- Описательные статистики

Содержание
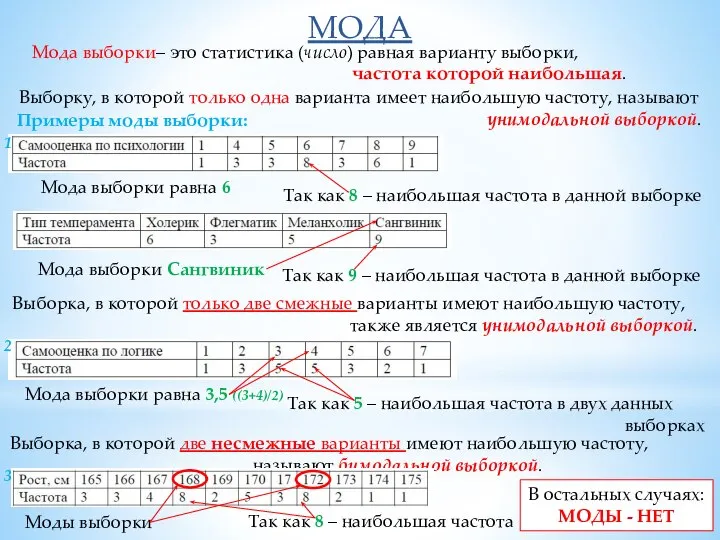
- 2. МОДА Мода выборки– это статистика (число) равная варианту выборки, частота которой наибольшая. Выборку, в которой только
- 3. СРЕДНЕЕ Среднее выборки (m)– это статистика (число) равная отношению суммы всех значений варианты к объёму выборки
- 4. САНДАРТНОЕ ОТКЛОНЕНИЕ Стандартное отклонение (s)– это статистика (число) обозначающая стандартный диапазон изменчивости (рассеяния) вариант от среднего
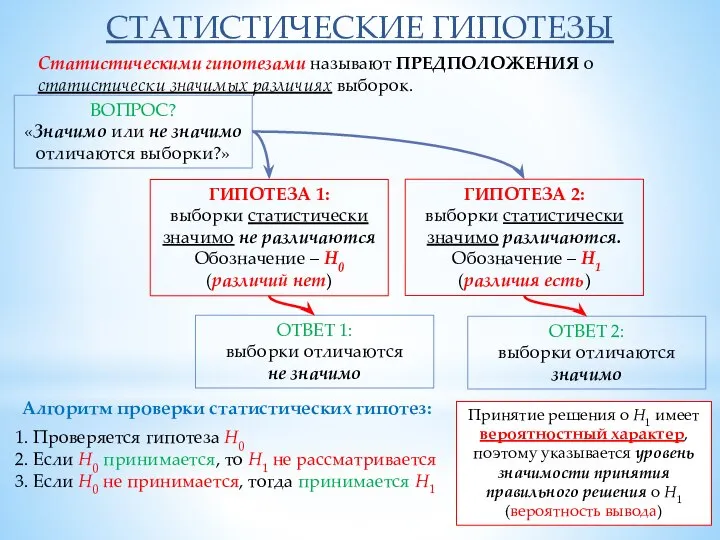
- 5. Статистический вывод Статистический критерий — строгое математическое ПРАВИЛО, по которому принимается или отвергается та или иная
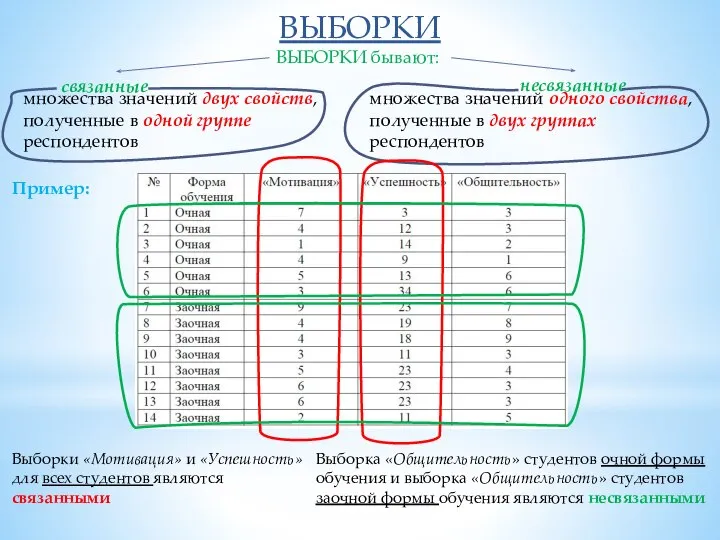
- 6. ВЫБОРКИ ВЫБОРКИ бывают: связанные несвязанные множества значений двух свойств, полученные в одной группе респондентов множества значений
- 7. Принятие решения о Н1 имеет вероятностный характер, поэтому указывается уровень значимости принятия правильного решения о Н1
- 8. ВЕРОЯТНОСТЬ ВЫВОДА Так как сперва проверяется гипотеза Н0, то существует: Вероятность ПРАВИЛЬНО ПРИНЯТЬ Н0 Вероятность ОШИБКИ
- 9. АЛГОРИТМ ПРОВЕРКИ ГИПОТЕЗ Статистические критерии (правила) представлены в форме алгоритма проверки статистических гипотез и содержат таблицы
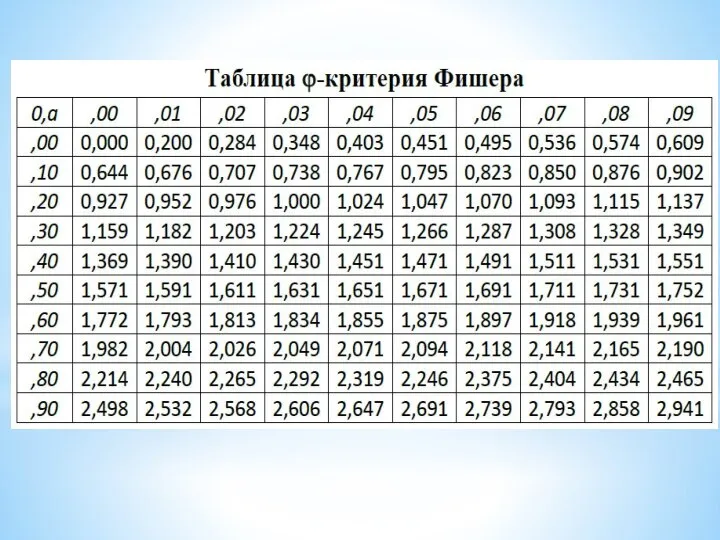
- 10. ϕ-критерий Фишера С помощью ϕ -критерия Фишера устанавливается значимость различия долей выраженности одинакового свойства в двух
- 12. λ-критерий Колмогорова-Смирнова С помощью λ -критерия Колмогорова-Смирнова устанавливается уровень статистической значимости различий распределений частот одинакового свойства
- 13. G-критерий знаков С помощью G-критерия знаков устанавливается уровень статистической значимости различий свойства А и свойства В
- 14. Таблица G-критерия знаков
- 15. U-критерий Манна-Уитни С помощью U-критерия Манна-Уитни устанавливается уровень статистической значимости различий одного свойства у респондентов двух
- 18. Корреляция Корреляция (англ. correlation) – взаимосвязь, соответствие, взаимозависимость, связь. Математическим методом выявления силы связей свойств является
- 19. Корреляция Для определения уровня значимости связи переменных используется таблица критических значений коэффициентов корреляции Таблица r-критерия Спирмена
- 20. r-критерий Спирмена r-критерий Спирмена является критерием ранговой корреляции, который применяется для переменных (свойств), измеренных, как правило,
- 21. r-критерий Пирсона r-критерий Пирсона является критерием линейной корреляции, который применяется для переменных (свойств), измеренных в шкале
- 22. Z-критерий Фишера Z-критерий Фишера является критерием, который применяется для сравнения коэффициентов корреляции двух переменных (свойств), полученных
- 23. ЗАДАНИЯ 1. Найдите моду выборок по таблицам распределения частот: 2. В таблице представлено распределение частот оценок
- 24. ЗАДАНИЯ 4. Сформулируйте статистические гипотезы Н0 и Н1 о различиях выборок школьников: а) оценок по математике
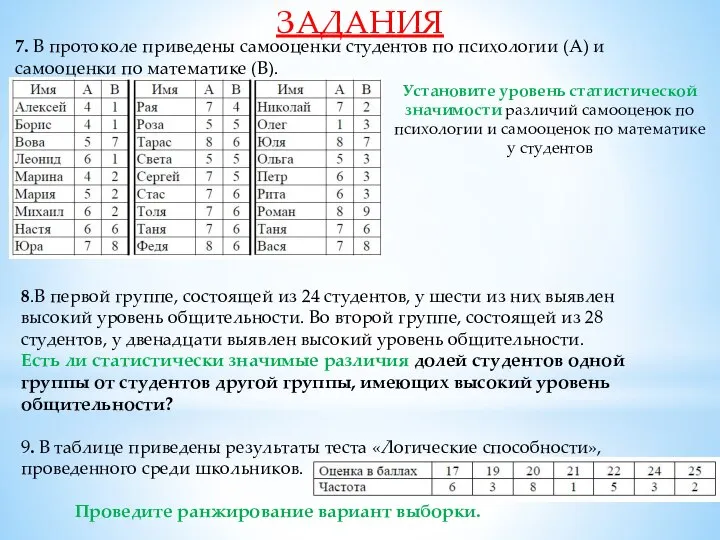
- 25. ЗАДАНИЯ 7. В протоколе приведены самооценки студентов по психологии (А) и самооценки по математике (В). Установите
- 27. Скачать презентацию
Слайд 2МОДА
Мода выборки– это статистика (число) равная варианту выборки,
частота которой наибольшая.
Выборку, в
МОДА
Мода выборки– это статистика (число) равная варианту выборки,
частота которой наибольшая.
Выборку, в
Слайд 3СРЕДНЕЕ
Среднее выборки (m)– это статистика (число) равная отношению суммы
всех значений варианты
СРЕДНЕЕ
Среднее выборки (m)– это статистика (число) равная отношению суммы
всех значений варианты

Слайд 4САНДАРТНОЕ ОТКЛОНЕНИЕ
Стандартное отклонение (s)– это статистика (число) обозначающая
стандартный диапазон изменчивости (рассеяния)
САНДАРТНОЕ ОТКЛОНЕНИЕ
Стандартное отклонение (s)– это статистика (число) обозначающая
стандартный диапазон изменчивости (рассеяния)

Слайд 5Статистический вывод
Статистический критерий — строгое математическое ПРАВИЛО, по которому
принимается или отвергается та
Статистический вывод
Статистический критерий — строгое математическое ПРАВИЛО, по которому
принимается или отвергается та

Слайд 6ВЫБОРКИ
ВЫБОРКИ бывают:
связанные
несвязанные
множества значений двух свойств,
полученные в одной группе
респондентов
множества значений одного свойства,
полученные
ВЫБОРКИ
ВЫБОРКИ бывают:
связанные
несвязанные
множества значений двух свойств,
полученные в одной группе
респондентов
множества значений одного свойства,
полученные
Слайд 7Принятие решения о Н1 имеет вероятностный характер, поэтому указывается уровень значимости принятия
Принятие решения о Н1 имеет вероятностный характер, поэтому указывается уровень значимости принятия
Слайд 8ВЕРОЯТНОСТЬ ВЫВОДА
Так как сперва проверяется гипотеза Н0, то существует:
Вероятность
ПРАВИЛЬНО ПРИНЯТЬ Н0
Вероятность
ОШИБКИ
ВЕРОЯТНОСТЬ ВЫВОДА
Так как сперва проверяется гипотеза Н0, то существует:
Вероятность
ПРАВИЛЬНО ПРИНЯТЬ Н0
Вероятность
ОШИБКИ

Слайд 9АЛГОРИТМ ПРОВЕРКИ ГИПОТЕЗ
Статистические критерии (правила) представлены в форме алгоритма проверки статистических гипотез
АЛГОРИТМ ПРОВЕРКИ ГИПОТЕЗ
Статистические критерии (правила) представлены в форме алгоритма проверки статистических гипотез

Слайд 10ϕ-критерий Фишера
С помощью ϕ -критерия Фишера устанавливается значимость различия долей выраженности одинакового
ϕ-критерий Фишера
С помощью ϕ -критерия Фишера устанавливается значимость различия долей выраженности одинакового

Слайд 12λ-критерий Колмогорова-Смирнова
С помощью λ -критерия Колмогорова-Смирнова устанавливается уровень статистической значимости различий распределений
λ-критерий Колмогорова-Смирнова
С помощью λ -критерия Колмогорова-Смирнова устанавливается уровень статистической значимости различий распределений

Слайд 13G-критерий знаков
С помощью G-критерия знаков устанавливается уровень статистической значимости различий свойства А
G-критерий знаков
С помощью G-критерия знаков устанавливается уровень статистической значимости различий свойства А

Слайд 14Таблица G-критерия знаков
Таблица G-критерия знаков
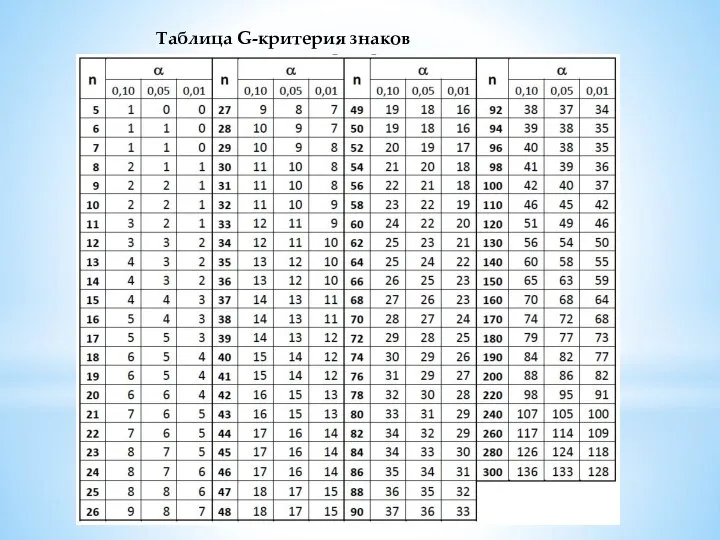
Слайд 15U-критерий Манна-Уитни
С помощью U-критерия Манна-Уитни устанавливается уровень статистической значимости различий одного свойства
U-критерий Манна-Уитни
С помощью U-критерия Манна-Уитни устанавливается уровень статистической значимости различий одного свойства

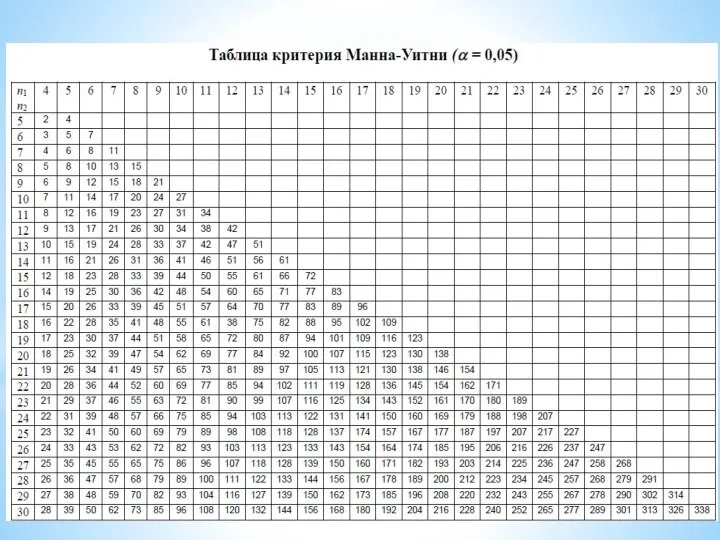
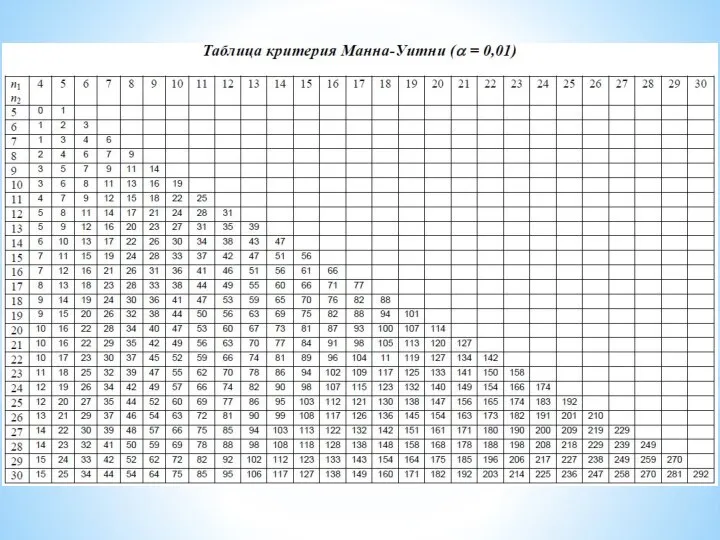
Слайд 18Корреляция
Корреляция (англ. correlation) – взаимосвязь, соответствие, взаимозависимость, связь.
Математическим методом выявления силы связей
Корреляция
Корреляция (англ. correlation) – взаимосвязь, соответствие, взаимозависимость, связь.
Математическим методом выявления силы связей

Слайд 19Корреляция
Для определения уровня значимости связи переменных используется
таблица критических значений коэффициентов корреляции
Таблица r-критерия
Корреляция
Для определения уровня значимости связи переменных используется
таблица критических значений коэффициентов корреляции
Таблица r-критерия

Слайд 20r-критерий Спирмена
r-критерий Спирмена является критерием ранговой корреляции, который применяется для переменных (свойств),
r-критерий Спирмена
r-критерий Спирмена является критерием ранговой корреляции, который применяется для переменных (свойств),

Слайд 21r-критерий Пирсона
r-критерий Пирсона является критерием линейной корреляции, который применяется для переменных (свойств),
r-критерий Пирсона
r-критерий Пирсона является критерием линейной корреляции, который применяется для переменных (свойств),

Слайд 22Z-критерий Фишера
Z-критерий Фишера является критерием, который применяется для сравнения коэффициентов корреляции двух
Z-критерий Фишера
Z-критерий Фишера является критерием, который применяется для сравнения коэффициентов корреляции двух

Слайд 23ЗАДАНИЯ
1. Найдите моду выборок по таблицам распределения частот:
2. В таблице представлено
ЗАДАНИЯ
1. Найдите моду выборок по таблицам распределения частот:
2. В таблице представлено
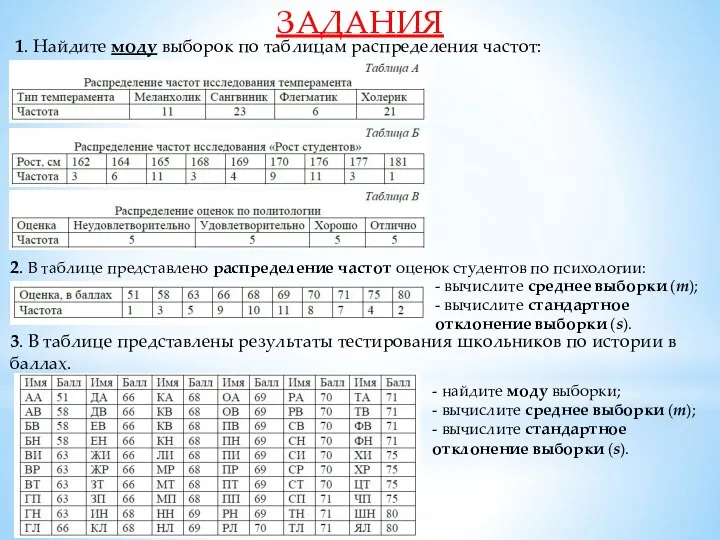
Слайд 24ЗАДАНИЯ
4. Сформулируйте статистические гипотезы Н0 и Н1 о различиях выборок школьников:
а) оценок
ЗАДАНИЯ
4. Сформулируйте статистические гипотезы Н0 и Н1 о различиях выборок школьников:
а) оценок

Слайд 25ЗАДАНИЯ
7. В протоколе приведены самооценки студентов по психологии (А) и самооценки по
ЗАДАНИЯ
7. В протоколе приведены самооценки студентов по психологии (А) и самооценки по
 Умножение трёхзначного числа на однозначное
Умножение трёхзначного числа на однозначное Пособие для самостоятельного обучения учащихся 5-6 классов. Проценты. Основные задачи на проценты
Пособие для самостоятельного обучения учащихся 5-6 классов. Проценты. Основные задачи на проценты Презентация на тему Старинные меры длины
Презентация на тему Старинные меры длины  Физическо-математический морской бой
Физическо-математический морской бой Топологические опыты. Мини-урок
Топологические опыты. Мини-урок Работу выполнила: Ученица 5б класса Беляева Александра Учитель: Сахокия Д.А.
Работу выполнила: Ученица 5б класса Беляева Александра Учитель: Сахокия Д.А. Регрессионный анализ
Регрессионный анализ Подмножество. Операции над множествами. Самостоятельная работа
Подмножество. Операции над множествами. Самостоятельная работа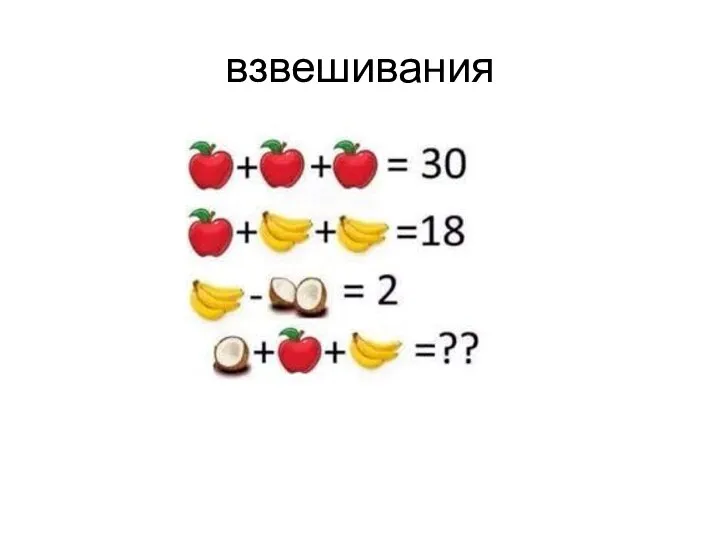 Взвешивания. Домашнее задание 1 класс
Взвешивания. Домашнее задание 1 класс Использование логических операций в теории множеств. Инверсия
Использование логических операций в теории множеств. Инверсия Решение прикладных задач с помощью свойств квадратичной функции
Решение прикладных задач с помощью свойств квадратичной функции Математика. Основные понятия математики
Математика. Основные понятия математики Системы линейных уравнений
Системы линейных уравнений Распознавание графиков функций
Распознавание графиков функций Тест по математике: меры времени (выражение в крупных мерах)
Тест по математике: меры времени (выражение в крупных мерах) Research Topics for Mathematics II
Research Topics for Mathematics II Симметрия и асимметрия
Симметрия и асимметрия Материальная точка. Система отсчета
Материальная точка. Система отсчета Конкурс А ну-ка, математики!
Конкурс А ну-ка, математики! Скользящее среднее
Скользящее среднее Круг. Окружность
Круг. Окружность Множество. Элемент множества
Множество. Элемент множества Функциональная грамотность на уроках математики начальных классов
Функциональная грамотность на уроках математики начальных классов Треугольник. Первый признак равенства треугольников
Треугольник. Первый признак равенства треугольников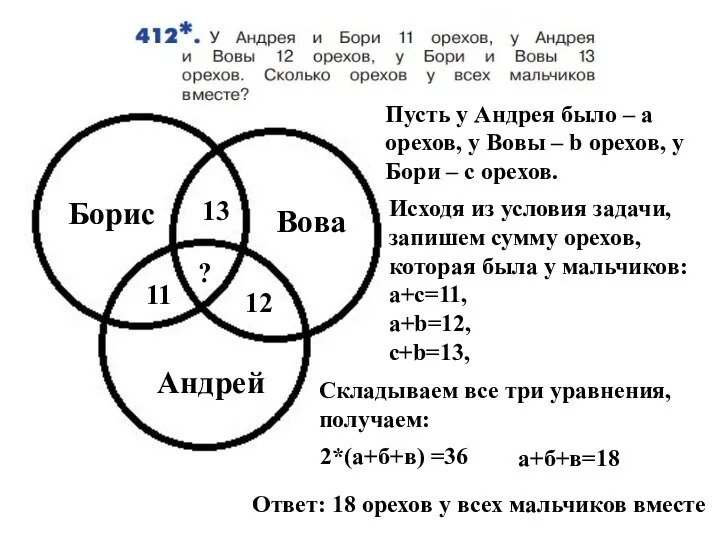 Уравнения. Задача
Уравнения. Задача Свойства ранга матрицы
Свойства ранга матрицы Вычисление углов
Вычисление углов Построение графика функции
Построение графика функции