Спортивное программирование. Занятие 1. Языковые средства, поразрядные операции, эффективность, структуры данных
- Спортивное программирование. Занятие 1. Языковые средства, поразрядные операции, эффективность, структуры данных

Содержание
- 2. Языковые средства (ввод и вывод) В большинстве олимпиадных задач для ввода и вывода используются стандартные потоки.
- 3. Языковые средства (ввод и вывод) Входными данными для программы обычно являются числа и строки, разделенные пробелами
- 4. Языковые средства (ввод и вывод) Поток cout используется для вывода: #include #include using namespace std; int
- 5. Языковые средства (ввод и вывод) Ввод и вывод часто оказываются узкими местами программы. Чтобы повысить эффективность
- 6. Языковые средства (ввод и вывод) C-функции scanf и printf – альтернатива стандартным потокам C++. Обычно они
- 7. Ввод и вывод (вывод информации) Функция printf() предназначена для форматированного вывода. Она переводит данные в символьное
- 8. Ввод и вывод (вывод информации) СтрокаФорматов состоит из следующих элементов: управляющих символов; текста, представленного для непосредственного
- 9. Ввод и вывод (вывод информации) Управляющие символы не выводятся на экран, а управляют расположением выводимых символов.
- 10. Ввод и вывод (вывод информации) Форматы нужны для того, чтобы указывать вид, в котором информация будет
- 11. Ввод и вывод (вывод информации) %ld – целое число типа long int со знаком в десятичной
- 12. Ввод и вывод (вывод информации) Строка форматов содержит форматы для вывода значений. Каждый формат вывода начинается
- 13. Ввод и вывод (вывод информации) #include using namespace std; int main() { int a = 5;
- 14. Ввод и вывод (вывод информации) Тот же самый код может быть представлен с использованием одного вызова
- 15. Ввод и вывод (табличный вывод) При указании формата можно явным образом указать общее количество знакомест и
- 16. Ввод и вывод (табличный вывод) В приведенном примере 10 – общее количество знакомест, отводимое под значение
- 17. Ввод и вывод (ввод информации) Функция форматированного ввода данных с клавиатуры scanf() выполняет чтение данных, вводимых
- 18. Ввод и вывод (ввод информации) Строка форматов аналогична функции printf(). Для формирования адреса переменной используется символ
- 19. Ввод и вывод (ввод информации) #define _CRT_SECURE_NO_WARNINGS // для возможности использования scanf #include using namespace std;
- 20. Ввод и вывод (ввод информации) Функция scanf() является функцией незащищенного ввода, т.к. появилась она в ранних
- 21. Ввод и вывод (ввод информации) Другой вариант – воспользоваться функцией защищенного ввода scanf_s(), которая появилась несколько
- 22. Языковые средства (ввод и вывод) Иногда программа должна прочитать целую входную строку, быть может, содержащую пробелы.
- 23. Языковые средства (ввод и вывод) Если объем данных заранее неизвестен, то полезен такой цикл: while (cin
- 24. Языковые средства (ввод и вывод) В некоторых олимпиадных системах для ввода и вывода используются файлы. В
- 25. Языковые средства (работа с числами) Целые числа. Из целых типов в олимпиадном программировании чаще всего используется
- 26. Языковые средства (работа с числами) Ниже определена переменная типа long long: long long x = 123456789123456789LL;
- 27. Языковые средства (работа с числами) Типичная ошибка при использовании типа long long возникает, когда где-то в
- 28. Языковые средства (работа с числами) Арифметика по модулю. Иногда ответом является очень большое число, но достаточно
- 29. Языковые средства (работа с числами) Остаток x от деления на m обозначается x mod m. Например,
- 30. Языковые средства (работа с числами) Например, следующий код вычисляет n! (n факториал) по модулю m: long
- 31. Языковые средства (работа с числами) Обычно хочется, чтобы остаток находился в диапазоне 0…m − 1. Но
- 32. Языковые средства (работа с числами) Числа с плавающей точкой. В большинстве олимпиадных задач целых чисел достаточно,
- 33. Языковые средства (работа с числами) Требуемая точность ответа обычно указывается в формулировке задачи. Проще всего для
- 34. Языковые средства (работа с числами) С использованием чисел с плавающей точкой связана одна сложность: некоторые числа
- 35. Языковые средства (работа с числами) Числа с плавающей точкой рискованно сравнивать с помощью оператора ==, потому
- 36. Языковые средства (работа с числами) Хотя числа с плавающей точкой, вообще говоря, не точны, не слишком
- 37. Языковые средства (сокращение кода) Имена типов. Ключевое слово typedef позволяет сопоставить типу данных короткое имя. Например,
- 38. Языковые средства (сокращение кода) После этого код long long a = 123456789; long long b =
- 39. Языковые средства (сокращение кода) Ключевое слово typedef применимо и к более сложным типам. Например, ниже вектору
- 40. Языковые средства (сокращение кода) Макросы. Еще один способ сократить код – макросы. Макрос говорит, что определенные
- 41. Языковые средства (сокращение кода) Например, можно определить следующие макросы: #define F first #define S second #define
- 42. Языковые средства (сокращение кода) После чего код v.push_back(make_pair(y1, x1)); v.push_back(make_pair(y2, x2)); int d = v[i].first +
- 43. Языковые средства (сокращение кода) У макроса могут быть параметры, что позволяет сокращать циклы и другие структуры.
- 44. Языковые средства (сокращение кода) После этого код for (int i = 1; i search(i); } можно
- 45. Поразрядные операции В программировании n-разрядное целое число хранится в виде двоичного числа, содержащего n бит. Например,
- 46. Поразрядные операции Биты в этом представлении нумеруются справа налево. Преобразование двоичного представления bk … b2b1b0 в
- 47. Поразрядные операции Двоичное представление числа может быть со знаком и без знака. Обычно используется представление со
- 48. Поразрядные операции Первый разряд в представлении со знаком содержит знак числа (0 для неотрицательных чисел, 1
- 49. Поразрядные операции Представление без знака позволяет представить только неотрицательные числа, но верхняя граница диапазона больше. n-разрядная
- 50. Поразрядные операции Между обоими представлениям существует связь: число со знаком –x равно числу без знака 2n
- 51. Поразрядные операции Если число больше верхней границы допустимого диапазона, то возникает переполнение. В представлении со знаком
- 52. Поразрядные операции Операция И. Результатом операции И x & y является число, двоичное представление которого содержит
- 53. Поразрядные операции Операция ИЛИ. Результатом операции ИЛИ x | y является число, двоичное представление которого содержит
- 54. Поразрядные операции Операция ИСКЛЮЧАЮЩЕЕ ИЛИ. Результатом операции ИСКЛЮЧАЮЩЕЕ ИЛИ x ^ y является число, двоичное представление
- 55. Поразрядные операции Операция НЕ. Результатом операции НЕ ~x является число, в двоичном представлении которого все биты
- 56. Поразрядные операции Поразрядный сдвиг. Операция поразрядного сдвига влево x > k удаляет k последних бит. Например,
- 57. Поразрядные операции Битовые маски. Битовой маской называется число вида 1 for (int k = 31; k
- 58. Поразрядные операции Аналогичным образом можно модифицировать отдельные биты числа. Выражение x | (1
- 59. Поразрядные операции При работе с битовыми масками нужно помнить, что 1
- 60. Эффективность (временная сложность) Временная сложность алгоритма – это оценка того, сколько времени будет работать алгоритм при
- 61. Эффективность (временная сложность) Для описания временной сложности применяется нотация O(…), где многоточием представлена некоторая функция. Обычно
- 62. Эффективность (временная сложность) Если код включает только линейную последовательность команд, как, например, показанный ниже, то его
- 63. Эффективность (временная сложность) Временная сложность цикла оценивает число выполненных итераций. Например, временная сложность следующего кода равна
- 64. Эффективность (временная сложность) Временная сложность следующего кода равна O(n2): for (int i = 1; i for
- 65. Эффективность (временная сложность) Временная сложность следующего кода равна O(n2): for (int i = 1; i for
- 66. Эффективность (временная сложность) Временная сложность не сообщает, сколько точно раз выполняется код внутри цикла, она показывает
- 67. Эффективность (временная сложность) С другой стороны, временная сложность следующего кода равна O(n2), поскольку код внутри цикла
- 68. Эффективность (временная сложность) Если алгоритм состоит из нескольких последовательных частей, то общая временная сложность равна максимуму
- 69. Эффективность (временная сложность) Иногда временная сложность зависит от нескольких факторов, поэтому формула включает несколько переменных. Например,
- 70. Эффективность (временная сложность) Временная сложность рекурсивной функции зависит от того, сколько раз она вызывается, и от
- 71. Эффективность (временная сложность) В качестве еще одного примера рассмотрим следующую функцию: void g(int n) { if
- 72. Эффективность (временная сложность) Далее перечислены часто встречающиеся оценки временной сложности алгоритмов. O(1) Время работы алгоритма с
- 73. Эффективность (временная сложность) O(log n) В логарифмическом алгоритме размер входных данных на каждом шаге обычно уменьшается
- 74. Эффективность (временная сложность)
- 75. Эффективность (временная сложность) O(n) Линейный алгоритм перебирает входные данные постоянное число раз. Зачастую это наилучшая возможная
- 76. Эффективность (временная сложность) O(n log n) Такая временная сложность часто означает, что алгоритм сортирует входные данные,
- 77. Эффективность (временная сложность) O(n2) Квадратичный алгоритм нередко содержит два вложенных цикла. Перебрать все пары входных элементов
- 78. Эффективность (временная сложность) O(n3) Кубический алгоритм часто содержит три вложенных цикла. Все тройки входных элементов можно
- 79. Эффективность (временная сложность) O(2n) Такая временная сложность нередко указывает на то, что алгоритм перебирает все подмножества
- 80. Эффективность (временная сложность) O(n!) Такая временная сложность часто означает, что алгоритм перебирает все перестановки входных элементов.
- 81. Эффективность (временная сложность) Алгоритм называется полиномиальным, если его временная сложность не выше O(nK), где k –
- 82. Эффективность (временная сложность) Существует много важных задач, для которых полиномиальный алгоритм неизвестен, т. е. никто не
- 83. Эффективность (временная сложность) Вычислив временную сложность алгоритма, можно еще до его реализации проверить, будет ли он
- 84. Эффективность (временная сложность) Например, предположим, что для задачи установлено временное ограничение – не более одной секунды
- 85. Эффективность (временная сложность) С другой стороны, зная размер входных данных, можно попытаться угадать временную сложность алгоритма,
- 86. Эффективность (временная сложность) Например, если размер входных данных n = 105, то, вероятно, можно ожидать, что
- 87. Эффективность (временная сложность) Важно помнить, что временная сложность – всего лишь оценка эффективности, поскольку она скрывает
- 88. Эффективность (временная сложность) Что в действительности означают слова «время работы алгоритма составляет O(f (n))»? Что существуют
- 89. Эффективность (временная сложность) Например, технически правильно будет сказать, что временная сложность следующего алгоритма равна O(n2). for
- 90. Эффективность (временная сложность) На практике часто применяются еще два варианта нотации. Буквой Ω обозначается нижняя граница
- 91. Эффективность (временная сложность) Описанная нотация используется во многих ситуациях, а не только в контексте временной сложности
- 92. Эффективность (пример) Обсудим задачу, которую можно решить несколькими способами. Начнем с простого алгоритма с полным перебором,
- 93. Эффективность (пример) Пусть дан массив n чисел; задача заключается в том, чтобы вычислить максимальную сумму подмассивов,
- 94. Эффективность (пример) Решение со сложностью O(n3). Задачу можно решить в лоб: перебрать все возможные подмассивы, вычислить
- 95. Эффективность (пример) Решение со сложностью O(n2). Алгоритм легко сделать более эффективным, исключив один цикл. Для этого
- 96. Эффективность (пример) Решение со сложностью O(n). Оказывается, что задачу можно решить и за время O(n), т.
- 97. Эффективность (пример) Алгоритм реализуется следующей программой: int best = 0, sum = 0; for (int k
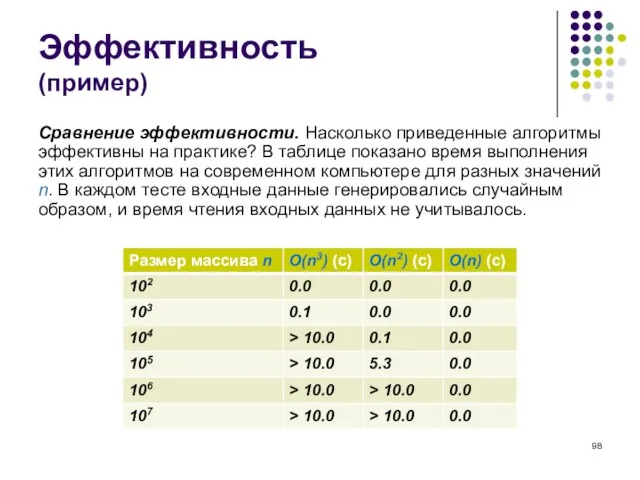
- 98. Эффективность (пример) Сравнение эффективности. Насколько приведенные алгоритмы эффективны на практике? В таблице показано время выполнения этих
- 99. Эффективность (пример) Сравнение показывает, что все алгоритмы работают быстро, если размер входных данных мал, но по
- 100. Структуры данных Познакомимся с наиболее важными структурами данных из стандартной библиотеки C++. В олимпиадном программировании чрезвычайно
- 101. Структуры данных В C++ обыкновенные массивы – это структуры фиксированного размера, т. е. после создания изменить
- 102. Структуры данных Динамическим называется массив, размер которого можно изменять в процессе выполнения программы. В стандартной библиотеке
- 103. Структуры данных (динамические массивы) Вектор – это динамический массив, который позволяет эффективно добавлять элементы в конце
- 104. Структуры данных (динамические массивы) Доступ к элементам осуществляется так же, как в обычном массиве: cout cout
- 105. Структуры данных (динамические массивы) Еще один способ создать вектор – перечислить все его элементы: vector v
- 106. Структуры данных (динамические массивы) Можно также задать число элементов и их начальное значение: vector a(8); //
- 107. Структуры данных (динамические массивы) Функция size возвращает число элементов вектора. В следующем коде обходится вектор и
- 108. Структуры данных (динамические массивы) Обход вектора можно записать и короче: for (auto x : v) {
- 109. Структуры данных (динамические массивы) Функция back возвращает последний элемент вектора, а функция pop_back удаляет последний элемент:
- 110. Структуры данных (динамические массивы) Векторы реализованы так, что функции push_back и pop_back в среднем имеют сложность
- 111. Структуры данных (динамические массивы) Итератором называется переменная, которая указывает на элемент структуры данных. Итератор begin указывает
- 112. Структуры данных (динамические массивы) Обратите внимание на асимметрию итераторов: begin() указывает на элемент, принадлежащий структуре данных,
- 113. Структуры данных (динамические массивы) Диапазоном называется последовательность соседних элементов структуры данных. Чаще всего диапазон задается с
- 114. Структуры данных (динамические массивы) Функции из стандартной библиотеки C++ обычно применяются к диапазонам. Так, в следующем
- 115. Структуры данных (динамические массивы) К элементу, на который указывает итератор, можно обратиться, воспользовавшись оператором *. В
- 116. Структуры данных (динамические массивы) Более полезный пример: функция lower_bound возвращает итератор на первый элемент отсортированного диапазона,
- 117. Структуры данных (динамические массивы) Отметим, что эти функции правильно работают, только если заданный диапазон отсортирован. В
- 118. Структуры данных (динамические массивы) В стандартной библиотеке C++ много полезных функций, заслуживающих внимания. Например, в следующем
- 119. Структуры данных (динамические массивы) Двусторонней очередью (деком) называется динамический массив, допускающий эффективные операции с обеих сторон.
- 120. Структуры данных (динамические массивы) Операции двусторонней очереди в среднем имеют сложность O(1). Однако постоянные множители для
- 121. Структуры данных (динамические массивы) C++ предоставляет также специализированные структуры данных, по умолчанию основанные на двусторонней очереди.
- 122. Структуры данных (динамические массивы) В случае очереди элементы вставляются в начало, а удаляются из конца. Для
- 123. Структуры данных (множества) Множеством называется структура данных, в которой хранится набор элементов. Основные операции над множествами
- 124. Структуры данных (множества) В стандартной библиотеке C++ имеются две структуры, относящиеся к множествам: set основана на
- 125. Структуры данных (множества) Обе структуры эффективны, и во многих случаях годится любая. Поскольку используются они одинаково,
- 126. Структуры данных (множества) В показанном ниже коде создается множество, содержащее целые числа, и демонстрируются некоторые его
- 127. Структуры данных (множества) Важным свойством множеств является тот факт, что все их элементы различны. Следовательно, функция
- 128. Структуры данных (множества) Множество в основном можно использовать как вектор, однако доступ к элементам с помощью
- 129. Структуры данных (множества) Функция find(x) возвращает итератор, указывающий на элемент со значением x. Если же множество
- 130. Структуры данных (множества) Упорядоченные множества. Основное различие между двумя структурами множества в C++ – то, что
- 131. Структуры данных (множества) Рассмотрим задачу о нахождении наименьшего и наибольшего значений во множестве. Чтобы сделать это
- 132. Структуры данных (множества) В структуре set имеются также функции lower_bound(x) и upper_bound(x), которые возвращают итератор на
- 133. Структуры данных (множества) Мультимножества. В отличие от множества, в мультимножество один и тот же элемент может
- 134. Структуры данных (множества) Функция erase удаляет все копии значения из мультимножества. s.erase(5); cout
- 135. Структуры данных (множества) Если требуется удалить только одно значение, то можно поступить так: s.erase(s.find(5)); cout
- 136. Структуры данных (множества) Отметим, что во временной сложности функций count и erase имеется дополнительный множитель O(k),
- 137. Структуры данных (множества) Отображением называется множество, состоящее из пар ключ-значение. Отображение можно также рассматривать как обобщение
- 138. Структуры данных (множества) В стандартной библиотеке C++ есть две структуры отображений, соответствующие структурам множеств: в основе
- 139. Структуры данных (множества) В следующем фрагменте создается отображение, ключами которого являются строки, а значениями – целые
- 140. Структуры данных (множества) Если в отображении нет запрошенного ключа, то он автоматически добавляется, и ему сопоставляется
- 141. Структуры данных (множества) Функция count проверяет, существует ли ключ в отображении: if (m.count("aybabtu")) { // ключ
- 142. Структуры данных (множества) В следующем коде печатаются все имеющиеся в отображении ключи и значения: for (auto
- 143. Структуры данных (эксперименты) Хотя временная сложность – отличный инструмент, она не всегда сообщает всю правду об
- 144. Структуры данных (эксперименты) Многие задачи можно решить, применяя как множества, так и сортировку. Важно понимать, что
- 145. Структуры данных (эксперименты) В качестве примера рассмотрим задачу о вычислении количества уникальных элементов вектора. Одно из
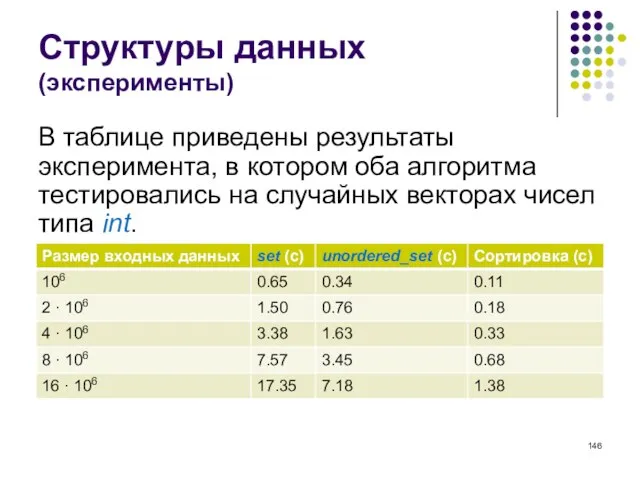
- 146. Структуры данных (эксперименты) В таблице приведены результаты эксперимента, в котором оба алгоритма тестировались на случайных векторах
- 147. Структуры данных (эксперименты) Оказалось, что алгоритм на основе unordered_set примерно в два раза быстрее алгоритма на
- 148. Структуры данных (эксперименты) Отображения – удобные структуры данных, по сравнению с массивами, поскольку позволяют использовать индексы
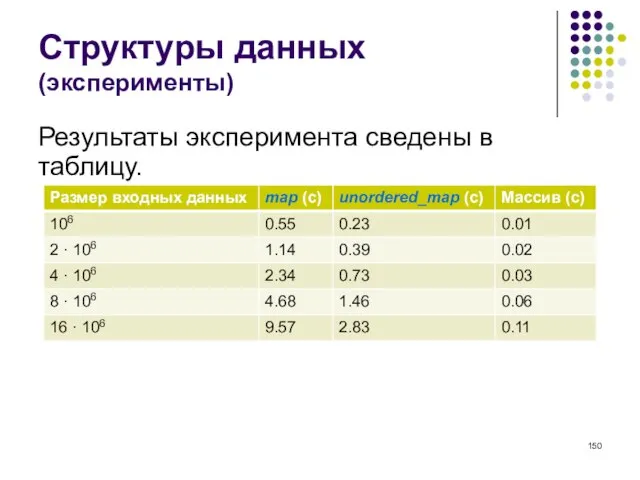
- 149. Структуры данных (эксперименты) Результаты эксперимента сведены в таблицу. Хотя unordered_map примерно в три раза быстрее map,
- 150. Структуры данных (эксперименты) Результаты эксперимента сведены в таблицу.
- 151. Структуры данных (эксперименты) Хотя unordered_map примерно в три раза быстрее map, массив все равно почти в
- 152. Структуры данных (эксперименты) Верно ли, что очереди с приоритетом действительно быстрее мультимножеств? Чтобы выяснить это, проведем
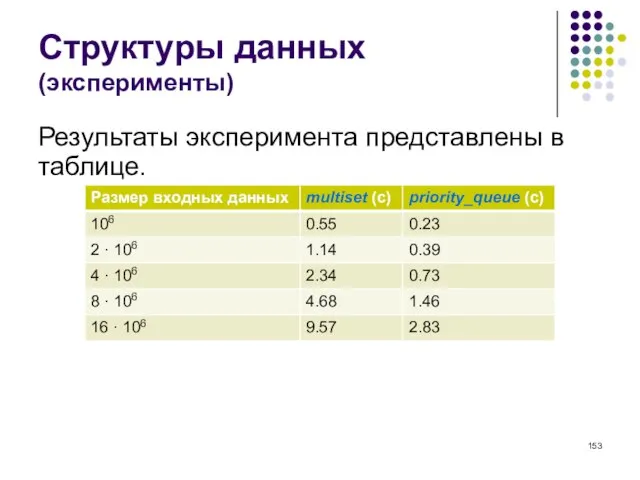
- 153. Структуры данных (эксперименты) Результаты эксперимента представлены в таблице.
- 155. Скачать презентацию

Слайд 3Языковые средства
(ввод и вывод)
Входными данными для программы обычно являются числа и
Языковые средства
(ввод и вывод)
Входными данными для программы обычно являются числа и

Слайд 4Языковые средства
(ввод и вывод)
Поток cout используется для вывода:
#include
#include
using namespace
Языковые средства
(ввод и вывод)
Поток cout используется для вывода:
#include
#include
using namespace

Слайд 5Языковые средства
(ввод и вывод)
Ввод и вывод часто оказываются узкими местами программы.
Языковые средства
(ввод и вывод)
Ввод и вывод часто оказываются узкими местами программы.

Слайд 6Языковые средства
(ввод и вывод)
C-функции scanf и printf – альтернатива стандартным потокам
Языковые средства
(ввод и вывод)
C-функции scanf и printf – альтернатива стандартным потокам

Слайд 7Ввод и вывод
(вывод информации)
Функция printf() предназначена для форматированного вывода. Она переводит данные
Ввод и вывод
(вывод информации)
Функция printf() предназначена для форматированного вывода. Она переводит данные

Слайд 8Ввод и вывод
(вывод информации)
СтрокаФорматов состоит из следующих элементов:
управляющих символов;
текста, представленного для непосредственного
Ввод и вывод
(вывод информации)
СтрокаФорматов состоит из следующих элементов:
управляющих символов;
текста, представленного для непосредственного

Слайд 9Ввод и вывод
(вывод информации)
Управляющие символы не выводятся на экран, а управляют расположением
Ввод и вывод
(вывод информации)
Управляющие символы не выводятся на экран, а управляют расположением

Слайд 10Ввод и вывод
(вывод информации)
Форматы нужны для того, чтобы указывать вид, в котором
Ввод и вывод
(вывод информации)
Форматы нужны для того, чтобы указывать вид, в котором

Слайд 11Ввод и вывод
(вывод информации)
%ld – целое число типа long int со знаком
Ввод и вывод
(вывод информации)
%ld – целое число типа long int со знаком

Слайд 12Ввод и вывод
(вывод информации)
Строка форматов содержит форматы для вывода значений. Каждый формат
Ввод и вывод
(вывод информации)
Строка форматов содержит форматы для вывода значений. Каждый формат

Слайд 13Ввод и вывод
(вывод информации)
#include
using namespace std;
int main() {
int a = 5;
float
Ввод и вывод
(вывод информации)
#include
using namespace std;
int main() {
int a = 5;
float

Слайд 14Ввод и вывод
(вывод информации)
Тот же самый код может быть представлен с использованием
Ввод и вывод
(вывод информации)
Тот же самый код может быть представлен с использованием

Слайд 15Ввод и вывод
(табличный вывод)
При указании формата можно явным образом указать общее количество
Ввод и вывод
(табличный вывод)
При указании формата можно явным образом указать общее количество

Слайд 16Ввод и вывод
(табличный вывод)
В приведенном примере 10 – общее количество знакомест, отводимое
Ввод и вывод
(табличный вывод)
В приведенном примере 10 – общее количество знакомест, отводимое

Слайд 17Ввод и вывод
(ввод информации)
Функция форматированного ввода данных с клавиатуры scanf() выполняет чтение
Ввод и вывод
(ввод информации)
Функция форматированного ввода данных с клавиатуры scanf() выполняет чтение

Слайд 18Ввод и вывод
(ввод информации)
Строка форматов аналогична функции printf().
Для формирования адреса переменной используется
Ввод и вывод
(ввод информации)
Строка форматов аналогична функции printf().
Для формирования адреса переменной используется

Слайд 19Ввод и вывод
(ввод информации)
#define _CRT_SECURE_NO_WARNINGS // для возможности использования scanf
#include
using namespace
Ввод и вывод
(ввод информации)
#define _CRT_SECURE_NO_WARNINGS // для возможности использования scanf
#include
using namespace

Слайд 20Ввод и вывод
(ввод информации)
Функция scanf() является функцией незащищенного ввода, т.к. появилась она
Ввод и вывод
(ввод информации)
Функция scanf() является функцией незащищенного ввода, т.к. появилась она

Слайд 21Ввод и вывод
(ввод информации)
Другой вариант – воспользоваться функцией защищенного ввода scanf_s(), которая
Ввод и вывод
(ввод информации)
Другой вариант – воспользоваться функцией защищенного ввода scanf_s(), которая

Слайд 22Языковые средства
(ввод и вывод)
Иногда программа должна прочитать целую входную строку, быть может,
Языковые средства
(ввод и вывод)
Иногда программа должна прочитать целую входную строку, быть может,

Слайд 23Языковые средства
(ввод и вывод)
Если объем данных заранее неизвестен, то полезен такой цикл:
while
Языковые средства
(ввод и вывод)
Если объем данных заранее неизвестен, то полезен такой цикл:
while

Слайд 24Языковые средства
(ввод и вывод)
В некоторых олимпиадных системах для ввода и вывода используются
Языковые средства
(ввод и вывод)
В некоторых олимпиадных системах для ввода и вывода используются

Слайд 25Языковые средства
(работа с числами)
Целые числа. Из целых типов в олимпиадном программировании чаще
Языковые средства
(работа с числами)
Целые числа. Из целых типов в олимпиадном программировании чаще

Слайд 26Языковые средства
(работа с числами)
Ниже определена переменная типа long long:
long long x =
Языковые средства
(работа с числами)
Ниже определена переменная типа long long:
long long x =

Слайд 27Языковые средства
(работа с числами)
Типичная ошибка при использовании типа long long возникает, когда
Языковые средства
(работа с числами)
Типичная ошибка при использовании типа long long возникает, когда

Слайд 28Языковые средства
(работа с числами)
Арифметика по модулю. Иногда ответом является очень большое число,
Языковые средства
(работа с числами)
Арифметика по модулю. Иногда ответом является очень большое число,

Слайд 29Языковые средства
(работа с числами)
Остаток x от деления на m обозначается
x mod
Языковые средства
(работа с числами)
Остаток x от деления на m обозначается x mod

Слайд 30Языковые средства
(работа с числами)
Например, следующий код вычисляет n! (n факториал) по модулю
Языковые средства
(работа с числами)
Например, следующий код вычисляет n! (n факториал) по модулю

Слайд 31Языковые средства
(работа с числами)
Обычно хочется, чтобы остаток находился в диапазоне 0…m −
Языковые средства
(работа с числами)
Обычно хочется, чтобы остаток находился в диапазоне 0…m −

Слайд 32Языковые средства
(работа с числами)
Числа с плавающей точкой. В большинстве олимпиадных задач целых
Языковые средства
(работа с числами)
Числа с плавающей точкой. В большинстве олимпиадных задач целых

Слайд 33Языковые средства
(работа с числами)
Требуемая точность ответа обычно указывается в формулировке задачи. Проще
Языковые средства
(работа с числами)
Требуемая точность ответа обычно указывается в формулировке задачи. Проще

Слайд 34Языковые средства
(работа с числами)
С использованием чисел с плавающей точкой связана одна сложность:
Языковые средства
(работа с числами)
С использованием чисел с плавающей точкой связана одна сложность:

Слайд 35Языковые средства
(работа с числами)
Числа с плавающей точкой рискованно сравнивать с помощью оператора
Языковые средства
(работа с числами)
Числа с плавающей точкой рискованно сравнивать с помощью оператора

Слайд 36Языковые средства
(работа с числами)
Хотя числа с плавающей точкой, вообще говоря, не точны,
Языковые средства
(работа с числами)
Хотя числа с плавающей точкой, вообще говоря, не точны,

Слайд 37Языковые средства
(сокращение кода)
Имена типов. Ключевое слово typedef позволяет сопоставить типу данных короткое
Языковые средства
(сокращение кода)
Имена типов. Ключевое слово typedef позволяет сопоставить типу данных короткое

Слайд 38Языковые средства
(сокращение кода)
После этого код
long long a = 123456789;
long long b =
Языковые средства
(сокращение кода)
После этого код
long long a = 123456789;
long long b =

Слайд 39Языковые средства
(сокращение кода)
Ключевое слово typedef применимо и к более сложным типам. Например,
Языковые средства
(сокращение кода)
Ключевое слово typedef применимо и к более сложным типам. Например,

Слайд 40Языковые средства
(сокращение кода)
Макросы. Еще один способ сократить
код – макросы. Макрос говорит,
Языковые средства
(сокращение кода)
Макросы. Еще один способ сократить код – макросы. Макрос говорит,

Слайд 41Языковые средства
(сокращение кода)
Например, можно определить следующие макросы:
#define F first
#define S second
#define PB
Языковые средства
(сокращение кода)
Например, можно определить следующие макросы:
#define F first
#define S second
#define PB

Слайд 42Языковые средства
(сокращение кода)
После чего код
v.push_back(make_pair(y1, x1));
v.push_back(make_pair(y2, x2));
int d = v[i].first + v[i].second;
можно
Языковые средства
(сокращение кода)
После чего код
v.push_back(make_pair(y1, x1));
v.push_back(make_pair(y2, x2));
int d = v[i].first + v[i].second;
можно

Слайд 43Языковые средства
(сокращение кода)
У макроса могут быть параметры, что позволяет сокращать циклы и
Языковые средства
(сокращение кода)
У макроса могут быть параметры, что позволяет сокращать циклы и

Слайд 44Языковые средства
(сокращение кода)
После этого код
for (int i = 1; i <= n;
Языковые средства
(сокращение кода)
После этого код
for (int i = 1; i <= n;

Слайд 45Поразрядные операции
В программировании n-разрядное целое число хранится в виде двоичного числа, содержащего
Поразрядные операции
В программировании n-разрядное целое число хранится в виде двоичного числа, содержащего

Слайд 46Поразрядные операции
Биты в этом представлении нумеруются справа налево. Преобразование двоичного представления bk
Поразрядные операции
Биты в этом представлении нумеруются справа налево. Преобразование двоичного представления bk

Слайд 47Поразрядные операции
Двоичное представление числа может быть со знаком и без знака. Обычно
Поразрядные операции
Двоичное представление числа может быть со знаком и без знака. Обычно

Слайд 48Поразрядные операции
Первый разряд в представлении со знаком содержит знак числа (0 для
Поразрядные операции
Первый разряд в представлении со знаком содержит знак числа (0 для

Слайд 49Поразрядные операции
Представление без знака позволяет представить только неотрицательные числа, но верхняя граница
Поразрядные операции
Представление без знака позволяет представить только неотрицательные числа, но верхняя граница

Слайд 50Поразрядные операции
Между обоими представлениям существует связь: число со знаком –x равно числу
Поразрядные операции
Между обоими представлениям существует связь: число со знаком –x равно числу

Слайд 51Поразрядные операции
Если число больше верхней границы допустимого диапазона, то возникает переполнение. В
Поразрядные операции
Если число больше верхней границы допустимого диапазона, то возникает переполнение. В

Слайд 52Поразрядные операции
Операция И. Результатом операции И x & y является число, двоичное
Поразрядные операции
Операция И. Результатом операции И x & y является число, двоичное

Слайд 53Поразрядные операции
Операция ИЛИ. Результатом операции ИЛИ x | y является число, двоичное
Поразрядные операции
Операция ИЛИ. Результатом операции ИЛИ x | y является число, двоичное

Слайд 54Поразрядные операции
Операция ИСКЛЮЧАЮЩЕЕ ИЛИ. Результатом операции ИСКЛЮЧАЮЩЕЕ ИЛИ x ^ y является
Поразрядные операции
Операция ИСКЛЮЧАЮЩЕЕ ИЛИ. Результатом операции ИСКЛЮЧАЮЩЕЕ ИЛИ x ^ y является

Слайд 55Поразрядные операции
Операция НЕ. Результатом операции НЕ ~x является число, в двоичном представлении
Поразрядные операции
Операция НЕ. Результатом операции НЕ ~x является число, в двоичном представлении

Слайд 56Поразрядные операции
Поразрядный сдвиг. Операция поразрядного сдвига влево x << k дописывает в
Поразрядные операции
Поразрядный сдвиг. Операция поразрядного сдвига влево x << k дописывает в

Слайд 57Поразрядные операции
Битовые маски. Битовой маской называется число вида 1 << k, содержащее
Поразрядные операции
Битовые маски. Битовой маской называется число вида 1 << k, содержащее

Слайд 58Поразрядные операции
Аналогичным образом можно модифицировать отдельные биты числа. Выражение x | (1
Поразрядные операции
Аналогичным образом можно модифицировать отдельные биты числа. Выражение x | (1

Слайд 59Поразрядные операции
При работе с битовыми масками нужно помнить, что 1<
Поразрядные операции
При работе с битовыми масками нужно помнить, что 1<
Слайд 60Эффективность
(временная сложность)
Временная сложность алгоритма – это оценка того, сколько времени будет работать
Эффективность
(временная сложность)
Временная сложность алгоритма – это оценка того, сколько времени будет работать

Слайд 61Эффективность
(временная сложность)
Для описания временной сложности применяется нотация O(…), где многоточием представлена некоторая
Эффективность
(временная сложность)
Для описания временной сложности применяется нотация O(…), где многоточием представлена некоторая

Слайд 62Эффективность
(временная сложность)
Если код включает только линейную последовательность команд, как, например, показанный ниже,
Эффективность
(временная сложность)
Если код включает только линейную последовательность команд, как, например, показанный ниже,

Слайд 63Эффективность
(временная сложность)
Временная сложность цикла оценивает число выполненных итераций. Например, временная сложность следующего
Эффективность
(временная сложность)
Временная сложность цикла оценивает число выполненных итераций. Например, временная сложность следующего

Слайд 64Эффективность
(временная сложность)
Временная сложность следующего кода равна O(n2):
for (int i = 1; i
Эффективность
(временная сложность)
Временная сложность следующего кода равна O(n2):
for (int i = 1; i

Слайд 65Эффективность
(временная сложность)
Временная сложность следующего кода равна O(n2):
for (int i = 1; i
Эффективность
(временная сложность)
Временная сложность следующего кода равна O(n2):
for (int i = 1; i

Слайд 66Эффективность
(временная сложность)
Временная сложность не сообщает, сколько точно раз выполняется код внутри цикла,
Эффективность
(временная сложность)
Временная сложность не сообщает, сколько точно раз выполняется код внутри цикла,

Слайд 67Эффективность
(временная сложность)
С другой стороны, временная сложность следующего кода равна O(n2), поскольку код
Эффективность
(временная сложность)
С другой стороны, временная сложность следующего кода равна O(n2), поскольку код

Слайд 68Эффективность
(временная сложность)
Если алгоритм состоит из нескольких последовательных частей, то общая временная сложность
Эффективность
(временная сложность)
Если алгоритм состоит из нескольких последовательных частей, то общая временная сложность

Слайд 69Эффективность
(временная сложность)
Иногда временная сложность зависит от нескольких факторов, поэтому формула включает несколько
Эффективность
(временная сложность)
Иногда временная сложность зависит от нескольких факторов, поэтому формула включает несколько

Слайд 70Эффективность
(временная сложность)
Временная сложность рекурсивной функции зависит от того, сколько раз она вызывается,
Эффективность
(временная сложность)
Временная сложность рекурсивной функции зависит от того, сколько раз она вызывается,

Слайд 71Эффективность
(временная сложность)
В качестве еще одного примера рассмотрим следующую функцию:
void g(int n) {
if
Эффективность
(временная сложность)
В качестве еще одного примера рассмотрим следующую функцию:
void g(int n) {
if

Слайд 72Эффективность
(временная сложность)
Далее перечислены часто встречающиеся оценки временной сложности алгоритмов.
O(1) Время работы алгоритма
Эффективность
(временная сложность)
Далее перечислены часто встречающиеся оценки временной сложности алгоритмов.
O(1) Время работы алгоритма

Слайд 73Эффективность
(временная сложность)
O(log n) В логарифмическом алгоритме размер входных данных на каждом шаге
Эффективность
(временная сложность)
O(log n) В логарифмическом алгоритме размер входных данных на каждом шаге

Слайд 74Эффективность
(временная сложность)
Эффективность
(временная сложность)

Слайд 75Эффективность
(временная сложность)
O(n) Линейный алгоритм перебирает входные данные постоянное число раз. Зачастую это
Эффективность
(временная сложность)
O(n) Линейный алгоритм перебирает входные данные постоянное число раз. Зачастую это

Слайд 76Эффективность
(временная сложность)
O(n log n) Такая временная сложность часто означает, что алгоритм сортирует
Эффективность
(временная сложность)
O(n log n) Такая временная сложность часто означает, что алгоритм сортирует

Слайд 77Эффективность
(временная сложность)
O(n2) Квадратичный алгоритм нередко содержит два вложенных цикла. Перебрать все пары
Эффективность
(временная сложность)
O(n2) Квадратичный алгоритм нередко содержит два вложенных цикла. Перебрать все пары

Слайд 78Эффективность
(временная сложность)
O(n3) Кубический алгоритм часто содержит три вложенных цикла. Все тройки входных
Эффективность
(временная сложность)
O(n3) Кубический алгоритм часто содержит три вложенных цикла. Все тройки входных

Слайд 79Эффективность
(временная сложность)
O(2n) Такая временная сложность нередко указывает на то, что алгоритм перебирает
Эффективность
(временная сложность)
O(2n) Такая временная сложность нередко указывает на то, что алгоритм перебирает

Слайд 80Эффективность
(временная сложность)
O(n!) Такая временная сложность часто означает, что алгоритм перебирает все перестановки
Эффективность
(временная сложность)
O(n!) Такая временная сложность часто означает, что алгоритм перебирает все перестановки

Слайд 81Эффективность
(временная сложность)
Алгоритм называется полиномиальным, если его временная сложность не выше O(nK), где
Эффективность
(временная сложность)
Алгоритм называется полиномиальным, если его временная сложность не выше O(nK), где

Слайд 82Эффективность
(временная сложность)
Существует много важных задач, для которых полиномиальный алгоритм неизвестен, т. е.
Эффективность
(временная сложность)
Существует много важных задач, для которых полиномиальный алгоритм неизвестен, т. е.

Слайд 83Эффективность
(временная сложность)
Вычислив временную сложность алгоритма, можно еще до его реализации проверить, будет
Эффективность
(временная сложность)
Вычислив временную сложность алгоритма, можно еще до его реализации проверить, будет

Слайд 84Эффективность
(временная сложность)
Например, предположим, что для задачи установлено временное ограничение – не более
Эффективность
(временная сложность)
Например, предположим, что для задачи установлено временное ограничение – не более

Слайд 85Эффективность
(временная сложность)
С другой стороны, зная размер входных данных, можно попытаться угадать временную
Эффективность
(временная сложность)
С другой стороны, зная размер входных данных, можно попытаться угадать временную

Слайд 86Эффективность
(временная сложность)
Например, если размер входных данных
n = 105, то, вероятно, можно
Эффективность
(временная сложность)
Например, если размер входных данных n = 105, то, вероятно, можно

Слайд 87Эффективность
(временная сложность)
Важно помнить, что временная
сложность – всего лишь оценка эффективности, поскольку
Эффективность
(временная сложность)
Важно помнить, что временная сложность – всего лишь оценка эффективности, поскольку

Слайд 88Эффективность
(временная сложность)
Что в действительности означают слова «время работы алгоритма составляет O(f (n))»?
Эффективность
(временная сложность)
Что в действительности означают слова «время работы алгоритма составляет O(f (n))»?

Слайд 89Эффективность
(временная сложность)
Например, технически правильно будет сказать, что временная сложность следующего алгоритма равна
Эффективность
(временная сложность)
Например, технически правильно будет сказать, что временная сложность следующего алгоритма равна

Слайд 90Эффективность
(временная сложность)
На практике часто применяются еще два варианта нотации. Буквой Ω обозначается
Эффективность
(временная сложность)
На практике часто применяются еще два варианта нотации. Буквой Ω обозначается

Слайд 91Эффективность
(временная сложность)
Описанная нотация используется во многих ситуациях, а не только в контексте
Эффективность
(временная сложность)
Описанная нотация используется во многих ситуациях, а не только в контексте

Слайд 92Эффективность
(пример)
Обсудим задачу, которую можно решить несколькими способами. Начнем с простого алгоритма с
Эффективность
(пример)
Обсудим задачу, которую можно решить несколькими способами. Начнем с простого алгоритма с

Слайд 93Эффективность
(пример)
Пусть дан массив n чисел; задача заключается в том, чтобы вычислить максимальную
Эффективность
(пример)
Пусть дан массив n чисел; задача заключается в том, чтобы вычислить максимальную

Слайд 94Эффективность
(пример)
Решение со сложностью O(n3). Задачу можно решить в лоб: перебрать все возможные
Эффективность
(пример)
Решение со сложностью O(n3). Задачу можно решить в лоб: перебрать все возможные

Слайд 95Эффективность
(пример)
Решение со сложностью O(n2). Алгоритм легко сделать более эффективным, исключив один цикл.
Эффективность
(пример)
Решение со сложностью O(n2). Алгоритм легко сделать более эффективным, исключив один цикл.

Слайд 96Эффективность
(пример)
Решение со сложностью O(n). Оказывается, что задачу можно решить и за время
Эффективность
(пример)
Решение со сложностью O(n). Оказывается, что задачу можно решить и за время

Слайд 97Эффективность
(пример)
Алгоритм реализуется следующей программой:
int best = 0, sum = 0;
for (int k
Эффективность
(пример)
Алгоритм реализуется следующей программой:
int best = 0, sum = 0;
for (int k

Слайд 98Эффективность
(пример)
Сравнение эффективности. Насколько приведенные алгоритмы эффективны на практике? В таблице показано время
Эффективность
(пример)
Сравнение эффективности. Насколько приведенные алгоритмы эффективны на практике? В таблице показано время
Слайд 99Эффективность
(пример)
Сравнение показывает, что все алгоритмы работают быстро, если размер входных данных мал,
Эффективность
(пример)
Сравнение показывает, что все алгоритмы работают быстро, если размер входных данных мал,

Слайд 100Структуры данных
Познакомимся с наиболее важными структурами данных из стандартной библиотеки C++. В
Структуры данных
Познакомимся с наиболее важными структурами данных из стандартной библиотеки C++. В

Слайд 101Структуры данных
В C++ обыкновенные массивы – это структуры фиксированного размера, т. е.
Структуры данных
В C++ обыкновенные массивы – это структуры фиксированного размера, т. е.

Слайд 102Структуры данных
Динамическим называется массив, размер которого можно изменять в процессе выполнения программы.
Структуры данных
Динамическим называется массив, размер которого можно изменять в процессе выполнения программы.

Слайд 103Структуры данных
(динамические массивы)
Вектор – это динамический массив, который позволяет эффективно добавлять элементы
Структуры данных
(динамические массивы)
Вектор – это динамический массив, который позволяет эффективно добавлять элементы

Слайд 104Структуры данных
(динамические массивы)
Доступ к элементам осуществляется так же, как в обычном массиве:
cout
Структуры данных
(динамические массивы)
Доступ к элементам осуществляется так же, как в обычном массиве:
cout

Слайд 105Структуры данных
(динамические массивы)
Еще один способ создать
вектор – перечислить все его элементы:
vector
Структуры данных
(динамические массивы)
Еще один способ создать
вектор – перечислить все его элементы:
vector

Слайд 106Структуры данных
(динамические массивы)
Можно также задать число элементов и их начальное значение:
vector a(8);
Структуры данных
(динамические массивы)
Можно также задать число элементов и их начальное значение:
vector

Слайд 107Структуры данных
(динамические массивы)
Функция size возвращает число элементов вектора. В следующем коде обходится
Структуры данных
(динамические массивы)
Функция size возвращает число элементов вектора. В следующем коде обходится

Слайд 108Структуры данных
(динамические массивы)
Обход вектора можно записать и короче:
for (auto x : v)
Структуры данных
(динамические массивы)
Обход вектора можно записать и короче:
for (auto x : v)

Слайд 109Структуры данных
(динамические массивы)
Функция back возвращает последний элемент вектора, а функция pop_back удаляет
Структуры данных
(динамические массивы)
Функция back возвращает последний элемент вектора, а функция pop_back удаляет

Слайд 110Структуры данных
(динамические массивы)
Векторы реализованы так, что функции push_back и pop_back в среднем
Структуры данных
(динамические массивы)
Векторы реализованы так, что функции push_back и pop_back в среднем

Слайд 111Структуры данных
(динамические массивы)
Итератором называется переменная, которая указывает на элемент структуры данных. Итератор
Структуры данных
(динамические массивы)
Итератором называется переменная, которая указывает на элемент структуры данных. Итератор

Слайд 112Структуры данных
(динамические массивы)
Обратите внимание на асимметрию итераторов: begin() указывает на элемент, принадлежащий
Структуры данных
(динамические массивы)
Обратите внимание на асимметрию итераторов: begin() указывает на элемент, принадлежащий

Слайд 113Структуры данных
(динамические массивы)
Диапазоном называется последовательность соседних элементов структуры данных. Чаще всего диапазон
Структуры данных
(динамические массивы)
Диапазоном называется последовательность соседних элементов структуры данных. Чаще всего диапазон

Слайд 114Структуры данных
(динамические массивы)
Функции из стандартной библиотеки C++ обычно применяются к диапазонам. Так,
Структуры данных
(динамические массивы)
Функции из стандартной библиотеки C++ обычно применяются к диапазонам. Так,

Слайд 115Структуры данных
(динамические массивы)
К элементу, на который указывает итератор, можно обратиться, воспользовавшись оператором
Структуры данных
(динамические массивы)
К элементу, на который указывает итератор, можно обратиться, воспользовавшись оператором

Слайд 116Структуры данных
(динамические массивы)
Более полезный пример: функция lower_bound возвращает итератор на первый элемент
Структуры данных
(динамические массивы)
Более полезный пример: функция lower_bound возвращает итератор на первый элемент

Слайд 117Структуры данных
(динамические массивы)
Отметим, что эти функции правильно работают, только если заданный диапазон
Структуры данных
(динамические массивы)
Отметим, что эти функции правильно работают, только если заданный диапазон

Слайд 118Структуры данных
(динамические массивы)
В стандартной библиотеке C++ много полезных функций, заслуживающих внимания. Например,
Структуры данных
(динамические массивы)
В стандартной библиотеке C++ много полезных функций, заслуживающих внимания. Например,

Слайд 119Структуры данных
(динамические массивы)
Двусторонней очередью (деком) называется динамический массив, допускающий эффективные операции с
Структуры данных
(динамические массивы)
Двусторонней очередью (деком) называется динамический массив, допускающий эффективные операции с

Слайд 120Структуры данных
(динамические массивы)
Операции двусторонней очереди в среднем имеют сложность O(1). Однако постоянные
Структуры данных
(динамические массивы)
Операции двусторонней очереди в среднем имеют сложность O(1). Однако постоянные

Слайд 121Структуры данных
(динамические массивы)
C++ предоставляет также специализированные структуры данных, по умолчанию основанные на
Структуры данных
(динамические массивы)
C++ предоставляет также специализированные структуры данных, по умолчанию основанные на

Слайд 122Структуры данных
(динамические массивы)
В случае очереди элементы вставляются в начало, а удаляются из
Структуры данных
(динамические массивы)
В случае очереди элементы вставляются в начало, а удаляются из

Слайд 123Структуры данных
(множества)
Множеством называется структура данных, в которой хранится набор элементов. Основные операции
Структуры данных
(множества)
Множеством называется структура данных, в которой хранится набор элементов. Основные операции

Слайд 124Структуры данных
(множества)
В стандартной библиотеке C++ имеются две структуры, относящиеся к множествам:
set основана
Структуры данных
(множества)
В стандартной библиотеке C++ имеются две структуры, относящиеся к множествам:
set основана

Слайд 125Структуры данных
(множества)
Обе структуры эффективны, и во многих случаях годится любая. Поскольку используются
Структуры данных
(множества)
Обе структуры эффективны, и во многих случаях годится любая. Поскольку используются

Слайд 126Структуры данных
(множества)
В показанном ниже коде создается множество, содержащее целые числа, и демонстрируются
Структуры данных
(множества)
В показанном ниже коде создается множество, содержащее целые числа, и демонстрируются

Слайд 127Структуры данных
(множества)
Важным свойством множеств является тот факт, что все их элементы различны.
Структуры данных
(множества)
Важным свойством множеств является тот факт, что все их элементы различны.

Слайд 128Структуры данных
(множества)
Множество в основном можно использовать как вектор, однако доступ к элементам
Структуры данных
(множества)
Множество в основном можно использовать как вектор, однако доступ к элементам

Слайд 129Структуры данных
(множества)
Функция find(x) возвращает итератор, указывающий на элемент со значением x. Если
Структуры данных
(множества)
Функция find(x) возвращает итератор, указывающий на элемент со значением x. Если

Слайд 130Структуры данных
(множества)
Упорядоченные множества. Основное различие между двумя структурами множества в C++ –
Структуры данных
(множества)
Упорядоченные множества. Основное различие между двумя структурами множества в C++ –

Слайд 131Структуры данных
(множества)
Рассмотрим задачу о нахождении наименьшего и наибольшего значений во множестве. Чтобы
Структуры данных
(множества)
Рассмотрим задачу о нахождении наименьшего и наибольшего значений во множестве. Чтобы

Слайд 132Структуры данных
(множества)
В структуре set имеются также функции lower_bound(x) и upper_bound(x), которые возвращают
Структуры данных
(множества)
В структуре set имеются также функции lower_bound(x) и upper_bound(x), которые возвращают

Слайд 133Структуры данных
(множества)
Мультимножества. В отличие от множества, в мультимножество один и тот же
Структуры данных
(множества)
Мультимножества. В отличие от множества, в мультимножество один и тот же

Слайд 134Структуры данных
(множества)
Функция erase удаляет все копии значения из мультимножества.
s.erase(5);
cout << s.count(5) <<
Структуры данных
(множества)
Функция erase удаляет все копии значения из мультимножества.
s.erase(5);
cout << s.count(5) <<

Слайд 135Структуры данных
(множества)
Если требуется удалить только одно значение, то можно поступить так:
s.erase(s.find(5));
cout <<
Структуры данных
(множества)
Если требуется удалить только одно значение, то можно поступить так:
s.erase(s.find(5));
cout <<

Слайд 136Структуры данных
(множества)
Отметим, что во временной сложности функций count и erase имеется дополнительный
Структуры данных
(множества)
Отметим, что во временной сложности функций count и erase имеется дополнительный

Слайд 137Структуры данных
(множества)
Отображением называется множество, состоящее из пар ключ-значение. Отображение можно также рассматривать
Структуры данных
(множества)
Отображением называется множество, состоящее из пар ключ-значение. Отображение можно также рассматривать

Слайд 138Структуры данных
(множества)
В стандартной библиотеке C++ есть две структуры отображений, соответствующие структурам множеств:
Структуры данных
(множества)
В стандартной библиотеке C++ есть две структуры отображений, соответствующие структурам множеств:

Слайд 139Структуры данных
(множества)
В следующем фрагменте создается отображение, ключами которого являются строки, а значениями
Структуры данных
(множества)
В следующем фрагменте создается отображение, ключами которого являются строки, а значениями

Слайд 140Структуры данных
(множества)
Если в отображении нет запрошенного ключа, то он автоматически добавляется, и
Структуры данных
(множества)
Если в отображении нет запрошенного ключа, то он автоматически добавляется, и

Слайд 141Структуры данных
(множества)
Функция count проверяет, существует ли ключ в отображении:
if (m.count("aybabtu")) {
// ключ
Структуры данных
(множества)
Функция count проверяет, существует ли ключ в отображении:
if (m.count("aybabtu")) {
// ключ

Слайд 142Структуры данных
(множества)
В следующем коде печатаются все имеющиеся в отображении ключи и значения:
for
Структуры данных
(множества)
В следующем коде печатаются все имеющиеся в отображении ключи и значения:
for

Слайд 143Структуры данных
(эксперименты)
Хотя временная сложность – отличный инструмент, она не всегда сообщает всю
Структуры данных
(эксперименты)
Хотя временная сложность – отличный инструмент, она не всегда сообщает всю

Слайд 144Структуры данных
(эксперименты)
Многие задачи можно решить, применяя как множества, так и сортировку. Важно
Структуры данных
(эксперименты)
Многие задачи можно решить, применяя как множества, так и сортировку. Важно

Слайд 145Структуры данных
(эксперименты)
В качестве примера рассмотрим задачу о вычислении количества уникальных элементов вектора.
Структуры данных
(эксперименты)
В качестве примера рассмотрим задачу о вычислении количества уникальных элементов вектора.

Слайд 146Структуры данных
(эксперименты)
В таблице приведены результаты эксперимента, в котором оба алгоритма тестировались на
Структуры данных
(эксперименты)
В таблице приведены результаты эксперимента, в котором оба алгоритма тестировались на
Слайд 147Структуры данных
(эксперименты)
Оказалось, что алгоритм на основе unordered_set примерно в два раза быстрее
Структуры данных
(эксперименты)
Оказалось, что алгоритм на основе unordered_set примерно в два раза быстрее

Слайд 148Структуры данных
(эксперименты)
Отображения – удобные структуры данных, по сравнению с массивами, поскольку позволяют
Структуры данных
(эксперименты)
Отображения – удобные структуры данных, по сравнению с массивами, поскольку позволяют

Слайд 149Структуры данных
(эксперименты)
Результаты эксперимента сведены в таблицу. Хотя unordered_map примерно в три раза
Структуры данных
(эксперименты)
Результаты эксперимента сведены в таблицу. Хотя unordered_map примерно в три раза

Слайд 150Структуры данных
(эксперименты)
Результаты эксперимента сведены в таблицу.
Структуры данных
(эксперименты)
Результаты эксперимента сведены в таблицу.
Слайд 151Структуры данных
(эксперименты)
Хотя unordered_map примерно в три раза быстрее map, массив все равно
Структуры данных
(эксперименты)
Хотя unordered_map примерно в три раза быстрее map, массив все равно

Слайд 152Структуры данных
(эксперименты)
Верно ли, что очереди с приоритетом действительно быстрее мультимножеств? Чтобы выяснить
Структуры данных
(эксперименты)
Верно ли, что очереди с приоритетом действительно быстрее мультимножеств? Чтобы выяснить

Слайд 153Структуры данных
(эксперименты)
Результаты эксперимента представлены в таблице.
Структуры данных
(эксперименты)
Результаты эксперимента представлены в таблице.
 Совмещение технологий локального и глобального позиционирования в ОС Android
Совмещение технологий локального и глобального позиционирования в ОС Android HTML таблицы+img
HTML таблицы+img Тренды instagram в развитии личного пространства
Тренды instagram в развитии личного пространства Интернет и гаджеты: как защитить
Интернет и гаджеты: как защитить Компьютерные вирусы
Компьютерные вирусы Информация и её свойства
Информация и её свойства Web of science. Символы усечения
Web of science. Символы усечения Защита конфиденциальной информации
Защита конфиденциальной информации Адресация в сети Интернет
Адресация в сети Интернет Система электронных ценников на базе Е-INK технологии
Система электронных ценников на базе Е-INK технологии Гимп (Урок 6)
Гимп (Урок 6) Организация вычислений в электронных таблицах
Организация вычислений в электронных таблицах Mit App Inventor. Компонент текст, переменные, арифметика (урок 2)
Mit App Inventor. Компонент текст, переменные, арифметика (урок 2) Как преуспеть в тестировании
Как преуспеть в тестировании Дискретная форма представления информации. Единицы измерения информации
Дискретная форма представления информации. Единицы измерения информации Интернет. Электронная почта
Интернет. Электронная почта Элементы алгебры логики. Математические основы информатики
Элементы алгебры логики. Математические основы информатики 202b64355ed2741af4039e665cb537b1
202b64355ed2741af4039e665cb537b1 Защита операционной системы при работе в интернете с помощью модема-маршрутизатора
Защита операционной системы при работе в интернете с помощью модема-маршрутизатора Устройство для сна
Устройство для сна Функции информационного менеджмента. Мотивация в сфере информатизации
Функции информационного менеджмента. Мотивация в сфере информатизации Конструирование программного продукта
Конструирование программного продукта Работа компьютерных сетей. Домен. Частная виртуальная сеть
Работа компьютерных сетей. Домен. Частная виртуальная сеть Использование связей
Использование связей Создание групп (сообществ) в образовательной сети
Создание групп (сообществ) в образовательной сети Развитие вычислительной техники
Развитие вычислительной техники Анонимная война
Анонимная война Модель текстового документа
Модель текстового документа