- Backpropagation

Содержание
- 2. Общая схема обучения ... 1. prepare batch 2. forward pass 3. backward pass 4. update weights
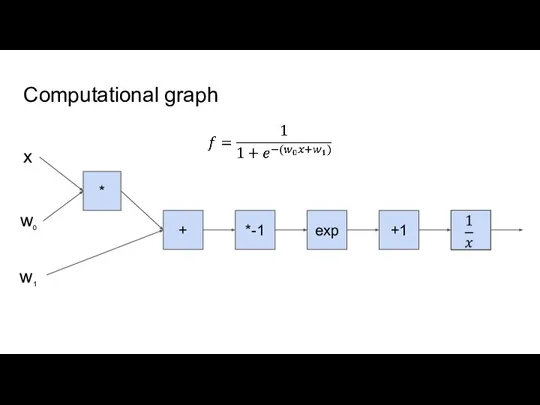
- 3. Computational graph * + *-1 exp +1 x w0 w1
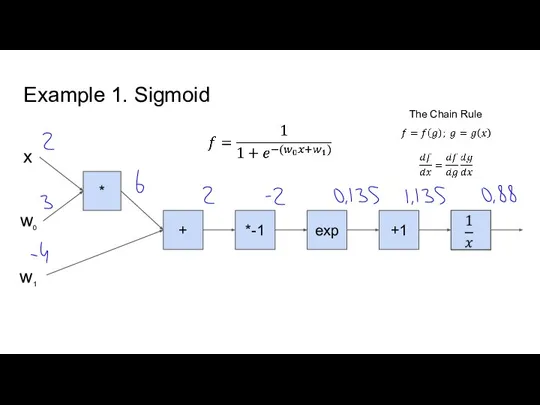
- 4. Example 1. Sigmoid * + *-1 exp +1 x w0 The Chain Rule w1
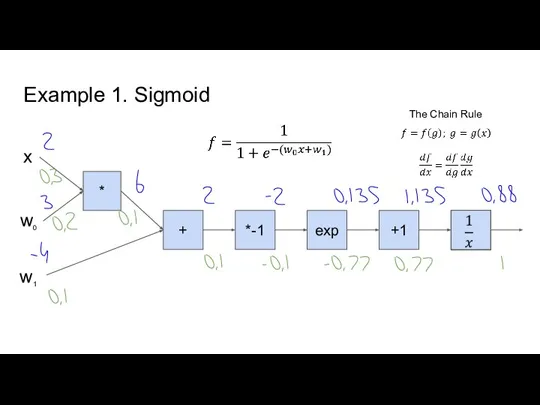
- 5. Example 1. Sigmoid * + *-1 exp +1 x w0 w1 The Chain Rule
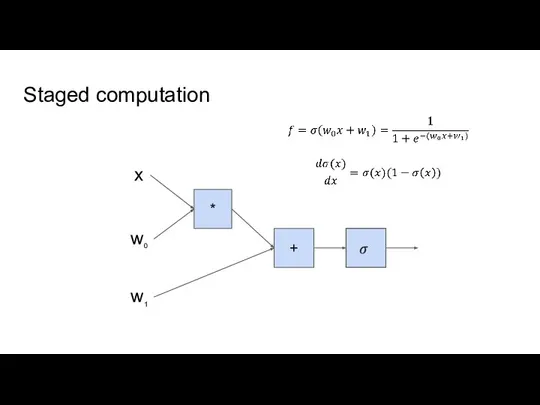
- 6. Staged computation * + x w0 w1
- 7. Gradient checking
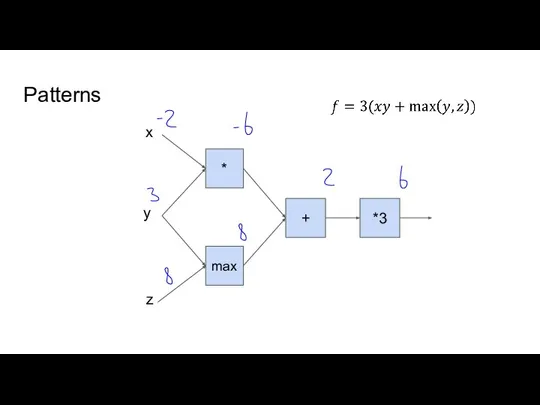
- 8. Patterns * + *3 x y z max
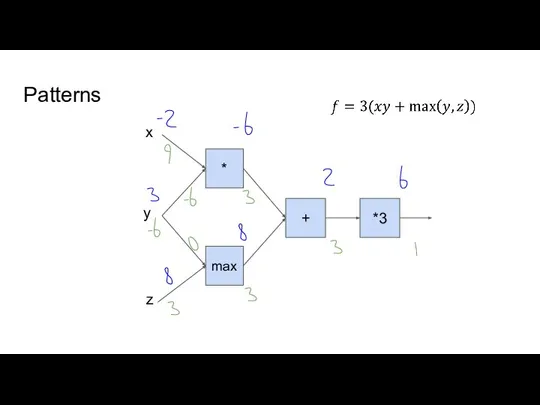
- 9. Patterns * + *3 max x y z
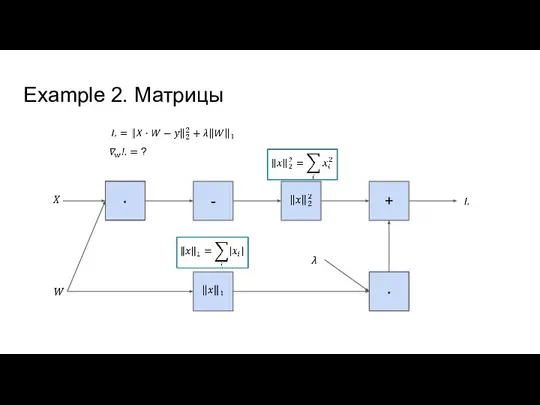
- 10. Example 2. Матрицы + -
- 11. Example 2. Матрицы Если Z = XY, то зная dZ имеем: далее dx = df /
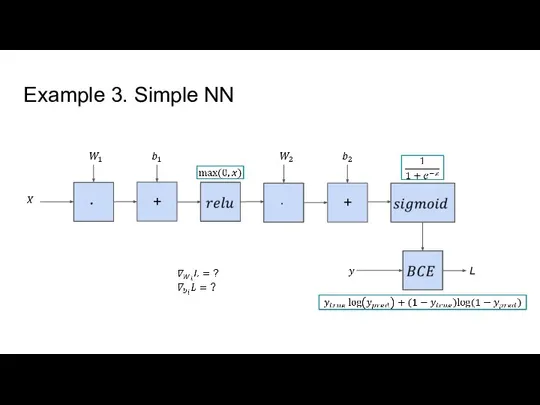
- 12. Example 3. Simple NN + + L
- 13. Example 4. Softmax
- 14. Example 4. Softmax
- 15. На практике backprop для softmax и cross-entropy loss обычно считают вместе В таком случае получается очень
- 17. Скачать презентацию
Слайд 2Общая схема обучения
...
1. prepare batch
2. forward pass
3. backward pass
4. update weights
non-linear activation
softmax
Общая схема обучения
...
1. prepare batch
2. forward pass
3. backward pass
4. update weights
non-linear activation
softmax

Слайд 3Computational graph
*
+
*-1
exp
+1
x
w0
w1
Computational graph
*
+
*-1
exp
+1
x
w0
w1
Слайд 4Example 1. Sigmoid
*
+
*-1
exp
+1
x
w0
The Chain Rule
w1
Example 1. Sigmoid
*
+
*-1
exp
+1
x
w0
The Chain Rule
w1
Слайд 5Example 1. Sigmoid
*
+
*-1
exp
+1
x
w0
w1
The Chain Rule
Example 1. Sigmoid
*
+
*-1
exp
+1
x
w0
w1
The Chain Rule
Слайд 6Staged computation
*
+
x
w0
w1
Staged computation
*
+
x
w0
w1
Слайд 7Gradient checking
Gradient checking

Слайд 8Patterns
*
+
*3
x
y
z
max
Patterns
*
+
*3
x
y
z
max
Слайд 9Patterns
*
+
*3
max
x
y
z
Patterns
*
+
*3
max
x
y
z
Слайд 10Example 2. Матрицы
+
-
Example 2. Матрицы
+
-
Слайд 11Example 2. Матрицы
Если Z = XY, то зная dZ имеем:
далее dx =
Example 2. Матрицы
Если Z = XY, то зная dZ имеем:
далее dx =

Слайд 12Example 3. Simple NN
+
+
L
Example 3. Simple NN
+
+
L
Слайд 13Example 4. Softmax
Example 4. Softmax

Слайд 14Example 4. Softmax
Example 4. Softmax

Слайд 15На практике backprop для softmax и cross-entropy loss обычно считают вместе
В таком
На практике backprop для softmax и cross-entropy loss обычно считают вместе
В таком

 Признаки равенства треугольников
Признаки равенства треугольников Решение задач по геометрии на параллельность прямых
Решение задач по геометрии на параллельность прямых Прикладна математика
Прикладна математика Геометрические фигуры и тела
Геометрические фигуры и тела L1-1
L1-1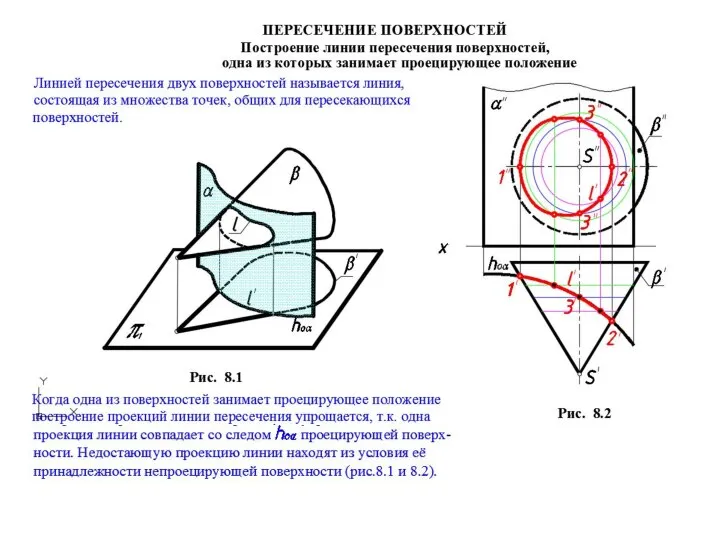 Пересечение поверхностей. Лекция 8,9,10
Пересечение поверхностей. Лекция 8,9,10 Средняя линия треугольника (8 класс)
Средняя линия треугольника (8 класс) Как можно заменить произведение равных сомножителей?
Как можно заменить произведение равных сомножителей? В гостях у деда. Аксиомы стереометрии
В гостях у деда. Аксиомы стереометрии Раз, два, три. Спортивно-математический турнир
Раз, два, три. Спортивно-математический турнир Диаграммы. Задачи
Диаграммы. Задачи Своя игра. Тесная связь математики с другими науками
Своя игра. Тесная связь математики с другими науками Использование краеведческого материала на уроках математики
Использование краеведческого материала на уроках математики Высшая математика. Экзамен (1й курс)
Высшая математика. Экзамен (1й курс) Приведение дробей к общему знаменателю Молодых Наталья Андреевна Учитель математики средней школы № 3 г.Каменска- Уральского Св
Приведение дробей к общему знаменателю Молодых Наталья Андреевна Учитель математики средней школы № 3 г.Каменска- Уральского Св Применение производной в различных науках
Применение производной в различных науках Чтобы найти целое, нужно сложить части
Чтобы найти целое, нужно сложить части Показательная функция, ее свойства и график. 11 класс
Показательная функция, ее свойства и график. 11 класс Задача на тему: Прогрессия
Задача на тему: Прогрессия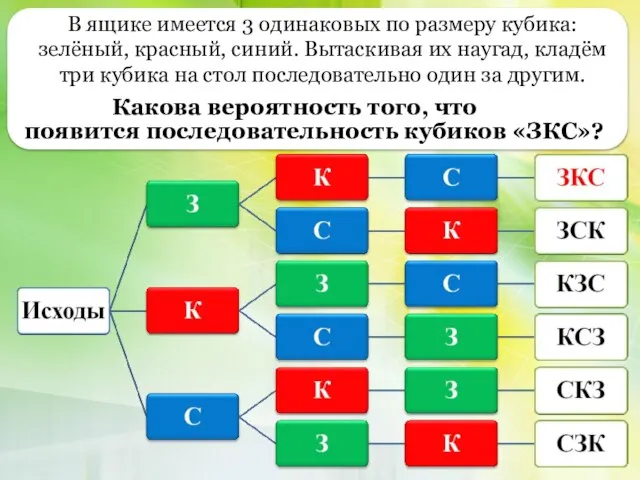 Решение вероятностных задач с помощью комбинаторики. 3-й вид задач
Решение вероятностных задач с помощью комбинаторики. 3-й вид задач Геометрические фигуры. 2 класс
Геометрические фигуры. 2 класс Классическое и статистическое определение вероятности. Основные теоремы теории вероятностей. Лекция 2
Классическое и статистическое определение вероятности. Основные теоремы теории вероятностей. Лекция 2 Lektsia_1
Lektsia_1 Сложение и вычитание десятичных дробей
Сложение и вычитание десятичных дробей Параллельные прямые
Параллельные прямые Правильні многокутники. Довжина кола. Площа круга
Правильні многокутники. Довжина кола. Площа круга Математический КВН
Математический КВН Веселый счет (Счет в прямом и обратном порядке в пределах 10)
Веселый счет (Счет в прямом и обратном порядке в пределах 10)