- Примеры использования OpenMP. Вычисление определенного интеграла

Содержание
- 2. ВЫЧИСЛЕНИЕ ОПРЕДЕЛЕННОГО ИНТЕГРАЛА
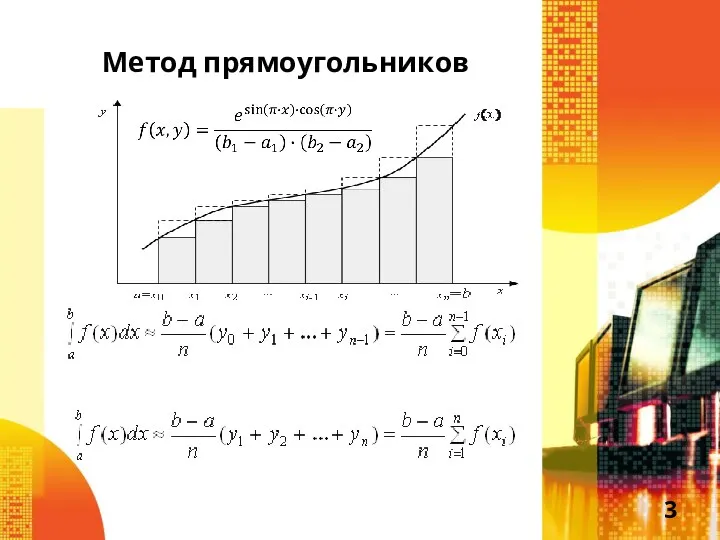
- 3. Метод прямоугольников
- 4. Последовательность выполнения Последовательная версия. Базовая реализация алгоритма интегрирования Эффект применения компилятора Использование предварительных вычислений сложных функций
- 5. Базовый алгоритм Должен содержать код, несколько раз запускающий тестируемую реализацию алгоритма вычислений. Должен вычислять минимальное, максимальное
- 6. Распараллеливание базового алгоритма Геометрическая декомпозиция данных (разделение данных на части и применение к ним одного и
- 7. Геометрическая декомпозиция данных По столбцам По строкам Блочно 1 2 3
- 8. Оптимизация базового алгоритма Предварительное вычисление сложных математических функций (sin, cos, exp и др.). Алгоритмическая оптимизация (исключение
- 9. Распараллеливание оптимизированного алгоритма Распараллеливание с учетом уже полученных результатов: В данной задаче наилучшие результаты дает распараллеливание
- 10. Пример выполнения вычислений
- 11. Структура программы main() experiment() integral()
- 12. Пример выполнения вычислений Базовый алгоритм
- 13. Основная программа int main () { int i; double time, res, min_time, max_time, avg_time; int numbExp
- 14. Функция experiment double experiment(double *res) { double stime, ftime; double a1 = 0.0 ; double a1
- 15. Функция integral void integral(const double a1, const double b1, const double a2, const double b2, const
- 16. Пример выполнения вычислений Базовый алгоритм - распараллеливание
- 17. Распараллеливание по столбцам #pragma omp parallel for for(i = 0; i { for(j = 0; j
- 18. Распараллеливание по столбцам с учетом data race #pragma omp parallel for private (x, y, j) reduction(+:
- 19. Распараллеливание по строкам for(i = 0; i { #pragma omp parallel for private (x, y) reduction(+:
- 20. Блочное разделение данных omp_set_nested(true); #pragma omp parallel for for (i = 0; i { #pragma omp
- 21. Результаты вычислений
- 22. Влияние параметров распараллеливания циклов
- 23. Пример выполнения вычислений Оптимизированный алгоритм – распараллеливание
- 24. Использование предварительных вычислений сложных функций void integral(const double a1, const double b1, const double a2, const
- 25. Результаты вычислений
- 26. Загрузка ядер процессора Последовательный алгоритм Оптимизированный параллельный алгоритм Параллельный алгоритм
- 27. Пример выполнения вычислений Вычисление интеграла методом Монте-Карло
- 28. Метод Монте-Карло
- 29. Функция integral void integral(const double a1, const double b1, const double a2, const double b2, const
- 31. Скачать презентацию

Слайд 3Метод прямоугольников
Метод прямоугольников
Слайд 4Последовательность выполнения
Последовательная версия.
Базовая реализация алгоритма интегрирования
Эффект применения компилятора
Использование предварительных
Последовательность выполнения
Последовательная версия.
Базовая реализация алгоритма интегрирования
Эффект применения компилятора
Использование предварительных

Слайд 5Базовый алгоритм
Должен содержать код, несколько раз запускающий тестируемую реализацию алгоритма вычислений.
Должен вычислять
Базовый алгоритм
Должен содержать код, несколько раз запускающий тестируемую реализацию алгоритма вычислений.
Должен вычислять

Слайд 6Распараллеливание базового алгоритма
Геометрическая декомпозиция данных (разделение данных на части и применение к
Распараллеливание базового алгоритма
Геометрическая декомпозиция данных (разделение данных на части и применение к

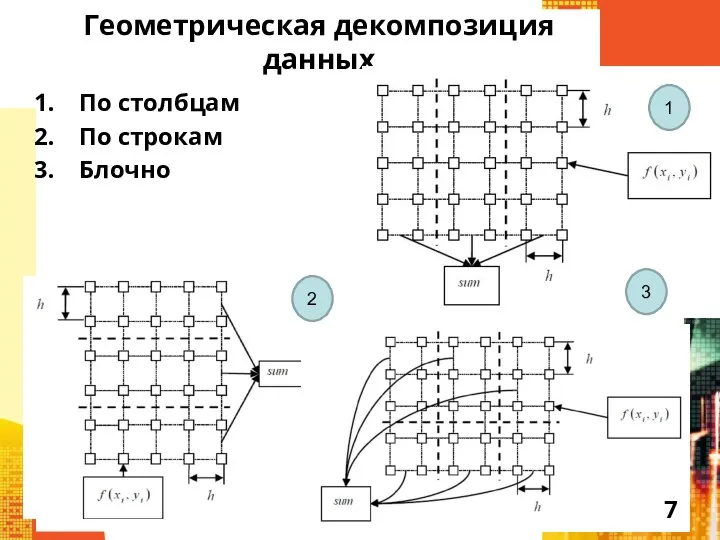
Слайд 7Геометрическая декомпозиция данных
По столбцам
По строкам
Блочно
1
2
3
Геометрическая декомпозиция данных
По столбцам
По строкам
Блочно
1
2
3
Слайд 8Оптимизация базового алгоритма
Предварительное вычисление сложных математических функций (sin, cos, exp и др.).
Алгоритмическая
Оптимизация базового алгоритма
Предварительное вычисление сложных математических функций (sin, cos, exp и др.).
Алгоритмическая

Слайд 9Распараллеливание оптимизированного алгоритма
Распараллеливание с учетом уже полученных результатов:
В данной задаче наилучшие результаты
Распараллеливание оптимизированного алгоритма
Распараллеливание с учетом уже полученных результатов:
В данной задаче наилучшие результаты

Слайд 10 Пример выполнения вычислений
Пример выполнения вычислений

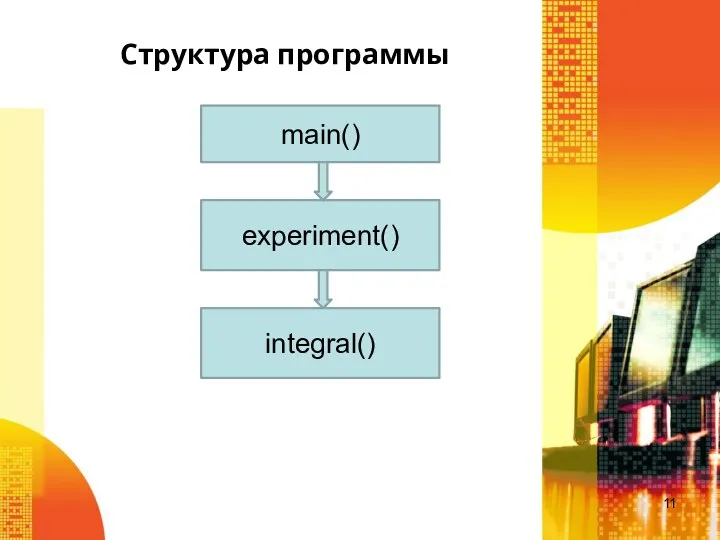
Слайд 11Структура программы
main()
experiment()
integral()
Структура программы
main()
experiment()
integral()
Слайд 12 Пример выполнения вычислений
Базовый алгоритм
Пример выполнения вычислений
Базовый алгоритм

Слайд 13Основная программа
int main () {
int i;
double time, res, min_time, max_time,
Основная программа
int main () {
int i;
double time, res, min_time, max_time,

Слайд 14Функция experiment
double experiment(double *res)
{
double stime, ftime;
double a1 = 0.0
Функция experiment
double experiment(double *res)
{
double stime, ftime;
double a1 = 0.0

Слайд 15Функция integral
void integral(const double a1, const double b1,
const double a2, const double
Функция integral
void integral(const double a1, const double b1,
const double a2, const double

Слайд 16 Пример выполнения вычислений
Базовый алгоритм - распараллеливание
Пример выполнения вычислений
Базовый алгоритм - распараллеливание

Слайд 17Распараллеливание по столбцам
#pragma omp parallel for
for(i = 0; i < n1;
Распараллеливание по столбцам
#pragma omp parallel for
for(i = 0; i < n1;

Слайд 18Распараллеливание по столбцам с учетом data race
#pragma omp parallel for private (x, y,
Распараллеливание по столбцам с учетом data race
#pragma omp parallel for private (x, y,

Слайд 19Распараллеливание по строкам
for(i = 0; i < n1; i++)
{
#pragma
Распараллеливание по строкам
for(i = 0; i < n1; i++)
{
#pragma

Слайд 20Блочное разделение данных
omp_set_nested(true);
#pragma omp parallel for
for (i = 0; i <
Блочное разделение данных
omp_set_nested(true);
#pragma omp parallel for
for (i = 0; i <

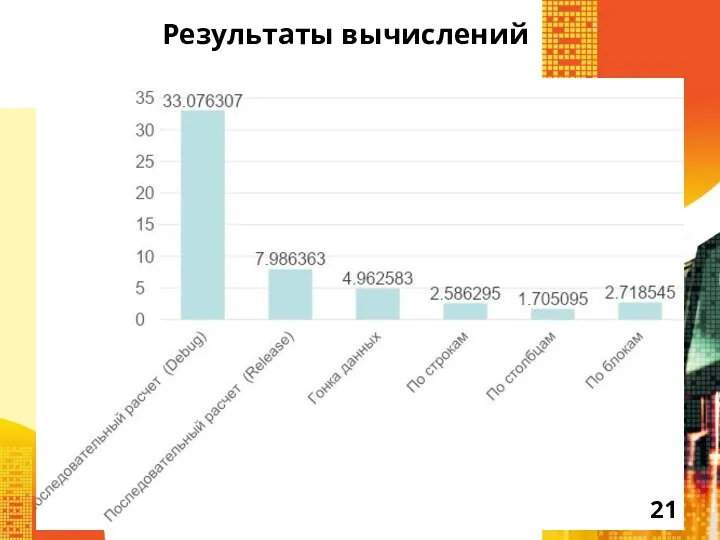
Слайд 21Результаты вычислений
Результаты вычислений
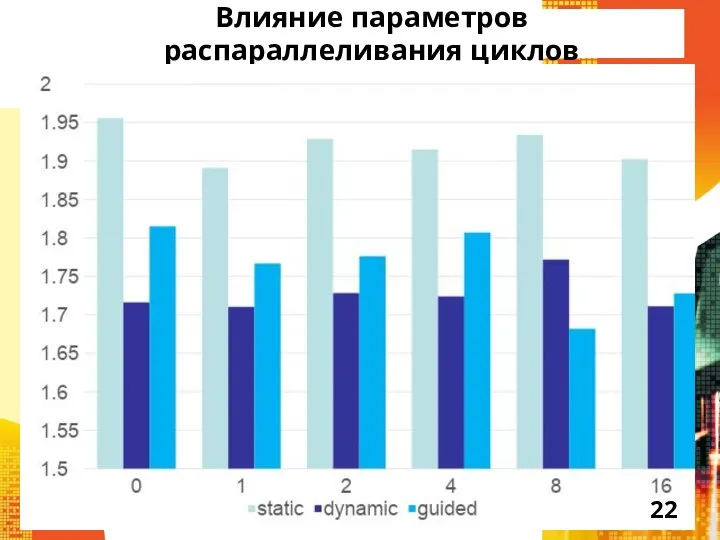
Слайд 22Влияние параметров распараллеливания циклов
Влияние параметров распараллеливания циклов
Слайд 23 Пример выполнения вычислений
Оптимизированный алгоритм –
распараллеливание
Пример выполнения вычислений
Оптимизированный алгоритм –
распараллеливание

Слайд 24Использование предварительных вычислений сложных функций
void integral(const double a1, const double b1,
const
Использование предварительных вычислений сложных функций
void integral(const double a1, const double b1,
const

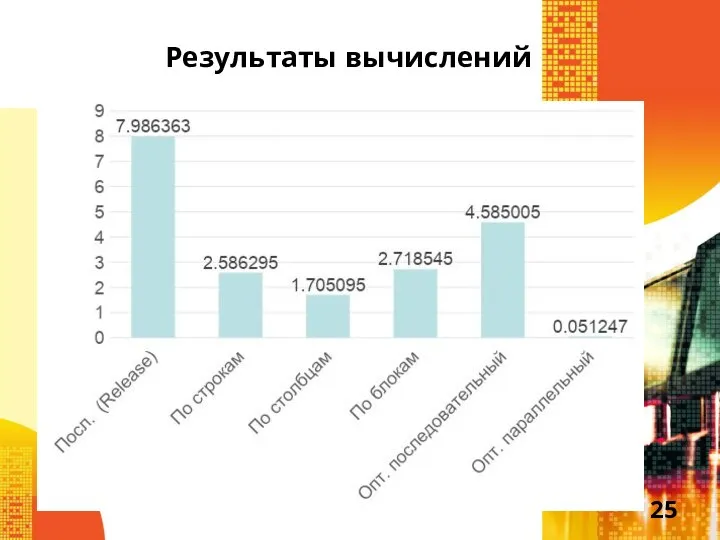
Слайд 25Результаты вычислений
Результаты вычислений
Слайд 26Загрузка ядер процессора
Последовательный алгоритм
Оптимизированный параллельный алгоритм
Параллельный алгоритм
Загрузка ядер процессора
Последовательный алгоритм
Оптимизированный параллельный алгоритм
Параллельный алгоритм

Слайд 27 Пример выполнения вычислений
Вычисление интеграла методом Монте-Карло
Пример выполнения вычислений
Вычисление интеграла методом Монте-Карло

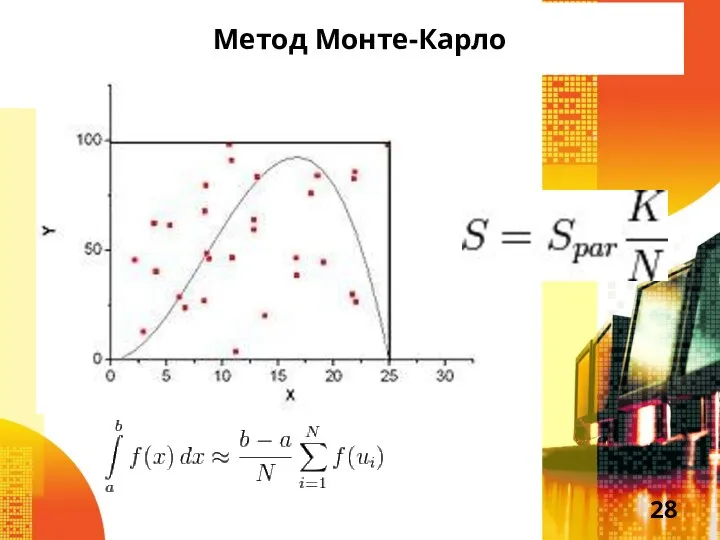
Слайд 28Метод Монте-Карло
Метод Монте-Карло
Слайд 29Функция integral
void integral(const double a1, const double b1, const double a2, const
Функция integral
void integral(const double a1, const double b1, const double a2, const

 Тела вращения. Урок 142
Тела вращения. Урок 142 Разряды чисел
Разряды чисел Двухфакторный дисперсионный анализ
Двухфакторный дисперсионный анализ Стереометрия
Стереометрия Числовые равенства и их свойства
Числовые равенства и их свойства Приложения производной
Приложения производной Презентация на тему Методы решения логарифмических уравнений
Презентация на тему Методы решения логарифмических уравнений  МО26
МО26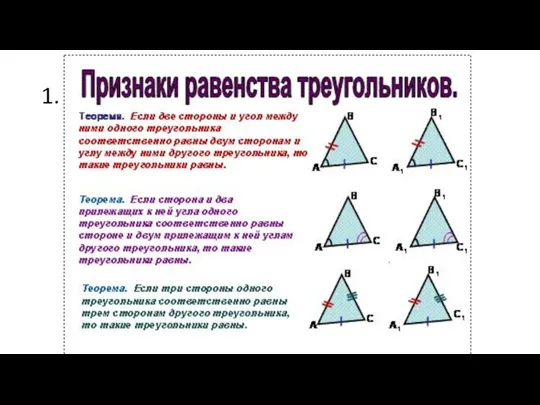 Признаки равенства треугольников
Признаки равенства треугольников Размещения и сочетания
Размещения и сочетания Закрепление решения задач на приведение к единице
Закрепление решения задач на приведение к единице Презентация на тему Решение задач с помощью квадратных уравнений
Презентация на тему Решение задач с помощью квадратных уравнений  Страна треугольников
Страна треугольников Площадь криволинейной трапеции
Площадь криволинейной трапеции Сколько? Как? Почему? Математическая игра
Сколько? Как? Почему? Математическая игра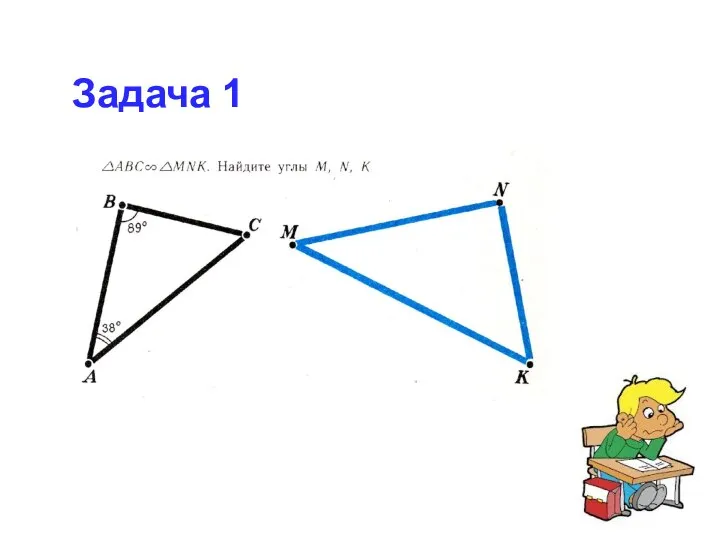 Подобие треугольников. Задачи
Подобие треугольников. Задачи Функция у = х в квадрате и её график
Функция у = х в квадрате и её график Дидактическая игра-тест Модуль числа. 6 класс
Дидактическая игра-тест Модуль числа. 6 класс Вычитание
Вычитание Алгоритм решения задач на нахождение слагаемых по сумме и разности
Алгоритм решения задач на нахождение слагаемых по сумме и разности 20f
20f Трапеция, ее элементы и виды, свойства и признаки
Трапеция, ее элементы и виды, свойства и признаки Neutrino Properties on the Basis of Neutrinoless
Neutrino Properties on the Basis of Neutrinoless Решение уравнений с весной
Решение уравнений с весной Решение задач с помощью уравнений
Решение задач с помощью уравнений Элементы теории множеств. Математические основы информатики
Элементы теории множеств. Математические основы информатики Основы тригонометрии. Упражнения
Основы тригонометрии. Упражнения Линейные неравенства с одной переменной. Обобщающий урок
Линейные неравенства с одной переменной. Обобщающий урок