- Линейная регрессия

Содержание
- 2. Почему линейные модели до сих пор используются? Очень простые, поэтому можно использовать там, где нужна интерпретируемость
- 3. Постановка задачи Датасет: Функция потерь:
- 4. Определение модели Мы будем искать модель в следующем виде Намного удобнее для записи внести 1 в
- 5. Линейность по параметрам Какое может быть происхождение у признаков ? Просто численный признак Преобразования численных признаков
- 6. Пример
- 7. Точное решение Запишем то, что мы хотим получить:
- 8. Точное решение Случай , тогда матрица - квадратная и может иметь обратную. = Система линейных уравнений:
- 9. Pseudo-Inverse Обычно , тогда у нас переопределенная система линейных уравнений. = Система линейных уравнений: Приближенное решение:
- 10. Получение решения через производную Подставим выражение для в функцию потерь и запишем в векторном виде: Возьмем
- 11. Обучение классификаторов
- 12. Получение решения через производную Возьмем производную Если у линейно независимые столбцы, то можно приравнять производную к
- 13. Постановка задачи Датасет: Функция потерь: , . То есть это вектор из 0 и 1 Будет
- 14. Мы хотим выбрать функцию потерь, но какая лучше всего подойдет не знаем. Попробуем искать лучшую модель
- 15. Вероятностная модель Х- случайная величина вектор признаков. Y- случайная величина целевая переменная. Пример случайной модели (клики
- 16. Функция правдоподобия Найдем способ для обучения любой модели, предсказывающей вероятность принадлежности к классу. - вектор признаков,
- 17. Обучение модели через максимальное правдоподобие Теорема из статистики гарантирует, что если мы найдем параметры модели, которые
- 18. Связь с минимизацией функции потерь Преобразуем задачу максимизации в задачу минимизации. Мы видим что минимизация полученного
- 19. Что мы сделали Мы знаем, что максимизация правдоподобия дает хорошие веса из статистики. Изменив формулу, мы
- 20. Логистическая регрессия
- 21. Определение модели Мы будем искать модель в следующем виде. Определение сигмоиды:
- 22. Предсказание вероятности Будем считать, что наша модель предсказывает вероятности. Именно поэтому она называется регрессией. Вероятносвть для
- 23. Пример работы Как выглядит обученная логистическая регрессия на данных с одним признаком.
- 24. Обучение логистической регрессии В полученную ранее формулу функции потерь можно подставить вероятность, которую предсказывает логистическая регрессия.
- 25. Обобщение на много классов Пусть у нас есть m классов. Введем две новые функции:
- 26. Пример работы Softmax
- 27. Много классов Выпишем предсказанную вероятность для к-го класса. Ее можно подставить в функцию потерь для произвольного
- 28. Градиентный спуск
- 29. Обучение логистической регрессии В полученную ранее формулу функции потерь можно подставить вероятность, которую предсказывает логистическая регрессия.
- 30. Эвристика градиентного спуска
- 31. Градиентный спуск формализация У нас стоит задача минимизации какой-то функции: Чтобы применять метод градиентного спуска нужно
- 32. Шаг градиентного спуска На каждом шаге будем менять все переменные, от которых зависит функция: ... Или
- 33. Градиентный спуск Выбираем точку, с которой начнем оптимизацию. На каждом шаге будем менять все переменные, от
- 34. Градиентный спуск для параболы Будем минимизировать , / / Теперь делаем обновления: С каждым шагом мы
- 35. Градиентный спуск для линейной регрессии Функция потерь (она зависит только от весов, потому что изменять мы
- 36. Градиентный спуск для линейной регрессии Пошагово возьмем производную лосса по параметрам:
- 37. Градиентный спуск для линейной регрессии Функция потерь (она зависит только от весов, потому что изменять мы
- 38. Градиентный спуск для линейной регрессии Будем минимизировать Как-то выберем начальные веса. Теперь делаем обновления:
- 39. Градиентный спуск для логистической регрессии Функция потерь:
- 40. Градиентный спуск для логистической регрессии Возьмем производную: Соединим:
- 41. Регуляризация
- 42. Мультиколлинеарность для линейной регрессии Вспомним определение линейной регрессии: Если столбцы матрицы линейно зависимы, то существуют такие
- 43. Weight Decay Мы можем предположить, что веса не должны быть большими по модулю. Изменим функцию потерь,
- 44. Как изменится градиент -регуляризация -регуляризация
- 45. Нормализация признаков
- 46. Что такое нормализация? Мы изменяем признаки в датасете по правилу: - среднее значение j-го признака в
- 47. Зачем? Градиентный спуск и другие методы плохо работают на признаках с очень большим или маленьким масштабом.
- 49. Скачать презентацию
Слайд 2Почему линейные модели до сих пор используются?
Очень простые, поэтому можно использовать там,
Почему линейные модели до сих пор используются?
Очень простые, поэтому можно использовать там,

Слайд 3Постановка задачи
Датасет:
Функция потерь:
Постановка задачи
Датасет:
Функция потерь:

Слайд 4Определение модели
Мы будем искать модель в следующем виде
Намного удобнее для записи внести
Определение модели
Мы будем искать модель в следующем виде
Намного удобнее для записи внести

Слайд 5Линейность по параметрам
Какое может быть происхождение у признаков ?
Просто численный признак
Преобразования численных
Линейность по параметрам
Какое может быть происхождение у признаков ?
Просто численный признак
Преобразования численных

Слайд 6Пример
Пример
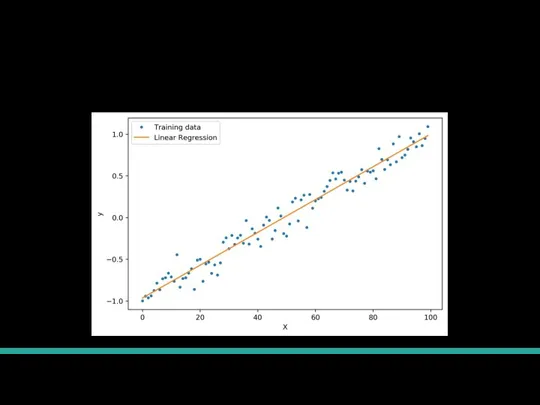
Слайд 7Точное решение
Запишем то, что мы хотим получить:
Точное решение
Запишем то, что мы хотим получить:

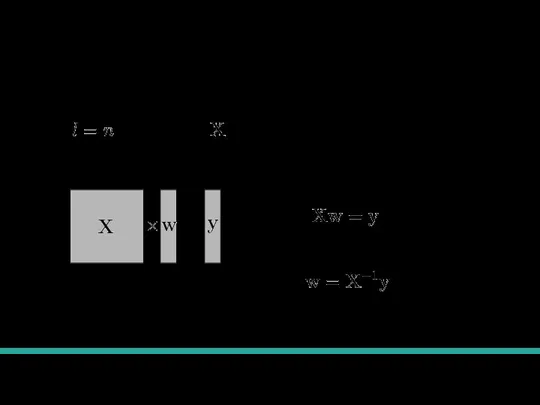
Слайд 8Точное решение
Случай , тогда матрица - квадратная и может иметь обратную.
=
Система линейных
Точное решение
Случай , тогда матрица - квадратная и может иметь обратную.
=
Система линейных
Слайд 9Pseudo-Inverse
Обычно , тогда у нас переопределенная система линейных уравнений.
=
Система линейных уравнений:
Приближенное решение:
Псевдообратная
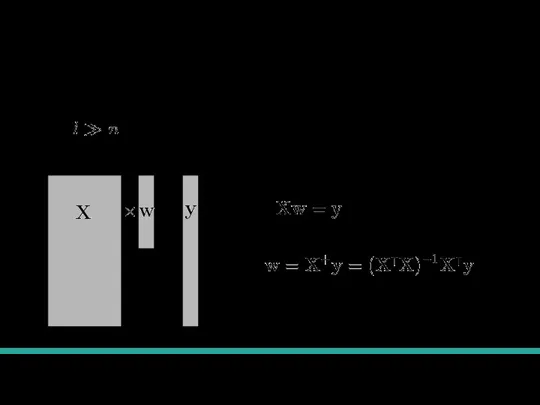
Pseudo-Inverse
Обычно , тогда у нас переопределенная система линейных уравнений.
=
Система линейных уравнений:
Приближенное решение:
Псевдообратная
Слайд 10Получение решения через производную
Подставим выражение для в функцию потерь и запишем в
Получение решения через производную
Подставим выражение для в функцию потерь и запишем в

Слайд 11Обучение классификаторов
Обучение классификаторов

Слайд 12Получение решения через производную
Возьмем производную
Если у линейно независимые столбцы, то можно приравнять
Получение решения через производную
Возьмем производную
Если у линейно независимые столбцы, то можно приравнять

Слайд 13Постановка задачи
Датасет:
Функция потерь:
, . То есть это вектор из 0 и
Постановка задачи
Датасет:
Функция потерь:
, . То есть это вектор из 0 и

Слайд 14Мы хотим выбрать функцию потерь, но какая лучше всего подойдет не знаем.
Попробуем
Мы хотим выбрать функцию потерь, но какая лучше всего подойдет не знаем.
Попробуем

Слайд 15Вероятностная модель
Х- случайная величина вектор признаков.
Y- случайная величина целевая переменная.
Пример случайной модели
Вероятностная модель
Х- случайная величина вектор признаков.
Y- случайная величина целевая переменная.
Пример случайной модели

Слайд 16Функция правдоподобия
Найдем способ для обучения любой модели, предсказывающей вероятность принадлежности к классу.
Функция правдоподобия
Найдем способ для обучения любой модели, предсказывающей вероятность принадлежности к классу.

Слайд 17Обучение модели через максимальное правдоподобие
Теорема из статистики гарантирует, что если мы найдем
Обучение модели через максимальное правдоподобие
Теорема из статистики гарантирует, что если мы найдем

Слайд 18Связь с минимизацией функции потерь
Преобразуем задачу максимизации в задачу минимизации.
Мы видим что
Связь с минимизацией функции потерь
Преобразуем задачу максимизации в задачу минимизации.
Мы видим что
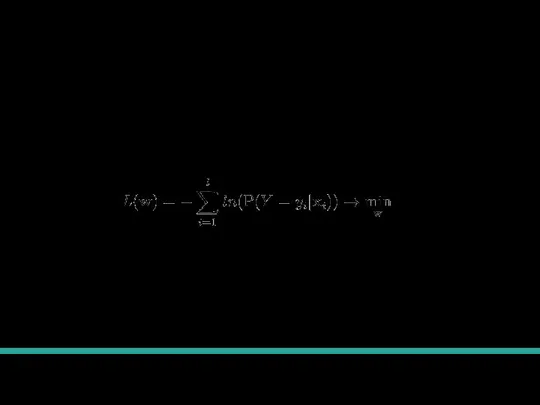
Слайд 19Что мы сделали
Мы знаем, что максимизация правдоподобия дает хорошие веса из статистики.
Изменив
Что мы сделали
Мы знаем, что максимизация правдоподобия дает хорошие веса из статистики.
Изменив
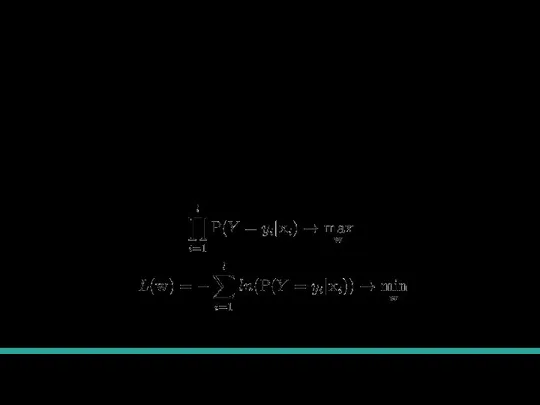
Слайд 20Логистическая регрессия
Логистическая регрессия

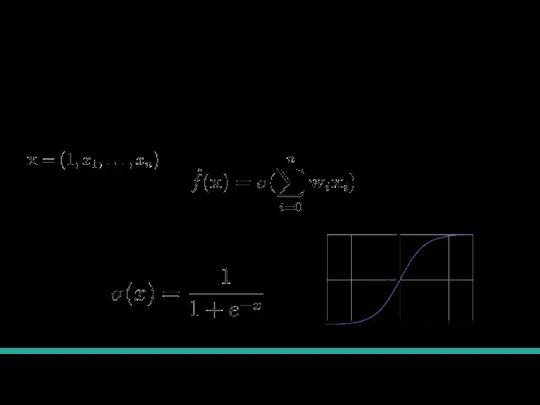
Слайд 21Определение модели
Мы будем искать модель в следующем виде.
Определение сигмоиды:
Определение модели
Мы будем искать модель в следующем виде.
Определение сигмоиды:
Слайд 22Предсказание вероятности
Будем считать, что наша модель предсказывает вероятности. Именно поэтому она называется
Предсказание вероятности
Будем считать, что наша модель предсказывает вероятности. Именно поэтому она называется

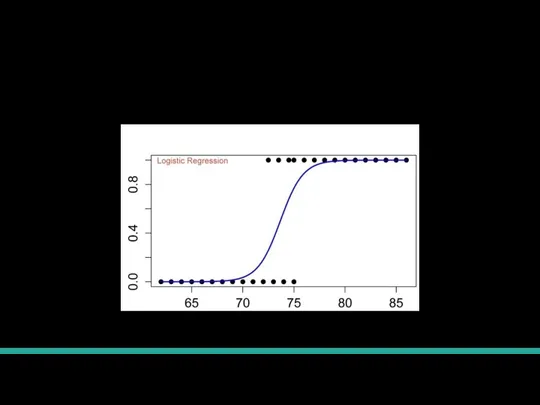
Слайд 23Пример работы
Как выглядит обученная логистическая регрессия на данных с одним признаком.
Пример работы
Как выглядит обученная логистическая регрессия на данных с одним признаком.
Слайд 24Обучение логистической регрессии
В полученную ранее формулу функции потерь можно подставить вероятность, которую
Обучение логистической регрессии
В полученную ранее формулу функции потерь можно подставить вероятность, которую

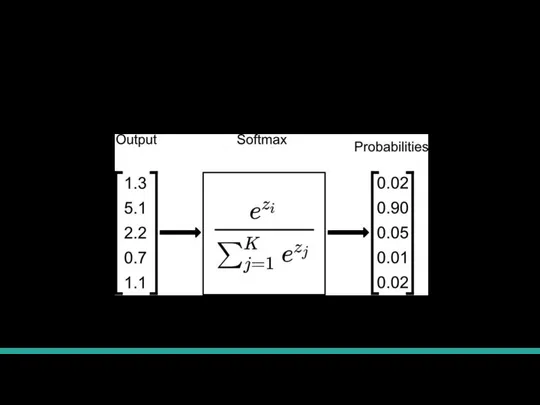
Слайд 25Обобщение на много классов
Пусть у нас есть m классов. Введем две новые
Обобщение на много классов
Пусть у нас есть m классов. Введем две новые

Слайд 26Пример работы Softmax
Пример работы Softmax
Слайд 27Много классов
Выпишем предсказанную вероятность для к-го класса.
Ее можно подставить в функцию
Много классов
Выпишем предсказанную вероятность для к-го класса.
Ее можно подставить в функцию

Слайд 28Градиентный спуск
Градиентный спуск

Слайд 29Обучение логистической регрессии
В полученную ранее формулу функции потерь можно подставить вероятность, которую
Обучение логистической регрессии
В полученную ранее формулу функции потерь можно подставить вероятность, которую

Слайд 30Эвристика градиентного спуска
Эвристика градиентного спуска
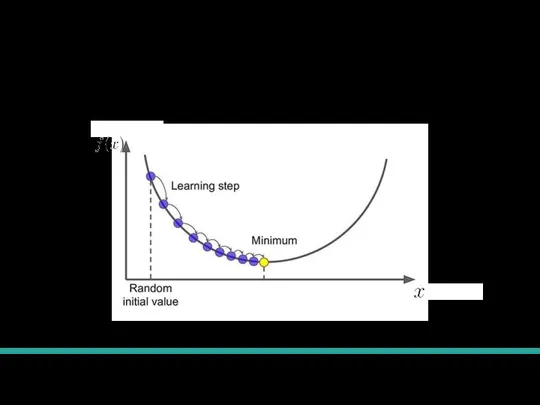
Слайд 31Градиентный спуск формализация
У нас стоит задача минимизации какой-то функции:
Чтобы применять метод градиентного
Градиентный спуск формализация
У нас стоит задача минимизации какой-то функции:
Чтобы применять метод градиентного

Слайд 32Шаг градиентного спуска
На каждом шаге будем менять все переменные, от которых зависит
Шаг градиентного спуска
На каждом шаге будем менять все переменные, от которых зависит

Слайд 33Градиентный спуск
Выбираем точку, с которой начнем оптимизацию.
На каждом шаге будем менять все
Градиентный спуск
Выбираем точку, с которой начнем оптимизацию.
На каждом шаге будем менять все

Слайд 34Градиентный спуск для параболы
Будем минимизировать ,
/ /
Теперь делаем обновления:
С каждым шагом мы
Градиентный спуск для параболы
Будем минимизировать ,
/ /
Теперь делаем обновления:
С каждым шагом мы
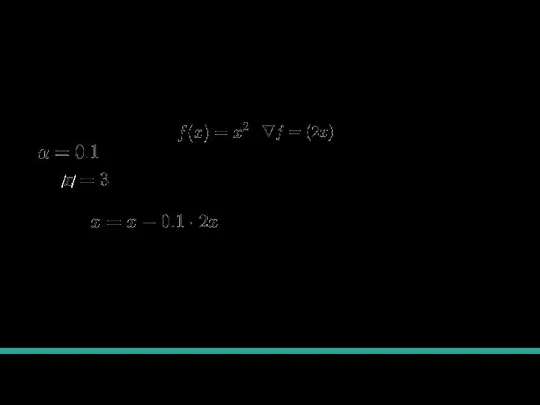
Слайд 35Градиентный спуск для линейной регрессии
Функция потерь (она зависит только от весов, потому
Градиентный спуск для линейной регрессии
Функция потерь (она зависит только от весов, потому
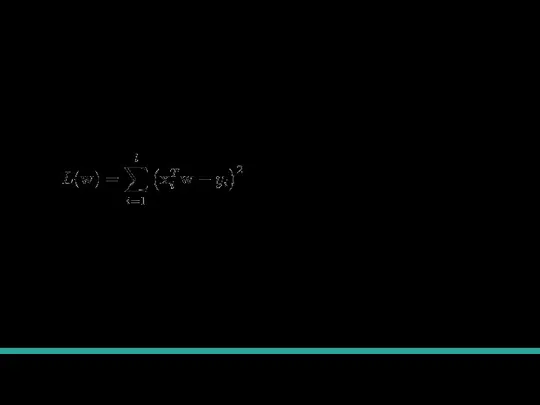
Слайд 36Градиентный спуск для линейной регрессии
Пошагово возьмем производную лосса по параметрам:
Градиентный спуск для линейной регрессии
Пошагово возьмем производную лосса по параметрам:

Слайд 37Градиентный спуск для линейной регрессии
Функция потерь (она зависит только от весов, потому
Градиентный спуск для линейной регрессии
Функция потерь (она зависит только от весов, потому

Слайд 38Градиентный спуск для линейной регрессии
Будем минимизировать
Как-то выберем начальные веса.
Теперь делаем обновления:
Градиентный спуск для линейной регрессии
Будем минимизировать
Как-то выберем начальные веса.
Теперь делаем обновления:

Слайд 39Градиентный спуск для логистической регрессии
Функция потерь:
Градиентный спуск для логистической регрессии
Функция потерь:

Слайд 40Градиентный спуск для логистической регрессии
Возьмем производную:
Соединим:
Градиентный спуск для логистической регрессии
Возьмем производную:
Соединим:

Слайд 41Регуляризация
Регуляризация

Слайд 42Мультиколлинеарность для линейной регрессии
Вспомним определение линейной регрессии:
Если столбцы матрицы линейно зависимы, то
Мультиколлинеарность для линейной регрессии
Вспомним определение линейной регрессии:
Если столбцы матрицы линейно зависимы, то

Слайд 43
Weight Decay
Мы можем предположить, что веса не должны быть большими по
Weight Decay
Мы можем предположить, что веса не должны быть большими по

Слайд 44Как изменится градиент
-регуляризация
-регуляризация
Как изменится градиент
-регуляризация
-регуляризация

Слайд 45Нормализация признаков
Нормализация признаков

Слайд 46Что такое нормализация?
Мы изменяем признаки в датасете по правилу:
- среднее значение
Что такое нормализация?
Мы изменяем признаки в датасете по правилу:
- среднее значение

Слайд 47Зачем?
Градиентный спуск и другие методы плохо работают на признаках с очень большим
Зачем?
Градиентный спуск и другие методы плохо работают на признаках с очень большим

 Действия с десятичными дробями
Действия с десятичными дробями Скрипт параллелограм
Скрипт параллелограм Методы обработки числовых данных
Методы обработки числовых данных Урок - игра В мире математики 6 класс
Урок - игра В мире математики 6 класс Площадь прямоугольника. Урок-открытие. 2 класс
Площадь прямоугольника. Урок-открытие. 2 класс Презентация на тему Преобразования графиков функций
Презентация на тему Преобразования графиков функций  Предел функции
Предел функции Презентация на тему Длина и меры ее измерения
Презентация на тему Длина и меры ее измерения  Презентация на тему Деление с остатком (3 класс)
Презентация на тему Деление с остатком (3 класс)  Презентация на тему Виды движения
Презентация на тему Виды движения  Тела вращения
Тела вращения Теорема Пифагора
Теорема Пифагора Противоположные и обратные числа
Противоположные и обратные числа Задачи на дроби
Задачи на дроби Презентация на тему Объемы тел 11 класс
Презентация на тему Объемы тел 11 класс  Теория вероятностей
Теория вероятностей Презентация на тему Десятичные дроби: повторение
Презентация на тему Десятичные дроби: повторение  Классная работа. Признаки равенства треугольников
Классная работа. Признаки равенства треугольников Волшебная страна - Геометрия
Волшебная страна - Геометрия Золотое сечение
Золотое сечение Каков развивающий потенциал функциональной линии в курсе математики?
Каков развивающий потенциал функциональной линии в курсе математики? Прогрессии в окружающей нас жизни
Прогрессии в окружающей нас жизни Логарифмические выражения
Логарифмические выражения Презентация на тему Понятие дроби. Равенство дробей
Презентация на тему Понятие дроби. Равенство дробей  Решение линейных неравенств
Решение линейных неравенств Квадратный корень
Квадратный корень Отображение множеств. Диаграммы
Отображение множеств. Диаграммы Путешествие в зазеркалье. Проект по геометрии
Путешествие в зазеркалье. Проект по геометрии