- Пять парадигм параллельного программирования

Содержание
- 2. Основные разделы Что такое параллельная программа? Пять стилей параллельного программирования Ноутбук как симметричная мультипроцессорная система (SMP)
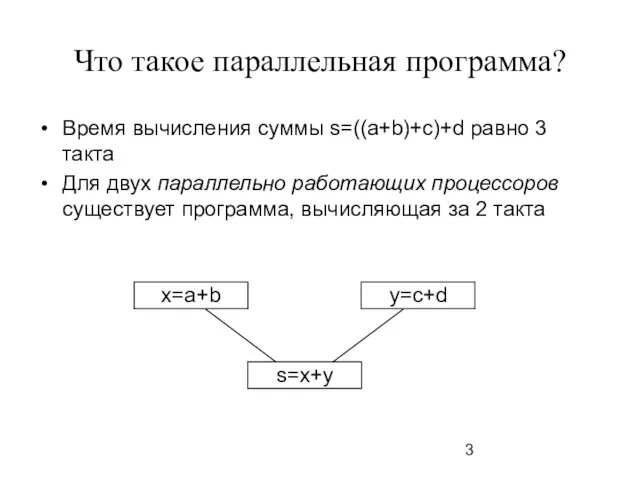
- 3. Что такое параллельная программа? Время вычисления суммы s=((a+b)+c)+d равно 3 такта Для двух параллельно работающих процессоров
- 4. Пять стилей параллельного программирования Итеративный параллелизм Рекурсивный параллелизм Производители и потребители Клиенты и серверы Взаимодействующие каналы
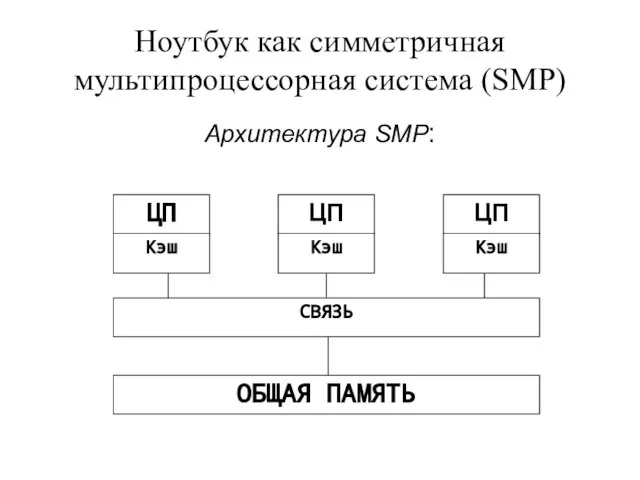
- 5. Ноутбук как симметричная мультипроцессорная система (SMP) Архитектура SMP:
- 6. Как писать параллельные программы? 1. Разрабатываются подпрограммы, которые могут выполняться независимо. Например, для метода трассировки лучей
- 7. Как писать параллельные программы? Эта подпрограмма всегда имеет один аргумент типа (void *). Если подпрограмма имеет
- 8. Как писать параллельные программы? Например: struct arg { int ithr ; … }; DWORD WINAPI Part(void
- 9. Итеративный параллелизм и семафоры Метод трассировки лучей реализуется с помощью цикла, в котором на каждом шаге
- 10. Итеративный параллелизм и семафоры
- 11. Итеративный параллелизм и семафоры Для того, чтобы исправить это, введем Определение. Семафором Дейкстры называется структура данных,
- 12. Итеративный параллелизм и семафоры
- 13. Итеративный параллелизм и семафоры Пример программы, в которой решается проблема сериализации. Рассмотрим задачу вычисления интеграла равного
- 14. Итеративный параллелизм и семафоры Напишем главную программу main() { int i; int p[n]; for(i=0; i mut
- 15. Математическое моделирование параллельных вычислительных систем При синхронизации работы потоков с помощью семафоров возникают проблемы, связанные с
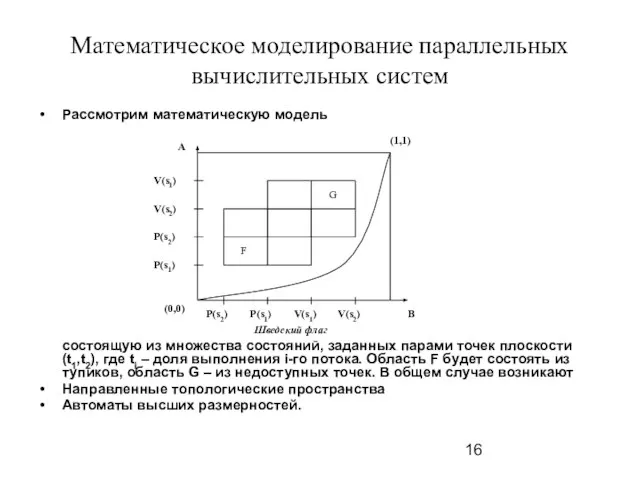
- 16. Математическое моделирование параллельных вычислительных систем Рассмотрим математическую модель состоящую из множества состояний, заданных парами точек плоскости
- 17. Математическое моделирование параллельных вычислительных систем Категория состоит из объектов A,B,C, … и морфизмов , , ,
- 18. Математическое моделирование параллельных вычислительных систем Пусть U: A →B - функтор. Объект A называется универсальным для
- 19. Полукубические множества
- 20. Полукубические множества
- 21. Моноиды трасс и вычислительные процессы Что такое вычислительный процесс? Рассмотрим вычислительную систему, состоящую из операций Определение.
- 22. Моноиды трасс и полукубические множества Теорема 1. Каждому полукубическому множеству с выделенной вершиной соответствует универсальный моноид
- 23. Рекурсивный параллелизм Метод сдваивания int sum(int l, int r) // x[l] + … + x[r] {
- 24. Рекурсивный параллелизм Данные и структура параметров int x[100]; struct arg {int l, r, res}; Вызываемый поток
- 25. Рекурсивный параллелизм Рекурсивный параллелизм применяется для распараллеливания алгоритма перебора с возвратом И.А. Трещев установил в программе
- 26. Конвейерные системы Рассмотрим вычислительную систему для вычисления суммы векторов. Она состоит из 5 микроопераций Comp(a,b) –
- 27. Конвейерные системы Ускорение S5=T1/T5=5nh/((n+4)h) ≈ 5
- 28. Производители и потребители: каналы template class channel { Type *buf; // буфер для очереди int size;
- 29. Производители и потребители: каналы С помощью каналов можно реализовать конвейерные системы. Блок конвейера DWORD WINAPI name_op(void
- 30. Клиент-сервер: задача о читателях и писателях Процессы читают и редактируют файл Имеющие право на чтение –
- 31. Асинхронные системы T=(S,s0,E,I,Tran) S – множество состояний, s0∈ S – начальное состояние, E – множество событий,
- 32. Асинхронные системы a – читатель поступил доступ b – читатель закончил работу с файлом c –
- 33. Асинхронные системы и кубические множества Теорема 2. Каждой асинхронной системе соответствует некоторое кубическое множество. И наоборот,
- 34. Асинхронные системы и кубические множества Асинхронным системам соответствуют также полиэдры – топологические пространства, склеенные из точек,
- 35. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 36. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 37. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 38. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 39. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 40. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 41. Взаимодействующие каналы Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
- 42. Взаимодействующие каналы Каналы, соответствующие местам channel *pc[11]; Подпрограмма потока DWORD WINAPI mult(LPVOID) // поток для умножения
- 43. Взаимодействующие каналы Полученные «асинхронные систолические системы» называются волновыми системами Более точная математическая модель волновой системы, чем
- 44. Сети Петри и асинхронные системы Пример a b c a b c p0 p1 M(E,I)= 〈a,b,c|
- 45. Топология – «резиновая» геометрия (изучает инварианты гомеоморфизмов) Каждой дырке соответствует цикл, не являющийся границей подобласти. В
- 46. Числа Бетти. Резиновый мяч. Любой 1-мерный цикл является границей поверхности, содержащейся в области {(x,y,z): r2 ≤
- 47. Числа Бетти Сn= L{(x0,x1, …, xn) – симплекс: x0 Zn=dn-1(0), Bn=dn+1Cn+1 Hn=Zn/Bn βn=dim Cn- r(dn)-r(dn+1) Разбиваем
- 48. Числа Бетти . β0=3-0-r(d1)=3-2=1, β1=3-r(d1)-0=1 2-цепей нет ⇒ цикл 01+12-02 ≠ 0
- 49. Вычисление чисел Бетти βn= dim Cn – r( dn )– r (dn+1) С0 = L{0,1,2,3} ≈
- 50. Числа Бетти полукубических множеств d1= d2=
- 51. Числа Бетти асинхронных систем S0=S∪{*}, S1={(s,e1): s∈S0,e1 ∈E}, … , Sn= {(s, e1 , …, en):
- 52. Числа Бетти асинхронных систем rk d1 = 3 β0=4-3=1 , β 1=8-3-3=2 , β 2=4-3=1 rk
- 53. Числа Бетти асинхронных систем 28 октября (четверг), в 12.00, в 201/3 состоится защита диссертации В.Е. Лопаткина
- 54. Числа Бетти сетей Петри 2 подхода к определению чисел Бетти сетей Петри: Сети Петри сопоставляется асинхронная
- 55. Числа Бетти сетей Петри
- 57. Скачать презентацию
Слайд 2Основные разделы
Что такое параллельная программа?
Пять стилей параллельного программирования
Ноутбук как симметричная мультипроцессорная система
Основные разделы
Что такое параллельная программа?
Пять стилей параллельного программирования
Ноутбук как симметричная мультипроцессорная система

Слайд 3Что такое параллельная программа?
Время вычисления суммы s=((a+b)+c)+d равно 3 такта
Для двух параллельно
Что такое параллельная программа?
Время вычисления суммы s=((a+b)+c)+d равно 3 такта
Для двух параллельно
Слайд 4Пять стилей параллельного программирования
Итеративный параллелизм
Рекурсивный параллелизм
Производители и потребители
Клиенты и серверы
Взаимодействующие каналы (или
Пять стилей параллельного программирования
Итеративный параллелизм
Рекурсивный параллелизм
Производители и потребители
Клиенты и серверы
Взаимодействующие каналы (или

Слайд 5Ноутбук как симметричная мультипроцессорная система (SMP)
Архитектура SMP:
Ноутбук как симметричная мультипроцессорная система (SMP)
Архитектура SMP:
Слайд 6Как писать параллельные программы?
1. Разрабатываются подпрограммы, которые могут выполняться независимо. Например, для
Как писать параллельные программы?
1. Разрабатываются подпрограммы, которые могут выполняться независимо. Например, для

Слайд 7Как писать параллельные программы?
Эта подпрограмма всегда имеет один аргумент типа (void *).
Как писать параллельные программы?
Эта подпрограмма всегда имеет один аргумент типа (void *).
Слайд 8Как писать параллельные программы?
Например:
struct arg
{
int ithr ; …
};
DWORD WINAPI Part(void *a)
{
Как писать параллельные программы?
Например:
struct arg
{
int ithr ; …
};
DWORD WINAPI Part(void *a)
{

Слайд 9Итеративный параллелизм и семафоры
Метод трассировки лучей реализуется с помощью цикла, в котором
Итеративный параллелизм и семафоры
Метод трассировки лучей реализуется с помощью цикла, в котором

Слайд 10Итеративный параллелизм и семафоры
Итеративный параллелизм и семафоры

Слайд 11Итеративный параллелизм и семафоры
Для того, чтобы исправить это, введем
Определение. Семафором Дейкстры
Итеративный параллелизм и семафоры
Для того, чтобы исправить это, введем
Определение. Семафором Дейкстры

Слайд 12Итеративный параллелизм и семафоры
Итеративный параллелизм и семафоры

Слайд 13Итеративный параллелизм и семафоры
Пример программы, в которой решается проблема сериализации. Рассмотрим задачу
Итеративный параллелизм и семафоры
Пример программы, в которой решается проблема сериализации. Рассмотрим задачу

Слайд 14Итеративный параллелизм и семафоры
Напишем главную программу
main()
{
int i; int p[n];
for(i=0; i
Итеративный параллелизм и семафоры
Напишем главную программу
main()
{
int i; int p[n];
for(i=0; i
Слайд 15Математическое моделирование параллельных вычислительных систем
При синхронизации работы потоков с помощью семафоров возникают
Математическое моделирование параллельных вычислительных систем
При синхронизации работы потоков с помощью семафоров возникают

Слайд 16Математическое моделирование параллельных вычислительных систем
Рассмотрим математическую модель
состоящую из множества состояний, заданных парами
Математическое моделирование параллельных вычислительных систем
Рассмотрим математическую модель
состоящую из множества состояний, заданных парами
Слайд 17Математическое моделирование параллельных вычислительных систем
Категория состоит из объектов A,B,C, …
и морфизмов
Математическое моделирование параллельных вычислительных систем
Категория состоит из объектов A,B,C, …
и морфизмов

Слайд 18Математическое моделирование параллельных вычислительных систем
Пусть U: A →B - функтор. Объект A
Математическое моделирование параллельных вычислительных систем
Пусть U: A →B - функтор. Объект A

Слайд 19Полукубические множества
Полукубические множества

Слайд 20Полукубические множества
Полукубические множества

Слайд 21Моноиды трасс и вычислительные процессы
Что такое вычислительный процесс?
Рассмотрим вычислительную систему, состоящую из
Моноиды трасс и вычислительные процессы
Что такое вычислительный процесс?
Рассмотрим вычислительную систему, состоящую из

Слайд 22Моноиды трасс и полукубические множества
Теорема 1. Каждому полукубическому множеству с выделенной вершиной
Моноиды трасс и полукубические множества
Теорема 1. Каждому полукубическому множеству с выделенной вершиной

Слайд 23Рекурсивный параллелизм
Метод сдваивания
int sum(int l, int r) // x[l] + … +
Рекурсивный параллелизм
Метод сдваивания
int sum(int l, int r) // x[l] + … +
![Рекурсивный параллелизм Метод сдваивания int sum(int l, int r) // x[l] +](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/411992/slide-22.jpg)
Слайд 24Рекурсивный параллелизм
Данные и структура параметров
int x[100]; struct arg {int l, r, res};
Вызываемый
Рекурсивный параллелизм
Данные и структура параметров
int x[100]; struct arg {int l, r, res};
Вызываемый
![Рекурсивный параллелизм Данные и структура параметров int x[100]; struct arg {int l,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/411992/slide-23.jpg)
Слайд 25Рекурсивный параллелизм
Рекурсивный параллелизм применяется для распараллеливания алгоритма перебора с возвратом
И.А. Трещев установил
Рекурсивный параллелизм
Рекурсивный параллелизм применяется для распараллеливания алгоритма перебора с возвратом
И.А. Трещев установил

Слайд 26Конвейерные системы
Рассмотрим вычислительную систему для вычисления суммы векторов. Она состоит из 5
Конвейерные системы
Рассмотрим вычислительную систему для вычисления суммы векторов. Она состоит из 5

Слайд 27Конвейерные системы
Ускорение S5=T1/T5=5nh/((n+4)h) ≈ 5
Конвейерные системы
Ускорение S5=T1/T5=5nh/((n+4)h) ≈ 5

Слайд 28Производители и потребители: каналы
template
class channel
{
Type *buf; // буфер для очереди
int
Производители и потребители: каналы
template
class channel
{
Type *buf; // буфер для очереди
int

Слайд 29Производители и потребители: каналы
С помощью каналов можно реализовать конвейерные системы.
Блок конвейера
DWORD
Производители и потребители: каналы
С помощью каналов можно реализовать конвейерные системы.
Блок конвейера
DWORD

Слайд 30Клиент-сервер: задача о читателях и писателях
Процессы читают и редактируют файл
Имеющие право на
Клиент-сервер: задача о читателях и писателях
Процессы читают и редактируют файл
Имеющие право на

Слайд 31Асинхронные системы
T=(S,s0,E,I,Tran)
S – множество состояний,
s0∈ S – начальное состояние,
E –
Асинхронные системы
T=(S,s0,E,I,Tran)
S – множество состояний,
s0∈ S – начальное состояние,
E –

Слайд 32Асинхронные системы
a – читатель поступил доступ
b – читатель закончил работу с файлом
c
Асинхронные системы
a – читатель поступил доступ
b – читатель закончил работу с файлом
c

Слайд 33Асинхронные системы и кубические множества
Теорема 2. Каждой асинхронной системе соответствует некоторое кубическое
Асинхронные системы и кубические множества
Теорема 2. Каждой асинхронной системе соответствует некоторое кубическое

Слайд 34Асинхронные системы и кубические множества
Асинхронным системам соответствуют также полиэдры – топологические пространства,
Асинхронные системы и кубические множества
Асинхронным системам соответствуют также полиэдры – топологические пространства,

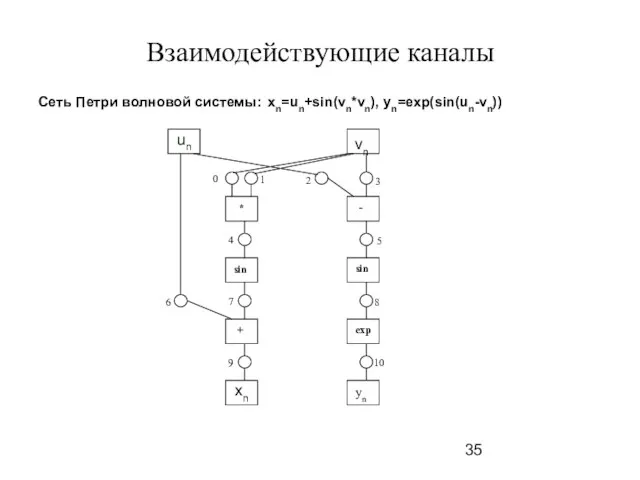
Слайд 35Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
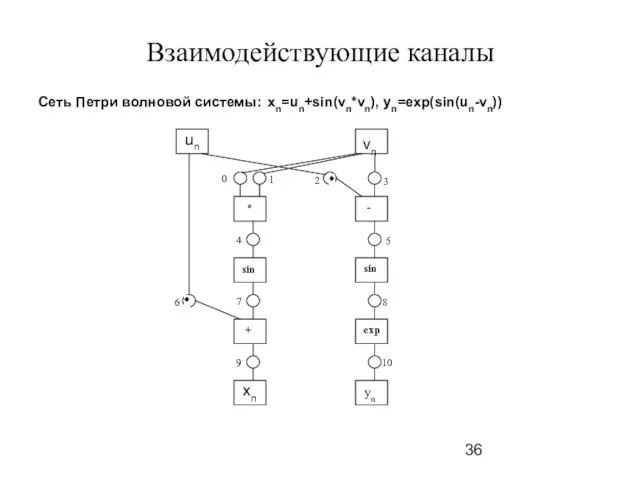
Слайд 36Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
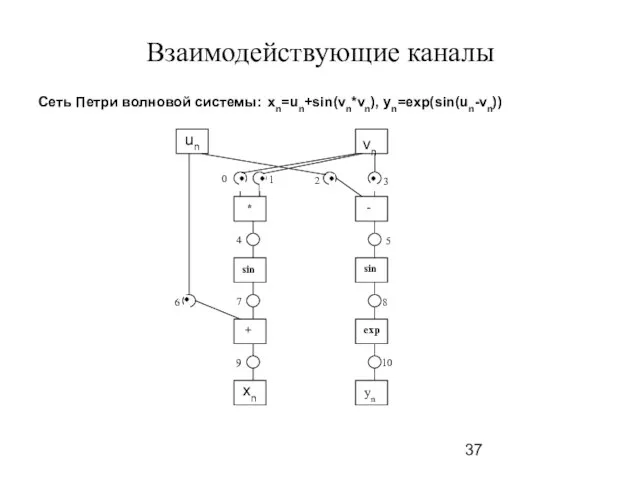
Слайд 37Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
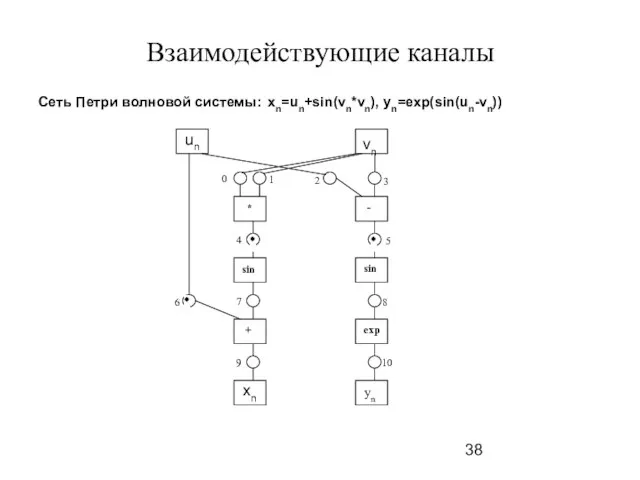
Слайд 38Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Слайд 39Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
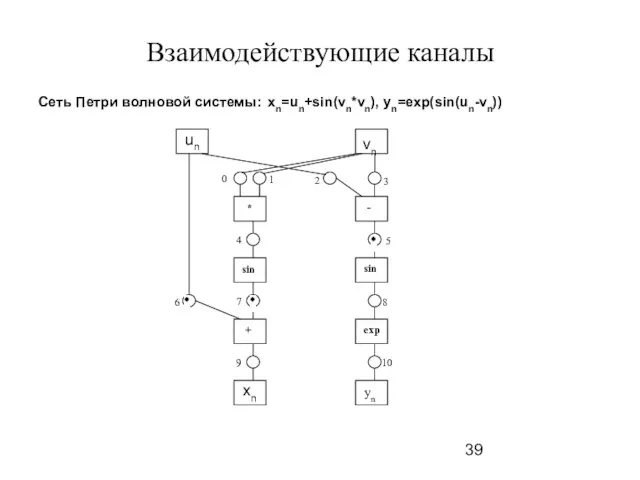
Слайд 40Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
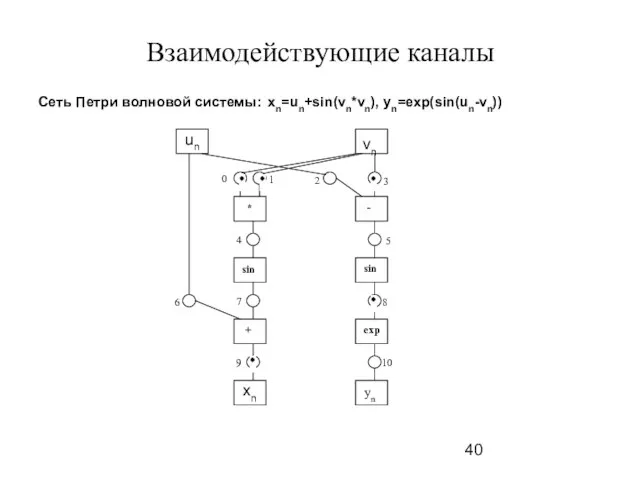
Слайд 41Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
Взаимодействующие каналы
Сеть Петри волновой системы: xn=un+sin(vn*vn), yn=exp(sin(un-vn))
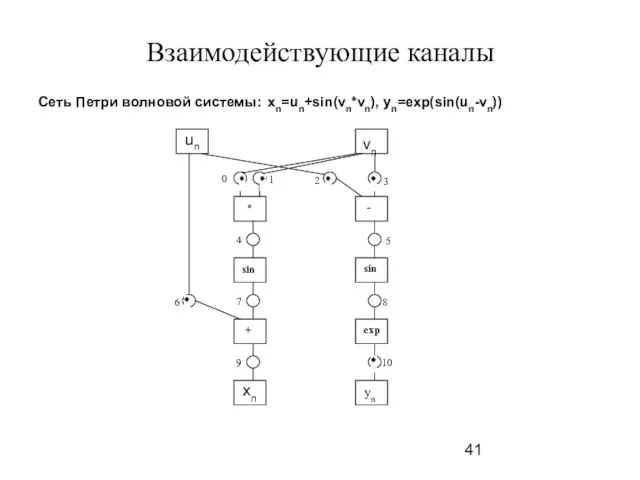
Слайд 42Взаимодействующие каналы
Каналы, соответствующие местам
channel *pc[11];
Подпрограмма потока
DWORD WINAPI mult(LPVOID) // поток для
Взаимодействующие каналы
Каналы, соответствующие местам
channel *pc[11];
Подпрограмма потока
DWORD WINAPI mult(LPVOID) // поток для
![Взаимодействующие каналы Каналы, соответствующие местам channel *pc[11]; Подпрограмма потока DWORD WINAPI mult(LPVOID)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/411992/slide-41.jpg)
Слайд 43Взаимодействующие каналы
Полученные «асинхронные систолические системы» называются волновыми системами
Более точная математическая модель волновой
Взаимодействующие каналы
Полученные «асинхронные систолические системы» называются волновыми системами
Более точная математическая модель волновой

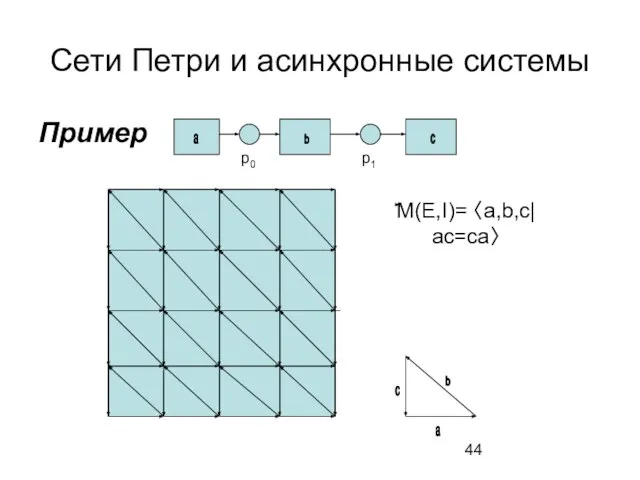
Слайд 44Сети Петри и асинхронные системы
Пример
a
b
c
a
b
c
p0
p1
M(E,I)= 〈a,b,c| ac=ca〉
Сети Петри и асинхронные системы
Пример
a
b
c
a
b
c
p0
p1
M(E,I)= 〈a,b,c| ac=ca〉
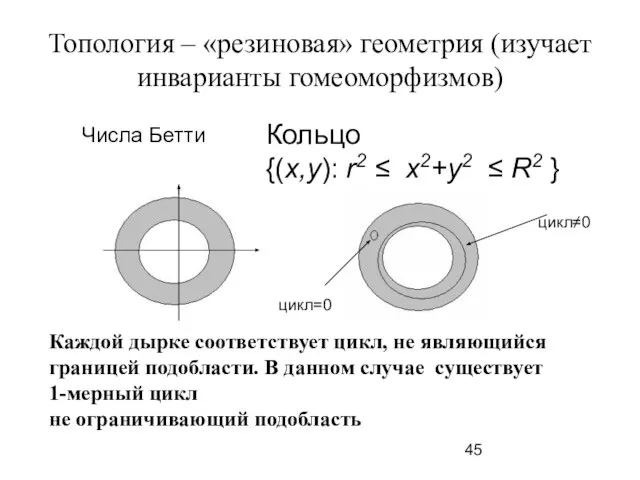
Слайд 45Топология – «резиновая» геометрия (изучает инварианты гомеоморфизмов)
Каждой дырке соответствует цикл, не являющийся
Топология – «резиновая» геометрия (изучает инварианты гомеоморфизмов)
Каждой дырке соответствует цикл, не являющийся
Слайд 46Числа Бетти.
Резиновый мяч. Любой 1-мерный цикл является границей поверхности, содержащейся в области
Числа Бетти.
Резиновый мяч. Любой 1-мерный цикл является границей поверхности, содержащейся в области

Слайд 47Числа Бетти
Сn= L{(x0,x1, …, xn) – симплекс: x0 < x1<…< xn }
Числа Бетти
Сn= L{(x0,x1, …, xn) – симплекс: x0 < x1<…< xn }

Слайд 48Числа Бетти
.
β0=3-0-r(d1)=3-2=1, β1=3-r(d1)-0=1
2-цепей нет ⇒ цикл 01+12-02 ≠ 0
Числа Бетти
.
β0=3-0-r(d1)=3-2=1, β1=3-r(d1)-0=1
2-цепей нет ⇒ цикл 01+12-02 ≠ 0

Слайд 49Вычисление чисел Бетти
βn= dim Cn – r( dn )– r (dn+1)
С0 =
Вычисление чисел Бетти
βn= dim Cn – r( dn )– r (dn+1)
С0 =

Слайд 50Числа Бетти полукубических множеств
d1=
d2=
Числа Бетти полукубических множеств
d1=
d2=

Слайд 51Числа Бетти асинхронных систем
S0=S∪{*}, S1={(s,e1): s∈S0,e1 ∈E}, … ,
Sn= {(s, e1
Числа Бетти асинхронных систем
S0=S∪{*}, S1={(s,e1): s∈S0,e1 ∈E}, … ,
Sn= {(s, e1

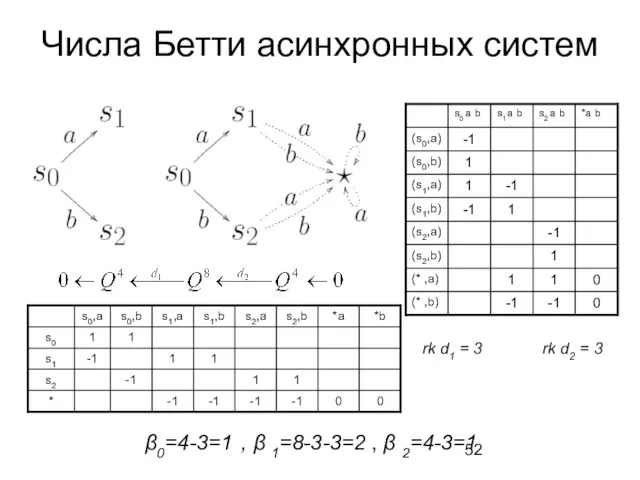
Слайд 52Числа Бетти асинхронных систем
rk d1 = 3
β0=4-3=1 , β 1=8-3-3=2 ,
Числа Бетти асинхронных систем
rk d1 = 3
β0=4-3=1 , β 1=8-3-3=2 ,
Слайд 53Числа Бетти асинхронных систем
28 октября (четверг), в 12.00, в 201/3 состоится защита
Числа Бетти асинхронных систем
28 октября (четверг), в 12.00, в 201/3 состоится защита

Слайд 54Числа Бетти сетей Петри
2 подхода к определению чисел Бетти сетей Петри:
Сети Петри
Числа Бетти сетей Петри
2 подхода к определению чисел Бетти сетей Петри:
Сети Петри

Слайд 55Числа Бетти сетей Петри
Числа Бетти сетей Петри
 Действие норм права во времени, в пространстве и по кругу лиц
Действие норм права во времени, в пространстве и по кругу лиц Решение показательных неравенств
Решение показательных неравенств Международные переговоры. Специфика переговорного процесса в различных условиях
Международные переговоры. Специфика переговорного процесса в различных условиях Бизнес-план: производство духов в Хабаровске
Бизнес-план: производство духов в Хабаровске Система и отрасли права
Система и отрасли права Презентация на тему Иван Калита внук Александра Невского
Презентация на тему Иван Калита внук Александра Невского  Институт будущего
Институт будущего Школьный компьютер в 21 веке Проектная работа учеников 5 класса ГОУ ЦО № 1474, Учитель Головкин Ю. В.
Школьный компьютер в 21 веке Проектная работа учеников 5 класса ГОУ ЦО № 1474, Учитель Головкин Ю. В. Intelli Corder
Intelli Corder Экспертный отдел продаж
Экспертный отдел продаж Уставный капитал 480 млн. рублей ОАО «Камский Индустриальный парк «Мастер» основано 29 июля 2004 года в городе Набережные Челны на базе
Уставный капитал 480 млн. рублей ОАО «Камский Индустриальный парк «Мастер» основано 29 июля 2004 года в городе Набережные Челны на базе Центр дополнительного профессионального образования ГБОУВО РК КИПУ
Центр дополнительного профессионального образования ГБОУВО РК КИПУ Что такое оценка?
Что такое оценка? Пропиточные лаки, эмали и компаунды
Пропиточные лаки, эмали и компаунды Семантические особенности фразеологизмов-зоонимов с компонентами лошадь, корова в якутском и бурятском языках
Семантические особенности фразеологизмов-зоонимов с компонентами лошадь, корова в якутском и бурятском языках ШКОЛЬНЫЙ ЭТАПКОНКУРСА« УЧИТЕЛЬ ГОДА-2010»
ШКОЛЬНЫЙ ЭТАПКОНКУРСА« УЧИТЕЛЬ ГОДА-2010» Особенности формирования экономики знаний в современных условиях
Особенности формирования экономики знаний в современных условиях Ситуация на рынке жилья Санкт-Петербурга в 2008 году. Прогноз на 2009.
Ситуация на рынке жилья Санкт-Петербурга в 2008 году. Прогноз на 2009. Живопись в начале xx века
Живопись в начале xx века Государственное регулирование охраны труда
Государственное регулирование охраны труда Синус, косинус, тангенс суммы и разности аргументов (10 класс)
Синус, косинус, тангенс суммы и разности аргументов (10 класс) История Олимпийских игр. Олимпиады Древней Греции (776 до н.э. – 394 н.э.)
История Олимпийских игр. Олимпиады Древней Греции (776 до н.э. – 394 н.э.) Bogunly gur&amp;#231;uklar
Bogunly gur&amp;#231;uklar Иван Алексеевич Бунин
Иван Алексеевич Бунин Государственное учреждение «Управление по обеспечению рационального использования и качества топливно-энергетических ресурсов
Государственное учреждение «Управление по обеспечению рационального использования и качества топливно-энергетических ресурсов  Открытие Декады филологического образования в МБОУ Гайдаровская СОШ
Открытие Декады филологического образования в МБОУ Гайдаровская СОШ Composers: Romantic period (1820 -1910)
Composers: Romantic period (1820 -1910) Степень числа с натуральным показателем
Степень числа с натуральным показателем