Метод определения тематики математических документов на основе вероятностной модели скрытого размещения Дирихле
- Метод определения тематики математических документов на основе вероятностной модели скрытого размещения Дирихле

Содержание
- 2. Постановка задачи
- 3. Цель работы
- 4. Модель скрытого размещения Дирихле
- 5. Модифицированный вариационный вывод Байеса
- 6. Схема работы программы
- 7. Загрузка коллекции документов и предпроцессорная обработка
- 8. Извлечение текста из PDF документа
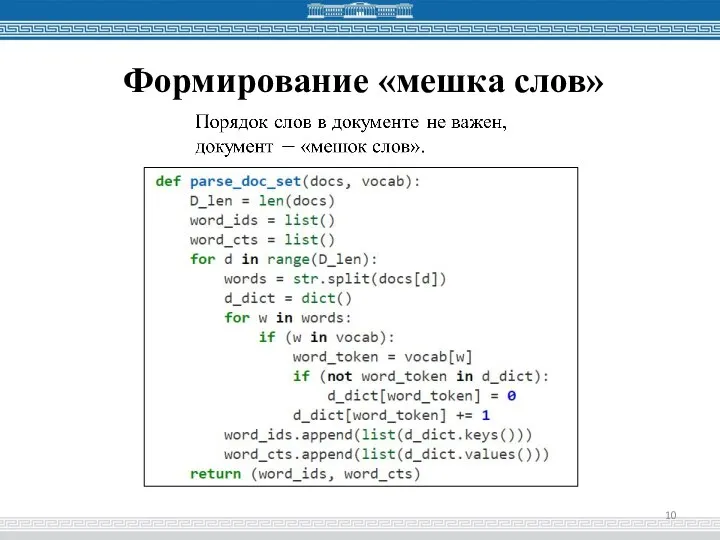
- 10. Формирование «мешка слов»
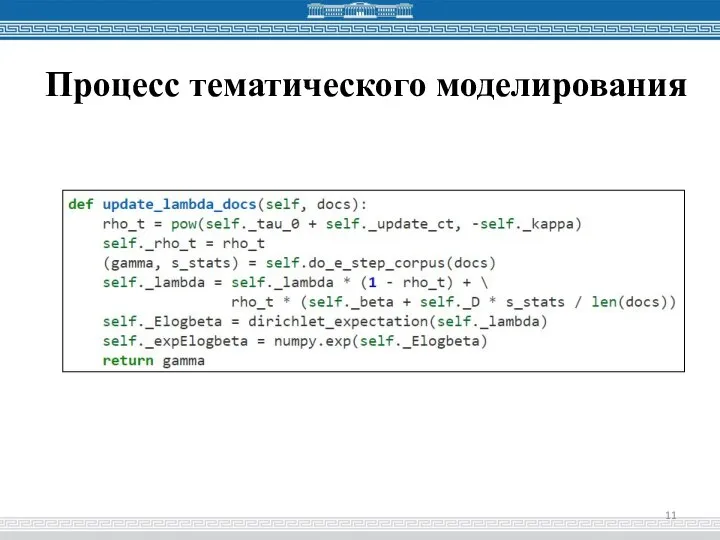
- 11. Процесс тематического моделирования
- 13. Тестирование работы программы В качестве коллекции русскоязычных математических документов были использованы труды математического центра имени Н.И.
- 14. Результаты обработки коллекции
- 15. Результаты обработки одной статьи из коллекции
- 16. Перспективы развития работы Использование методов оптического распознавания символов (Optical Character Recognition, OCR) Создание русскоязычного словаря математических
- 17. Заключение
- 19. Скачать презентацию

Слайд 3Цель работы
Цель работы

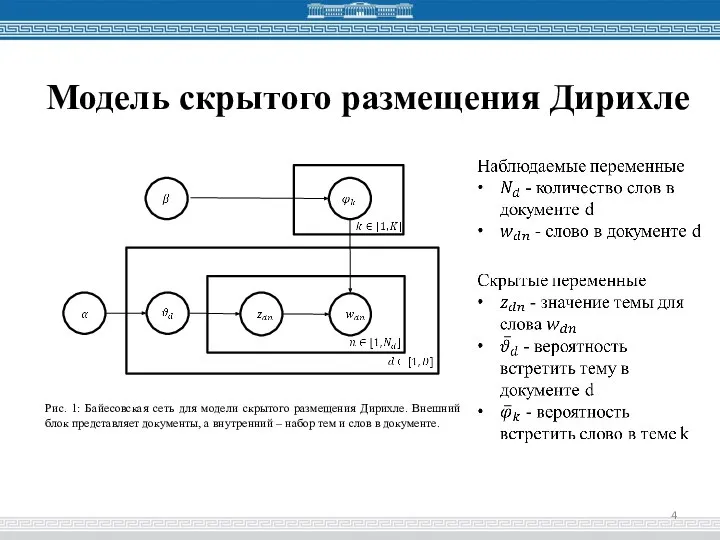
Слайд 4Модель скрытого размещения Дирихле
Модель скрытого размещения Дирихле
Слайд 5
Модифицированный вариационный вывод Байеса
Модифицированный вариационный вывод Байеса

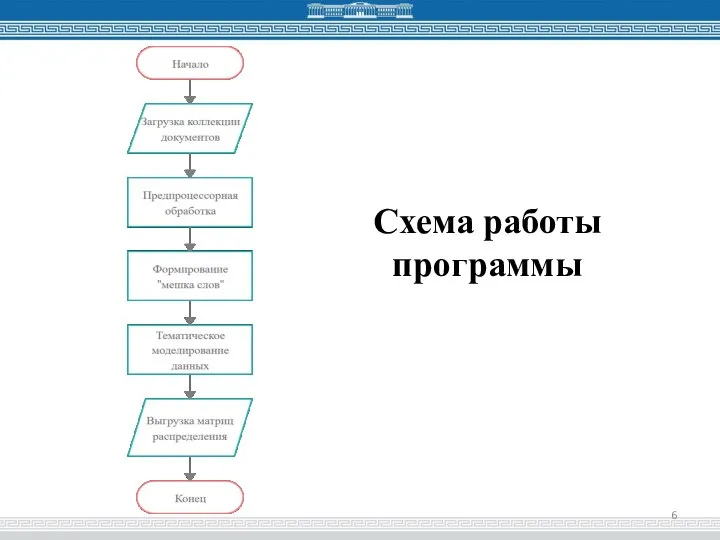
Слайд 6Схема работы программы
Схема работы программы
Слайд 7Загрузка коллекции документов
и предпроцессорная обработка
Загрузка коллекции документов
и предпроцессорная обработка

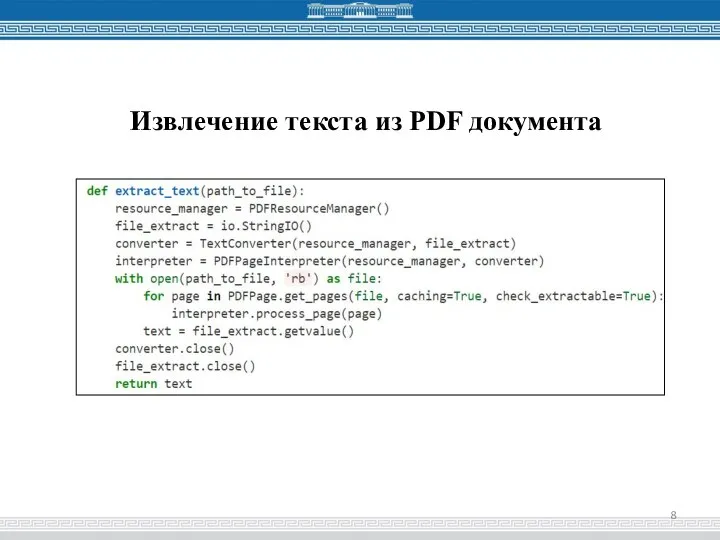
Слайд 8Извлечение текста из PDF документа
Извлечение текста из PDF документа
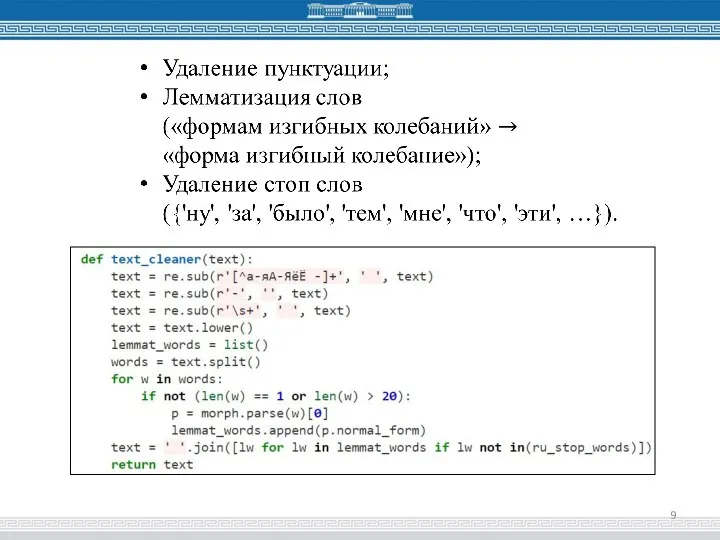
Слайд 10Формирование «мешка слов»
Формирование «мешка слов»
Слайд 11Процесс тематического моделирования
Процесс тематического моделирования
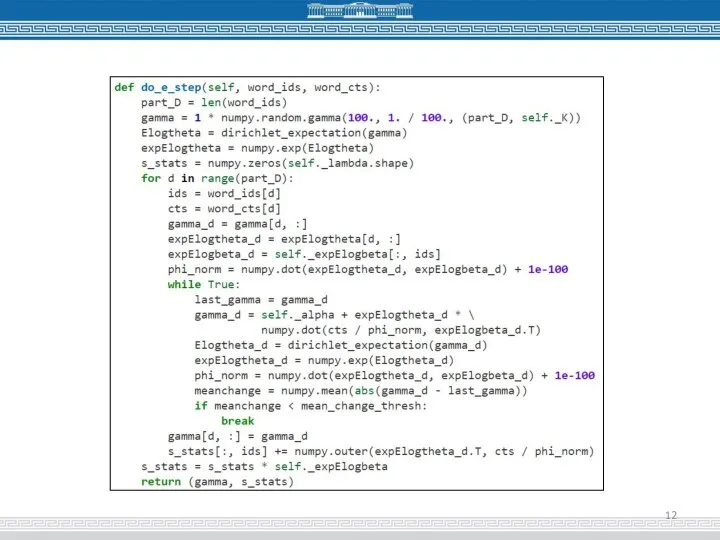
Слайд 13Тестирование работы программы
В качестве коллекции русскоязычных математических документов были использованы труды математического
Тестирование работы программы
В качестве коллекции русскоязычных математических документов были использованы труды математического

Слайд 14Результаты обработки коллекции
Результаты обработки коллекции
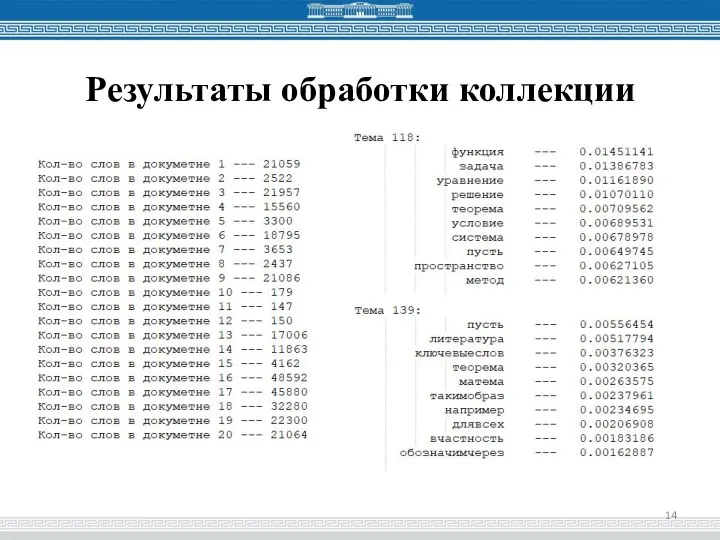
Слайд 15Результаты обработки одной статьи из коллекции
Результаты обработки одной статьи из коллекции

Слайд 16Перспективы развития работы
Использование методов оптического распознавания символов
(Optical Character Recognition, OCR)
Создание русскоязычного словаря
Перспективы развития работы
Использование методов оптического распознавания символов
(Optical Character Recognition, OCR)
Создание русскоязычного словаря

Слайд 17Заключение
Заключение

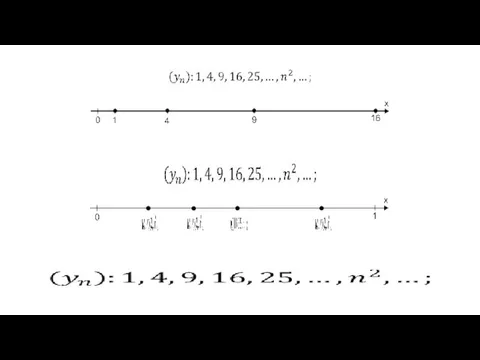 Пояснения к определению предела последовательности
Пояснения к определению предела последовательности Вычисление площадей с помощью интегралов
Вычисление площадей с помощью интегралов тригонометрические неравенства (1)
тригонометрические неравенства (1) Функция и график
Функция и график Методы оценки показателей качества результатов анализа в лаборатории, по приложению Б, РМГ 76-2014
Методы оценки показателей качества результатов анализа в лаборатории, по приложению Б, РМГ 76-2014 Сложение и вычитание смешанных чисел
Сложение и вычитание смешанных чисел Сумма углов треугольника
Сумма углов треугольника Степенная функция
Степенная функция attachment_642692504
attachment_642692504 Измерение объема жидких и сыпучих веществ с помощью условной меры масс
Измерение объема жидких и сыпучих веществ с помощью условной меры масс Операции с числовыми множествами. Формулы сокращённого умножения
Операции с числовыми множествами. Формулы сокращённого умножения МХСИ
МХСИ Выбор средств измерения для технологического процесса
Выбор средств измерения для технологического процесса Сложение и вычитание многочленов
Сложение и вычитание многочленов Презентация на тему Математика - царица наук
Презентация на тему Математика - царица наук  15 задание. Виды. Делимость. Числовая последовательность. Конъюнкция. Множества
15 задание. Виды. Делимость. Числовая последовательность. Конъюнкция. Множества Разбор Мат.Вертикали. 6 класс
Разбор Мат.Вертикали. 6 класс Классическое определение вероятности
Классическое определение вероятности Физические величины
Физические величины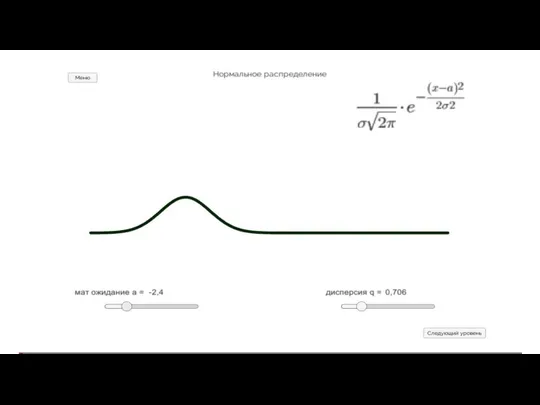 Критерий Пирсона
Критерий Пирсона Взятие Измаила в математических и исторических нюансах
Взятие Измаила в математических и исторических нюансах Презентация на тему Задачи на движение для учителя
Презентация на тему Задачи на движение для учителя  Масштаб задачи
Масштаб задачи Темір жолдың жылжымалы құрамын пайдалану, жөндеу және техникалық қызмет көрсету (түрлері бойынша)
Темір жолдың жылжымалы құрамын пайдалану, жөндеу және техникалық қызмет көрсету (түрлері бойынша) Назовите углы
Назовите углы Координатная плоскость. Построение точки по ее координатам. 6 класс
Координатная плоскость. Построение точки по ее координатам. 6 класс Двоичная арифметика
Двоичная арифметика О сохранении и нарушении равносильности при решении уравнений и неравенств
О сохранении и нарушении равносильности при решении уравнений и неравенств