- Классификция. Задача классификации

Содержание
- 2. Проблема несбалансированности Данные несбалансированы когда представители классов представлены не в приблизительном равном количестве (далее все рассматриваем
- 3. В чем проблема? Многие стандартные классификаторы пытаются увеличить точность и не изменить распределение обучающей выборки, поэтому
- 4. Цель классификации - детектирование Стоимость ошибки неправильно классифицировать ненормальный образец данных как нормальный много выше чем
- 5. Примеры несбалансированных данных: 1) из 100 000 тысяч подавших заявку, только 2% проходят в гарвард на
- 6. Техники работы с несбалансированными данными I. Работа с данными : SMOTE Random Undersampling Random Oversampling II.Чувствительность
- 7. Метрики качества Пусть есть два класса — отрицательный и положительный (меньший)
- 8. 1) Accuracy – для сбалансированных данных Процент правильно классифицированных образцов от всего числа образцов
- 9. 2) ROC кривая – для несбалансированных представляет границы лучших решений для относительных TP (по оси У)
- 11. AUC - площадь под ROC кривой . Она эквивалентна вероятности того что классификатор ценит произвольно выбранный
- 12. Для одной точки
- 13. Преимущества ROC Когда алгоритм изучает больше образцов одного (-) класса он будет ошибочно классифицировать больше образцов
- 14. Алгоритм SMOTE Считываем число образцов меньшего класса Т Процент генерируемых образцов N Число ближайших соседей k
- 15. SMOTE
- 17. Преимущества SMOTE Этот способ увеличения меньшего класса не приводит к переобучению (в отличие от random oversampling),
- 18. Модификации SMOTE для дискретных атрибутов образцов При вычислении атрибутов генерируемого образца для номинальных атрибутов значением будут
- 20. Скачать презентацию
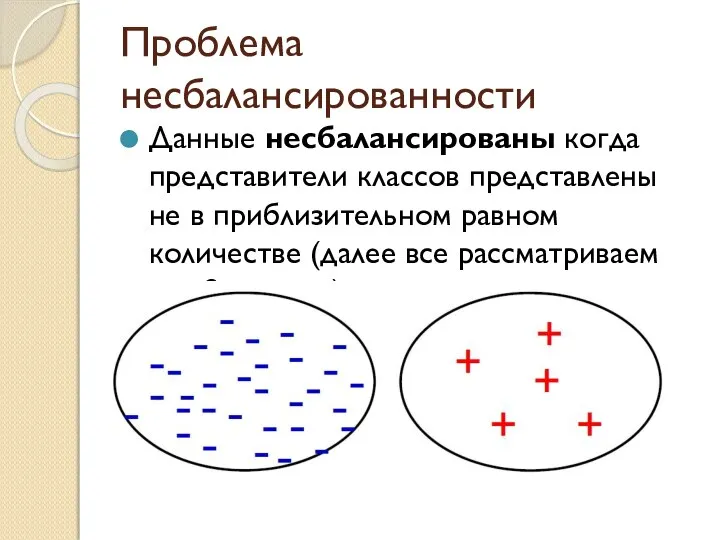
Слайд 2Проблема несбалансированности
Данные несбалансированы когда представители классов представлены не в приблизительном равном количестве
Проблема несбалансированности
Данные несбалансированы когда представители классов представлены не в приблизительном равном количестве
Слайд 3В чем проблема?
Многие стандартные классификаторы пытаются увеличить точность и не изменить распределение
В чем проблема?
Многие стандартные классификаторы пытаются увеличить точность и не изменить распределение

Слайд 4Цель классификации - детектирование
Стоимость ошибки неправильно классифицировать ненормальный образец данных как нормальный
Цель классификации - детектирование
Стоимость ошибки неправильно классифицировать ненормальный образец данных как нормальный

Слайд 5Примеры несбалансированных данных:
1) из 100 000 тысяч подавших заявку, только 2% проходят
Примеры несбалансированных данных:
1) из 100 000 тысяч подавших заявку, только 2% проходят

Слайд 6Техники работы с несбалансированными данными
I. Работа с данными :
SMOTE
Random Undersampling
Random Oversampling
II.Чувствительность
Техники работы с несбалансированными данными
I. Работа с данными :
SMOTE
Random Undersampling
Random Oversampling
II.Чувствительность

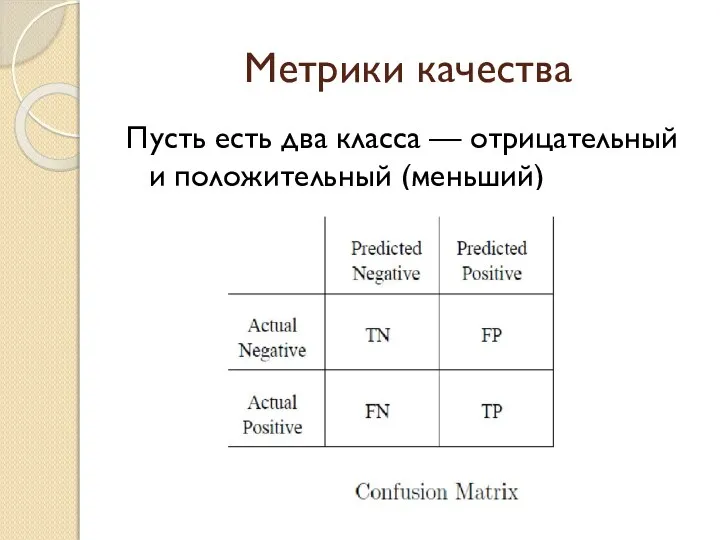
Слайд 7Метрики качества
Пусть есть два класса — отрицательный и положительный (меньший)
Метрики качества
Пусть есть два класса — отрицательный и положительный (меньший)
Слайд 81) Accuracy – для сбалансированных данных
Процент правильно классифицированных образцов от всего числа
1) Accuracy – для сбалансированных данных
Процент правильно классифицированных образцов от всего числа

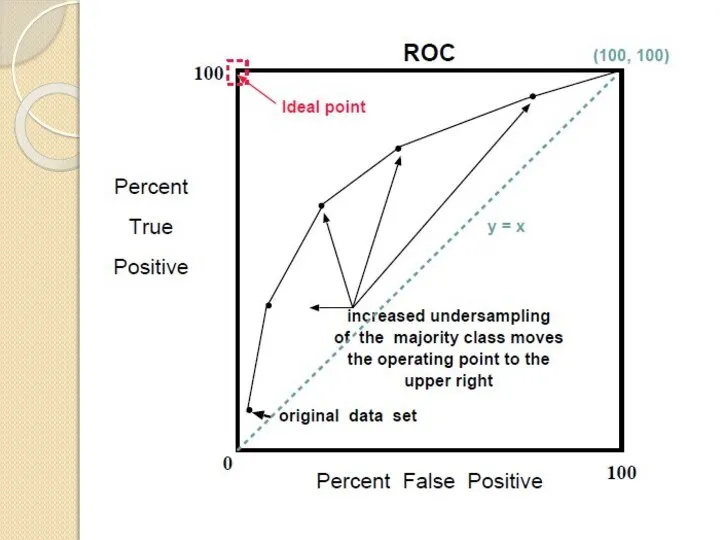
Слайд 92) ROC кривая – для несбалансированных
представляет границы лучших решений для относительных TP
2) ROC кривая – для несбалансированных
представляет границы лучших решений для относительных TP

Слайд 11AUC - площадь под ROC кривой .
Она эквивалентна вероятности того
AUC - площадь под ROC кривой .
Она эквивалентна вероятности того

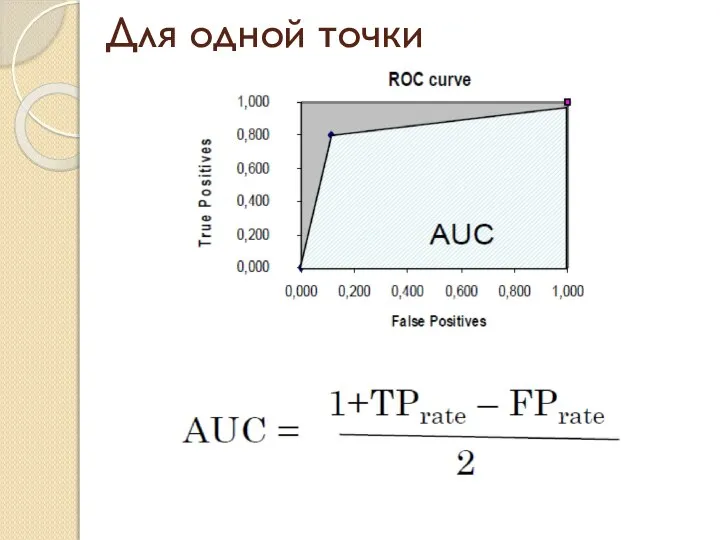
Слайд 12Для одной точки
Для одной точки
Слайд 13Преимущества ROC
Когда алгоритм изучает больше образцов одного (-) класса он будет ошибочно
Преимущества ROC
Когда алгоритм изучает больше образцов одного (-) класса он будет ошибочно

Слайд 14Алгоритм SMOTE
Считываем число образцов меньшего класса Т
Процент генерируемых образцов N
Число ближайших
Алгоритм SMOTE
Считываем число образцов меньшего класса Т
Процент генерируемых образцов N
Число ближайших

Слайд 15SMOTE
SMOTE


Слайд 17Преимущества SMOTE
Этот способ увеличения меньшего класса не приводит к переобучению (в отличие
Преимущества SMOTE
Этот способ увеличения меньшего класса не приводит к переобучению (в отличие

Слайд 18Модификации SMOTE для дискретных атрибутов образцов
При вычислении атрибутов генерируемого образца для номинальных
Модификации SMOTE для дискретных атрибутов образцов
При вычислении атрибутов генерируемого образца для номинальных

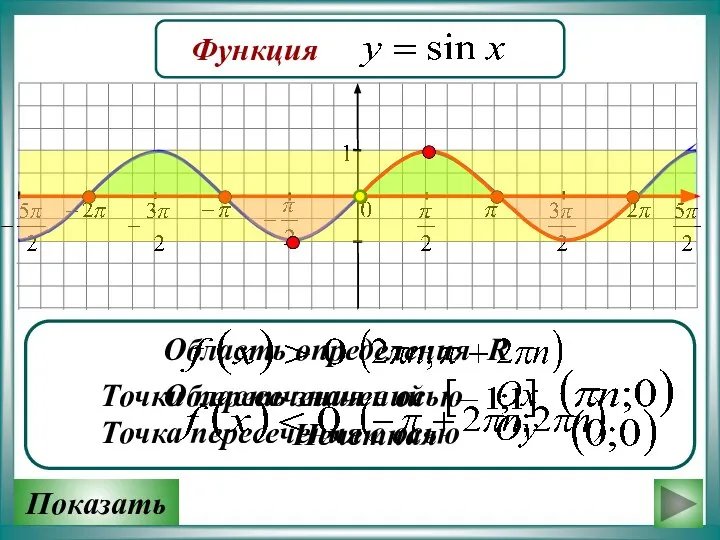 График функции y = sin x
График функции y = sin x Матрицы и определители
Матрицы и определители Деление на 3
Деление на 3 Треугольники
Треугольники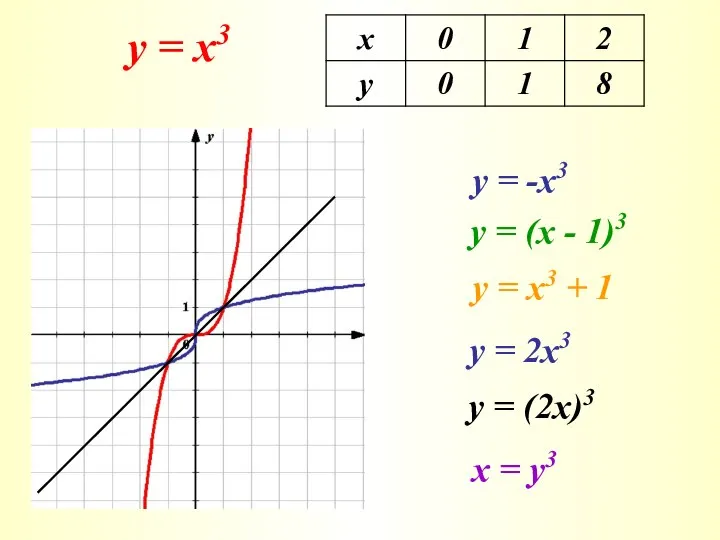 Логарифмические функции
Логарифмические функции Презентация на тему НЕРАВЕНСТВО ТРЕУГОЛЬНИКА
Презентация на тему НЕРАВЕНСТВО ТРЕУГОЛЬНИКА  Задачи для подготовки к контрольной работе
Задачи для подготовки к контрольной работе Тригонометрия
Тригонометрия Решение задач на работу
Решение задач на работу Алгоритм деления
Алгоритм деления Неравенство треугольника (7 класс)
Неравенство треугольника (7 класс) Умножение натуральных чисел. Графический диктант. 5 класс
Умножение натуральных чисел. Графический диктант. 5 класс Розв’язування задач
Розв’язування задач Операции над матрицами
Операции над матрицами Презентация на тему Вводное повторени для 8 классов по геометрии
Презентация на тему Вводное повторени для 8 классов по геометрии  Система нелинейных уравнений. Организация и проведение итогового повторения
Система нелинейных уравнений. Организация и проведение итогового повторения Приемы устных вычислений двузначных чисел
Приемы устных вычислений двузначных чисел Решение тригонометрических уравнений
Решение тригонометрических уравнений Классическая формула подсчета результатов
Классическая формула подсчета результатов Симметрия и асимметрия
Симметрия и асимметрия Сложение дробей
Сложение дробей Методика изучения одномерных геометрических фигур: ломаная, многоугольники и их виды: прямоугольник, квадрат и их свойства
Методика изучения одномерных геометрических фигур: ломаная, многоугольники и их виды: прямоугольник, квадрат и их свойства Функции, их свойства и графики
Функции, их свойства и графики Цилиндр. Конус
Цилиндр. Конус Понятие площади. Площадь квадрата и прямоугольника
Понятие площади. Площадь квадрата и прямоугольника Решение систем неравенств первой степени с одним неизвестным
Решение систем неравенств первой степени с одним неизвестным Презентация на тему Действия с рациональными числами
Презентация на тему Действия с рациональными числами  Уравнение. Корень уравнения
Уравнение. Корень уравнения