- Методы статистического анализа литературных текстов

Содержание
- 2. Обсуждаемые вопросы Точность статистического анализа в зависимости от объема текста. Идентификация автора неизвестного текста в библиотеке
- 3. Обсуждаемые вопросы Анализ авторских тандемов и проверка текста на однородность. Динамические системы, генерирующие ряд расстояний между
- 4. Цель и программа работы Сопоставление тексту структуры в фазовом пространстве (букв, слов и т.п.) Введение нормы
- 5. Текстовый инвариант? – Нет! Текстовый инвариант – это функционал F(T) от текстовой структуры. Два текста близки
- 6. 1. Статистическая достоверность определения частот употребления букв в литературных произведениях
- 7. Выборочное распределение текста по буквам Пусть ξ – случайная величина (буква или буквосочетание), принимающая значения из
- 8. Минимально достаточная длина текста Тексты должны быть таких длин, чтобы статистическая неопределенность в оценке вероятностей буквосочетаний
- 9. Оценка достаточной длины текста Для стационарного процесса оценка среднего при неизвестной дисперсии дается статистикой Стьюдента Оценка
- 10. Достаточная длина текста При ε=0,05: для 1-ПФР N=40 тыс. знаков, для 2-ПФР N=400 тыс. знаков, для
- 11. Распределение расстояний между 2-ПФР в норме L1
- 12. Минимальная длина текста
- 13. Уровень нестационарности текстов Расстояние между ПФР текстов: Чтобы сравнивать распределения текстов разных объемов, следует убедиться в
- 14. Длина квазистационарности L(ε) для 1-ПФР Для практических целей, где допустимы небольшие отклонения 1-ПФР отрывка от 1-ПФР
- 15. 2. Кластеризация текстов, создание эталонных распределений и метод идентификации автора
- 16. Идентификация автора текста Пусть имеется библиотека из A авторов, у a-го автора текстов, в i-ом тексте
- 17. Авторские 1-ПФР Вывод: авторские 1-ПФР очень близки, поэтому различие между ними должно выявляться на «тонкой структуре»
- 18. Ошибки 1-го и 2-го родов функция распределения расстояний текстов автора от его эталона; чужих текстов от
- 19. Мощность статистических методов идентификации автора
- 20. Шолохов – автор «Тихого Дона» по расстояниям между 2-ПФР текстов с вероятностью 96%
- 21. Распределение расстояний между произведениями Шекспира
- 22. Шекспир – автор всех своих пьес по расстояниям между 2-ПФР текстов с вероятностью 94%
- 23. 3. Спектральные портреты авторов и эффект переводчика
- 24. Оператор трансляций Пусть есть условная вероятность того, что буква следует за буквой . Пусть также есть
- 25. Оператор трансляций на 1 шаг выражается через 1-ПФР и 2-ПФР: По формуле полной вероятности Следовательно, 1-ПФР
- 26. ε-спектр оператора соседних трансляций Число λ называется принадлежащим ε-спектру матрицы P, если существует матрица Δ такая,
- 27. Вычисление ε-спектра Параметром дихотомии спектра относительно кривой называется норма квадрата резольвенты на данной кривой: Если на
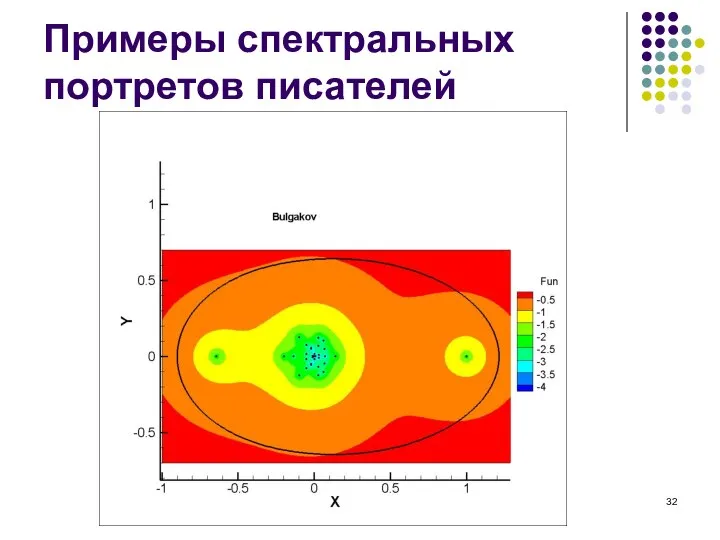
- 28. Примеры спектральных портретов писателей
- 29. Примеры спектральных портретов писателей
- 30. Примеры спектральных портретов писателей
- 31. Примеры спектральных портретов писателей
- 32. Примеры спектральных портретов писателей
- 33. Эффект переводчика и вектор «подсознания» Кроме с.з. , которому отвечает с.в. 1-ПФР f , у оператора
- 34. Шекспир – оригинальный текст «Гамлет» «Много шума из ничего»
- 35. Шекспир – перевод «Гамлет» (Лозинский) «Много шума из ничего» (Щепкина-Куперник)
- 36. 4. Анализ авторских тандемов и проверка текста на однородность
- 37. Горизонтный ряд Пусть x(t) – эквидистантный временной ряд, f(N,t) – его ВПФР, построенная к моменту t
- 38. Примеры горизонтных рядов Сдвиг ВПФР на τ = 10 при уровне ε = 0,05 Значения h,
- 39. Горизонтный ряд как индикатор разладки (τ = 10, ε = 0,05)
- 40. Распределения горизонтных рядов для τ = 10, ε = 0,05
- 41. Распределение расстояний между одинаковыми буквами
- 42. Распределение горизонтного ряда для расстояний «b-b» (τ = 10, ε = 0,05) Для всех букв распределение
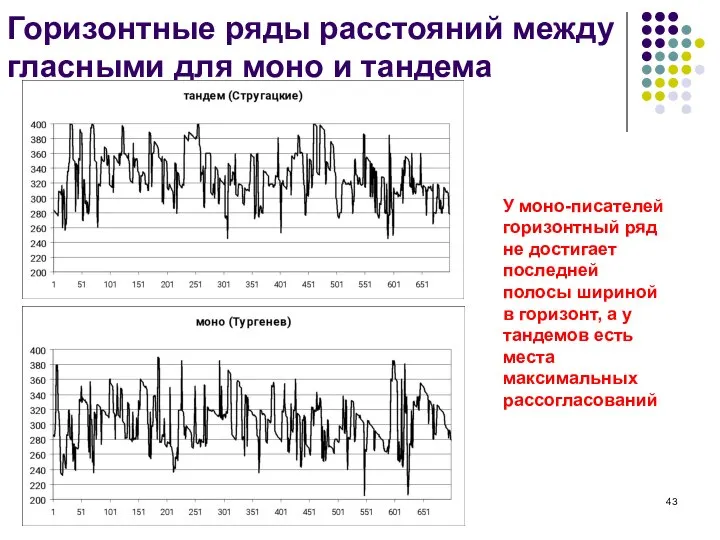
- 43. Горизонтные ряды расстояний между гласными для моно и тандема У моно-писателей горизонтный ряд не достигает последней
- 44. 5. Упорядоченность букв по частоте встречаемости в европейских языках
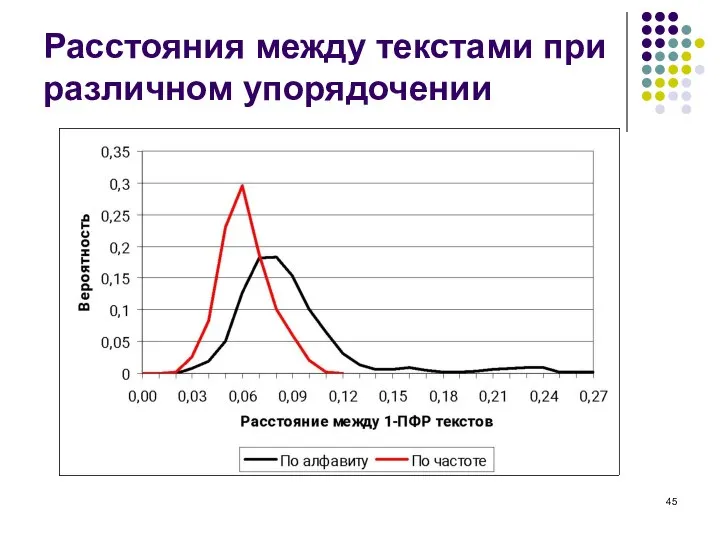
- 45. Расстояния между текстами при различном упорядочении
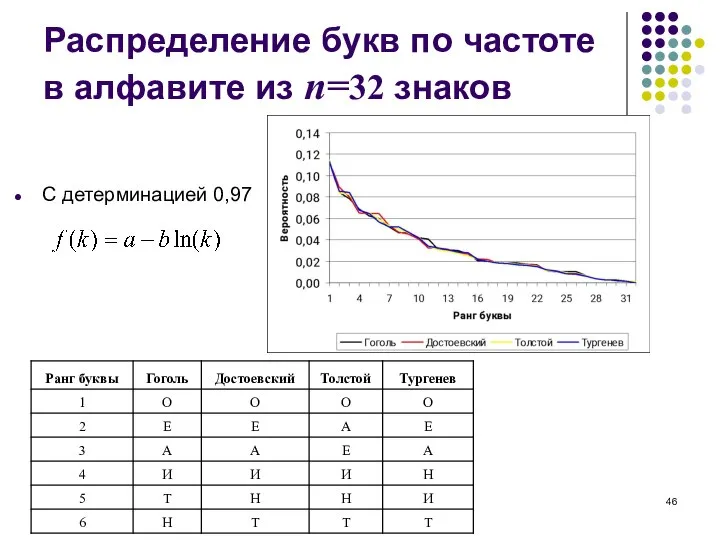
- 46. Распределение букв по частоте в алфавите из n=32 знаков С детерминацией 0,97
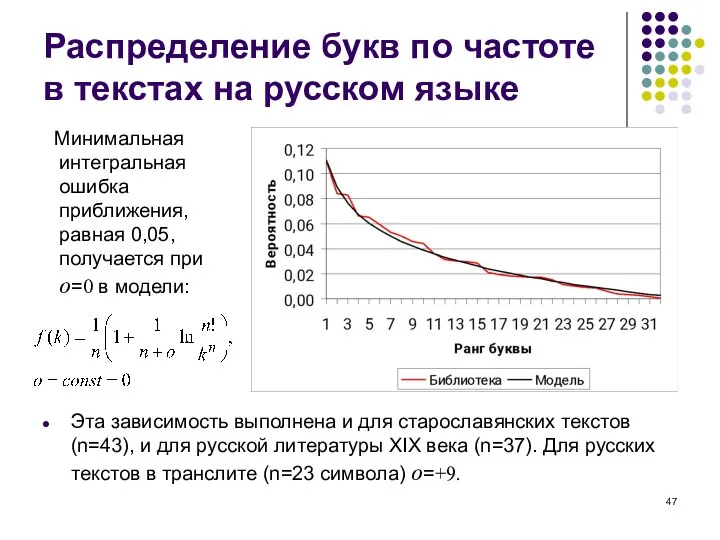
- 47. Распределение букв по частоте в текстах на русском языке Минимальная интегральная ошибка приближения, равная 0,05, получается
- 48. Избыточность и недостаточность алфавитов европейских языков Параметр o трактуем как оценку избыточности (o 0) алфавита по
- 49. Основные результаты 3-ПФР представляет ту текстовую структуру, расстояние в которой позволяет с высокой точностью опознавать автора
- 51. Скачать презентацию
Слайд 2Обсуждаемые вопросы
Точность статистического анализа в зависимости от объема текста.
Идентификация автора неизвестного текста
Обсуждаемые вопросы
Точность статистического анализа в зависимости от объема текста.
Идентификация автора неизвестного текста

Слайд 3Обсуждаемые вопросы
Анализ авторских тандемов и проверка текста на однородность. Динамические системы, генерирующие
Обсуждаемые вопросы
Анализ авторских тандемов и проверка текста на однородность. Динамические системы, генерирующие

Слайд 4Цель и программа работы
Сопоставление тексту структуры в фазовом пространстве (букв, слов и
Цель и программа работы
Сопоставление тексту структуры в фазовом пространстве (букв, слов и

Слайд 5Текстовый инвариант? – Нет!
Текстовый инвариант – это функционал F(T) от текстовой структуры.
Текстовый инвариант? – Нет!
Текстовый инвариант – это функционал F(T) от текстовой структуры.

Слайд 61. Статистическая достоверность определения частот употребления букв
в литературных произведениях
в литературных произведениях

Слайд 7Выборочное распределение текста по буквам
Пусть ξ – случайная величина (буква или
Выборочное распределение текста по буквам
Пусть ξ – случайная величина (буква или

Слайд 8Минимально достаточная длина текста
Тексты должны быть таких длин, чтобы статистическая неопределенность в
Минимально достаточная длина текста
Тексты должны быть таких длин, чтобы статистическая неопределенность в

Слайд 9Оценка достаточной длины текста
Для стационарного процесса оценка среднего при неизвестной дисперсии дается
Оценка достаточной длины текста
Для стационарного процесса оценка среднего при неизвестной дисперсии дается

Слайд 10Достаточная длина текста
При ε=0,05:
для 1-ПФР N=40 тыс. знаков,
для
Достаточная длина текста
При ε=0,05:
для 1-ПФР N=40 тыс. знаков,
для
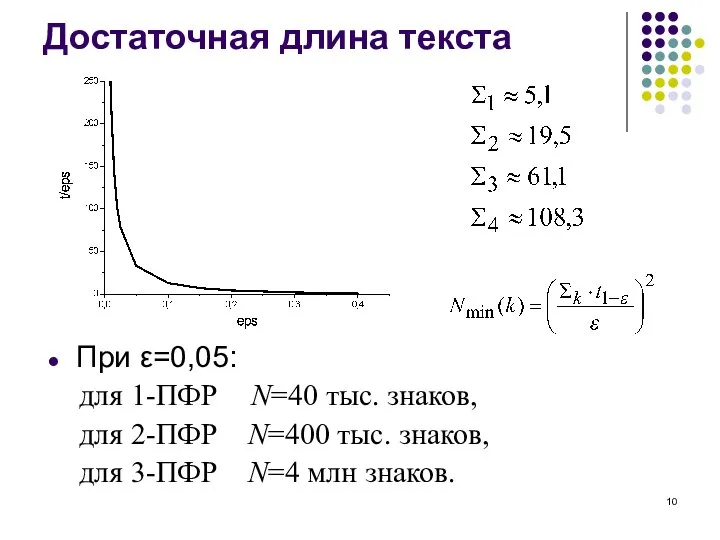
Слайд 11Распределение расстояний между 2-ПФР в норме L1
Распределение расстояний между 2-ПФР в норме L1
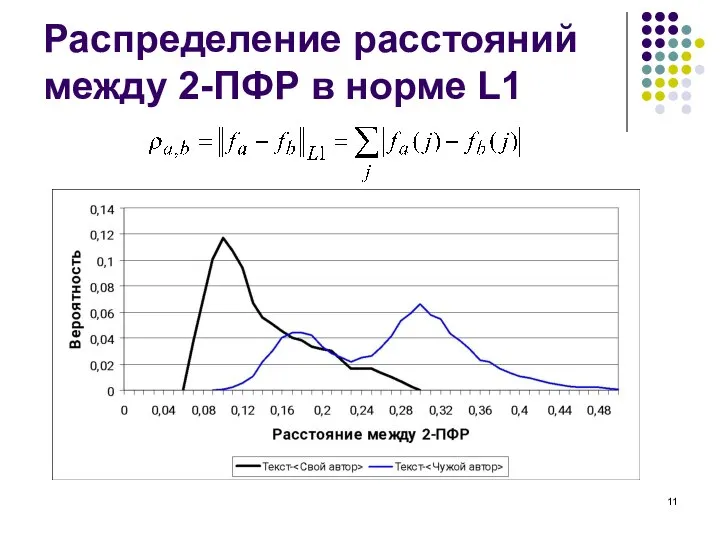
Слайд 12Минимальная длина текста
Минимальная длина текста
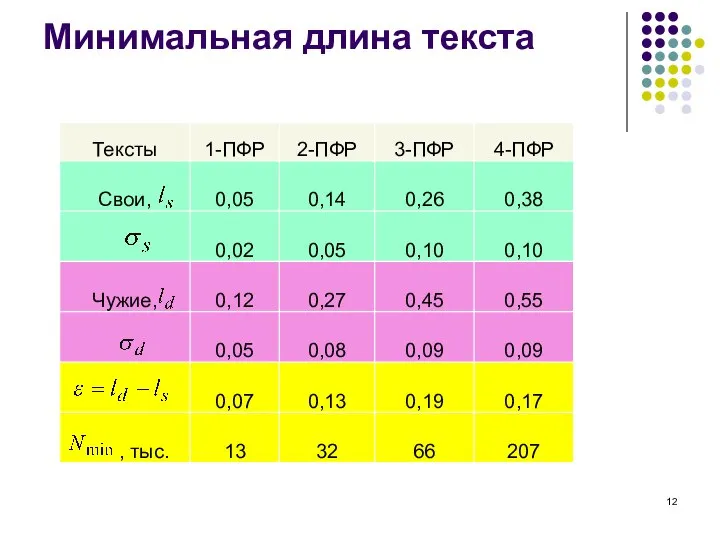
Слайд 13Уровень нестационарности текстов
Расстояние между ПФР текстов:
Чтобы сравнивать распределения текстов разных объемов, следует
Уровень нестационарности текстов
Расстояние между ПФР текстов:
Чтобы сравнивать распределения текстов разных объемов, следует

Слайд 14Длина квазистационарности L(ε) для 1-ПФР
Для практических целей, где допустимы небольшие отклонения 1-ПФР
Длина квазистационарности L(ε) для 1-ПФР
Для практических целей, где допустимы небольшие отклонения 1-ПФР
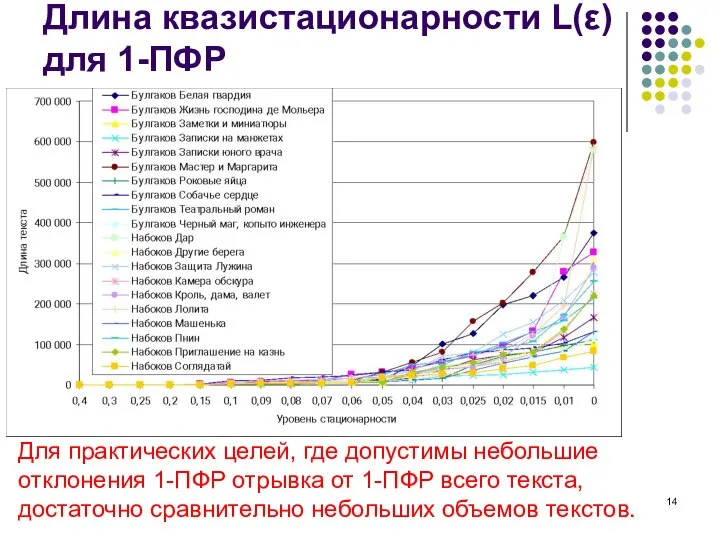
Слайд 152. Кластеризация текстов, создание эталонных распределений
и метод идентификации автора
и метод идентификации автора

Слайд 16Идентификация автора текста
Пусть имеется библиотека из A авторов, у a-го автора текстов,
Идентификация автора текста
Пусть имеется библиотека из A авторов, у a-го автора текстов,

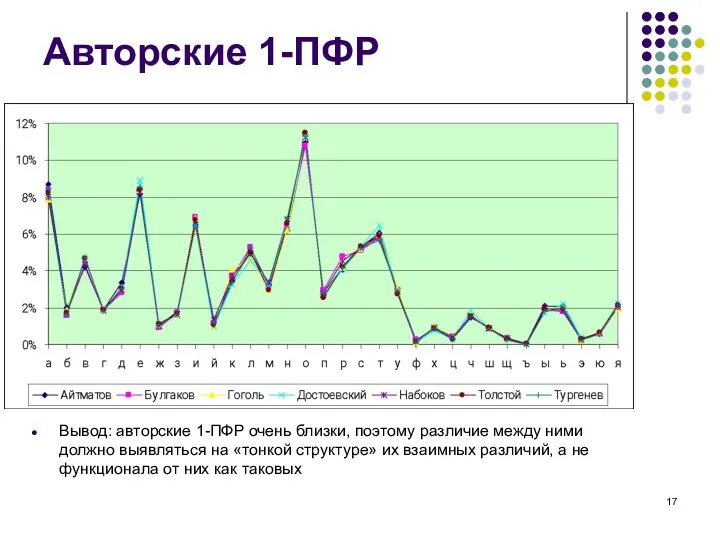
Слайд 17Авторские 1-ПФР
Вывод: авторские 1-ПФР очень близки, поэтому различие между ними должно выявляться
Авторские 1-ПФР
Вывод: авторские 1-ПФР очень близки, поэтому различие между ними должно выявляться
Слайд 18Ошибки 1-го и 2-го родов
функция распределения расстояний текстов автора от его
Ошибки 1-го и 2-го родов
функция распределения расстояний текстов автора от его

Слайд 19Мощность статистических методов идентификации автора
Мощность статистических методов идентификации автора

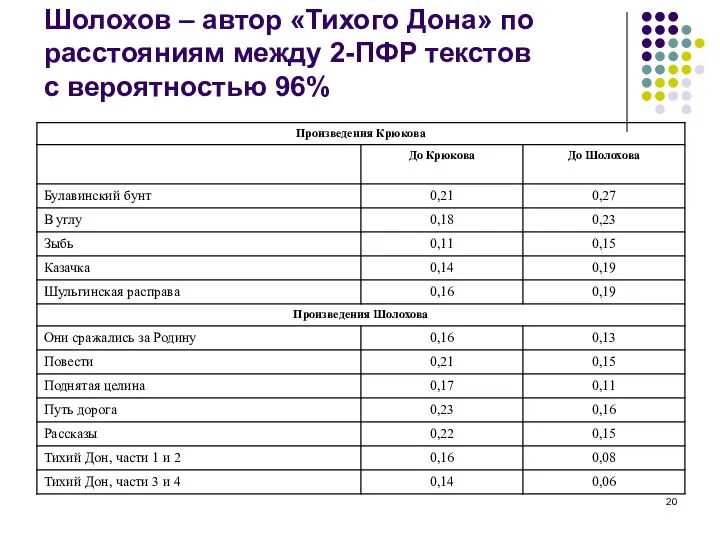
Слайд 20Шолохов – автор «Тихого Дона» по расстояниям между 2-ПФР текстов с вероятностью
Шолохов – автор «Тихого Дона» по расстояниям между 2-ПФР текстов с вероятностью
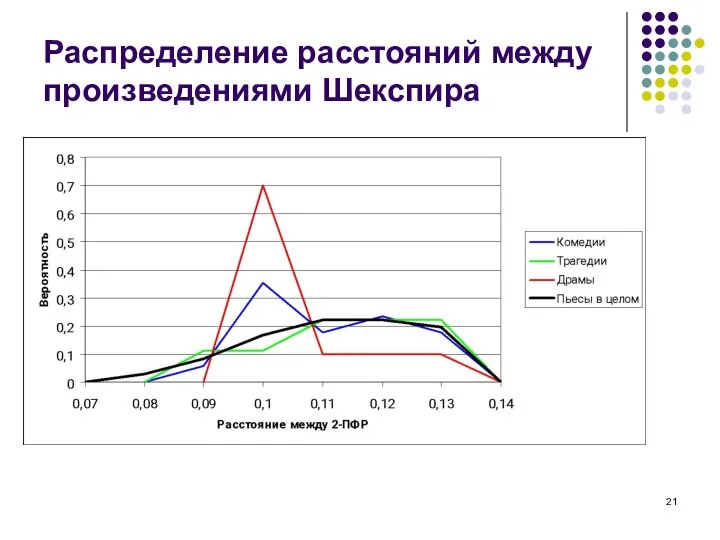
Слайд 21Распределение расстояний между произведениями Шекспира
Распределение расстояний между произведениями Шекспира
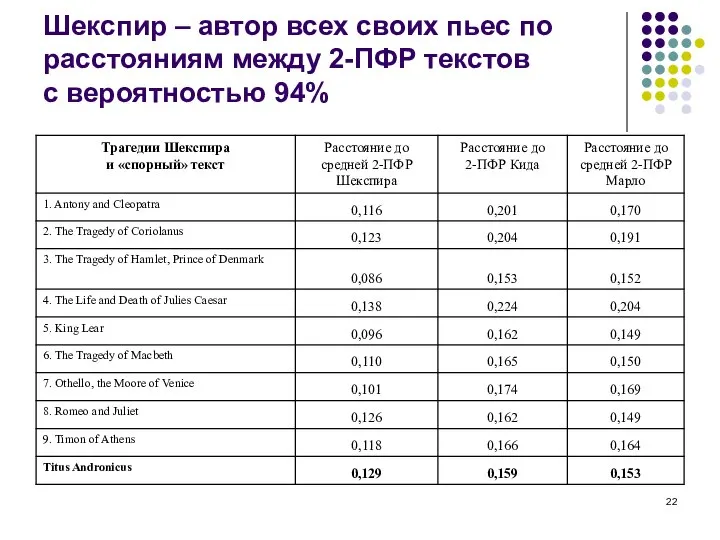
Слайд 22Шекспир – автор всех своих пьес по расстояниям между 2-ПФР текстов с
Шекспир – автор всех своих пьес по расстояниям между 2-ПФР текстов с
Слайд 233. Спектральные портреты авторов
и эффект переводчика
и эффект переводчика

Слайд 24Оператор трансляций
Пусть есть условная вероятность того, что буква следует за буквой .
Оператор трансляций
Пусть есть условная вероятность того, что буква следует за буквой .

Слайд 25Оператор трансляций на 1 шаг
выражается через 1-ПФР и 2-ПФР:
По формуле полной
Оператор трансляций на 1 шаг
выражается через 1-ПФР и 2-ПФР:
По формуле полной

Слайд 26ε-спектр оператора соседних трансляций
Число λ называется принадлежащим ε-спектру матрицы P, если существует
ε-спектр оператора соседних трансляций
Число λ называется принадлежащим ε-спектру матрицы P, если существует

Слайд 27Вычисление ε-спектра
Параметром дихотомии спектра относительно кривой называется норма квадрата резольвенты на данной
Вычисление ε-спектра
Параметром дихотомии спектра относительно кривой называется норма квадрата резольвенты на данной

Слайд 28Примеры спектральных портретов писателей
Примеры спектральных портретов писателей
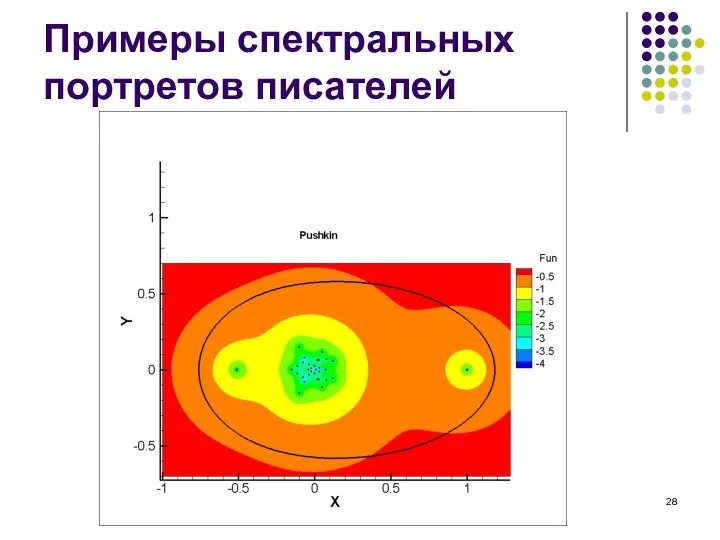
Слайд 29Примеры спектральных портретов писателей
Примеры спектральных портретов писателей
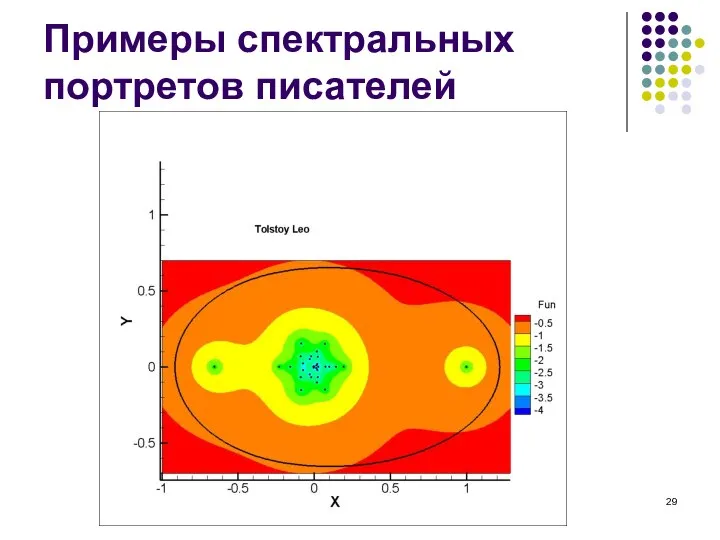
Слайд 30Примеры спектральных портретов писателей
Примеры спектральных портретов писателей
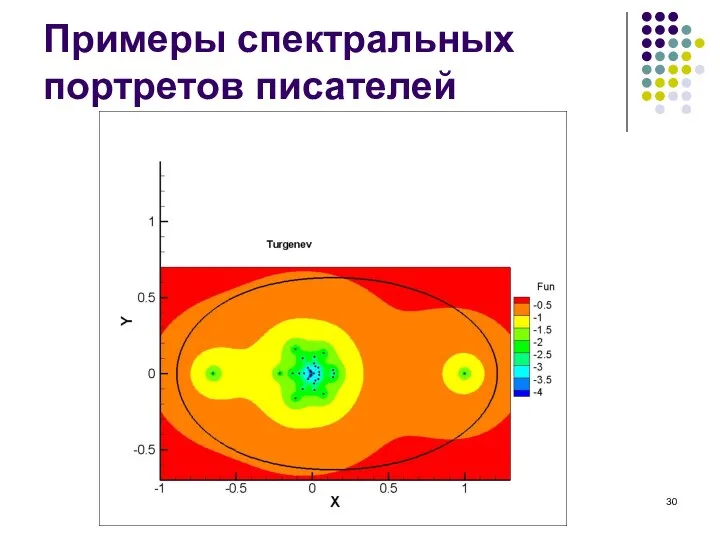
Слайд 31Примеры спектральных портретов писателей
Примеры спектральных портретов писателей
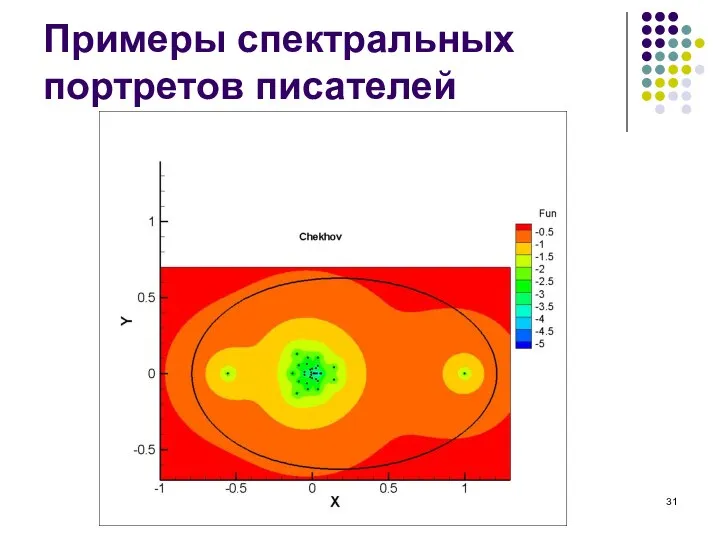
Слайд 32Примеры спектральных портретов писателей
Примеры спектральных портретов писателей
Слайд 33Эффект переводчика и вектор «подсознания»
Кроме с.з. , которому отвечает с.в. 1-ПФР f
Эффект переводчика и вектор «подсознания»
Кроме с.з. , которому отвечает с.в. 1-ПФР f

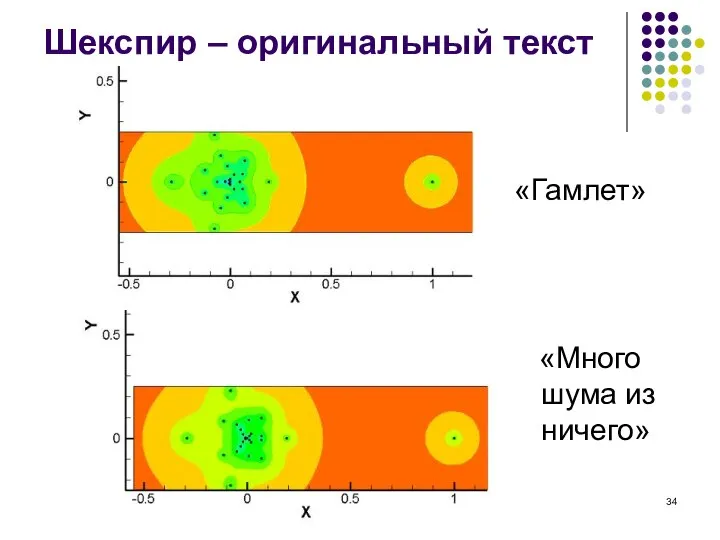
Слайд 34Шекспир – оригинальный текст
«Гамлет»
«Много шума из ничего»
Шекспир – оригинальный текст
«Гамлет»
«Много шума из ничего»
Слайд 35Шекспир – перевод
«Гамлет»
(Лозинский)
«Много шума из ничего»
(Щепкина-Куперник)
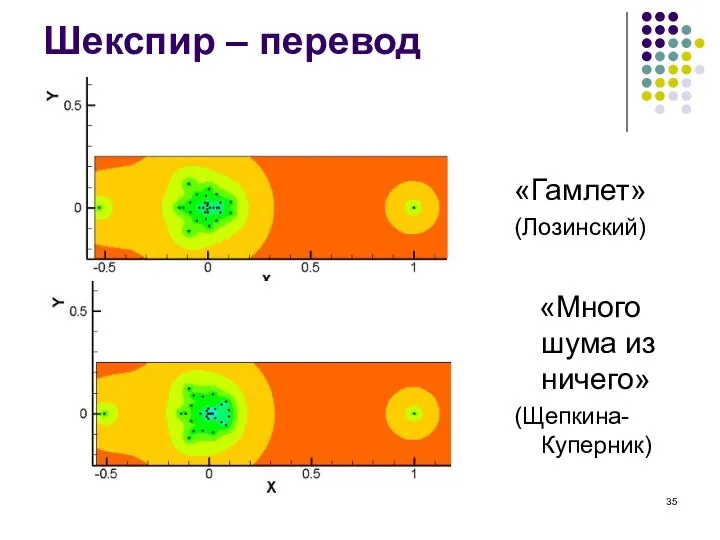
Шекспир – перевод
«Гамлет»
(Лозинский)
«Много шума из ничего»
(Щепкина-Куперник)
Слайд 364. Анализ авторских тандемов
и проверка текста на однородность
и проверка текста на однородность

Слайд 37Горизонтный ряд
Пусть x(t) – эквидистантный временной ряд, f(N,t) – его ВПФР, построенная
Горизонтный ряд
Пусть x(t) – эквидистантный временной ряд, f(N,t) – его ВПФР, построенная

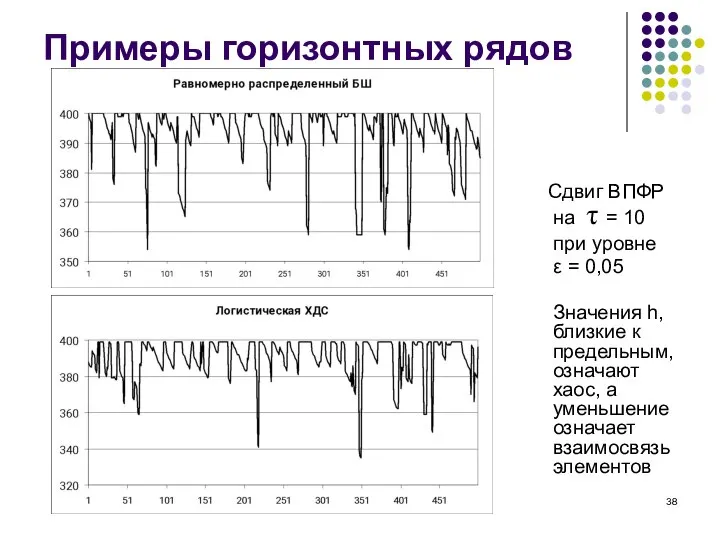
Слайд 38Примеры горизонтных рядов
Сдвиг ВПФР на τ = 10
при уровне
Примеры горизонтных рядов
Сдвиг ВПФР на τ = 10
при уровне
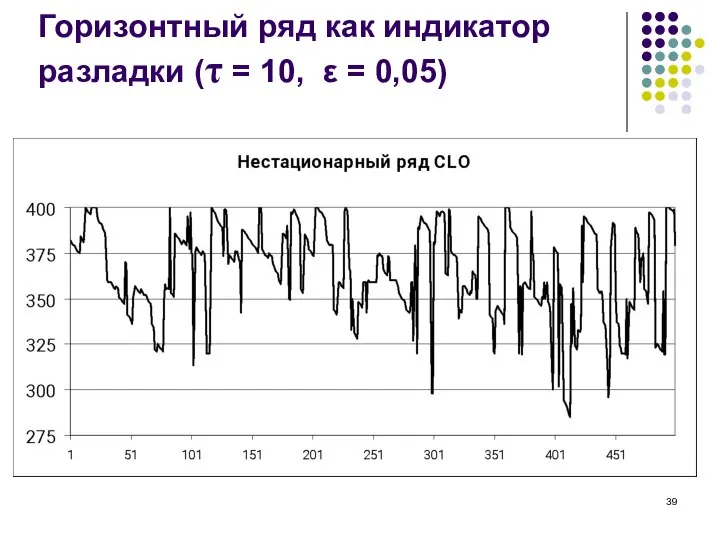
Слайд 39Горизонтный ряд как индикатор разладки (τ = 10, ε = 0,05)
Горизонтный ряд как индикатор разладки (τ = 10, ε = 0,05)
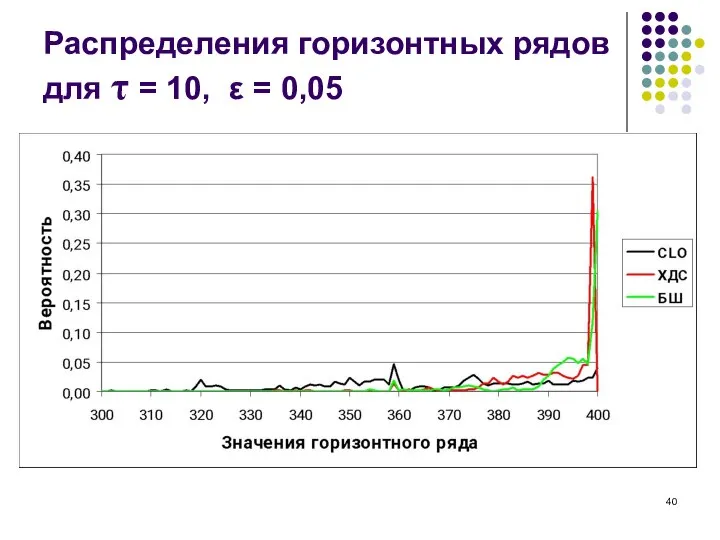
Слайд 40Распределения горизонтных рядов для τ = 10, ε = 0,05
Распределения горизонтных рядов для τ = 10, ε = 0,05
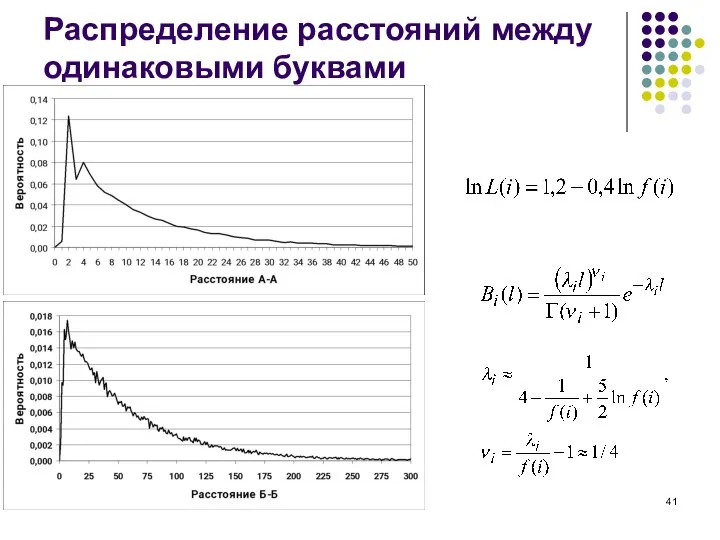
Слайд 41Распределение расстояний между одинаковыми буквами
Распределение расстояний между одинаковыми буквами
Слайд 42Распределение горизонтного ряда для расстояний «b-b» (τ = 10, ε = 0,05)
Для
Распределение горизонтного ряда для расстояний «b-b» (τ = 10, ε = 0,05)
Для
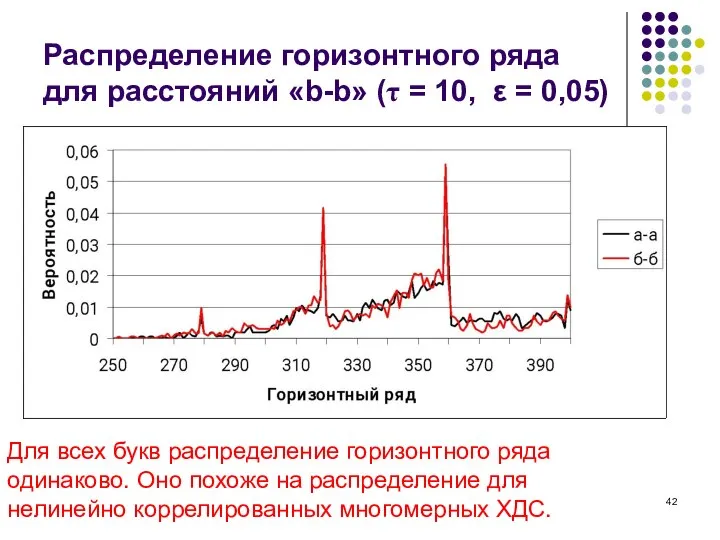
Слайд 43Горизонтные ряды расстояний между гласными для моно и тандема
У моно-писателей горизонтный ряд
Горизонтные ряды расстояний между гласными для моно и тандема
У моно-писателей горизонтный ряд
Слайд 445. Упорядоченность букв по частоте встречаемости в европейских языках

Слайд 45Расстояния между текстами при различном упорядочении
Расстояния между текстами при различном упорядочении
Слайд 46Распределение букв по частоте в алфавите из n=32 знаков
С детерминацией 0,97
Распределение букв по частоте в алфавите из n=32 знаков
С детерминацией 0,97
Слайд 47Распределение букв по частоте в текстах на русском языке
Минимальная интегральная ошибка
Распределение букв по частоте в текстах на русском языке
Минимальная интегральная ошибка
Слайд 48Избыточность и недостаточность алфавитов европейских языков
Параметр o трактуем как оценку избыточности (o<0)
Избыточность и недостаточность алфавитов европейских языков
Параметр o трактуем как оценку избыточности (o<0)

Слайд 49Основные результаты
3-ПФР представляет ту текстовую структуру, расстояние в которой позволяет с высокой
Основные результаты
3-ПФР представляет ту текстовую структуру, расстояние в которой позволяет с высокой

 аксіоми стереометрії
аксіоми стереометрії Daļas atņemšana no veselā
Daļas atņemšana no veselā Вычитание чисел. Математический тренажер
Вычитание чисел. Математический тренажер Координаты вектора
Координаты вектора Деление натуральных чисел
Деление натуральных чисел Исследование транспортной задачи с нечёткими условиями
Исследование транспортной задачи с нечёткими условиями Правило произведения. Комбинаторика
Правило произведения. Комбинаторика Реляционная алгебра
Реляционная алгебра Виды векторов
Виды векторов Нулевой угловой коэффицент
Нулевой угловой коэффицент Параллельный перенос
Параллельный перенос Презентация на тему Цилиндр 11 класс
Презентация на тему Цилиндр 11 класс  Усный счет
Усный счет Урок-игра Математика и здоровье. Поликлиника имени Лобачевкого
Урок-игра Математика и здоровье. Поликлиника имени Лобачевкого Презентация на тему ПРИМЕНЕНИЕ ТЕСТОВ НА УРОКАХ МАТЕМАТИКИ
Презентация на тему ПРИМЕНЕНИЕ ТЕСТОВ НА УРОКАХ МАТЕМАТИКИ  Измерение углов, расстояний. Теодолит, устройство, поверки (лекция 5)
Измерение углов, расстояний. Теодолит, устройство, поверки (лекция 5) Физико-математический турнир. Интегрированный урок
Физико-математический турнир. Интегрированный урок Решение задач на доказательство равенства треугольников на готовых чертежах
Решение задач на доказательство равенства треугольников на готовых чертежах Приведение дробей к общему знаменателю Молодых Наталья Андреевна Учитель математики средней школы № 3 г.Каменска- Уральского Св
Приведение дробей к общему знаменателю Молодых Наталья Андреевна Учитель математики средней школы № 3 г.Каменска- Уральского Св Презентация на тему Статистика
Презентация на тему Статистика  Презентация на тему Прямоугольная система координат в пространстве (11 класс)
Презентация на тему Прямоугольная система координат в пространстве (11 класс)  Типовые звенья
Типовые звенья Положительные и отрицательные числа. Диагностика
Положительные и отрицательные числа. Диагностика Презентация на тему Решение задач - Треугольники
Презентация на тему Решение задач - Треугольники  Представьте данные смешанные числа в виде неправильных дробей
Представьте данные смешанные числа в виде неправильных дробей Сжатие(растяжение) графика вдоль оси ординат
Сжатие(растяжение) графика вдоль оси ординат Случаи вычитания 12 -
Случаи вычитания 12 - Закрепление изученного материала
Закрепление изученного материала