- Проверка статистических гипотез. Версия 2

Содержание
- 2. Определение Статистическая гипотеза – утверждение о свойствах распределения вероятностей случайной величины (или случайного вектора). Гипотеза нуждается
- 3. Напоминание Что такое функция распределения? Что такое плотность распределения?
- 4. Раздел 1 Зачем проверяют статистические гипотезы Обсудим наиболее важные статистические гипотезы.
- 5. 1. Гипотеза согласия. Обозначим функцию распределения случайной величины Х. Пусть - некоторая заданная функция распределения. Гипотеза
- 6. Пример гипотезы согласия Гипотеза о нормальности распределения В этом случае
- 8. Почему гипотеза нормальности важна? 1. Нормальное распределение часто встречается (вспомним центральную предельную теорему).
- 9. Почему гипотеза нормальности важна? 2. Когда распределение нормальное, экономим деньги: если А) распределение можно считать нормальным
- 10. Пример гипотезы согласия 2 Гипотеза об экспоненциальности распределения. В этом случае функция распределения
- 11. Почему важна гипотеза экспоненциальности? Экспоненциальное распределение часто встречается, когда изучается «время ожидания».
- 12. Например, Время до аварии (нужно для расчета страховой премии). Время обслуживания покупателя кассиром (нужно для определения
- 13. 2. Гипотеза однородности. Обозначим функцию распределения случайной величины Х. Обозначим функцию распределения случайной величины Y Гипотеза
- 14. Например, Распределение продаж до рекламной акции и после нее. Если распределение продаж не изменилось, то улучшения
- 15. 3. Гипотеза независимости. Гипотеза : случайные величины X и Y независимы Кому и когда приходится проверять
- 16. Например, Если возраст покупателей и объем покупки зависимы, то возраст надо учитывать при сегментации покупателей. Иногда
- 17. Вопрос: наличие балкона влияет на цену квартиры?
- 18. На шаг дальше… В эконометрике редко интересен сам факт зависимости. Обычно идут дальше, пытаются описать зависимость.
- 19. 4. Гипотезы о параметре распределения. Очень часто не так важно распределение случайной величины. Интересна лишь одна
- 20. Если анализируются продажи магазина, то в первую очередь интересно… Математическое ожидание Так как математическое ожидание –
- 21. Гипотеза. Математические ожидания случайных величин X и Y одинаковы. EX = EY
- 22. Если сравниваются медианы: Гипотеза. Медианы случайных величин X и Y одинаковы. Med(X) = med(Y)
- 23. Основные условия применения статистических тестов Вопрос должен касаться какой-либо характеристики массового явления. Характеристика меняется случайным образом
- 24. Пример 1 В обычных условиях зафиксирован некоторый уровень продаж. Затем была проведена рекламная акция. Руководству фирмы
- 25. Основная проблема: Увеличение продаж могло быть вызвано случайными факторами. Продажи все время меняются, случайным образом отклоняются
- 26. Пример 2 Разработан новый варианта упаковки товара. Требуется проверить предположение, что товар в новой упаковке имеет
- 27. Пример 3 Верно ли, что основной конкурент действует на том же сегменте рынка, что и фирма
- 28. Пример 4 Фирма изучает постоянных покупателей своей продукции, чтобы увеличить их лояльность и количество. В рамках
- 29. Пример 4. Часть 2 Статистическая формулировка: проверить гипотезы о независимости уровня лояльности и а) пола покупателя;
- 30. Раздел 2 Технологии проверки статистических гипотез Основные понятия
- 31. Выбираем из двух гипотез! Гипотеза принимается или отвергается Так неудобно Надо: выбираем между двумя статистическими гипотезами.
- 32. Определение Проверку гипотез на основе выборочных статистических данных называют статистической проверкой гипотез.
- 33. Основная и альтернативная гипотезы Одну из гипотез называют основной и обозначают, как правило, Н, а другую
- 34. Неточно говорить «…выбрана основная гипотеза…» или «…выбрана альтернативная гипотеза…», Неточно говорить «…основная гипотеза принята…» или «основная
- 35. Важное уточнение. Правильно говорить «основная гипотеза отвергнута…» и «основная гипотеза не отвергнута…». Так как обычно проверяют
- 36. Комментарий 1: Гипотеза: число делится на 6 нацело. Фактически проверяем, делится ли число на 2 нацело.
- 37. Комментарий 2: Часто случается, что у аналитика недостаточно данных, чтобы проявился изучаемый эффект. Например, фармацевтическая компания
- 38. Отвергнуть гипотезу недостаточно Основная гипотеза при анализе: отличия между лекарствами нет. Дело касается здоровья людей, и
- 39. Вывод Хотя часто можно услышать, что (основная) гипотеза принята, такое выражение неточно. Точнее говорить, что (основная)
- 40. Ошибки первого и второго рода Ошибка первого рода состоит в том, что отвергается основная гипотеза, когда
- 41. Аналогия В больнице врач принимает решение, направлять пациента на операцию, или нет.
- 42. Когда врач делает ошибку первого рода? Когда врач делает ошибку второго рода?
- 43. Гипотеза: нужна срочная операция
- 44. Может ли врач свести частоту (вероятность) ошибок первого рода к нулю? Может ли врач свести частоту
- 45. Есть исключения Например, если мы будем вакцинацию считать операцией, то получается, что врачи предпочитают делать маленькую
- 46. Последствия ошибок могут быть различными Ошибка первого рода (обычно) опаснее, но полностью избежать ее не удастся.
- 47. Уровень значимости Долю ошибок первого рода ограничивают сверху числом, называемым уровень значимости. Исторически сложилось так, что
- 48. Для новичков! Чаще всего уровень значимости равен 0,05 На самом деле выбор уровня значимости – большая
- 49. «медицинский» пример На что влияет выбор уровня значимости? Проектирование атомной электростанции Трелевочный трактор
- 50. Ошибка второго рода и мощность Как добиться того, чтобы вероятность ошибки второго рода была малой? Очень
- 51. Дополнительно Если выборка маленькая (часто границей между большой и маленькой выборкой рекомендуют считать 30 наблюдений), проверить
- 52. Задача. Вместо врача рассмотрим банковского служащего, принимающего решение, выдавать заем или нет. Как будут интерпретироваться статистические
- 53. Алгоритм проверки статистических гипотез 1. Имеются n наблюдений , то есть n чисел, полученных, например, в
- 54. 3. Задан статистический критерий, то есть функция от наблюдений . 4. Найдено p-значение (p-value). Иногда переводится
- 55. 5. Проверяются все условия, при которых критерий будет работать. Условия – Из учебника или справочника. Несколько
- 56. 6. Если p α - не отвергаем. Напомним: α – уровень значимости p - p-value.
- 57. Комментарии Наблюдения не обязательно являются числами. Выбор того статистического критерия, который подходит для задачи – важная
- 58. Проверка условий применимости Например, для применения t – критерия Стьюдента или для проверка гипотезы независимости с
- 59. Статистика критерия или тестовая статистикой Иногда используют статистику критерия или тестовую статистику. Изредка она важна сама
- 60. Интерпретация статистики критерия Значение статистики критерия (обычно) измеряет, насколько данные согласуются с гипотезой.
- 61. "Маленькие" значения статистики критерия указывают, что данные «ведут себя» в соответствии с гипотезой. В этом случае
- 62. "Большие" значения статистики критерия указывают, что данные не соответствуют гипотезе, противоречат ей. Гипотеза отвергается.
- 63. Пример Нормальное распределение с дисперсией 1 Имеется n наблюдений Основная гипотеза: математическое ожидание равно 11 Альтернативная
- 64. Напоминание из теории вероятностей Среднее арифметическое n независимых одинаково распределенных случайных величин с общим нормальным распределением
- 65. Вопрос: Где на графике ошибка первого рода, где ошибка второго рода?
- 66. Интерпретация статистики критерия В статистике существует традиция, что именно задавать в качестве основной гипотезы. Примеры.
- 67. Раздел 3 Важные частные случаи
- 68. Проверка гипотезы о нормальности распределения случайной величины
- 69. Статистическая формулировка Гипотеза: Случайная величина имеет нормальное распределение, значения параметров распределения заранее не известны. Конкурирующая гипотеза:
- 70. Критерий Шапиро-Уилка Критерий Шапиро-Уилка. shapiro.test(data) От 3 до 5000 наблюдений
- 71. Package "nortest" Критерий Anderson-Darling library(nortest) ad.test(data) Критерий Lilliefors (Kolmogorov-Smirnov) library(nortest) lillie.test(x)
- 72. Число наблюдений Если анализируется меньше 60 (2000) наблюдений, рекомендуется использовать критерий Шапиро-Уилка если больше 60, то
- 73. А нужно ли проверять гипотезу нормальности?
- 74. Как оказалось, для тех методов, которые рассматриваются в курсе, требование нормальности распределения можно заметно ослабить. Эти
- 75. допустим известно, что распределение случайной величины не нормальное. В каком случае отклонение от нормальности не существенное?
- 76. Итак, гипотеза о нормальности распределения изучаемой переменной уже отвергнута.
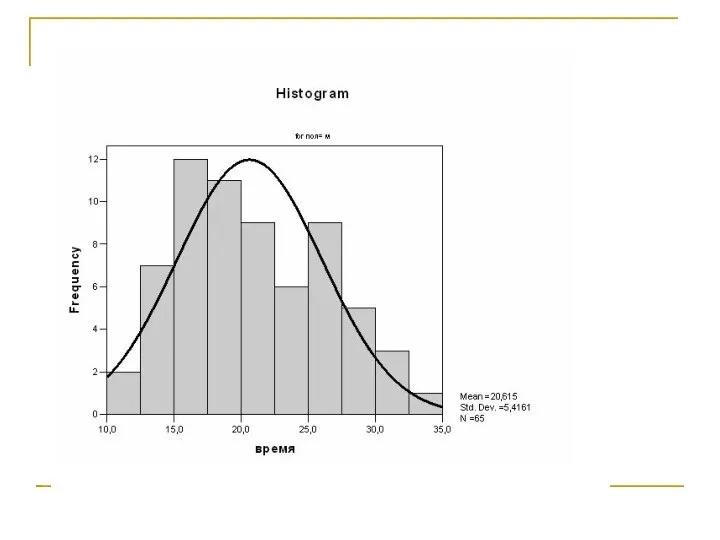
- 77. Существенные отклонения 1. Наличие выбросов в данных. 2. Явная асимметрия гистограммы. 3. Очень сильное отклонение формы
- 78. Рекомендуется строго относиться к присутствию выбросов, снисходительно к отклонениям от симметрии. Наше отношение к колоколообразной форме
- 82. Лекарство Иногда оно опаснее болезни... Выбросы — удаляем (осторожно!) Асимметрия — преобразуем данные (например, логарифмируем, или
- 83. Пример 1 Население городов России в 1959 году Исходные данные Логарифм населения
- 84. Пример 2 Альбукерк – продажи домов
- 85. Сравнение центров распределений
- 86. Сравнение центров распределений Центр распределения - то одно единственное число, которое описывало, характеризовало бы выборку. В
- 87. Другие методы оценки центра распределения Andrews; Bickel; Hampel; Huber; Rogers, Tukey. Robust estimates of location: survey
- 88. Среднее арифметическое или медиана? Если распределение хотя бы одной из выборок существенно отличается от нормального, в
- 89. Выбор центра распределения Если центром распределения выбрана медиана, центры сравниваются с помощью критерия Манна – Уитни-Вилкоксона.
- 90. Примеры Обучение менеджеров Магазины
- 91. Парные и независимые выборки В случае парных выборок имеются пары наблюдений (измерений) одного и того же
- 92. Независимые выборки В случае независимых выборок каждое наблюдение соответствует отдельному объекту, т.е. измеряются разные объекты. Принадлежность
- 93. Независимые и парные выборки Если выборки парные, используется опция paired = TRUE. Если выборки независимые, используется
- 94. Примеры Время в магазинах Альбукерк
- 95. Сравнение медиан выборок Гипотеза: Медианы равны. Альтернативная гипотеза: Медианы различаются.
- 96. Статистика критерия Манна-Уитни U U1 = n1*n2 + {n1 * (n1 + 1)/2} — T1 U2
- 97. Статистика критерия Манна-Уитни идея метода Обозначим одну выборку x, другую y. Для каждого наблюдения из выборки
- 98. Важно! Критерий Манна-Уитни проверяет не равенство медиан, а другое утверждение. Имеются две выборки наблюдений случайных величин
- 99. Under more strict assumptions than those above, e.g., if the responses are assumed to be continuous
- 100. Критерий Манна-Уитни-Вилкоксона wilcox.test(x, y, alternative = "two.sided", paired = FALSE, exact = TRUE, correct = FALSE)
- 101. Примеры Время в магазинах Альбукерк
- 102. Сравнение средних значений выборок Гипотеза: Математические ожидания равны. Альтернативная гипотеза: Математические ожидания различны.
- 103. T-критерий Стьюдента t.test(x, y, alternative = "two.sided", paired = FALSE, var.equal = FALSE)
- 104. Выбор статистического критерия Если выборки парные, рекомендуется использовать парный t-критерий Стьюдента. Если выборки независимые, рекомендуется использовать
- 105. Надо еще сравнить дисперсии - 1 Метод 1 F-test of equality of variances Не рекомендуется, слишком
- 106. Надо еще сравнить дисперсии - 2 Метод 2 Bartlett's test Если данные нормально распределены, лучший вариант.
- 107. Надо еще сравнить дисперсии - 2 Метод 2 Bartlett's test bartlett.test(x, g, data=data.table) bartlett.test(x~g, data=data.table)
- 108. Надо еще сравнить дисперсии - 3 Levene's test Критерий Ливиня/Левена Содержится в пакете car
- 109. Надо еще сравнить дисперсии - 3 Levene's test library(car) leveneTest(x~g, data=data.table)
- 110. Надо еще сравнить дисперсии - 4 Fligner-Killeen test Робастный, рекомендуется. Хотя есть еще Brown-Forsythe test, возможно
- 111. Надо еще сравнить дисперсии - 4 Fligner-Killeen test fligner.test(x~g, data=data.table)
- 112. Примеры Время в магазинах Альбукерк
- 113. Гипотеза независимости Основная гипотеза: Случайные величины X и Y независимы Альтернативная гипотеза: Случайные величины X и
- 114. На практике: Отвечаем на вопрос: переменная X влияет на переменную Y?
- 115. Комментарий Если неизвестно, что на что влияет: X на Y или Y на X статистический критерий
- 116. Пример Бернарда Шоу
- 117. Диаграмма рассеивания Иногда пишут - диаграмма рассеяния Пример – швейцарские банкноты.
- 118. Зависимость -1 X – в количественной шкале Y – в количественной шкале Применяется коэффициент корреляции Пирсона
- 119. Функциональная зависимость
- 120. Статистическая зависимость двух переменных Обобщение функциональной зависимости. Одному и тому же значению x могут соответствовать разные
- 121. статистическая зависимость Определение статистическая зависимость – это функциональная зависимость СРЕДНЕГО значения переменной y от значения переменной
- 122. среднее значение переменной y равно натуральному логарифму значения x.
- 123. среднее значение переменной y равно натуральному логарифму значения x.
- 124. Коэффициент корреляции как «градусник», измеряющий степень зависимости Формула для коэффициента корреляции
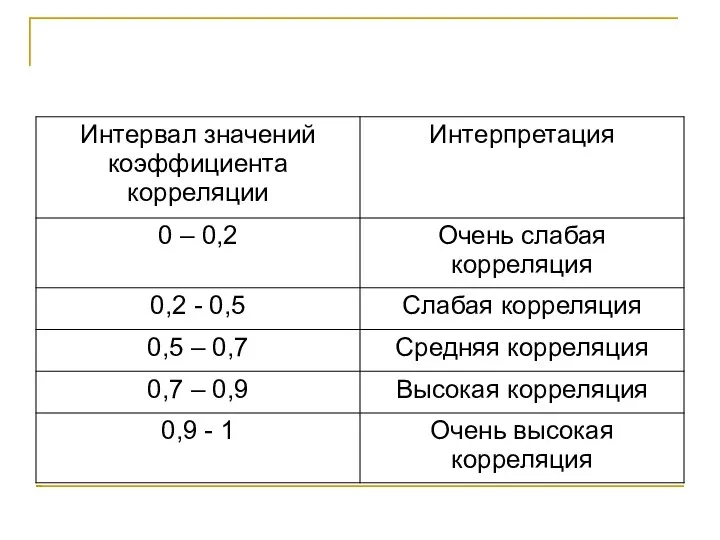
- 125. Выбор коэффициента Если распределение каждой переменной несущественно отличается от нормального, применяется коэффициент корреляции Пирсона В остальных
- 127. Как проявляется зависимость на диаграмме рассеивания
- 128. Коэффициент корреляции равен 1
- 129. Коэффициент корреляции равен 0.9
- 130. Коэффициент корреляции равен 0.8
- 131. Коэффициент корреляции равен 0.6
- 132. Коэффициент корреляции равен 0.4
- 133. Коэффициент корреляции равен 0.2
- 134. Коэффициент корреляции равен 0.
- 135. Проблемы и ошибки при использовании коэффициента корреляции
- 138. Данные без выброса коэффициент корреляции равен -0.81
- 139. Добавлен выброс в точке (10,10). Коэффициент корреляции упал до -0,55.
- 140. Выброс сдвинут в точку (18,5, 18,5) Коэффициент равен 0
- 141. Выброс сдвинут в точку (53, 53). Корреляция равна +0,81
- 142. Ложная корреляция
- 143. Зависимость -2 X – в количественной шкале Y – в номинальной шкале Сравниваем средние или медианы
- 144. Зависимость -3 X – в порядковой шкале Y – в порядковой шкале Используем коэффициент корреляции Спирмена
- 145. Зависимость -4 X – в номинальной шкале Y – в номинальной шкале Таблица сопряженности и критерий
- 146. Критерий хи-квадрат Формула для статистики
- 147. Статистика хи-квадрат как коэффициент корреляции Коэффициент Пирсона Коэффициент Чупрова
- 148. Примеры типичных ошибок при использовании критерия хи-квадрат
- 149. Пример 1 Действительно ли использование Internet связано с полом? Все опрошенные пользуются Интернетом. Тех из них,
- 150. Пример 1 sex = пол. Кодировка: "1" – мужчина, "0" – женщина. internet = использование Internet.
- 151. Пример 1
- 152. Пример 2 В результате изучения связи между покупкой модной одежды и семейным положением получены, среди прочих,
- 153. Пример 2 Переменные. sex = пол. Кодировка: "1" – мужчина, "0" – женщина. marriage = семейное
- 154. Пример 2
- 155. Пример 2
- 156. Пример 2
- 157. Пример 3 Маркетолог проводит исследование для рекламного агентства, разрабатывающего рекламу для автомобилей стоимостью свыше 30 тысяч
- 158. Пример 3 Переменные. high_edu = образование. Кодировка: "1" – высшее образование, "0" – нет высшего образования.
- 159. Пример 3
- 160. Пример 3
- 161. Пример 3
- 162. Пример 4 Маркетолог, исследующий сферу туристических поездок за границу, предположил, что на желание путешествовать влияет возраст.
- 163. Пример 4 Переменные. desire = желание совершить путешествие за границу. Кодировка: "1" – желание есть, "0"
- 164. Пример 4
- 165. Пример 4
- 166. Пример 4
- 167. Пример 4
- 168. Пример 5 Результаты анкетирования о проведении семейного досуга содержат, среди прочего, следующую информацию. Переменные. fastfood =
- 169. Пример 5
- 170. Пример 5
- 172. Скачать презентацию
Слайд 2Определение
Статистическая гипотеза – утверждение о свойствах распределения вероятностей случайной величины (или
Определение
Статистическая гипотеза – утверждение о свойствах распределения вероятностей случайной величины (или

Слайд 3Напоминание
Что такое функция распределения?
Что такое плотность распределения?
Напоминание
Что такое функция распределения?
Что такое плотность распределения?

Слайд 4Раздел 1
Зачем проверяют
статистические гипотезы
Обсудим наиболее важные статистические гипотезы.
Раздел 1
Зачем проверяют
статистические гипотезы
Обсудим наиболее важные статистические гипотезы.
Слайд 51. Гипотеза согласия.
Обозначим функцию распределения случайной величины Х.
Пусть - некоторая заданная
1. Гипотеза согласия.
Обозначим функцию распределения случайной величины Х.
Пусть - некоторая заданная

Слайд 6Пример гипотезы согласия
Гипотеза о нормальности распределения
В этом случае
Пример гипотезы согласия
Гипотеза о нормальности распределения
В этом случае


Слайд 8Почему гипотеза нормальности важна?
1. Нормальное распределение часто встречается
(вспомним центральную предельную теорему).
Почему гипотеза нормальности важна?
1. Нормальное распределение часто встречается
(вспомним центральную предельную теорему).

Слайд 9Почему гипотеза нормальности важна?
2. Когда распределение нормальное, экономим деньги: если
А) распределение
Почему гипотеза нормальности важна?
2. Когда распределение нормальное, экономим деньги: если
А) распределение

Слайд 10Пример гипотезы согласия 2
Гипотеза об экспоненциальности распределения.
В этом случае функция распределения
Пример гипотезы согласия 2
Гипотеза об экспоненциальности распределения.
В этом случае функция распределения

Слайд 11Почему важна гипотеза экспоненциальности?
Экспоненциальное распределение часто встречается, когда изучается «время ожидания».
Почему важна гипотеза экспоненциальности?
Экспоненциальное распределение часто встречается, когда изучается «время ожидания».

Слайд 12Например,
Время до аварии (нужно для расчета страховой премии).
Время обслуживания покупателя кассиром (нужно
Например,
Время до аварии (нужно для расчета страховой премии).
Время обслуживания покупателя кассиром (нужно

Слайд 132. Гипотеза однородности.
Обозначим функцию распределения случайной величины Х.
Обозначим функцию распределения случайной
2. Гипотеза однородности.
Обозначим функцию распределения случайной величины Х.
Обозначим функцию распределения случайной

Слайд 14Например,
Распределение продаж до рекламной акции и после нее.
Если распределение продаж не изменилось,
Например,
Распределение продаж до рекламной акции и после нее.
Если распределение продаж не изменилось,

Слайд 15 3. Гипотеза независимости.
Гипотеза : случайные величины X и Y независимы
Кому
3. Гипотеза независимости.
Гипотеза : случайные величины X и Y независимы
Кому

Слайд 16Например,
Если возраст покупателей и объем покупки зависимы, то возраст надо учитывать при
Например,
Если возраст покупателей и объем покупки зависимы, то возраст надо учитывать при

Слайд 17Вопрос:
наличие балкона влияет на цену квартиры?
Вопрос:
наличие балкона влияет на цену квартиры?

Слайд 18На шаг дальше…
В эконометрике редко интересен сам факт зависимости. Обычно идут дальше,
На шаг дальше…
В эконометрике редко интересен сам факт зависимости. Обычно идут дальше,

Слайд 194. Гипотезы о параметре распределения.
Очень часто не так важно распределение случайной величины.
4. Гипотезы о параметре распределения.
Очень часто не так важно распределение случайной величины.

Слайд 20Если анализируются продажи магазина, то в первую очередь интересно…
Математическое ожидание
Так как
Если анализируются продажи магазина, то в первую очередь интересно…
Математическое ожидание
Так как

Слайд 21Гипотеза. Математические ожидания случайных величин X и Y одинаковы.
EX = EY
EX = EY

Слайд 22Если сравниваются медианы:
Гипотеза. Медианы случайных величин X и Y одинаковы.
Med(X) =
Если сравниваются медианы:
Гипотеза. Медианы случайных величин X и Y одинаковы.
Med(X) =

Слайд 23Основные условия применения статистических тестов
Вопрос должен касаться какой-либо характеристики массового явления.
Характеристика
Основные условия применения статистических тестов
Вопрос должен касаться какой-либо характеристики массового явления.
Характеристика

Слайд 24Пример 1
В обычных условиях зафиксирован некоторый уровень продаж. Затем была проведена рекламная
Пример 1
В обычных условиях зафиксирован некоторый уровень продаж. Затем была проведена рекламная

Слайд 25Основная проблема:
Увеличение продаж могло быть вызвано случайными факторами.
Продажи все время меняются,
Основная проблема:
Увеличение продаж могло быть вызвано случайными факторами.
Продажи все время меняются,

Слайд 26Пример 2
Разработан новый варианта упаковки товара.
Требуется проверить предположение, что товар в
Пример 2
Разработан новый варианта упаковки товара.
Требуется проверить предположение, что товар в

Слайд 27Пример 3
Верно ли, что основной конкурент действует на том же сегменте рынка,
Пример 3
Верно ли, что основной конкурент действует на том же сегменте рынка,

Слайд 28Пример 4
Фирма изучает постоянных покупателей своей продукции, чтобы увеличить их лояльность и
Пример 4
Фирма изучает постоянных покупателей своей продукции, чтобы увеличить их лояльность и

Слайд 29Пример 4. Часть 2
Статистическая формулировка: проверить гипотезы о независимости уровня лояльности и
Пример 4. Часть 2
Статистическая формулировка: проверить гипотезы о независимости уровня лояльности и

Слайд 30
Раздел 2
Технологии проверки статистических гипотез
Основные понятия
Раздел 2
Технологии проверки статистических гипотез
Основные понятия

Слайд 31Выбираем из двух гипотез!
Гипотеза принимается или отвергается
Так неудобно
Надо: выбираем между двумя
Выбираем из двух гипотез!
Гипотеза принимается или отвергается
Так неудобно
Надо: выбираем между двумя

Слайд 32Определение
Проверку гипотез на основе выборочных статистических данных называют статистической проверкой гипотез.
Определение
Проверку гипотез на основе выборочных статистических данных называют статистической проверкой гипотез.

Слайд 33Основная и альтернативная гипотезы
Одну из гипотез называют основной и обозначают, как правило,
Основная и альтернативная гипотезы
Одну из гипотез называют основной и обозначают, как правило,

Слайд 34Неточно говорить «…выбрана основная гипотеза…» или «…выбрана альтернативная гипотеза…»,
Неточно говорить
«…основная
Неточно говорить «…выбрана основная гипотеза…» или «…выбрана альтернативная гипотеза…»,
Неточно говорить
«…основная

Слайд 35Важное уточнение.
Правильно говорить
«основная гипотеза отвергнута…» и
«основная гипотеза не отвергнута…».
Так
Важное уточнение.
Правильно говорить
«основная гипотеза отвергнута…» и
«основная гипотеза не отвергнута…».
Так

Слайд 36Комментарий 1:
Гипотеза: число делится на 6 нацело.
Фактически проверяем, делится ли число на
Комментарий 1:
Гипотеза: число делится на 6 нацело.
Фактически проверяем, делится ли число на

Слайд 37Комментарий 2:
Часто случается, что у аналитика недостаточно данных, чтобы проявился изучаемый эффект.
Комментарий 2:
Часто случается, что у аналитика недостаточно данных, чтобы проявился изучаемый эффект.

Слайд 38Отвергнуть гипотезу недостаточно
Основная гипотеза при анализе: отличия между лекарствами нет.
Дело касается
Отвергнуть гипотезу недостаточно
Основная гипотеза при анализе: отличия между лекарствами нет.
Дело касается

Слайд 39Вывод
Хотя часто можно услышать, что (основная) гипотеза принята, такое выражение неточно.
Точнее
Вывод
Хотя часто можно услышать, что (основная) гипотеза принята, такое выражение неточно.
Точнее

Слайд 40Ошибки первого и второго рода
Ошибка первого рода состоит в том, что отвергается
Ошибки первого и второго рода
Ошибка первого рода состоит в том, что отвергается

Слайд 41Аналогия
В больнице врач принимает решение, направлять пациента на операцию, или нет.
Аналогия
В больнице врач принимает решение, направлять пациента на операцию, или нет.

Слайд 42Когда врач делает ошибку первого рода?
Когда врач делает ошибку второго рода?
Когда врач делает ошибку второго рода?

Слайд 43Гипотеза: нужна срочная операция
Гипотеза: нужна срочная операция

Слайд 44Может ли врач свести частоту (вероятность) ошибок первого рода к нулю?
Может
Может ли врач свести частоту (вероятность) ошибок первого рода к нулю?
Может

Слайд 45Есть исключения
Например,
если мы будем вакцинацию считать операцией,
то получается, что врачи
Есть исключения
Например,
если мы будем вакцинацию считать операцией,
то получается, что врачи

Слайд 46Последствия ошибок могут быть различными
Ошибка первого рода (обычно) опаснее, но полностью избежать
Последствия ошибок могут быть различными
Ошибка первого рода (обычно) опаснее, но полностью избежать

Слайд 47Уровень значимости
Долю ошибок первого рода ограничивают сверху числом, называемым уровень значимости.
Уровень значимости
Долю ошибок первого рода ограничивают сверху числом, называемым уровень значимости.

Слайд 48Для новичков!
Чаще всего уровень значимости равен 0,05
На самом деле выбор уровня значимости
Для новичков!
Чаще всего уровень значимости равен 0,05
На самом деле выбор уровня значимости

Слайд 49«медицинский» пример
На что влияет выбор уровня значимости?
Проектирование атомной электростанции
Трелевочный трактор
«медицинский» пример
На что влияет выбор уровня значимости?
Проектирование атомной электростанции
Трелевочный трактор

Слайд 50Ошибка второго рода и мощность
Как добиться того, чтобы вероятность ошибки второго рода
Ошибка второго рода и мощность
Как добиться того, чтобы вероятность ошибки второго рода

Слайд 51Дополнительно
Если выборка маленькая (часто границей между большой и маленькой выборкой рекомендуют считать
Дополнительно
Если выборка маленькая (часто границей между большой и маленькой выборкой рекомендуют считать

Слайд 52Задача.
Вместо врача рассмотрим банковского служащего, принимающего решение, выдавать заем или нет.
Задача.
Вместо врача рассмотрим банковского служащего, принимающего решение, выдавать заем или нет.

Слайд 53Алгоритм проверки статистических гипотез
1. Имеются n наблюдений , то есть n
Алгоритм проверки статистических гипотез
1. Имеются n наблюдений , то есть n

Слайд 543. Задан статистический критерий, то есть функция от наблюдений .
4. Найдено
3. Задан статистический критерий, то есть функция от наблюдений .
4. Найдено

Слайд 555. Проверяются все условия, при которых критерий будет работать.
Условия – Из учебника
5. Проверяются все условия, при которых критерий будет работать.
Условия – Из учебника

Слайд 566.
Если p< α - гипотезу отвергаем, если p> α - не
6.
Если p< α - гипотезу отвергаем, если p> α - не

Слайд 57Комментарии
Наблюдения не обязательно являются числами.
Выбор того статистического критерия, который подходит
Комментарии
Наблюдения не обязательно являются числами.
Выбор того статистического критерия, который подходит

Слайд 58Проверка условий применимости
Например, для применения t – критерия Стьюдента или для проверка
Проверка условий применимости
Например, для применения t – критерия Стьюдента или для проверка

Слайд 59Статистика критерия или
тестовая статистикой
Иногда используют статистику критерия или тестовую статистику.
Изредка
Статистика критерия или
тестовая статистикой
Иногда используют статистику критерия или тестовую статистику.
Изредка

Слайд 60Интерпретация статистики критерия
Значение статистики критерия (обычно) измеряет, насколько данные согласуются с гипотезой.
Интерпретация статистики критерия
Значение статистики критерия (обычно) измеряет, насколько данные согласуются с гипотезой.

Слайд 61"Маленькие" значения статистики критерия указывают, что данные «ведут себя» в соответствии с
"Маленькие" значения статистики критерия указывают, что данные «ведут себя» в соответствии с

Слайд 62"Большие" значения статистики критерия указывают, что данные не соответствуют гипотезе, противоречат ей.
Гипотеза
"Большие" значения статистики критерия указывают, что данные не соответствуют гипотезе, противоречат ей.
Гипотеза

Слайд 63Пример
Нормальное распределение с дисперсией 1
Имеется n наблюдений
Основная гипотеза: математическое ожидание равно
Пример
Нормальное распределение с дисперсией 1
Имеется n наблюдений
Основная гипотеза: математическое ожидание равно

Слайд 64Напоминание из теории вероятностей
Среднее арифметическое n независимых одинаково распределенных случайных величин с
Напоминание из теории вероятностей
Среднее арифметическое n независимых одинаково распределенных случайных величин с

Слайд 65Вопрос:
Где на графике ошибка первого рода, где ошибка второго рода?
Вопрос:
Где на графике ошибка первого рода, где ошибка второго рода?

Слайд 66Интерпретация статистики критерия
В статистике существует традиция, что именно задавать в качестве основной
Интерпретация статистики критерия
В статистике существует традиция, что именно задавать в качестве основной

Слайд 67Раздел 3
Важные частные случаи
Раздел 3
Важные частные случаи

Слайд 68
Проверка гипотезы о нормальности распределения случайной величины
Проверка гипотезы о нормальности распределения случайной величины

Слайд 69Статистическая формулировка
Гипотеза: Случайная величина имеет нормальное распределение, значения параметров распределения заранее не
Статистическая формулировка
Гипотеза: Случайная величина имеет нормальное распределение, значения параметров распределения заранее не

Слайд 70Критерий Шапиро-Уилка
Критерий Шапиро-Уилка.
shapiro.test(data)
От 3 до 5000 наблюдений
Критерий Шапиро-Уилка
Критерий Шапиро-Уилка.
shapiro.test(data)
От 3 до 5000 наблюдений

Слайд 71Package "nortest"
Критерий Anderson-Darling
library(nortest)
ad.test(data)
Критерий Lilliefors (Kolmogorov-Smirnov)
library(nortest)
lillie.test(x)
Package "nortest"
Критерий Anderson-Darling
library(nortest)
ad.test(data)
Критерий Lilliefors (Kolmogorov-Smirnov)
library(nortest)
lillie.test(x)

Слайд 72Число наблюдений
Если анализируется меньше 60 (2000) наблюдений, рекомендуется использовать критерий Шапиро-Уилка
если больше
Число наблюдений
Если анализируется меньше 60 (2000) наблюдений, рекомендуется использовать критерий Шапиро-Уилка
если больше

Слайд 73
А нужно ли проверять гипотезу нормальности?
А нужно ли проверять гипотезу нормальности?

Слайд 74Как оказалось, для тех методов, которые рассматриваются в курсе, требование нормальности распределения
Как оказалось, для тех методов, которые рассматриваются в курсе, требование нормальности распределения

Слайд 75допустим известно, что распределение случайной величины не нормальное.
В каком случае отклонение
допустим известно, что распределение случайной величины не нормальное.
В каком случае отклонение

Слайд 76Итак,
гипотеза о нормальности распределения изучаемой переменной уже отвергнута.
Итак,
гипотеза о нормальности распределения изучаемой переменной уже отвергнута.

Слайд 77Существенные отклонения
1. Наличие выбросов в данных.
2. Явная асимметрия гистограммы.
3. Очень
Существенные отклонения
1. Наличие выбросов в данных.
2. Явная асимметрия гистограммы.
3. Очень

Слайд 78Рекомендуется
строго относиться к присутствию выбросов,
снисходительно к отклонениям от симметрии.
Наше отношение к
Рекомендуется
строго относиться к присутствию выбросов,
снисходительно к отклонениям от симметрии.
Наше отношение к



Слайд 82 Лекарство
Иногда оно опаснее болезни...
Выбросы — удаляем (осторожно!)
Асимметрия — преобразуем данные
Лекарство
Иногда оно опаснее болезни...
Выбросы — удаляем (осторожно!)
Асимметрия — преобразуем данные

Слайд 83Пример 1
Население городов России в 1959 году
Исходные данные
Логарифм населения
Пример 1
Население городов России в 1959 году
Исходные данные
Логарифм населения

Слайд 84Пример 2
Альбукерк – продажи домов
Пример 2
Альбукерк – продажи домов

Слайд 85
Сравнение центров распределений
Сравнение центров распределений

Слайд 86Сравнение центров распределений
Центр распределения - то одно единственное число, которое описывало,
Сравнение центров распределений
Центр распределения - то одно единственное число, которое описывало,

Слайд 87Другие методы
оценки центра распределения
Andrews; Bickel; Hampel; Huber; Rogers, Tukey.
Robust
Другие методы
оценки центра распределения
Andrews; Bickel; Hampel; Huber; Rogers, Tukey.
Robust

Слайд 88Среднее арифметическое или медиана?
Если распределение хотя бы одной из выборок существенно отличается
Среднее арифметическое или медиана?
Если распределение хотя бы одной из выборок существенно отличается

Слайд 89Выбор центра распределения
Если центром распределения выбрана медиана, центры сравниваются с помощью критерия
Выбор центра распределения
Если центром распределения выбрана медиана, центры сравниваются с помощью критерия

Слайд 90Примеры
Обучение менеджеров
Магазины
Примеры
Обучение менеджеров
Магазины

Слайд 91Парные и независимые выборки
В случае парных выборок имеются пары наблюдений (измерений) одного
Парные и независимые выборки
В случае парных выборок имеются пары наблюдений (измерений) одного

Слайд 92Независимые выборки
В случае независимых выборок каждое наблюдение соответствует отдельному объекту, т.е. измеряются
Независимые выборки
В случае независимых выборок каждое наблюдение соответствует отдельному объекту, т.е. измеряются

Слайд 93Независимые и парные выборки
Если выборки парные, используется опция paired = TRUE.
Если выборки
Независимые и парные выборки
Если выборки парные, используется опция paired = TRUE.
Если выборки

Слайд 94Примеры
Время в магазинах
Альбукерк
Примеры
Время в магазинах
Альбукерк

Слайд 95Сравнение медиан выборок
Гипотеза: Медианы равны.
Альтернативная гипотеза: Медианы различаются.
Сравнение медиан выборок
Гипотеза: Медианы равны.
Альтернативная гипотеза: Медианы различаются.

Слайд 96Статистика критерия Манна-Уитни U
U1 = n1*n2 + {n1 * (n1 + 1)/2}
Статистика критерия Манна-Уитни U
U1 = n1*n2 + {n1 * (n1 + 1)/2}

Слайд 97Статистика критерия Манна-Уитни
идея метода
Обозначим одну выборку x, другую y.
Для каждого наблюдения из
Статистика критерия Манна-Уитни
идея метода
Обозначим одну выборку x, другую y.
Для каждого наблюдения из

Слайд 98 Важно!
Критерий Манна-Уитни проверяет не равенство медиан, а другое утверждение.
Имеются две
Важно!
Критерий Манна-Уитни проверяет не равенство медиан, а другое утверждение.
Имеются две

Слайд 99Under more strict assumptions than those above, e.g., if the responses are
Under more strict assumptions than those above, e.g., if the responses are

Слайд 100Критерий
Манна-Уитни-Вилкоксона
wilcox.test(x, y,
alternative = "two.sided",
paired = FALSE,
Критерий
Манна-Уитни-Вилкоксона
wilcox.test(x, y,
alternative = "two.sided",
paired = FALSE,

Слайд 101Примеры
Время в магазинах
Альбукерк
Примеры
Время в магазинах
Альбукерк

Слайд 102Сравнение средних значений выборок
Гипотеза: Математические ожидания равны.
Альтернативная гипотеза: Математические ожидания различны.
Сравнение средних значений выборок
Гипотеза: Математические ожидания равны.
Альтернативная гипотеза: Математические ожидания различны.

Слайд 103T-критерий Стьюдента
t.test(x, y, alternative = "two.sided", paired = FALSE, var.equal = FALSE)
T-критерий Стьюдента
t.test(x, y, alternative = "two.sided", paired = FALSE, var.equal = FALSE)

Слайд 104Выбор статистического критерия
Если выборки парные, рекомендуется использовать парный t-критерий Стьюдента.
Если выборки независимые,
Выбор статистического критерия
Если выборки парные, рекомендуется использовать парный t-критерий Стьюдента.
Если выборки независимые,

Слайд 105Надо еще сравнить дисперсии - 1
Метод 1
F-test of equality of variances
Не рекомендуется,
Надо еще сравнить дисперсии - 1
Метод 1
F-test of equality of variances
Не рекомендуется,

Слайд 106Надо еще сравнить дисперсии - 2
Метод 2
Bartlett's test
Если данные нормально распределены, лучший
Надо еще сравнить дисперсии - 2
Метод 2
Bartlett's test
Если данные нормально распределены, лучший

Слайд 107Надо еще сравнить дисперсии - 2
Метод 2
Bartlett's test
bartlett.test(x, g, data=data.table)
bartlett.test(x~g, data=data.table)
Надо еще сравнить дисперсии - 2
Метод 2
Bartlett's test
bartlett.test(x, g, data=data.table)
bartlett.test(x~g, data=data.table)

Слайд 108Надо еще сравнить дисперсии - 3
Levene's test
Критерий Ливиня/Левена
Содержится в пакете car
Надо еще сравнить дисперсии - 3
Levene's test
Критерий Ливиня/Левена
Содержится в пакете car

Слайд 109Надо еще сравнить дисперсии - 3
Levene's test
library(car)
leveneTest(x~g, data=data.table)
Надо еще сравнить дисперсии - 3
Levene's test
library(car)
leveneTest(x~g, data=data.table)

Слайд 110Надо еще сравнить дисперсии - 4
Fligner-Killeen test
Робастный, рекомендуется.
Хотя есть еще Brown-Forsythe test,
Надо еще сравнить дисперсии - 4
Fligner-Killeen test
Робастный, рекомендуется.
Хотя есть еще Brown-Forsythe test,

Слайд 111Надо еще сравнить дисперсии - 4
Fligner-Killeen test
fligner.test(x~g, data=data.table)
Надо еще сравнить дисперсии - 4
Fligner-Killeen test
fligner.test(x~g, data=data.table)

Слайд 112Примеры
Время в магазинах
Альбукерк
Примеры
Время в магазинах
Альбукерк

Слайд 113Гипотеза независимости
Основная гипотеза:
Случайные величины X и Y независимы
Альтернативная гипотеза:
Случайные величины X и
Гипотеза независимости
Основная гипотеза:
Случайные величины X и Y независимы
Альтернативная гипотеза:
Случайные величины X и

Слайд 114На практике:
Отвечаем на вопрос: переменная X влияет на переменную Y?
На практике:
Отвечаем на вопрос: переменная X влияет на переменную Y?

Слайд 115Комментарий
Если неизвестно, что на что влияет:
X на Y или
Y на X
статистический
Комментарий
Если неизвестно, что на что влияет:
X на Y или
Y на X
статистический

Слайд 116Пример Бернарда Шоу
Пример Бернарда Шоу

Слайд 117Диаграмма рассеивания
Иногда пишут - диаграмма рассеяния
Пример – швейцарские банкноты.
Диаграмма рассеивания
Иногда пишут - диаграмма рассеяния
Пример – швейцарские банкноты.

Слайд 118Зависимость -1
X – в количественной шкале
Y – в количественной шкале
Применяется коэффициент корреляции
Зависимость -1
X – в количественной шкале
Y – в количественной шкале
Применяется коэффициент корреляции

Слайд 119Функциональная зависимость
Функциональная зависимость

Слайд 120Статистическая зависимость
двух переменных
Обобщение функциональной зависимости.
Одному и тому же значению x могут
Статистическая зависимость
двух переменных
Обобщение функциональной зависимости.
Одному и тому же значению x могут

Слайд 121статистическая зависимость
Определение статистическая зависимость – это функциональная зависимость СРЕДНЕГО значения переменной y
статистическая зависимость
Определение статистическая зависимость – это функциональная зависимость СРЕДНЕГО значения переменной y

Слайд 122среднее значение переменной y равно натуральному логарифму значения x.
среднее значение переменной y равно натуральному логарифму значения x.

Слайд 123среднее значение переменной y равно натуральному логарифму значения x.
среднее значение переменной y равно натуральному логарифму значения x.

Слайд 124Коэффициент корреляции как «градусник», измеряющий степень зависимости
Формула для коэффициента корреляции
Формула для коэффициента корреляции

Слайд 125Выбор коэффициента
Если распределение каждой переменной несущественно отличается от нормального, применяется коэффициент корреляции
Выбор коэффициента
Если распределение каждой переменной несущественно отличается от нормального, применяется коэффициент корреляции

Слайд 127Как проявляется зависимость на диаграмме рассеивания

Слайд 128Коэффициент корреляции равен 1
Коэффициент корреляции равен 1

Слайд 129Коэффициент корреляции равен 0.9
Коэффициент корреляции равен 0.9

Слайд 130Коэффициент корреляции равен 0.8
Коэффициент корреляции равен 0.8

Слайд 131Коэффициент корреляции равен 0.6
Коэффициент корреляции равен 0.6

Слайд 132Коэффициент корреляции равен 0.4
Коэффициент корреляции равен 0.4

Слайд 133Коэффициент корреляции равен 0.2
Коэффициент корреляции равен 0.2

Слайд 134Коэффициент корреляции равен 0.
Коэффициент корреляции равен 0.

Слайд 135Проблемы и ошибки при использовании коэффициента корреляции



Слайд 138Данные без выброса
коэффициент корреляции равен -0.81
Данные без выброса
коэффициент корреляции равен -0.81

Слайд 139Добавлен выброс в точке (10,10). Коэффициент корреляции упал до -0,55.
Добавлен выброс в точке (10,10). Коэффициент корреляции упал до -0,55.

Слайд 140Выброс сдвинут в точку (18,5, 18,5) Коэффициент равен 0
Выброс сдвинут в точку (18,5, 18,5) Коэффициент равен 0

Слайд 141Выброс сдвинут в точку (53, 53). Корреляция равна +0,81
Выброс сдвинут в точку (53, 53). Корреляция равна +0,81

Слайд 142Ложная корреляция

Слайд 143Зависимость -2
X – в количественной шкале
Y – в номинальной шкале
Сравниваем средние или
Зависимость -2
X – в количественной шкале
Y – в номинальной шкале
Сравниваем средние или

Слайд 144Зависимость -3
X – в порядковой шкале
Y – в порядковой шкале
Используем коэффициент корреляции
Зависимость -3
X – в порядковой шкале
Y – в порядковой шкале
Используем коэффициент корреляции

Слайд 145Зависимость -4
X – в номинальной шкале
Y – в номинальной шкале
Таблица сопряженности и
Зависимость -4
X – в номинальной шкале
Y – в номинальной шкале
Таблица сопряженности и

Слайд 146Критерий хи-квадрат
Формула для статистики
Критерий хи-квадрат
Формула для статистики

Слайд 147Статистика хи-квадрат как коэффициент корреляции
Коэффициент Пирсона
Коэффициент Чупрова
Статистика хи-квадрат как коэффициент корреляции
Коэффициент Пирсона
Коэффициент Чупрова

Слайд 148Примеры типичных ошибок при использовании критерия хи-квадрат

Слайд 149Пример 1
Действительно ли использование Internet связано с полом?
Все опрошенные пользуются Интернетом. Тех
Пример 1
Действительно ли использование Internet связано с полом?
Все опрошенные пользуются Интернетом. Тех

Слайд 150Пример 1
sex = пол.
Кодировка: "1" – мужчина, "0" – женщина.
internet = использование
Пример 1
sex = пол.
Кодировка: "1" – мужчина, "0" – женщина.
internet = использование

Слайд 151Пример 1
Пример 1

Слайд 152Пример 2
В результате изучения связи между покупкой модной одежды и семейным положением
Пример 2
В результате изучения связи между покупкой модной одежды и семейным положением

Слайд 153Пример 2
Переменные.
sex = пол.
Кодировка: "1" – мужчина, "0" – женщина.
marriage = семейное
Пример 2
Переменные.
sex = пол.
Кодировка: "1" – мужчина, "0" – женщина.
marriage = семейное

Слайд 154Пример 2
Пример 2

Слайд 155Пример 2
Пример 2

Слайд 156Пример 2
Пример 2

Слайд 157Пример 3
Маркетолог проводит исследование для рекламного агентства, разрабатывающего рекламу для автомобилей стоимостью
Пример 3
Маркетолог проводит исследование для рекламного агентства, разрабатывающего рекламу для автомобилей стоимостью

Слайд 158Пример 3
Переменные.
high_edu = образование.
Кодировка: "1" – высшее образование, "0" – нет высшего
Пример 3
Переменные.
high_edu = образование.
Кодировка: "1" – высшее образование, "0" – нет высшего

Слайд 159Пример 3
Пример 3

Слайд 160Пример 3
Пример 3

Слайд 161Пример 3
Пример 3

Слайд 162Пример 4
Маркетолог, исследующий сферу туристических поездок за границу, предположил, что на желание
Пример 4
Маркетолог, исследующий сферу туристических поездок за границу, предположил, что на желание

Слайд 163Пример 4
Переменные.
desire = желание совершить путешествие за границу.
Кодировка: "1" – желание есть,
Пример 4
Переменные.
desire = желание совершить путешествие за границу.
Кодировка: "1" – желание есть,

Слайд 164Пример 4
Пример 4

Слайд 165Пример 4
Пример 4

Слайд 166Пример 4
Пример 4

Слайд 167Пример 4
Пример 4

Слайд 168Пример 5
Результаты анкетирования о проведении семейного досуга содержат, среди прочего, следующую информацию.
Переменные.
fastfood
Пример 5
Результаты анкетирования о проведении семейного досуга содержат, среди прочего, следующую информацию.
Переменные.
fastfood

Слайд 169Пример 5
Пример 5

Слайд 170Пример 5
Пример 5

 Построение аксонометрических проекций геометрических фигур и тел
Построение аксонометрических проекций геометрических фигур и тел Проценты
Проценты Числовые последовательности. Арифметическая прогрессия. Геометрическая прогрессия
Числовые последовательности. Арифметическая прогрессия. Геометрическая прогрессия Виды многоугольников. Свойства квадрата и прямоугольника. Спорт и туризм укрепляют организм
Виды многоугольников. Свойства квадрата и прямоугольника. Спорт и туризм укрепляют организм Решение дифференциальных уравнений первого порядка
Решение дифференциальных уравнений первого порядка Объём. Начало геометрии
Объём. Начало геометрии Статистика. Занятие 2
Статистика. Занятие 2 Интервальное оценивание параметров распределения случайных величин. Доверительный интервал
Интервальное оценивание параметров распределения случайных величин. Доверительный интервал Путешествие по океану МиФ Математики и Фантазии
Путешествие по океану МиФ Математики и Фантазии График функции
График функции Десятки. Мозаика заданий
Десятки. Мозаика заданий Задача о поиске устойчивых паросочетаний. (Лекция 11)
Задача о поиске устойчивых паросочетаний. (Лекция 11) Многочлен. Основные понятия. Определение многочлена
Многочлен. Основные понятия. Определение многочлена Теория вероятности
Теория вероятности Презентация на тему Задачи по теме "Обыкновенные дроби"
Презентация на тему Задачи по теме "Обыкновенные дроби"  множества
множества Л.10_Непрерывность функции
Л.10_Непрерывность функции Интеллектуальный марафон
Интеллектуальный марафон Поворот и центральная симметрия
Поворот и центральная симметрия Прямоугольный треугольник и его свойства. Единственность перпендикуляра к прямой
Прямоугольный треугольник и его свойства. Единственность перпендикуляра к прямой Логарифмические уравнения
Логарифмические уравнения Арифметические действия
Арифметические действия Путешествие в страну Геометрию
Путешествие в страну Геометрию Подготовка к ПА
Подготовка к ПА Упрощение выражений. Тест
Упрощение выражений. Тест Презентация на тему Виды симметрии. Центральная и осевая симметрия
Презентация на тему Виды симметрии. Центральная и осевая симметрия  Домашнее задание. Решение задач
Домашнее задание. Решение задач Задачи на кратное сравнение
Задачи на кратное сравнение