- Описательная статистика

Содержание
- 2. Робастные показатели Робастный означает устойчивый (не зависящий от предположения о типе распределения, от наличия вылетающих наблюдений)
- 3. Робастные показатели В теории оценок принято анализировать чувствительность показателя центральной тенденции к вылетающим наблюдениям по проценту
- 4. Робастные показатели Лучше иметь возможность отсекать наблюдения не симметрично (потеря данных) – М-оценки Одношаговый метод: определить
- 5. Робастные показатели М-оценка (R) library(MASS) xs huber(xs, k=1.28) $mu [1] 284.7575 $s [1] 169.0164
- 6. Робастные показатели МОМ (малые группы) Аналогичен обычным М-оценкам, но не включает в числителе произведения, содержащего MAD
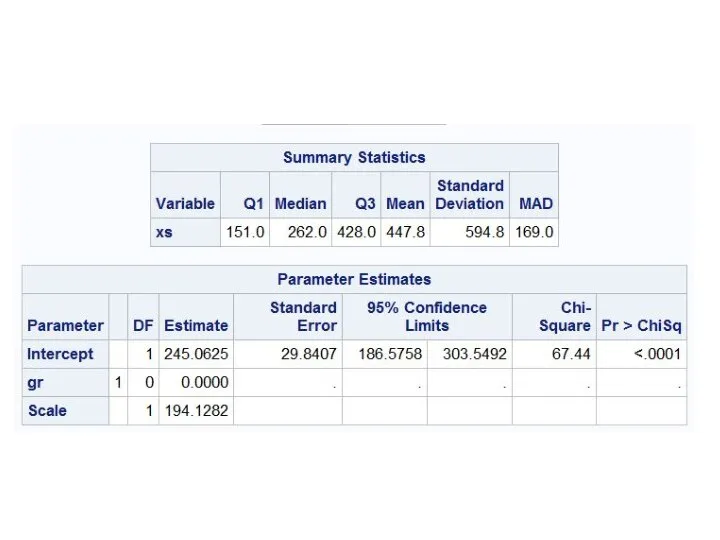
- 7. Робастные оценки data xs; input xs @@; gr=1; cards; 77 81 88 114 151 210 219
- 9. Как описывать показатели центральной тенденции Количественные переменные: Симметричное распределение данных - среднее арифметическое Скошенное распределение данных
- 10. Методы описания показателей разброса данных
- 11. Простейшие Разброс (амплитуда) Дисперсия (стандартное отклонение)
- 12. Робастные Стандартное отклонение для усеченных и винзоризированных средних Для винзоризированных средних стандартное отклонение считается аналогичным образом,
- 13. Робастные Межквартильное расстояние MAD Tn Rousseeuw и Croux, (1993) Более эффективный, но мало где рассчитывается автоматом
- 14. Tn в SAS data xs; input xs @@; gr=1; id=_n_; cards; 77 81 88 114 151
- 15. Tn в R library(RMySQL) xs id new con dbWriteTable(con,"new",new) xtab SELECT prim.xs, ABS(prim.xs - sec.xs) AS
- 16. Tn
- 17. Как описывать разброс Для количественных данных - стандартное отклонение (включая стандартное отклонение винзоризированных и обрезанных средних)
- 18. Бивариантный анализ Как описывать связи
- 19. Количественная зависимая Количественная зависимая переменная и количественная независимая переменная Коэффициент линейной регрессии в случае нормальности распределения
- 20. Ординальная зависимая Ординальная зависимая переменная и количественная или ординальная независимая переменная (большое количество классов независимой переменной)
- 22. Скачать презентацию
Слайд 2Робастные показатели
Робастный означает устойчивый (не зависящий от предположения о типе распределения, от
Робастные показатели
Робастный означает устойчивый (не зависящий от предположения о типе распределения, от

Слайд 3Робастные показатели
В теории оценок принято анализировать чувствительность показателя центральной тенденции к вылетающим
Робастные показатели
В теории оценок принято анализировать чувствительность показателя центральной тенденции к вылетающим

Слайд 4Робастные показатели
Лучше иметь возможность отсекать наблюдения не симметрично (потеря данных) – М-оценки
Одношаговый
Робастные показатели
Лучше иметь возможность отсекать наблюдения не симметрично (потеря данных) – М-оценки
Одношаговый

Слайд 5Робастные показатели
М-оценка (R)
library(MASS)
xs<-c(77, 81, 88, 114, 151, 210, 219, 246, 253, 262,
Робастные показатели
М-оценка (R)
library(MASS)
xs<-c(77, 81, 88, 114, 151, 210, 219, 246, 253, 262,
![Робастные показатели М-оценка (R) library(MASS) xs huber(xs, k=1.28) $mu [1] 284.7575 $s [1] 169.0164](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1114595/slide-4.jpg)
Слайд 6Робастные показатели
МОМ (малые группы)
Аналогичен обычным М-оценкам, но не включает в числителе произведения,
Робастные показатели
МОМ (малые группы)
Аналогичен обычным М-оценкам, но не включает в числителе произведения,

Слайд 7Робастные оценки
data xs;
input xs @@;
gr=1;
cards;
77 81 88 114 151 210 219 246
Робастные оценки
data xs;
input xs @@;
gr=1;
cards;
77 81 88 114 151 210 219 246

Слайд 9Как описывать показатели центральной тенденции
Количественные переменные:
Симметричное распределение данных - среднее арифметическое
Скошенное
Как описывать показатели центральной тенденции
Количественные переменные:
Симметричное распределение данных - среднее арифметическое
Скошенное

Слайд 10Методы описания показателей разброса данных
Методы описания показателей разброса данных

Слайд 11Простейшие
Разброс (амплитуда)
Дисперсия (стандартное отклонение)
Простейшие
Разброс (амплитуда)
Дисперсия (стандартное отклонение)

Слайд 12Робастные
Стандартное отклонение для усеченных и винзоризированных средних
Для винзоризированных средних стандартное отклонение считается
Робастные
Стандартное отклонение для усеченных и винзоризированных средних
Для винзоризированных средних стандартное отклонение считается

Слайд 13Робастные
Межквартильное расстояние
MAD
Tn Rousseeuw и Croux, (1993)
Более эффективный, но мало где рассчитывается
Робастные
Межквартильное расстояние
MAD
Tn Rousseeuw и Croux, (1993)
Более эффективный, но мало где рассчитывается

Слайд 14Tn в SAS
data xs;
input xs @@;
gr=1;
id=_n_;
cards;
77 81 88 114 151 210 219
Tn в SAS
data xs;
input xs @@;
gr=1;
id=_n_;
cards;
77 81 88 114 151 210 219

Слайд 15Tn в R
library(RMySQL)
xs<-c(77, 81, 88, 114, 151, 210, 219, 246, 253, 262,
Tn в R
library(RMySQL)
xs<-c(77, 81, 88, 114, 151, 210, 219, 246, 253, 262,

Слайд 16Tn
Tn

Слайд 17Как описывать разброс
Для количественных данных - стандартное отклонение (включая стандартное отклонение винзоризированных
Как описывать разброс
Для количественных данных - стандартное отклонение (включая стандартное отклонение винзоризированных

Слайд 18Бивариантный анализ
Как описывать связи
Бивариантный анализ
Как описывать связи

Слайд 19Количественная зависимая
Количественная зависимая переменная и количественная независимая переменная
Коэффициент линейной регрессии в случае
Количественная зависимая
Количественная зависимая переменная и количественная независимая переменная
Коэффициент линейной регрессии в случае

Слайд 20Ординальная зависимая
Ординальная зависимая переменная и количественная или ординальная независимая переменная (большое количество
Ординальная зависимая
Ординальная зависимая переменная и количественная или ординальная независимая переменная (большое количество

 Углы в прямоугольном параллелепипеде. Прямоугольный параллелепипед в задачах В9 и В11 ЕГЭ
Углы в прямоугольном параллелепипеде. Прямоугольный параллелепипед в задачах В9 и В11 ЕГЭ Расстояние от точки до прямой
Расстояние от точки до прямой Презентация на тему Математическая мозаика
Презентация на тему Математическая мозаика  Центральная симметрия
Центральная симметрия Prezentado de enspezoj
Prezentado de enspezoj Великий квадрат не знает пределов
Великий квадрат не знает пределов Религия Байеса
Религия Байеса Подготовка к ОГЭ, 9 класс, геометрия
Подготовка к ОГЭ, 9 класс, геометрия Предельные теоремы теории вероятностей и её практические применения
Предельные теоремы теории вероятностей и её практические применения Тайна Египетского треугольника
Тайна Египетского треугольника Проценты. Задания
Проценты. Задания Презентация на тему Угол между векторами и скалярное произведение векторов
Презентация на тему Угол между векторами и скалярное произведение векторов  Функции. 8 класс
Функции. 8 класс Теорема Пифагора. Решение задач
Теорема Пифагора. Решение задач Число и цифра 2
Число и цифра 2 Аксонометрические проекции. Самостоятельная работа
Аксонометрические проекции. Самостоятельная работа Знаки коэффициентов квадратичной функции
Знаки коэффициентов квадратичной функции Площадь треугольника
Площадь треугольника Презентация на тему Сочетательное свойство сложения
Презентация на тему Сочетательное свойство сложения  Теорема. Франсуа Виет (1540-1603)
Теорема. Франсуа Виет (1540-1603) Решение задач
Решение задач Физические величины
Физические величины Второй признак равенства треугольников
Второй признак равенства треугольников Совокупность математических методов для изучения свойств кубика Рубика
Совокупность математических методов для изучения свойств кубика Рубика Элементы математической статистики
Элементы математической статистики Перпендикуляр и наклонная
Перпендикуляр и наклонная Параллельные прямые в архитектуре
Параллельные прямые в архитектуре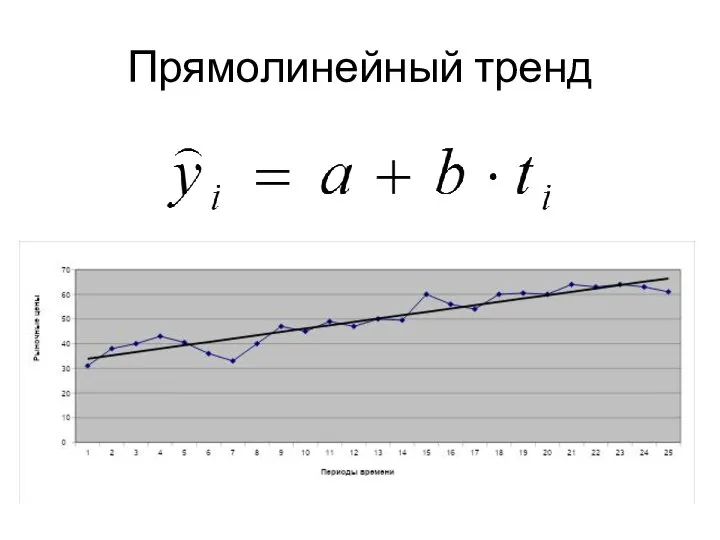 Прямолинейный тренд
Прямолинейный тренд