- Сортировки. Внутренние сортировки (1)

Содержание
- 2. Понятие Сортировать - распределять, разбирать по сортам, качеству, размерам, по сходным признакам. (толковый словарь Ожегова) синонимы:
- 3. Классы сортировок сортировка массивов сортировка (последовательных) файлов. или внутренняя сортировка внешняя сортировка
- 4. Определение Частичным порядком на множестве S называется такое бинарное отношение R, что для любых а, b
- 5. Определение Линейным, или полным, порядком на множестве S называется такой частичный порядок R на S, что
- 6. Задача сортировки Пусть дана последовательность из n элементов а1 , а2 , … , аn ,
- 7. Задача сортировки Требуется найти такую перестановку π = (π(1), π(2),…, π(n)) этих n записей, после которой
- 8. Определение Алгоритм сортировки называется устойчивым, если в процессе сортировки относительное расположение элементов одинаковыми ключами не изменяется
- 9. Сортировки Все алгоритмы сортировки можно разбить на три группы: сортировка с помощью включения, сортировка выбором, сортировка
- 10. Сортировка с помощью включения Пусть элементы а1 , а2 , … , аi-1 , ; 1
- 11. Сортировка с помощью включения В зависимости от того, как происходит процесс включения элемента, различаю прямое включение
- 12. Алгоритм сортировки с помощью прямого включения Алгоритм insertion (a, n); Input: массив А, содержащий n чисел
- 13. Пример
- 14. Оценка трудоемкости алгоритма
- 15. Алгоритм двоичного включения Алгоритмinsertion2(a, n); for i ← 2to n{ x ← a[i]; L ←1; R
- 16. Алгоритм двоичного включения
- 17. Сортировка выбором Идея сортировки заключается в следующем: 1.Выбрать элемент с наименьшим ключом и поменять его с
- 18. Сортировка выбором Алгоритм selection (a, n); for i ← 1to n-1{ k ← i; for j
- 19. Оценка трудоемкости алгоритма В худшем случае: T(n)=Cn+T(n-1), T(1)=0; T(n)=Θ(n2)
- 20. Сортировка с помощью обменов Сортировки помощью обменов основываются на сравнении двух элементов. Если порядок элементов не
- 21. Сортировка с помощью обменов Пузырьковая сортировка Шейкерная сортировка
- 22. Пузырьковая сортировка Просматриваем исходную последовательность справа налево и на каждом шаге меньший из двух соседних элементов
- 23. Пузырьковая сортировка Алгоритм bubble_sort (a, n); for i ← 2to n { for j ← n
- 24. Шейкерная сортировка Анализ алгоритма пузырьковой сортировки приводит к следующим наблюдениям: Если при некотором из проходов нет
- 25. Шейкерная сортировка Алгоритм shaker_sort (a, n); L ← 2; R ← n; k ← n; repeat
- 26. Сортировка слиянием Сортировка слиянием заключается в следующем: 1.Делим последовательность элементов на две части; 2.Сортируем отдельно каждую
- 27. Процедура слияния отсортированных частей последовательности Алгоритм merge (a, L, Z, R); i ← L; j ←
- 28. Сортировка слиянием Алгоритм merge_sort (L, R); if (L ≠ R ){ k ← (L+R) div 2;
- 29. Быстрая сортировка (Хоара) Суть алгоритма состоит в следующем: 1.Выбрать некоторый элемент х для сравнения (это может
- 30. Быстрая сортировка Данные действия могу быть выполнены, например, следующим алгоритмом: просматриваем массив слева, пока не встретим
- 31. Быстрая сортировка Алгоритм quick_sort (L, R); x ← a[(L+R) div 2]; i ← L; j ←
- 32. Оценка сложности алгоритма Процедура разделения n элементов требует Cn операций, так как каждый элемент последовательности необходимо
- 33. Оценка сложности алгоритма Худшим случаем является ситуация, когда в качестве сравниваемого элемента выбирается наибольший из всех
- 34. Пример Фиксируем элемент x = 7 (средний)
- 35. Пример
- 36. Пример
- 37. Пример
- 38. Пример
- 39. Порядковые статистики Задача: дано множество из n чисел. Найти тот его элемент, который будет k-м по
- 40. Порядковые статистики Медианой (median) называется элемент множества, находящийся (по счёту) посередине между минимумом и максимумом. Точнее
- 41. Порядковые статистики Пример: 18 24 12 27 19 Медиана =19 Поиск медианы является частным случаем более
- 42. Выбор элемента с данным номером Дано: Множество А из n различных элементов и целое число k,
- 43. Выбор элемента с k номером (A1) Выполняется операция разделения на отрезке [L, R], где первоначально L
- 44. Реализация (A1) L ← 1; R ← n; while (L x ←A[k]; Разделение a[L] … a[R]
- 45. Оценка сложности алгоритма (A1) Если предположить, что разделение в среднем разбивает часть, где находится требуем элемент
- 46. Выбор элемента с k номером (A2) Разбиваем исходную последовательность А на n/5 подпоследовательностей по пять элементов
- 47. Оценка сложности алгоритма (A2) Таким образом, рекуррентное уравнение для описанного выше алгоритма имеет вид T(n) =
- 48. Сортировка вычерпыванием Алгоритм сортировки вычёрпыванием (bucket sort) работает за линейное (среднее) время. Эта сортировка годится не
- 49. Сортировка вычерпыванием промежуток [0; 1) делится на n равных частей, после чего для чисел из каждой
- 50. Алгоритм Алгоритм bucket_sort(A) n ← length[A] for i ← 1 to n { добавить A[i] к
- 51. Пример
- 52. Время работы алгоритма Операции во всех строках, кроме пятой, требуют (общего) времени Θ(n). Просмотр всех ящиков
- 53. Время работы алгоритма Т.к. числа распределены равномерно, а величины всех отрезков равны, вероятность того, что данное
- 54. Лексикографическая сортировка Пусть S некоторое множество на котором задан ‹– линейный порядок. Лексикографическим порядком на множестве
- 55. Лексикографическая сортировка Очевидно, что любое целое число можно считать k-членным кортежем цифр от 0 до n
- 56. Сортировка вычёрпыванием Создадим исходную очередь A из n элементов, в которую занесем все рассматриваемые кортежи длины
- 57. Рекуррентное уравнение для алгоритма Пусть m — количество организованных очередей, тогда трудоемкость сортировки кортежей по некоторой
- 58. Алгоритм Алгоритм lexicographical_sort k ← length(A[1]); for c ← ‘a’ to ‘z’ { B[c].tail ← null;
- 59. Алгоритм сортировки кортежей разной длины Сначала сортируемые кортежи располагаются в порядке убывания длины. Пусть lтах -
- 60. Алгоритм сортировки кортежей разной длины
- 61. Оценка сложности
- 62. Пример Дан массив: Один, Два, Три, Четыре, Пять, Шесть, Семь, Восемь, Девять, Десять Упорядочиваем по длине:
- 63. 1-я итерация Вспомогательный массив B: e: Четыре Ь: Восемь, Девять, Десять
- 64. 2-я итерация Вспомогательный массив B: м: Восемь р: Четыре т: Девять, Десять ь: Шесть
- 65. 3-я итерация Вспомогательный массив B: е: Восемь н: Один т: Шесть ь: Пять, Семь ы: Четыре
- 66. 4-я итерация Вспомогательный массив B: а: Два в: Девять и: Один, Три м: Семь с: Восемь,
- 67. 5-я итерация Вспомогательный массив B: в: Два д: Один е: Девять, Семь, Шесть, Десять, Четыре о:
- 68. 6-я итерация Вспомогательный массив B: в: Восемь д: Два, Девять, Десять о: Один п: Пять с:
- 69. Пирамидальная сортировка Сортировка пирамидой использует бинарное сортирующее дерево. Сортирующее дерево — это такое дерево, у которого
- 70. Пирамидальная сортировка Этап 1. Выстраиваем элементы массива в виде сортирующего дерева A[i] ≥ A[2i+1] A[i] ≥
- 71. Пирамидальная сортировка Этап 2. Будем удалять элементы из корня по одному за раз и перестраивать дерево,
- 72. Достоинства сортировки Имеет доказанную оценку худшего случая O(nlogn). Сортирует на месте, то есть требует всего O(1)
- 73. Недостатки сортировки Неустойчив — для обеспечения устойчивости нужно расширять ключ. На почти отсортированных массивах работает столь
- 74. Пример
- 75. Пример
- 76. Пример
- 78. Скачать презентацию
Слайд 2Понятие
Сортировать - распределять, разбирать по сортам, качеству, размерам, по сходным признакам. (толковый
Понятие
Сортировать - распределять, разбирать по сортам, качеству, размерам, по сходным признакам. (толковый

Слайд 3Классы сортировок
сортировка массивов
сортировка (последовательных) файлов.
или
внутренняя сортировка
внешняя сортировка
Классы сортировок
сортировка массивов
сортировка (последовательных) файлов.
или
внутренняя сортировка
внешняя сортировка

Слайд 4Определение
Частичным порядком на множестве S называется такое бинарное отношение R, что для
Определение
Частичным порядком на множестве S называется такое бинарное отношение R, что для

Слайд 5Определение
Линейным, или полным, порядком на множестве S называется такой частичный порядок R
Определение
Линейным, или полным, порядком на множестве S называется такой частичный порядок R

Слайд 6Задача сортировки
Пусть дана последовательность из n элементов а1 , а2 , …
Задача сортировки
Пусть дана последовательность из n элементов а1 , а2 , …

Слайд 7Задача сортировки
Требуется найти такую перестановку π = (π(1), π(2),…, π(n)) этих n
Задача сортировки
Требуется найти такую перестановку π = (π(1), π(2),…, π(n)) этих n

Слайд 8Определение
Алгоритм сортировки называется устойчивым, если в процессе сортировки относительное расположение элементов одинаковыми
Определение
Алгоритм сортировки называется устойчивым, если в процессе сортировки относительное расположение элементов одинаковыми

Слайд 9Сортировки
Все алгоритмы сортировки можно разбить на три группы:
сортировка с помощью включения,
Сортировки
Все алгоритмы сортировки можно разбить на три группы:
сортировка с помощью включения,

Слайд 10Сортировка с помощью включения
Пусть элементы а1 , а2 , … , аi-1
Сортировка с помощью включения
Пусть элементы а1 , а2 , … , аi-1

Слайд 11Сортировка с помощью включения
В зависимости от того, как происходит процесс включения элемента,
Сортировка с помощью включения
В зависимости от того, как происходит процесс включения элемента,

Слайд 12Алгоритм сортировки с помощью прямого включения
Алгоритм insertion (a, n);
Input: массив
Алгоритм сортировки с помощью прямого включения
Алгоритм insertion (a, n);
Input: массив

Слайд 13Пример
Пример
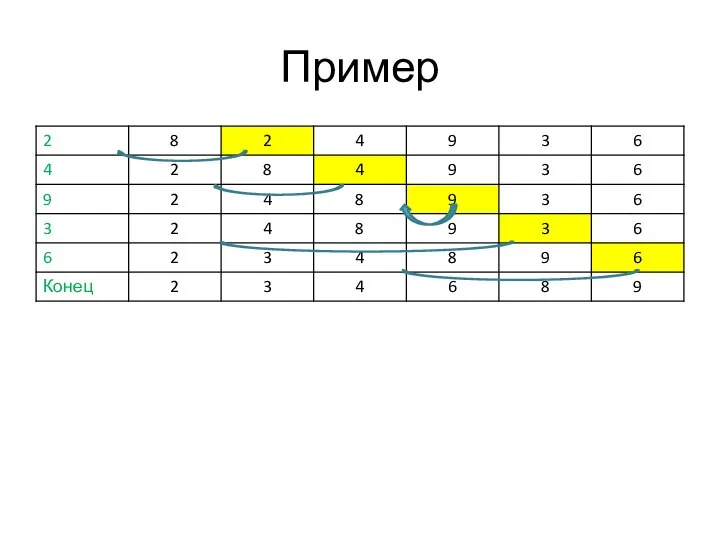
Слайд 14Оценка трудоемкости алгоритма
Оценка трудоемкости алгоритма

Слайд 15Алгоритм двоичного включения
Алгоритмinsertion2(a, n);
for i ← 2to n{
x ← a[i]; L
Алгоритм двоичного включения
Алгоритмinsertion2(a, n);
for i ← 2to n{
x ← a[i]; L

Слайд 16Алгоритм двоичного включения
Алгоритм двоичного включения

Слайд 17Сортировка выбором
Идея сортировки заключается в следующем:
1.Выбрать элемент с наименьшим ключом и поменять
Сортировка выбором
Идея сортировки заключается в следующем:
1.Выбрать элемент с наименьшим ключом и поменять

Слайд 18Сортировка выбором
Алгоритм selection (a, n);
for i ← 1to n-1{
k ← i;
for
Сортировка выбором
Алгоритм selection (a, n);
for i ← 1to n-1{
k ← i;
for

Слайд 19Оценка трудоемкости алгоритма
В худшем случае:
T(n)=Cn+T(n-1), T(1)=0;
T(n)=Θ(n2)
Оценка трудоемкости алгоритма
В худшем случае:
T(n)=Cn+T(n-1), T(1)=0;
T(n)=Θ(n2)

Слайд 20Сортировка с помощью обменов
Сортировки помощью обменов основываются на сравнении двух элементов.
Если порядок
Сортировка с помощью обменов
Сортировки помощью обменов основываются на сравнении двух элементов.
Если порядок

Слайд 21Сортировка с помощью обменов
Пузырьковая сортировка
Шейкерная сортировка
Сортировка с помощью обменов
Пузырьковая сортировка
Шейкерная сортировка

Слайд 22Пузырьковая сортировка
Просматриваем исходную последовательность справа налево и на каждом шаге меньший из
Пузырьковая сортировка
Просматриваем исходную последовательность справа налево и на каждом шаге меньший из

Слайд 23Пузырьковая сортировка
Алгоритм bubble_sort (a, n);
for i ← 2to n {
for j
Пузырьковая сортировка
Алгоритм bubble_sort (a, n);
for i ← 2to n {
for j

Слайд 24Шейкерная сортировка
Анализ алгоритма пузырьковой сортировки приводит к следующим наблюдениям:
Если при некотором из
Шейкерная сортировка
Анализ алгоритма пузырьковой сортировки приводит к следующим наблюдениям:
Если при некотором из

Слайд 25Шейкерная сортировка
Алгоритм shaker_sort (a, n);
L ← 2; R ← n; k ←
Шейкерная сортировка
Алгоритм shaker_sort (a, n);
L ← 2; R ← n; k ←

Слайд 26Сортировка слиянием
Сортировка слиянием заключается в следующем:
1.Делим последовательность элементов на две части;
2.Сортируем отдельно
Сортировка слиянием
Сортировка слиянием заключается в следующем:
1.Делим последовательность элементов на две части;
2.Сортируем отдельно

Слайд 27Процедура слияния отсортированных частей последовательности
Алгоритм merge (a, L, Z, R);
i ← L;
Процедура слияния отсортированных частей последовательности
Алгоритм merge (a, L, Z, R);
i ← L;

Слайд 28Сортировка слиянием
Алгоритм merge_sort (L, R);
if (L ≠ R ){
k ← (L+R)
Сортировка слиянием
Алгоритм merge_sort (L, R);
if (L ≠ R ){
k ← (L+R)

Слайд 29Быстрая сортировка (Хоара)
Суть алгоритма состоит в следующем:
1.Выбрать некоторый элемент х для сравнения
Быстрая сортировка (Хоара)
Суть алгоритма состоит в следующем:
1.Выбрать некоторый элемент х для сравнения

Слайд 30Быстрая сортировка
Данные действия могу быть выполнены, например, следующим алгоритмом:
просматриваем массив слева, пока
Быстрая сортировка
Данные действия могу быть выполнены, например, следующим алгоритмом:
просматриваем массив слева, пока

Слайд 31Быстрая сортировка
Алгоритм quick_sort (L, R);
x ← a[(L+R) div 2]; i ← L;
Быстрая сортировка
Алгоритм quick_sort (L, R);
x ← a[(L+R) div 2]; i ← L;
![Быстрая сортировка Алгоритм quick_sort (L, R); x ← a[(L+R) div 2]; i](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/993586/slide-30.jpg)
Слайд 32Оценка сложности алгоритма
Процедура разделения n элементов требует Cn операций, так как каждый
Оценка сложности алгоритма
Процедура разделения n элементов требует Cn операций, так как каждый

Слайд 33Оценка сложности алгоритма
Худшим случаем является ситуация, когда в качестве сравниваемого элемента выбирается
Оценка сложности алгоритма
Худшим случаем является ситуация, когда в качестве сравниваемого элемента выбирается

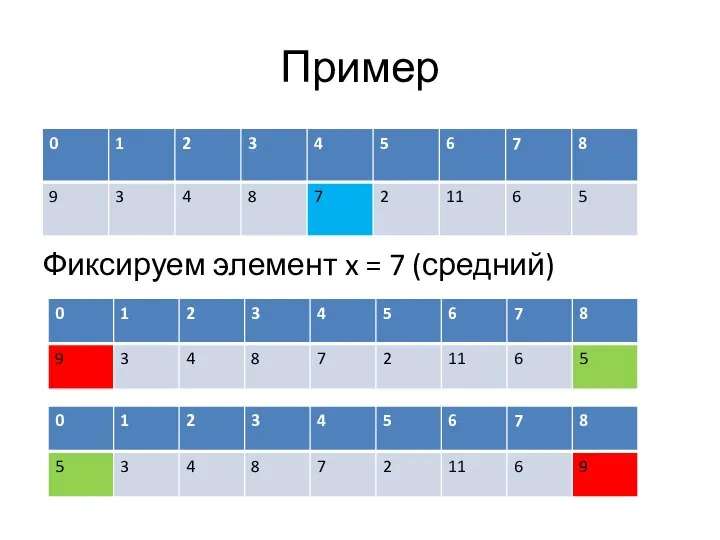
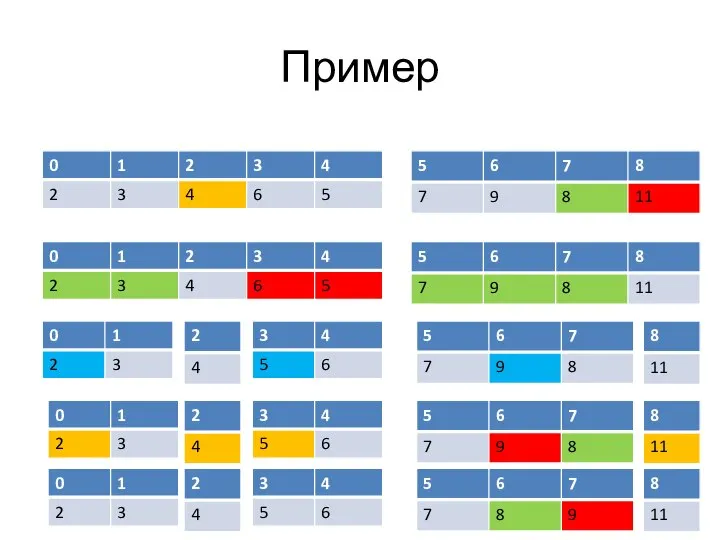
Слайд 34Пример
Фиксируем элемент x = 7 (средний)
Пример
Фиксируем элемент x = 7 (средний)
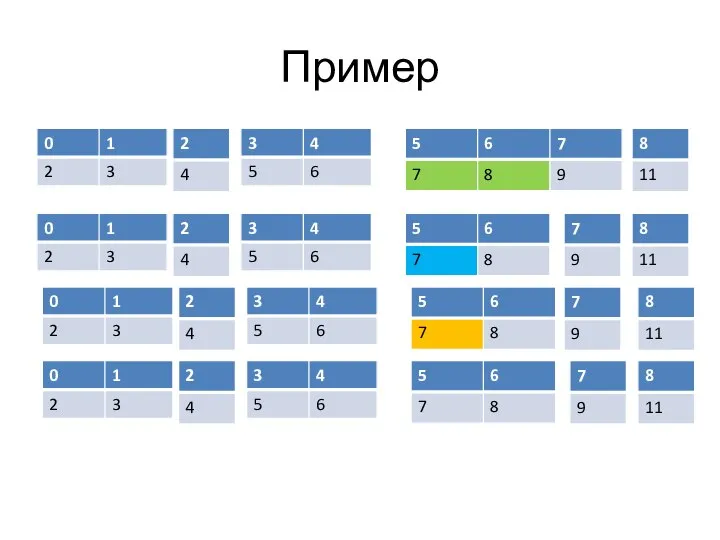
Слайд 35Пример
Пример
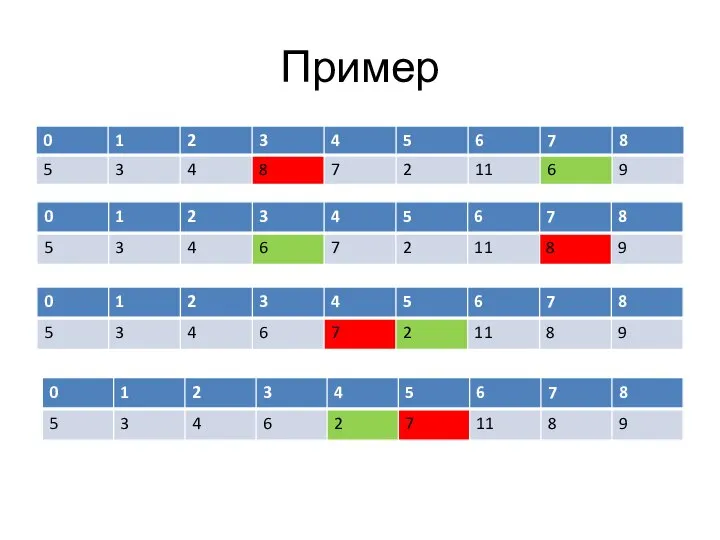
Слайд 36Пример
Пример
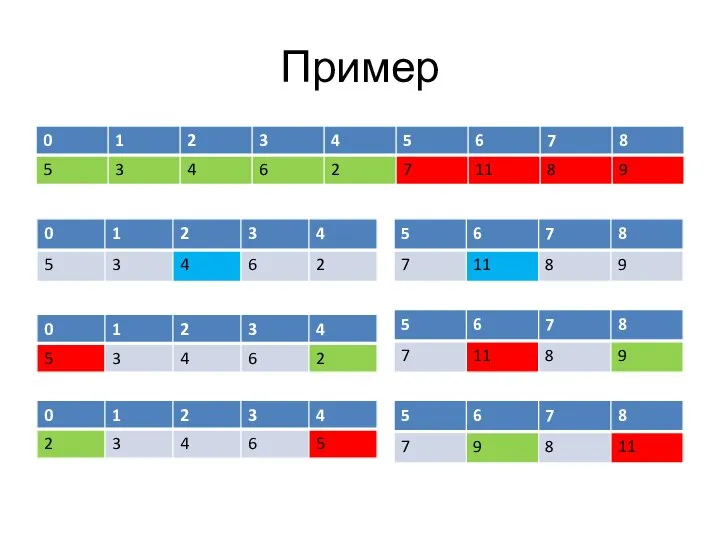
Слайд 37Пример
Пример
Слайд 38Пример
Пример
Слайд 39Порядковые статистики
Задача: дано множество из n чисел. Найти тот его элемент, который
Порядковые статистики
Задача: дано множество из n чисел. Найти тот его элемент, который

Слайд 40Порядковые статистики
Медианой (median) называется элемент множества, находящийся (по счёту) посередине между минимумом
Порядковые статистики
Медианой (median) называется элемент множества, находящийся (по счёту) посередине между минимумом

Слайд 41Порядковые статистики
Пример: 18 24 12 27 19
Медиана =19
Поиск медианы является
Порядковые статистики
Пример: 18 24 12 27 19
Медиана =19
Поиск медианы является

Слайд 42Выбор элемента с данным номером
Дано: Множество А из n различных элементов и
Выбор элемента с данным номером
Дано: Множество А из n различных элементов и

Слайд 43Выбор элемента с k номером (A1)
Выполняется операция разделения на отрезке [L, R],
Выбор элемента с k номером (A1)
Выполняется операция разделения на отрезке [L, R],

Слайд 44Реализация (A1)
L ← 1; R ← n;
while (L< k) {
x ←A[k];
Разделение
Реализация (A1)
L ← 1; R ← n;
while (L< k) {
x ←A[k];
Разделение
![Реализация (A1) L ← 1; R ← n; while (L x ←A[k];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/993586/slide-43.jpg)
Слайд 45Оценка сложности алгоритма (A1)
Если предположить, что разделение в среднем разбивает часть, где
Оценка сложности алгоритма (A1)
Если предположить, что разделение в среднем разбивает часть, где

Слайд 46Выбор элемента с k номером (A2)
Разбиваем исходную последовательность А на n/5 подпоследовательностей
Выбор элемента с k номером (A2)
Разбиваем исходную последовательность А на n/5 подпоследовательностей

Слайд 47Оценка сложности алгоритма (A2)
Таким образом, рекуррентное уравнение для описанного выше алгоритма имеет
Оценка сложности алгоритма (A2)
Таким образом, рекуррентное уравнение для описанного выше алгоритма имеет

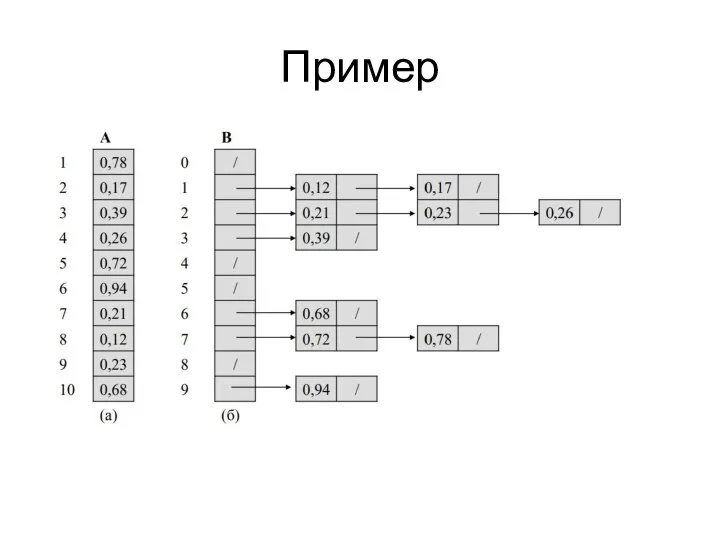
Слайд 48Сортировка вычерпыванием
Алгоритм сортировки вычёрпыванием (bucket sort) работает за линейное (среднее) время. Эта
Сортировка вычерпыванием
Алгоритм сортировки вычёрпыванием (bucket sort) работает за линейное (среднее) время. Эта

Слайд 49Сортировка вычерпыванием
промежуток [0; 1) делится на n равных частей, после чего для
Сортировка вычерпыванием
промежуток [0; 1) делится на n равных частей, после чего для

Слайд 50Алгоритм
Алгоритм bucket_sort(A)
n ← length[A]
for i ← 1 to n
{
Алгоритм
Алгоритм bucket_sort(A)
n ← length[A]
for i ← 1 to n
{
![Алгоритм Алгоритм bucket_sort(A) n ← length[A] for i ← 1 to n](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/993586/slide-49.jpg)
Слайд 51Пример
Пример
Слайд 52Время работы алгоритма
Операции во всех строках, кроме пятой, требуют (общего) времени Θ(n).
Время работы алгоритма
Операции во всех строках, кроме пятой, требуют (общего) времени Θ(n).

Слайд 53Время работы алгоритма
Т.к. числа распределены равномерно, а величины всех отрезков равны, вероятность
Время работы алгоритма
Т.к. числа распределены равномерно, а величины всех отрезков равны, вероятность

Слайд 54Лексикографическая сортировка
Пусть S некоторое множество на котором задан
‹– линейный порядок.
Лексикографическим
Лексикографическая сортировка
Пусть S некоторое множество на котором задан
‹– линейный порядок.
Лексикографическим

Слайд 55Лексикографическая сортировка
Очевидно, что любое целое число можно считать k-членным кортежем цифр от
Лексикографическая сортировка
Очевидно, что любое целое число можно считать k-членным кортежем цифр от

Слайд 56Сортировка вычёрпыванием
Создадим исходную очередь A из n элементов, в которую занесем все
Сортировка вычёрпыванием
Создадим исходную очередь A из n элементов, в которую занесем все

Слайд 57Рекуррентное уравнение для алгоритма
Пусть m — количество организованных очередей, тогда трудоемкость сортировки
Рекуррентное уравнение для алгоритма
Пусть m — количество организованных очередей, тогда трудоемкость сортировки

Слайд 58Алгоритм
Алгоритм lexicographical_sort
k ← length(A[1]);
for c ← ‘a’ to ‘z’
{
Алгоритм
Алгоритм lexicographical_sort
k ← length(A[1]);
for c ← ‘a’ to ‘z’
{
![Алгоритм Алгоритм lexicographical_sort k ← length(A[1]); for c ← ‘a’ to ‘z’](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/993586/slide-57.jpg)
Слайд 59Алгоритм сортировки кортежей разной длины
Сначала сортируемые кортежи располагаются в порядке убывания
Алгоритм сортировки кортежей разной длины
Сначала сортируемые кортежи располагаются в порядке убывания

Слайд 60Алгоритм сортировки кортежей разной длины
Алгоритм сортировки кортежей разной длины

Слайд 61Оценка сложности
Оценка сложности

Слайд 62Пример
Дан массив:
Один, Два, Три, Четыре, Пять, Шесть, Семь, Восемь, Девять, Десять
Упорядочиваем по
Пример
Дан массив: Один, Два, Три, Четыре, Пять, Шесть, Семь, Восемь, Девять, Десять Упорядочиваем по

Слайд 631-я итерация
Вспомогательный массив B:
e: Четыре
Ь: Восемь, Девять, Десять
1-я итерация
Вспомогательный массив B:
e: Четыре
Ь: Восемь, Девять, Десять

Слайд 642-я итерация
Вспомогательный массив B:
м: Восемь
р: Четыре
т: Девять, Десять
ь: Шесть
2-я итерация
Вспомогательный массив B:
м: Восемь
р: Четыре
т: Девять, Десять
ь: Шесть

Слайд 653-я итерация
Вспомогательный массив B:
е: Восемь
н: Один
т: Шесть
ь: Пять, Семь
ы: Четыре
я: Девять,
3-я итерация
Вспомогательный массив B:
е: Восемь
н: Один
т: Шесть
ь: Пять, Семь
ы: Четыре
я: Девять,

Слайд 664-я итерация
Вспомогательный массив B:
а: Два
в: Девять
и: Один, Три
м: Семь
с: Восемь, Шесть,
4-я итерация
Вспомогательный массив B:
а: Два
в: Девять
и: Один, Три
м: Семь
с: Восемь, Шесть,

Слайд 675-я итерация
Вспомогательный массив B:
в: Два
д: Один
е: Девять, Семь, Шесть, Десять, Четыре
5-я итерация
Вспомогательный массив B:
в: Два
д: Один
е: Девять, Семь, Шесть, Десять, Четыре

Слайд 686-я итерация
Вспомогательный массив B:
в: Восемь
д: Два, Девять, Десять
о: Один
п: Пять
с: Семь
т: Три
ч:
6-я итерация
Вспомогательный массив B:
в: Восемь
д: Два, Девять, Десять
о: Один
п: Пять
с: Семь
т: Три
ч:

Слайд 69Пирамидальная сортировка
Сортировка пирамидой использует бинарное сортирующее дерево.
Сортирующее дерево — это такое дерево,
Пирамидальная сортировка
Сортировка пирамидой использует бинарное сортирующее дерево.
Сортирующее дерево — это такое дерево,

Слайд 70Пирамидальная сортировка
Этап 1. Выстраиваем элементы массива в виде сортирующего дерева
A[i] ≥ A[2i+1]
Пирамидальная сортировка
Этап 1. Выстраиваем элементы массива в виде сортирующего дерева
A[i] ≥ A[2i+1]
![Пирамидальная сортировка Этап 1. Выстраиваем элементы массива в виде сортирующего дерева A[i]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/993586/slide-69.jpg)
Слайд 71Пирамидальная сортировка
Этап 2. Будем удалять элементы из корня по одному за раз
Пирамидальная сортировка
Этап 2. Будем удалять элементы из корня по одному за раз

Слайд 72Достоинства сортировки
Имеет доказанную оценку худшего случая O(nlogn).
Сортирует на месте, то есть требует
Достоинства сортировки
Имеет доказанную оценку худшего случая O(nlogn).
Сортирует на месте, то есть требует

Слайд 73Недостатки сортировки
Неустойчив — для обеспечения устойчивости нужно расширять ключ.
На почти отсортированных массивах работает
Недостатки сортировки
Неустойчив — для обеспечения устойчивости нужно расширять ключ.
На почти отсортированных массивах работает

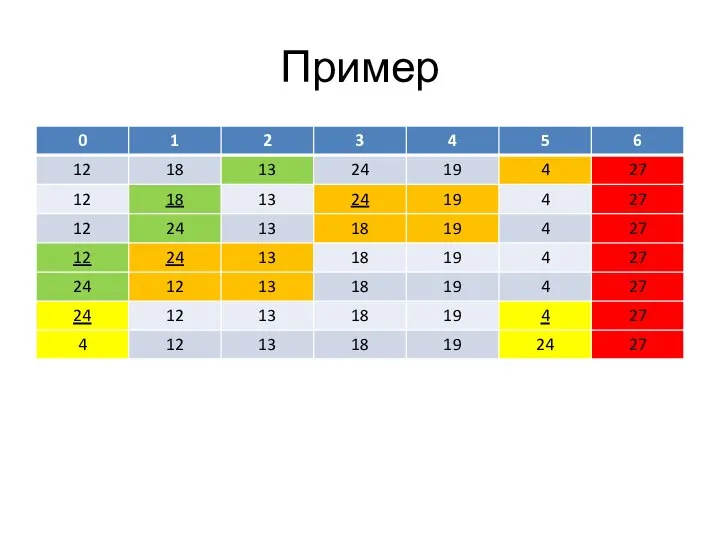
Слайд 74Пример
Пример
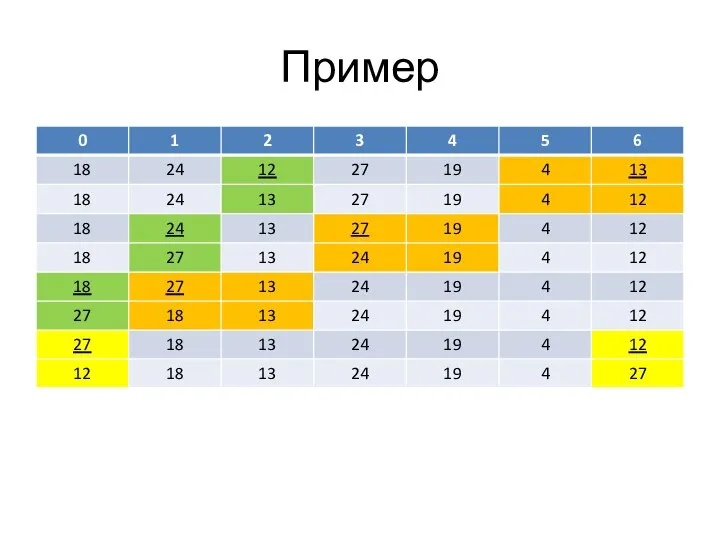
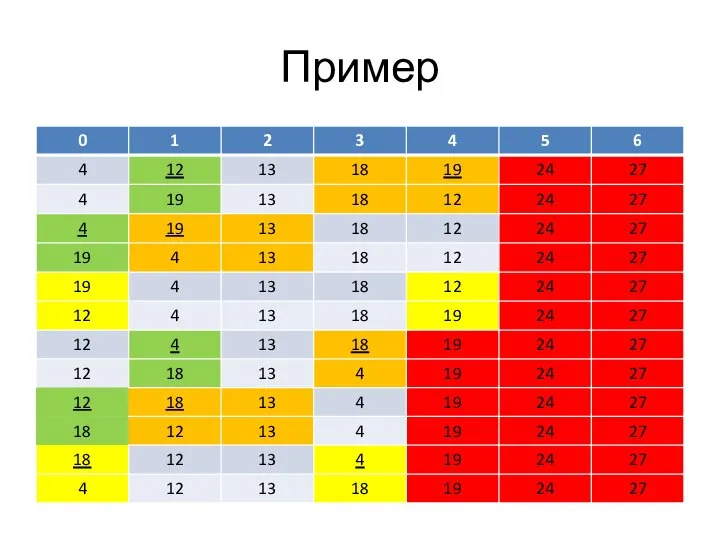
Слайд 75Пример
Пример
Слайд 76Пример
Пример
 Системы счисления (СС)
Системы счисления (СС) Правила игры с монстрами
Правила игры с монстрами Графическое изображение
Графическое изображение Конструкция switch
Конструкция switch Лекция о научных публикациях
Лекция о научных публикациях Компьютерное моделирование
Компьютерное моделирование Алгоритмы и исполнители
Алгоритмы и исполнители Устройства вывода информации
Устройства вывода информации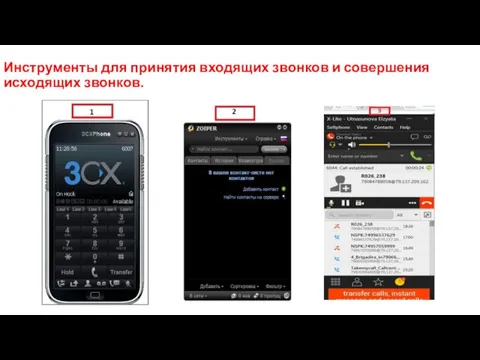 Инструменты для принятия входящих звонков и совершения исходящих звонков
Инструменты для принятия входящих звонков и совершения исходящих звонков Информатика. Внеклассное мероприятие
Информатика. Внеклассное мероприятие Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование 2_6_pamyat
2_6_pamyat Продвижение личного бренда
Продвижение личного бренда Графические редакторы
Графические редакторы Рефлексия. Лекция 4
Рефлексия. Лекция 4 Advent Empire. Карьерная лестница
Advent Empire. Карьерная лестница Беспилотные автомобили — транспорт будущего. 8 класс
Беспилотные автомобили — транспорт будущего. 8 класс Внутренняя и внешняя память компьютера
Внутренняя и внешняя память компьютера Комитет по связям с общественностью
Комитет по связям с общественностью Классы, дружественные функции
Классы, дружественные функции Разработка программного приложения на основе модели нечеткого регулятора спроса на товар производственного предприятия
Разработка программного приложения на основе модели нечеткого регулятора спроса на товар производственного предприятия Носители_и_современность
Носители_и_современность Архивация файлов
Архивация файлов Зачетная работа по информатике
Зачетная работа по информатике Файловая система
Файловая система Носители информации (7 класс)
Носители информации (7 класс) Международный день БЕЗ интернета
Международный день БЕЗ интернета Электронная цифровая подпись
Электронная цифровая подпись