- Прикладной Python. Базы данных. Лекция №6

Содержание
- 2. Базовые понятия реляционных БД Проектирование БД SQL. Основные операции: SELECT, INSERT, UPDATE, DELETE, JOIN Индексы EXPLAIN
- 3. Где хранить данные? На клиенте Cookie (4кб) Web Storage На сервере В памяти На диске На
- 4. БД - Взаимосвязанные данные специальным образом хранящиеся на каком-либо носителе СУБД – Программный комплекс обеспечивающий работу
- 5. Предназначение СУБД Управление данными на дисках и в оперативной памяти Журнализация, резервное копирование Предоставление интерфейсов взаимодействия
- 6. Реляционная модель данных Таблица - отношение, relation Строка - кортеж, tuple Столбец - атрибут, column
- 7. Таблица пользователей
- 8. Первиичный ключ (primary key) — в реляционной модели данных один из потенциальных ключей отношения, выбранный в
- 9. Внешний ключ — это столбец или комбинация столбцов, значения которых соответствуют Первичному ключу в другой таблице.
- 10. Виды связей в реляционной БД Связь один к одному образуется, когда ключевой столбец (идентификатор) присутствует в
- 11. Примеры
- 12. Примеры
- 13. Пример
- 14. Структура SQL запроса SELECT SELECT [DISTINCT | DISTINCTROW | ALL] select_expression,... FROM table_references [WHERE where_definition] [GROUP
- 15. Операции SQL: SELECT SELECT * FROM users WHERE age > 10; SELECT * FROM users WHERE
- 16. Агрегация SELECT first_name, count(id) as cnt FROM users_user WHERE first_name LIKE "%дим%" GROUP BY first_name HAVING
- 17. Агрегатные функции MySQL AVG: вычисляет среднее значение SUM: вычисляет сумму значений MIN: вычисляет наименьшее значение MAX:
- 18. JOIN SELECT h.name, a.name FROM heroes h, abilities a WHERE h.id = a.hero_id; SELECT h.name, a.name
- 19. Вложенные запросы SELECT title FROM article t1 JOIN ( SELECT rubric_id, MAX(id) max_id FROM article GROUP
- 20. Операции SQL: INSERT, UPDATE, DELETE INSERT INTO users (name, age) VALUES ('Petr', 10); UPDATE users SET
- 21. Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных
- 22. По каким полям надо делать индексы Индексы для полей, по которым происходит JOIN Индексы для полей,
- 23. Задачи проектирования Обеспечение хранения всей необходимой информации Обеспечение возможности получения данных по всем запросам Сокращение избыточности
- 24. Типы данных в MySQL INT - Целое число нормального размера. Диапазон со знаком от -2147483648 до
- 25. Больше типов данных CHAR(M) [BINARY] - Строка фиксированной длины, при хранении всегда дополняется пробелами в конце
- 26. Проектируем БД Спроектировать базу данных для магазина
- 27. Анализ запросов: EXPLAIN Ничего не говорит о том как влияют на запросы триггеры. Не работает с
- 28. Explain: id EXPLAIN select * from users_car where id LIKE "1%" EXPLAIN select *, (SELECT 1
- 29. Explain: select_type SIMPLE – Простой запрос SELECT без подзапросов или UNION PRIMARY - Самый внешний запрос
- 30. Explain: table EXPLAIN select * from users_car where id LIKE "1%" EXPLAIN select * from users_car
- 31. Explain: type ALL - Этот подход обычно называют сканированием таблицы. index - То же, что и
- 32. Explain: possible_keys, key EXPLAIN select id from users_user\G;
- 33. NoSQL Rising
- 34. Общие характеристики NoSQL БД Не используют реляционную модель Хорошо подходят для развертывания на кластере Open-source Schemaless
- 35. NoSQL: key-value СУБД Кейсы применения БД хранилищ ключ-значение: Кеширование - быстрое и частое сохранение данных для
- 36. NoSQL: распределенные СУБД Кейсы применения распределенных СУБД: Хранение неструктурированных, не разрушаемых данных - если вам необходимо
- 37. NoSQL: документоориентированные СУБД Кейсы применения документоориентированные СУБД: Популярные СУБД MongoDB - очень популярное и функциональное хранилище
- 38. NoSQL: СУБД типа граф Кейсы применения распределенных СУБД: работа со сложно связанной информацией. Например граф знакомств
- 39. SQL подход к проектированию БД
- 40. NoSQL подход
- 42. Скачать презентацию
Слайд 2Базовые понятия реляционных БД
Проектирование БД
SQL. Основные операции: SELECT, INSERT, UPDATE, DELETE, JOIN
Индексы
EXPLAIN
NoSQL
Базы
Базовые понятия реляционных БД
Проектирование БД
SQL. Основные операции: SELECT, INSERT, UPDATE, DELETE, JOIN
Индексы
EXPLAIN
NoSQL
Базы
Слайд 3Где хранить данные?
На клиенте
Cookie (4кб)
Web Storage
На сервере
В памяти
На диске
На
Где хранить данные?
На клиенте
Cookie (4кб)
Web Storage
На сервере
В памяти
На диске
На

Слайд 4БД - Взаимосвязанные данные специальным образом хранящиеся на каком-либо носителе
СУБД –
БД - Взаимосвязанные данные специальным образом хранящиеся на каком-либо носителе
СУБД –

Слайд 5Предназначение СУБД
Управление данными на дисках и в оперативной памяти
Журнализация, резервное копирование
Предоставление
Предназначение СУБД
Управление данными на дисках и в оперативной памяти
Журнализация, резервное копирование
Предоставление

Слайд 6Реляционная модель данных
Таблица - отношение, relation
Строка - кортеж, tuple
Столбец -
Реляционная модель данных
Таблица - отношение, relation
Строка - кортеж, tuple
Столбец -

Слайд 7Таблица пользователей
Таблица пользователей

Слайд 8Первиичный ключ (primary key) — в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве
Первиичный ключ (primary key) — в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве

Слайд 9Внешний ключ — это столбец или комбинация столбцов, значения которых соответствуют Первичному ключу
Внешний ключ — это столбец или комбинация столбцов, значения которых соответствуют Первичному ключу

Слайд 10Виды связей в реляционной БД
Связь один к одному образуется, когда ключевой столбец
Виды связей в реляционной БД
Связь один к одному образуется, когда ключевой столбец

Слайд 11Примеры
Примеры

Слайд 12Примеры
Примеры

Слайд 13Пример
Пример

Слайд 14Структура SQL запроса SELECT
SELECT
[DISTINCT | DISTINCTROW | ALL]
select_expression,...
Структура SQL запроса SELECT
SELECT
[DISTINCT | DISTINCTROW | ALL]
select_expression,...
![Структура SQL запроса SELECT SELECT [DISTINCT | DISTINCTROW | ALL] select_expression,... FROM](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1101311/slide-13.jpg)
Слайд 15Операции SQL: SELECT
SELECT * FROM users WHERE age > 10;
SELECT * FROM
Операции SQL: SELECT
SELECT * FROM users WHERE age > 10;
SELECT * FROM

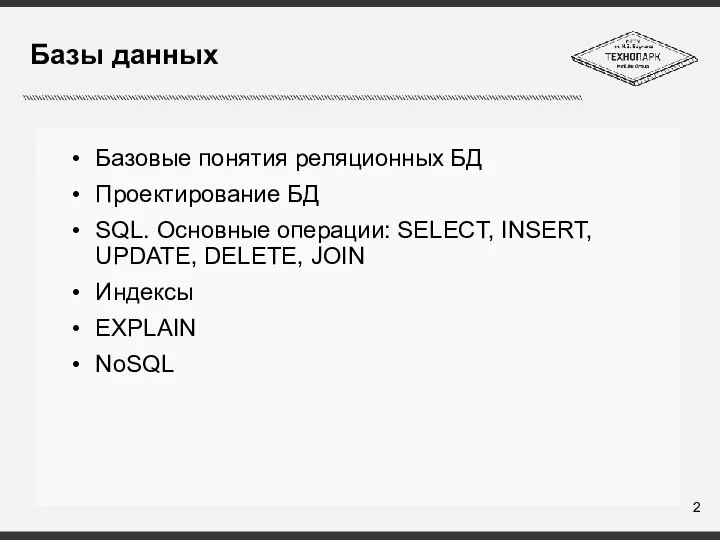
Слайд 16Агрегация
SELECT first_name, count(id) as cnt
FROM users_user
WHERE first_name
LIKE "%дим%"
GROUP
Агрегация
SELECT first_name, count(id) as cnt
FROM users_user
WHERE first_name
LIKE "%дим%"
GROUP
Слайд 17Агрегатные функции MySQL
AVG: вычисляет среднее значение
SUM: вычисляет сумму значений
MIN: вычисляет наименьшее значение
MAX:
Агрегатные функции MySQL
AVG: вычисляет среднее значение
SUM: вычисляет сумму значений
MIN: вычисляет наименьшее значение
MAX:

Слайд 18JOIN
SELECT h.name, a.name
FROM heroes h, abilities a
WHERE h.id = a.hero_id;
SELECT h.name, a.name
FROM
JOIN
SELECT h.name, a.name
FROM heroes h, abilities a
WHERE h.id = a.hero_id;
SELECT h.name, a.name
FROM

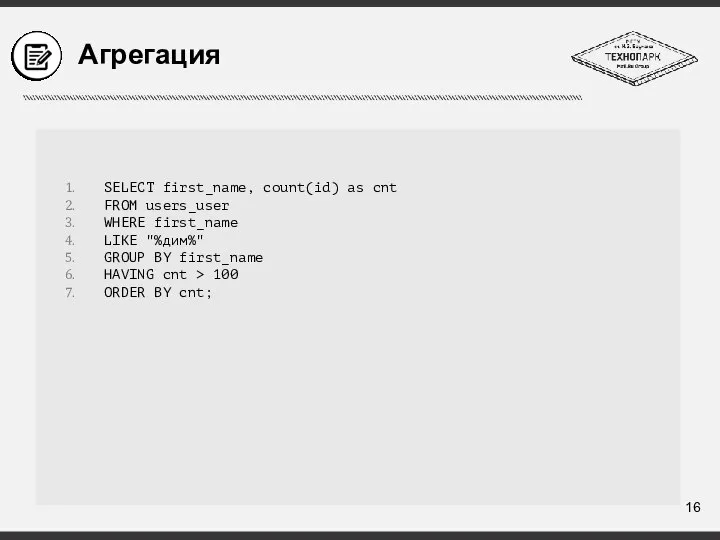
Слайд 19Вложенные запросы
SELECT title
FROM article t1
JOIN (
SELECT rubric_id, MAX(id) max_id
FROM article
Вложенные запросы
SELECT title
FROM article t1
JOIN (
SELECT rubric_id, MAX(id) max_id
FROM article
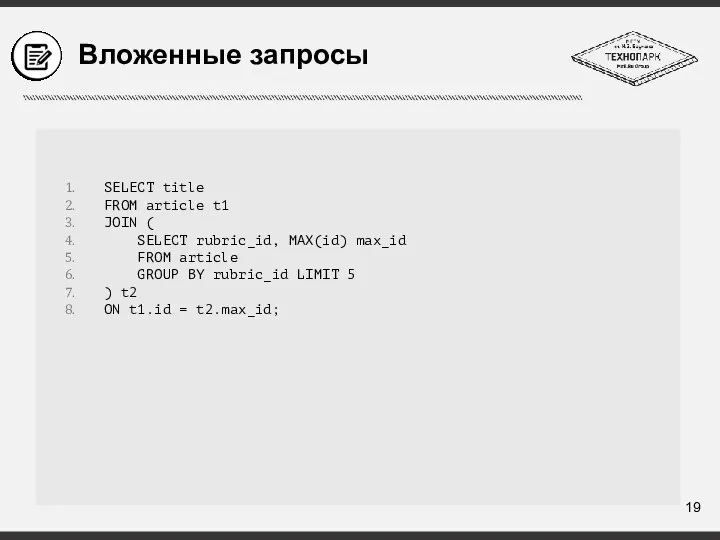
Слайд 20Операции SQL: INSERT, UPDATE, DELETE
INSERT INTO users (name, age) VALUES ('Petr', 10);
UPDATE
Операции SQL: INSERT, UPDATE, DELETE
INSERT INTO users (name, age) VALUES ('Petr', 10);
UPDATE
Слайд 21Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в
Индекс — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в

Слайд 22По каким полям надо делать индексы
Индексы для полей, по которым происходит JOIN
По каким полям надо делать индексы
Индексы для полей, по которым происходит JOIN

Слайд 23Задачи проектирования
Обеспечение хранения всей необходимой информации
Обеспечение возможности получения данных по всем
Задачи проектирования
Обеспечение хранения всей необходимой информации
Обеспечение возможности получения данных по всем

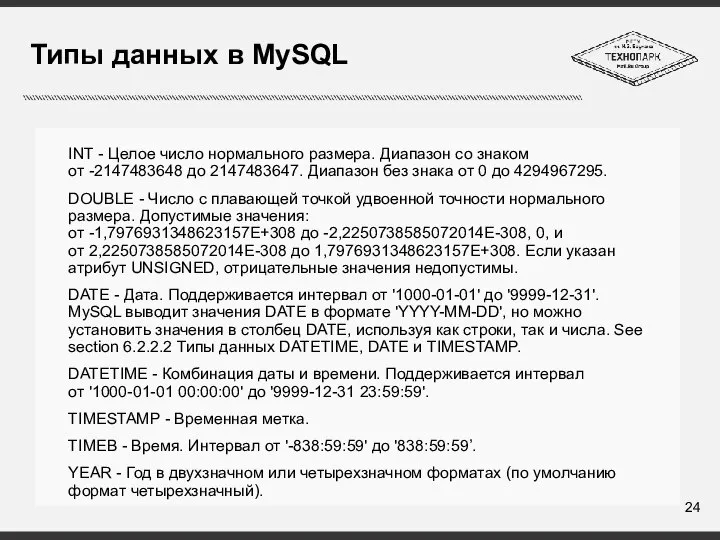
Слайд 24Типы данных в MySQL
INT - Целое число нормального размера. Диапазон со знаком
Типы данных в MySQL
INT - Целое число нормального размера. Диапазон со знаком
Слайд 25Больше типов данных
CHAR(M) [BINARY] - Строка фиксированной длины, при хранении всегда дополняется
Больше типов данных
CHAR(M) [BINARY] - Строка фиксированной длины, при хранении всегда дополняется
![Больше типов данных CHAR(M) [BINARY] - Строка фиксированной длины, при хранении всегда](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1101311/slide-24.jpg)
Слайд 26Проектируем БД
Спроектировать базу данных для магазина
Проектируем БД
Спроектировать базу данных для магазина

Слайд 27Анализ запросов: EXPLAIN
Ничего не говорит о том как влияют на запросы триггеры.
Не
Анализ запросов: EXPLAIN
Ничего не говорит о том как влияют на запросы триггеры.
Не

Слайд 28Explain: id
EXPLAIN select * from users_car where id LIKE "1%"
EXPLAIN select *,
Explain: id
EXPLAIN select * from users_car where id LIKE "1%"
EXPLAIN select *,

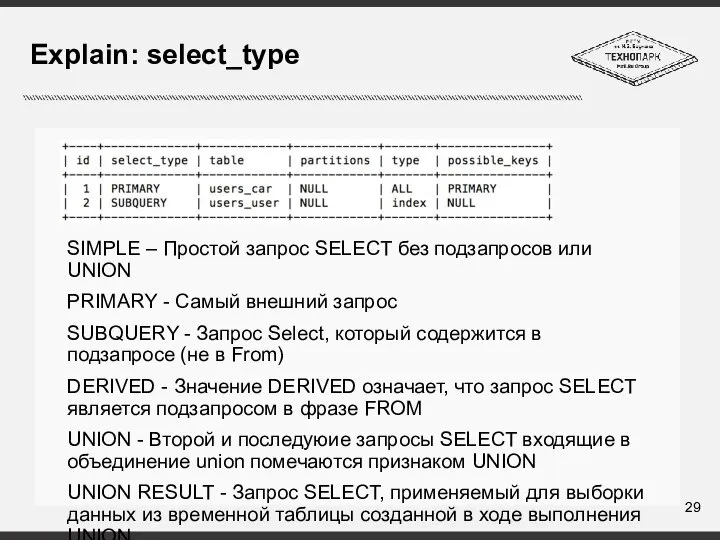
Слайд 29Explain: select_type
SIMPLE – Простой запрос SELECT без подзапросов или UNION
PRIMARY - Самый
Explain: select_type
SIMPLE – Простой запрос SELECT без подзапросов или UNION
PRIMARY - Самый
Слайд 30Explain: table
EXPLAIN select * from users_car where id LIKE "1%"
EXPLAIN select *
Explain: table
EXPLAIN select * from users_car where id LIKE "1%"
EXPLAIN select *

Слайд 31Explain: type
ALL - Этот подход обычно называют сканированием таблицы.
index - То же,
Explain: type
ALL - Этот подход обычно называют сканированием таблицы.
index - То же,

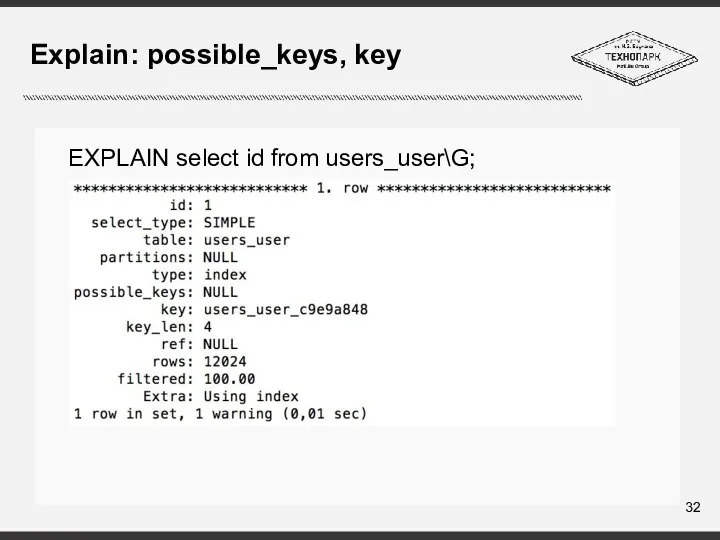
Слайд 32Explain: possible_keys, key
EXPLAIN select id from users_user\G;
Explain: possible_keys, key
EXPLAIN select id from users_user\G;
Слайд 33NoSQL Rising
NoSQL Rising

Слайд 34Общие характеристики NoSQL БД
Не используют реляционную модель
Хорошо подходят для развертывания на кластере
Open-source
Schemaless
Общие характеристики NoSQL БД
Не используют реляционную модель
Хорошо подходят для развертывания на кластере
Open-source
Schemaless
Слайд 35NoSQL: key-value СУБД
Кейсы применения БД хранилищ ключ-значение:
Кеширование - быстрое и частое сохранение
NoSQL: key-value СУБД
Кейсы применения БД хранилищ ключ-значение:
Кеширование - быстрое и частое сохранение

Слайд 36NoSQL: распределенные СУБД
Кейсы применения распределенных СУБД:
Хранение неструктурированных, не разрушаемых данных - если
NoSQL: распределенные СУБД
Кейсы применения распределенных СУБД:
Хранение неструктурированных, не разрушаемых данных - если

Слайд 37NoSQL: документоориентированные СУБД
Кейсы применения документоориентированные СУБД:
Популярные СУБД
MongoDB - очень популярное и функциональное
NoSQL: документоориентированные СУБД
Кейсы применения документоориентированные СУБД:
Популярные СУБД
MongoDB - очень популярное и функциональное

Слайд 38NoSQL: СУБД типа граф
Кейсы применения распределенных СУБД:
работа со сложно связанной информацией. Например
NoSQL: СУБД типа граф
Кейсы применения распределенных СУБД:
работа со сложно связанной информацией. Например

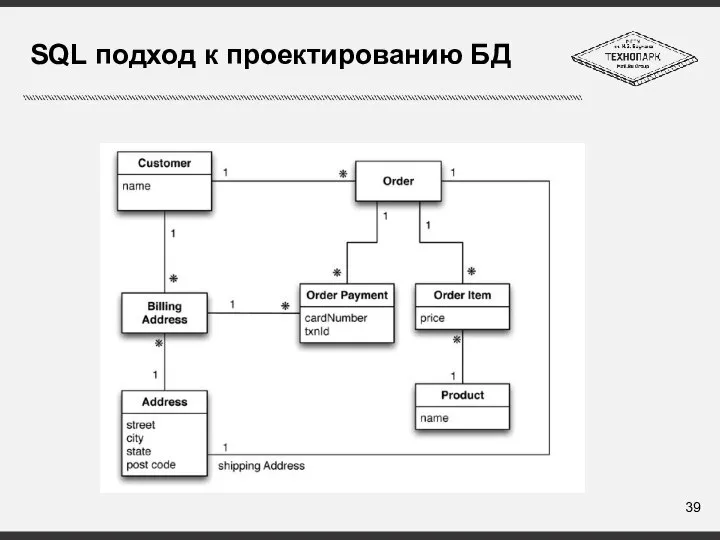
Слайд 39SQL подход к проектированию БД
SQL подход к проектированию БД
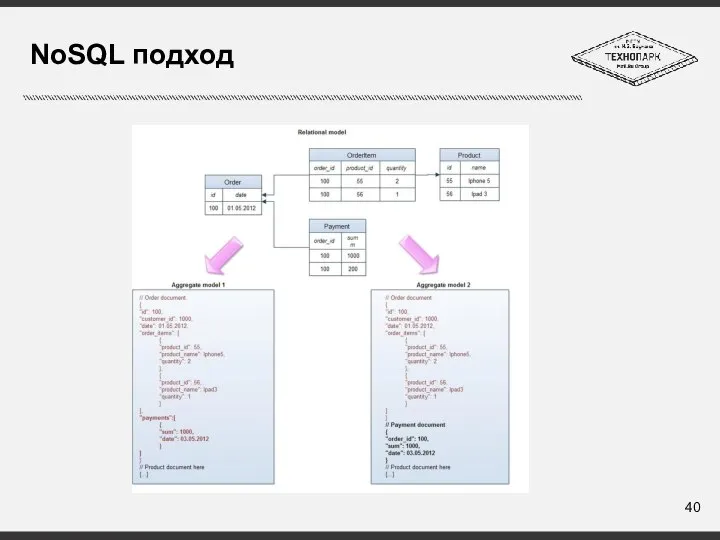
Слайд 40NoSQL подход
NoSQL подход
 Интернет вещей. Управление GPIO из WEB-браузера
Интернет вещей. Управление GPIO из WEB-браузера Кладбище рядом. Взаимный фарм хонора
Кладбище рядом. Взаимный фарм хонора История и современная парадигма информационной безопасности
История и современная парадигма информационной безопасности Страшные муки землян
Страшные муки землян Операционные Системы
Операционные Системы Misrosoft Excel. Основы работы с программой. Часть 2
Misrosoft Excel. Основы работы с программой. Часть 2 Виды угроз компьютерной информации
Виды угроз компьютерной информации ЯП. Приложения с базами данных
ЯП. Приложения с базами данных Хранение информации в компьютере
Хранение информации в компьютере Лекция 6_2019
Лекция 6_2019 Объединение компьютеров в локальную сеть
Объединение компьютеров в локальную сеть GNU Эмулятор данные и переходы
GNU Эмулятор данные и переходы Осуществление межпредметных связей с помощью программы Microsoft Excel. География России
Осуществление межпредметных связей с помощью программы Microsoft Excel. География России Внешний вид содержимого формы
Внешний вид содержимого формы Введение в контроль версий
Введение в контроль версий Базы данных. Системы управления базами данных и банками знаний
Базы данных. Системы управления базами данных и банками знаний Групповое вещание Multicasting
Групповое вещание Multicasting Как правильно оформить курсовую работу
Как правильно оформить курсовую работу Построение диаграмм в Excel
Построение диаграмм в Excel Функции. Решение задач
Функции. Решение задач Автор работы: учитель начальных классов МБОУ «Зензелинская СОШ» Лиманского района Астраханской области Пивоварова Анжела Анатол
Автор работы: учитель начальных классов МБОУ «Зензелинская СОШ» Лиманского района Астраханской области Пивоварова Анжела Анатол Microsoft Office. Краткая характеристика изученных программ
Microsoft Office. Краткая характеристика изученных программ Формирование каталога CТЕ для Портал поставщиков
Формирование каталога CТЕ для Портал поставщиков Изменение размера и шрифта текста в документе Microsoft Word. Урок 4
Изменение размера и шрифта текста в документе Microsoft Word. Урок 4 Село Каракулино — школа для обучающихся с ОВЗ
Село Каракулино — школа для обучающихся с ОВЗ Сервис для автоматического мониторинга и оповещения о предпочтительных пользователю сеансах в кинотеатре
Сервис для автоматического мониторинга и оповещения о предпочтительных пользователю сеансах в кинотеатре Симплекс метод
Симплекс метод Правила этикета в сети интернета
Правила этикета в сети интернета