- Введение

Содержание
- 2. Москва, 2008 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 32 Содержание Тенденции развития
- 3. В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2 года. Это обеспечивалось и
- 4. Время Тенденции развития современных процессоров В П В П В П В П В П В
- 5. Тенденции развития современных процессоров Суперкомпьютер СКИФ МГУ «Чебышев» Пиковая производительность - 60 TFlop/s Число процессоров/ядер в
- 6. Тенденции развития современных процессоров Quad-Core AMD Opteron 4 ядра встроенный контроллер памяти (2 канала памяти DDR2
- 7. Тенденции развития современных процессоров Intel Core i7 (архитектура Nehalem ) 4 ядра 8 потоков с технологией
- 8. Тенденции развития современных процессоров SUN UltraSPARC T2 Processor (Niagara 2) 8 ядер 64 потоков 4 контроллера
- 9. из 32 Тенденции развития современных процессоров Темпы уменьшения латентности памяти гораздо ниже темпов ускорения процессоров +
- 10. Существующие подходы для создания параллельных программ Автоматическое распараллеливание Библиотеки нитей Win32 API POSIX Библиотеки передачи сообщений
- 11. Вычисление числа π Москва, 2008 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 32
- 12. из 32 #include int main () { int n =100000, i; double pi, h, sum, x;
- 13. Автоматическое распараллеливание Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, ParaWise, ОРС, САПФОР icc -parallel pi.c pi.c(8):
- 14. из 32 #include "mpi.h" #include int main (int argc, char *argv[]) { int n =100000, myid,
- 15. из 32 for (i = myid + 1; i { x = h * ((double)i -
- 16. из 32 #include #include #define NUM_THREADS 2 CRITICAL_SECTION hCriticalSection; double pi = 0.0; int n =100000;
- 17. из 32 void Pi (void *arg) { int i, start; double h, sum, x; h =
- 18. из 32 #include int main () { int n =100000, i; double pi, h, sum, x;
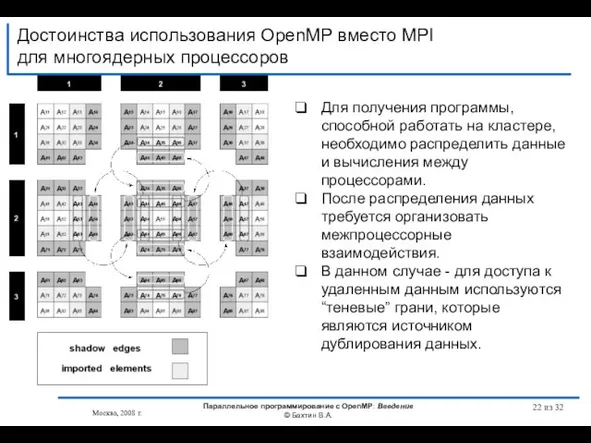
- 19. Достоинства использования OpenMP вместо MPI для многоядерных процессоров Возможность инкрементального распараллеливания Упрощение программирования и эффективность на
- 20. Достоинства использования OpenMP вместо MPI для многоядерных процессоров Процессоры Intel® Xeon® серии 5000 Процессоры Intel® Xeon®
- 21. Достоинства использования OpenMP вместо MPI для многоядерных процессоров #define Max(a,b) ((a)>(b)?(a):(b)) #define L 8 #define ITMAX
- 22. Достоинства использования OpenMP вместо MPI для многоядерных процессоров Москва, 2008 г. Параллельное программирование с OpenMP: Введение
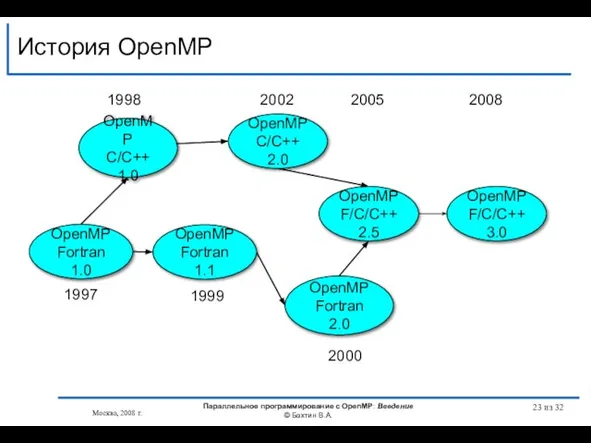
- 23. История OpenMP OpenMP Fortran 1.1 OpenMP C/C++ 1.0 OpenMP Fortran 2.0 OpenMP C/C++ 2.0 1998 2000
- 24. OpenMP Architecture Review Board AMD Cray Fujitsu HP IBM Intel NEC The Portland Group, Inc. SGI
- 25. Компиляторы, поддеживающие OpenMP OpenMP 3.0: Intel 11.0: Linux, Windows and MacOS Sun Studio Express 11/08: Linux
- 26. Обзор основных возможностей OpenMP omp_set_lock(lck) #pragma omp parallel for private(a, b) #pragma omp critical C$OMP PARALLEL
- 27. из 32 Литература… http://www.openmp.org http://www.compunity.org http://www.parallel.ru/tech/tech_dev/openmp.html Москва, 2008 г. Параллельное программирование с OpenMP: Введение © Бахтин
- 28. из 32 Литература… Гергель В.П. Теория и практика параллельных вычислений. - М.: Интернет-Университет, БИНОМ. Лаборатория знаний,
- 29. из 32 Литература… Учебные курсы Интернет Университета Информационных технологий Гергель В.П. Теория и практика параллельных вычислений.
- 30. из 32 Вопросы? Вопросы? Москва, 2008 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А.
- 31. из 32 OpenMP – модель параллелизма по управлению Следующая тема Москва, 2008 г. Параллельное программирование с
- 33. Скачать презентацию
Слайд 2Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из 32
Содержание
Тенденции
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из 32
Содержание
Тенденции

Слайд 3В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2
В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2

Слайд 4Время
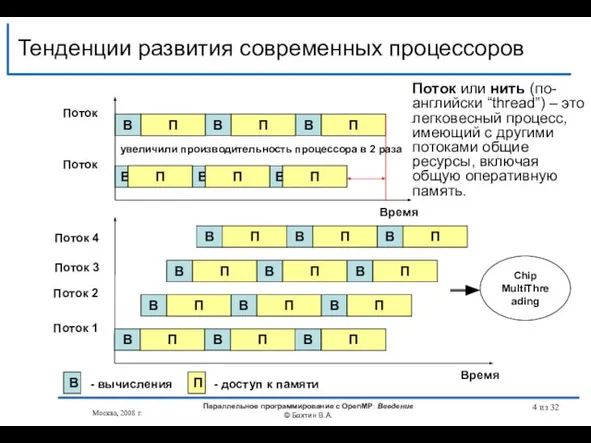
Тенденции развития современных процессоров
В
П
В
П
В
П
В
П
В
П
В
П
Поток
Поток
Время
В
П
В
П
В
П
Поток 1
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
Поток 2
Поток 3
Поток 4
В
- вычисления
П
- доступ к памяти
Chip
MultiThreading
увеличили
Время
Тенденции развития современных процессоров
В
П
В
П
В
П
В
П
В
П
В
П
Поток
Поток
Время
В
П
В
П
В
П
Поток 1
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
Поток 2
Поток 3
Поток 4
В
- вычисления
П
- доступ к памяти
Chip
MultiThreading
увеличили
Слайд 5Тенденции развития современных процессоров
Суперкомпьютер СКИФ МГУ «Чебышев»
Пиковая производительность - 60 TFlop/s
Число
Тенденции развития современных процессоров
Суперкомпьютер СКИФ МГУ «Чебышев»
Пиковая производительность - 60 TFlop/s
Число

Слайд 6Тенденции развития современных процессоров
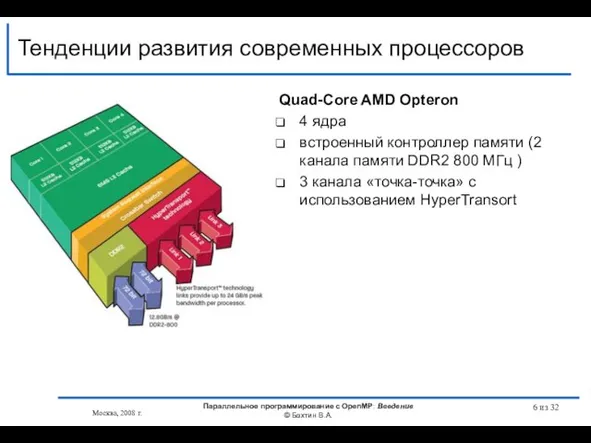
Quad-Core AMD Opteron
4 ядра
встроенный контроллер памяти (2 канала
Тенденции развития современных процессоров
Quad-Core AMD Opteron
4 ядра
встроенный контроллер памяти (2 канала
Слайд 7Тенденции развития современных процессоров
Intel Core i7 (архитектура Nehalem )
4 ядра
8 потоков с
Тенденции развития современных процессоров
Intel Core i7 (архитектура Nehalem )
4 ядра
8 потоков с

Слайд 8Тенденции развития современных процессоров
SUN UltraSPARC T2 Processor (Niagara 2)
8 ядер
64 потоков
4 контроллера
Тенденции развития современных процессоров
SUN UltraSPARC T2 Processor (Niagara 2)
8 ядер
64 потоков
4 контроллера

Слайд 9 из 32
Тенденции развития современных процессоров
Темпы уменьшения латентности памяти гораздо ниже темпов
из 32
Тенденции развития современных процессоров
Темпы уменьшения латентности памяти гораздо ниже темпов

Слайд 10Существующие подходы для создания параллельных программ
Автоматическое распараллеливание
Библиотеки нитей
Win32 API
POSIX
Библиотеки передачи сообщений
MPI
OpenMP
Москва,
Существующие подходы для создания параллельных программ
Автоматическое распараллеливание
Библиотеки нитей
Win32 API
POSIX
Библиотеки передачи сообщений
MPI
OpenMP
Москва,

Слайд 11Вычисление числа π
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
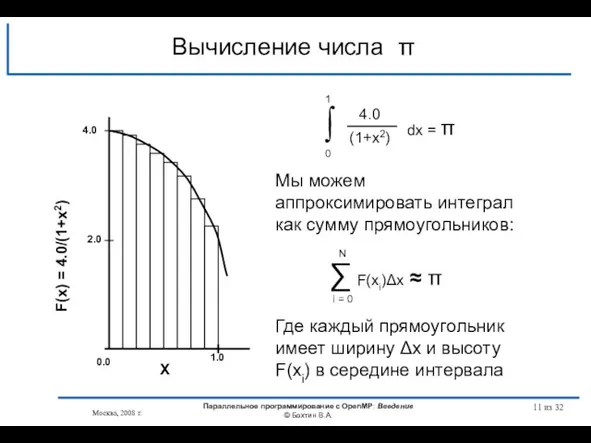
Вычисление числа π
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
Слайд 12 из 32
#include
int main ()
{
int n =100000, i;
double pi,
из 32
#include
int main ()
{
int n =100000, i;
double pi,

Слайд 13Автоматическое распараллеливание
Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, ParaWise, ОРС, САПФОР
icc
Автоматическое распараллеливание
Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, ParaWise, ОРС, САПФОР
icc

Слайд 14 из 32
#include "mpi.h"
#include
int main (int argc, char *argv[])
{
int n
из 32
#include "mpi.h"
#include
int main (int argc, char *argv[])
{
int n
![из 32 #include "mpi.h" #include int main (int argc, char *argv[]) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/468078/slide-13.jpg)
Слайд 15 из 32
for (i = myid + 1; i <= n;
из 32
for (i = myid + 1; i <= n;

Слайд 16 из 32
#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n
из 32
#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n

Слайд 17 из 32
void Pi (void *arg)
{
int i, start;
double h, sum,
из 32
void Pi (void *arg)
{
int i, start;
double h, sum,

Слайд 18 из 32
#include
int main ()
{
int n =100000, i;
double pi,
из 32
#include
int main ()
{
int n =100000, i;
double pi,

Слайд 19Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Возможность инкрементального распараллеливания
Упрощение программирования и эффективность
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Возможность инкрементального распараллеливания
Упрощение программирования и эффективность

Слайд 20Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
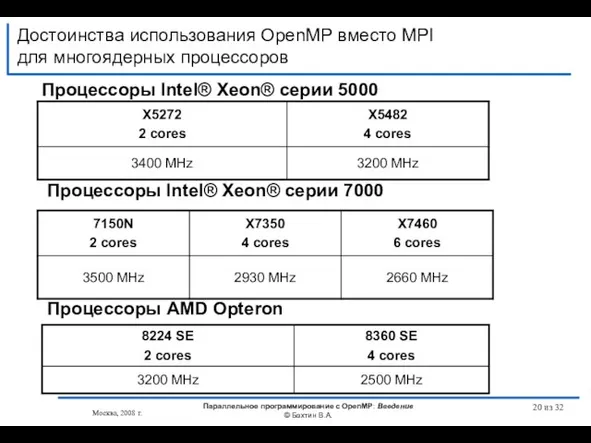
Процессоры Intel® Xeon® серии 5000
Процессоры Intel®
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Процессоры Intel® Xeon® серии 5000
Процессоры Intel®
Слайд 21Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
#define Max(a,b) ((a)>(b)?(a):(b))
#define L 8
#define ITMAX
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
#define Max(a,b) ((a)>(b)?(a):(b))
#define L 8
#define ITMAX

Слайд 22Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Москва, 2008 г.
Параллельное программирование с OpenMP:
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Москва, 2008 г.
Параллельное программирование с OpenMP:
Слайд 23История OpenMP
OpenMP
Fortran 1.1
OpenMP
C/C++ 1.0
OpenMP
Fortran 2.0
OpenMP
C/C++ 2.0
1998
2000
1999
2002
OpenMP
Fortran 1.0
1997
OpenMP
F/C/C++ 2.5
2005
OpenMP
F/C/C++ 3.0
2008
Москва, 2008 г.
Параллельное программирование
История OpenMP
OpenMP
Fortran 1.1
OpenMP
C/C++ 1.0
OpenMP
Fortran 2.0
OpenMP
C/C++ 2.0
1998
2000
1999
2002
OpenMP
Fortran 1.0
1997
OpenMP
F/C/C++ 2.5
2005
OpenMP
F/C/C++ 3.0
2008
Москва, 2008 г.
Параллельное программирование
Слайд 24OpenMP Architecture Review Board
AMD
Cray
Fujitsu
HP
IBM
Intel
NEC
The Portland Group, Inc.
SGI
Sun
Microsoft
ASC/LLNL
cOMPunity
EPCC
NASA
RWTH Aachen University
Москва, 2008
OpenMP Architecture Review Board
AMD
Cray
Fujitsu
HP
IBM
Intel
NEC
The Portland Group, Inc.
SGI
Sun
Microsoft
ASC/LLNL
cOMPunity
EPCC
NASA
RWTH Aachen University
Москва, 2008

Слайд 25Компиляторы, поддеживающие OpenMP
OpenMP 3.0:
Intel 11.0: Linux, Windows and MacOS
Sun Studio Express 11/08:
Компиляторы, поддеживающие OpenMP
OpenMP 3.0:
Intel 11.0: Linux, Windows and MacOS
Sun Studio Express 11/08:

Слайд 26Обзор основных возможностей OpenMP
omp_set_lock(lck)
#pragma omp parallel for private(a, b)
#pragma omp critical
C$OMP PARALLEL
Обзор основных возможностей OpenMP
omp_set_lock(lck)
#pragma omp parallel for private(a, b)
#pragma omp critical
C$OMP PARALLEL

Слайд 27 из 32
Литература…
http://www.openmp.org
http://www.compunity.org
http://www.parallel.ru/tech/tech_dev/openmp.html
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин
из 32
Литература…
http://www.openmp.org
http://www.compunity.org
http://www.parallel.ru/tech/tech_dev/openmp.html
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение © Бахтин

Слайд 28 из 32
Литература…
Гергель В.П. Теория и практика параллельных вычислений. - М.:
из 32
Литература…
Гергель В.П. Теория и практика параллельных вычислений. - М.:

Слайд 29 из 32
Литература…
Учебные курсы Интернет Университета Информационных технологий
Гергель В.П. Теория и
из 32
Литература…
Учебные курсы Интернет Университета Информационных технологий
Гергель В.П. Теория и

Слайд 30 из 32
Вопросы?
Вопросы?
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из 32
Вопросы?
Вопросы?
Москва, 2008 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.

Слайд 31 из 32
OpenMP – модель параллелизма по управлению
Следующая тема
Москва, 2008 г.
Параллельное
из 32
OpenMP – модель параллелизма по управлению
Следующая тема
Москва, 2008 г.
Параллельное

 Периодика. О журналах
Периодика. О журналах Перспективные технологии и экспертиза качества строительных материалов. Материаловедение в технологии материалов
Перспективные технологии и экспертиза качества строительных материалов. Материаловедение в технологии материалов Встраивание музыкальных файлов в презентацию
Встраивание музыкальных файлов в презентацию УПРАВЛЕНИЕ СЕТЯМИ СВЯЗИ:ЗАДАЧИ, ПОДХОДЫ и ПЕРСПЕКТИВЫ ДЛЯ РОССИЙСКОГО ТЕЛЕКОММУНИКАЦИОННОГО РЫНКА
УПРАВЛЕНИЕ СЕТЯМИ СВЯЗИ:ЗАДАЧИ, ПОДХОДЫ и ПЕРСПЕКТИВЫ ДЛЯ РОССИЙСКОГО ТЕЛЕКОММУНИКАЦИОННОГО РЫНКА Анализ отрасли образования для бизнес-идеи
Анализ отрасли образования для бизнес-идеи Карьера
Карьера Динамика двигательной подготовленности и физического здоровья у легкоатлетов
Динамика двигательной подготовленности и физического здоровья у легкоатлетов Презентация на тему Выталкивающая сила (7 класс)
Презентация на тему Выталкивающая сила (7 класс) Управление предметной
Управление предметной Саша Черный Что ты тискаешь утенка
Саша Черный Что ты тискаешь утенка Продукт «NanoVit-Motor-Renovator» Результаты сертификационных испытаний TUV-Тюрингия и MSH Mineralstoffhandel GmbH
Продукт «NanoVit-Motor-Renovator» Результаты сертификационных испытаний TUV-Тюрингия и MSH Mineralstoffhandel GmbH Презентация на тему Художники-передвижники
Презентация на тему Художники-передвижники  Презентация на тему Введение дошкольника в мир искусства
Презентация на тему Введение дошкольника в мир искусства  Конечные автоматы и преобразователи
Конечные автоматы и преобразователи  Предложение по совместному проекту Российского Предприятия (РП)иZENNER International GmbH & Co. KG по предоставлению конечному клиенту услуги
Предложение по совместному проекту Российского Предприятия (РП)иZENNER International GmbH & Co. KG по предоставлению конечному клиенту услуги  Информатика и вычислительная техника
Информатика и вычислительная техника Оценка факторов, влияющих на качество программных продуктов
Оценка факторов, влияющих на качество программных продуктов Презентация на тему Подцарство Простейшие
Презентация на тему Подцарство Простейшие  Требования к проводнику пассажирских вагонов при посадке пассажиров
Требования к проводнику пассажирских вагонов при посадке пассажиров углеводы
углеводы Цвет и зрительные иллюзии.
Цвет и зрительные иллюзии. Друзья мои, прекрасен наш союз
Друзья мои, прекрасен наш союз Российские храмы
Российские храмы Ректификация. Сущность процесса ректификации
Ректификация. Сущность процесса ректификации Сложноподчиненное предложение с придаточным определительным
Сложноподчиненное предложение с придаточным определительным Финансовое планирование на предприятии
Финансовое планирование на предприятии Первичное наблюдение как основа информационной системы бухгалтерского учета
Первичное наблюдение как основа информационной системы бухгалтерского учета Государственное образовательное учреждение Среднего профессионального образования Московский вечерний авиационный технологич
Государственное образовательное учреждение Среднего профессионального образования Московский вечерний авиационный технологич