- Ряды динамики

Содержание
- 2. Понятие рядов динамики Dr. Igor Arzhenovskiy Статистика Ряд динамики (или временной, или хронологический ряд – это
- 3. Компоненты ряда динамики Dr. Igor Arzhenovskiy Статистика ● тренд T(t) – это основная тенденция развития явления
- 4. Связь компонентов ряда динамики Статистика Между компонентами ряда динамики существует аддитивная либо мультипликативная связь ● аддитивная
- 5. Показатели ряда динамики Статистика ● Начальный уровень ряда ● Конечный уровень ряда ● Средний уровень ряда
- 6. Показатели ряда динамики Статистика ● Начальный уровень ряда ● Конечный уровень ряда ● Средний уровень ряда
- 7. Пример 2: Предприятие выпустило продукции за первые 3 месяца года на 300 тыс. руб., за последующие
- 8. Dr. Igor Arzhenovskiy Статистика Для моментного ряда c равноотстоящими интервалами средний уровень исчисляется по формуле средней
- 9. Dr. Igor Arzhenovskiy Статистика Для моментного ряда с неравноотстоящими интервалами применяют формулу средней хронологической взвешенной: В
- 10. Dr. Igor Arzhenovskiy Статистика Темпы роста и прироста Коэффициент роста отвечает на вопрос, во сколько раз
- 11. Dr. Igor Arzhenovskiy Статистика Правила составления рядов динамики 1. Все уровни динамического ряда должны быть сопоставимыми
- 12. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Сглаживание и выравнивание ряда 1. Выявление тренда визуальным методом
- 13. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Сглаживание и выравнивание ряда Сведения о продажах продукции по
- 14. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Сглаживание и выравнивание ряда Уравнение регрессии: Выровненные значения y:
- 15. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Приведение ряда динамики к одному основанию Метод используется в
- 16. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Смыкание рядов динамики Метод используется в случае, если необходимо
- 17. Dr. Igor Arzhenovskiy Статистика Преобразование рядов динамики Интерполяция и экстраполяция Интерполяция – нахождение уровней внутри динамического
- 18. Dr. Igor Arzhenovskiy Статистика Определение и устранение сезонных колебаний 1. Если тренд не известен - Определяем
- 19. Dr. Igor Arzhenovskiy Статистика Определение и устранение сезонных колебаний Пример: оборот предприятия за 3 года
- 20. Dr. Igor Arzhenovskiy Статистика Определение и устранение сезонных колебаний 1) Определяем среднемесячные оборот по годам 1
- 21. Dr. Igor Arzhenovskiy Статистика Определение и устранение сезонных колебаний 3) Рассчитанные величины для одноименных месяцев складываются
- 22. Тема 10. Выборка 1. Понятие выборки 2. Способы отбора 3. Ошибки выборки 4. Доверительные интервалы. Распространение
- 23. Понятие выборки Выборка – это один из видов несплошного наблюдения, когда о целом судят по его
- 24. Cпособы отбора Dr. Igor Arzhenovskiy Статистика 1) Собственно случайный отбор - это отбор по жребию, по
- 25. Способы отбора Dr. Igor Arzhenovskiy Статистика 3) Типический отбор - генеральная совокупность разбивается на типические группы,
- 26. Ошибки выборки Dr. Igor Arzhenovskiy Статистика где Δ – предельная ошибка выборки Выборка характеризуется прежде всего
- 27. Ошибки выборки Dr. Igor Arzhenovskiy Статистика Случайный отбор - повторный случайный отбор: Пример 2.: из стада
- 28. Ошибки выборки Dr. Igor Arzhenovskiy Статистика 3) Типический отбор - повторный типический отбор - бесповторный типический
- 29. Ошибки выборки Dr. Igor Arzhenovskiy Статистика 4) Серийный отбор - повторный серийный отбор - бесповторный серийный
- 30. Доверительные интервалы Dr. Igor Arzhenovskiy Статистика Выборочные характеристики отличаются от характеристик (параметров) генеральной совокупности, т.е. являются
- 31. Доверительные интервалы Dr. Igor Arzhenovskiy Статистика Пример: при проверке изделий на наличие брака произведена случайная повторная
- 32. Распространение результатов выборки на всю совокупность Dr. Igor Arzhenovskiy Статистика - Метод прямого пересчета заключается в
- 33. Необходимая численность выборки Dr. Igor Arzhenovskiy Статистика Объём выборки – это число единиц генеральной совокупности, которое
- 34. Необходимая численность выборки Dr. Igor Arzhenovskiy Статистика 2) Механический отбор – используются формулы случайного отбора -
- 35. Практика применения выборки Dr. Igor Arzhenovskiy Статистика Основные направления применения выборочного метода: ● маркетинговые исследования ●
- 36. Практика применения выборки Dr. Igor Arzhenovskiy Статистика Пример 2: определение объёма выборки. В ходе изучения конъюнктуры
- 37. Тема 11. Статистическая проверка гипотез 1. Основные понятия и определения 2. Ошибки при проверке гипотез 3.
- 38. Основные понятия и определения Dr. Igor Arzhenovskiy Статистика Статистическая гипотеза – это предположение о свойствах случайных
- 39. Ошибки при проверке гипотез Dr. Igor Arzhenovskiy Статистика Ошибки, допускаемые при проверке гипотез, делятся на два
- 40. Статистические критерии Dr. Igor Arzhenovskiy Статистика Для проверки выдвинутых нулевых гипотез используют случайную величину К, которую
- 41. Критическая область и область принятия гипотезы Dr. Igor Arzhenovskiy Статистика После выбора критерия множество его возможных
- 42. Общая схема проверки гипотез Dr. Igor Arzhenovskiy Статистика Формулируются нулевая и альтернативная гипотезы Н0 и Н1.
- 43. Общая схема проверки гипотез: пример Dr. Igor Arzhenovskiy Статистика Оценить значимость коэффициента корреляции r = 0,89
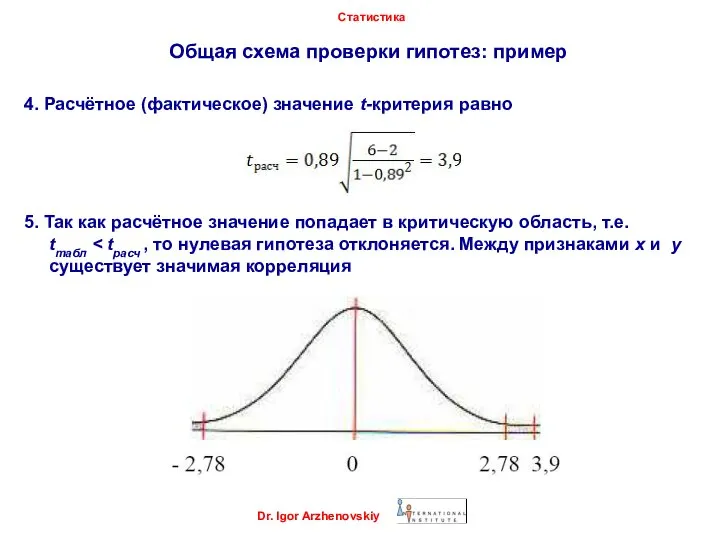
- 44. Общая схема проверки гипотез: пример Dr. Igor Arzhenovskiy Статистика 4. Расчётное (фактическое) значение t-критерия равно 5.
- 45. Критерий согласия χ2 Dr. Igor Arzhenovskiy Статистика Применяется для проверки предположения о нормальном распределении генеральной совокупности.
- 46. Критерий согласия χ2 Dr. Igor Arzhenovskiy Статистика 6. Из таблиц распределения χ2 находится критическое значение χ2табл
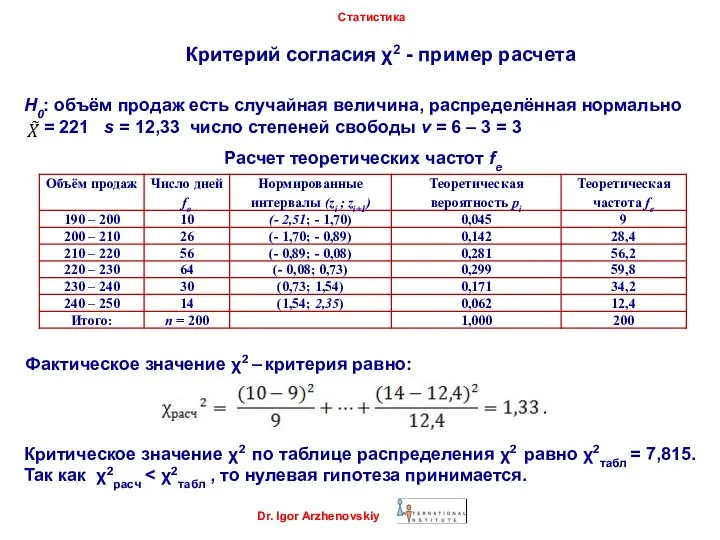
- 47. Критерий согласия χ2 - пример расчета Dr. Igor Arzhenovskiy Статистика Н0: объём продаж есть случайная величина,
- 48. Z - критерий Dr. Igor Arzhenovskiy Статистика Применяется для оценки значимости отклонений параметров генеральной совокупности от
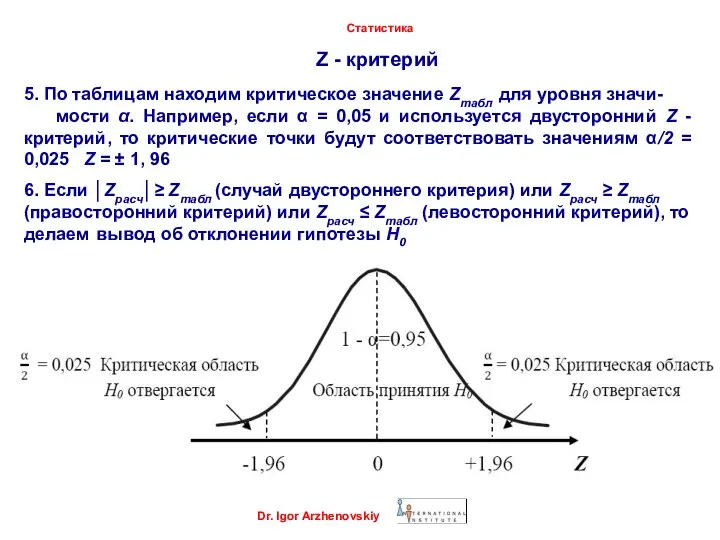
- 49. Z - критерий Dr. Igor Arzhenovskiy Статистика 5. По таблицам находим критическое значение Zтабл для уровня
- 50. Z – критерий – пример расчета Dr. Igor Arzhenovskiy Статистика Вы являетесь менеджером на кондитерской фабрике,
- 51. Dr. Igor Arzhenovskiy Статистика Т - критерий Применяется для оценки значимости отклонений параметров генеральной совокупности от
- 52. Dr. Igor Arzhenovskiy Статистика F-критерий Применяется для сравнения двух выборочных дисперсий из нормальных генеральных совокупностей H0:
- 54. Скачать презентацию
Слайд 2
Понятие рядов динамики
Dr. Igor Arzhenovskiy
Статистика
Ряд динамики (или временной, или хронологический
Понятие рядов динамики
Dr. Igor Arzhenovskiy
Статистика
Ряд динамики (или временной, или хронологический

Слайд 3
Компоненты ряда динамики
Dr. Igor Arzhenovskiy
Статистика
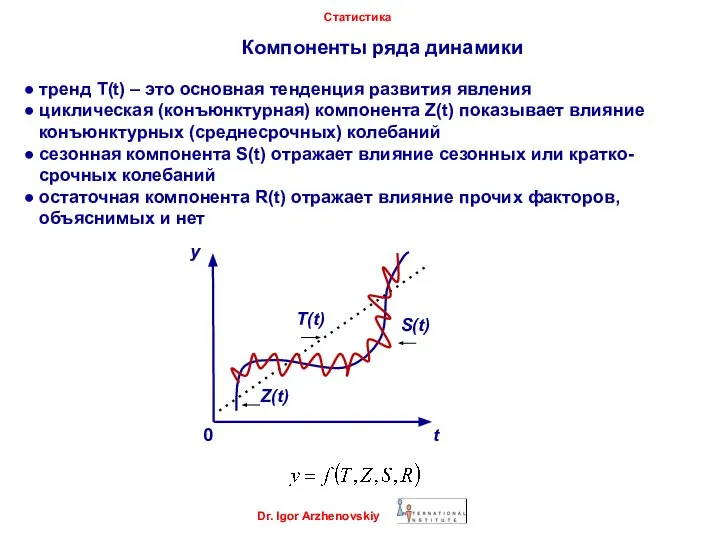
● тренд T(t) – это основная
Компоненты ряда динамики
Dr. Igor Arzhenovskiy
Статистика
● тренд T(t) – это основная
Слайд 4
Связь компонентов ряда динамики
Статистика
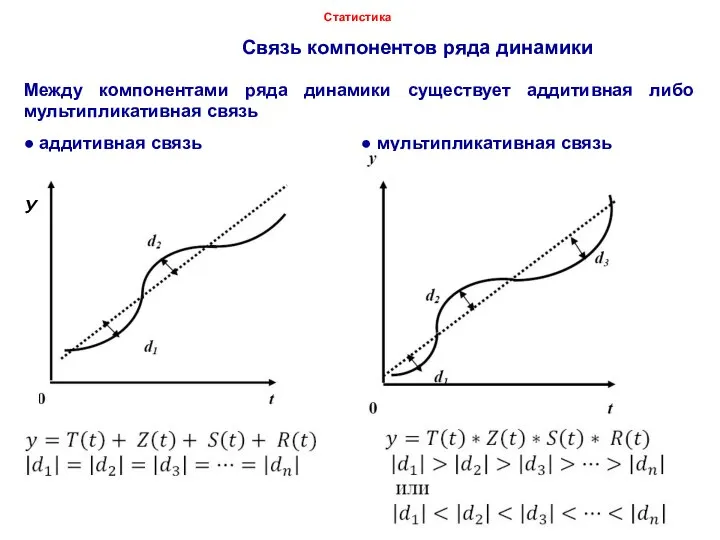
Между компонентами ряда динамики существует аддитивная либо мультипликативная
Связь компонентов ряда динамики
Статистика
Между компонентами ряда динамики существует аддитивная либо мультипликативная
Слайд 5
Показатели ряда динамики
Статистика
● Начальный уровень ряда
● Конечный уровень ряда
● Средний уровень
Показатели ряда динамики
Статистика
● Начальный уровень ряда
● Конечный уровень ряда
● Средний уровень

Слайд 6
Показатели ряда динамики
Статистика
● Начальный уровень ряда
● Конечный уровень ряда
● Средний уровень
Показатели ряда динамики
Статистика
● Начальный уровень ряда
● Конечный уровень ряда
● Средний уровень

Слайд 7
Пример 2: Предприятие выпустило продукции за первые 3 месяца года на
Пример 2: Предприятие выпустило продукции за первые 3 месяца года на

Слайд 8 Dr. Igor Arzhenovskiy
Статистика
Для моментного ряда c равноотстоящими интервалами средний уровень исчисляется
Dr. Igor Arzhenovskiy
Статистика
Для моментного ряда c равноотстоящими интервалами средний уровень исчисляется

Слайд 9 Dr. Igor Arzhenovskiy
Статистика
Для моментного ряда с неравноотстоящими интервалами применяют формулу средней
Dr. Igor Arzhenovskiy
Статистика
Для моментного ряда с неравноотстоящими интервалами применяют формулу средней

Слайд 10 Dr. Igor Arzhenovskiy
Статистика
Темпы роста и прироста
Коэффициент роста отвечает на вопрос,
Dr. Igor Arzhenovskiy
Статистика
Темпы роста и прироста
Коэффициент роста отвечает на вопрос,

Слайд 11 Dr. Igor Arzhenovskiy
Статистика
Правила составления рядов динамики
1. Все уровни динамического ряда
Dr. Igor Arzhenovskiy
Статистика
Правила составления рядов динамики
1. Все уровни динамического ряда

Слайд 12 Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
1. Выявление
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
1. Выявление

Слайд 13 Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
Сведения о
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
Сведения о

Слайд 14 Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
Уравнение регрессии:
Выровненные
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Сглаживание и выравнивание ряда
Уравнение регрессии:
Выровненные

Слайд 15 Dr. Igor Arzhenovskiy
Статистика
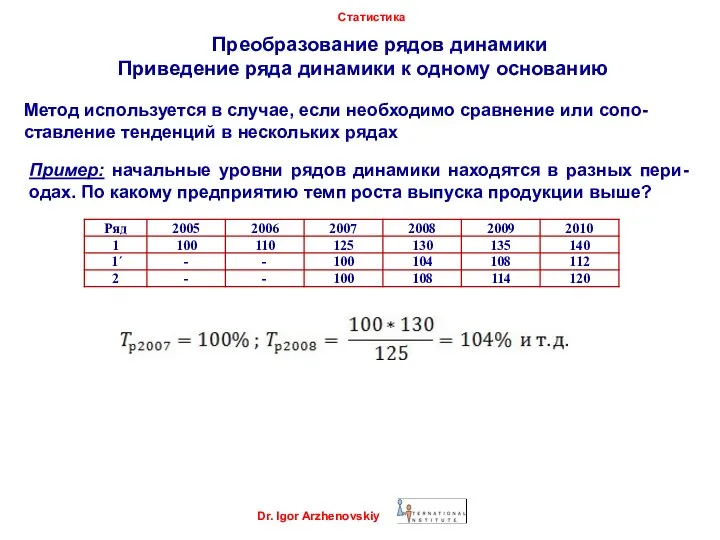
Преобразование рядов динамики
Приведение ряда динамики к одному
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Приведение ряда динамики к одному
Слайд 16 Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
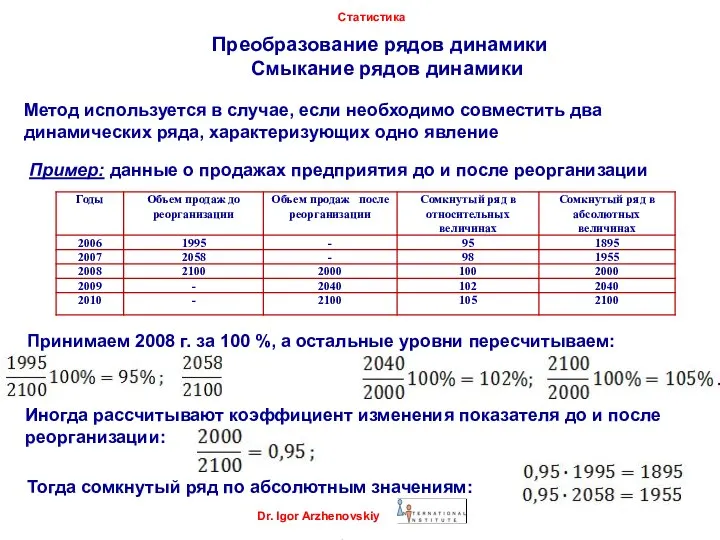
Смыкание рядов динамики
Метод используется в
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Смыкание рядов динамики
Метод используется в
Слайд 17 Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Интерполяция и экстраполяция
Интерполяция – нахождение
Dr. Igor Arzhenovskiy
Статистика
Преобразование рядов динамики
Интерполяция и экстраполяция
Интерполяция – нахождение

Слайд 18 Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
1. Если тренд не
Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
1. Если тренд не

Слайд 19 Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
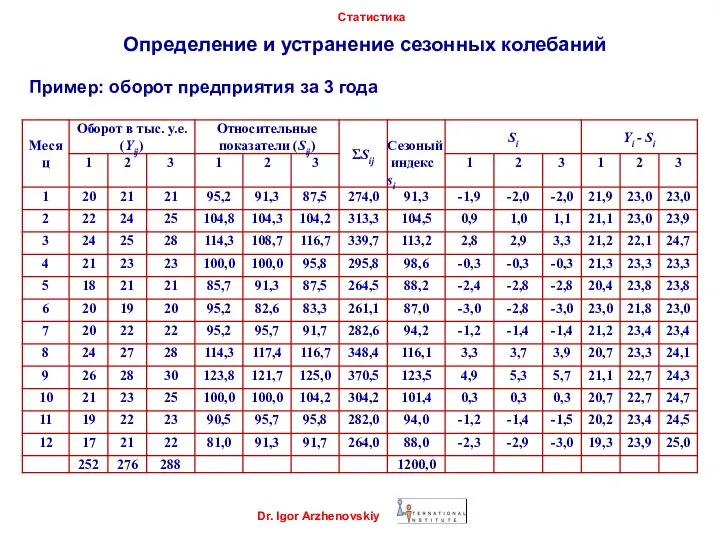
Пример: оборот предприятия за
Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
Пример: оборот предприятия за
Слайд 20 Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
1) Определяем среднемесячные оборот
Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
1) Определяем среднемесячные оборот

Слайд 21 Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
3) Рассчитанные величины для
Dr. Igor Arzhenovskiy
Статистика
Определение и устранение сезонных колебаний
3) Рассчитанные величины для

Слайд 22
Тема 10. Выборка
1. Понятие выборки
2. Способы отбора
3. Ошибки выборки
4. Доверительные
Тема 10. Выборка 1. Понятие выборки 2. Способы отбора 3. Ошибки выборки 4. Доверительные

Слайд 23
Понятие выборки
Выборка – это один из видов несплошного наблюдения, когда
Понятие выборки Выборка – это один из видов несплошного наблюдения, когда

Слайд 24
Cпособы отбора
Dr. Igor Arzhenovskiy
Статистика
1) Собственно случайный отбор - это
Cпособы отбора
Dr. Igor Arzhenovskiy
Статистика
1) Собственно случайный отбор - это

Слайд 25
Способы отбора
Dr. Igor Arzhenovskiy
Статистика
3) Типический отбор - генеральная совокупность
Способы отбора
Dr. Igor Arzhenovskiy
Статистика
3) Типический отбор - генеральная совокупность

Слайд 26 Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
где Δ – предельная ошибка выборки
Выборка характеризуется
Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
где Δ – предельная ошибка выборки
Выборка характеризуется

Слайд 27 Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
Случайный отбор
- повторный случайный отбор:
Пример 2.:
Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
Случайный отбор
- повторный случайный отбор:
Пример 2.:

Слайд 28 Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
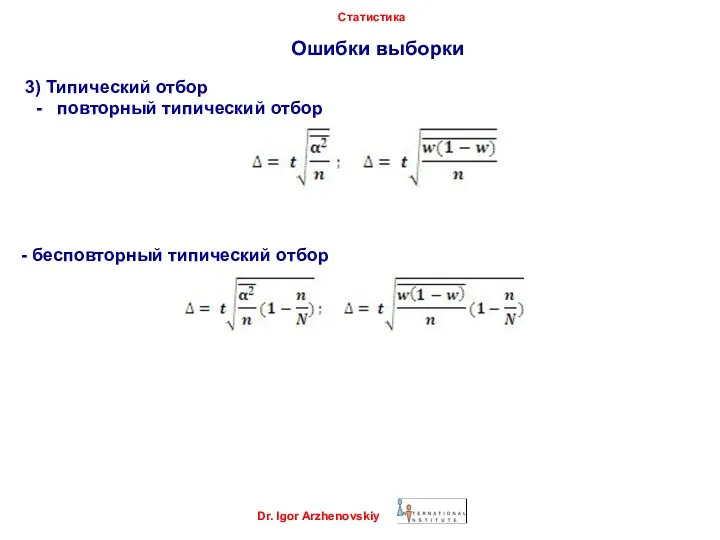
3) Типический отбор
- повторный типический отбор
- бесповторный
Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
3) Типический отбор
- повторный типический отбор
- бесповторный
Слайд 29 Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
4) Серийный отбор
- повторный серийный отбор
- бесповторный
Ошибки выборки
Dr. Igor Arzhenovskiy
Статистика
4) Серийный отбор
- повторный серийный отбор
- бесповторный

Слайд 30 Доверительные интервалы
Dr. Igor Arzhenovskiy
Статистика
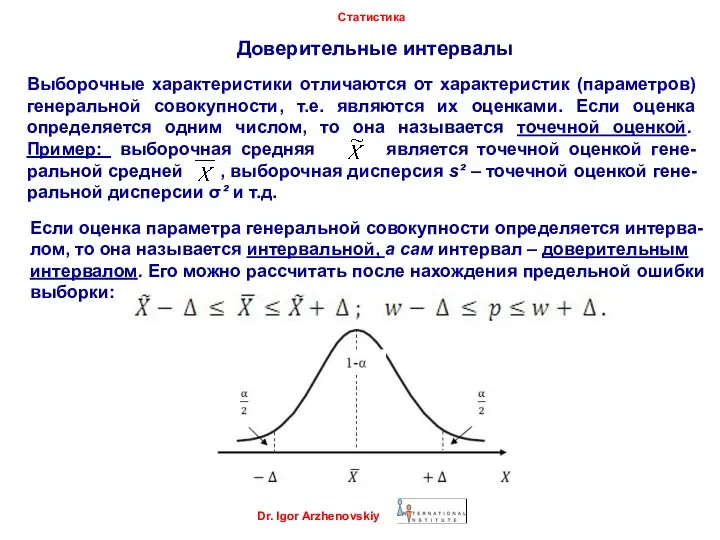
Выборочные характеристики отличаются от характеристик (параметров) генеральной
Доверительные интервалы
Dr. Igor Arzhenovskiy
Статистика
Выборочные характеристики отличаются от характеристик (параметров) генеральной
Слайд 31 Доверительные интервалы
Dr. Igor Arzhenovskiy
Статистика
Пример: при проверке изделий на наличие брака
Доверительные интервалы
Dr. Igor Arzhenovskiy
Статистика
Пример: при проверке изделий на наличие брака

Слайд 32 Распространение результатов выборки на всю совокупность
Dr. Igor Arzhenovskiy
Статистика
- Метод прямого
Распространение результатов выборки на всю совокупность
Dr. Igor Arzhenovskiy
Статистика
- Метод прямого

Слайд 33 Необходимая численность выборки
Dr. Igor Arzhenovskiy
Статистика
Объём выборки – это число
Необходимая численность выборки
Dr. Igor Arzhenovskiy
Статистика
Объём выборки – это число

Слайд 34 Необходимая численность выборки
Dr. Igor Arzhenovskiy
Статистика
2) Механический отбор – используются
Необходимая численность выборки
Dr. Igor Arzhenovskiy
Статистика
2) Механический отбор – используются

Слайд 35 Практика применения выборки
Dr. Igor Arzhenovskiy
Статистика
Основные направления применения выборочного метода:
●
Практика применения выборки
Dr. Igor Arzhenovskiy
Статистика
Основные направления применения выборочного метода:
●

Слайд 36 Практика применения выборки
Dr. Igor Arzhenovskiy
Статистика
Пример 2: определение объёма выборки.
В
Практика применения выборки
Dr. Igor Arzhenovskiy
Статистика
Пример 2: определение объёма выборки.
В

Слайд 37
Тема 11. Статистическая проверка гипотез
1. Основные понятия и определения
2. Ошибки при
Тема 11. Статистическая проверка гипотез 1. Основные понятия и определения 2. Ошибки при

Слайд 38 Основные понятия и определения
Dr. Igor Arzhenovskiy
Статистика
Статистическая гипотеза – это предположение
Основные понятия и определения
Dr. Igor Arzhenovskiy
Статистика
Статистическая гипотеза – это предположение

Слайд 39 Ошибки при проверке гипотез
Dr. Igor Arzhenovskiy
Статистика
Ошибки, допускаемые при проверке гипотез,
Ошибки при проверке гипотез
Dr. Igor Arzhenovskiy
Статистика
Ошибки, допускаемые при проверке гипотез,

Слайд 40 Статистические критерии
Dr. Igor Arzhenovskiy
Статистика
Для проверки выдвинутых нулевых гипотез используют случайную
Статистические критерии
Dr. Igor Arzhenovskiy
Статистика
Для проверки выдвинутых нулевых гипотез используют случайную

Слайд 41 Критическая область и область принятия гипотезы
Dr. Igor Arzhenovskiy
Статистика
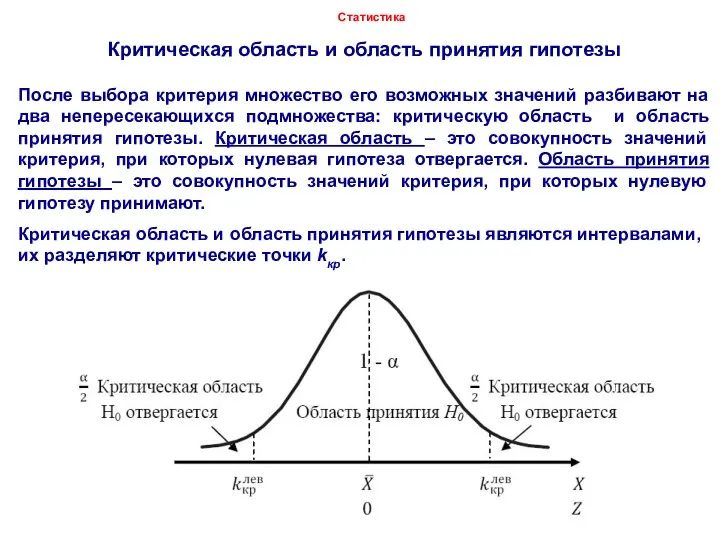
После выбора критерия
Критическая область и область принятия гипотезы
Dr. Igor Arzhenovskiy
Статистика
После выбора критерия
Слайд 42 Общая схема проверки гипотез
Dr. Igor Arzhenovskiy
Статистика
Формулируются нулевая и альтернативная
Общая схема проверки гипотез
Dr. Igor Arzhenovskiy
Статистика
Формулируются нулевая и альтернативная

Слайд 43 Общая схема проверки гипотез: пример
Dr. Igor Arzhenovskiy
Статистика
Оценить значимость коэффициента
Общая схема проверки гипотез: пример
Dr. Igor Arzhenovskiy
Статистика
Оценить значимость коэффициента

Слайд 44 Общая схема проверки гипотез: пример
Dr. Igor Arzhenovskiy
Статистика
4. Расчётное (фактическое) значение
Общая схема проверки гипотез: пример
Dr. Igor Arzhenovskiy
Статистика
4. Расчётное (фактическое) значение
Слайд 45
Критерий согласия χ2
Dr. Igor Arzhenovskiy
Статистика
Применяется для проверки предположения о
Критерий согласия χ2
Dr. Igor Arzhenovskiy
Статистика
Применяется для проверки предположения о

Слайд 46
Критерий согласия χ2
Dr. Igor Arzhenovskiy
Статистика
6. Из таблиц распределения χ2 находится
Критерий согласия χ2
Dr. Igor Arzhenovskiy
Статистика
6. Из таблиц распределения χ2 находится

Слайд 47
Критерий согласия χ2 - пример расчета
Dr. Igor Arzhenovskiy
Статистика
Н0: объём продаж
Критерий согласия χ2 - пример расчета
Dr. Igor Arzhenovskiy
Статистика
Н0: объём продаж
Слайд 48
Z - критерий
Dr. Igor Arzhenovskiy
Статистика
Применяется для оценки значимости отклонений параметров
Z - критерий
Dr. Igor Arzhenovskiy
Статистика
Применяется для оценки значимости отклонений параметров

Слайд 49
Z - критерий
Dr. Igor Arzhenovskiy
Статистика
5. По таблицам находим критическое
Z - критерий
Dr. Igor Arzhenovskiy
Статистика
5. По таблицам находим критическое
Слайд 50
Z – критерий – пример расчета
Dr. Igor Arzhenovskiy
Статистика
Вы являетесь менеджером
Z – критерий – пример расчета
Dr. Igor Arzhenovskiy
Статистика
Вы являетесь менеджером

Слайд 51
Dr. Igor Arzhenovskiy
Статистика
Т - критерий
Применяется для оценки значимости отклонений
Dr. Igor Arzhenovskiy
Статистика
Т - критерий
Применяется для оценки значимости отклонений

Слайд 52
Dr. Igor Arzhenovskiy
Статистика
F-критерий
Применяется для сравнения двух выборочных дисперсий
Dr. Igor Arzhenovskiy
Статистика
F-критерий
Применяется для сравнения двух выборочных дисперсий

 Мгновенное умножение
Мгновенное умножение Случаи вычитания
Случаи вычитания Общие сведения о надстройке Пакет анализа и статистических функциях MS Excel. Лекция 1
Общие сведения о надстройке Пакет анализа и статистических функциях MS Excel. Лекция 1 Сложение и вычитание многочленов
Сложение и вычитание многочленов Происхождение неевклидовой геометрии
Происхождение неевклидовой геометрии Корни натуральной степени из числа, их свойства
Корни натуральной степени из числа, их свойства Определенный интеграл
Определенный интеграл Решение задач. Урок 22
Решение задач. Урок 22 Презентация на тему Функция у=к/х и её график
Презентация на тему Функция у=к/х и её график  Пирамиды
Пирамиды Некоторые законы распределения случайных величин. Нормальный закон распределения (закон Гаусса)
Некоторые законы распределения случайных величин. Нормальный закон распределения (закон Гаусса) Множество. Элемент множества
Множество. Элемент множества Обыкновенные дроби
Обыкновенные дроби В математике один и тот же объект может быть назван по-разному
В математике один и тот же объект может быть назван по-разному Коэффициент. Упрощение выражений
Коэффициент. Упрощение выражений Симметрия в Алтайских орнаментах на примере алтайских костюмов
Симметрия в Алтайских орнаментах на примере алтайских костюмов Умножение числа 5 на однозначное число
Умножение числа 5 на однозначное число Теорема Пифагора
Теорема Пифагора Числовые неравенства
Числовые неравенства Презентация на тему Деление обыкновенных дробей (6 класс)
Презентация на тему Деление обыкновенных дробей (6 класс)  Арккосинус. Решение уравнения cos t = a
Арккосинус. Решение уравнения cos t = a ГИА - 2016. Задачи №9,10,11,12
ГИА - 2016. Задачи №9,10,11,12 Среднее арифметическое. Задания
Среднее арифметическое. Задания Обыкновенные дроби
Обыкновенные дроби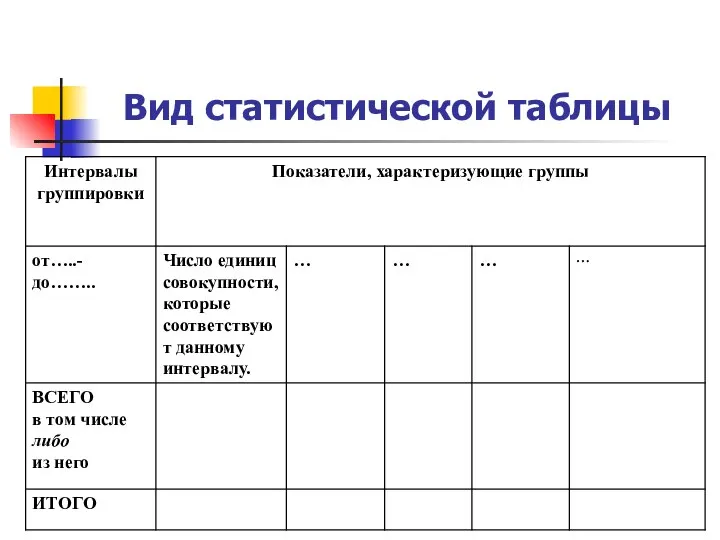 Вид статистической таблицы
Вид статистической таблицы слож и выч вект умножение на число
слож и выч вект умножение на число Определители второго и третьего порядков
Определители второго и третьего порядков _Лекция СА № 2 Структуры и распределения
_Лекция СА № 2 Структуры и распределения