- Регрессионный анализ. Линейная регрессионная модель

Содержание
- 2. Если расчёт коэффициентов корреляции характеризует силу связи между двумя переменными, то регрессионный анализ служит для определения
- 3. Линейная регрессионная модель Прежде чем приступать к построению регрессионной модели обратимся к диаграмме рассеивания, она поможет
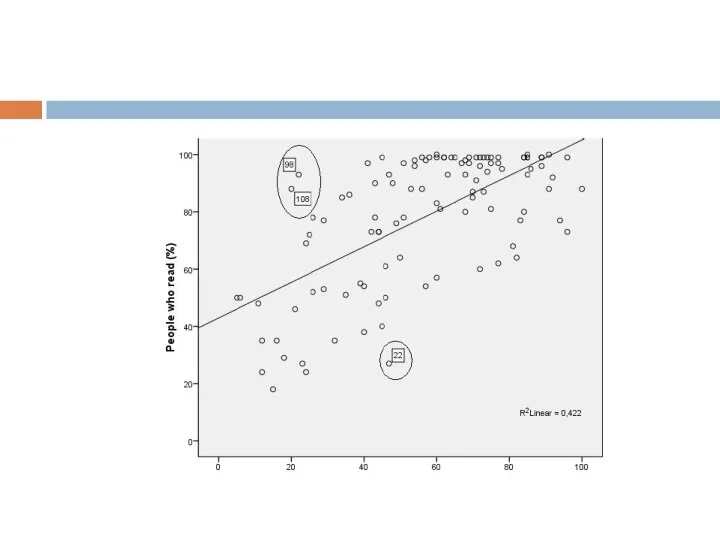
- 4. На графике мы можем наблюдать линейную зависимость между переменными, а, следовательно, приступить к построению линейной регрессии.
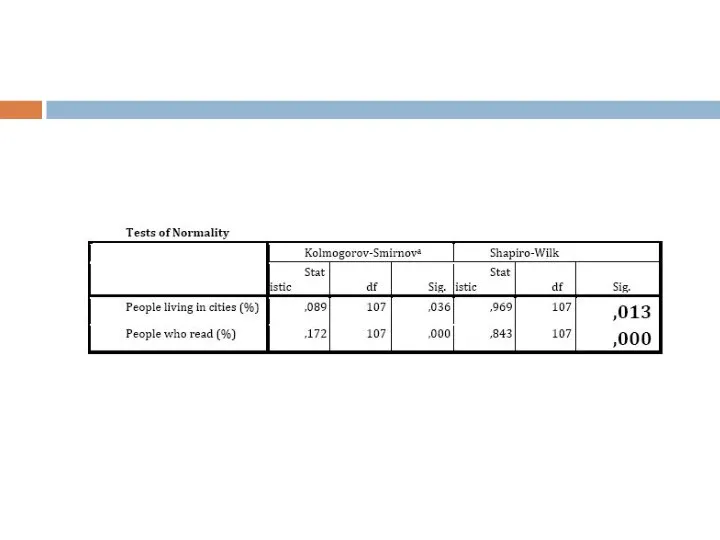
- 6. И последнее что необходимо проверить перед построением регрессионной модели это нормальность распределения наших переменных (это необходимо
- 8. Для того чтобы интерпретировать полученные результаты сформулируем две гипотезы. Н0: распределение значений переменной не отличается от
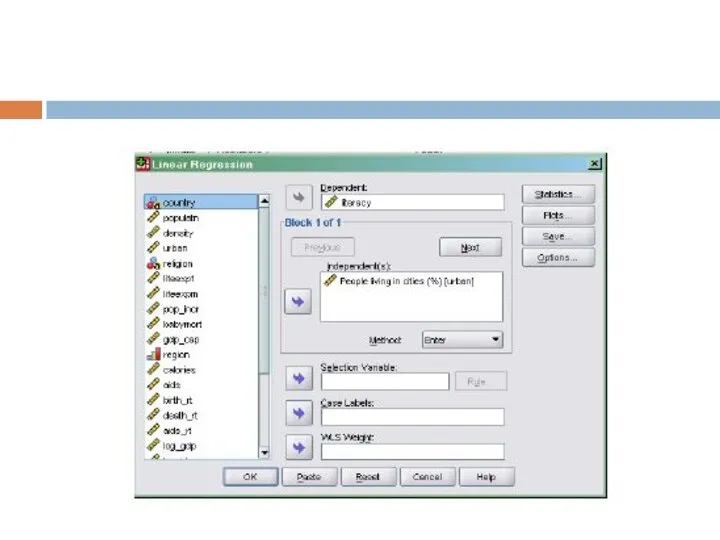
- 9. Теперь приступим к построению линейной регрессионной модели. Для того чтобы осуществить линейный регрессионный анализ необходимо выполнить
- 11. После добавления переменных заходим во вкладки. Во вкладке Save сохраняем предсказанные значения (Predicted Values‐ Unstandardized) и
- 13. Итак, мы с вами видим, что наша модель неплохая, и объясняет 42% случаев. Казалось бы, все
- 15. Для того чтобы правильно интерпретировать результаты этой таблицы нам необходимо сформулировать гипотезы, как мы это делали
- 17. Таким образом, мы можем сделать вывод о том, что чем больше численность городского населения, тем больше
- 18. Множественная регрессия Множественная регрессия отличается от простой только количеством независимых переменных, поэтому порядок действий остается прежним.
- 19. Самым важным действием на данном этапе является работа с вкладками. Итак, первая вкладка Statistics, в ней
- 21. Интерпретация в целом ничем не отличается от того, что мы делали в простой модели. В первую
- 23. В первую очередь обращаем внимание на то, какие переменные наиболее важные, т.е. те, чьи значения высокие
- 24. Поскольку в нашей модели несколько независимых переменных, то мы можем говорить о таком понятии как мультиколлинеарность,
- 25. Данный показатель противоположен по смыслу толерантности, поэтому высокие значения VIF говорят нам о высокой мультиколлинеарности. Принято
- 26. !!! Следует помнить, что если по каким то причинам мы не можем удалить наши переменные из
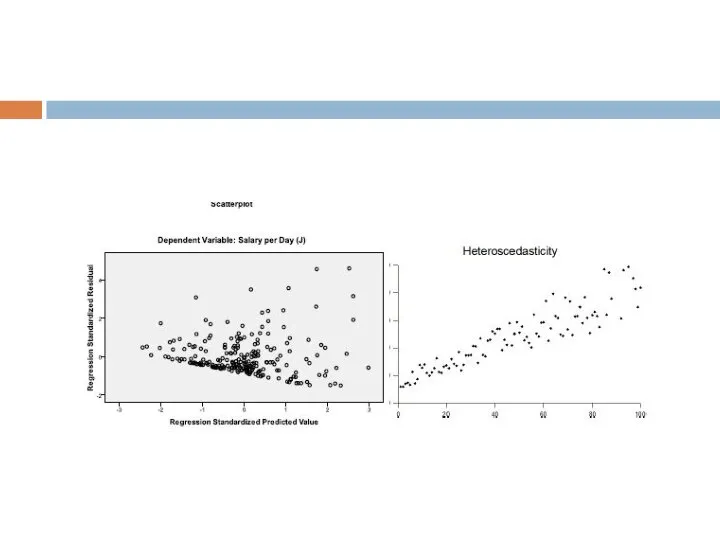
- 27. Теперь нам осталось оценить наши остатки на гомо или гетероскедастичность. Для этого мы построили диаграмму рассеивания.
- 29. Смотря на диаграмму, мы можем говорить об однородности наблюдений, т.е. о гомоскедастичности (нет общей тенденции, наблюдения
- 32. Скачать презентацию
Слайд 2 Если расчёт коэффициентов корреляции характеризует силу связи между двумя переменными, то регрессионный
Если расчёт коэффициентов корреляции характеризует силу связи между двумя переменными, то регрессионный

Слайд 3Линейная регрессионная модель
Прежде чем приступать к построению регрессионной модели обратимся к диаграмме
Линейная регрессионная модель
Прежде чем приступать к построению регрессионной модели обратимся к диаграмме

Слайд 4На графике мы можем наблюдать линейную зависимость между переменными, а, следовательно, приступить
На графике мы можем наблюдать линейную зависимость между переменными, а, следовательно, приступить

Слайд 6И последнее что необходимо проверить перед построением регрессионной модели это нормальность распределения
И последнее что необходимо проверить перед построением регрессионной модели это нормальность распределения

Слайд 8Для того чтобы интерпретировать полученные результаты сформулируем две гипотезы.
Н0: распределение значений переменной
Для того чтобы интерпретировать полученные результаты сформулируем две гипотезы.
Н0: распределение значений переменной

Слайд 9Теперь приступим к построению линейной регрессионной модели. Для того чтобы осуществить линейный
Теперь приступим к построению линейной регрессионной модели. Для того чтобы осуществить линейный

Слайд 11После добавления переменных заходим во вкладки. Во вкладке Save сохраняем предсказанные значения
После добавления переменных заходим во вкладки. Во вкладке Save сохраняем предсказанные значения

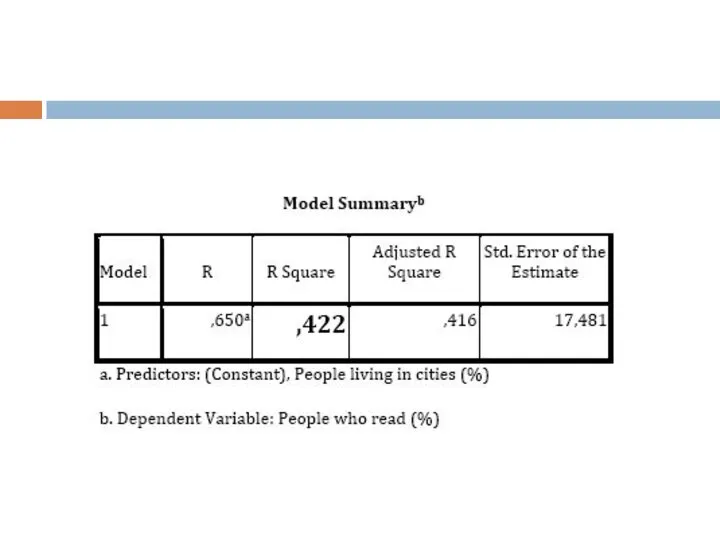
Слайд 13Итак, мы с вами видим, что наша модель неплохая, и объясняет 42%
Итак, мы с вами видим, что наша модель неплохая, и объясняет 42%

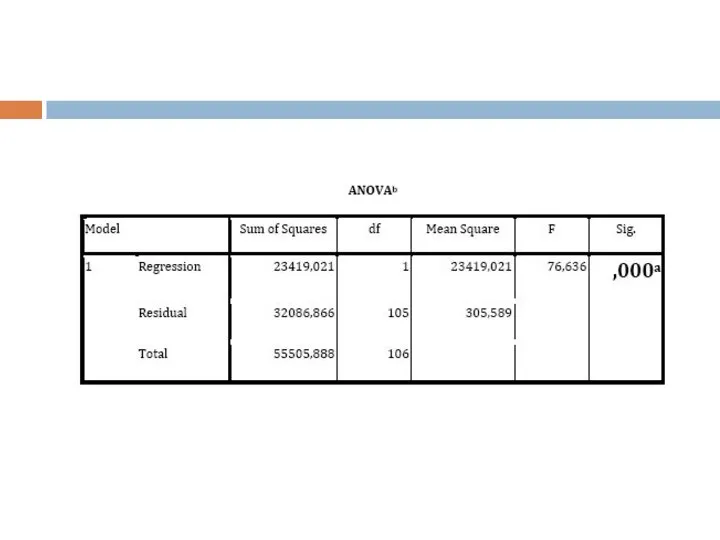
Слайд 15Для того чтобы правильно интерпретировать результаты этой таблицы нам необходимо сформулировать гипотезы,
Для того чтобы правильно интерпретировать результаты этой таблицы нам необходимо сформулировать гипотезы,


Слайд 17Таким образом, мы можем сделать вывод о том, что чем больше численность
Таким образом, мы можем сделать вывод о том, что чем больше численность

Слайд 18Множественная регрессия
Множественная регрессия отличается от простой только количеством независимых переменных, поэтому порядок
Множественная регрессия
Множественная регрессия отличается от простой только количеством независимых переменных, поэтому порядок

Слайд 19Самым важным действием на данном этапе является работа с вкладками. Итак, первая
Самым важным действием на данном этапе является работа с вкладками. Итак, первая

Слайд 21Интерпретация в целом ничем не отличается от того, что мы делали в
Интерпретация в целом ничем не отличается от того, что мы делали в

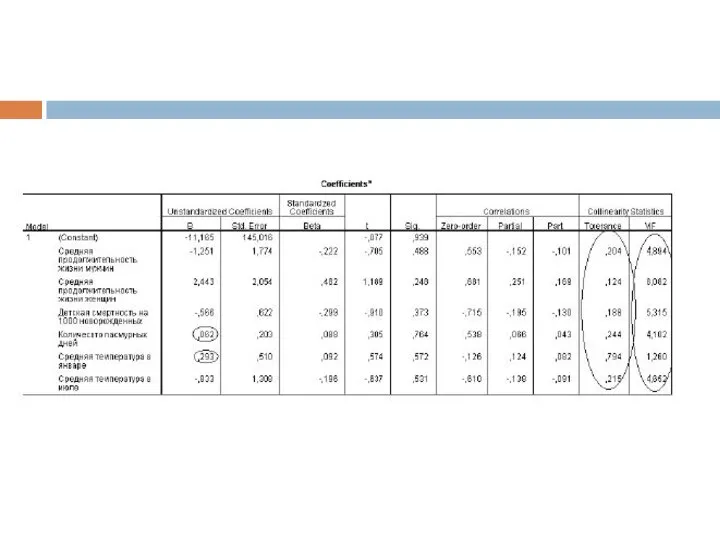
Слайд 23В первую очередь обращаем внимание на то, какие переменные наиболее важные, т.е.
В первую очередь обращаем внимание на то, какие переменные наиболее важные, т.е.

Слайд 24Поскольку в нашей модели несколько независимых переменных, то мы можем говорить о
Поскольку в нашей модели несколько независимых переменных, то мы можем говорить о

Слайд 25Данный показатель противоположен по смыслу толерантности, поэтому высокие значения VIF говорят нам
Данный показатель противоположен по смыслу толерантности, поэтому высокие значения VIF говорят нам

Слайд 26!!! Следует помнить, что если по каким то причинам мы не можем
!!! Следует помнить, что если по каким то причинам мы не можем

Слайд 27Теперь нам осталось оценить наши остатки на гомо или гетероскедастичность. Для этого
Теперь нам осталось оценить наши остатки на гомо или гетероскедастичность. Для этого

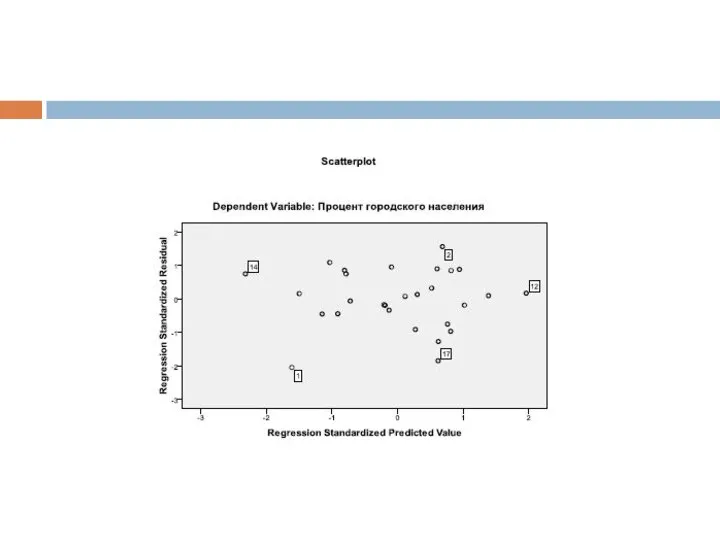
Слайд 29Смотря на диаграмму, мы можем говорить об однородности наблюдений, т.е. о гомоскедастичности
Смотря на диаграмму, мы можем говорить об однородности наблюдений, т.е. о гомоскедастичности

 Разработка тестов. Практическая работа № 5
Разработка тестов. Практическая работа № 5 Самая популярная газета в Сан-Фиерро
Самая популярная газета в Сан-Фиерро Сравнительный анализ сайтов. Сайты вузов
Сравнительный анализ сайтов. Сайты вузов FX Net. Практическая работа
FX Net. Практическая работа Текстовый процессор MS Word
Текстовый процессор MS Word Что такое айтишечка?
Что такое айтишечка? Компьютерные технологии и информационные системы. Тема 3.2
Компьютерные технологии и информационные системы. Тема 3.2 Почтовые программы
Почтовые программы Пошук у сетцы Інтэрнэт
Пошук у сетцы Інтэрнэт Інформація. Інформаційні процеси
Інформація. Інформаційні процеси Интерактивные форматы и особенности вёрстки в медиа
Интерактивные форматы и особенности вёрстки в медиа Презентация на тему Основные понятия и правила записи функций в Excel
Презентация на тему Основные понятия и правила записи функций в Excel  Однопроходные алгоритмы
Однопроходные алгоритмы Размещение графики на Web-страницах
Размещение графики на Web-страницах Системы счисления
Системы счисления О себе
О себе Типы данных в VBA
Типы данных в VBA Защита информации. Безопасность информации. Математический аппарат
Защита информации. Безопасность информации. Математический аппарат Электронные таблицы обработка числовой информации в электронных таблицах
Электронные таблицы обработка числовой информации в электронных таблицах Основные понятия теории управления сложными системами. Информационные технологии и их классификация
Основные понятия теории управления сложными системами. Информационные технологии и их классификация Компьютерная графика
Компьютерная графика Ростейшие преобразования изображений
Ростейшие преобразования изображений Логические основы компьютера
Логические основы компьютера Форматирование текста (шрифт)
Форматирование текста (шрифт) Динамические структуры данных
Динамические структуры данных Знакомство с языком программирования. Линейные вычислительные алгоритмы
Знакомство с языком программирования. Линейные вычислительные алгоритмы Паскаль. Ветвление
Паскаль. Ветвление Характеристика производственной системы. Тема №4
Характеристика производственной системы. Тема №4