- Системное программное обеспечение Таблицы идентификаторов

Содержание
- 2. Любая таблица идентификаторов состоит из набора полей, количество которых равно числу различных идентификаторов, найденных в исходной
- 3. Логарифмический поиск Искомый символ сравнивается с элементом в середине таблицы ( (N + 1)/2). Если этот
- 4. Алгоритм бинарного дерева Первый идентификатор поместить в вершину дерева. Шаг 1. Выбрать очередной идентификатор из входного
- 5. Шаг 5. Если у текущего узла существует левая вершина, то сделать ее текущим узлом и вернуться
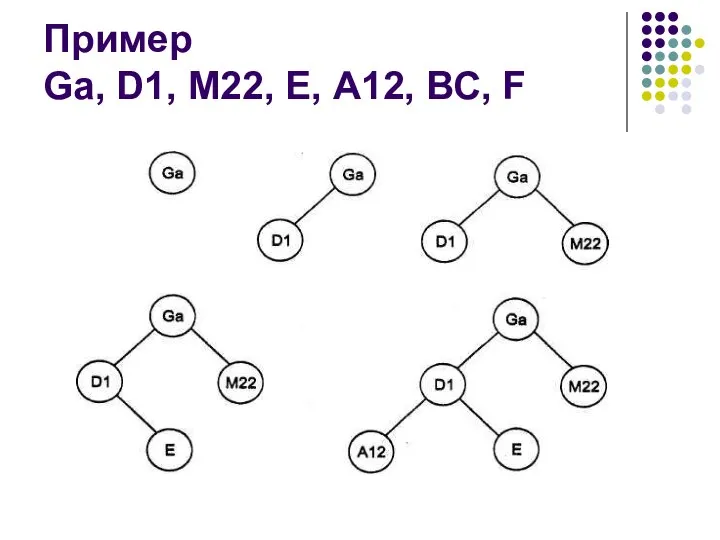
- 6. Пример Gа, D1, M22, Е, А12, ВС, F
- 8. Поиск нужного элемента в дереве Шаг 1. Сделать текущим узлом дерева корневую вершину. Шаг 2. Сравнить
- 9. Шаг 4. Если очередной идентификатор меньше, то перейти к шагу 5, иначе – к шагу 6.
- 10. Хэш-функция Хэш-функцией F называется некоторое отображение множества входных элементов R на множество целых неотрицательных чисел Хэш-адресация
- 11. Метод рехэширования Шаг 1. Вычислить значение хэш-функции n = h(A) для нового элемента А. Шаг 2.
- 12. Поиск элемента в таблице идентификаторов Шаг 1. Вычислить значение хэш-функции n = h(A) для искомого элемента
- 13. Метод цепочек Шаг 1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов пуста, переменная FreePtr
- 14. Шаг 4. Для ячейки таблицы идентификаторов по адресу mj проверить значение поля ссылки. Если оно пустое,
- 16. Скачать презентацию
Слайд 2 Любая таблица идентификаторов состоит
из набора полей, количество которых равно числу различных
Любая таблица идентификаторов состоит
из набора полей, количество которых равно числу различных

Слайд 3Логарифмический поиск
Искомый символ сравнивается с элементом в середине таблицы ( (N +
Логарифмический поиск
Искомый символ сравнивается с элементом в середине таблицы ( (N +

Слайд 4Алгоритм бинарного дерева
Первый идентификатор поместить в вершину дерева.
Шаг 1. Выбрать очередной
Алгоритм бинарного дерева
Первый идентификатор поместить в вершину дерева.
Шаг 1. Выбрать очередной

Слайд 5Шаг 5. Если у текущего узла существует левая вершина, то сделать ее
Шаг 5. Если у текущего узла существует левая вершина, то сделать ее

Слайд 6Пример
Gа, D1, M22, Е, А12, ВС, F
Пример
Gа, D1, M22, Е, А12, ВС, F
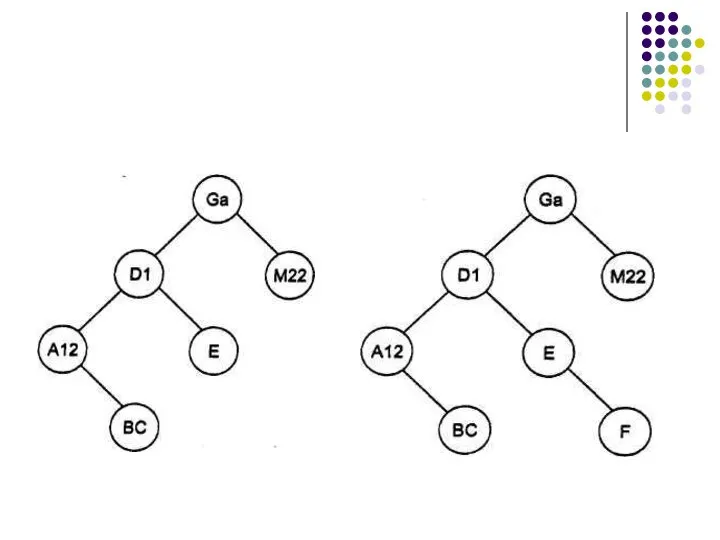
Слайд 8Поиск нужного элемента в дереве
Шаг 1. Сделать текущим узлом дерева корневую вершину.
Шаг
Поиск нужного элемента в дереве
Шаг 1. Сделать текущим узлом дерева корневую вершину.
Шаг

Слайд 9Шаг 4. Если очередной идентификатор меньше, то перейти к шагу 5, иначе
Шаг 4. Если очередной идентификатор меньше, то перейти к шагу 5, иначе

Слайд 10Хэш-функция
Хэш-функцией F называется некоторое отображение множества входных элементов R на множество целых
Хэш-функция
Хэш-функцией F называется некоторое отображение множества входных элементов R на множество целых

Слайд 11Метод рехэширования
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового
Метод рехэширования
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового

Слайд 12Поиск элемента в таблице идентификаторов
Шаг 1. Вычислить значение хэш-функции n =
Поиск элемента в таблице идентификаторов
Шаг 1. Вычислить значение хэш-функции n =

Слайд 13Метод цепочек
Шаг 1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов
Метод цепочек
Шаг 1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов

Слайд 14Шаг 4. Для ячейки таблицы идентификаторов по адресу mj проверить значение поля
Шаг 4. Для ячейки таблицы идентификаторов по адресу mj проверить значение поля

 7 советов как продвигать свой бизнес в YouTube
7 советов как продвигать свой бизнес в YouTube История серии видеоигры: Warhammer
История серии видеоигры: Warhammer Знакомьтесь – Маруся! Голосовой помощник, знающий все на свете
Знакомьтесь – Маруся! Голосовой помощник, знающий все на свете Access (Звіти). Лекція 7. Створення звітів
Access (Звіти). Лекція 7. Створення звітів Построение таблиц истинности
Построение таблиц истинности Персональный компьютер
Персональный компьютер Лаборатория онлайн бизнеса 2021
Лаборатория онлайн бизнеса 2021 Немонотонная логика. Лекция 6
Немонотонная логика. Лекция 6 Pick the note. Правила игры
Pick the note. Правила игры Аппаратное ПК
Аппаратное ПК Устройства компьютера: процессор и память
Устройства компьютера: процессор и память Опрос аудитории паблика OH MY HYPE
Опрос аудитории паблика OH MY HYPE Successful apps $1,000,000,000 case
Successful apps $1,000,000,000 case Журнал “Дружба народов”
Журнал “Дружба народов” Безопасный интернет
Безопасный интернет Сети. Основные понятия
Сети. Основные понятия тестирование смэв 2022
тестирование смэв 2022 Презентация на тему Поисковые системы
Презентация на тему Поисковые системы  История вычислительной техники
История вычислительной техники Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование Множества
Множества Программное системное обеспечение
Программное системное обеспечение Электронные таблицы: общие сведения
Электронные таблицы: общие сведения 17varAsemb
17varAsemb 267130(1)
267130(1) Формы представления информации
Формы представления информации Virtual Box. Виртуальная машина
Virtual Box. Виртуальная машина Анализ информационных моделей
Анализ информационных моделей