- Построение QSAR модели для предсказания активности ингибиторов ренина

Содержание
- 2. ЦЕЛЬ И ЗАДАЧИ Цель: построить модель машинного обучения на основе алгоритма “случайных лесов” (random forest), которая
- 3. АКТУАЛЬНОСТЬ Сердечно-сосудистые заболевания являются основной причиной смерти и инвалидизации во всем мире. Поиск новых способов лечения
- 4. МАТЕРИАЛЫ И МЕТОДЫ Машинное обучение (machine learning, ML) – совокупность методов искусственного интеллекта, позволяющих строить алгоритмы
- 5. Скрипты для обработки данных и построения модели были написаны на языке программирования Python. Для 1D представления
- 6. Для отбора ингибиторов ренина использовалась база данных ChEMBL. Всего было найдено 5154 лиганда. Для дальнейшей работы
- 7. Фингерпринты – представление молекул в виде битовой строки, где каждый бит соответствует наличию (1) либо отсутствию
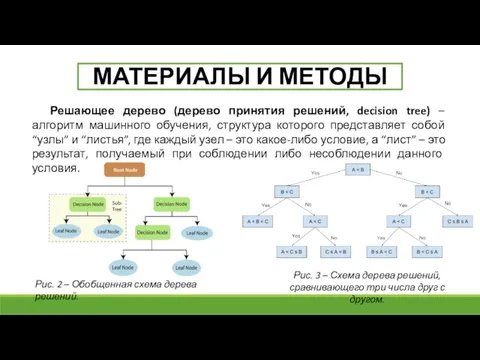
- 8. Решающее дерево (дерево принятия решений, decision tree) – алгоритм машинного обучения, структура которого представляет собой “узлы”
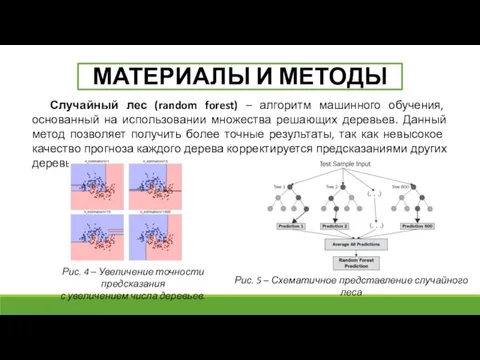
- 9. Случайный лес (random forest) – алгоритм машинного обучения, основанный на использовании множества решающих деревьев. Данный метод
- 10. МАТЕРИАЛЫ И МЕТОДЫ В качестве меры активности молекул использовалась IC50. Для удобства анализа данной меры активности
- 11. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ С помощью метода RandomForestClassifier была построена QSAR модель “случайных лесов”. Обучение модели
- 12. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ Метрики качества модели составили: Точность предсказания на тренировочных данных: 0,9472; Точность предсказания
- 13. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ Конфузионная матрица (confusion matrix) – таблица, представляющая результаты предсказания в сравнении с
- 14. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ По метрикам качества модели можно сделать вывод, что данная модель находит практически
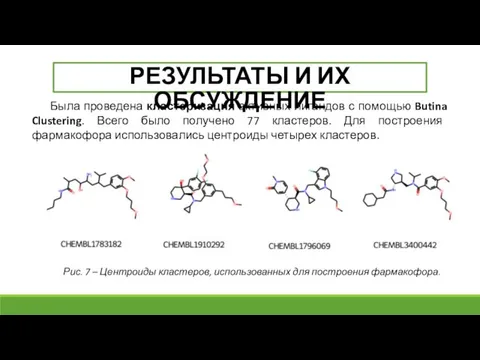
- 15. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ Была проведена кластеризация активных лигандов с помощью Butina Clustering. Всего было получено
- 16. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ Построение фармакофора проводилось с помощью алгоритма MAPex. Полученный фармакофор имеет 4 фармакофорных
- 17. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ По данному фармакофору был проведен поиск в базе данных ZINCPharmer, были сохранены
- 18. РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ 1811 соединений, которые удовлетворяли критериям Липински были проверены по фильтру PAINS (Pan-assay
- 19. Для оставшихся 1245 соединений были получены их фингерпринты. С использованием QSAR модели, которая была построена ранее
- 21. Скачать презентацию

Слайд 3АКТУАЛЬНОСТЬ
Сердечно-сосудистые заболевания являются основной причиной смерти и инвалидизации во всем мире. Поиск
АКТУАЛЬНОСТЬ
Сердечно-сосудистые заболевания являются основной причиной смерти и инвалидизации во всем мире. Поиск

Слайд 4МАТЕРИАЛЫ И МЕТОДЫ
Машинное обучение (machine learning, ML) – совокупность методов искусственного интеллекта,
МАТЕРИАЛЫ И МЕТОДЫ
Машинное обучение (machine learning, ML) – совокупность методов искусственного интеллекта,

Слайд 5Скрипты для обработки данных и построения модели были написаны на языке программирования
Скрипты для обработки данных и построения модели были написаны на языке программирования

Слайд 6Для отбора ингибиторов ренина использовалась база данных ChEMBL. Всего было найдено 5154
Для отбора ингибиторов ренина использовалась база данных ChEMBL. Всего было найдено 5154

Слайд 7Фингерпринты – представление молекул в виде битовой строки, где каждый бит соответствует
Фингерпринты – представление молекул в виде битовой строки, где каждый бит соответствует

Слайд 8Решающее дерево (дерево принятия решений, decision tree) – алгоритм машинного обучения, структура
Решающее дерево (дерево принятия решений, decision tree) – алгоритм машинного обучения, структура
Слайд 9Случайный лес (random forest) – алгоритм машинного обучения, основанный на использовании множества
Случайный лес (random forest) – алгоритм машинного обучения, основанный на использовании множества
Слайд 10МАТЕРИАЛЫ И МЕТОДЫ
В качестве меры активности молекул использовалась IC50. Для удобства анализа
МАТЕРИАЛЫ И МЕТОДЫ
В качестве меры активности молекул использовалась IC50. Для удобства анализа

Слайд 11РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
С помощью метода RandomForestClassifier была построена QSAR модель “случайных
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
С помощью метода RandomForestClassifier была построена QSAR модель “случайных

Слайд 12РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Метрики качества модели составили:
Точность предсказания на тренировочных данных: 0,9472;
Точность
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Метрики качества модели составили:
Точность предсказания на тренировочных данных: 0,9472;
Точность

Слайд 13РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Конфузионная матрица (confusion matrix) – таблица, представляющая результаты предсказания
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Конфузионная матрица (confusion matrix) – таблица, представляющая результаты предсказания

Слайд 14РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
По метрикам качества модели можно сделать вывод, что данная
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
По метрикам качества модели можно сделать вывод, что данная

Слайд 15РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Была проведена кластеризация активных лигандов с помощью Butina Clustering.
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Была проведена кластеризация активных лигандов с помощью Butina Clustering.
Слайд 16РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Построение фармакофора проводилось с помощью алгоритма MAPex. Полученный фармакофор
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Построение фармакофора проводилось с помощью алгоритма MAPex. Полученный фармакофор

Слайд 17РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
По данному фармакофору был проведен поиск в базе данных
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
По данному фармакофору был проведен поиск в базе данных

Слайд 18РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
1811 соединений, которые удовлетворяли критериям Липински были проверены по
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
1811 соединений, которые удовлетворяли критериям Липински были проверены по

Слайд 19Для оставшихся 1245 соединений были получены их фингерпринты. С использованием QSAR модели,
Для оставшихся 1245 соединений были получены их фингерпринты. С использованием QSAR модели,

 Здоровое питание
Здоровое питание Бүйрек поликистоз
Бүйрек поликистоз Функции желёз внутренней секреции. 8 класс
Функции желёз внутренней секреции. 8 класс Секреторные кардиомиоциты
Секреторные кардиомиоциты Квант. АИТВ-инфекциясы бар науқастарда вирусты гепатиттердің алдын алу және емдеу ерекшеліктері
Квант. АИТВ-инфекциясы бар науқастарда вирусты гепатиттердің алдын алу және емдеу ерекшеліктері Курація хворого з гострою серцевою недостатністю
Курація хворого з гострою серцевою недостатністю Внутриутробный гидронефроз
Внутриутробный гидронефроз Инфекционные заболевания
Инфекционные заболевания Жүрек, орталық жүйке жүйесі, бұлшықеттің электрлік белсенділігі
Жүрек, орталық жүйке жүйесі, бұлшықеттің электрлік белсенділігі Влияние мобильных устройств на организм человека
Влияние мобильных устройств на организм человека Оптимизация мозгового кровотока, как средство стимуляции нейропластических преобразований в ЦНС
Оптимизация мозгового кровотока, как средство стимуляции нейропластических преобразований в ЦНС Группы крови
Группы крови Антибиотикопрофилактика. Антибиотик
Антибиотикопрофилактика. Антибиотик Фостер и Тримбоу. Информационные материалы
Фостер и Тримбоу. Информационные материалы In silico поиск потенциальных ингибиторов гепараназы (Q9Y251)
In silico поиск потенциальных ингибиторов гепараназы (Q9Y251) Дәрілік заттар, дәрілік формалар, Дәрілік препараттар тауар ретінде
Дәрілік заттар, дәрілік формалар, Дәрілік препараттар тауар ретінде От повивальных бабок до современных акушерок
От повивальных бабок до современных акушерок Холестеатома наружного слухового прохода
Холестеатома наружного слухового прохода Схваткообразные боли в животе у беременных. Резус-конфликт
Схваткообразные боли в животе у беременных. Резус-конфликт Противовоспалительные средства
Противовоспалительные средства Подагра. Подагрический артрит
Подагра. Подагрический артрит Первая помощь при травмах на уроках физкультуры и в спортивных секциях
Первая помощь при травмах на уроках физкультуры и в спортивных секциях Сколиоз. Степени сколиоза
Сколиоз. Степени сколиоза Антигипертензивные средства
Антигипертензивные средства Технология Tesla HyperLight® – новая эра в оптике
Технология Tesla HyperLight® – новая эра в оптике Роль медицинской сестры в обеспечении качества жизни пациентов с ревматоидным артритом
Роль медицинской сестры в обеспечении качества жизни пациентов с ревматоидным артритом Морфология клеток крови и костного мозга
Морфология клеток крови и костного мозга Гигиена питания
Гигиена питания