- Основы математической статистики. Регрессионный и корреляционный анализы

Содержание
- 2. Основы математической статистики Большой раздел современной матема-тической статистики — статистический последовательный анализ, фундаментальный вклад в создание
- 3. Выборочный метод Выборочный метод заключается в том, что из общей совокупности объектов, называемых генеральной совокупностью, извлекают
- 4. Пример использования «выборочного метода» - расчёт потерь Пример. Как правило, после расчёта потерь электроэнергии в сетях
- 5. Доверительные интервалы Доверительный интервал – термин, используемый в математической статистике при интервальной оценке статистических параметров, более
- 6. Доверительные интервалы
- 7. Пример использования – планирование расхода тепловой энергии на основе прогноза температуры воздуха Расход тепловой энергии для
- 8. Проверка статистических гипотез Проверка статистических гипотез является содержанием одного из обширных классов задач математической статистики. Статистическая
- 9. Проверка статистических гипотез Метод проверки статистической гипотезы состоит в следующем. Производится выборка, на основе которой вычисляется
- 10. Проверка статистических гипотез Критерии значимости - проверка гипотез о нормальности выборки Критерий Шапира-Уилка Критерий хи-квадрат Пирсона
- 11. Пример использования – Бомбардировка Лондона Пример. Задача о бомбардировках Лондона. Задача возникла в связи с бомбардировками
- 12. Пример использования – Бомбардировка Лондона Как видно из графика распределение сброшенных на Лондон бомб далеко от
- 13. Гипотеза H0: стрельба случайна (нет "целевых" участков). Закон редких событий (распределение Пуассона) Тогда при уровне значимости
- 14. Отсев грубых ошибок Исходные данные, получаемые в результате экспериментов, в силу разных причин, могут содержать грубые
- 15. Пример. Имеются данные потребления электроэнергии в жилой квартире в период с января по ноябрь. Необходимо установить
- 16. Пример использования – Достоверизация телеизмерений мощности Имея выборку, состоящую из телеизмерений (ТИ) перетока мощности по данным
- 17. Пример использования – Достоверизация телеизмерений мощности Выходная форма контроля достоверности измерений перетоков мощности. Подобный метод достове-ризации
- 18. Регрессионный анализ Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными. Различают два вида взаимосвязи:
- 19. Регрессионный анализ Термин "регрессия" был введён Фрэнсисом Гальтоном в конце 19-го века. Гальтон обнаружил, что дети
- 20. Регрессионный анализ Регрессия — зависимость математического ожидания (например, среднего значения) случайной величины от одной или нескольких
- 21. Регрессионный анализ
- 22. Регрессионный анализ Линейная регрессия Нелинейная регрессия
- 23. Регрессионный анализ Решение задачи регрессионного анализа целесообразно разбить на несколько этапов: предварительная обработка данных; выбор вида
- 24. Регрессионный анализ Уравнение регрессии в регрессионном анализе следует трактовать как векторное, ибо речь идет о матрице
- 25. Регрессионный анализ – метод наименьших квадратов
- 26. Регрессионный анализ – метод наименьших квадратов В основе МНК лежат следующие положения: значения величин ошибок и
- 27. Регрессионный анализ Качество полученного уравнения регрессии оценивают по степени близости между результатами наблюдений за показателем и
- 28. Традиционный подход к предсказанию выработки мощности ВЭУ с использованием регрессионных моделей АРПСС заключается в прогнозировании следующего
- 29. Пример использования – Моделирование распределение температуры оборудования от параметров работы электровозов при их движении Тепловой нагрев
- 30. Пример использования – Моделирование распределение температуры оборудования от параметров работы электровозов при их движении Установлено, что
- 31. Корреляционный анализ Для управления сложными системами, на которые воздействует множество факторов, необходимо иметь представление о факторах,
- 32. Корреляционный анализ Употребляется в науке с конца XYIII века. Его ввел французский палеонтолог Жорж Кювье, основавший
- 33. Корреляционный анализ Корреляция - это статистическая зависимость между случайными величинами, не имеющая строго функционального характера, при
- 34. Корреляционный анализ – основная идея Идея сопоставления колебаний значений признака относительно друг друга Если численные значения
- 35. Корреляционный связь Характеризует сложный механизм взаимодействия двух или нескольких признаков При котором при изменении одного признака
- 36. Коэффициент корреляции Пирсона Предполагает, что: обе переменные распределены нормально связь линейна Коэффициент корреляции Пирсона основан на
- 37. Корреляционный анализ при r > 0,85 (при этом варьирование признаков взаимосвязано приблизительно на 75% и более)
- 38. Коэффициент Спирмена Не предполагает, что данные распределены каким-то особым образом Вместо исходных значений использует их ранги
- 39. Оценка значимости корреляции Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается от нуля. Но
- 40. Оценка значимости корреляции Для проверки гипотезы о значимости коэффициента корреляции используется критерий Стьюдента в виде: В
- 41. Расчёт коэффициента Пирсона в R Пример. Даны выборки данных по техническим и коммерческим потерям электроэнергии в
- 42. Расчёт коэффициента Пирсона в R #корреляционный анализ Pearson's product-moment correlation data: loss$techloss and loss$steal t =
- 43. Связь между потерями нелинейна (на исходной шкале)
- 44. Ни одна из переменных не распределена нормально Shapiro-Wilk normality test data: loss$techloss W = 0.95535, p-value
- 46. Скачать презентацию
Слайд 2Основы математической статистики
Большой раздел современной матема-тической статистики — статистический последовательный анализ, фундаментальный
Основы математической статистики
Большой раздел современной матема-тической статистики — статистический последовательный анализ, фундаментальный

Слайд 3Выборочный метод
Выборочный метод заключается в том, что из общей совокупности объектов, называемых
Выборочный метод
Выборочный метод заключается в том, что из общей совокупности объектов, называемых

Слайд 4Пример использования
«выборочного метода» - расчёт потерь
Пример.
Как правило, после расчёта потерь
Пример использования
«выборочного метода» - расчёт потерь
Пример.
Как правило, после расчёта потерь

Слайд 5Доверительные интервалы
Доверительный интервал – термин, используемый в математической статистике при интервальной оценке
Доверительные интервалы
Доверительный интервал – термин, используемый в математической статистике при интервальной оценке

Слайд 6Доверительные интервалы
Доверительные интервалы

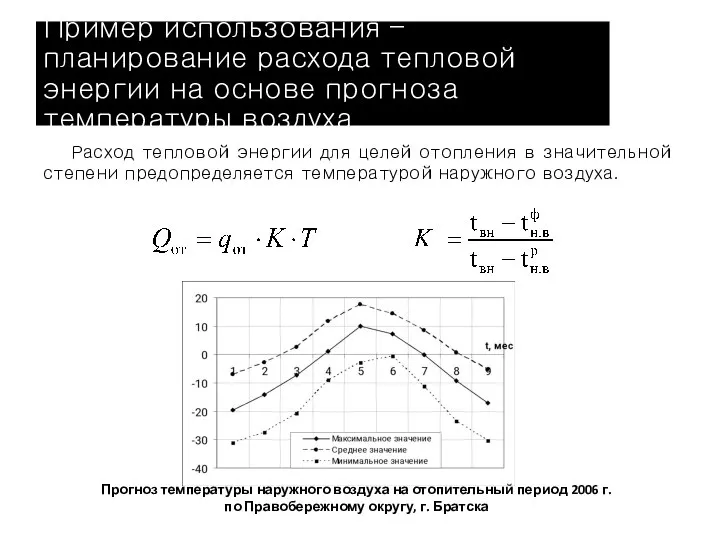
Слайд 7Пример использования – планирование расхода тепловой энергии на основе прогноза температуры воздуха
Расход
Пример использования – планирование расхода тепловой энергии на основе прогноза температуры воздуха
Расход
Слайд 8Проверка статистических гипотез
Проверка статистических гипотез является содержанием одного из обширных классов
Проверка статистических гипотез
Проверка статистических гипотез является содержанием одного из обширных классов

Слайд 9Проверка статистических гипотез
Метод проверки статистической гипотезы состоит в следующем.
Производится выборка, на
Проверка статистических гипотез
Метод проверки статистической гипотезы состоит в следующем.
Производится выборка, на

Слайд 10Проверка статистических гипотез
Критерии значимости - проверка гипотез о нормальности выборки
Критерий Шапира-Уилка
Критерий
Проверка статистических гипотез
Критерии значимости - проверка гипотез о нормальности выборки
Критерий Шапира-Уилка
Критерий

Слайд 11Пример использования –
Бомбардировка Лондона
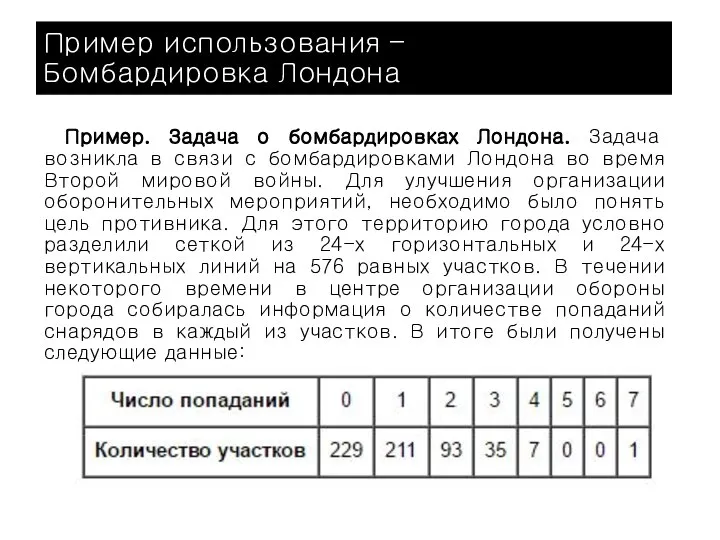
Пример. Задача о бомбардировках Лондона. Задача возникла в
Пример использования –
Бомбардировка Лондона
Пример. Задача о бомбардировках Лондона. Задача возникла в
Слайд 12Пример использования –
Бомбардировка Лондона
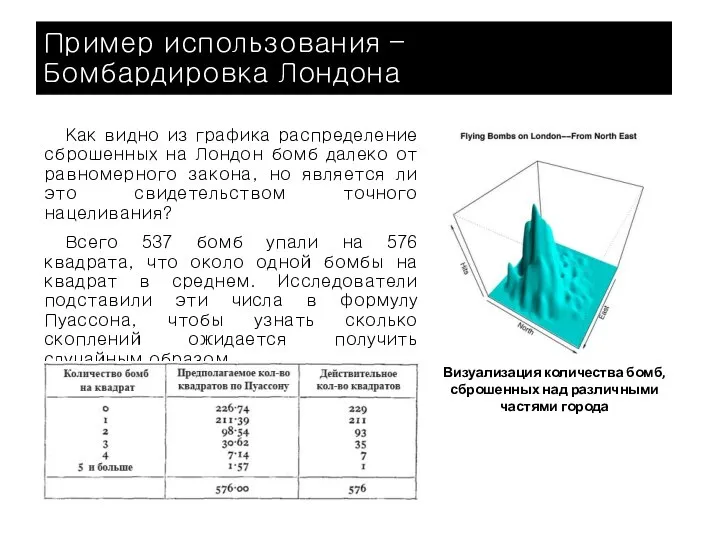
Как видно из графика распределение сброшенных на Лондон
Пример использования –
Бомбардировка Лондона
Как видно из графика распределение сброшенных на Лондон
Слайд 13Гипотеза H0: стрельба случайна (нет "целевых" участков).
Закон редких событий (распределение Пуассона)
Тогда при
Гипотеза H0: стрельба случайна (нет "целевых" участков).
Закон редких событий (распределение Пуассона)
Тогда при

Слайд 14Отсев грубых ошибок
Исходные данные, получаемые в результате экспериментов, в силу разных причин,
Отсев грубых ошибок
Исходные данные, получаемые в результате экспериментов, в силу разных причин,

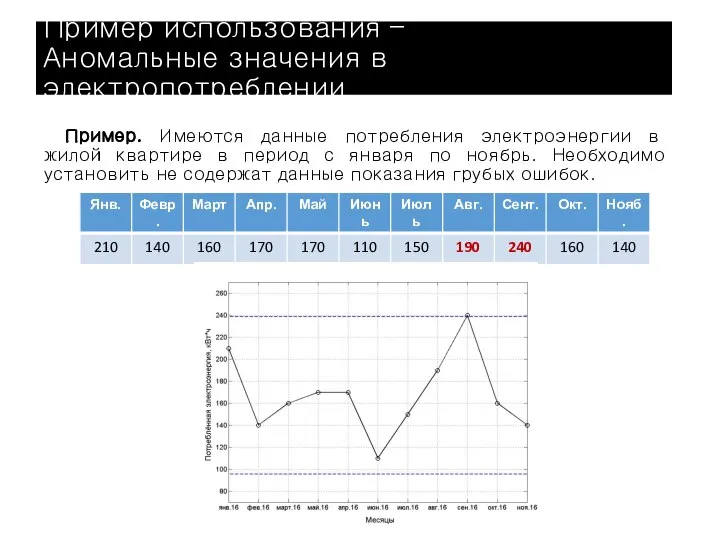
Слайд 15Пример. Имеются данные потребления электроэнергии в жилой квартире в период с января
Пример. Имеются данные потребления электроэнергии в жилой квартире в период с января
Слайд 16Пример использования –
Достоверизация телеизмерений мощности
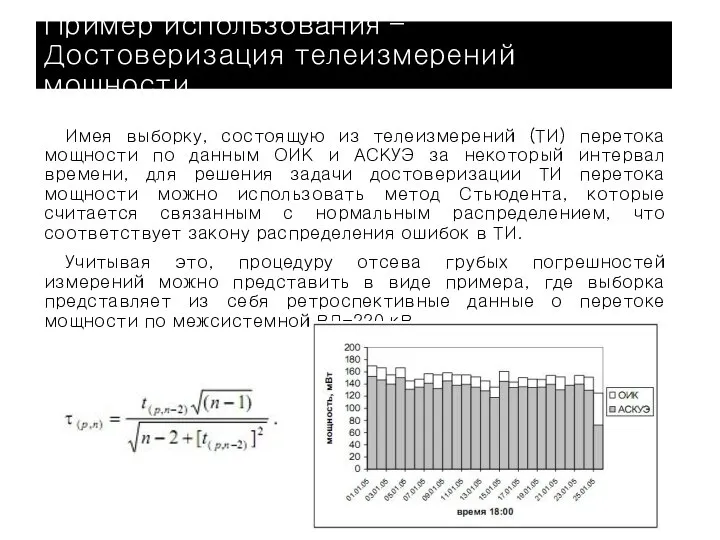
Имея выборку, состоящую из телеизмерений (ТИ) перетока
Пример использования –
Достоверизация телеизмерений мощности
Имея выборку, состоящую из телеизмерений (ТИ) перетока
Слайд 17Пример использования –
Достоверизация телеизмерений мощности
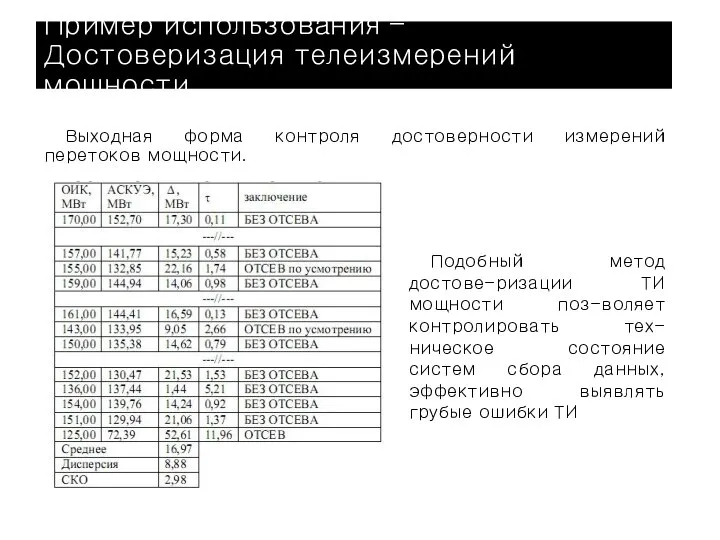
Выходная форма контроля достоверности измерений перетоков мощности.
Пример использования –
Достоверизация телеизмерений мощности
Выходная форма контроля достоверности измерений перетоков мощности.
Слайд 18Регрессионный анализ
Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными.
Регрессионный анализ
Величины, характеризующие различные свойства объектов, могут быть независимыми или взаимосвязанными.

Слайд 19Регрессионный анализ
Термин "регрессия" был введён Фрэнсисом Гальтоном в конце 19-го века.
Регрессионный анализ
Термин "регрессия" был введён Фрэнсисом Гальтоном в конце 19-го века.

Слайд 20Регрессионный анализ
Регрессия — зависимость математического ожидания (например, среднего значения) случайной величины
Регрессионный анализ
Регрессия — зависимость математического ожидания (например, среднего значения) случайной величины

Слайд 21Регрессионный анализ
Регрессионный анализ

Слайд 22Регрессионный анализ
Линейная регрессия
Нелинейная регрессия
Регрессионный анализ
Линейная регрессия
Нелинейная регрессия
Слайд 23Регрессионный анализ
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
предварительная обработка
Регрессионный анализ
Решение задачи регрессионного анализа целесообразно разбить на несколько этапов:
предварительная обработка

Слайд 24Регрессионный анализ
Уравнение регрессии в регрессионном анализе следует трактовать как векторное, ибо
Регрессионный анализ
Уравнение регрессии в регрессионном анализе следует трактовать как векторное, ибо

Слайд 25Регрессионный анализ – метод наименьших квадратов
Регрессионный анализ – метод наименьших квадратов

Слайд 26Регрессионный анализ – метод наименьших квадратов
В основе МНК лежат следующие положения:
значения
Регрессионный анализ – метод наименьших квадратов
В основе МНК лежат следующие положения:
значения

Слайд 27Регрессионный анализ
Качество полученного уравнения регрессии оценивают по степени близости между результатами
Регрессионный анализ
Качество полученного уравнения регрессии оценивают по степени близости между результатами

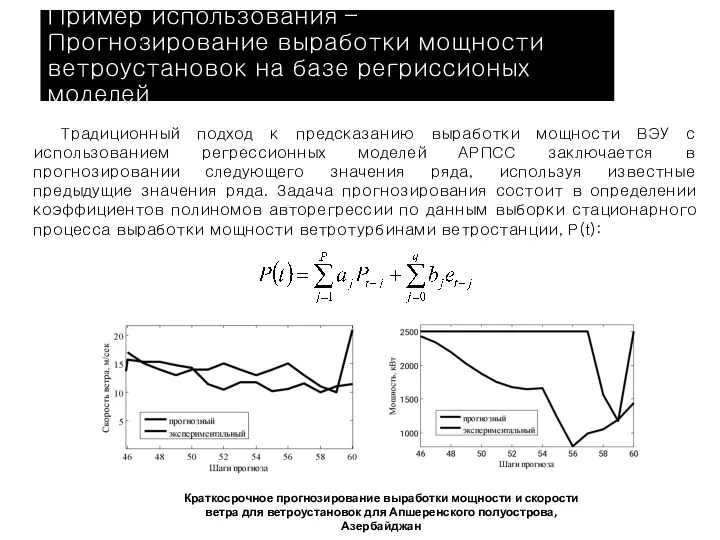
Слайд 28Традиционный подход к предсказанию выработки мощности ВЭУ с использованием регрессионных моделей АРПСС
Традиционный подход к предсказанию выработки мощности ВЭУ с использованием регрессионных моделей АРПСС
Слайд 29Пример использования –
Моделирование распределение температуры оборудования от параметров работы электровозов при
Пример использования – Моделирование распределение температуры оборудования от параметров работы электровозов при

Слайд 30Пример использования –
Моделирование распределение температуры оборудования от параметров работы электровозов при
Пример использования – Моделирование распределение температуры оборудования от параметров работы электровозов при

Слайд 31Корреляционный анализ
Для управления сложными системами, на которые воздействует множество факторов, необходимо
Корреляционный анализ
Для управления сложными системами, на которые воздействует множество факторов, необходимо

Слайд 32Корреляционный анализ
Употребляется в науке с конца XYIII века. Его ввел французский
Корреляционный анализ
Употребляется в науке с конца XYIII века. Его ввел французский

Слайд 33Корреляционный анализ
Корреляция - это статистическая зависимость между случайными величинами, не имеющая
Корреляционный анализ
Корреляция - это статистическая зависимость между случайными величинами, не имеющая

Слайд 34Корреляционный анализ – основная идея
Идея сопоставления колебаний значений признака относительно друг
Корреляционный анализ – основная идея
Идея сопоставления колебаний значений признака относительно друг

Слайд 35Корреляционный связь
Характеризует сложный механизм взаимодействия двух или нескольких признаков
При котором при изменении
Корреляционный связь
Характеризует сложный механизм взаимодействия двух или нескольких признаков
При котором при изменении

Слайд 36Коэффициент корреляции Пирсона
Предполагает, что:
обе переменные распределены нормально
связь линейна
Коэффициент корреляции Пирсона основан на
Коэффициент корреляции Пирсона
Предполагает, что:
обе переменные распределены нормально
связь линейна
Коэффициент корреляции Пирсона основан на

Слайд 37Корреляционный анализ
при r > 0,85 (при этом варьирование признаков взаимосвязано приблизительно
Корреляционный анализ
при r > 0,85 (при этом варьирование признаков взаимосвязано приблизительно

Слайд 38Коэффициент Спирмена
Не предполагает, что данные распределены каким-то особым образом
Вместо исходных значений использует
Коэффициент Спирмена
Не предполагает, что данные распределены каким-то особым образом
Вместо исходных значений использует

Слайд 39Оценка значимости корреляции
Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается
Оценка значимости корреляции
Оценка коэффициента корреляции, вычисленная по ограниченной выборке, практически всегда отличается

Слайд 40Оценка значимости корреляции
Для проверки гипотезы о значимости коэффициента корреляции используется критерий Стьюдента
Оценка значимости корреляции
Для проверки гипотезы о значимости коэффициента корреляции используется критерий Стьюдента

Слайд 41Расчёт коэффициента Пирсона в R
Пример. Даны выборки данных по техническим и коммерческим
Расчёт коэффициента Пирсона в R
Пример. Даны выборки данных по техническим и коммерческим
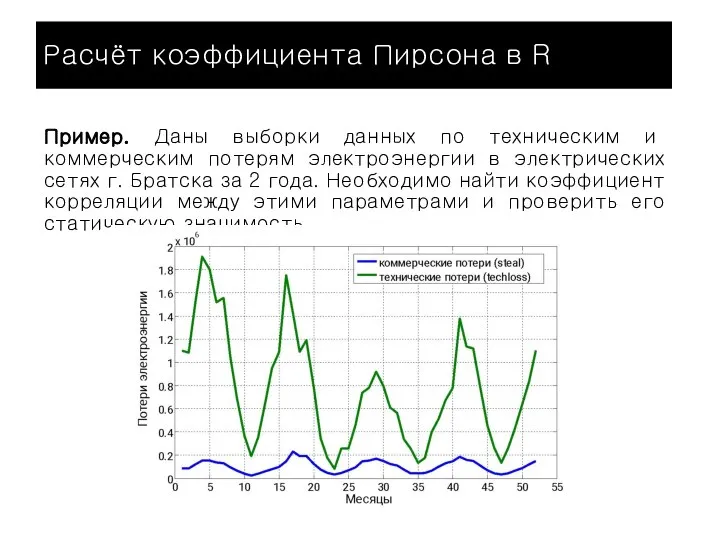
Слайд 42Расчёт коэффициента Пирсона в R
< loss <- read.csv ("loss.csv", sep = ";",
Расчёт коэффициента Пирсона в R
< loss <- read.csv ("loss.csv", sep = ";",

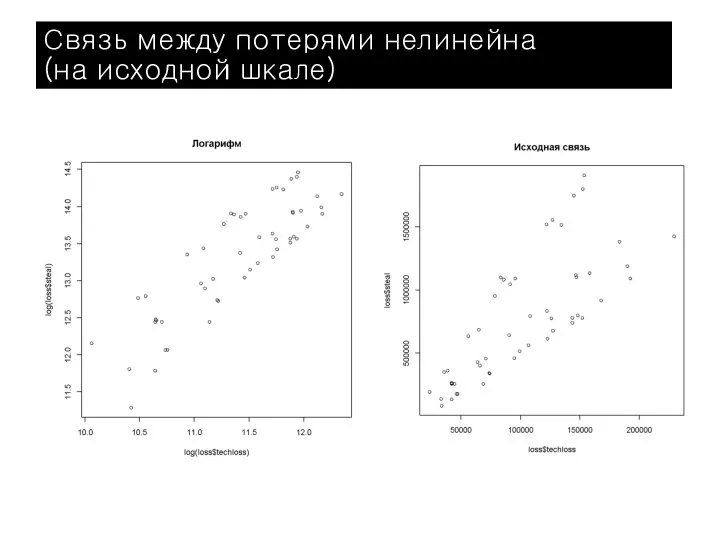
Слайд 43Связь между потерями нелинейна
(на исходной шкале)
Связь между потерями нелинейна
(на исходной шкале)
Слайд 44Ни одна из переменных не распределена нормально
Shapiro-Wilk normality test
data: loss$techloss
W =
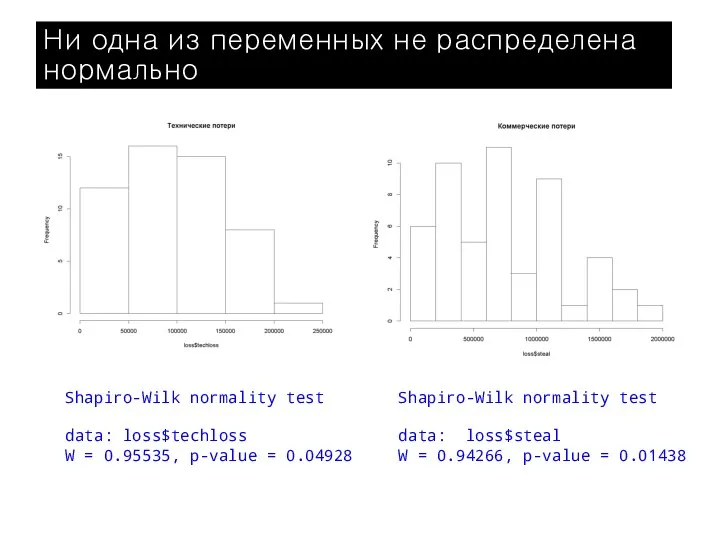
Ни одна из переменных не распределена нормально
Shapiro-Wilk normality test
data: loss$techloss
W =
 Сложение и вычитание в пределах 10. 1 класс
Сложение и вычитание в пределах 10. 1 класс Презентация на тему Решение задач на применение свойств подобия
Презентация на тему Решение задач на применение свойств подобия  Собираем ягоды. Математика 1 класс. Итоговое повторение. Тренажёр
Собираем ягоды. Математика 1 класс. Итоговое повторение. Тренажёр Соотношения между сторонами и углами треугольника. Подготовка к контрольной работе
Соотношения между сторонами и углами треугольника. Подготовка к контрольной работе Параллелограмм. Свойства параллелограмма. Трапеция
Параллелограмм. Свойства параллелограмма. Трапеция Презентация на тему Определение арифметической прогрессии (9 класс)
Презентация на тему Определение арифметической прогрессии (9 класс)  Векторная алгебра
Векторная алгебра Нормальное распределения случайной величины. Функция Лапласа
Нормальное распределения случайной величины. Функция Лапласа Исследование функций с помощью производных. Правила Лопиталя
Исследование функций с помощью производных. Правила Лопиталя Прямая и плоскость в пространстве
Прямая и плоскость в пространстве Векторы в пространстве
Векторы в пространстве Презентация на тему Перпендикулярные прямые (7 класс)
Презентация на тему Перпендикулярные прямые (7 класс)  Показательная функция
Показательная функция Наивероятнейшее число наступления события в схеме Бернулли
Наивероятнейшее число наступления события в схеме Бернулли Розв'язання задач
Розв'язання задач Прибавление и вычитание числа 3. Помоги белочке
Прибавление и вычитание числа 3. Помоги белочке Теорема косинусов
Теорема косинусов Теорема Пифагора
Теорема Пифагора Логарифмические уравнения
Логарифмические уравнения Решение задач на проценты
Решение задач на проценты Координати вектора. Модуль вектора
Координати вектора. Модуль вектора Деление с остатком
Деление с остатком Сравнение двух прогрессий
Сравнение двух прогрессий Прогрессии. Основные формулы арифметической прогрессии
Прогрессии. Основные формулы арифметической прогрессии Степень с целым показателем. Блиц-опрос
Степень с целым показателем. Блиц-опрос Сравнение групп предметов. Свойства предметов (1 класс)
Сравнение групп предметов. Свойства предметов (1 класс) Сравнение дробей
Сравнение дробей Площади. Объёмы
Площади. Объёмы