- 2_LEKTsIYa_1

Содержание
- 2. ВОПРОСЫ
- 10. ОРГАНИЗАЦИЯ ДАННЫХ
- 18. ИЗМЕНЕНИЕ ЗНАЧЕНИЙ ДАННЫХ
- 25. ОПИСАТЕЛЬНАЯ СТАТИСТИКА ДЛЯ КАТЕГОРИАЛЬНЫХ ДАННЫХ Частотный анализ для категориальных переменных. Частотные таблицы для порядковых шкал. Графическое
- 26. ТАБЛИЦЫ СОПРЯЖЕННОСТИ
- 27. Таблица сопряженности двумерного распределения категориальных переменных для выявления взаимосвязи: - строки таблицы задаются категориями одной переменной;
- 28. Независимая переменная оказывает влияние на зависимую переменную. Например: уровень образования респондента может оказывать влияние на категорию
- 29. ПРОЦЕНТЫ В ЯЧЕЙКАХ ТАБЛИЦЫ СОПРЯЖЕННОСТИ
- 31. Вычисление остатков – разница между наблюденными частотами и ожидаемыми частотами. Остатки являются показателем того, насколько сильно
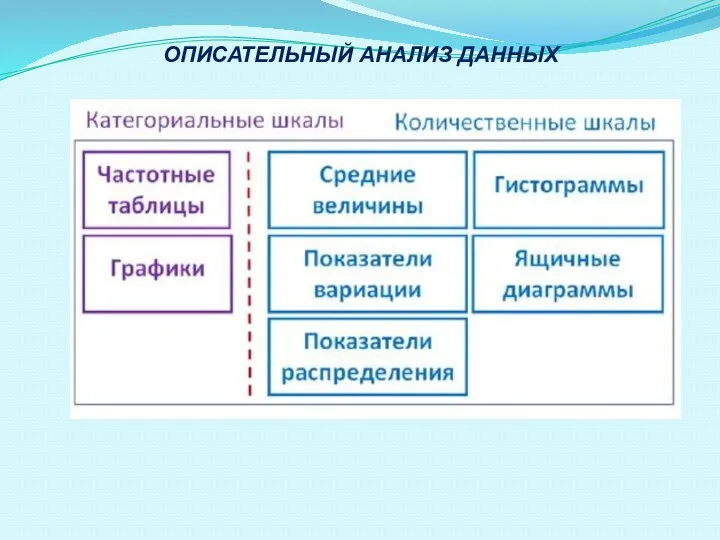
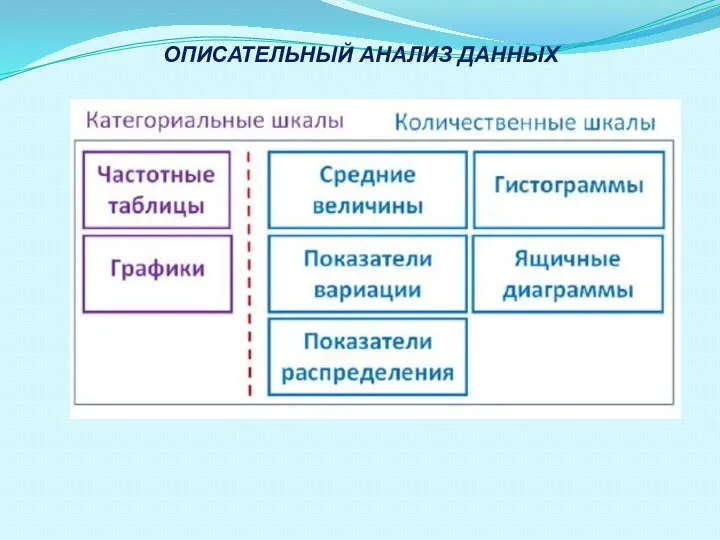
- 32. ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
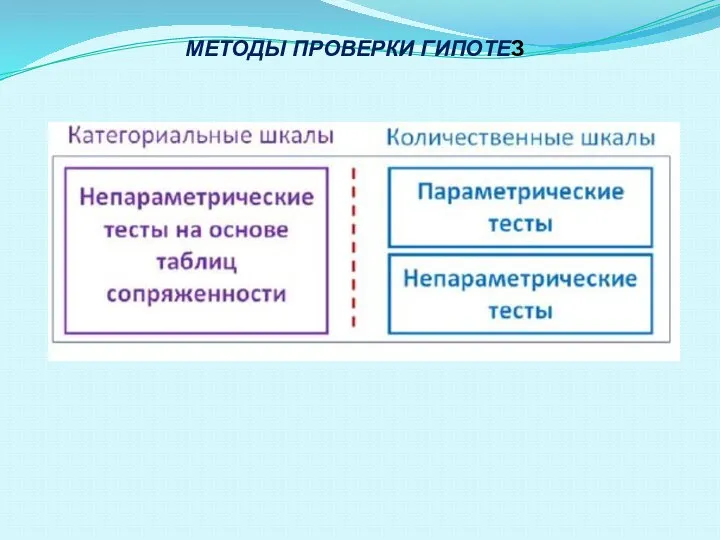
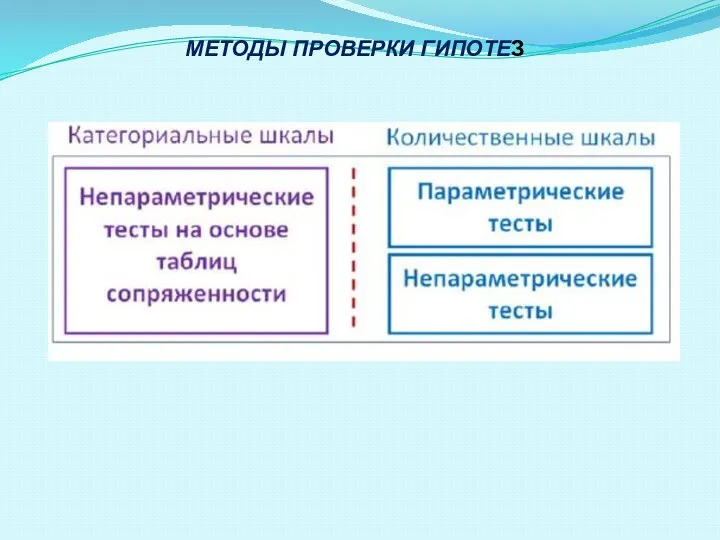
- 33. МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
- 34. 1. оценка параметров – получение точечных и интервальных оценок параметров генеральной совокупности; проверка статистических гипотез –
- 35. Проверка гипотез и изучение взаимосвязи для категориальных шкал происходит, как правило, на основе таблиц сопряженности. Таблица
- 36. СТАТИСТИЧЕСКАЯ ГИПОТЕЗА
- 37. Статистическая гипотеза – это любое предположение (утверждение) относительно неизвестного закона распределения переменной в генеральной совокупности или
- 38. При проверке статистических гипотез различают основную (выдвигаемую, нулевую) гипотезу, которую необходимо проверить, и альтернативную (конкурирующую) гипотезу.
- 39. КРИТЕРИЙ ХИ-КВАДРАТ
- 40. Критерий хи-квадрат основан на различиях между наблюденными и ожидаемыми частотами в ячейках таблицы сопряженности: Чем больше
- 41. 7. При вычислении критерия хи-квадрат может использоваться альтернативная формула с поправкой на правдоподобие. 8. При большом
- 42. ЗАДАНИЕ СЛОЕВ В ТАБЛИЦЕ СОПРЯЖЕННОСТИ
- 43. Процедура Таблицы сопряженности также позволяет добавлять в таблице третье измерение - слои. В этом случае появляется
- 44. ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
- 45. МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
- 46. СТАТИСТИКИ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
- 47. Основные показателя оценки «типичных» значений: - среднее арифметическое – сумма всех значений числового ряда, деленная на
- 49. Медианное значение – альтернативная мера оценки среднего значения в генеральной совокупности вместо средней арифметической. Медиану используют
- 51. Для определения, насколько сильно значения переменной отличаются друг от друга, используют статистики разброса или вариации. Статистики
- 52. Используют следующие меры разброса: - дисперсия – сумма квадратов разностей каждого значения переменной и среднего значения,
- 55. Значение процентиля – это значение количественной переменной, которое разделяет упорядоченные данные на две группы таким образом,
- 57. Одним из наиболее информативных средств подытоживания и наглядного представления количественных переменных является гистограмма. В отличие от
- 59. 1. Предпосылкой применения большинства методов статистического анализа является нормальность распределения. 2. Для переменных, относящихся к интервальной
- 61. Асимметрия и эксцесс – это статистики, описывающие форму и симметричность распределения изучаемой переменной по сравнению с
- 63. Для приблизительной оценки нормальности распределения необходимо сравнить моду, медиану и среднее значение, а также проанализировать коэффициенты
- 65. Для проверки гипотезы о нормальности распределения применяют статистический тест Колмогорова-Смирнова или Шапиро-Уилка. В тесте на нормальность
- 66. ВЫЯВЛЕНИЕ СТАТИСТИЧЕСКОЙ ВЗАИМОСВЯЗИ МЕЖДУ КОЛИЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ
- 68. Одна из задач статистического анализа – изучение взаимосвязи между переменными. Факторные признаки – переменные, которые обуславливают
- 69. При анализе взаимосвязи двух переменных можно построить диаграмму рассеяния (поле корреляции). Диаграмма рассеяния – это простейший
- 72. Корреляционный анализ – метод определения тесноты и направления линейной взаимосвязи между двумя количественными переменными. Теснота и
- 77. Ранжирование – это процедура упорядочения объектов изучения, которая выполняется на основе предпочтения. Ранг – это порядковый
- 82. Скачать презентацию





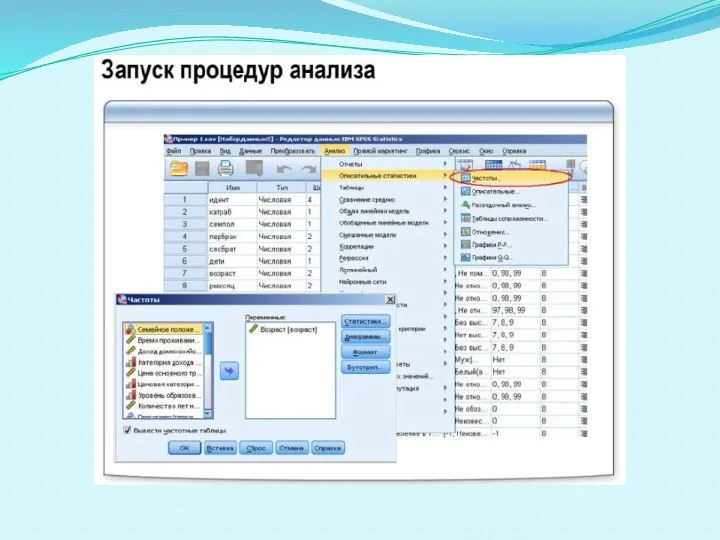

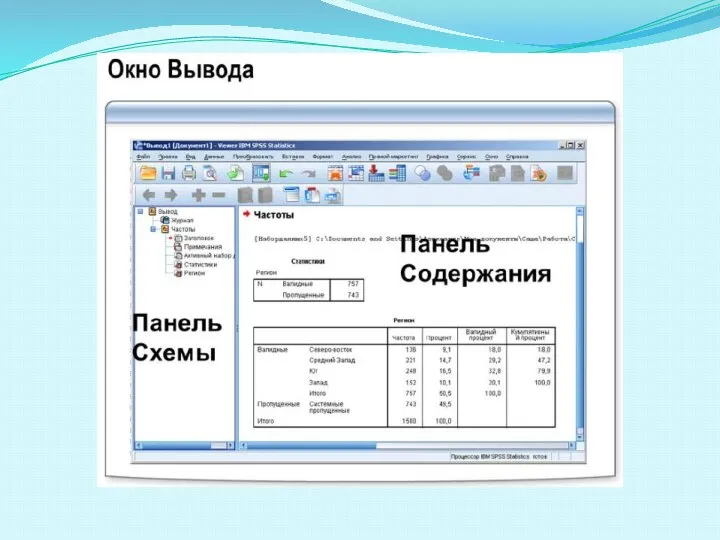
Слайд 10ОРГАНИЗАЦИЯ ДАННЫХ
ОРГАНИЗАЦИЯ ДАННЫХ






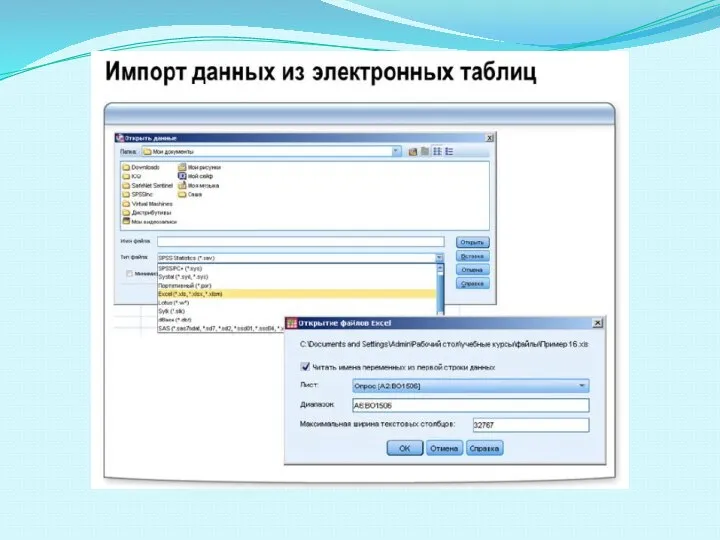

Слайд 18ИЗМЕНЕНИЕ ЗНАЧЕНИЙ ДАННЫХ
ИЗМЕНЕНИЕ ЗНАЧЕНИЙ ДАННЫХ






Слайд 25ОПИСАТЕЛЬНАЯ СТАТИСТИКА ДЛЯ КАТЕГОРИАЛЬНЫХ ДАННЫХ
Частотный анализ для категориальных переменных.
Частотные таблицы для порядковых
ОПИСАТЕЛЬНАЯ СТАТИСТИКА ДЛЯ КАТЕГОРИАЛЬНЫХ ДАННЫХ
Частотный анализ для категориальных переменных.
Частотные таблицы для порядковых

Слайд 26ТАБЛИЦЫ СОПРЯЖЕННОСТИ
ТАБЛИЦЫ СОПРЯЖЕННОСТИ

Слайд 27Таблица сопряженности двумерного распределения категориальных переменных для выявления взаимосвязи:
- строки таблицы задаются
Таблица сопряженности двумерного распределения категориальных переменных для выявления взаимосвязи:
- строки таблицы задаются

Слайд 28Независимая переменная оказывает влияние на зависимую переменную.
Например: уровень образования респондента может оказывать
Например: уровень образования респондента может оказывать

Слайд 29ПРОЦЕНТЫ В ЯЧЕЙКАХ ТАБЛИЦЫ СОПРЯЖЕННОСТИ
ПРОЦЕНТЫ В ЯЧЕЙКАХ ТАБЛИЦЫ СОПРЯЖЕННОСТИ


Слайд 31Вычисление остатков – разница между наблюденными частотами и ожидаемыми частотами. Остатки являются
Вычисление остатков – разница между наблюденными частотами и ожидаемыми частотами. Остатки являются

Слайд 32ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
Слайд 33МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
Слайд 341. оценка параметров – получение точечных и интервальных оценок параметров генеральной совокупности;
1. оценка параметров – получение точечных и интервальных оценок параметров генеральной совокупности;

Слайд 35Проверка гипотез и изучение взаимосвязи для категориальных шкал происходит, как правило, на
Проверка гипотез и изучение взаимосвязи для категориальных шкал происходит, как правило, на

Слайд 36СТАТИСТИЧЕСКАЯ ГИПОТЕЗА
СТАТИСТИЧЕСКАЯ ГИПОТЕЗА
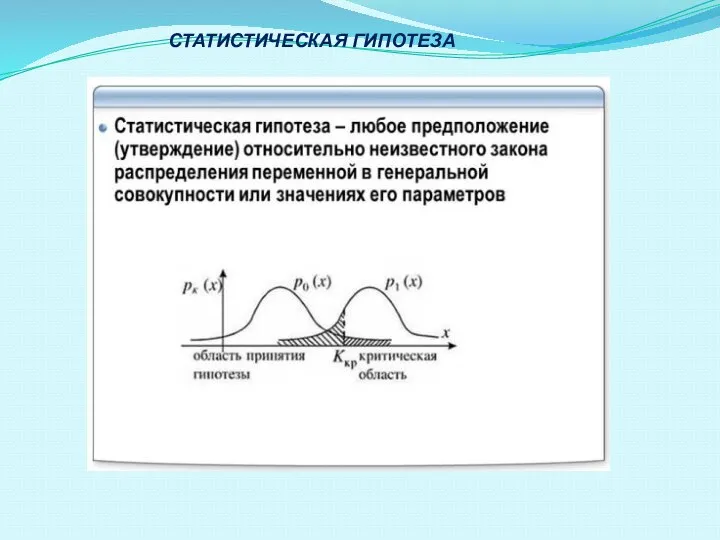
Слайд 37 Статистическая гипотеза – это любое предположение (утверждение) относительно неизвестного закона распределения
Статистическая гипотеза – это любое предположение (утверждение) относительно неизвестного закона распределения

Слайд 38При проверке статистических гипотез различают основную (выдвигаемую, нулевую) гипотезу, которую необходимо проверить,
При проверке статистических гипотез различают основную (выдвигаемую, нулевую) гипотезу, которую необходимо проверить,

Слайд 39КРИТЕРИЙ ХИ-КВАДРАТ
КРИТЕРИЙ ХИ-КВАДРАТ

Слайд 40Критерий хи-квадрат основан на различиях между наблюденными и ожидаемыми частотами в ячейках
Критерий хи-квадрат основан на различиях между наблюденными и ожидаемыми частотами в ячейках

Слайд 417. При вычислении критерия хи-квадрат может использоваться альтернативная формула с поправкой на
7. При вычислении критерия хи-квадрат может использоваться альтернативная формула с поправкой на

Слайд 42ЗАДАНИЕ СЛОЕВ В ТАБЛИЦЕ СОПРЯЖЕННОСТИ
ЗАДАНИЕ СЛОЕВ В ТАБЛИЦЕ СОПРЯЖЕННОСТИ
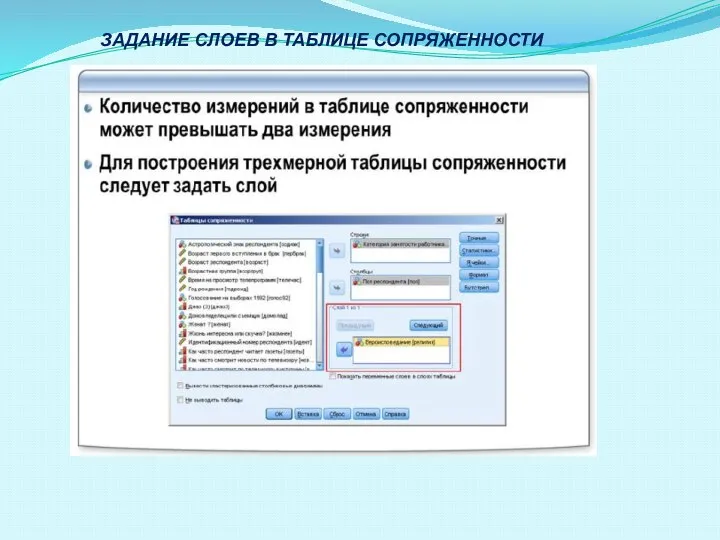
Слайд 43Процедура Таблицы сопряженности также позволяет добавлять в таблице третье измерение - слои.
В
Процедура Таблицы сопряженности также позволяет добавлять в таблице третье измерение - слои.
В

Слайд 44ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
ОПИСАТЕЛЬНЫЙ АНАЛИЗ ДАННЫХ
Слайд 45МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
МЕТОДЫ ПРОВЕРКИ ГИПОТЕЗ
Слайд 46СТАТИСТИКИ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
СТАТИСТИКИ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ

Слайд 47Основные показателя оценки «типичных» значений:
- среднее арифметическое – сумма всех значений числового
Основные показателя оценки «типичных» значений:
- среднее арифметическое – сумма всех значений числового


Слайд 49Медианное значение – альтернативная мера оценки среднего значения в генеральной совокупности вместо
Медианное значение – альтернативная мера оценки среднего значения в генеральной совокупности вместо


Слайд 51Для определения, насколько сильно значения переменной отличаются друг от друга, используют статистики
Для определения, насколько сильно значения переменной отличаются друг от друга, используют статистики

Слайд 52Используют следующие меры разброса:
- дисперсия – сумма квадратов разностей каждого значения переменной
Используют следующие меры разброса:
- дисперсия – сумма квадратов разностей каждого значения переменной



Слайд 55Значение процентиля – это значение количественной переменной, которое разделяет упорядоченные данные на
Значение процентиля – это значение количественной переменной, которое разделяет упорядоченные данные на

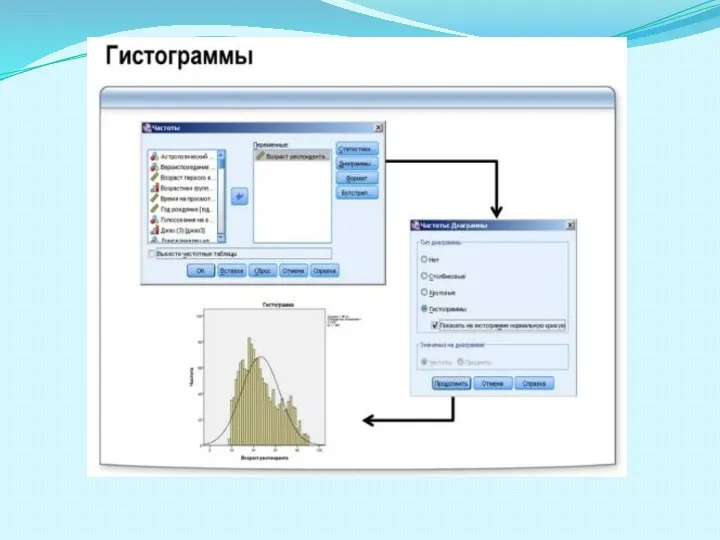
Слайд 57Одним из наиболее информативных средств подытоживания и наглядного представления количественных переменных является

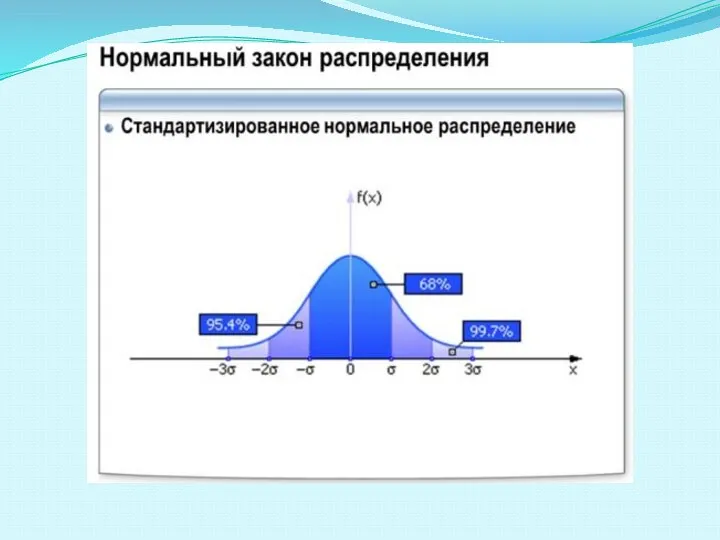
Слайд 591. Предпосылкой применения большинства методов статистического анализа является нормальность распределения.
2. Для переменных,
1. Предпосылкой применения большинства методов статистического анализа является нормальность распределения.
2. Для переменных,


Слайд 61Асимметрия и эксцесс – это статистики, описывающие форму и симметричность распределения изучаемой
Асимметрия и эксцесс – это статистики, описывающие форму и симметричность распределения изучаемой


Слайд 63Для приблизительной оценки нормальности распределения необходимо сравнить моду, медиану и среднее значение,
Для приблизительной оценки нормальности распределения необходимо сравнить моду, медиану и среднее значение,

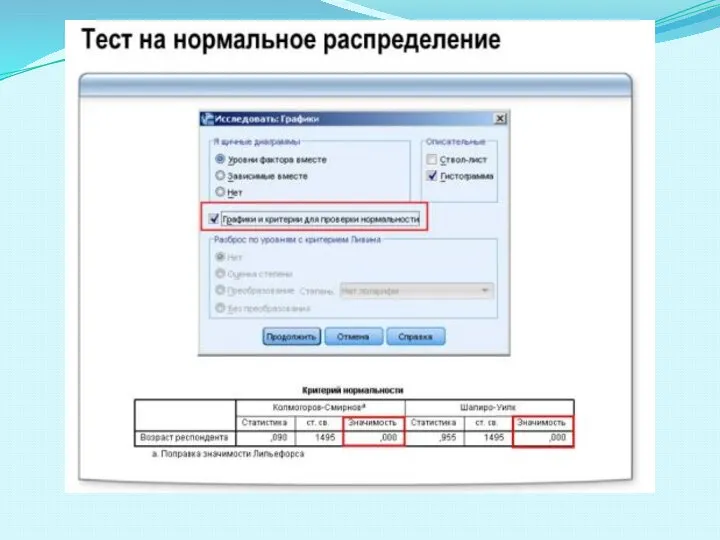
Слайд 65Для проверки гипотезы о нормальности распределения применяют статистический тест Колмогорова-Смирнова или Шапиро-Уилка.
В
Для проверки гипотезы о нормальности распределения применяют статистический тест Колмогорова-Смирнова или Шапиро-Уилка.
В

Слайд 66ВЫЯВЛЕНИЕ СТАТИСТИЧЕСКОЙ ВЗАИМОСВЯЗИ
МЕЖДУ КОЛИЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ
ВЫЯВЛЕНИЕ СТАТИСТИЧЕСКОЙ ВЗАИМОСВЯЗИ
МЕЖДУ КОЛИЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ


Слайд 68Одна из задач статистического анализа – изучение взаимосвязи между переменными.
Факторные признаки
Одна из задач статистического анализа – изучение взаимосвязи между переменными.
Факторные признаки

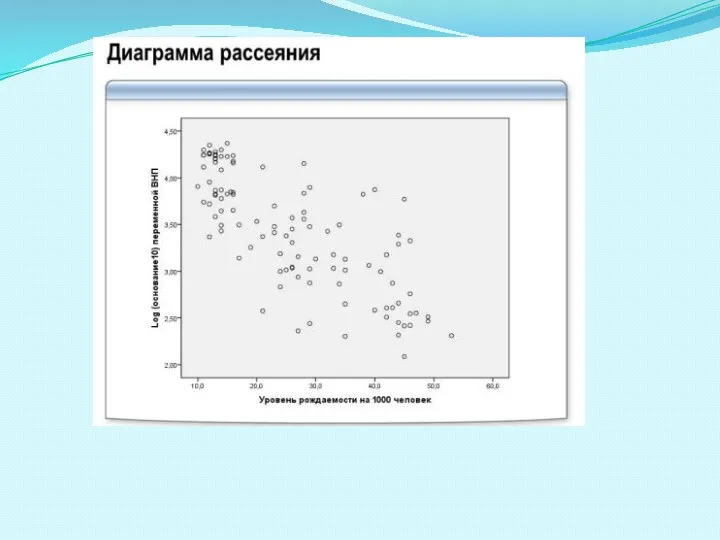
Слайд 69При анализе взаимосвязи двух переменных можно построить диаграмму рассеяния (поле корреляции).
Диаграмма
При анализе взаимосвязи двух переменных можно построить диаграмму рассеяния (поле корреляции).
Диаграмма


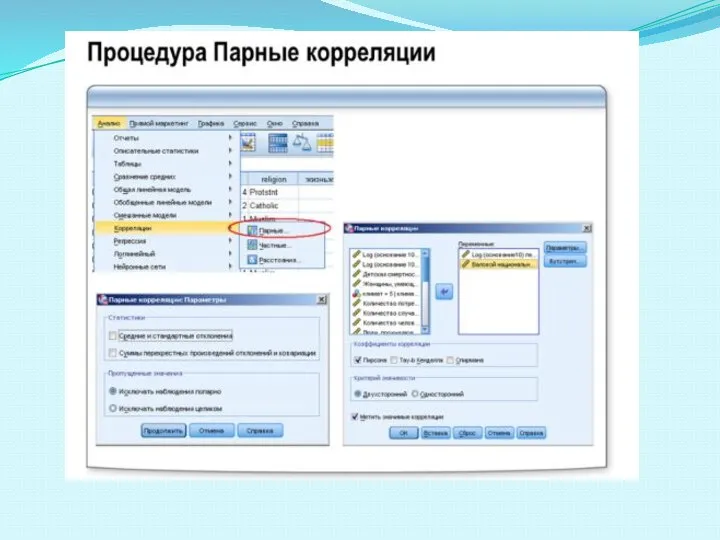
Слайд 72Корреляционный анализ – метод определения тесноты и направления линейной взаимосвязи между двумя
Корреляционный анализ – метод определения тесноты и направления линейной взаимосвязи между двумя




Слайд 77Ранжирование – это процедура упорядочения объектов изучения, которая выполняется на основе предпочтения.
Ранжирование – это процедура упорядочения объектов изучения, которая выполняется на основе предпочтения.




 График функции y = sin x
График функции y = sin x Матрицы и определители
Матрицы и определители Деление на 3
Деление на 3 Треугольники
Треугольники Логарифмические функции
Логарифмические функции Презентация на тему НЕРАВЕНСТВО ТРЕУГОЛЬНИКА
Презентация на тему НЕРАВЕНСТВО ТРЕУГОЛЬНИКА  Задачи для подготовки к контрольной работе
Задачи для подготовки к контрольной работе Тригонометрия
Тригонометрия Решение задач на работу
Решение задач на работу Алгоритм деления
Алгоритм деления Неравенство треугольника (7 класс)
Неравенство треугольника (7 класс) Умножение натуральных чисел. Графический диктант. 5 класс
Умножение натуральных чисел. Графический диктант. 5 класс Розв’язування задач
Розв’язування задач Операции над матрицами
Операции над матрицами Презентация на тему Вводное повторени для 8 классов по геометрии
Презентация на тему Вводное повторени для 8 классов по геометрии  Система нелинейных уравнений. Организация и проведение итогового повторения
Система нелинейных уравнений. Организация и проведение итогового повторения Приемы устных вычислений двузначных чисел
Приемы устных вычислений двузначных чисел Решение тригонометрических уравнений
Решение тригонометрических уравнений Классическая формула подсчета результатов
Классическая формула подсчета результатов Симметрия и асимметрия
Симметрия и асимметрия Сложение дробей
Сложение дробей Методика изучения одномерных геометрических фигур: ломаная, многоугольники и их виды: прямоугольник, квадрат и их свойства
Методика изучения одномерных геометрических фигур: ломаная, многоугольники и их виды: прямоугольник, квадрат и их свойства Функции, их свойства и графики
Функции, их свойства и графики Цилиндр. Конус
Цилиндр. Конус Понятие площади. Площадь квадрата и прямоугольника
Понятие площади. Площадь квадрата и прямоугольника Решение систем неравенств первой степени с одним неизвестным
Решение систем неравенств первой степени с одним неизвестным Презентация на тему Действия с рациональными числами
Презентация на тему Действия с рациональными числами  Уравнение. Корень уравнения
Уравнение. Корень уравнения