Слайд 21.Разработать новые методы, алгоритмы и технологии решения задачи создания декларативных средств для
1.Разработать новые методы, алгоритмы и технологии решения задачи создания декларативных средств для

Слайд 3Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла
Основной идеей этой концепции является обоснование использования в качестве основных единиц смысла

Слайд 4 Основные технологии автоматической обработки неструктурированной текстовой информации
1.Технологии создание декларативных средств по
Основные технологии автоматической обработки неструктурированной текстовой информации
1.Технологии создание декларативных средств по

Слайд 5Формально-логический контроль текста
Морфологический анализ
Семантико-синтаксический анализ
Концептуальный анализ
Дистрибутивно-статистический анализ
Автоматическое смысловое структурирование документов на предложения
Формально-логический контроль текста
Морфологический анализ
Семантико-синтаксический анализ
Концептуальный анализ
Дистрибутивно-статистический анализ
Автоматическое смысловое структурирование документов на предложения

Слайд 6Концепция установления смысловой близости фрагментов документов
В качестве базовой теоретической концепции использовалась концепция
Концепция установления смысловой близости фрагментов документов
В качестве базовой теоретической концепции использовалась концепция

Слайд 7В связном тексте предложения выступают в тесной смысловой связи. В основе этой
В связном тексте предложения выступают в тесной смысловой связи. В основе этой

Слайд 8Преобразование текстового представления в его формализованное смысловое представление дает возможность сопоставления текстов
Преобразование текстового представления в его формализованное смысловое представление дает возможность сопоставления текстов

Слайд 9Выделение наименований понятий выполняется на этапе концептуального анализа текстов
Концептуальный анализ текстов -
Выделение наименований понятий выполняется на этапе концептуального анализа текстов
Концептуальный анализ текстов -

Слайд 10Фрагмент частотного словаря синтаксических структур словосочетаний в словаре ЭКС
Фрагмент частотного словаря синтаксических структур словосочетаний в словаре ЭКС

Слайд 111.Идея алгоритма: если некоторому отрезку текста соответствует в эталонном словаре хотя бы

Слайд 12Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.
Шаг 2. Морфологический анализ текста;
Шаг 3.

Слайд 131.Идея алгоритма: если известна информация о длине словосочетания и о всех словах,

Слайд 14Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.
Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.

Слайд 151.Идея алгоритма: если некоторому отрезку текста соответствует в эталонном словаре хотя бы

Слайд 16Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.
Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.

Слайд 171.Идея алгоритма: если сформированной последовательности обобщенных символов грамматических классов слов некоторого отрезка

Слайд 18Шаг 7. Поиск синтаксических структур, построенных по фрагментам текста, в эталонном словаре

Слайд 191.Идея алгоритма: если фрагменту сформированной последовательности обобщенных синтагм предложения соответствует какой-либо элемент

Слайд 20Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.
Шаг 1. Членение входного текста на предложения;
Шаг 2. Морфологический анализ текста;
Шаг 3.

Слайд 21Результаты работы алгоритм №4 (выделения словосочетаний основе обобщенных синтагм)
Результаты работы алгоритм №4 (выделения словосочетаний основе обобщенных синтагм)

Слайд 22Гибридный алгоритм №5 выявления наименований понятий в текстах документов
Гибридный алгоритм №5 выявления наименований понятий в текстах документов
Слайд 23Кол. Документов в массиве = 3 004 документов
Всего слов в массиве документов=
Всего слов в массиве документов=

Слайд 24Сравнительные характеристики объемов частотных словарей, полученных по корпусу текстов сообщений СМИ различными
Сравнительные характеристики объемов частотных словарей, полученных по корпусу текстов сообщений СМИ различными
Слайд 25Для реализации статистической меры TF-IDF ( TF — term frequency, IDF — inverse document frequency) и ряда подобных

Слайд 2600000084 глава государство * Глава государства
00000084 чемпионат мир * Чемпионат Мира
00000065 русский
00000084 глава государство * Глава государства
00000084 чемпионат мир * Чемпионат Мира
00000065 русский

Слайд 27Doc-934.t = 0003 Олимпийские игры в Лондоне / 0002 двукратный олимпийский чемпион

Слайд 28Кол.док.=00036 Понятие - «неправительственная организация» *1342.t*1347.t*1353.t*1358.t *1367.t *1369.t *1374.t *1398.t *1442.t *1456.t

Слайд 29Объем сокращенного частотного словаря (полученного по словарю ЭКС)=23 205 Объем частного словаря

Слайд 30Родовое понятие =«спорт*4208.00»
Видовые понятия =
спорт велосипедный - велосипедный спорт *4208.01
спорт высших достижений
Родовое понятие =«спорт*4208.00»
Видовые понятия =
спорт велосипедный - велосипедный спорт *4208.01
спорт высших достижений

Слайд 3100002 спортивная машина *1994.00 *1994.09
00002 спортивная команда *1624.00 *1624.07
00002 спортивная карьера *1519.00
00002 спортивная машина *1994.00 *1994.09
00002 спортивная команда *1624.00 *1624.07
00002 спортивная карьера *1519.00

Слайд 3200001 являлся *9878.00
00001 являлся аграрным донором *9878.00 *9878.01
00001 являлся акционером этой компании
00001 являлся *9878.00
00001 являлся аграрным донором *9878.00 *9878.01
00001 являлся акционером этой компании

Слайд 331.Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для
1.Разработаны новые методы, алгоритмы и технологии решения задачи создания декларативных средств для

 Пишем эссе по обществознанию
Пишем эссе по обществознанию Общее понятие о морфемике
Общее понятие о морфемике Сочинение рассуждение
Сочинение рассуждение У Кондрата куртка коротковата
У Кондрата куртка коротковата Сложноподчинённые предложения с придаточными изъяснительными и определительными
Сложноподчинённые предложения с придаточными изъяснительными и определительными Речевые ошибки
Речевые ошибки Аудиодиктант. Прогулка в лесу
Аудиодиктант. Прогулка в лесу Корень слова
Корень слова 1 класс Пропись №3 Автор: М.М. Безруких, М.И. Кузнецова.
1 класс Пропись №3 Автор: М.М. Безруких, М.И. Кузнецова. Употребление параллельной связи с повтором
Употребление параллельной связи с повтором Не с глаголами
Не с глаголами Читаем, играем, говорим
Читаем, играем, говорим Словарь иносказательных слов по сказу Н.С. Лескова Левша
Словарь иносказательных слов по сказу Н.С. Лескова Левша Текст
Текст Приставочные глаголы
Приставочные глаголы Причастие. Морской бой
Причастие. Морской бой Презентация на тему Правописание Н и НН в прилагательных, образованных от существительных
Презентация на тему Правописание Н и НН в прилагательных, образованных от существительных  Функциональные стили речи (1)
Функциональные стили речи (1) Деловое общение
Деловое общение Способы и средства связи предложений в тексте
Способы и средства связи предложений в тексте Знаки препинания в сложных предложениях. Обобщение. 9 класс
Знаки препинания в сложных предложениях. Обобщение. 9 класс Пособие по логопедии Звук Р
Пособие по логопедии Звук Р Статус русского языка
Статус русского языка Презентация "Причастие Повторение и обобщение изученного" - скачать презентации по Русскому языку
Презентация "Причастие Повторение и обобщение изученного" - скачать презентации по Русскому языку Правописание приставок ПРИ - и ПРЕ-
Правописание приставок ПРИ - и ПРЕ- Презентация на тему Сложноподчинённое предложение 9 класс
Презентация на тему Сложноподчинённое предложение 9 класс  Местоимения с предлогами
Местоимения с предлогами Форма 2 генетив
Форма 2 генетив