- Статистика. Тренды

Содержание
- 2. Тренды Тренд (от англ. trend — тенденция) — это долговременная тенденция изменения исследуемого временного ряда. Тренды
- 3. Анализ ряда данных Для анализа тренда необходимо разложить временные ряды на сумму регулярной составляющей (тренда) и
- 4. Анализ ряда данных (продолжение) Для анализа тренда временных рядов необходимо выполнить следующие шаги: Шаг 1. Обнаружение
- 5. Тест Манна-Кендалла Непараметрический тест для определения наличия монотонной, статистически значимой тенденции. Для многолетних рядов данных без
- 6. S-статистика Теста Манна-Кендалла Если временной ряд состоит из 9 или менее значений то результаты расчета по
- 7. Аппроксимационный тест (Z- статистика) Теста Манна-Кендалла Для временного ряда из 10 и более значений. Для проведения
- 8. Метод Сенса Использует линейную модель для оцени наклона тренда (т.е. в случаях, если предполагается что тренд
- 10. Анализ ряда данных с явно выраженной сезонной составляющей (один из методов) Тренд (Tt) можно разложить на
- 11. Количество гармоник можно рассчитать с использованием F-статистики. Для анализа содержания ТМ и СОЗ оптимальным считается 2
- 12. Пример Количественной оценки тренда total reduction: Rtot = (Cbeg – Cend) / Cbeg = 1 –
- 13. Нормальное (Гаусса) распределение это функция, которая описывает тенденцию высокой концентрации значений около центра Кривая Гаусса по
- 14. Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации,
- 15. Правило трёх сигм Вероятность того, что случайная величина отклонится от своего математического ожидания на большую величину,
- 16. Логнормальное распределение случайная величина X имеет логнормальное распределение с параметрами μ, σ, если X = exp(Y),
- 17. Оценка показателя повторяемости методики анализа Рассчитывают среднее арифметическое и выборочную дисперсию результатов единичного анализа содержания компонента,
- 18. Критерий Кохрена Рассчитывается для выборки и сравнивается с табличными значениями. Если рассчитанного значение выше табличного, то
- 19. Оценка показателя правильности методики анализа Рассчитывают значение смещения - как разность между средним значением результатов анализа
- 21. Скачать презентацию
Слайд 2Тренды
Тренд (от англ. trend — тенденция) — это долговременная тенденция изменения исследуемого временного ряда.
Тренды
Тренд (от англ. trend — тенденция) — это долговременная тенденция изменения исследуемого временного ряда.

Слайд 3Анализ ряда данных
Для анализа тренда необходимо разложить временные ряды на сумму регулярной
Анализ ряда данных
Для анализа тренда необходимо разложить временные ряды на сумму регулярной
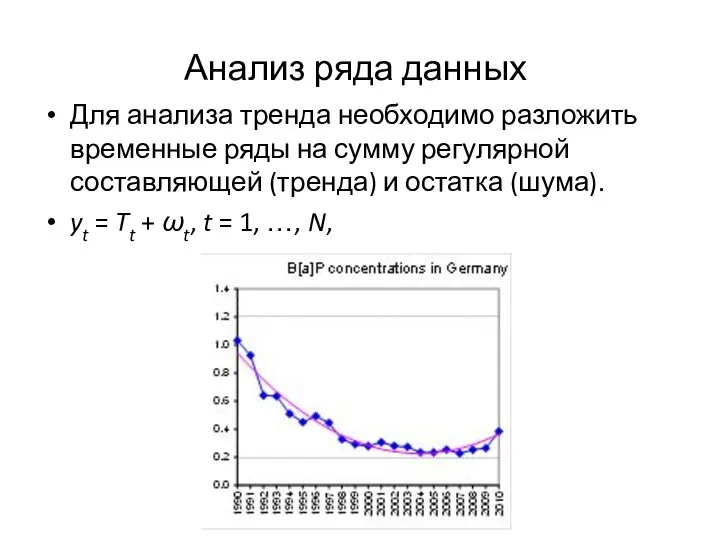
Слайд 4Анализ ряда данных (продолжение)
Для анализа тренда временных рядов необходимо выполнить следующие шаги:
Шаг
Анализ ряда данных (продолжение)
Для анализа тренда временных рядов необходимо выполнить следующие шаги:
Шаг

Слайд 5Тест Манна-Кендалла
Непараметрический тест для определения наличия монотонной, статистически значимой тенденции.
Для многолетних рядов
Тест Манна-Кендалла
Непараметрический тест для определения наличия монотонной, статистически значимой тенденции.
Для многолетних рядов

Слайд 6S-статистика Теста Манна-Кендалла
Если временной ряд состоит из 9 или менее значений то
S-статистика Теста Манна-Кендалла
Если временной ряд состоит из 9 или менее значений то

Слайд 7Аппроксимационный тест (Z- статистика) Теста Манна-Кендалла
Для временного ряда из 10 и более
Аппроксимационный тест (Z- статистика) Теста Манна-Кендалла
Для временного ряда из 10 и более

Слайд 8Метод Сенса
Использует линейную модель для оцени наклона тренда (т.е. в случаях, если
Метод Сенса
Использует линейную модель для оцени наклона тренда (т.е. в случаях, если


Слайд 10Анализ ряда данных с явно выраженной сезонной составляющей (один из методов)
Тренд (Tt)
Анализ ряда данных с явно выраженной сезонной составляющей (один из методов)
Тренд (Tt)

Слайд 11Количество гармоник можно рассчитать с использованием F-статистики. Для анализа содержания ТМ и
Количество гармоник можно рассчитать с использованием F-статистики. Для анализа содержания ТМ и
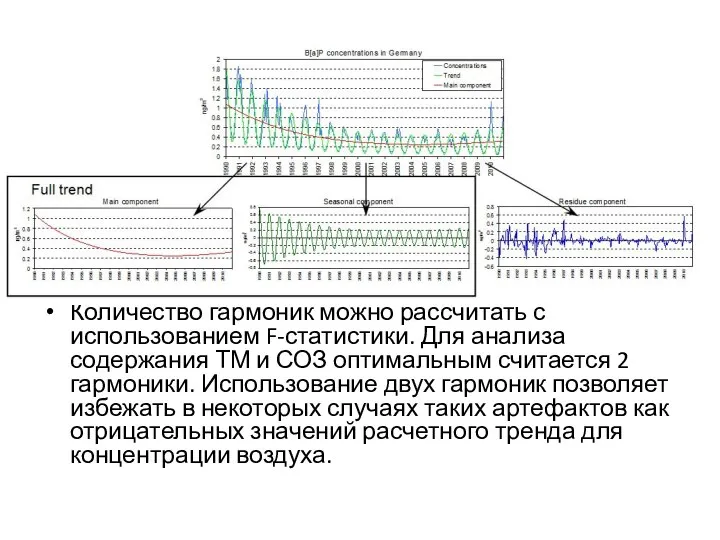
Слайд 12Пример Количественной оценки тренда
total reduction: Rtot = (Cbeg – Cend) / Cbeg =
Пример Количественной оценки тренда
total reduction: Rtot = (Cbeg – Cend) / Cbeg =
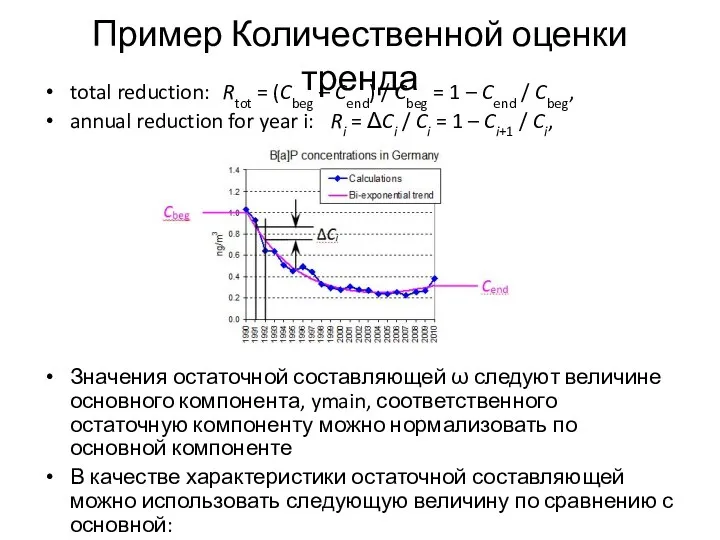
Слайд 13Нормальное (Гаусса) распределение
это функция, которая описывает тенденцию высокой концентрации значений около центра
Кривая
Нормальное (Гаусса) распределение
это функция, которая описывает тенденцию высокой концентрации значений около центра
Кривая
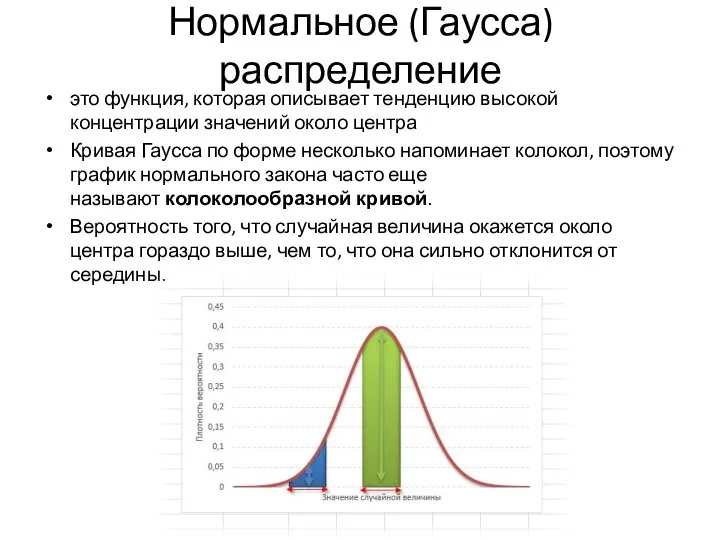
Слайд 14Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации,
Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации,

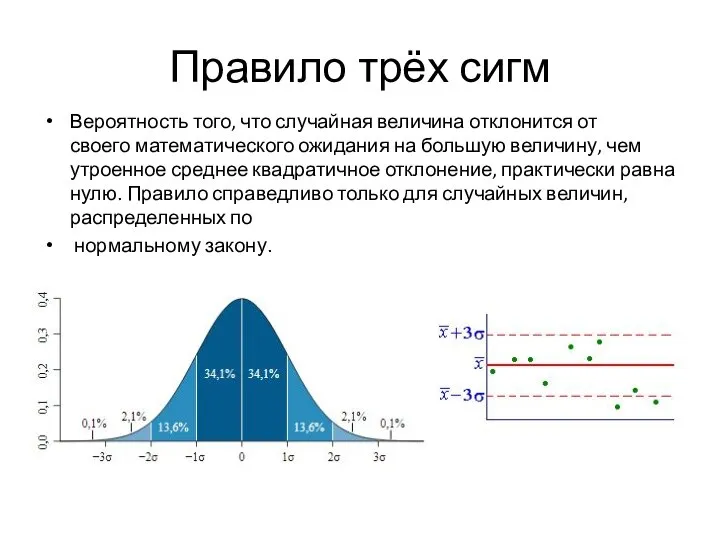
Слайд 15Правило трёх сигм
Вероятность того, что случайная величина отклонится от своего математического ожидания на
Правило трёх сигм
Вероятность того, что случайная величина отклонится от своего математического ожидания на
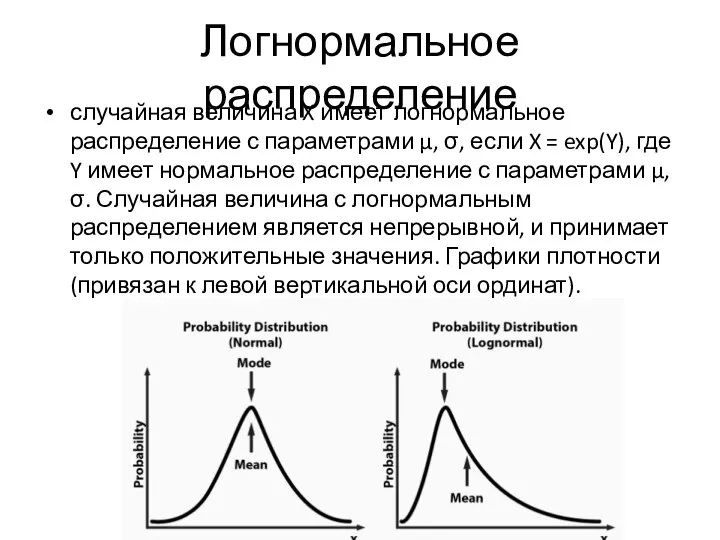
Слайд 16Логнормальное распределение
случайная величина X имеет логнормальное распределение с параметрами μ, σ, если
Логнормальное распределение
случайная величина X имеет логнормальное распределение с параметрами μ, σ, если
Слайд 17Оценка показателя повторяемости методики анализа
Рассчитывают среднее арифметическое и выборочную дисперсию результатов единичного анализа содержания
Оценка показателя повторяемости методики анализа
Рассчитывают среднее арифметическое и выборочную дисперсию результатов единичного анализа содержания

Слайд 18Критерий Кохрена
Рассчитывается для выборки и сравнивается с табличными значениями. Если рассчитанного значение выше
Критерий Кохрена
Рассчитывается для выборки и сравнивается с табличными значениями. Если рассчитанного значение выше

Слайд 19 Оценка показателя правильности методики анализа
Рассчитывают значение смещения - как разность между средним значением
Оценка показателя правильности методики анализа
Рассчитывают значение смещения - как разность между средним значением

 Теорема Тейлора
Теорема Тейлора Параллельность прямых и плоскостей
Параллельность прямых и плоскостей Подобие треугольников
Подобие треугольников Логарифмы. История возникновения логарифмов
Логарифмы. История возникновения логарифмов Математика вокруг нас. Геометрия на столе с ножницами и без
Математика вокруг нас. Геометрия на столе с ножницами и без Сложение и вычитание дробей
Сложение и вычитание дробей Случаи вычитания 11-
Случаи вычитания 11- Идеально сбалансированное дерево. Задание
Идеально сбалансированное дерево. Задание Подобные слагаемые
Подобные слагаемые Человек трудолюбивый – самый счастливый– самый
Человек трудолюбивый – самый счастливый– самый Числовые последовательности
Числовые последовательности Презентация на тему Квадратный сантиметр (3 класс)
Презентация на тему Квадратный сантиметр (3 класс)  Симметрия относительно прямой
Симметрия относительно прямой Своя игра по теме: Сложение и вычитание дробей
Своя игра по теме: Сложение и вычитание дробей Удивительный мир математики
Удивительный мир математики Действительный анализ. Интеграл Римана и критерий Лебега
Действительный анализ. Интеграл Римана и критерий Лебега Матрицы. Основные определения
Матрицы. Основные определения Классическое определение вероятности
Классическое определение вероятности Метод Ньютона
Метод Ньютона Устная работа
Устная работа Задача з піцою
Задача з піцою Делимость, как инвариант
Делимость, как инвариант Логарифмические неравенства
Логарифмические неравенства Задачи на вычисление площадей и объемов тел вращения и многогранников
Задачи на вычисление площадей и объемов тел вращения и многогранников Решение квадратных уравнений
Решение квадратных уравнений Презентация на тему Построение сечений тетраэдра
Презентация на тему Построение сечений тетраэдра  Пирамиды. Объём пирамиды
Пирамиды. Объём пирамиды Решение задач на смеси и сплавы. Основное вещество
Решение задач на смеси и сплавы. Основное вещество