- Анатолий Свириденков (сodedgers.com) Блог: http://bit.ly/cuda_blog

Содержание
- 2. Проблематика Где нужна вычислительная мощность: - Ускорение вычислений - Переход в реальное время - Разгрузка CPU
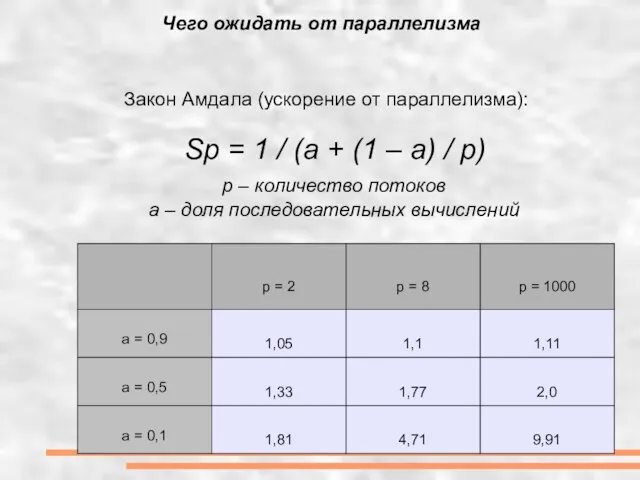
- 3. Чего ожидать от параллелизма Закон Амдала (ускорение от параллелизма): Sp = 1 / (a + (1
- 4. - Параллелизм данных, DPL: MMX, SSE, и т. д. - Параллелизм кода, IPL: спекулятивные вычисления и
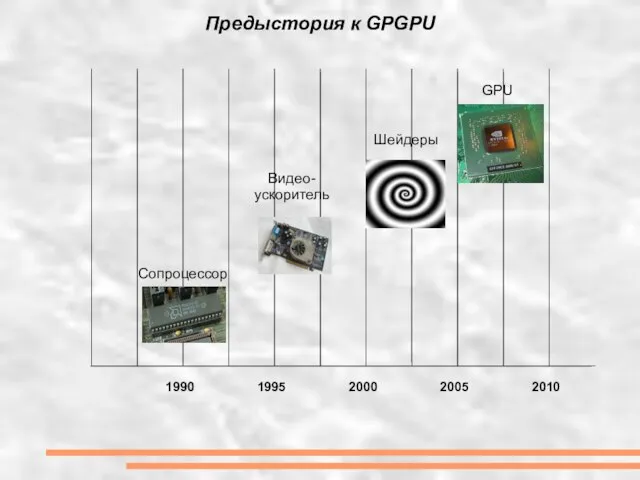
- 5. Предыстория к GPGPU 1990 1995 2000 2005 2010 Сопроцессор Видео- ускоритель Шейдеры GPU
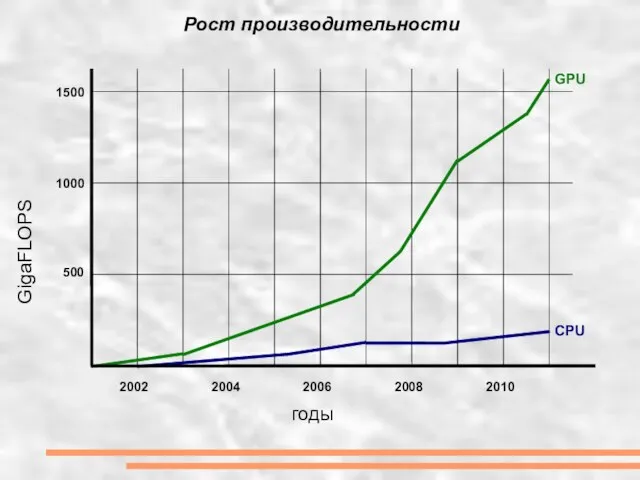
- 6. Рост производительности GigaFLOPS годы 500 1000 1500 2002 2004 2006 2008 2010 GPU CPU
- 7. Терминология - host - CPU - device - GPU - ядро — код запускаемого на GPU
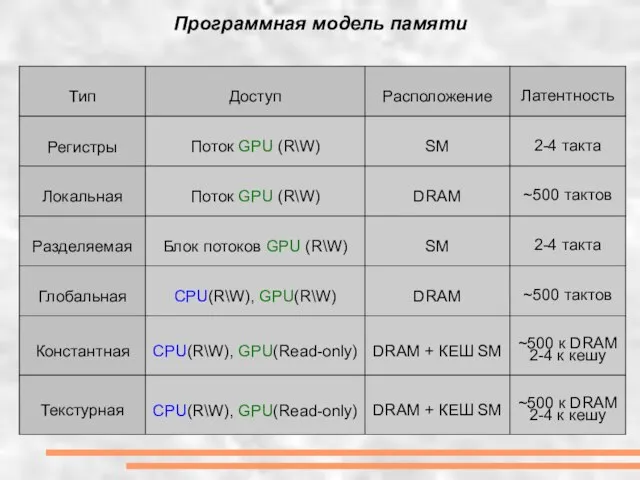
- 8. Программная модель памяти
- 9. Программная модель потоков B (0:0) B (0:1) B (0:2) B (0:3) B (1:0) B (1:1) B
- 10. Особенности программирования - функция ядро возвращает только void - память — узкое место в вычисленях и
- 11. Программный стек CUDA Device Host CUDA Driver CUDA Driver API CUDA Runtime API Libraries Application
- 12. Последняя версия CUDA Toolkit 4.0 RC2 - https://nvdeveloper.nvidia.com Состав: - Драйвер для разработчиков - GPU Computing
- 13. Самый важный параметр: --help (-help) — печатает справку Основные выходные форматы (и ключи компиляции): --cubin (-cubin)
- 14. Типы функций - по умолчанию все функции __host__ - __host__ и __device__ совместимы, компилятор создаст две
- 15. Hello World! Сложение массивов. #define N 1024 // GPU __global__ void sum(float *c, float *a, float
- 16. Hello World! CPU инициализация int main(int argc, char **argv) { float *a, *b, *c; float *A,
- 17. Hello World! CPU вызов ядра cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(B, b, N * sizeof(float),
- 18. Hello World! CPU вызов ядра cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(B, b, N * sizeof(float),
- 19. Hello World! CPU вызов ядра cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(B, b, N * sizeof(float),
- 20. Hello World! CPU вызов ядра cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(B, b, N * sizeof(float),
- 21. GPGPU прочее DirectCompute — библиотека от Microsoft. Часть DirectX; OpenCL — кроссплатформенная библиотека; Готовые библиотеки с
- 22. OpenCV #include #include "opencv2/opencv.hpp" #include "opencv2/gpu/gpu.hpp" int main (int argc, char* argv[]) { cv::gpu::GpuMat dst, src
- 24. Скачать презентацию
Слайд 2Проблематика
Где нужна вычислительная мощность:
- Ускорение вычислений
- Переход в реальное время
Проблематика
Где нужна вычислительная мощность:
- Ускорение вычислений
- Переход в реальное время

Слайд 3Чего ожидать от параллелизма
Закон Амдала (ускорение от параллелизма):
Sp = 1 /
Чего ожидать от параллелизма
Закон Амдала (ускорение от параллелизма):
Sp = 1 /
Слайд 4- Параллелизм данных, DPL: MMX, SSE, и т. д.
- Параллелизм кода, IPL:
- Параллелизм кода, IPL:

Слайд 5Предыстория к GPGPU
1990
1995
2000
2005
2010
Сопроцессор
Видео- ускоритель
Шейдеры
GPU
Предыстория к GPGPU
1990
1995
2000
2005
2010
Сопроцессор
Видео- ускоритель
Шейдеры
GPU
Слайд 6Рост производительности
GigaFLOPS
годы
500
1000
1500
2002
2004
2006
2008
2010
GPU
CPU
Рост производительности
GigaFLOPS
годы
500
1000
1500
2002
2004
2006
2008
2010
GPU
CPU
Слайд 7Терминология
- host - CPU
- device - GPU
- ядро —
Терминология
- host - CPU
- device - GPU
- ядро —

Слайд 8Программная модель памяти
Программная модель памяти
Слайд 9Программная модель потоков
B (0:0)
B (0:1)
B (0:2)
B (0:3)
B (1:0)
B (1:1)
B (1:2)
B (1:3)
B (2:0)
B
Программная модель потоков
B (0:0)
B (0:1)
B (0:2)
B (0:3)
B (1:0)
B (1:1)
B (1:2)
B (1:3)
B (2:0)
B
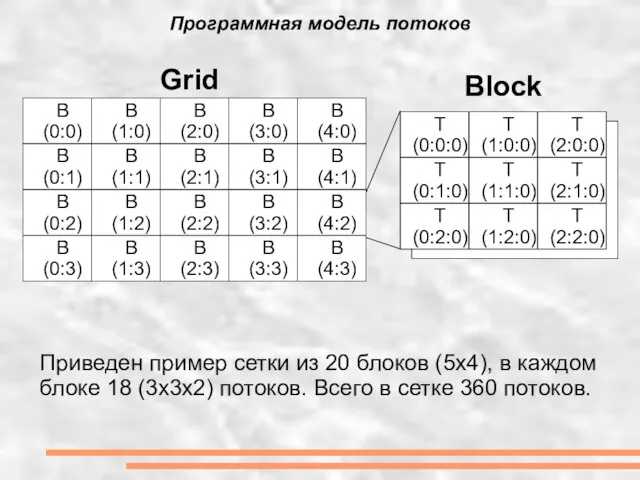
Слайд 10Особенности программирования
- функция ядро возвращает только void
- память — узкое
Особенности программирования
- функция ядро возвращает только void
- память — узкое

Слайд 11Программный стек CUDA
Device
Host
CUDA Driver
CUDA Driver API
CUDA Runtime API
Libraries
Application
Программный стек CUDA
Device
Host
CUDA Driver
CUDA Driver API
CUDA Runtime API
Libraries
Application
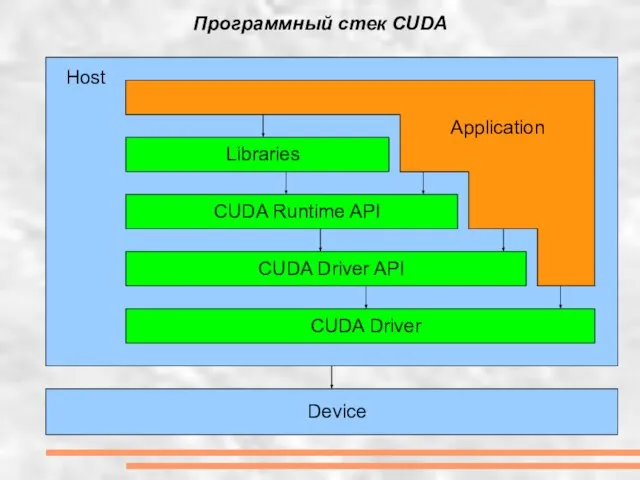
Слайд 12Последняя версия CUDA Toolkit 4.0 RC2
- https://nvdeveloper.nvidia.com
Состав:
- Драйвер для разработчиков
Последняя версия CUDA Toolkit 4.0 RC2
- https://nvdeveloper.nvidia.com
Состав:
- Драйвер для разработчиков

Слайд 13Самый важный параметр:
--help (-help) — печатает справку
Основные выходные форматы (и ключи компиляции):
Самый важный параметр:
--help (-help) — печатает справку
Основные выходные форматы (и ключи компиляции):

Слайд 14Типы функций
- по умолчанию все функции __host__
- __host__ и __device__
Типы функций
- по умолчанию все функции __host__
- __host__ и __device__
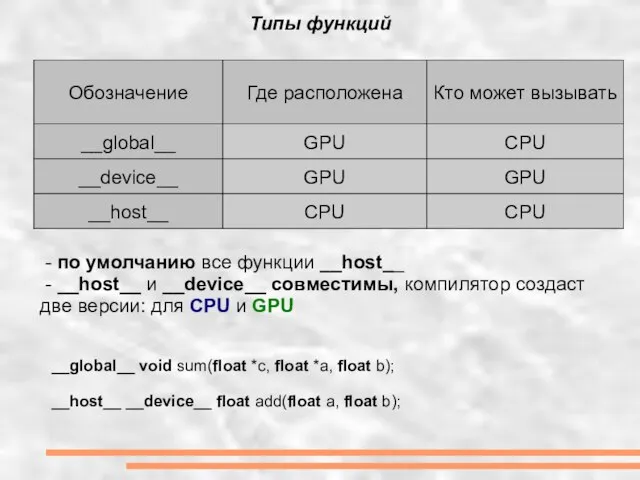
Слайд 15Hello World! Сложение массивов.
#define N 1024
// GPU
__global__ void sum(float *c, float *a, float
Hello World! Сложение массивов.
#define N 1024
// GPU
__global__ void sum(float *c, float *a, float

Слайд 16Hello World! CPU инициализация
int main(int argc, char **argv)
{
float *a, *b, *c;
Hello World! CPU инициализация
int main(int argc, char **argv)
{
float *a, *b, *c;

Слайд 17Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,
Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,

Слайд 18Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,
Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,

Слайд 19Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,
Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,

Слайд 20Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,
Hello World! CPU вызов ядра
cudaMemcpy(A, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B,

Слайд 21 GPGPU прочее
DirectCompute — библиотека от Microsoft. Часть DirectX;
OpenCL — кроссплатформенная библиотека;
Готовые
GPGPU прочее
DirectCompute — библиотека от Microsoft. Часть DirectX;
OpenCL — кроссплатформенная библиотека;
Готовые

Слайд 22OpenCV
#include
#include "opencv2/opencv.hpp"
#include "opencv2/gpu/gpu.hpp"
int main (int argc, char* argv[])
{
cv::gpu::GpuMat dst, src
OpenCV
#include
#include "opencv2/opencv.hpp"
#include "opencv2/gpu/gpu.hpp"
int main (int argc, char* argv[])
{
cv::gpu::GpuMat dst, src
![OpenCV #include #include "opencv2/opencv.hpp" #include "opencv2/gpu/gpu.hpp" int main (int argc, char* argv[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/474589/slide-21.jpg)
 Динамические методы оценки эффективности инвестиционных проектов (NPV, IRR)
Динамические методы оценки эффективности инвестиционных проектов (NPV, IRR) История арифметической и геометрической прогрессий
История арифметической и геометрической прогрессий Читать человека с первого взгляда. Чакры
Читать человека с первого взгляда. Чакры День Государственного флага Донецкой Народной Республики
День Государственного флага Донецкой Народной Республики Роль международного разделения труда в системе современной мировой экономики и международных экономических отношений
Роль международного разделения труда в системе современной мировой экономики и международных экономических отношений  Квадратные уравнения
Квадратные уравнения Каждый голос имеет значение Как надёжно подготовить сайт к нашествию посетителей
Каждый голос имеет значение Как надёжно подготовить сайт к нашествию посетителей modal_verbs_game_4_teacher_switcher
modal_verbs_game_4_teacher_switcher «Развитие детей в театрализованной деятельности» Музыкальный руководитель: Ахизова Елена Михайловна
«Развитие детей в театрализованной деятельности» Музыкальный руководитель: Ахизова Елена Михайловна Учебно-методический комплекс (УМК) по дисциплине «Инженерная и компьютерная графика»
Учебно-методический комплекс (УМК) по дисциплине «Инженерная и компьютерная графика» Презентация Выпускной
Презентация Выпускной ЧЕХОСЛОВАЦКИЕ ВОЕННЫЕ ФОРМИРОВАНИЯ В РОССИИ (1914-1920 ГГ.)Презентация магистерской работы Габрусевича С.А.
ЧЕХОСЛОВАЦКИЕ ВОЕННЫЕ ФОРМИРОВАНИЯ В РОССИИ (1914-1920 ГГ.)Презентация магистерской работы Габрусевича С.А. Анимализм в Англии XVIII в. Творчество Томаса Гейнсборо
Анимализм в Англии XVIII в. Творчество Томаса Гейнсборо Презентация на тему Жизнь и творчество Ломоносова
Презентация на тему Жизнь и творчество Ломоносова Датчик уровня наполненности
Датчик уровня наполненности ИНФОРМАЦИОНН ОЕОБЕСПЕЧЕНИЕ ИС
ИНФОРМАЦИОНН ОЕОБЕСПЕЧЕНИЕ ИС Изображение человека в движении. Эскиз модели
Изображение человека в движении. Эскиз модели Красота человека
Красота человека 984967
984967 История ЭВМ Автор: Николаева О. А.МОУ СОШ № 4 п. Хинганск
История ЭВМ Автор: Николаева О. А.МОУ СОШ № 4 п. Хинганск Первый раз, в первый класс!
Первый раз, в первый класс! Система мотивации продавцов
Система мотивации продавцов Инженер по эксплуатации железных дорог
Инженер по эксплуатации железных дорог Родник "Горный хрусталь"
Родник "Горный хрусталь" Для меня жизнь – Христос
Для меня жизнь – Христос функції мови
функції мови Презентация на тему Театр и музыка Античности
Презентация на тему Театр и музыка Античности Аттестационная работа. Проектная и исследовательская деятельность как способ формирования метапредметных результатов обучения
Аттестационная работа. Проектная и исследовательская деятельность как способ формирования метапредметных результатов обучения