- Тема 1.6_ДОП_Регрессия

Содержание
- 2. Группы методов
- 3. Диаграмма рассеяния
- 4. Свойства коэффициента корреляции
- 6. Построение уравнения регрессии
- 7. Чаще всего используются следующие зависимости : линейная ; параболическая ; экспоненциальная . Оценка параметров осуществляется методом
- 8. Графическая интерпретация i = 1, 2, … , n
- 9. Количественная шкала
- 10. Вычисление коэффициентов
- 12. Алгоритм кластерного анализа: K-means Одной из широко используемых методик кластеризации является разделительная кластеризация, в соответствии с
- 14. Скачать презентацию
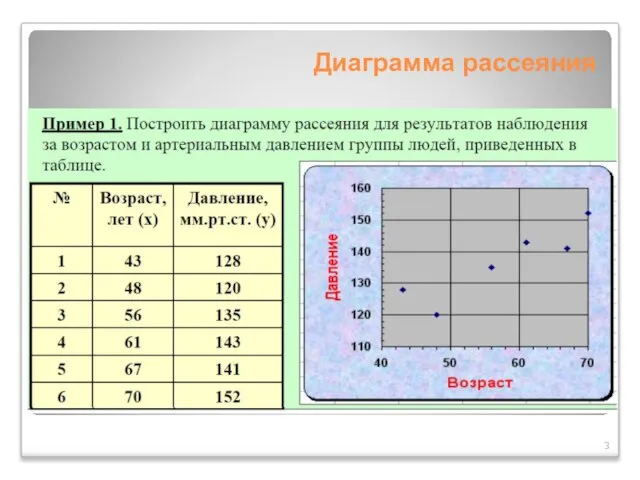
Слайд 3Диаграмма рассеяния
Диаграмма рассеяния
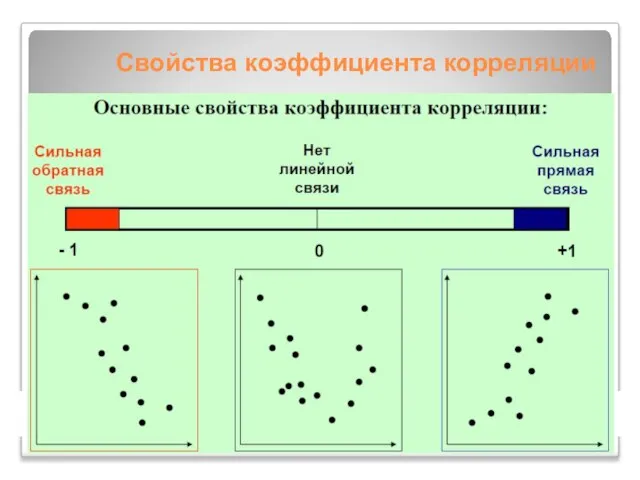
Слайд 4Свойства коэффициента корреляции
Свойства коэффициента корреляции

Слайд 6Построение уравнения регрессии
Построение уравнения регрессии

Слайд 7
Чаще всего используются следующие зависимости :
линейная ;
параболическая ;
экспоненциальная .
Оценка параметров осуществляется
Чаще всего используются следующие зависимости :
линейная ;
параболическая ;
экспоненциальная .
Оценка параметров осуществляется

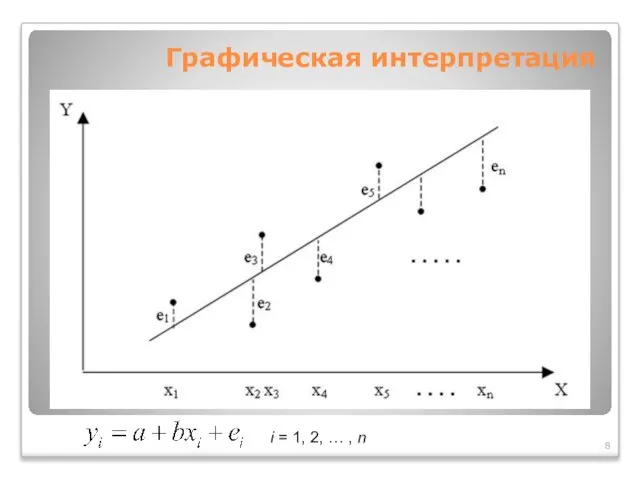
Слайд 8Графическая интерпретация
i = 1, 2, … , n
Графическая интерпретация
i = 1, 2, … , n
Слайд 9Количественная шкала
Количественная шкала

Слайд 10Вычисление коэффициентов
Вычисление коэффициентов


Слайд 12Алгоритм кластерного анализа: K-means
Одной из широко используемых методик кластеризации является разделительная
Алгоритм кластерного анализа: K-means
Одной из широко используемых методик кластеризации является разделительная

 Логарифмы. Что такое логарифм
Логарифмы. Что такое логарифм Учимся писать цифры
Учимся писать цифры Замечательные отрезки многоугольников
Замечательные отрезки многоугольников Тайны треугольника. 7 класс
Тайны треугольника. 7 класс Презентация на тему Магия чисел 9 класс
Презентация на тему Магия чисел 9 класс  Теорема Пифагора
Теорема Пифагора Решение системы уравнений методом обратной матрицы
Решение системы уравнений методом обратной матрицы Математическое моделирование, внедрение методов численного анализа в системах. Расчетный эксперимент
Математическое моделирование, внедрение методов численного анализа в системах. Расчетный эксперимент Упрощение логических выражений
Упрощение логических выражений Треугольники
Треугольники Решение задач. Параллельные прямые
Решение задач. Параллельные прямые Квадратное уравнение и его корни. Решение полных квадратных уравнений
Квадратное уравнение и его корни. Решение полных квадратных уравнений Многогранники
Многогранники Процент. Понятие процента
Процент. Понятие процента Деление с остатком. 4 класс
Деление с остатком. 4 класс Индивидуальный итоговый проект по математике 22 задание ОГЭ
Индивидуальный итоговый проект по математике 22 задание ОГЭ Решение задач на определение часовых поясов и часовых зон России
Решение задач на определение часовых поясов и часовых зон России Комбинаторика и теория вероятности
Комбинаторика и теория вероятности Письменное умножение на трёхзначное число
Письменное умножение на трёхзначное число Алгебраические структуры. Аналитические преобразования с помощью компьютера
Алгебраические структуры. Аналитические преобразования с помощью компьютера Класс точности средств измерений
Класс точности средств измерений Задачи на проценты. Путешествие по лабиринту, урок-игра в 5-м классе
Задачи на проценты. Путешествие по лабиринту, урок-игра в 5-м классе Организация исследовательской деятельности учащихся на уроках математики
Организация исследовательской деятельности учащихся на уроках математики Практическая работа
Практическая работа Область определения функции
Область определения функции Статистическое наблюдение
Статистическое наблюдение Приемы устных вычислений двузначных чисел
Приемы устных вычислений двузначных чисел Экономические задачи
Экономические задачи