- Обработка оптических изображений. Несколько слов о статистике

Содержание
- 2. Несколько слов о статистике Кратко о том как охарактеризовать и сравнить Ваши данные Почти инструкция В
- 3. Статистический анализ данных Включает несколько этапов. Один из наиболее важных для вас разделов это Описательная (дескриптивная)
- 4. Типы данных Имеют некоторое числовое значение количественные дискретные Принимают строго определенные, как правило, целочисленные значения непрерывные
- 5. Описательная (дескриптивная) статистика Важно учитывать тип данных и параметры распределения, характеризующиеся показателями асимметрии и гистограммой распределения
- 6. Нормальное распределение практически все значения нормально распределённой случайной величины лежат в интервале 3σ (0,9973). Если же
- 7. Среднее (выборочное) Стандартное отклонение Стандартная ошибка среднего ! В случае больших выборок (больше 200) даже очень
- 8. Параметрические методы анализируют нормально распределенные количественные признаки Непараметрические методы используются во всех остальных случаях (для анализа
- 9. - показатели разброса, описывающие степень разброса данных Описательная (дескриптивная) статистика Показатели описательной статистики показатели положения экспериментальных
- 10. Описательная (дескриптивная) статистика Показатели положения экспериментальных данных на числовой оси наиболее часто встречаемое значение в выборке.
- 11. Описательная (дескриптивная) статистика показатели разброса, описывающие степень разброса данных Стандартное отклонение Квантили характеризует собой частоту попадания
- 12. Описательная (дескриптивная) статистика Графическое представление результатов Гистограмма Количественные данные Количественные данные Качественные данные Диаграммы Ящик с
- 13. Индуктивная статистика Основная область применения – использование для сравнения двух (или более) выборок для определения их
- 14. Индуктивная статистика Типы ошибок Ошибка – обязательный компонент статистического анализа Допустимый уровень ошибок выбирается исследователем. Обычно
- 15. Индуктивная статистика (сравнение групп) смещение признака двусторонние тесты односторонние тесты Априорно предполагается, что в одной из
- 16. К а т ег ориа ль ные да нные Од на гру ппа Критерий Манна-Уитни Более
- 17. Статистическая обработка Как правильно обработать статистические данные? однозначного ответа нет, зависит от формы проведения эксперимента, количества
- 18. Статистическая обработка Статистическая обработка измеренного параметра Находим среднее, стандартное отклонение и стандартную ошибку среднего Строим гистограмму
- 19. Где и что про это можно прочитать Ищем методички для медиков, там мало объясняют, зато пишут
- 20. доверительный интервал Статистическая обработка Референсные значения Доверительный интервал Если распределение данных соответствует нормальному распределению, то это
- 21. Статистическая обработка Эффект множественных сравнений Вероятность ошибиться в одном из трех случаев Опасность попарного сравнения P=1-(1-α)k
- 22. Статистическая обработка оценка качественных переменных Оценивают не количество, а доли! Своя специфика в математике Стандартное отклонение
- 23. Программы для обработки изображений FIJI (ImageJ) Gwiddion Femtoskan SPIP Продукция компании Мекос Семейство программ Image Pro
- 24. Данная процедура позволяет устранить дефекты, обусловленные следующими причинами Постоянная составляющая Постоянный наклон Искажения, связанные с неравномерностью
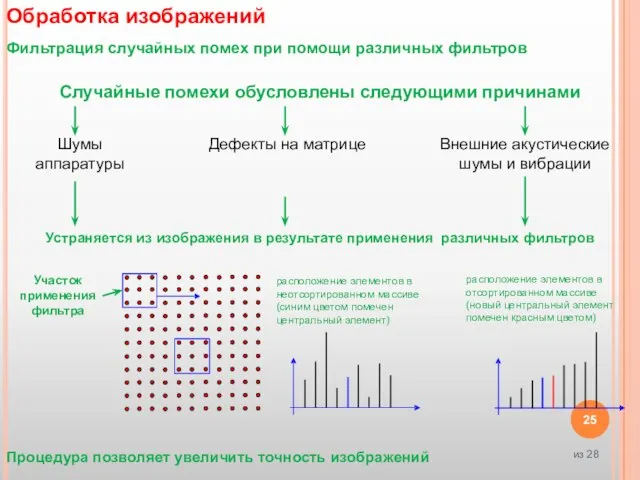
- 25. Обработка изображений Фильтрация случайных помех при помощи различных фильтров Случайные помехи обусловлены следующими причинами Процедура позволяет
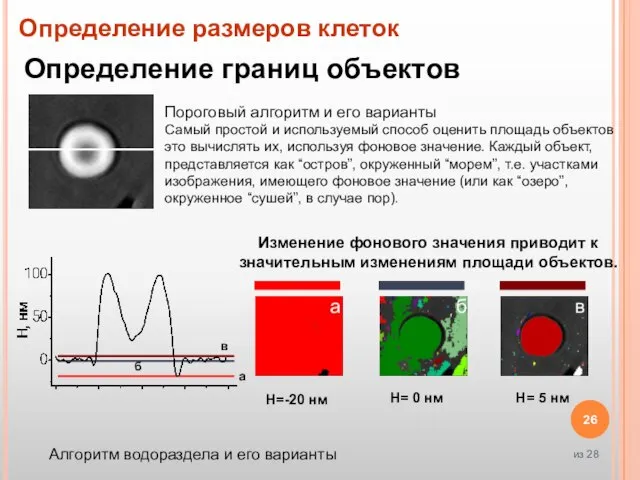
- 26. Определение размеров клеток Определение границ объектов Изменение фонового значения приводит к значительным изменениям площади объектов. Алгоритм
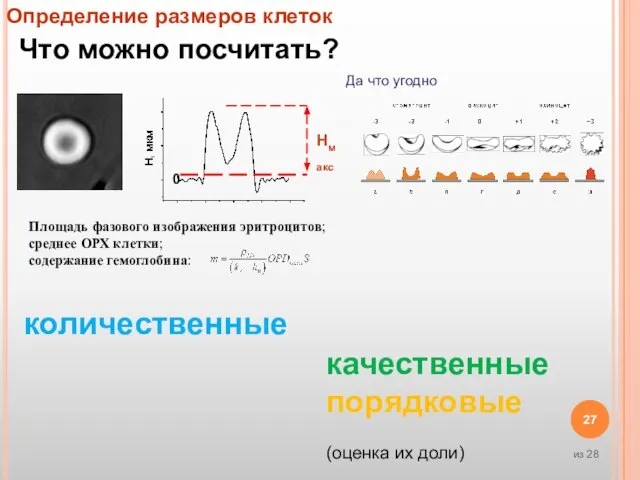
- 27. Определение размеров клеток Да что угодно Что можно посчитать? Площадь фазового изображения эритроцитов; среднее ОРХ клетки;
- 29. Скачать презентацию

Слайд 3Статистический анализ данных
Включает несколько этапов. Один из наиболее важных для вас разделов
Статистический анализ данных
Включает несколько этапов. Один из наиболее важных для вас разделов

Слайд 4Типы данных
Имеют некоторое числовое значение
количественные
дискретные
Принимают строго определенные, как правило, целочисленные значения
непрерывные
Данные могут
Типы данных
Имеют некоторое числовое значение
количественные
дискретные
Принимают строго определенные, как правило, целочисленные значения
непрерывные
Данные могут

Слайд 5Описательная (дескриптивная) статистика
Важно учитывать тип данных и параметры распределения, характеризующиеся показателями асимметрии
Описательная (дескриптивная) статистика
Важно учитывать тип данных и параметры распределения, характеризующиеся показателями асимметрии

Слайд 6Нормальное распределение
практически все значения нормально распределённой случайной величины лежат в интервале 3σ
Нормальное распределение
практически все значения нормально распределённой случайной величины лежат в интервале 3σ
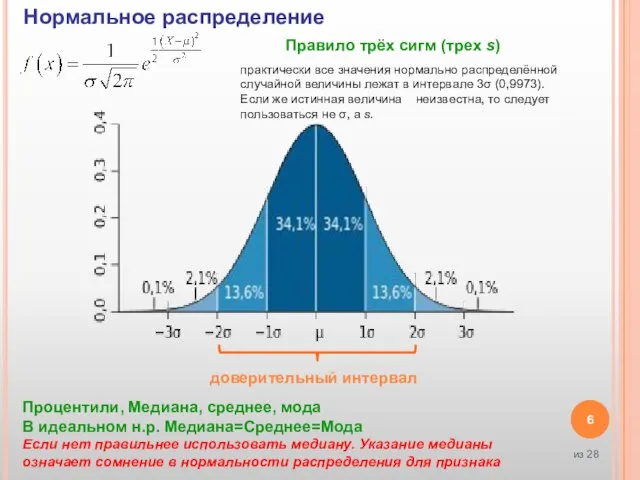
Слайд 7Среднее
(выборочное) Стандартное отклонение
Стандартная ошибка среднего
!
В случае больших выборок (больше 200) даже очень
Среднее
(выборочное) Стандартное отклонение
Стандартная ошибка среднего
!
В случае больших выборок (больше 200) даже очень
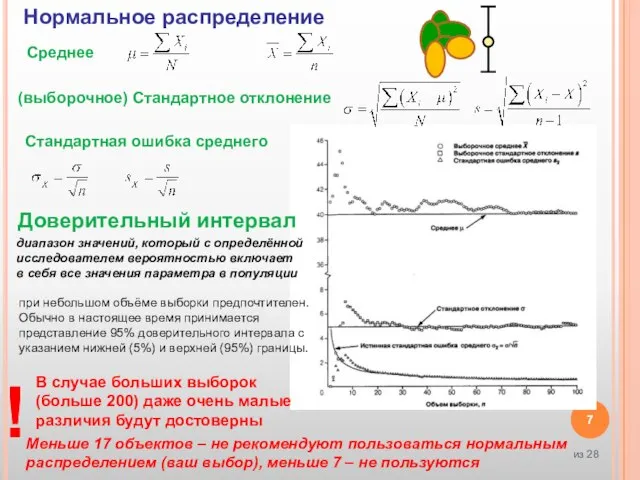
Слайд 8Параметрические методы анализируют нормально распределенные количественные признаки
Непараметрические методы используются во всех остальных
Параметрические методы анализируют нормально распределенные количественные признаки
Непараметрические методы используются во всех остальных

Слайд 9- показатели разброса, описывающие степень разброса данных
Описательная (дескриптивная) статистика
Показатели описательной статистики
показатели положения
- показатели разброса, описывающие степень разброса данных
Описательная (дескриптивная) статистика
Показатели описательной статистики
показатели положения

Слайд 10Описательная (дескриптивная) статистика
Показатели положения экспериментальных данных на числовой оси
наиболее часто встречаемое значение
Описательная (дескриптивная) статистика
Показатели положения экспериментальных данных на числовой оси
наиболее часто встречаемое значение

Слайд 11Описательная (дескриптивная) статистика
показатели разброса, описывающие степень разброса данных
Стандартное отклонение
Квантили характеризует собой частоту
Описательная (дескриптивная) статистика
показатели разброса, описывающие степень разброса данных
Стандартное отклонение
Квантили характеризует собой частоту

Слайд 12Описательная (дескриптивная) статистика
Графическое представление результатов
Гистограмма
Количественные данные
Количественные данные
Качественные данные
Диаграммы
Ящик с усами
ус
ящик
Нижняя квартиль
Верхняя квартиль
медиана
среднее
из
Описательная (дескриптивная) статистика
Графическое представление результатов
Гистограмма
Количественные данные
Количественные данные
Качественные данные
Диаграммы
Ящик с усами
ус
ящик
Нижняя квартиль
Верхняя квартиль
медиана
среднее
из
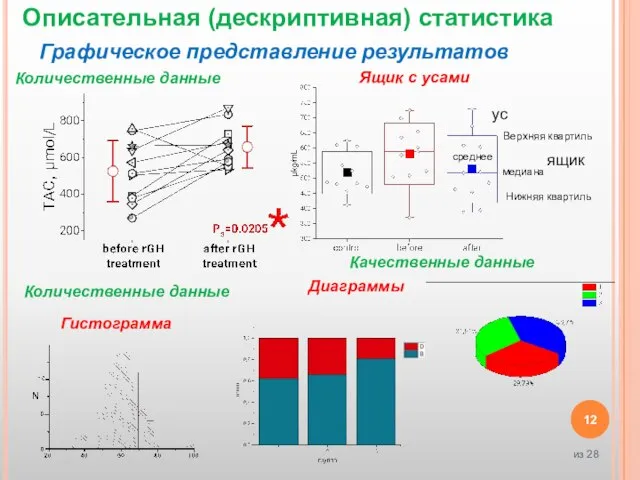
Слайд 13Индуктивная статистика
Основная область применения – использование для сравнения двух (или более) выборок
Индуктивная статистика
Основная область применения – использование для сравнения двух (или более) выборок

Слайд 14Индуктивная статистика
Типы ошибок
Ошибка – обязательный компонент статистического анализа
Допустимый уровень ошибок выбирается исследователем.
Индуктивная статистика
Типы ошибок
Ошибка – обязательный компонент статистического анализа
Допустимый уровень ошибок выбирается исследователем.

Слайд 15Индуктивная статистика (сравнение групп)
смещение признака
двусторонние тесты
односторонние тесты
Априорно предполагается, что в одной из
Индуктивная статистика (сравнение групп)
смещение признака
двусторонние тесты
односторонние тесты
Априорно предполагается, что в одной из
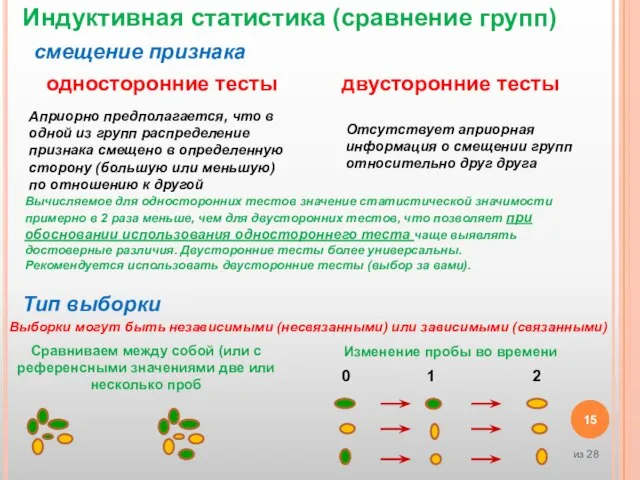
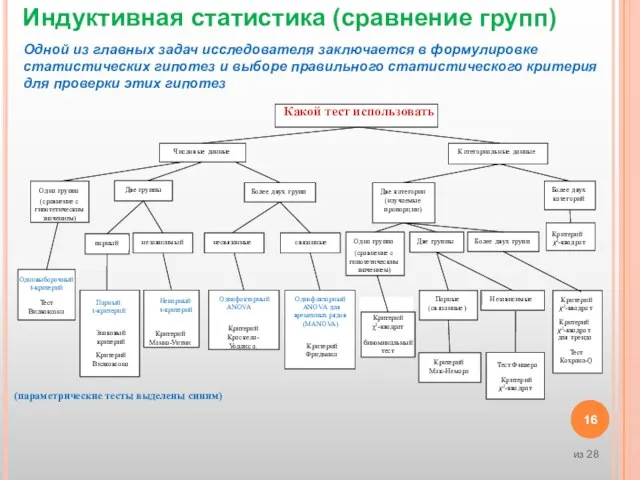
Слайд 16К
а
т
ег
ориа
ль
ные
да
нные
Од
на
гру
ппа
Критерий Манна-Уитни
Более
д
в
ух
г
р
у
пп
Д
ве
гру
п
пы
парный
не
за
в
исим
ый
Чис
лов
ые
д
анные
Какой тест использовать
(параметрические тесты выделены
К
а
т
ег
ориа
ль
ные
да
нные
Од
на
гру
ппа
Критерий Манна-Уитни
Более
д
в
ух
г
р
у
пп
Д
ве
гру
п
пы
парный
не
за
в
исим
ый
Чис
лов
ые
д
анные
Какой тест использовать
(параметрические тесты выделены
Слайд 17Статистическая обработка
Как правильно обработать статистические данные?
однозначного ответа нет, зависит от формы
Статистическая обработка
Как правильно обработать статистические данные?
однозначного ответа нет, зависит от формы

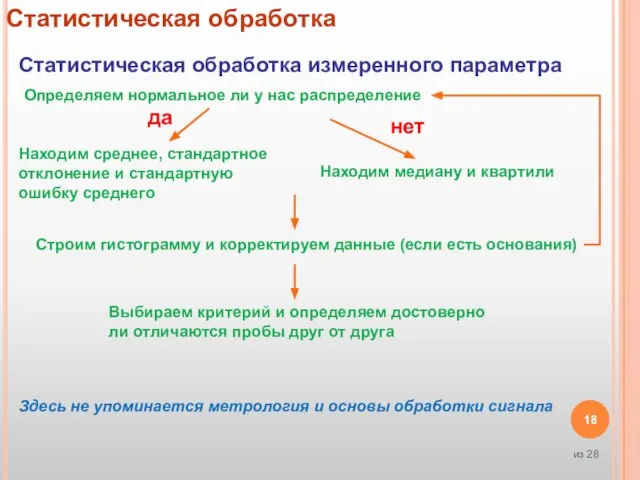
Слайд 18Статистическая обработка
Статистическая обработка измеренного параметра
Находим среднее, стандартное отклонение и стандартную ошибку
Статистическая обработка
Статистическая обработка измеренного параметра
Находим среднее, стандартное отклонение и стандартную ошибку
Слайд 19Где и что про это можно прочитать
Ищем методички для медиков, там мало
Где и что про это можно прочитать
Ищем методички для медиков, там мало

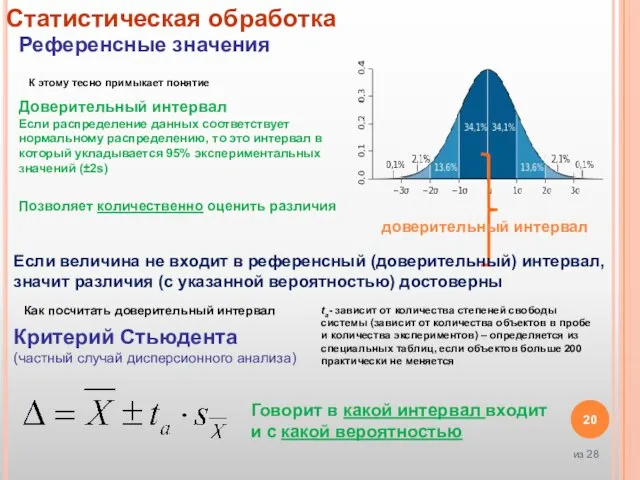
Слайд 20доверительный интервал
Статистическая обработка
Референсные значения
Доверительный интервал
Если распределение данных соответствует нормальному распределению,
доверительный интервал
Статистическая обработка
Референсные значения
Доверительный интервал
Если распределение данных соответствует нормальному распределению,
Слайд 21Статистическая обработка
Эффект множественных сравнений
Вероятность ошибиться в одном из трех случаев
Опасность попарного
Статистическая обработка
Эффект множественных сравнений
Вероятность ошибиться в одном из трех случаев
Опасность попарного

Слайд 22Статистическая обработка
оценка качественных переменных
Оценивают не количество, а доли!
Своя специфика в математике
Статистическая обработка
оценка качественных переменных
Оценивают не количество, а доли!
Своя специфика в математике

Слайд 23Программы для обработки изображений
FIJI (ImageJ)
Gwiddion
Femtoskan
SPIP
Продукция компании Мекос
Семейство программ Image Pro Plus
Metamorph
И др.
из
Программы для обработки изображений
FIJI (ImageJ)
Gwiddion
Femtoskan
SPIP
Продукция компании Мекос
Семейство программ Image Pro Plus
Metamorph
И др.
из

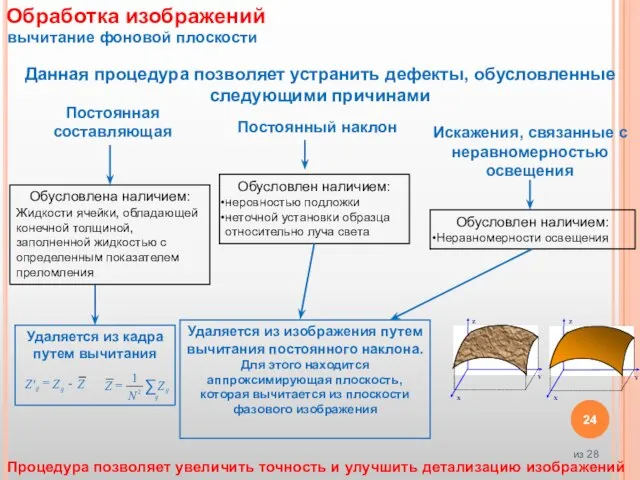
Слайд 24Данная процедура позволяет устранить дефекты, обусловленные следующими причинами
Постоянная составляющая
Постоянный наклон
Искажения, связанные с
Данная процедура позволяет устранить дефекты, обусловленные следующими причинами
Постоянная составляющая
Постоянный наклон
Искажения, связанные с
Слайд 25Обработка изображений
Фильтрация случайных помех при помощи различных фильтров
Случайные помехи обусловлены следующими
Обработка изображений
Фильтрация случайных помех при помощи различных фильтров
Случайные помехи обусловлены следующими
Слайд 26Определение размеров клеток
Определение границ объектов
Изменение фонового значения приводит к значительным изменениям площади
Определение размеров клеток
Определение границ объектов
Изменение фонового значения приводит к значительным изменениям площади
Слайд 27Определение размеров клеток
Да что угодно
Что можно посчитать?
Площадь фазового изображения эритроцитов;
среднее ОРХ клетки;
содержание
Определение размеров клеток
Да что угодно
Что можно посчитать?
Площадь фазового изображения эритроцитов;
среднее ОРХ клетки;
содержание
 Экстремумы функции (пример)
Экстремумы функции (пример) Табличний симплекс-метод
Табличний симплекс-метод Неравенства. 8 класс
Неравенства. 8 класс Ну, погоди!
Ну, погоди! Решение показательных неравенств
Решение показательных неравенств Подготовка к ГИА. Задачи
Подготовка к ГИА. Задачи Математические игры
Математические игры Призма. Пирамида
Призма. Пирамида Подготовка к контрольной работе
Подготовка к контрольной работе Логарифм и его свойства
Логарифм и его свойства Угол – это фигура, образованная двумя лучами с общим началом
Угол – это фигура, образованная двумя лучами с общим началом Подготовка к контрольной работе. Уравнения
Подготовка к контрольной работе. Уравнения Задача о нахождении стороны квадрата
Задача о нахождении стороны квадрата Золотое сечение
Золотое сечение Решение задач на применение аксиом стереометрии и их следствий
Решение задач на применение аксиом стереометрии и их следствий Применение признаков подобия треугольников к решению задач и доказательству теорем
Применение признаков подобия треугольников к решению задач и доказательству теорем Соотношения между углами и сторонами прямоугольного треугольника
Соотношения между углами и сторонами прямоугольного треугольника Параллельность плоскостей определение
Параллельность плоскостей определение Презентация по математике "Основы концепции “глубинного анализа текстов" -
Презентация по математике "Основы концепции “глубинного анализа текстов" -  Функции, их свойства и графики
Функции, их свойства и графики Симметрия в окружающем мире
Симметрия в окружающем мире Равенство геометрических фигур
Равенство геометрических фигур Параллельность прямых и плоскостей в пространстве
Параллельность прямых и плоскостей в пространстве Аттестационная работа. Взаимодействие учебной и исследовательской деятельности на уроках математики
Аттестационная работа. Взаимодействие учебной и исследовательской деятельности на уроках математики Выборочное наблюдение
Выборочное наблюдение Определители второго и третьего порядков
Определители второго и третьего порядков Числовые ряды
Числовые ряды Обобщающий урок по начертательной геометрии прямая. Плоскость
Обобщающий урок по начертательной геометрии прямая. Плоскость